## Overview
Easy Dataset is an application specifically designed for building large language model (LLM) datasets. It features an intuitive interface, along with built-in powerful document parsing tools, intelligent segmentation algorithms, data cleaning and augmentation capabilities. The application can convert domain-specific documents in various formats into high-quality structured datasets, which are applicable to scenarios such as model fine-tuning, retrieval-augmented generation (RAG), and model performance evaluation.
## News
🎉🎉 Easy Dataset Version 1.7.0 launches brand-new evaluation capabilities! You can effortlessly convert domain-specific documents into evaluation datasets (test sets) and automatically run multi-dimensional evaluation tasks. Additionally, it comes with a human blind test system, enabling you to easily meet needs such as vertical domain model evaluation, post-fine-tuning model performance assessment, and RAG recall rate evaluation. Tutorial: [https://www.bilibili.com/video/BV1CRrVB7Eb4/](https://www.bilibili.com/video/BV1CRrVB7Eb4/)
## Features
### 📄 Document Processing & Data Generation
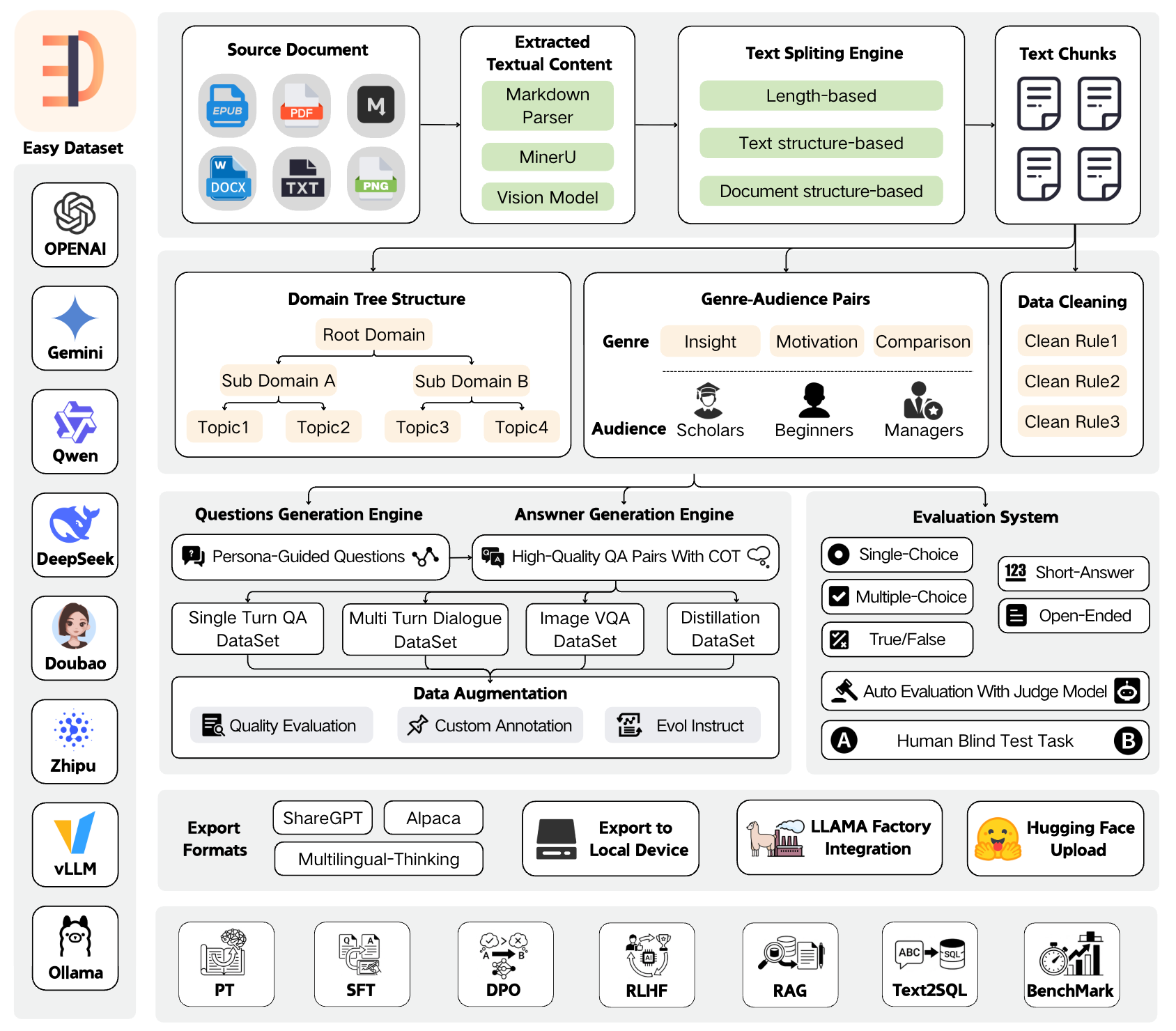
- **Intelligent Document Processing**: Supports PDF, Markdown, DOCX, TXT, EPUB and more formats with intelligent recognition
- **Intelligent Text Splitting**: Multiple splitting algorithms (Markdown structure, recursive separators, fixed length, code-aware chunking), with customizable visual segmentation
- **Intelligent Question Generation**: Auto-extract relevant questions from text segments, with question templates and batch generation
- **Domain Label Tree**: Intelligently builds global domain label trees based on document structure, with auto-tagging capabilities
- **Answer Generation**: Uses LLM API to generate comprehensive answers and Chain of Thought (COT), with AI optimization
- **Data Cleaning**: Intelligent text cleaning to remove noise and improve data quality
### 🔄 Multiple Dataset Types
- **Single-Turn QA Datasets**: Standard question-answer pairs for basic fine-tuning
- **Multi-Turn Dialogue Datasets**: Customizable roles and scenarios for conversational format
- **Image QA Datasets**: Generate visual QA data from images, with multiple import methods (directory, PDF, ZIP)
