---
template: overrides/blogs.html
tags:
- analytics
- python
---
# PySpark简介
!!! info
作者:Void,发布于2021-09-20,阅读时间:约10分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/3oJdhYxrIoRqbvYGnH0cKQ)
## 1 引言
Hadoop生态依旧是当今不少公司使用的数据存储方案。操作这些数据的工具有Hive(主要是写SQL),Pig(直接处理底层的数据文件,读取、过滤、拼接、存储等等)还有Spark。
Spark据称在性能上更快之外,还提供了不少库,如SQL查询,流式计算,机器学习等。
而PySpark的出现使我们可以直接用Python的API来运行Spark任务。有了它,我们甚至可以抛弃功能略显单一的Pig。也不需要把数据先存储成Hive的表格,才能执行Hive SQL。
本文将从[PySpark文档](https://spark.apache.org/docs/latest/api/python/index.html)出发,介绍相关功能及语法。
## 2 PySpark介绍
PySpark的安装需要适配Hadoop版本,安装好后,我们按如下代码即可启动Spark进程。
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
```
表格型的数据在PySpark中以Spark DataFrame的形式存在。我们可以按如下方式直接创建一个DataFrame:
```python
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
```
也可以将底层的数据以Spark DataFrame的形式直接读入(常用)。
有了DataFrame后,我们可以通过df.show()来展示数据。
```python
df.show(1)
```
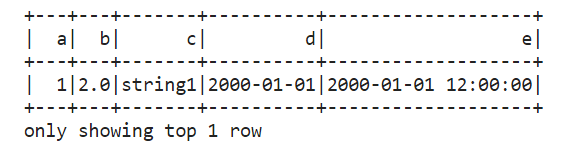 Spark DataFrame的基本操作有:
- 选择列:df.select(df.c)
- 增加列:df.withColumn('upper_c', upper(df.c))
- 筛选行:df.filter(df.a == 1)
- 聚合:df.groupby('color').avg()
- 自定义的函数(UDF)等
我们还可以通过df.toPandas()将Spark DataFrame转换成Python DataFrame以直接使用相关方法。我们也可以将Python DataFrame转换成Spark DataFrame:
```python
df = pd.DataFrame([["jack",23], ["tony", 34]], columns = ["name", "age"])
df_values = df.values.tolist()
df_columns = list(df.columns)
spark_df = spark.createDataFrame(df_values, df_columns)
```
由于Spark DataFrame和Spark SQL共享同样的执行引擎。我们可以将Spark DataFrame注册成表格,使用SQL进行逻辑运算。
```python
df.createOrReplaceTempView("tableA")
df2 = spark.sql("SELECT count(*) from tableA")
#存储计算结果
df2.write.csv('data.csv', header=True)
df2.show()
```
Spark DataFrame的基本操作有:
- 选择列:df.select(df.c)
- 增加列:df.withColumn('upper_c', upper(df.c))
- 筛选行:df.filter(df.a == 1)
- 聚合:df.groupby('color').avg()
- 自定义的函数(UDF)等
我们还可以通过df.toPandas()将Spark DataFrame转换成Python DataFrame以直接使用相关方法。我们也可以将Python DataFrame转换成Spark DataFrame:
```python
df = pd.DataFrame([["jack",23], ["tony", 34]], columns = ["name", "age"])
df_values = df.values.tolist()
df_columns = list(df.columns)
spark_df = spark.createDataFrame(df_values, df_columns)
```
由于Spark DataFrame和Spark SQL共享同样的执行引擎。我们可以将Spark DataFrame注册成表格,使用SQL进行逻辑运算。
```python
df.createOrReplaceTempView("tableA")
df2 = spark.sql("SELECT count(*) from tableA")
#存储计算结果
df2.write.csv('data.csv', header=True)
df2.show()
```
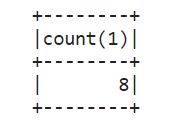 有了它,我们可以通过SQL的join拼接数据(替代Pig join的功能),也可以执行复杂的SQL逻辑(类似Hive SQL)并将最终的计算结果存储成不同格式的数据(csv,parquet等)。可以说Spark给我们提供了一个更完善,更易用的框架。
Spark DataFrame还有许多其他的[API](https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql.html),由于工作中并没有太多接触,这里就不多介绍了。需要的时候不妨去官方文档查询即可。
## 3 小结
在Hadoop生态圈中,Spark以及PySpark给我们提供了一套很强大的工具。我们并不需要关心底层的MapReduce具体是如何执行的,我们只需要按照简单的PySpark语法,甚至常用的SQL语言即可灵活,自如地操作底层的数据。
有了它,我们可以通过SQL的join拼接数据(替代Pig join的功能),也可以执行复杂的SQL逻辑(类似Hive SQL)并将最终的计算结果存储成不同格式的数据(csv,parquet等)。可以说Spark给我们提供了一个更完善,更易用的框架。
Spark DataFrame还有许多其他的[API](https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql.html),由于工作中并没有太多接触,这里就不多介绍了。需要的时候不妨去官方文档查询即可。
## 3 小结
在Hadoop生态圈中,Spark以及PySpark给我们提供了一套很强大的工具。我们并不需要关心底层的MapReduce具体是如何执行的,我们只需要按照简单的PySpark语法,甚至常用的SQL语言即可灵活,自如地操作底层的数据。
%20-%20Tail%20Pic.png)