---
template: overrides/blogs.html
tags:
- deep learning
- tensorflow
- recommendation
---
# TensorFlow推荐系统(二)
!!! info
作者:Tina,发布于2021-12-10,阅读时间:约6分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/0WcTB6WLBZX0EwbVZ_DeCg)
## 1 前言
读过[TensorFlow推荐系统(一)](https://mp.weixin.qq.com/s/OUsG-JqqYeh9q6oAa_uhmg)的朋友们应该还有印象,上回我们介绍的模型是信息检索(retrieval),而在推荐系统中还有另一个任务模型,即为信息排序(ranking)。在排序阶段,其主要任务是对检索模型产出的条目进行调整以选择最有可能被用户喜欢和选择的电影条目。
今天,我们将详细介绍一下排序模型的原理和调用实例。
## 2 源码解析
- 数据准备,获取数据并拆分数据集。
- 搭建排序模型。
- 拟合并评估模型。
### 2.1 数据准备
```Python
import os
import pprint
import tempfile
from typing import Dict, Text
import numpy as np
import tensorflow as tf
## TensorFlow Dataset Resource
import tensorflow_datasets as tfds
## TensorFlow 推荐系统
import tensorflow_recommenders as tfrs
```
从`TensorFlow Dataset`中引入和信息检索模型相同的`movielens`电影数据集,并只保留以下三个变量:
```Python
ratings = tfds.load("movielens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"user_rating": x["user_rating"]
})
```
随机打乱数据,并取80%为训练数据集,其余的20%为测试数据集:
```Python
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
```
为了给分类型变量做嵌入向量,这里是先用连续整数来匹配电影标题和用户ID的每个数值:
```Python
movie_titles = ratings.batch(1_000_000).map(lambda x: x["movie_title"])
user_ids = ratings.batch(1_000_000).map(lambda x: x["user_id"])
unique_movie_titles = np.unique(np.concatenate(list(movie_titles)))
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
```
### 2.2 搭建排序模型
在文本模型中,需要先为用户和电影做词嵌入(Embeddings),简单来说就是将文本型数据转化为可计算数值型向量的过程,这里每一个嵌入向量的维度为32。第二步是搭建顺序模型,其模型调用的是`Keras Dense`的全连接层,激活函数为`relu`整流线性单元,它的特点是在用默认值时,返回逐元素的`max(x,0)`。最后用`call()`函数输入input,从而返回ranking的结果。
```Python
class RankingModel(tf.keras.Model):
def __init__(self):
super().__init__()
## 嵌入维度为32
embedding_dimension = 32
## Compute embeddings for users.
self.user_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, embedding_dimension)
])
# Compute embeddings for movies.
self.movie_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles, mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, embedding_dimension)
])
# Compute predictions.
self.ratings = tf.keras.Sequential([
# Learn multiple dense layers.
tf.keras.layers.Dense(256, activation="relu"),
## 输出维度为 256
tf.keras.layers.Dense(64, activation="relu"),
## 输出层维度为 64
# Make rating predictions in the final layer.
tf.keras.layers.Dense(1)
])
def call(self, inputs):
##用户ID和电影标题为模型的输入值
user_id, movie_title = inputs
user_embedding = self.user_embeddings(user_id)
movie_embedding = self.movie_embeddings(movie_title)
return self.ratings(tf.concat([user_embedding, movie_embedding], axis=1))
```
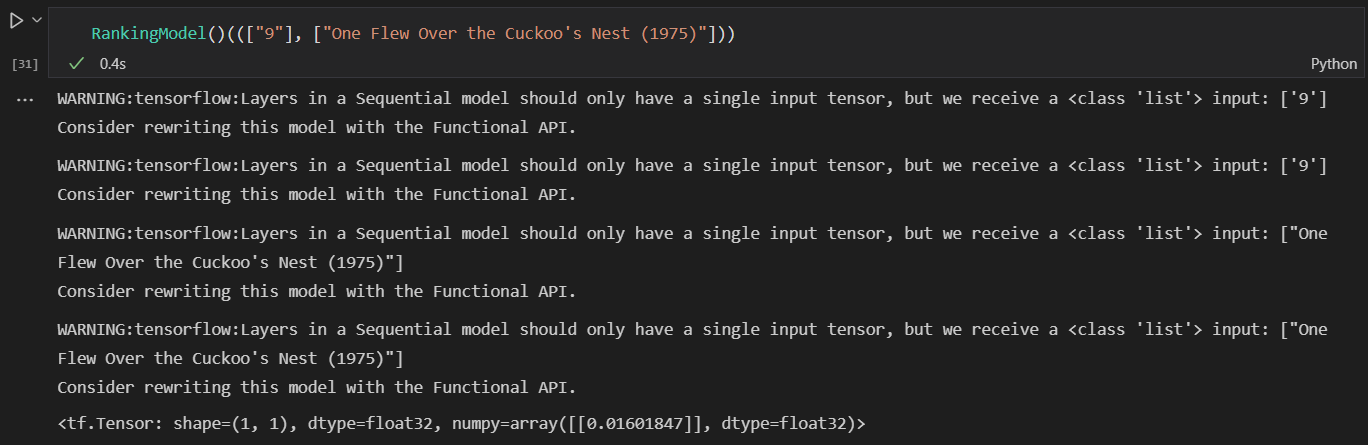
由下图所示,用未经过训练的模型为用户号为9推荐电影《One Flew Over the Cuckoo's Nest (1975)》,预测的可能性为0.016:
 为了可以在训练时有评估值,在原有的模型任务中加入`MSE`均方误差的损失函数和`RMSE`均方根误差的评估函数:
```Python
task = tfrs.tasks.Ranking(
loss = tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)
```
将排序模型和上述的函数一起打包为新的电影模型,并准备`call()`函数和`comupte_loss()`函数来拟合和评估模型的表现:
```Python
class MovielensModel(tfrs.models.Model):
def __init__(self):
super().__init__()
self.ranking_model: tf.keras.Model = RankingModel()
self.task: tf.keras.layers.Layer = tfrs.tasks.Ranking(
loss = tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)
def call(self, features: Dict[str, tf.Tensor]) -> tf.Tensor:
return self.ranking_model(
(features["user_id"], features["movie_title"]))
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
labels = features.pop("user_rating")
rating_predictions = self(features)
