---
template: overrides/blogs.html
tags:
- machine learning
- python
---
# AMEX - Default Prediction Kaggle竞赛精华总结
!!! info
作者:[Vincent](https://github.com/Realvincentyuan),发布于2021-06-06,阅读时间:约6分钟,微信公众号文章链接:[:fontawesome-solid-link:](https://mp.weixin.qq.com/s?__biz=MzI4Mjk3NzgxOQ==&mid=2247485350&idx=1&sn=630219a13b43b343585b69c048f5f640&chksm=eb90f4d2dce77dc40ed6a88d7e174b6de9a0211e02588b686f76e6840af72fdb72afb8b61876&token=1184541802&lang=zh_CN#rd)
## 1 概述
美国著名金融服务公司American Express(AMEX)在Kaggle上举办了一个[数据科学竞赛](https://www.kaggle.com/competitions/amex-default-prediction),要求参赛者针对信用卡账单数据预测持卡人是否在未来会逾期。其中,各个特征都做了脱敏处理,AMEX提供了特征前缀的解释:
```
D_* = 逾期相关的变量
S_* = 消费相关的变量
P_* = 还款信息
B_* = 欠款信息
R_* = 风险相关的变量
```
下表为竞赛的数据示意(值为虚构,仅做参考)
| customer_ID | S_2 | P_2 | ... | B_2 | D_41 | target |
|---|---|---|---|---|---|---|
| 000002399d6bd597023 | 2017-04-07 | 0.9366 | ... | 0.1243 | 0.2824 | 1 |
| 0000099d6bd597052ca | 2017-03-32 | 0.3466 | ... | 0.5155 | 0.0087 | 0 |
其中`'B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68'`特征为类别型的数据。比赛的目标是对于每一个customer_ID,预测其在未来逾期(target = 1,否则target = 0)的可能性。其中负样本已经做了欠采样(采样率为5%)。近日比赛已经结束,本文将选取目前已经公开代码的方案及一些讨论进行总结,和大家一起学习社区中优秀的思路和具体实现。
## 2 准备工作
由于数据量相对于Kaggle提供的实验环境很大,因此有一些工作是围绕内存的优化展开的,比如[AMEX data - integer dtypes - parquet format](https://www.kaggle.com/datasets/raddar/amex-data-integer-dtypes-parquet-format 'AMEX data - integer dtypes - parquet format')将浮点型的数据转化为了整型,并将数据以`parquet format`格式存储,有效地减少了内存的开销。类似的数据压缩方案还有[AMEX-Feather-Dataset](https://www.kaggle.com/datasets/munumbutt/amexfeather, 'AMEX-Feather-Dataset')。
```
60M sample_submission.csv
32G test_data.csv
16G train_data.csv
30M train_labels.csv
```
