{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"toc": "true"
},
"source": [
"# Table of Contents\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Newton's Method and Fisher Scoring (KL Chapter 14)\n",
"\n",
"Consider maximizing log-likelihood function $L(\\mathbf{\\theta})$, $\\theta \\in \\Theta \\subset \\mathbb{R}^p$.\n",
"\n",
"## Notations\n",
"\n",
"* **Gradient** (or **score**) of $L$:\n",
" $$\n",
" \\nabla L(\\theta) = \\begin{pmatrix}\n",
" \\frac{\\partial L(\\theta)}{\\partial \\theta_1} \\\\\n",
" \\vdots \\\\\n",
" \\frac{\\partial L(\\theta)}{\\partial \\theta_p}\n",
" \\end{pmatrix}\n",
" $$\n",
" \n",
"* **Hessian** of $L$: \n",
" $$\n",
" \\nabla^2 L(\\theta) = \\begin{pmatrix}\n",
" \\frac{\\partial^2 L(\\theta)}{\\partial \\theta_1 \\partial \\theta_1} & \\dots & \\frac{\\partial^2 L(\\theta)}{\\partial \\theta_1 \\partial \\theta_p} \\\\\n",
" \\vdots & \\ddots & \\vdots \\\\\n",
" \\frac{\\partial^2 L(\\theta)}{\\partial \\theta_p \\partial \\theta_1} & \\dots & \\frac{\\partial^2 L(\\theta)}{\\partial \\theta_p \\partial \\theta_p}\n",
" \\end{pmatrix}\n",
" $$\n",
" \n",
"* **Observed information matrix** (negative Hessian): \n",
"\n",
"$$\n",
" - \\nabla^2 L(\\theta)\n",
"$$\n",
" \n",
"* **Expected (Fisher) information matrix**: \n",
"$$\n",
" \\mathbf{E}[- \\nabla^2 L(\\theta)].\n",
"$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Newton's method\n",
"\n",
"* Newton's method was originally developed for finding roots of nonlinear equations\n",
"$f(\\mathbf{x}) = \\mathbf{0}$ (KL 5.4).\n",
"\n",
"* Newton's method, aka **Newton-Raphson method**, is considered the gold standard for its fast (quadratic) convergence\n",
"$$\n",
"\t\\frac{\\|\\mathbf{\\theta}^{(t+1)} - \\mathbf{\\theta}^*\\|}{\\|\\mathbf{\\theta}^{(t)} - \\mathbf{\\theta}^*\\|^2} \\to \\text{constant}.\n",
"$$\n",
"\n",
"* Idea: iterative quadratic approximation. \n",
"\n",
"* Taylor expansion around the current iterate $\\mathbf{\\theta}^{(t)}$\n",
"$$\n",
"\tL(\\mathbf{\\theta}) \\approx L(\\mathbf{\\theta}^{(t)}) + \\nabla L(\\mathbf{\\theta}^{(t)})^T (\\mathbf{\\theta} - \\mathbf{\\theta}^{(t)}) + \\frac 12 (\\mathbf{\\theta} - \\mathbf{\\theta}^{(t)})^T [\\nabla^2L(\\mathbf{\\theta}^{(t)})] (\\mathbf{\\theta} - \\mathbf{\\theta}^{(t)})\n",
"$$\n",
"and then maximize the quadratic approximation.\n",
"\n",
"* To maximize the quadratic function, we equate its gradient to zero\n",
"$$\n",
"\t\\nabla L(\\theta^{(t)}) + [\\nabla^2L(\\theta^{(t)})] (\\theta - \\theta^{(t)}) = \\mathbf{0}_p,\n",
"$$\n",
"which suggests the next iterate\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\theta^{(t+1)} &=& \\theta^{(t)} - [\\nabla^2L(\\theta^{(t)})]^{-1} \\nabla L(\\theta^{(t)}) \\\\\n",
"\t&=& \\theta^{(t)} + [-\\nabla^2L(\\theta^{(t)})]^{-1} \\nabla L(\\theta^{(t)}).\n",
"\\end{eqnarray*}\n",
"$$\n",
"We call this **naive Newton's method**.\n",
"\n",
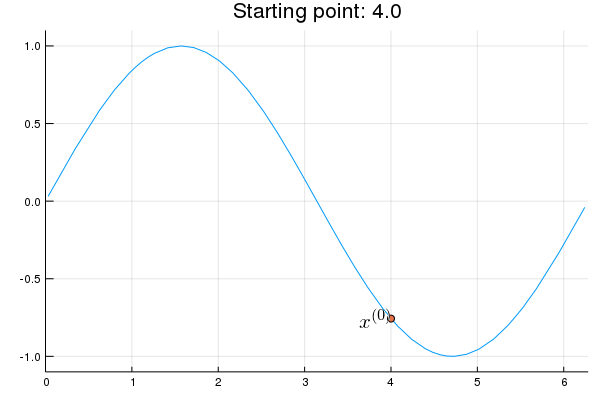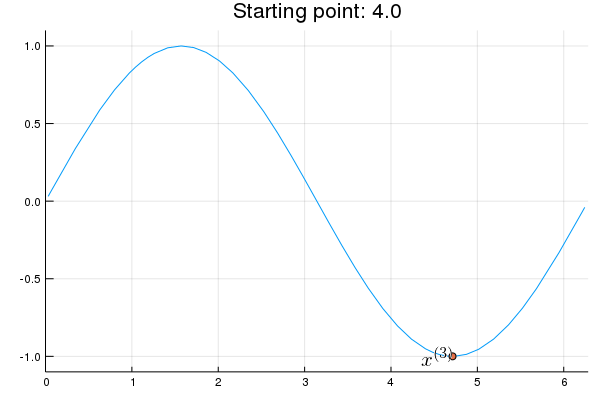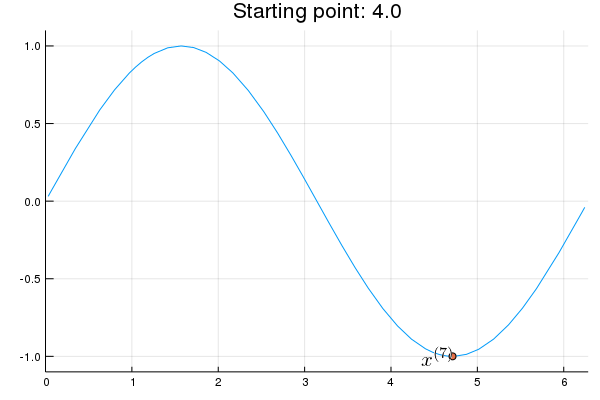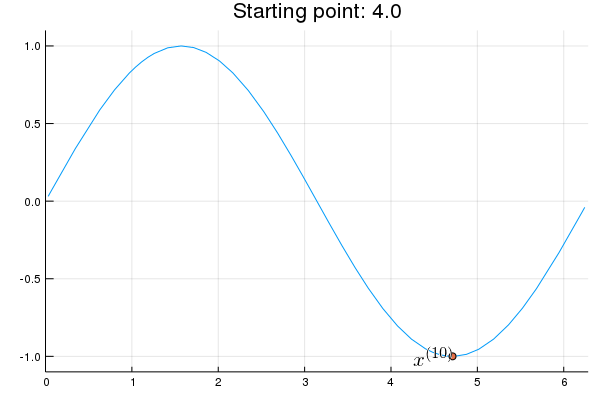
