[English](README.md) · [简体中文](README_zh-CN.md) · [日本語](README_ja.md)
👋 DiscordとWeChatでご参加ください
このプロジェクトが役に立ったら、GitHubで⭐を付けてください!
# はじめに
**Dingo は包括的な AI データ、モデル、アプリケーション品質評価ツール**であり、機械学習エンジニア、データエンジニア、AI 研究者向けに設計されています。トレーニングデータ、ファインチューニングデータセット、本番 AI システムの品質を体系的に評価・改善するのを支援します。
---
## 🚀 エンタープライズ SaaS 版
**本番グレードのデータ品質プラットフォーム**が必要ですか?[Dingo SaaS](https://dingo.openxlab.org.cn) エンタープライズ版をお試しください!
### ✨ オープンソース版と比較して、SaaS 版が提供する機能:
- 🌐 **Web UI** - ビジュアル評価インターフェース、コーディング不要
- 🔐 **アクセス制御** - JWT + Google OAuth 2.0
- 📊 **ビジュアルレポート** - インタラクティブなチャート、トレンド分析、エクスポート機能
- 🔌 **RESTful API** - 既存システムとのシームレスな統合
SaaS — Dashboard
SaaS — Playground
SaaS — Evaluation output
### 📝 無料 SaaS コードの入手方法
👉 **[Dingo SaaS リポジトリアクセスを申請する](https://aicarrier.feishu.cn/share/base/form/shrcnr19E0upfiA92Wm5i2eic7g)**
審査時間:1-5営業日 | エンタープライズデータガバナンス、チームコラボレーションに最適
---
## なぜ Dingo を選ぶのか?
🎯 **本番グレードの品質チェック** - 事前学習データセットから RAG システムまで、AI に高品質なデータを提供
🗄️ **マルチソースデータ統合** - ローカルファイル、SQL データベース(PostgreSQL/MySQL/SQLite)、HuggingFace データセット、S3 ストレージへのシームレスな接続
🔍 **マルチフィールド評価** - 異なるフィールドに並行して異なる品質ルールを適用(例:`isbn` フィールドには ISBN 検証、`title` フィールドにはテキスト品質チェック)
🤖 **RAG システム評価** - 5つの学術的裏付けのある指標で検索と生成品質を包括的に評価
🧠 **LLM とルールのハイブリッド** - 高速ヒューリスティックルール(30以上の組み込みルール)と LLM ベースの深度評価を組み合わせ
🚀 **柔軟な実行** - ローカルで実行して迅速に反復、または Spark で数十億規模のデータセットにスケール
📊 **豊富なレポート** - GUI 可視化とフィールドレベルの洞察を備えた詳細な品質レポート
## アーキテクチャ図
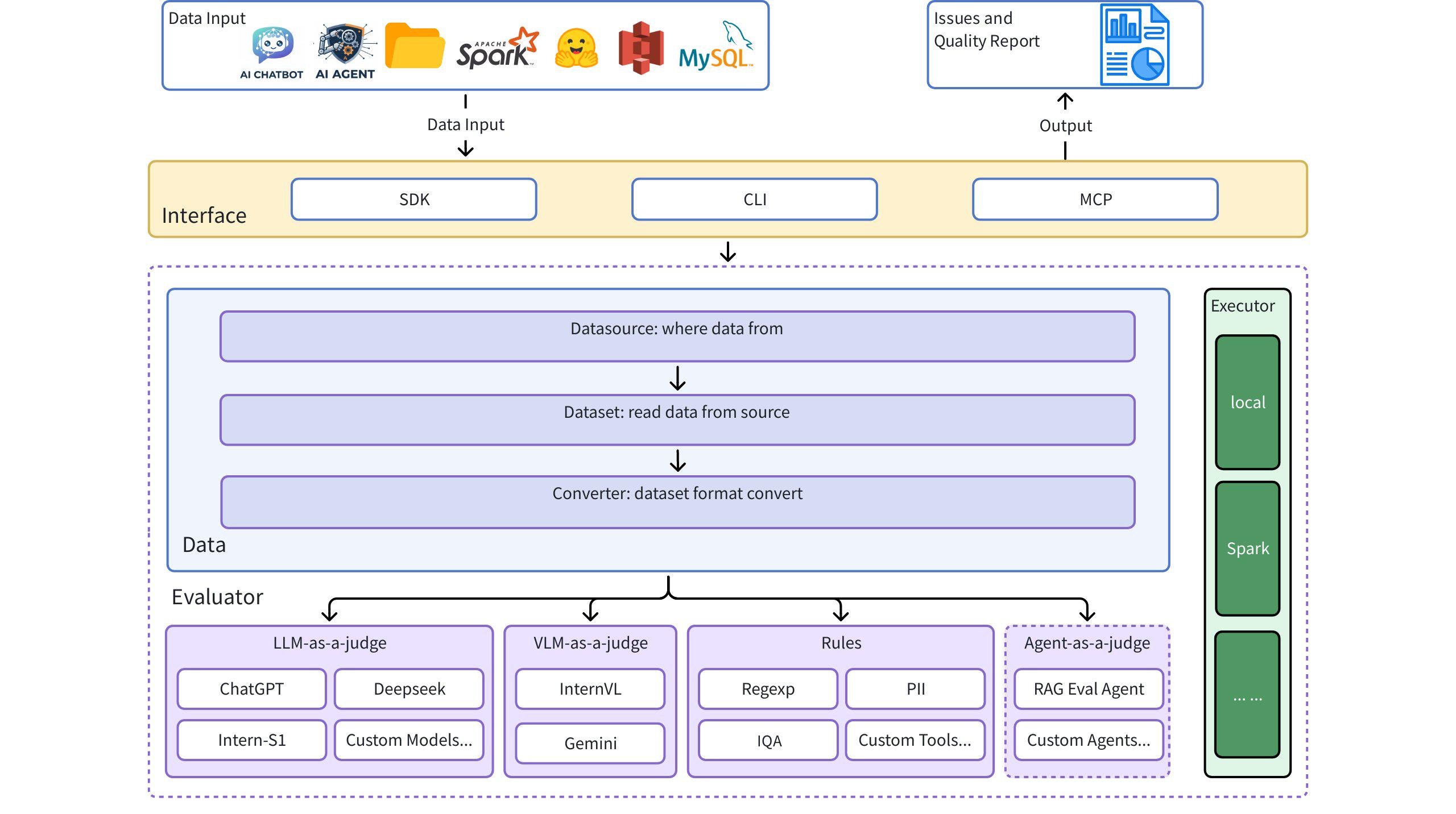
# クイックスタート
## インストール
```shell
# コアパッケージ(ルール評価、LLM 評価、MCP サーバー、データソース対応)
pip install dingo-python
# HHEM 幻覚検出モデル(transformers + torch が必要)
pip install "dingo-python[hhem]"
# 全機能をインストール(HHEM + Agent)
pip install "dingo-python[all]"
```
## 使用例
### 1. LLMチャットデータの評価
```python
from dingo.config.input_args import EvaluatorLLMArgs
from dingo.io.input import Data
from dingo.model.llm.text_quality.llm_text_quality_v4 import LLMTextQualityV4
from dingo.model.rule.rule_common import RuleSpecialCharacter
data = Data(
data_id='123',
prompt="hello, introduce the world",
content="�I am 8 years old. ^I love apple because:"
)
def llm():
LLMTextQualityV4.dynamic_config = EvaluatorLLMArgs(
key='YOUR_API_KEY',