- **Data Distillation**: Generate label trees and questions directly from domain topics without uploading documents
### 📊 Model Evaluation System
- **Evaluation Datasets**: Generate true/false, single-choice, multiple-choice, short-answer, and open-ended questions
- **Automated Model Evaluation**: Use Judge Model to automatically evaluate model answer quality with customizable scoring rules
- **Human Blind Test (Arena)**: Double-blind comparison of two models' answers for unbiased evaluation
- **AI Quality Assessment**: Automatic quality scoring and filtering of generated datasets
### 🛠️ Advanced Features
- **Custom Prompts**: Project-level customization of all prompt templates (question generation, answer generation, data cleaning, etc.)
- **GA Pair Generation**: Genre-Audience pair generation to enrich data diversity
- **Task Management Center**: Background batch task processing with monitoring and interruption support
- **Resource Monitoring Dashboard**: Token consumption statistics, API call tracking, model performance analysis
- **Model Testing Playground**: Compare up to 3 models simultaneously
### 📤 Export & Integration
- **Multiple Export Formats**: Alpaca, ShareGPT, Multilingual-Thinking formats with JSON/JSONL file types
- **Balanced Export**: Configure export counts per tag for dataset balancing
- **LLaMA Factory Integration**: One-click LLaMA Factory configuration file generation
- **Hugging Face Upload**: Direct upload datasets to Hugging Face Hub
### 🤖 Model Support
- **Wide Model Compatibility**: Compatible with all LLM APIs that follow the OpenAI format
- **Multi-Provider Support**: OpenAI, MiniMax, Ollama (local models), Zhipu AI, Alibaba Bailian, OpenRouter, and more
- **Vision Models**: Support Gemini, Claude, etc. for PDF parsing and image QA
### 🌐 User Experience
- **User-Friendly Interface**: Modern, intuitive UI designed for both technical and non-technical users
- **Multi-Language Support**: Complete Chinese, English, Turkish and Portuguese language support 🇹🇷
- **Dataset Square**: Discover and explore public dataset resources
- **Desktop Clients**: Available for Windows, macOS, and Linux
## Quick Demo
https://github.com/user-attachments/assets/6ddb1225-3d1b-4695-90cd-aa4cb01376a8
## Local Run
### Download Client








{kind=link}