"* **Stability issue**: naive Newton's iterate is **not** guaranteed to be an ascent algorithm. It's equally happy to head uphill or downhill. Following example shows that the Newton iterate converges to a local maximum, converges to a local minimum, or diverges depending on starting points."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"┌ Info: Saved animation to \n",
"│ fn = /Users/huazhou/Documents/github.com/Hua-Zhou.github.io/teaching/biostatm280-2019spring/slides/21-newton/tmp.gif\n",
"└ @ Plots /Users/huazhou/.julia/packages/Plots/oiirH/src/animation.jl:90\n"
]
}
],
"source": [
"using Plots; gr()\n",
"using LaTeXStrings, ForwardDiff\n",
"\n",
"f(x) = sin(x)\n",
"df = x -> ForwardDiff.derivative(f, x) # gradient\n",
"d2f = x -> ForwardDiff.derivative(df, x) # hessian\n",
"x = 2.0 # start point: 2.0 (local maximum), 2.75 (diverge), 4.0 (local minimum)\n",
"titletext = \"Starting point: $x\"\n",
"anim = @animate for iter in 0:10\n",
" iter > 0 && (global x = x - d2f(x) \\ df(x))\n",
" p = Plots.plot(f, 0, 2π, xlim=(0, 2π), ylim=(-1.1, 1.1), legend=nothing, title=titletext)\n",
" Plots.plot!(p, [x], [f(x)], shape=:circle)\n",
" Plots.annotate!(p, x, f(x), text(latexstring(\"x^{($iter)}\"), :right))\n",
"end\n",
"gif(anim, \"./tmp.gif\", fps = 1);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"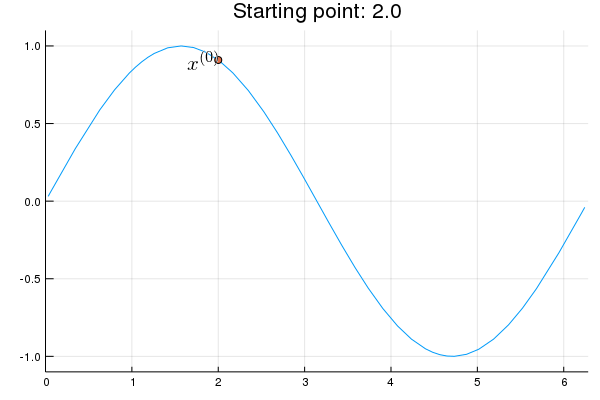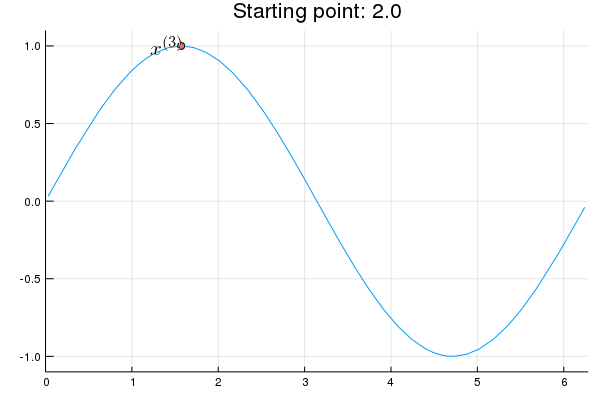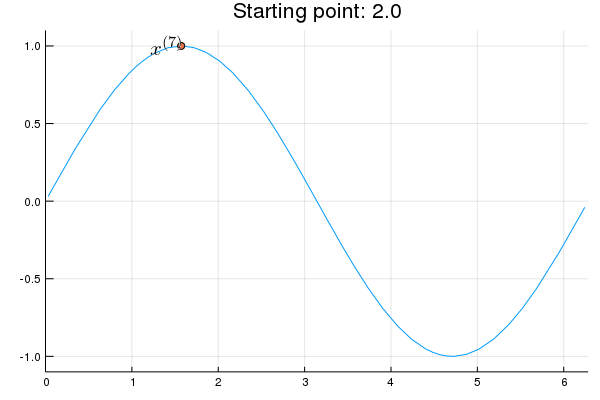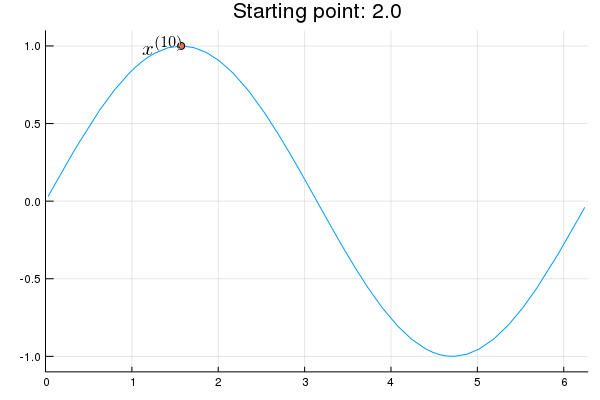\n",
"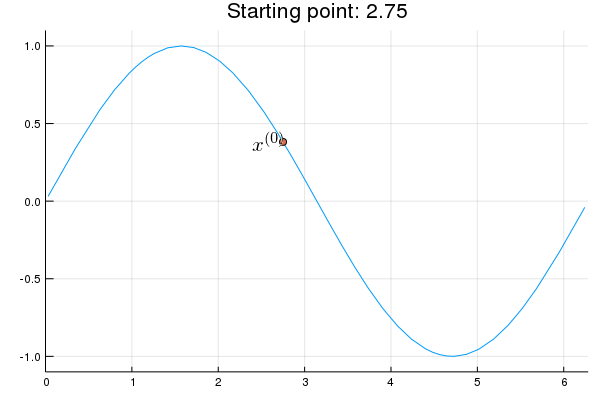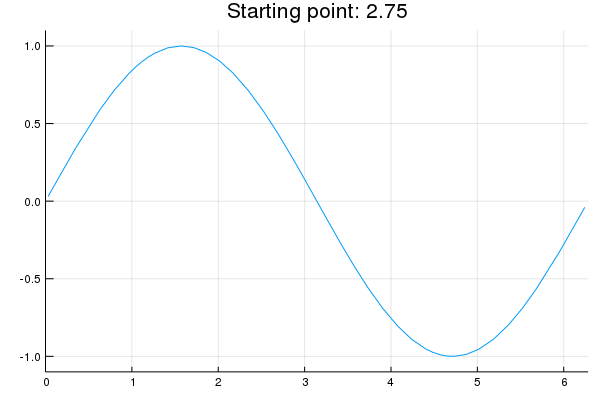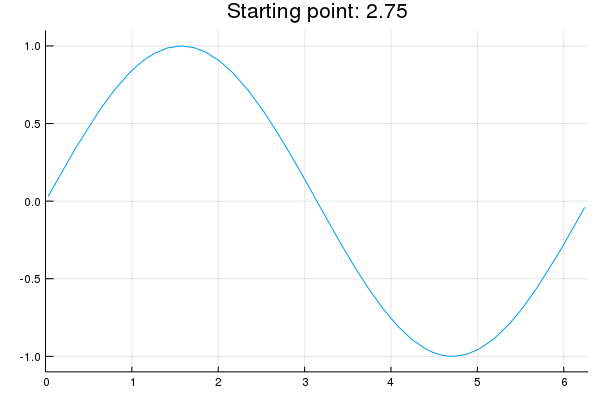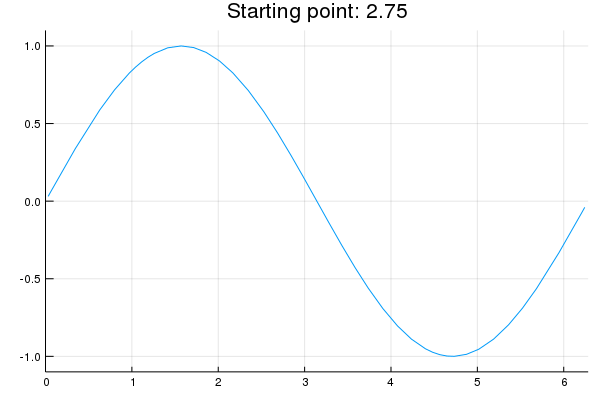\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Remedies for the instability issue:\n",
" 1. approximate $-\\nabla^2L(\\theta^{(t)})$ by a positive definite $\\mathbf{A}$ (if it's not), **and** \n",
" 2. line search (backtracking). \n",
"\n",
"* Why insist on a _positive definite_ approximation of Hessian? By first-order Taylor expansion,\n",
"$$\n",
"\\begin{eqnarray*}\n",
" & & L(\\theta^{(t)} + s \\Delta \\theta^{(t)}) - L(\\theta^{(t)}) \\\\\n",
" &=& \\nabla L(\\theta^{(t)})^T s \\Delta \\theta^{(t)} + o(s) \\\\\n",
" &=& s \\cdot \\nabla L(\\theta^{(t)})^T [\\mathbf{A}^{(t)}]^{-1} \\nabla L(\\theta^{(t)}) + o(s).\n",
"\\end{eqnarray*}\n",
"$$\n",
"For $s$ sufficiently small, right hand side is strictly positive when $\\mathbf{A}^{(t)}$ is positive definite. The quantity $\\{\\nabla L(\\theta^{(t)})^T [\\mathbf{A}^{(t)}]^{-1} \\nabla L(\\theta^{(t)})\\}^{1/2}$ is termed the **Newton decrement**.\n",
"\n",
"* In summary, a **practical Newton-type algorithm** iterates according to\n",
"$$\n",
"\t\\boxed{ \\theta^{(t+1)} = \\theta^{(t)} + s [\\mathbf{A}^{(t)}]^{-1} \\nabla L(\\theta^{(t)}) \n",
"\t= \\theta^{(t)} + s \\Delta \\theta^{(t)} }\n",
"$$\n",
"where $\\mathbf{A}^{(t)}$ is a pd approximation of $-\\nabla^2L(\\theta^{(t)})$ and $s$ is a step length.\n",
"\n",
"* For strictly concave $L$, $-\\nabla^2L(\\theta^{(t)})$ is always positive definite. Line search is still needed to guarantee convergence.\n",
"\n",
"* Line search strategy: step-halving ($s=1,1/2,\\ldots$), golden section search, cubic interpolation, Amijo rule, ... Note the **Newton direction** \n",
"$$\n",
"\\Delta \\theta^{(t)} = [\\mathbf{A}^{(t)}]^{-1} \\nabla L(\\theta^{(t)})\n",
"$$\n",