同时,本次竞赛的评价指标是客制化的,融合了`top 4% capture`和`gini`,许多方案都参考了[Amex Competition Metric (Python)](https://www.kaggle.com/code/inversion/amex-competition-metric-python, 'Amex Competition Metric (Python)')和[Metric without DF](https://www.kaggle.com/competitions/amex-default-prediction/discussion/327534 'Metric without DF')的代码进行模型性能的评价。
## 3 探索性数据分析
在对数据建模前,透彻地了解它非常关键,探索性数据分析(Exploratory Data Analysis)成为了许多后续工作的基础。在AMEX的竞赛中,Kagglers在这一阶段的工作关注点主要有:
- 检查缺失值
- 检查重复的记录
- 标签的分布
- 每位客户信用卡账单数量及账单日分布
- 类别型变量及数值型变量的分布,是否有异常值
- 特征之间的相关性
- 人为噪音
- 训练集和测试集中特征分布对比
针对这些分析,高分笔记本有如下:
- [Time Series EDA](https://www.kaggle.com/code/cdeotte/time-series-eda#Load-Train-Data, 'Time Series EDA')
- [AMEX EDA which makes sense](https://www.kaggle.com/code/ambrosm/amex-eda-which-makes-sense, 'AMEX EDA which makes sense')
- [American Express EDA](https://www.kaggle.com/code/datark1/american-express-eda, 'American Express EDA')
- [Understanding NA values in AMEX competition](https://www.kaggle.com/code/raddar/understanding-na-values-in-amex-competition, 'Understanding NA values in AMEX competition')
## 4 特征工程 & 建模
### 4.1 特征工程
因为数据为信用卡账单,一个客户有多个账单,而最后预测目标是以客户为单位的,因此融合不同时间的账单数据成为了许多方案的关注点,如:
- 针对连续型变量,以客户为单位对每个特征在所有时间范围内求均值、标准差、最小值、最大值、最近一次账单的值,以及最近一个账单和最开始账单特征的差值、比率等。
- 针对类别型变量,以客户为单位对每个特征在所有时间范围内计数,最近一次账单的值,每个特征值出现的次数,将其转化为数值型变量。随后再根据模型类别做编码(或不手动编码,让模型自己处理)。
相关的高分笔记本主要有:
- [Amex Agg Data How It Created](https://www.kaggle.com/code/huseyincot/amex-agg-data-how-it-created/notebook, 'Amex Agg Data How It Created')
- [Lag Features Are All You Need](https://www.kaggle.com/code/thedevastator/lag-features-are-all-you-need, 'Lag Features Are All You Need')
- [Amex Features: The best of both worlds](https://www.kaggle.com/code/thedevastator/amex-features-the-best-of-both-worlds, 'Amex Features: The best of both worlds')
### 4.2 模型设计、训练及推理
高分方案基本是XGBoost,LightGBM,CatBoost,Transformer, TabNet以及这些模型的集成,各路高手为了提高分数各显神通,在此针对一些高分思路进行讨论。
