---
layout: post
title: HDFS的Federation之路
category: 技术
tags: Hadoop
keywords:
description: HDFS的Federation之路
---
{:toc}
**该指南提供了HDFS 联邦特性的概述和怎样配置和管理联邦集群**
## 背景
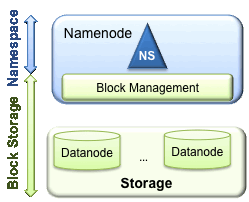
HDFS 有两个主要的层:
- **命名空间**
目录,文件和块的一致性
支持文件系统相关的所有命令空间操作:增删改查等。
- **块存储服务**
- 块管理器(被NN执行)
- 提供了DataNode集群成员注册和周期性报告心跳
- 处理块报告和维护块的位置
- 支持块相关操作,如增删改查块的位置
- 管理副本的位置,重复块下的块副本,删除重复的块
- 存储
- DN提供并将块存储在本地文件系统并且允许读写访问。
以前的HDFS架构只允许在一个集群中有一个`nameservices`,那样的话,单个NN管理`nameservices`。
`Federation`通过对HDFS增加多个NN(nameNode)和多个NS(nameservices)的支持,解除了该限制。
## 多NN/多NS
为了水平扩展NS,`Federation`使用了多个独立的NN/NS,这些NN是结盟的。这些NN是独立的,并且不需要与其他NN相互协调。
DN集群作为所有NN节点公共的块存储使用。每个DN会在集群中的所有NN中注册。DN会定期向所有的NN发送心跳和块报告。
他们也会处理来自NN的命令。
用户可能会用`ViewFS`来创建更加个性化的NS视图。`VIewFS`就像linux/unix系统中的客户端注册表。
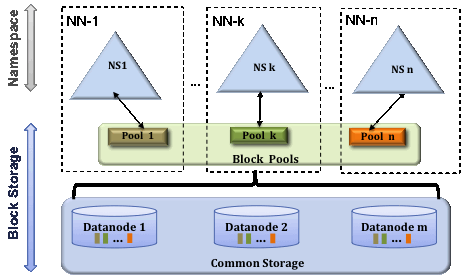
**块池**
块池是属于一个NS的块的集合,DN存储集群中所有块池中的块,每个块池都是独立管理的。这允许一个NS为新的块生成块ID而不需要与其他的NS协调。
集群中一个NN挂掉了,不会影响DN为其他的NN继续提供服务。
NS和它的块池一起叫做**NS卷**,它是独立的经营单位。当一个NN/NS被删除时,其在DN上对应的块也会被删除。
在集群升级的时候,NS卷作为一个单元升级。
**集群ID**
集群ID是为了标识集群内所有的节点。当NN被格式化时,该标识要么被提供要么自动生成。该标识应该被用来格式化加入集群的其他NN
### 核心优势
- NS扩展性
Federation可以添加NS水平扩展。通过将更过的NN加入到集群使,大型部署或部署使用大量小文件从NS扩展中获益。
- 性能
文件系统的吞吐量不再受限于单个NN。在集群中添加更多的NN可以扩展文件系统的吞吐量。
- 隔离
单个NN在多用户环境中没有提供隔离性。比如,一个测试会因为超负载运行,导致生产应用变慢。但是通过多个NS,不同的应用和用户可以隔离在不同的NS中。
## Federation配置
federation 的配置是向后兼容的,并且允许已经存在的单节点配置可以没有任何修改继续工作。新配置设计成集群中所有节点使用相同的配置,这样就不会根据集群节点类型的不同而部署不同的配置了。
Federation会增加一个新的抽象的`NameServiceID`,一个NN和与它相应的Secondary/backup/checkpointer节点属于同一个`NameServiceID`。
为了支持单配置文件,NN和与它相应的Secondary/backup/checkpointer节点配置参数都会有`NameServiceID`。
### 配置
步骤一:添加参数`dfs.nameservices`到你的配置并配置以逗号分隔的`NameServiceID`列表。该设置用于DN判定集群中的NN。
步骤二:在通用配置文件中,每个NN和与它相应的Secondary/backup/checkpointer节点添加如下参数都需要添加相应的`NameServiceID`作为后缀。
|进程|参数|
|---|---|
|NN|dfs.namenode.rpc-address |
|NN|dfs.namenode.servicerpc-address |
|NN|dfs.namenode.http-address |
|NN|dfs.namenode.https-address |
|NN|dfs.namenode.keytab.file |
|NN|dfs.namenode.name.dir |
|NN|dfs.namenode.edits.dir |
|NN|dfs.namenode.checkpoint.dir |
|NN|dfs.namenode.checkpoint.edits.dir|
|SNN|dfs.namenode.secondary.http-address |
|SNN|dfs.secondary.namenode.keytab.file|
|BN|dfs.namenode.backup.address |
|BN|dfs.secondary.namenode.keytab.file|
两个NN配置的例子;
```xml
dfs.nameservices
ns1,ns2
dfs.namenode.rpc-address.ns1
nn-host1:rpc-port
dfs.namenode.http-address.ns1
nn-host1:http-port
dfs.namenode.secondaryhttp-address.ns1
snn-host1:http-port
dfs.namenode.rpc-address.ns2
nn-host2:rpc-port
dfs.namenode.http-address.ns2
nn-host2:http-port
dfs.namenode.secondaryhttp-address.ns2
snn-host2:http-port
.... Other common configuration ...