"only needs to be calculated once. Cost of line search mainly lies in objective function evaluation.\n",
"\n",
"* How to approximate $-\\nabla^2L(\\theta)$? More of an art than science. Often requires problem specific analysis. \n",
"\n",
"* Taking $\\mathbf{A} = \\mathbf{I}$ leads to the method of **steepest ascent**, aka **gradient ascent**.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Fisher's scoring method\n",
"\n",
"* **Fisher's scoring method**: replace $- \\nabla^2L(\\theta)$ by the expected Fisher information matrix\n",
"$$\n",
"\t\\mathbf{FIM}(\\theta) = \\mathbf{E}[-\\nabla^2L(\\theta)] = \\mathbf{E}[\\nabla L(\\theta) \\nabla L(\\theta)^T] \\succeq \\mathbf{0}_{p \\times p},\n",
"$$\n",
"which is psd under exchangeability of expectation and differentiation.\n",
"\n",
" Therefore the Fisher's scoring algorithm iterates according to\n",
"$$\n",
"\t\\boxed{ \\theta^{(t+1)} = \\theta^{(t)} + s [\\mathbf{FIM}(\\theta^{(t)})]^{-1} \\nabla L(\\theta^{(t)})}.\n",
"$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generalized linear model (GLM) (KL 14.7)\n",
"\n",
"### Logistic regression\n",
"\n",
"Let's consider a concrete example: logistic regression.\n",
"\n",
"* The goal is to predict whether a credit card transaction is fraud ($y_i=1$) or not ($y_i=0$). Predictors ($\\mathbf{x}_i$) include: time of transaction, last location, merchant, ...\n",
"\n",
"* $y_i \\in \\{0,1\\}$, $\\mathbf{x}_i \\in \\mathbb{R}^{p}$. Model $y_i \\sim $Bernoulli$(p_i)$.\n",
"\n",
"* Logistic regression. Density\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\tf(y_i|p_i) &=& p_i^{y_i} (1-p_i)^{1-y_i} \\\\\n",
"\t&=& e^{y_i \\ln p_i + (1-y_i) \\ln (1-p_i)} \\\\\n",
"\t&=& e^{y_i \\ln \\frac{p_i}{1-p_i} + \\ln (1-p_i)},\n",
"\\end{eqnarray*}\n",
"$$\n",
"where\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\mathbf{E} (y_i) = p_i &=& \\frac{e^{\\eta_i}}{1+ e^{\\eta_i}} \\quad \\text{(mean function, inverse link function)} \\\\\n",
"\t\\eta_i = \\mathbf{x}_i^T \\beta &=& \\ln \\left( \\frac{p_i}{1-p_i} \\right) \\quad \\text{(logit link function)}.\n",
"\\end{eqnarray*}\n",
"$$\n",
"\n",
"* Given data $(y_i,\\mathbf{x}_i)$, $i=1,\\ldots,n$,\n",
"\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\tL_n(\\beta) &=& \\sum_{i=1}^n \\left[ y_i \\ln p_i + (1-y_i) \\ln (1-p_i) \\right] \\\\\n",
"\t&=& \\sum_{i=1}^n \\left[ y_i \\mathbf{x}_i^T \\beta - \\ln (1 + e^{\\mathbf{x}_i^T \\beta}) \\right] \\\\\n",
"\t\\nabla L_n(\\beta) &=& \\sum_{i=1}^n \\left( y_i \\mathbf{x}_i - \\frac{e^{\\mathbf{x}_i^T \\beta}}{1+e^{\\mathbf{x}_i^T \\beta}} \\mathbf{x}_i \\right) \\\\\n",
"\t&=& \\sum_{i=1}^n (y_i - p_i) \\mathbf{x}_i = \\mathbf{X}^T (\\mathbf{y} - \\mathbf{p})\t\\\\\n",
"\t- \\nabla^2L_n(\\beta) &=& \\sum_{i=1}^n p_i(1-p_i) \\mathbf{x}_i \\mathbf{x}_i^T = \\mathbf{X}^T \\mathbf{W} \\mathbf{X}, \\quad\n",
"\t\\text{where } \\mathbf{W} &=& \\text{diag}(w_1,\\ldots,w_n), w_i = p_i (1-p_i) \\\\\n",
"\t\\mathbf{FIM}_n(\\beta) &=& \\mathbf{E} [- \\nabla^2L_n(\\beta)] = - \\nabla^2L_n(\\beta).\n",
"\\end{eqnarray*}\n",
"$$\n",
"\n",
"* Newton's method == Fisher's scoring iteration: \n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\beta^{(t+1)} &=& \\beta^{(t)} + s[-\\nabla^2 L(\\beta^{(t)})]^{-1} \\nabla L(\\beta^{(t)})\t\\\\\n",
