---
template: overrides/blogs.html
tags:
- machine learning
---
# 集成学习小介
!!! info
作者:Tina,发布于2021-06-06,阅读时间:约6分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/CrNeVH2Qm84QQvdHZAIp2g)
## 1 前言
在机器学习中有一个常见且重要的概念——集成学习(Ensemble Learning),即通过构建多个机器学习器来完成学习任务。今天,我们将介绍集成学习的一些常见方法,如`Voting Classifiers`,`Bagging`和`Boosting`。
## 2 集成方法
### 2.1 Voting Classifiers
如下图所示,`Voting Classifiers`的基本原则就是基于相同的训练集,采用不同的模型算法去拟合数据,从而将最后的预测结果聚合取得最终的结果。
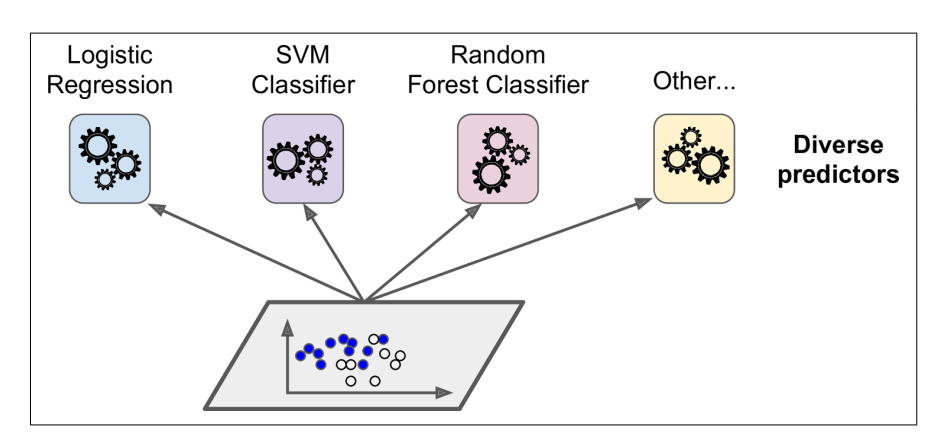 Voting Classifier Prediction
**其代码实现如下所示**:
```Python
## RandomForest, Logistic Regression and SVC
## participate in ensemble learning
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
##aggregate three algorithms as Voting Classifier
voting_clf = VotingClassifier(
estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf )],
voting= 'hard'
)
voting_clf.fit(X_tran,y_train)
```
训练结束后,可以查看每个分类器在测试集上的表现:
```Python
## Look at each classifier's accuracy on the test set:
from sklearn.metrics import accuracy_score
for clf in (log_cf,rnd_clf,svm_clf,voting_clf):
y_pred = clf.predict(X_test)
print(clf.__class__.name__,accuracy_score(y_test,y_pred))
#### Output:
### LogisticRegression 0.864
### RandomForestClassifier 0.872
### SVC 0.888
### VotingClassifier 0.896
```
需要补充一点的是,集成分类器并不一定在所有的情况下都可以有很好的表现,比如当组成集成分类器中,`weak learner`占多数,而有良好表现的模型占少数,在取`major votes`作为预测结果时,集合学习的表现就有可能没有某个单个分类器好。
### 2.2 Bagging and Pasting
集成学习也可以用一个模型算法去拟合不同的子数据集来实现。
`bagging (boostrap aggregating)`是指抽样并放回,而`pasting`是指抽样不放回。 由下图所示,集成学习可通过多次抽样获得多个预测结果,再将所有的结果集成在一起,一般选择频率最大的预测值或是平均值作为最终学习的结果。
Voting Classifier Prediction
**其代码实现如下所示**:
```Python
## RandomForest, Logistic Regression and SVC
## participate in ensemble learning
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
##aggregate three algorithms as Voting Classifier
voting_clf = VotingClassifier(
estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf )],
voting= 'hard'
)
voting_clf.fit(X_tran,y_train)
```
