---
template: overrides/blogs.html
tags:
- machine learning
---
# Kaggle量化竞赛Top方案
!!! info
作者:Void,发布于2022-01-30,阅读时间:约10分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s/M1UrhmJ9dlBlsZUv_jAHxg)
## 1 引言
最近,Kaggle上量化相关的竞赛层出不穷。
前有Jane Street主办的预测是否交易,最大化收益的比赛,刚结束的Optiver主办的预测已实现波动率的比赛。在进行中的,G-Research主办的预测数字货币收益率的比赛以及国内量化私募——九坤主办的预测收益率的比赛。
可能是这些机构真的从Kaggle中获得了不少insight,赚到了真金白银,才使它们如此热衷地举办此类竞赛。
不同于之前解读在比赛进行中开源的方案:
- [想体验量化交易吗](https://mp.weixin.qq.com/s?__biz=MzI4Mjk3NzgxOQ==&mid=2247484518&idx=1&sn=1110c1bc0a927d0a43446e2ac538fee1&scene=19#wechat_redirect)
- [抄作业啦](https://mp.weixin.qq.com/s?__biz=MzI4Mjk3NzgxOQ==&mid=2247484478&idx=1&sn=87de555f9ccfb00fc4d9ec6934bc61fa&scene=19#wechat_redirect)
本文将解读已结束的`Jane Street Market Prediction`以及`Optiver Realized Volatility Prediction`最终排名第一的解决方案。
## 2 竞赛介绍
简单回顾下两个竞赛的赛题:
- Jane Street要求我们给出是否交易的信号以最大化收益。
- Optiver要求我们预测高频金融数据(股票)的波动率。
这两个比赛在私榜(Private Leaderboard)阶段都会定期的用实际的金融数据更新方案排名。虽然金融市场难以预测,但是神奇的是高分团队可以一直保持在排行榜顶端,让人不得不信服他们方案的有效性。下面我们就来一起看看他们的获胜方案吧。
## 3 方案解读
### 3.1 [Jane Street Top 1 solution from Cats Trading...](https://www.kaggle.com/c/jane-street-market-prediction/discussion/224348 'Jane Street Top 1 solution from Cats Trading...')
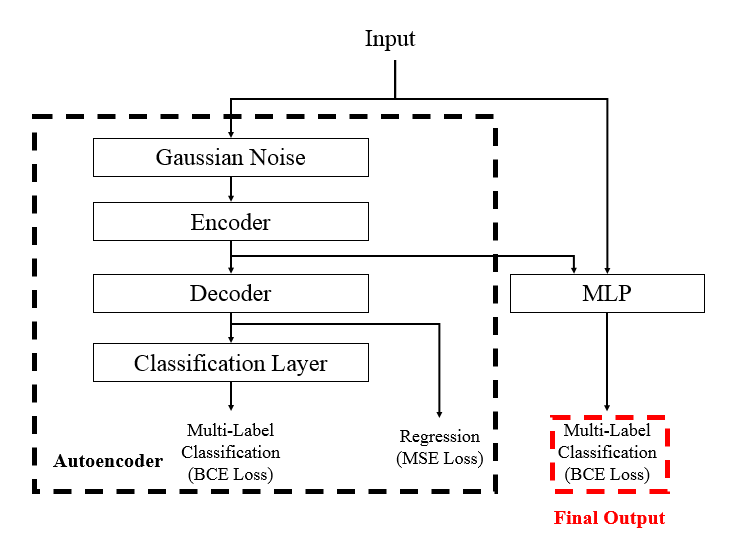
获胜方案采用了一个XGBoost和一个含有自编码器的神经网络(Supervised Autoencoder with MLP)模型集成,其中后者单模型也能保持第一。模型结构如下所示:
 ```python
def create_ae_mlp(num_columns, num_labels, hidden_units, dropout_rates, ls = 1e-2, lr = 1e-3):
inp = tf.keras.layers.Input(shape = (num_columns, ))
x0 = tf.keras.layers.BatchNormalization()(inp)
encoder = tf.keras.layers.GaussianNoise(dropout_rates[0])(x0)
encoder = tf.keras.layers.Dense(hidden_units[0])(encoder)
encoder = tf.keras.layers.BatchNormalization()(encoder)
encoder = tf.keras.layers.Activation('swish')(encoder)
decoder = tf.keras.layers.Dropout(dropout_rates[1])(encoder)
decoder = tf.keras.layers.Dense(num_columns, name = 'decoder')(decoder)
x_ae = tf.keras.layers.Dense(hidden_units[1])(decoder)
x_ae = tf.keras.layers.BatchNormalization()(x_ae)
x_ae = tf.keras.layers.Activation('swish')(x_ae)
x_ae = tf.keras.layers.Dropout(dropout_rates[2])(x_ae)
out_ae = tf.keras.layers.Dense(num_labels, activation = 'sigmoid', name = 'ae_action')(x_ae)
x = tf.keras.layers.Concatenate()([x0, encoder])
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(dropout_rates[3])(x)
for i in range(2, len(hidden_units)):
x = tf.keras.layers.Dense(hidden_units[i])(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('swish')(x)
x = tf.keras.layers.Dropout(dropout_rates[i + 2])(x)
out = tf.keras.layers.Dense(num_labels, activation = 'sigmoid', name = 'action')(x)
model = tf.keras.models.Model(inputs = inp, outputs = [decoder, out_ae, out])