"\t&=& \\beta^{(t)} + s(\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T (\\mathbf{y} - \\mathbf{p}^{(t)}) \\\\\n",
"\t&=& (\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T \\mathbf{W}^{(t)} \\left[ \\mathbf{X} \\beta^{(t)} + s(\\mathbf{W}^{(t)})^{-1} (\\mathbf{y} - \\mathbf{p}^{(t)}) \\right] \\\\\n",
"\t&=& (\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{z}^{(t)},\n",
"\\end{eqnarray*}\n",
"$$\n",
"where \n",
"$$\n",
"\t\\mathbf{z}^{(t)} = \\mathbf{X} \\beta^{(t)} + s(\\mathbf{W}^{(t)})^{-1} (\\mathbf{y} - \\mathbf{p}^{(t)})\n",
"$$ \n",
"are the working responses. A Newton's iteration is equivalent to solving a weighed least squares problem $\\sum_{i=1}^n w_i (z_i - \\mathbf{x}_i^T \\beta)^2$. Thus the name **IRWLS (iteratively re-weighted least squares)**.\n",
"\n",
"### GLM \n",
"\n",
"Let's consider the more general class of generalized linear models (GLM).\n",
"\n",
"\n",
"| Family | Canonical Link | Variance Function |\n",
"|------------------|-------------------------------|-------------------|\n",
"| Normal | $\\eta=\\mu$ | 1 |\n",
"| Poisson | $\\eta=\\log \\mu$ | $\\mu$ |\n",
"| Binomial | $\\eta=\\log \\left( \\frac{\\mu}{1 - \\mu} \\right)$ | $\\mu (1 - \\mu)$ |\n",
"| Gamma | $\\eta = \\mu^{-1}$ | $\\mu^2$ |\n",
"| Inverse Gaussian | $\\eta = \\mu^{-2}$ | $\\mu^3$ |\n",
"\n",
"* $Y$ belongs to an exponential family with density\n",
"$$\n",
"\tp(y|\\theta,\\phi) = \\exp \\left\\{ \\frac{y\\theta - b(\\theta)}{a(\\phi)} + c(y,\\phi) \\right\\}.\n",
"$$\n",
" * $\\theta$: natural parameter. \n",
" * $\\phi>0$: dispersion parameter. \n",
"GLM relates the mean $\\mu = \\mathbf{E}(Y|\\mathbf{x})$ via a strictly increasing link function\n",
"$$\n",
"\tg(\\mu) = \\eta = \\mathbf{x}^T \\beta, \\quad \\mu = g^{-1}(\\eta)\n",
"$$\n",
"\n",
"* Score, Hessian, information\n",
"\n",
"$$\n",
"\\begin{eqnarray*}\n",
" \t\\nabla L_n(\\beta) &=& \\sum_{i=1}^n \\frac{(y_i-\\mu_i) \\mu_i'(\\eta_i)}{\\sigma_i^2} \\mathbf{x}_i \\\\\n",
"\t- \\nabla^2 L_n(\\beta) &=& \\sum_{i=1}^n \\frac{[\\mu_i'(\\eta_i)]^2}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T - \\sum_{i=1}^n \\frac{(y_i - \\mu_i) \\theta''(\\eta_i)}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T\t\\\\\n",
"\t\\mathbf{FIM}_n(\\beta) &=& \\mathbf{E} [- \\nabla^2 L_n(\\beta)] = \\sum_{i=1}^n \\frac{[\\mu_i'(\\eta_i)]^2}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T = \\mathbf{X}^T \\mathbf{W} \\mathbf{X}.\n",
"\\end{eqnarray*} \n",
"$$\n",
"\n",
"* Fisher scoring method\n",
"$$\n",
" \t\\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM}(\\beta^{(t)})]^{-1} \\nabla L_n(\\beta^{(t)})\n",
"$$\n",
"IRWLS with weights $w_i = [\\mu_i(\\eta_i)]^2/\\sigma_i^2$ and some working responses $z_i$.\n",
"\n",
"* For **canonical link**, $\\theta = \\eta$, the second term of Hessian vanishes and Hessian coincides with Fisher information matrix. Convex problem 😄\n",
"$$\n",
"\t\\text{Fisher's scoring == Newton's method}.\n",
"$$\n",
" \n",
"* Non-canonical link, non-convex problem 😞\n",
"$$\n",
"\t\\text{Fisher's scoring algorithm} \\ne \\text{Newton's method}.\n",
"$$\n",
"Example: Probit regression (binary response with probit link).\n",
"$$\n",
"\\begin{eqnarray*}\n",