Chris Deotte是一位在Nvidia工作的Kaggle Grandmaster,他贡献了许多基础的解决方案(如[XGBoost](https://www.kaggle.com/code/cdeotte/xgboost-starter-0-793, 'XGBoost Starter'),[TensorFlow GRU](https://www.kaggle.com/code/cdeotte/tensorflow-gru-starter-0-790, 'TensorFlow GRU Starter'),[TensorFlow Transformer](https://www.kaggle.com/code/cdeotte/tensorflow-transformer-0-790, 'TensorFlow Transformer Starter'))供参考,这些工作为社区提供了很好的工作起点,而Chris最终的方案排名15/4875,使用Transformer并加入了LightGBM知识蒸馏,详见[15th Place Gold – NN Transformer using LGBM Knowledge Distillation](https://www.kaggle.com/competitions/amex-default-prediction/discussion/347641, '15th Place Gold – NN Transformer using LGBM Knowledge Distillation'):
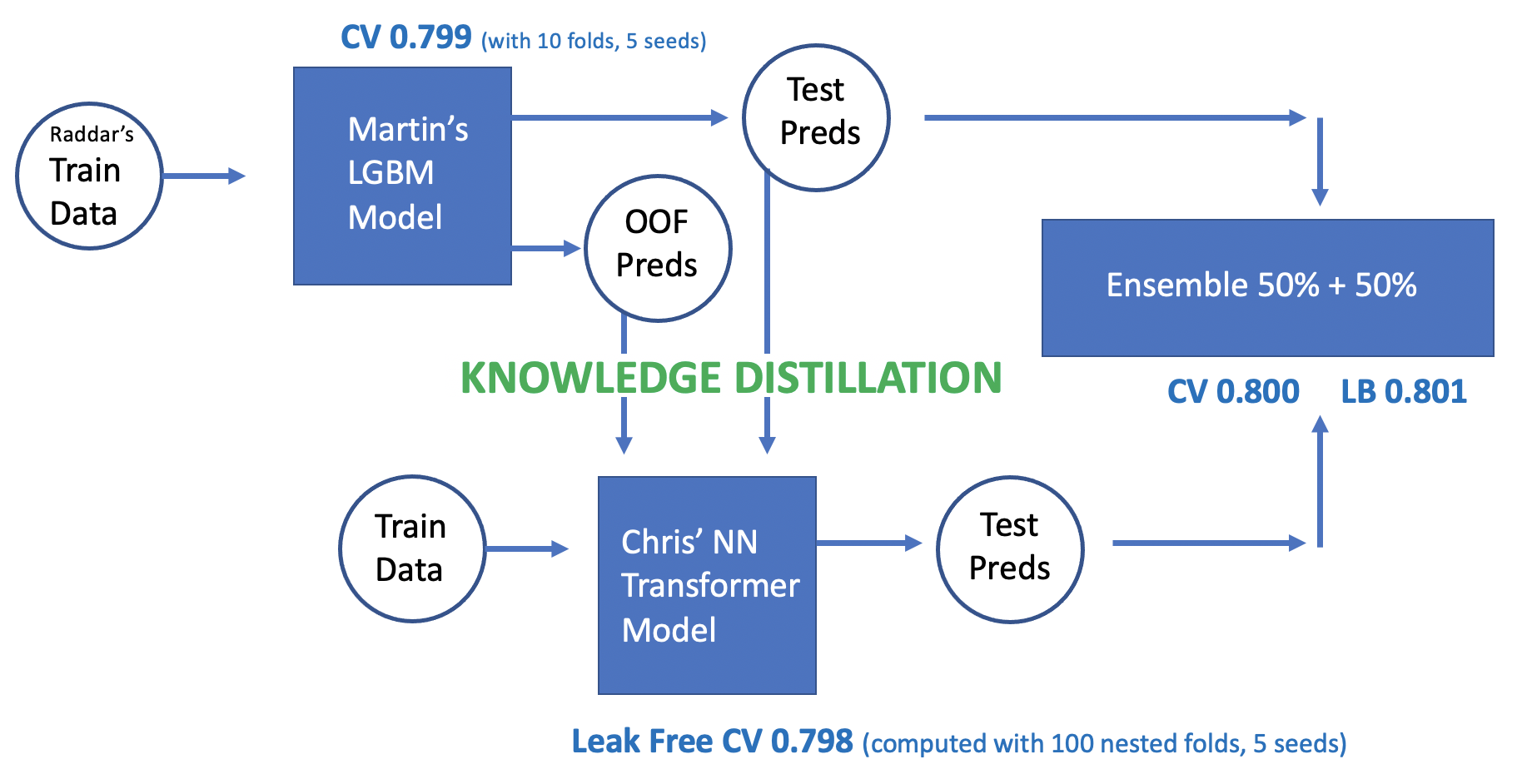 Transformer和LGBM知识蒸馏
- 首先在原始数据上训练LightGBM,将cross validation中的out of fold(OOF)预测结果存下,同时对test集进行预测做pseudo labeling,同时将`OOF和test preds`送入Transformer进行训练
- Transformer从零开始训练是比较困难的,但借助知识蒸馏,Transformer接受了来自LightGBM的教育,同时带有伪标签的测试集数据量很大,这些都帮助了Transformer进行学习。由于Transformer与LightGBM结构迥异,借助于注意力机制,Transformer学习到的信息也有所不同,使得最后在模型融合时有更好的效果。
- 然后Transformer继续基于原始的训练集再次进行训练,这其中融合了nested cross validation,seed blending等方法
- 最终使用50%/50%集成LightGBM和Transformer的输出
私榜第二名的团队也对方案([2nd place solution - team JuneHomes](https://www.kaggle.com/competitions/amex-default-prediction/discussion/347637, '2nd place solution - team JuneHomes'))进行了分享(其称源码会稍后公开),在JuneHomes的分享里,除了技术本身,还有很多最佳实践:
- 团队为了协作,使用了AWS的计算资源,同时对各个过程进行了版本管理(如流程版本,特征工程版本,模型版本等)
- 首先借助社区中的思路去除了一些数据中的噪音,然后进行一些手动特征工程的尝试,但效果有限,最终还是选择了使用上文提及的统计量。
- 在特征选择时,主要依赖于LightGBM的特征重要性和Permutation importance循环迭代特征选择,并用模型CV结果中的AUC做验证。作者也提到其团队尝试了其他的特征选择的办法,但都不如该方法稳定。
- 做模型选择时,作者经过很多实验最后选择了LightGBM,同时还针对账单较少的客户单独建模,最后进行集成。作者的实验表明Stacking作用很小,不同的seed和特征工程的顺序对于结果同样影响甚微。
- 最后作者分享了团队的最开始的项目计划,将全过程工作流里值得注意的点及相关的资料详细地记录了下来,按照计划井井有条地执行,真是赢得实至名归!
