---
template: overrides/blogs.html
tags:
- app
---
# Apache项目介绍
!!! info
作者:Void,发布于 2021-12-25,阅读时间:约6分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/4Epc4KbWO_BY3h0bHl_-og)
## 1 前言
Apache软件基金会(Apache Software Foundation)是一个为运作开源软件项目的团体提供支持的非营利性组织。
从最开始的开发者们技术交流的社区,到如今Apache已经成为全世界最大的开源软件基金会。其所孵化的各种开源软件已经服务于全球的各行各业,深入我们的生活之中。
本文将简单介绍一些(我)常见的[Apache顶级项目](https://projects.apache.org/projects.html?committee 'Apache顶级项目一览')。所谓顶级项目,是指经过孵化,满足一定质量要求的毕业项目。
## 2 Airflow
Apache Airflow是用Python编写的处理data pipeline工作流的调度和监控的平台。它是通过DAG(Directed acyclic graph,有向无环图)来构建工作流的。
通过可视化的网页,我们可以很直观地观察依赖关系,监控进度,管理任务等。
## 3 Arrow
Apache Arrow是一个跨平台的内存数据处理、交换的格式。
它采用了列式存储,并且由于不同平台使用同一个内存格式,从而减少系统间通信的开销。
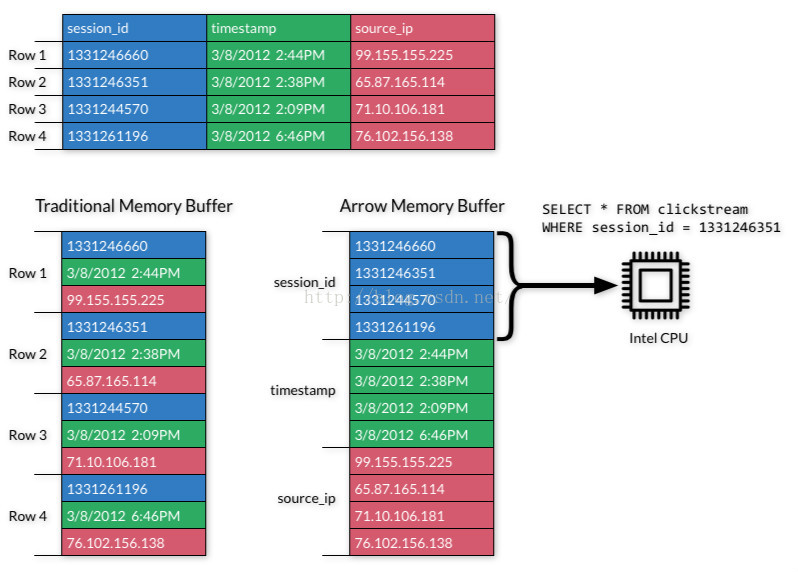 使用Python读取大数据文件往往耗时较长。我们可以使用Pyarrow大大减少这一耗时。
Feather是Apache Arrow项目中包含的一种数据格式。我们可以将Dataframe存储成feather文件并读取它。
```python
df.to_feather(path, compression, compression_level)
df = pd.read_feather('data.feather')
```
## 4 Avro
Apache Avro是一种与编程语言无关的序列化格式。它可以与Hadoop生态系统结合,Hive表定义也可以直接用Avro schema来声明。
## 5 Flink
Apache Flink是一个流处理框架。它以数据并行和流水线方式执行任意流数据程序。值得一提的是,2019年阿里巴巴以1亿美金收购了Flink。可见Flink很好的满足了阿里需要复杂实时计算的这一需求。
## 6 Hadoop
Apache Hadoop是一个分布式系统基础架构,是当今不可或缺的大数据生态之一。
Hadoop框架最核心的设计就是:HDFS(Hadoop Distributed FileSystem)和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
## 7 Hive
Apache Hive是基于Hadoop的一个分布式的数据仓库系统。它可以将SQL语言翻译成MapReduce程序,丢给计算引擎去计算。Hive活跃在大大小小的互联网公司之中,也是每天陪伴我的老朋友。
## 8 HTTP Server
Apache HTTP Server是当今最最流行的网页服务器。不需要太多赘述。Apache基金会也是起源于这一项目。
## 9 Kafka
Apache Kafka是一种高吞吐量的分布式发布订阅消息系统,可以高效地处理动作流数据。
## 10 Pig
Apache Pig也是基于Hadoop生态,它提供的类SQL语言叫Pig Latin,它会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。我在日常工作中也经常用到。