" y_i &\\sim& \\text{Bernoulli}(p_i) \\\\\n",
" p_i &=& \\Phi(\\mathbf{x}_i^T \\beta) \\\\\n",
" \\eta_i &=& \\mathbf{x}_i^T \\beta = \\Phi^{-1}(p_i).\n",
"\\end{eqnarray*}\n",
"$$\n",
"where $\\Phi(\\cdot)$ is the cdf of a standard normal.\n",
" \n",
"* Julia, R and Matlab implement the Fisher scoring method, aka IRWLS, for GLMs.\n",
" * [GLM.jl](https://github.com/JuliaStats/GLM.jl) package."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Nonlinear regression - Gauss-Newton method (KL 14.4-14.6)\n",
"\n",
"* Now we finally get to the problem Gauss faced in 1800! \n",
"Relocate Ceres by fitting 41 observations to a 6-parameter (nonlinear) orbit.\n",
"\n",
"* Nonlinear least squares (curve fitting): \n",
"$$\n",
"\t\\text{minimize} \\,\\, f(\\beta) = \\frac{1}{2} \\sum_{i=1}^n [y_i - \\mu_i(\\mathbf{x}_i, \\beta)]^2\n",
"$$\n",
"For example, $y_i =$ dry weight of onion and $x_i=$ growth time, and we want to fit a 3-parameter growth curve\n",
"$$\n",
"\t\\mu(x, \\beta_1,\\beta_2,\\beta_3) = \\frac{\\beta_3}{1 + e^{-\\beta_1 - \\beta_2 x}}.\n",
"$$\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Fisher's scoring method\n",
"\n",
"* **Fisher's scoring method**: replace $- \\nabla^2L(\\theta)$ by the expected Fisher information matrix\n",
"$$\n",
"\t\\mathbf{FIM}(\\theta) = \\mathbf{E}[-\\nabla^2L(\\theta)] = \\mathbf{E}[\\nabla L(\\theta) \\nabla L(\\theta)^T] \\succeq \\mathbf{0}_{p \\times p},\n",
"$$\n",
"which is psd under exchangeability of expectation and differentiation.\n",
"\n",
" Therefore the Fisher's scoring algorithm iterates according to\n",
"$$\n",
"\t\\boxed{ \\theta^{(t+1)} = \\theta^{(t)} + s [\\mathbf{FIM}(\\theta^{(t)})]^{-1} \\nabla L(\\theta^{(t)})}.\n",
"$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generalized linear model (GLM) (KL 14.7)\n",
"\n",
"### Logistic regression\n",
"\n",
"Let's consider a concrete example: logistic regression.\n",
"\n",
"* The goal is to predict whether a credit card transaction is fraud ($y_i=1$) or not ($y_i=0$). Predictors ($\\mathbf{x}_i$) include: time of transaction, last location, merchant, ...\n",
"\n",
"* $y_i \\in \\{0,1\\}$, $\\mathbf{x}_i \\in \\mathbb{R}^{p}$. Model $y_i \\sim $Bernoulli$(p_i)$.\n",
"\n",
"* Logistic regression. Density\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\tf(y_i|p_i) &=& p_i^{y_i} (1-p_i)^{1-y_i} \\\\\n",
"\t&=& e^{y_i \\ln p_i + (1-y_i) \\ln (1-p_i)} \\\\\n",
"\t&=& e^{y_i \\ln \\frac{p_i}{1-p_i} + \\ln (1-p_i)},\n",
"\\end{eqnarray*}\n",
"$$\n",
"where\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\mathbf{E} (y_i) = p_i &=& \\frac{e^{\\eta_i}}{1+ e^{\\eta_i}} \\quad \\text{(mean function, inverse link function)} \\\\\n",
"\t\\eta_i = \\mathbf{x}_i^T \\beta &=& \\ln \\left( \\frac{p_i}{1-p_i} \\right) \\quad \\text{(logit link function)}.\n",
"\\end{eqnarray*}\n",
"$$\n",
"\n",
"* Given data $(y_i,\\mathbf{x}_i)$, $i=1,\\ldots,n$,\n",
"\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\tL_n(\\beta) &=& \\sum_{i=1}^n \\left[ y_i \\ln p_i + (1-y_i) \\ln (1-p_i) \\right] \\\\\n",
"\t&=& \\sum_{i=1}^n \\left[ y_i \\mathbf{x}_i^T \\beta - \\ln (1 + e^{\\mathbf{x}_i^T \\beta}) \\right] \\\\\n",