训练结束后,可以查看每个分类器在测试集上的表现:
```Python
## Look at each classifier's accuracy on the test set:
from sklearn.metrics import accuracy_score
for clf in (log_cf,rnd_clf,svm_clf,voting_clf):
y_pred = clf.predict(X_test)
print(clf.__class__.name__,accuracy_score(y_test,y_pred))
#### Output:
### LogisticRegression 0.864
### RandomForestClassifier 0.872
### SVC 0.888
### VotingClassifier 0.896
```
需要补充一点的是,集成分类器并不一定在所有的情况下都可以有很好的表现,比如当组成集成分类器中,`weak learner`占多数,而有良好表现的模型占少数,在取`major votes`作为预测结果时,集合学习的表现就有可能没有某个单个分类器好。
### 2.2 Bagging and Pasting
集成学习也可以用一个模型算法去拟合不同的子数据集来实现。
`bagging (boostrap aggregating)`是指抽样并放回,而`pasting`是指抽样不放回。 由下图所示,集成学习可通过多次抽样获得多个预测结果,再将所有的结果集成在一起,一般选择频率最大的预测值或是平均值作为最终学习的结果。
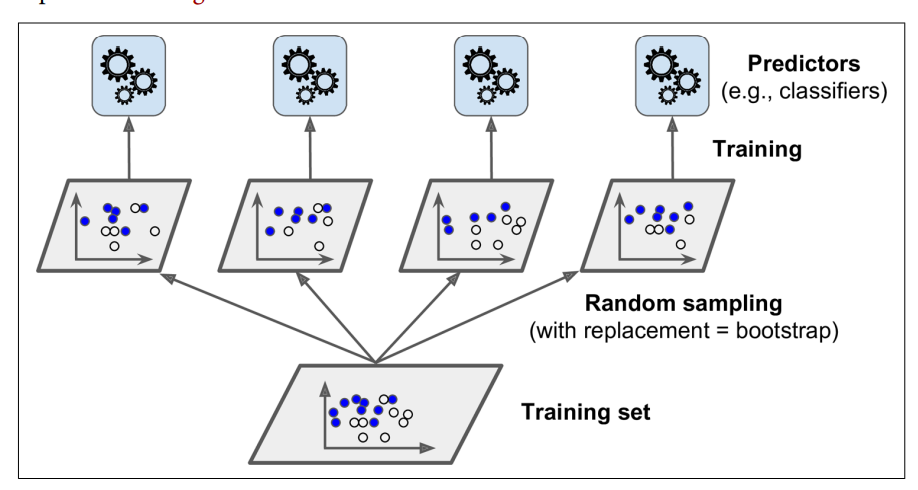 Bagging Training
**其代码实现如下所示:**
```Python
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
## with 500 trees, n_jobs = -1
## means using all processors
##to fit and predict in parallel.
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1
)
bag_clf.fit(X_train,y_pred)
y_pred = bag_clf.predict(X_test)
```
在`bagging`中,会出现数据被多个分类器同时拟合的情况,那么就会有一些数据没有被训练过,这一部分的数据就是`out-of-bag(oob)`,最后用来评估模型的表现。
在`Scikit-Learn`中可通过设置`oob_score=True`来直接实现:
```Python
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1, oob_score = True
)
bag_clf.fit(X_train,y_pred)
bga_clf.oob_score_
###0.93066666666664
### To verify by accuracy score on test set
from sklearn.metrics import accuracy_score
y_pred = bag_clf(X_test)
accuracy_score(y_test,y_pred)
###0.936000000000005
```
### 2.3 Boosting
`Boosting`是指将多个`weak learner`组合在一起的集成方式。与前面几个不同的是,它是按照顺序逐个训练分类器,并在每次训练中纠正前一个分类器,最常见的方法就是`Adaptive Boosting(AdaBoost)`和`Gradient Boosting`。
#### 2.3.1 AdaBoost
`AdaBoost`在进化分类器过程中是着重训练欠拟合的训练数据集。如下图所示,在搭建此类分类器时,后续的分类器在训练时会不断地学习以更新前者的权重以提高数据的拟合效果。
Bagging Training
**其代码实现如下所示:**
```Python
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
## with 500 trees, n_jobs = -1
## means using all processors
##to fit and predict in parallel.