# The task computes the loss and the metrics.
return self.task(labels=labels, predictions=rating_predictions)
```
### 2.3 拟合并评估模型
调用模型编译`complie()`方法并使用`Adagrad`的优化器,指定学习率为0.1:
```Python
model = MovielensModel()
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.1))
```
数据拟合时,这里将训练集重排,`batch`处理和数据缓存,共`epoch`三次:
```Python
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
model.fit(cached_train, epochs=3)
```
```Python
model.evaluate(cached_test, return_dict=True)
## output:
#{'root_mean_squared_error': 1.1102582216262817,
# 'loss': 1.2078243494033813,
# 'regularization_loss': 0,
# 'total_loss': 1.2078243494033813}
```
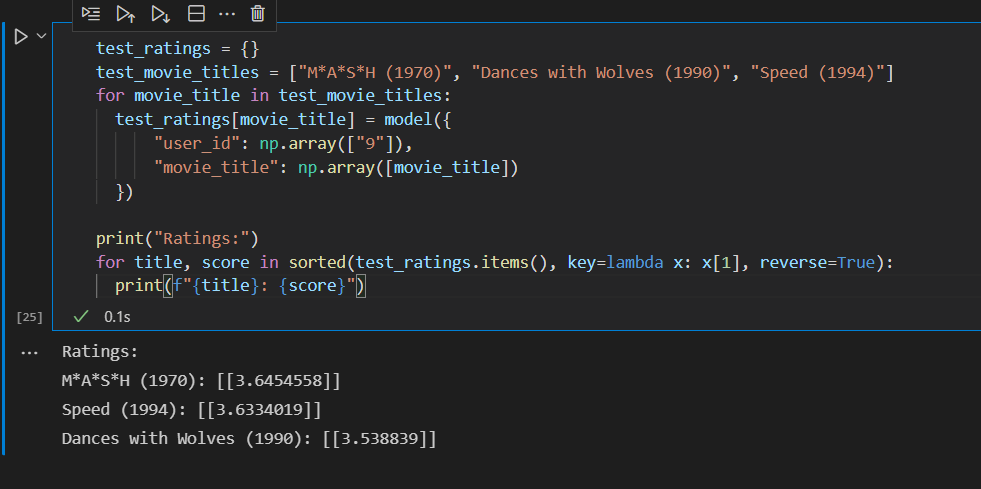
最后,为用户9推荐以下三部电影并附有模型预测的ranking结果:
为了可以在训练时有评估值,在原有的模型任务中加入`MSE`均方误差的损失函数和`RMSE`均方根误差的评估函数:
```Python
task = tfrs.tasks.Ranking(
loss = tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)
```
将排序模型和上述的函数一起打包为新的电影模型,并准备`call()`函数和`comupte_loss()`函数来拟合和评估模型的表现:
```Python
class MovielensModel(tfrs.models.Model):
def __init__(self):
super().__init__()
self.ranking_model: tf.keras.Model = RankingModel()
self.task: tf.keras.layers.Layer = tfrs.tasks.Ranking(
loss = tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)
def call(self, features: Dict[str, tf.Tensor]) -> tf.Tensor:
return self.ranking_model(
(features["user_id"], features["movie_title"]))
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
labels = features.pop("user_rating")
rating_predictions = self(features)
# The task computes the loss and the metrics.
return self.task(labels=labels, predictions=rating_predictions)
```
### 2.3 拟合并评估模型
调用模型编译`complie()`方法并使用`Adagrad`的优化器,指定学习率为0.1:
```Python
model = MovielensModel()
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.1))
```
数据拟合时,这里将训练集重排,`batch`处理和数据缓存,共`epoch`三次:
```Python
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
model.fit(cached_train, epochs=3)
```
```Python
model.evaluate(cached_test, return_dict=True)
## output:
#{'root_mean_squared_error': 1.1102582216262817,
# 'loss': 1.2078243494033813,
# 'regularization_loss': 0,
# 'total_loss': 1.2078243494033813}
```
最后,为用户9推荐以下三部电影并附有模型预测的ranking结果:
 ## 3 总结
TensorFlow电影推荐系统中,第一步先从数据集中获取用户可能会喜欢的电影条目,第二步则是对这些电影条目进行预测排序,目的就是推荐有限的用户最有可能感兴趣并点击的电影。而在现实生活中,你就是用户。所以,教给大家一个解决剧荒的小技巧,与其随机浏览寻找,不如搜索一些你看过的喜欢的电影,和你喜欢相似的电影就在”为你推荐“一栏了,不妨试试吧!
希望这篇分享可以对你有所帮助,欢迎各位留言讨论。
## 3 总结
TensorFlow电影推荐系统中,第一步先从数据集中获取用户可能会喜欢的电影条目,第二步则是对这些电影条目进行预测排序,目的就是推荐有限的用户最有可能感兴趣并点击的电影。而在现实生活中,你就是用户。所以,教给大家一个解决剧荒的小技巧,与其随机浏览寻找,不如搜索一些你看过的喜欢的电影,和你喜欢相似的电影就在”为你推荐“一栏了,不妨试试吧!
希望这篇分享可以对你有所帮助,欢迎各位留言讨论。
%20-%20Tail%20Pic.png)