"\t\\nabla L_n(\\beta) &=& \\sum_{i=1}^n \\left( y_i \\mathbf{x}_i - \\frac{e^{\\mathbf{x}_i^T \\beta}}{1+e^{\\mathbf{x}_i^T \\beta}} \\mathbf{x}_i \\right) \\\\\n",
"\t&=& \\sum_{i=1}^n (y_i - p_i) \\mathbf{x}_i = \\mathbf{X}^T (\\mathbf{y} - \\mathbf{p})\t\\\\\n",
"\t- \\nabla^2L_n(\\beta) &=& \\sum_{i=1}^n p_i(1-p_i) \\mathbf{x}_i \\mathbf{x}_i^T = \\mathbf{X}^T \\mathbf{W} \\mathbf{X}, \\quad\n",
"\t\\text{where } \\mathbf{W} &=& \\text{diag}(w_1,\\ldots,w_n), w_i = p_i (1-p_i) \\\\\n",
"\t\\mathbf{FIM}_n(\\beta) &=& \\mathbf{E} [- \\nabla^2L_n(\\beta)] = - \\nabla^2L_n(\\beta).\n",
"\\end{eqnarray*}\n",
"$$\n",
"\n",
"* Newton's method == Fisher's scoring iteration: \n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\beta^{(t+1)} &=& \\beta^{(t)} + s[-\\nabla^2 L(\\beta^{(t)})]^{-1} \\nabla L(\\beta^{(t)})\t\\\\\n",
"\t&=& \\beta^{(t)} + s(\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T (\\mathbf{y} - \\mathbf{p}^{(t)}) \\\\\n",
"\t&=& (\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T \\mathbf{W}^{(t)} \\left[ \\mathbf{X} \\beta^{(t)} + s(\\mathbf{W}^{(t)})^{-1} (\\mathbf{y} - \\mathbf{p}^{(t)}) \\right] \\\\\n",
"\t&=& (\\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{X})^{-1} \\mathbf{X}^T \\mathbf{W}^{(t)} \\mathbf{z}^{(t)},\n",
"\\end{eqnarray*}\n",
"$$\n",
"where \n",
"$$\n",
"\t\\mathbf{z}^{(t)} = \\mathbf{X} \\beta^{(t)} + s(\\mathbf{W}^{(t)})^{-1} (\\mathbf{y} - \\mathbf{p}^{(t)})\n",
"$$ \n",
"are the working responses. A Newton's iteration is equivalent to solving a weighed least squares problem $\\sum_{i=1}^n w_i (z_i - \\mathbf{x}_i^T \\beta)^2$. Thus the name **IRWLS (iteratively re-weighted least squares)**.\n",
"\n",
"### GLM \n",
"\n",
"Let's consider the more general class of generalized linear models (GLM).\n",
"\n",
"\n",
"| Family | Canonical Link | Variance Function |\n",
"|------------------|-------------------------------|-------------------|\n",
"| Normal | $\\eta=\\mu$ | 1 |\n",
"| Poisson | $\\eta=\\log \\mu$ | $\\mu$ |\n",
"| Binomial | $\\eta=\\log \\left( \\frac{\\mu}{1 - \\mu} \\right)$ | $\\mu (1 - \\mu)$ |\n",
"| Gamma | $\\eta = \\mu^{-1}$ | $\\mu^2$ |\n",
"| Inverse Gaussian | $\\eta = \\mu^{-2}$ | $\\mu^3$ |\n",
"\n",
"* $Y$ belongs to an exponential family with density\n",
"$$\n",
"\tp(y|\\theta,\\phi) = \\exp \\left\\{ \\frac{y\\theta - b(\\theta)}{a(\\phi)} + c(y,\\phi) \\right\\}.\n",
"$$\n",
" * $\\theta$: natural parameter. \n",
" * $\\phi>0$: dispersion parameter. \n",
"GLM relates the mean $\\mu = \\mathbf{E}(Y|\\mathbf{x})$ via a strictly increasing link function\n",
"$$\n",
"\tg(\\mu) = \\eta = \\mathbf{x}^T \\beta, \\quad \\mu = g^{-1}(\\eta)\n",
"$$\n",
"\n",
"* Score, Hessian, information\n",
"\n",
"$$\n",
"\\begin{eqnarray*}\n",
" \t\\nabla L_n(\\beta) &=& \\sum_{i=1}^n \\frac{(y_i-\\mu_i) \\mu_i'(\\eta_i)}{\\sigma_i^2} \\mathbf{x}_i \\\\\n",
"\t- \\nabla^2 L_n(\\beta) &=& \\sum_{i=1}^n \\frac{[\\mu_i'(\\eta_i)]^2}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T - \\sum_{i=1}^n \\frac{(y_i - \\mu_i) \\theta''(\\eta_i)}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T\t\\\\\n",
"\t\\mathbf{FIM}_n(\\beta) &=& \\mathbf{E} [- \\nabla^2 L_n(\\beta)] = \\sum_{i=1}^n \\frac{[\\mu_i'(\\eta_i)]^2}{\\sigma_i^2} \\mathbf{x}_i \\mathbf{x}_i^T = \\mathbf{X}^T \\mathbf{W} \\mathbf{X}.\n",