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = lr),
loss = {'decoder': tf.keras.losses.MeanSquaredError(),
'ae_action': tf.keras.losses.BinaryCrossentropy(label_smoothing = ls),
'action': tf.keras.losses.BinaryCrossentropy(label_smoothing = ls),
},
metrics = {'decoder': tf.keras.metrics.MeanAbsoluteError(name = 'MAE'),
'ae_action': tf.keras.metrics.AUC(name = 'AUC'),
'action': tf.keras.metrics.AUC(name = 'AUC'),
},
)
return model
```
可以看到最终的损失是Decoder的MSE损失加上自编码器BCE损失(是否交易)加上原始Input和Encoder拼接后网络的BCE损失(是否交易)。虽然比赛时已经有开源的方案使用了自编码器。但是Cats Trading...做了一些优化,如将自编码器部分和拼接后的网络同时优化,这样也避免了先在整体训练自编码器再使用CV(cross validation)带来的leakage(数据泄露)。
### 3.2 [Optiver Top 1 solution from nyanp](https://www.kaggle.com/c/optiver-realized-volatility-prediction/discussion/302626 'Optiver Top 1 solution from nyanp')
之前的文章中我们提到过,竞赛给出的数据主要是交易相关数据(价格、成交量等)以及订单簿数据(买一价、卖一价等)这两大类。有一定领域相关知识的选手可以构造出不少有用的特征。在开源的Code或是Discussion中也有大佬给出了这些思路。大家用的特征都差不多,因此特征这块并不是获胜的关键。
在模型ensemble方面,最终的模型是一个CNN(权重0.4),一个GBDT(权重0.4),一个TabNet(权重0.1)以及一个MLP(权重0.1)的集成。从单模型角度,一个GBDT最终即可获得第一,其他单模型也都在金牌区。可见他的单模型都表现很好,最终模型集成的提升并没有特别大。
获胜的关键是nyanp采用了7种不同的最近邻的方式来获得聚合特征。
```python
def create_ae_mlp(num_columns, num_labels, hidden_units, dropout_rates, ls = 1e-2, lr = 1e-3):
inp = tf.keras.layers.Input(shape = (num_columns, ))
x0 = tf.keras.layers.BatchNormalization()(inp)
encoder = tf.keras.layers.GaussianNoise(dropout_rates[0])(x0)
encoder = tf.keras.layers.Dense(hidden_units[0])(encoder)
encoder = tf.keras.layers.BatchNormalization()(encoder)
encoder = tf.keras.layers.Activation('swish')(encoder)
decoder = tf.keras.layers.Dropout(dropout_rates[1])(encoder)
decoder = tf.keras.layers.Dense(num_columns, name = 'decoder')(decoder)
x_ae = tf.keras.layers.Dense(hidden_units[1])(decoder)
x_ae = tf.keras.layers.BatchNormalization()(x_ae)
x_ae = tf.keras.layers.Activation('swish')(x_ae)
x_ae = tf.keras.layers.Dropout(dropout_rates[2])(x_ae)
out_ae = tf.keras.layers.Dense(num_labels, activation = 'sigmoid', name = 'ae_action')(x_ae)
x = tf.keras.layers.Concatenate()([x0, encoder])
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(dropout_rates[3])(x)
for i in range(2, len(hidden_units)):
x = tf.keras.layers.Dense(hidden_units[i])(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('swish')(x)
x = tf.keras.layers.Dropout(dropout_rates[i + 2])(x)
out = tf.keras.layers.Dense(num_labels, activation = 'sigmoid', name = 'action')(x)
model = tf.keras.models.Model(inputs = inp, outputs = [decoder, out_ae, out])
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = lr),
loss = {'decoder': tf.keras.losses.MeanSquaredError(),
'ae_action': tf.keras.losses.BinaryCrossentropy(label_smoothing = ls),
'action': tf.keras.losses.BinaryCrossentropy(label_smoothing = ls),