## 11 Spark
Apache Spark又是一个大名鼎鼎的项目。它提供了一个统一的数据处理平台。它具有类Hadoop MapReduce的通用并行框架,但又有所优化。它包括Spark Core,Spark SQL,Spark Streaming,MLlib等。
## 12 Tez
Apache Tez通过允许Apache Hive和Apache Pig这样的项目运行复杂的DAG任务,构建了一个应用程序框架。
## 13 ZooKeeper
Apache ZooKeeper是用来管Hadoop(大象),Hive(蜜蜂),Pig(小猪)的动物管理员。它是一个分布式的、开源的程序协调服务,主要功能包括:配置管理、名字服务、分布式锁、集群管理。
## 14 小结
可以看到Apache基金会孵化了许许多多大名鼎鼎的项目,这些项目运用于各式各样的软件之中,服务于我们生活的方方面面。感谢这些开源大佬的贡献!
使用Python读取大数据文件往往耗时较长。我们可以使用Pyarrow大大减少这一耗时。
Feather是Apache Arrow项目中包含的一种数据格式。我们可以将Dataframe存储成feather文件并读取它。
```python
df.to_feather(path, compression, compression_level)
df = pd.read_feather('data.feather')
```
## 4 Avro
Apache Avro是一种与编程语言无关的序列化格式。它可以与Hadoop生态系统结合,Hive表定义也可以直接用Avro schema来声明。
## 5 Flink
Apache Flink是一个流处理框架。它以数据并行和流水线方式执行任意流数据程序。值得一提的是,2019年阿里巴巴以1亿美金收购了Flink。可见Flink很好的满足了阿里需要复杂实时计算的这一需求。
## 6 Hadoop
Apache Hadoop是一个分布式系统基础架构,是当今不可或缺的大数据生态之一。
Hadoop框架最核心的设计就是:HDFS(Hadoop Distributed FileSystem)和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
## 7 Hive
Apache Hive是基于Hadoop的一个分布式的数据仓库系统。它可以将SQL语言翻译成MapReduce程序,丢给计算引擎去计算。Hive活跃在大大小小的互联网公司之中,也是每天陪伴我的老朋友。
## 8 HTTP Server
Apache HTTP Server是当今最最流行的网页服务器。不需要太多赘述。Apache基金会也是起源于这一项目。
## 9 Kafka
Apache Kafka是一种高吞吐量的分布式发布订阅消息系统,可以高效地处理动作流数据。
## 10 Pig
Apache Pig也是基于Hadoop生态,它提供的类SQL语言叫Pig Latin,它会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。我在日常工作中也经常用到。
## 11 Spark
Apache Spark又是一个大名鼎鼎的项目。它提供了一个统一的数据处理平台。它具有类Hadoop MapReduce的通用并行框架,但又有所优化。它包括Spark Core,Spark SQL,Spark Streaming,MLlib等。
## 12 Tez
Apache Tez通过允许Apache Hive和Apache Pig这样的项目运行复杂的DAG任务,构建了一个应用程序框架。
## 13 ZooKeeper
Apache ZooKeeper是用来管Hadoop(大象),Hive(蜜蜂),Pig(小猪)的动物管理员。它是一个分布式的、开源的程序协调服务,主要功能包括:配置管理、名字服务、分布式锁、集群管理。
## 14 小结
可以看到Apache基金会孵化了许许多多大名鼎鼎的项目,这些项目运用于各式各样的软件之中,服务于我们生活的方方面面。感谢这些开源大佬的贡献!
%20-%20Tail%20Pic.png)