api_url='https://api.openai.com/v1/chat/completions',
model='gpt-4o',
)
res = LLMTextQualityV4.eval(data)
print(res)
def rule():
res = RuleSpecialCharacter().eval(data)
print(res)
rule()
```
### 2. データセットの評価
```python
from dingo.config import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
if __name__ == '__main__':
input_data = {
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"dataset": {
"source": "hugging_face",
"format": "plaintext" # Format: plaintext
},
"executor": {
"result_save": {
"bad": True # Save evaluation results
}
},
"evaluator": [
{
"evals": [
{"name": "RuleColonEnd"},
{"name": "RuleSpecialCharacter"}
]
}
]
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
```
## コマンドラインインターフェース
### ルールセットでの評価
```shell
dingo eval --input .github/env/local_plaintext.json
```
### LLM(例:GPT-4o)での評価
```shell
dingo eval --input .github/env/local_json.json
```
---
# MCPサーバー
Dingoは、AIエージェント統合のための組み込みModel Context Protocol(MCP)サーバーを提供します:
```bash
# MCPサーバーを起動(SSEトランスポート、デフォルトポート8000)
dingo serve
# カスタムポート
dingo serve --port 9000
# stdioトランスポート(Claude Desktop用)
dingo serve --transport stdio
```
詳細なセットアップとCursor/Claude Desktop統合については、専用のドキュメントをご覧ください:
[English](README_mcp.md) · [简体中文](README_mcp_zh-CN.md) · [日本語](README_mcp_ja.md)
## ビデオデモンストレーション
Dingo MCPを素早く始められるよう、ビデオウォークスルーを作成しました:
https://github.com/user-attachments/assets/aca26f4c-3f2e-445e-9ef9-9331c4d7a37b
このビデオでは、Dingo MCPサーバーをCursorと一緒に使用する方法をステップバイステップで説明しています。
---
# 📚 データ品質メトリクス
Dingo は **70以上の評価メトリクス**を提供し、複数の次元にわたってルールベースの速度と LLM ベースの深度を組み合わせます。
## メトリクスカテゴリ
| カテゴリ | 例 | 使用例 |
|----------|----------|----------|
| **事前学習テキスト品質** | 完全性、有効性、類似性、セキュリティ | LLM 事前学習データフィルタリング |
| **SFT データ品質** | 正直、有用、無害 (3H) | 指示ファインチューニングデータ |
| **RAG 評価** | 忠実度、コンテキスト精度、答え関連性 | RAG システム評価 |
| **幻覚検出** | HHEM-2.1-Open、事実性チェック | 本番 AI 信頼性 |
| **分類** | トピック分類、コンテンツラベリング | データ整理 |
| **マルチモーダル** | 画像テキスト関連性、VLM 品質、OCR 視覚評価 | ビジュアル言語データ |
| **セキュリティ** | PII 検出、Perspective API 毒性 | プライバシーと安全性 |
📊 **[完全なメトリクス文書を表示 →](docs/metrics.md)**
📖 **[RAG 評価ガイド →](docs/rag_evaluation_metrics_zh.md)**
🔍 **[幻覚検出ガイド →](docs/hallucination_guide.md)**