},
metrics = {'decoder': tf.keras.metrics.MeanAbsoluteError(name = 'MAE'),
'ae_action': tf.keras.metrics.AUC(name = 'AUC'),
'action': tf.keras.metrics.AUC(name = 'AUC'),
},
)
return model
```
可以看到最终的损失是Decoder的MSE损失加上自编码器BCE损失(是否交易)加上原始Input和Encoder拼接后网络的BCE损失(是否交易)。虽然比赛时已经有开源的方案使用了自编码器。但是Cats Trading...做了一些优化,如将自编码器部分和拼接后的网络同时优化,这样也避免了先在整体训练自编码器再使用CV(cross validation)带来的leakage(数据泄露)。
### 3.2 [Optiver Top 1 solution from nyanp](https://www.kaggle.com/c/optiver-realized-volatility-prediction/discussion/302626 'Optiver Top 1 solution from nyanp')
之前的文章中我们提到过,竞赛给出的数据主要是交易相关数据(价格、成交量等)以及订单簿数据(买一价、卖一价等)这两大类。有一定领域相关知识的选手可以构造出不少有用的特征。在开源的Code或是Discussion中也有大佬给出了这些思路。大家用的特征都差不多,因此特征这块并不是获胜的关键。
在模型ensemble方面,最终的模型是一个CNN(权重0.4),一个GBDT(权重0.4),一个TabNet(权重0.1)以及一个MLP(权重0.1)的集成。从单模型角度,一个GBDT最终即可获得第一,其他单模型也都在金牌区。可见他的单模型都表现很好,最终模型集成的提升并没有特别大。
获胜的关键是nyanp采用了7种不同的最近邻的方式来获得聚合特征。
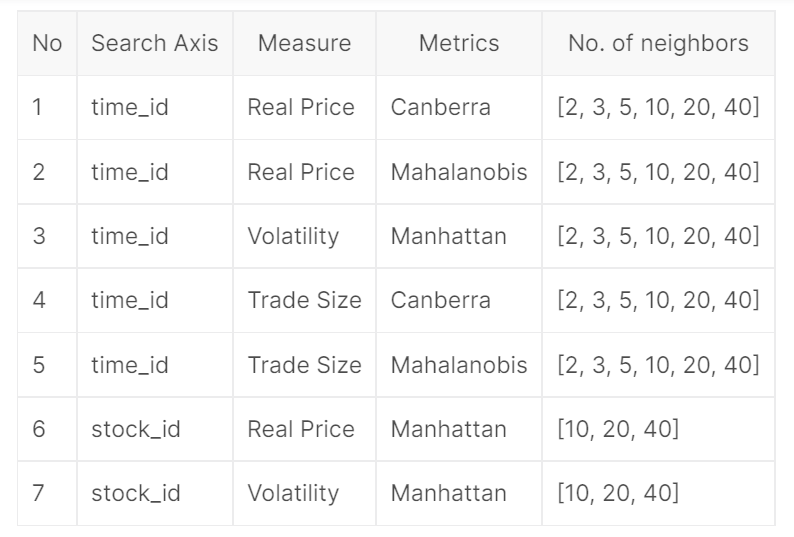 可以看到聚合的维度主要是时间和股票两种,衡量的指标有价格、波动率、交易量,采用的最近邻算法是sklearn中的NearestNeighbors算法,并采用了不同的衡量距离的方式。
NearestNeighbors是无监督的最近邻算法,包括了brute force以及通过KD树等优化距离计算的一些算法。
```python
class Neighbors:
def __init__(self,
name: str,
pivot: pd.DataFrame,
p: float,
metric: str = 'minkowski',
metric_params: Optional[Dict] = None,
exclude_self: bool = False):
self.name = name
self.exclude_self = exclude_self
self.p = p
self.metric = metric
if metric == 'random':
n_queries = len(pivot)
self.neighbors = np.random.randint(n_queries, size=(n_queries, N_NEIGHBORS_MAX))
else:
nn = NearestNeighbors(
n_neighbors=N_NEIGHBORS_MAX,
p=p,
metric=metric,
metric_params=metric_params
)
nn.fit(pivot)
_, self.neighbors = nn.kneighbors(pivot, return_distance=True)
self.columns = self.index = self.feature_values = self.feature_col = None
def rearrange_feature_values(self, df: pd.DataFrame, feature_col: str) -> None:
raise NotImplementedError()
def make_nn_feature(self, n=5, agg=np.mean) -> pd.DataFrame:
assert self.feature_values is not None, "should call rearrange_feature_values beforehand"
start = 1 if self.exclude_self else 0
pivot_aggs = pd.DataFrame(
agg(self.feature_values[start:n,:,:], axis=0),
columns=self.columns,
index=self.index
)
dst = pivot_aggs.unstack().reset_index()
dst.columns = ['stock_id', 'time_id', f'{self.feature_col}_nn{n}_{self.name}_{agg.__name__}']
return dst
class TimeIdNeighbors(Neighbors):
def rearrange_feature_values(self, df: pd.DataFrame, feature_col: str) -> None:
feature_pivot = df.pivot('time_id', 'stock_id', feature_col)
feature_pivot = feature_pivot.fillna(feature_pivot.mean())
feature_pivot.head()
feature_values = np.zeros((N_NEIGHBORS_MAX, *feature_pivot.shape))
for i in range(N_NEIGHBORS_MAX):
feature_values[i, :, :] += feature_pivot.values[self.neighbors[:, i], :]