"\\end{eqnarray*} \n",
"$$\n",
"\n",
"* Fisher scoring method\n",
"$$\n",
" \t\\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM}(\\beta^{(t)})]^{-1} \\nabla L_n(\\beta^{(t)})\n",
"$$\n",
"IRWLS with weights $w_i = [\\mu_i(\\eta_i)]^2/\\sigma_i^2$ and some working responses $z_i$.\n",
"\n",
"* For **canonical link**, $\\theta = \\eta$, the second term of Hessian vanishes and Hessian coincides with Fisher information matrix. Convex problem 😄\n",
"$$\n",
"\t\\text{Fisher's scoring == Newton's method}.\n",
"$$\n",
" \n",
"* Non-canonical link, non-convex problem 😞\n",
"$$\n",
"\t\\text{Fisher's scoring algorithm} \\ne \\text{Newton's method}.\n",
"$$\n",
"Example: Probit regression (binary response with probit link).\n",
"$$\n",
"\\begin{eqnarray*}\n",
" y_i &\\sim& \\text{Bernoulli}(p_i) \\\\\n",
" p_i &=& \\Phi(\\mathbf{x}_i^T \\beta) \\\\\n",
" \\eta_i &=& \\mathbf{x}_i^T \\beta = \\Phi^{-1}(p_i).\n",
"\\end{eqnarray*}\n",
"$$\n",
"where $\\Phi(\\cdot)$ is the cdf of a standard normal.\n",
" \n",
"* Julia, R and Matlab implement the Fisher scoring method, aka IRWLS, for GLMs.\n",
" * [GLM.jl](https://github.com/JuliaStats/GLM.jl) package."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Nonlinear regression - Gauss-Newton method (KL 14.4-14.6)\n",
"\n",
"* Now we finally get to the problem Gauss faced in 1800! \n",
"Relocate Ceres by fitting 41 observations to a 6-parameter (nonlinear) orbit.\n",
"\n",
"* Nonlinear least squares (curve fitting): \n",
"$$\n",
"\t\\text{minimize} \\,\\, f(\\beta) = \\frac{1}{2} \\sum_{i=1}^n [y_i - \\mu_i(\\mathbf{x}_i, \\beta)]^2\n",
"$$\n",
"For example, $y_i =$ dry weight of onion and $x_i=$ growth time, and we want to fit a 3-parameter growth curve\n",
"$$\n",
"\t\\mu(x, \\beta_1,\\beta_2,\\beta_3) = \\frac{\\beta_3}{1 + e^{-\\beta_1 - \\beta_2 x}}.\n",
"$$\n",
"\n",
" \n",
"\n",
"* \"Score\" and \"information matrices\"\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\nabla f(\\beta) &=& - \\sum_{i=1}^n [y_i - \\mu_i(\\beta)] \\nabla \\mu_i(\\beta) \\\\\n",
"\t\\nabla^2 f(\\beta) &=& \\sum_{i=1}^n \\nabla \\mu_i(\\beta) \\nabla \\mu_i(\\beta)^T - \\sum_{i=1}^n [y_i - \\mu_i(\\beta)] \\nabla^2 \\mu_i(\\beta) \\\\\n",
"\t\\mathbf{FIM}(\\beta) &=& \\sum_{i=1}^n \\nabla \\mu_i(\\beta) \\nabla \\mu_i(\\beta)^T = \\mathbf{J}(\\beta)^T \\mathbf{J}(\\beta),\n",
"\\end{eqnarray*}\n",
"$$\n",
"where $\\mathbf{J}(\\beta)^T = [\\nabla \\mu_1(\\beta), \\ldots, \\nabla \\mu_n(\\beta)] \\in \\mathbb{R}^{p \\times n}$.\n",
"\n",
"* **Gauss-Newton** (= \"Fisher's scoring algorithm\") uses $\\mathbf{I}(\\beta)$, which is always psd.\n",
"$$\n",
"\t\\boxed{ \\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM} (\\beta^{(t)})]^{-1} \\nabla L(\\beta^{(t)}) }\n",
"$$\n",
"\n",
"* **Levenberg-Marquardt** method, aka **damped least squares algorithm (DLS)**, adds a ridge term to the approximate Hessian\n",
"$$\n",
"\t\\boxed{ \\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM} (\\beta^{(t)}) + \\tau \\mathbf{I}_p]^{-1} \\nabla L(\\beta^{(t)}) }\n",
"$$\n",
"bridging between Gauss-Newton and steepest descent.\n",
"\n",
"* Other approximation to Hessians: nonlinear GLMs. \n",
"See KL 14.4 for examples."