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1
)
bag_clf.fit(X_train,y_pred)
y_pred = bag_clf.predict(X_test)
```
在`bagging`中,会出现数据被多个分类器同时拟合的情况,那么就会有一些数据没有被训练过,这一部分的数据就是`out-of-bag(oob)`,最后用来评估模型的表现。
在`Scikit-Learn`中可通过设置`oob_score=True`来直接实现:
```Python
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1, oob_score = True
)
bag_clf.fit(X_train,y_pred)
bga_clf.oob_score_
###0.93066666666664
### To verify by accuracy score on test set
from sklearn.metrics import accuracy_score
y_pred = bag_clf(X_test)
accuracy_score(y_test,y_pred)
###0.936000000000005
```
### 2.3 Boosting
`Boosting`是指将多个`weak learner`组合在一起的集成方式。与前面几个不同的是,它是按照顺序逐个训练分类器,并在每次训练中纠正前一个分类器,最常见的方法就是`Adaptive Boosting(AdaBoost)`和`Gradient Boosting`。
#### 2.3.1 AdaBoost
`AdaBoost`在进化分类器过程中是着重训练欠拟合的训练数据集。如下图所示,在搭建此类分类器时,后续的分类器在训练时会不断地学习以更新前者的权重以提高数据的拟合效果。
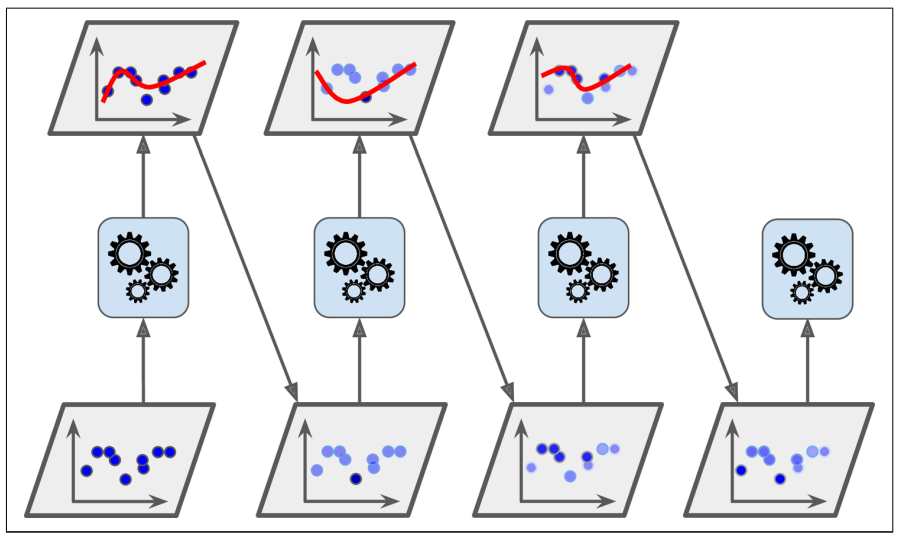 AdaBoost sequential training
**其代码实现如下所示:**
```Python
from sklearn.ensemble import AdaBoostClassifier
## 200 decision stumps with 0.5 learning rate using the
## Stagewise Additive Modeling Multiclass Exponential loss function
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth =1),n_estimator = 200,
algorithm = "SAMME.R",learning_rate =0.5
)
ada_clf.fit(X_train,y_train)
```
可通过减少`n_estimator`数量来控制`AdaBoost Ensemble`出现过度拟合的情况。
#### 2.3.2 Gradient Boosting
和`AdaBoosting`一样,梯度提升(Gradient Boosting)也是按照一定序列去学习数据集,不断迭代来生成稳健的集成模型。然而,不同之处在于梯度提升是拟合新数据来减少前者的残差,而非更新前者的权重。
我们可以用`Gradient Boosted Regression Trees(GBRT)`为例来学习代码的实现方式:
```Python
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X,y)
### residual errors
y2 = y-tree_reg1.predict(X)
## Train the second regressor on residual errors made by the first one
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X,y2)
## Train the third regressor on the residual errors made by the second one
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)
## The ensemble model contains three trees, it can make predictions on a
## new instance by adding up the predictions of all trees
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2,tree_reg3))
```
也可以直接使用`GradientBoostingRegressor`的方法来实现以上的效果:
```Python
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth = 2,n_estimators = 3, learning_rate=1.0)
gbrt.fit(X,y)
```
