---
template: overrides/blogs.html
tags:
- machine learning
---
# Kaggle Jane Street竞赛
!!! info
作者:Void,发布于2021-09-02,阅读时间:约10分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/oaT49hLhGiL_ajz1dIlGcQ)
## 1 引言
Kaggle上对冲基金赞助的竞赛不少,可能成为了一种新式内卷,也可能是真的想从Kaggler身上得到一些idea。
这次我们来学习的是刚刚结束的Jane Street赞助的比赛。
## 2 竞赛介绍
本次竞赛是一个分类问题,对每一条数据(一次交易机会),我们需要给出是否行动(action)。如果执行交易,相应的收益就是return * weight,加总到每一天即为:
$$
p_{i}=\sum_{j}\left(\text { weight }_{i j} * \operatorname{resp}_{i j} * \operatorname{action}_{i j}\right)
$$
在投资领域,很多人追求的是高sharpe值(同时考虑了收益和风险),它的具体计算如下所示:
$$
t=\frac{\sum p_{i}}{\sqrt{\sum p_{i}^{2}}} * \sqrt{\frac{250}{|i|}}
$$
我们最终的评价指标为:
$$
u=\min (\max (t, 0), 6) \sum p_{i}
$$
## 3 具体代码
同样,我们一起来看一下开源的高分代码。
### 3.1 import packages
第一部分照例是导入一堆包。值得一提的是,由于本次数据量较大。代码使用了datatable进行数据读取。datatable据称是一个性能碾压pandas的高效多线程数据处理工具
```python
import datatable as dtable
train = dtable.fread('/kaggle/input/jane-street-market-prediction/train.csv').to_pandas()
```
### 3.2 特征工程
由于本次提供的特征仍然是一些不知道含义的匿名特征。代码根据每个特征的分布人为地划分为了4种特征:Linear,Noisy,Negative和Hybrid。
最后的特征即为所有原始特征,加上每类特征的均值构造的特征。
```python
train['f_Linear']=train[f_Linear].mean(axis=1)
train['f_Noisy']=train[f_Noisy].mean(axis=1)
train['f_Negative']=train[f_Negative].mean(axis=1)
train['f_Hybrid']=train[f_Hybrid].mean(axis=1)
```
### 3.3 确定label
训练集并没有直接给我们label,即是否action。它提供的是5种不同时间窗口的收益率(return)。代码构造label的方式是判断若有大于3个收益为正,即执行交易(action=1)。
```python
resp_cols = ['resp', 'resp_1', 'resp_2', 'resp_3', 'resp_4']
y = np.stack([(train[c] > 0).astype('int') for c in resp_cols]).T
train['action'] = (y.mean(axis=1) > 0.5).astype('int')
```
### 3.4 模型训练
关于模型部分,方案使用了一个XGBoost模型,并用HyperOpt进行了参数优化。
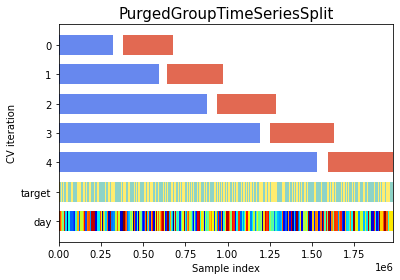
关于cv的使用,它使用了适合于此类时间序列问题的PurgedGroupTimeSeriesSplit,从下图中可以很直观的看到。验证集永远在训练集后面,并且中间隔了一小段时间。
 ## 4 小结
可以看到本次开源方案并不复杂,也仍有很多空间可以提升,如分析特征含义,使用神经网络模型,优化题目给出的评价指标等等。但是,在信噪比较低的金融世界中,这些方法是否有用仍是一个问号。
## 4 小结
可以看到本次开源方案并不复杂,也仍有很多空间可以提升,如分析特征含义,使用神经网络模型,优化题目给出的评价指标等等。但是,在信噪比较低的金融世界中,这些方法是否有用仍是一个问号。
%20-%20Tail%20Pic.png)