self.columns = list(feature_pivot.columns)
self.index = list(feature_pivot.index)
self.feature_values = feature_values
self.feature_col = feature_col
def __repr__(self) -> str:
return f"time-id NN (name={self.name}, metric={self.metric}, p={self.p})"
```
其实,在比赛中开源的方案也提到了通过Kmeans获得聚合特征。nyanp做的较好的地方是采用了不同方式,使获得的特征更加稳健。加上此类聚合特征后,方案的排名有了大幅度的提升。
## 4 小结
可以看到获胜方案并没有特别标新立异,而是基于已有的好的解决方案(自编码器及聚类特征等)做了一些优化改进。模型结果在变化莫测的金融市场中经受住了考验,值得我们学习。
可以看到聚合的维度主要是时间和股票两种,衡量的指标有价格、波动率、交易量,采用的最近邻算法是sklearn中的NearestNeighbors算法,并采用了不同的衡量距离的方式。
NearestNeighbors是无监督的最近邻算法,包括了brute force以及通过KD树等优化距离计算的一些算法。
```python
class Neighbors:
def __init__(self,
name: str,
pivot: pd.DataFrame,
p: float,
metric: str = 'minkowski',
metric_params: Optional[Dict] = None,
exclude_self: bool = False):
self.name = name
self.exclude_self = exclude_self
self.p = p
self.metric = metric
if metric == 'random':
n_queries = len(pivot)
self.neighbors = np.random.randint(n_queries, size=(n_queries, N_NEIGHBORS_MAX))
else:
nn = NearestNeighbors(
n_neighbors=N_NEIGHBORS_MAX,
p=p,
metric=metric,
metric_params=metric_params
)
nn.fit(pivot)
_, self.neighbors = nn.kneighbors(pivot, return_distance=True)
self.columns = self.index = self.feature_values = self.feature_col = None
def rearrange_feature_values(self, df: pd.DataFrame, feature_col: str) -> None:
raise NotImplementedError()
def make_nn_feature(self, n=5, agg=np.mean) -> pd.DataFrame:
assert self.feature_values is not None, "should call rearrange_feature_values beforehand"
start = 1 if self.exclude_self else 0
pivot_aggs = pd.DataFrame(
agg(self.feature_values[start:n,:,:], axis=0),
columns=self.columns,
index=self.index
)
dst = pivot_aggs.unstack().reset_index()
dst.columns = ['stock_id', 'time_id', f'{self.feature_col}_nn{n}_{self.name}_{agg.__name__}']
return dst
class TimeIdNeighbors(Neighbors):
def rearrange_feature_values(self, df: pd.DataFrame, feature_col: str) -> None:
feature_pivot = df.pivot('time_id', 'stock_id', feature_col)
feature_pivot = feature_pivot.fillna(feature_pivot.mean())
feature_pivot.head()
feature_values = np.zeros((N_NEIGHBORS_MAX, *feature_pivot.shape))
for i in range(N_NEIGHBORS_MAX):
feature_values[i, :, :] += feature_pivot.values[self.neighbors[:, i], :]
self.columns = list(feature_pivot.columns)
self.index = list(feature_pivot.index)
self.feature_values = feature_values
self.feature_col = feature_col
def __repr__(self) -> str:
return f"time-id NN (name={self.name}, metric={self.metric}, p={self.p})"
```
其实,在比赛中开源的方案也提到了通过Kmeans获得聚合特征。nyanp做的较好的地方是采用了不同方式,使获得的特征更加稳健。加上此类聚合特征后,方案的排名有了大幅度的提升。
## 4 小结
可以看到获胜方案并没有特别标新立异,而是基于已有的好的解决方案(自编码器及聚类特征等)做了一些优化改进。模型结果在变化莫测的金融市场中经受住了考验,值得我们学习。
%20-%20Tail%20Pic.png)