]
}
],
"metadata": {
"@webio": {
"lastCommId": null,
"lastKernelId": null
},
"kernelspec": {
"display_name": "Julia 1.1.0",
"language": "julia",
"name": "julia-1.1"
},
"language_info": {
"file_extension": ".jl",
"mimetype": "application/julia",
"name": "julia",
"version": "1.1.0"
},
"toc": {
"colors": {
"hover_highlight": "#DAA520",
"running_highlight": "#FF0000",
"selected_highlight": "#FFD700"
},
"moveMenuLeft": true,
"nav_menu": {
"height": "153px",
"width": "252px"
},
"navigate_menu": true,
"number_sections": true,
"sideBar": true,
"skip_h1_title": true,
"threshold": 4,
"toc_cell": true,
"toc_position": {
"height": "441.3333435058594px",
"left": "0px",
"right": "903.3333129882813px",
"top": "140.6666717529297px",
"width": "166px"
},
"toc_section_display": "block",
"toc_window_display": true,
"widenNotebook": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
\n",
"\n",
"* \"Score\" and \"information matrices\"\n",
"$$\n",
"\\begin{eqnarray*}\n",
"\t\\nabla f(\\beta) &=& - \\sum_{i=1}^n [y_i - \\mu_i(\\beta)] \\nabla \\mu_i(\\beta) \\\\\n",
"\t\\nabla^2 f(\\beta) &=& \\sum_{i=1}^n \\nabla \\mu_i(\\beta) \\nabla \\mu_i(\\beta)^T - \\sum_{i=1}^n [y_i - \\mu_i(\\beta)] \\nabla^2 \\mu_i(\\beta) \\\\\n",
"\t\\mathbf{FIM}(\\beta) &=& \\sum_{i=1}^n \\nabla \\mu_i(\\beta) \\nabla \\mu_i(\\beta)^T = \\mathbf{J}(\\beta)^T \\mathbf{J}(\\beta),\n",
"\\end{eqnarray*}\n",
"$$\n",
"where $\\mathbf{J}(\\beta)^T = [\\nabla \\mu_1(\\beta), \\ldots, \\nabla \\mu_n(\\beta)] \\in \\mathbb{R}^{p \\times n}$.\n",
"\n",
"* **Gauss-Newton** (= \"Fisher's scoring algorithm\") uses $\\mathbf{I}(\\beta)$, which is always psd.\n",
"$$\n",
"\t\\boxed{ \\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM} (\\beta^{(t)})]^{-1} \\nabla L(\\beta^{(t)}) }\n",
"$$\n",
"\n",
"* **Levenberg-Marquardt** method, aka **damped least squares algorithm (DLS)**, adds a ridge term to the approximate Hessian\n",
"$$\n",
"\t\\boxed{ \\beta^{(t+1)} = \\beta^{(t)} + s [\\mathbf{FIM} (\\beta^{(t)}) + \\tau \\mathbf{I}_p]^{-1} \\nabla L(\\beta^{(t)}) }\n",
"$$\n",
"bridging between Gauss-Newton and steepest descent.\n",
"\n",
"* Other approximation to Hessians: nonlinear GLMs. \n",
"See KL 14.4 for examples."
]
}
],
"metadata": {
"@webio": {
"lastCommId": null,
"lastKernelId": null
},
"kernelspec": {
"display_name": "Julia 1.1.0",
"language": "julia",
"name": "julia-1.1"
},
"language_info": {
"file_extension": ".jl",
"mimetype": "application/julia",
"name": "julia",
"version": "1.1.0"
},
"toc": {
"colors": {
"hover_highlight": "#DAA520",
"running_highlight": "#FF0000",
"selected_highlight": "#FFD700"
},
"moveMenuLeft": true,
"nav_menu": {
"height": "153px",
"width": "252px"
},
"navigate_menu": true,
"number_sections": true,
"sideBar": true,
"skip_h1_title": true,
"threshold": 4,
"toc_cell": true,
"toc_position": {
"height": "441.3333435058594px",
"left": "0px",
"right": "903.3333129882813px",
"top": "140.6666717529297px",
"width": "166px"
},
"toc_section_display": "block",
"toc_window_display": true,
"widenNotebook": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}