```
### 格式化NN
步骤一:使用如下命令格式化一个NN
```
$HADOOP_PREFIX/bin/hdfs namenode -format [-clusterId ]
```
``选择一个你的环境中与其他集群不冲突的唯一clusterId,如果没有提供,会自动生成一个唯一id。
步骤二:格式化集群中其他的NN
```
$HADOOP_PREFIX/bin/hdfs namenode -format -clusterId
```
**注意:**该处要使用与步骤一相同的clusteId,如果不同,则附加的NN将不会是联邦集群的一部分。
### 从老版本升级并配置联邦
老版本只支持单个NN,为了启用Federation,升级集群到新版本。升级期间要提供一个像下面这样的clusterId。
```
$HADOOP_PREFIX/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId
```
如果clusterId没有提供,将会自动生成。
### 将新的NN添加到已存在的集群中
执行如下步骤:
- 将`dfs.nameservices`添加到配置中
- 更新带有`NameServiceID `后缀的配置,为了使用Federation,你必须使用新配置参数名称
- 将新的NN相关配置添加到配置文件中
- 将配置文件分散到集群其他所有节点上
- 启动新的NN/SNN/BackUp
- 对集群中所有DN节点通过运行如下的命令,来使得DN能识别新加入的NN。
```
$HADOOP_PREFIX/bin/hdfs dfsadmin -refreshNameNodes :
```
## 管理集群
### 启动和停止集群
启动集群:`$HADOOP_PREFIX/sbin/start-dfs.sh`
停止集群:`$HADOOP_PREFIX/sbin/stop-dfs.sh`
这些命令可以从能读到配置任何节点上执行。该命令根据配置决定集群中的NN,并在这些节点机器上启动NN进程。
DN在`salve`文件中指定的节点上启动。该脚本可以作为你自定义的启动和停止集群脚本的参考。
### 均衡器
均衡器已经改变为可使用多个NN工作。该均衡器可以执行下面的命令:
```
$HADOOP_PREFIX/sbin/hadoop-daemon.sh start balancer [-policy ]
```
policy参数可以是以下的任一种:
- `datenode`
默认的策略,该均衡存储在DN级别。与以前版本的均衡策略很类似。
- `blockpool`
该均衡存储在块池级别,块池的均衡在DN级别
**注意:**均衡器只均衡数据而不均衡namespace
### 停运
停运与之前版本相似,需要停运的节点要加在所有NN的exclude文件中。每个NN停运它自己的块池。只有当所有的NN停运了一个DN,该DN才会考虑停运。
步骤一:分发exclude文件到所有的NN,使用如下命令:
```
$HADOOP_PREFIX/sbin/distribute-exclude.sh
```
步骤二:刷新所有的NN,获取到新的exclude文件。
```
$HADOOP_PREFIX/sbin/refresh-namenodes.sh
```
上面的命令会根据配置决定集群中配置了的NN ,并刷新它们使得获取新的exclude文件。
### 集群web控制界面
和NN的状态web界面相似。在Federation集群可以使用web控制界面时,使用`http:///dfsclusterhealth.jsp`。集群中任一NN都可以访问该页面。
集群的web控制界面提供了如下信息:
- 集群的概览,包括文件数目、块数目、集群中总配置存储容量、可用和已用存储。
- NN的列表和概览,包括每个NN上的文件数目、块数目、丢失块数目、存活的DN数目、死掉的DN数目。也提供了一个连接访问每一个NN的web界面。
- 停用状态的DN。