相比之下,第一名的方案[1st solution](https://www.kaggle.com/competitions/amex-default-prediction/discussion/348111, 'AMEX 1st solution') 基本是一个大熔炉,并且作者没有详细描述,在此不做讨论。
## 5 总结
在本次比赛中,很多有用的信息和技巧来源于Discussion模块,因此本文也做了一些精华的摘录:
- [Speed Up XGB, CatBoost, and LGBM by 20x](https://www.kaggle.com/competitions/amex-default-prediction/discussion/328606, 'Speed Up XGB, CatBoost, and LGBM by 20x')
- [Which is the right feature importance?](https://www.kaggle.com/competitions/amex-default-prediction/discussion/331131, 'Which is the right feature importance?')
- [11th Place Solution (LightGBM with meta features)](https://www.kaggle.com/competitions/amex-default-prediction/discussion/347786, '11th Place Solution (LightGBM with meta features)')
- [14th Place Gold Solution](https://www.kaggle.com/competitions/amex-default-prediction/discussion/348014, '14th Place Gold Solution')
也有许多kagglers分享了很有借鉴意义的解决方案,以下是一些笔记本:
- [AMEX TabNetClassifier + Feature Eng [0.791]](https://www.kaggle.com/code/medali1992/amex-tabnetclassifier-feature-eng-0-791, 'AMEX TabNetClassifier + Feature Eng [0.791]')
- [KerasTuner - Find the MLP for you!](https://www.kaggle.com/code/illidan7/kerastuner-find-the-mlp-for-you 'KerasTuner - Find the MLP for you!')
- [AmEx lgbm+optuna baseline](https://www.kaggle.com/code/anuragiitr1823/amex-lgbm-optuna-baseline/notebook, 'AmEx lgbm+optuna baseline')
- [RAPIDS cudf Feature Engineering + XGB](https://www.kaggle.com/code/jiweiliu/rapids-cudf-feature-engineering-xgb, 'RAPIDS cudf Feature Engineering + XGB')
- [Amex LGBM Dart CV 0.7977](https://www.kaggle.com/code/ragnar123/amex-lgbm-dart-cv-0-7977, 'Amex LGBM Dart CV 0.7977')
- [AMEX Rank Ensemble](https://www.kaggle.com/code/finlay/amex-rank-ensemble, 'AMEX Rank Ensemble')
希望这次的分享对你有帮助,欢迎在评论区留言讨论!