✅ **[事実性評価ガイド →](docs/factcheck_guide.md)**
👁️ **[VLM レンダリング判定ガイド →](docs/en/vlm_render_judge_guide.md)** | **[中文版](docs/vlm_render_judge_guide.md)**
大部分のメトリクスは学術研究に裏付けられており、科学的厳密性を確保しています。
## メトリクスの迅速な使用
```python
llm_config = {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
input_data = {
"evaluator": [
{
"fields": {"content": "content"},
"evals": [
{"name": "RuleAbnormalChar"}, # ルールベース(高速)
{"name": "LLMTextQualityV5", "config": llm_config} # LLMベース(深度)
]
}
]
}
```
**カスタマイズ**:すべてのプロンプトは `dingo/model/llm/` ディレクトリに定義されています(カテゴリ別に整理:`text_quality/`、`rag/`、`hhh/` など)。ドメイン固有のニーズに合わせて拡張または変更できます。
---
# 🎓 実務者のための重要概念
## Dingo を本番環境で使用できる理由
### 1. **マルチフィールド評価パイプライン**
1回の実行で異なるフィールドに異なる品質チェックを適用:
```python
"evaluator": [
{"fields": {"content": "isbn"}, "evals": [{"name": "RuleIsbn"}]},
{"fields": {"content": "title"}, "evals": [{"name": "RuleAbnormalChar"}]},
{"fields": {"content": "description"}, "evals": [{"name": "LLMTextQualityV5"}]}
]
```
**重要性**:各フィールドごとに別々のスクリプトを書かずに構造化データ(データベーステーブルなど)を評価できます。
### 2. **大規模データセットのストリーミング処理**
SQL データソースは SQLAlchemy のサーバーサイドカーソルを使用:
```python
# メモリオーバーフローなしで数十億行を処理
for data in dataset.get_data(): # 1行ずつyield
result = evaluator.eval(data)
```
**重要性**:中間ファイルにエクスポートすることなく本番データベースを処理できます。
### 3. **メモリ内フィールド分離**
RAG 評価は異なるフィールド組み合わせ間のコンテキストリークを防止:
```
outputs/
├── user_input,response,retrieved_contexts/ # Faithfulness グループ
└── user_input,response/ # Answer Relevancy グループ
```
**重要性**:複数のフィールド組み合わせを評価する際のメトリクス計算の正確性を保証。
### 4. **ルール-LLM ハイブリッド戦略**
高速ルール(100% カバレッジ)とサンプリング LLM チェック(10% カバレッジ)を組み合わせ:
```python
"evals": [
{"name": "RuleAbnormalChar"}, # 高速、全データで実行
{"name": "LLMTextQualityV5"} # コスト高、必要に応じてサンプリング
]
```
**重要性**:本番規模の評価でコストとカバレッジのバランスを取る。
### 5. **登録による拡張性**
カスタムルール、プロンプト、モデルのための明確なプラグインアーキテクチャ:
```python
@Model.rule_register('QUALITY_BAD_CUSTOM', ['default'])
class MyCustomRule(BaseRule):
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
# 例:コンテンツが空かチェック
if not input_data.content:
return EvalDetail(
metric=cls.__name__,
status=True, # 問題を発見
label=[f'{cls.metric_type}.{cls.__name__}'],
reason=["コンテンツが空です"]
)
return EvalDetail(
