深度音频检测模型W2V-ASDG
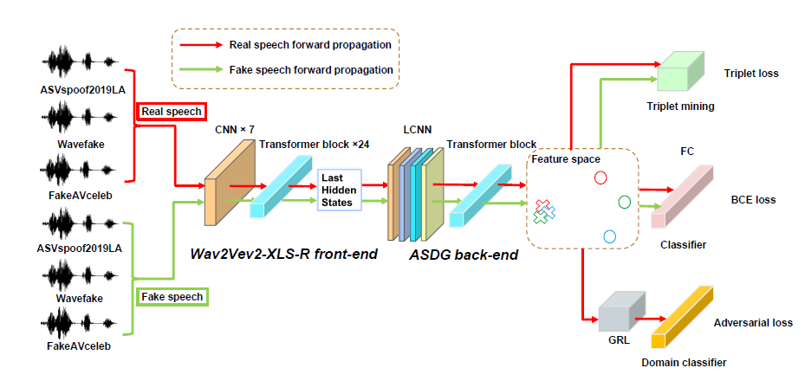
介绍
本模型前端由语音识别大模型Wav2Vec2-XLS-R提取语音的高级特征,
后端基于域泛化理论提出了Aggregation and Separation Domain Generalization
(ASDG)的新方法来学习域不变的语音特征空间。
训练集由三种不同语音鉴伪数据集构成,总计27种造假方法