Transformer和LGBM知识蒸馏
- 首先在原始数据上训练LightGBM,将cross validation中的out of fold(OOF)预测结果存下,同时对test集进行预测做pseudo labeling,同时将`OOF和test preds`送入Transformer进行训练
- Transformer从零开始训练是比较困难的,但借助知识蒸馏,Transformer接受了来自LightGBM的教育,同时带有伪标签的测试集数据量很大,这些都帮助了Transformer进行学习。由于Transformer与LightGBM结构迥异,借助于注意力机制,Transformer学习到的信息也有所不同,使得最后在模型融合时有更好的效果。
- 然后Transformer继续基于原始的训练集再次进行训练,这其中融合了nested cross validation,seed blending等方法
- 最终使用50%/50%集成LightGBM和Transformer的输出
私榜第二名的团队也对方案([2nd place solution - team JuneHomes](https://www.kaggle.com/competitions/amex-default-prediction/discussion/347637, '2nd place solution - team JuneHomes'))进行了分享(其称源码会稍后公开),在JuneHomes的分享里,除了技术本身,还有很多最佳实践:
- 团队为了协作,使用了AWS的计算资源,同时对各个过程进行了版本管理(如流程版本,特征工程版本,模型版本等)
- 首先借助社区中的思路去除了一些数据中的噪音,然后进行一些手动特征工程的尝试,但效果有限,最终还是选择了使用上文提及的统计量。
- 在特征选择时,主要依赖于LightGBM的特征重要性和Permutation importance循环迭代特征选择,并用模型CV结果中的AUC做验证。作者也提到其团队尝试了其他的特征选择的办法,但都不如该方法稳定。
- 做模型选择时,作者经过很多实验最后选择了LightGBM,同时还针对账单较少的客户单独建模,最后进行集成。作者的实验表明Stacking作用很小,不同的seed和特征工程的顺序对于结果同样影响甚微。
- 最后作者分享了团队的最开始的项目计划,将全过程工作流里值得注意的点及相关的资料详细地记录了下来,按照计划井井有条地执行,真是赢得实至名归!
相比之下,第一名的方案[1st solution](https://www.kaggle.com/competitions/amex-default-prediction/discussion/348111, 'AMEX 1st solution') 基本是一个大熔炉,并且作者没有详细描述,在此不做讨论。
## 5 总结
在本次比赛中,很多有用的信息和技巧来源于Discussion模块,因此本文也做了一些精华的摘录:
- [Speed Up XGB, CatBoost, and LGBM by 20x](https://www.kaggle.com/competitions/amex-default-prediction/discussion/328606, 'Speed Up XGB, CatBoost, and LGBM by 20x')
- [Which is the right feature importance?](https://www.kaggle.com/competitions/amex-default-prediction/discussion/331131, 'Which is the right feature importance?')
- [11th Place Solution (LightGBM with meta features)](https://www.kaggle.com/competitions/amex-default-prediction/discussion/347786, '11th Place Solution (LightGBM with meta features)')
- [14th Place Gold Solution](https://www.kaggle.com/competitions/amex-default-prediction/discussion/348014, '14th Place Gold Solution')
也有许多kagglers分享了很有借鉴意义的解决方案,以下是一些笔记本:
- [AMEX TabNetClassifier + Feature Eng [0.791]](https://www.kaggle.com/code/medali1992/amex-tabnetclassifier-feature-eng-0-791, 'AMEX TabNetClassifier + Feature Eng [0.791]')
- [KerasTuner - Find the MLP for you!](https://www.kaggle.com/code/illidan7/kerastuner-find-the-mlp-for-you 'KerasTuner - Find the MLP for you!')
- [AmEx lgbm+optuna baseline](https://www.kaggle.com/code/anuragiitr1823/amex-lgbm-optuna-baseline/notebook, 'AmEx lgbm+optuna baseline')
- [RAPIDS cudf Feature Engineering + XGB](https://www.kaggle.com/code/jiweiliu/rapids-cudf-feature-engineering-xgb, 'RAPIDS cudf Feature Engineering + XGB')
- [Amex LGBM Dart CV 0.7977](https://www.kaggle.com/code/ragnar123/amex-lgbm-dart-cv-0-7977, 'Amex LGBM Dart CV 0.7977')
- [AMEX Rank Ensemble](https://www.kaggle.com/code/finlay/amex-rank-ensemble, 'AMEX Rank Ensemble')
希望这次的分享对你有帮助,欢迎在评论区留言讨论!
%20-%20Tail%20Pic.png)