为了找到最佳的决策树的数量,`staged_predict()`根据设定的`n_estimators`,从0到`n_estimators`不断地预测,产生预测值和误差值,然后根据`n_estimator`和对应的误差值,找到最佳的参数值,代码如下:
```Python
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors)
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
gbrt_best.fit(X_train, y_train)
```
## 3 总结
通俗地说,集成学习就是利用群众的智慧去学习同样的数据集,不断地迭代以达到比单个模型更好的效果,因此集成学习一般都有很高的准确性。但是,需要注意的是上述集成学习的方法还是有各自的局限性的,比如会存在过度拟合,分类器数目的设定,对离群点敏感等难点。
希望这篇文章可以对你有所帮助,欢迎各位留言讨论。
AdaBoost sequential training
**其代码实现如下所示:**
```Python
from sklearn.ensemble import AdaBoostClassifier
## 200 decision stumps with 0.5 learning rate using the
## Stagewise Additive Modeling Multiclass Exponential loss function
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth =1),n_estimator = 200,
algorithm = "SAMME.R",learning_rate =0.5
)
ada_clf.fit(X_train,y_train)
```
可通过减少`n_estimator`数量来控制`AdaBoost Ensemble`出现过度拟合的情况。
#### 2.3.2 Gradient Boosting
和`AdaBoosting`一样,梯度提升(Gradient Boosting)也是按照一定序列去学习数据集,不断迭代来生成稳健的集成模型。然而,不同之处在于梯度提升是拟合新数据来减少前者的残差,而非更新前者的权重。
我们可以用`Gradient Boosted Regression Trees(GBRT)`为例来学习代码的实现方式:
```Python
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X,y)
### residual errors
y2 = y-tree_reg1.predict(X)
## Train the second regressor on residual errors made by the first one
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X,y2)
## Train the third regressor on the residual errors made by the second one
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)
## The ensemble model contains three trees, it can make predictions on a
## new instance by adding up the predictions of all trees
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2,tree_reg3))
```
也可以直接使用`GradientBoostingRegressor`的方法来实现以上的效果:
```Python
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth = 2,n_estimators = 3, learning_rate=1.0)
gbrt.fit(X,y)
```
为了找到最佳的决策树的数量,`staged_predict()`根据设定的`n_estimators`,从0到`n_estimators`不断地预测,产生预测值和误差值,然后根据`n_estimator`和对应的误差值,找到最佳的参数值,代码如下:
```Python
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors)
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
gbrt_best.fit(X_train, y_train)
```
## 3 总结
通俗地说,集成学习就是利用群众的智慧去学习同样的数据集,不断地迭代以达到比单个模型更好的效果,因此集成学习一般都有很高的准确性。但是,需要注意的是上述集成学习的方法还是有各自的局限性的,比如会存在过度拟合,分类器数目的设定,对离群点敏感等难点。
希望这篇文章可以对你有所帮助,欢迎各位留言讨论。
%20-%20Tail%20Pic.png)