metric=cls.__name__,
status=False, # 問題なし
label=['QUALITY_GOOD']
)
```
**重要性**:コードベースをフォークせずにドメイン固有のニーズに適応。
---
# 🌟 機能ハイライト
## 📊 マルチソースデータ統合
**多様なデータソース** - データがある場所に接続
✅ **ローカルファイル**:JSONL、CSV、TXT、Parquet
✅ **SQL データベース**:PostgreSQL、MySQL、SQLite、Oracle、SQL Server(ストリーミング処理対応)
✅ **クラウドストレージ**:S3 および S3 互換ストレージ
✅ **ML プラットフォーム**:HuggingFace データセットの直接統合
**エンタープライズ対応 SQL サポート** - 本番データベース統合
✅ 数十億規模のデータセットのメモリ効率的なストリーミング
✅ 接続プールと自動リソースクリーンアップ
✅ 複雑な SQL クエリ(JOIN、WHERE、集計)
✅ SQLAlchemy による複数の方言サポート
**マルチフィールド品質チェック** - 異なるフィールドに異なるルール
✅ 並列評価パイプライン(例:ISBN 検証 + テキスト品質を同時実行)
✅ フィールドエイリアスとネストされたフィールド抽出(`user.profile.name`)
✅ フィールドごとに独立した結果レポート
✅ 柔軟なデータ変換のための ETL パイプラインアーキテクチャ
---
## 🤖 RAG システム評価
**5つの学術的裏付けのある指標** - RAGAS、DeepEval、TruLens 研究に基づく
✅ **忠実度(Faithfulness)**:答え-コンテキストの一貫性(幻覚検出)
✅ **答え関連性(Answer Relevancy)**:答え-クエリの整合性
✅ **コンテキスト精度(Context Precision)**:検索精度
✅ **コンテキスト再現率(Context Recall)**:検索再現率
✅ **コンテキスト関連性(Context Relevancy)**:コンテキスト-クエリ関連性
**包括的なレポート** - 自動集計統計
✅ 各メトリクスの平均、最小、最大、標準偏差
✅ フィールド別にグループ化された結果
✅ バッチおよび単一評価モード
📖 **[RAG 評価ガイドを見る →](docs/rag_evaluation_metrics_zh.md)**
---
## 🧠 ハイブリッド評価システム
**ルールベース** - 高速、決定論的、コスト効率
✅ 30以上の組み込みルール(テキスト品質、フォーマット、PII 検出)
✅ 正規表現、ヒューリスティック、統計チェック
✅ カスタムルール登録
**LLM ベース** - 深い意味理解
✅ OpenAI(GPT-4o、GPT-3.5)、DeepSeek、Kimi
✅ ローカルモデル(Llama3、Qwen)
✅ ビジョン言語モデル(InternVL、Gemini)
✅ カスタムプロンプト登録
**エージェントベース** - ツールを活用した多段階推論
✅ Web 検索統合(Tavily)
✅ 適応型コンテキスト収集
✅ マルチソース事実検証
✅ カスタムエージェントとツール登録
**拡張可能なアーキテクチャ**
✅ プラグインベースのルール/プロンプト/モデル登録
✅ 明確な関心の分離(エージェント、ツール、オーケストレーション)
✅ ドメイン固有のカスタマイズ
---
## 🚀 柔軟な実行と統合
**複数のインターフェース**
✅ 迅速なチェックのための CLI
✅ 統合のための Python SDK
✅ IDE 用 MCP(モデルコンテキストプロトコル)サーバー(Cursor など)
**スケーラブルな実行**
✅ 迅速な反復のためのローカル実行
✅ 分散処理のための Spark 実行
✅ 設定可能な並行性とバッチ処理
**データソース**
✅ **ローカルファイル**:JSONL、CSV、TXT、Parquet フォーマット
✅ **Hugging Face**:HF データセットハブとの直接統合
✅ **S3 ストレージ**:AWS S3 および S3 互換ストレージ
✅ **SQL データベース**:PostgreSQL、MySQL、SQLite、Oracle、SQL Server(大規模データのストリーミング処理)
**モダリティ**
✅ テキスト(チャット、ドキュメント、コード)
✅ 画像(VLM サポート)
✅ マルチモーダル(テキスト+画像の一貫性)
---
## 📈 豊富なレポートと可視化
**多層レポート**
✅ 全体スコア付き Summary JSON
✅ フィールドレベルの内訳
✅ ルール違反ごとの詳細情報
✅ タイプと名前の分布
**GUI 可視化([Dingo SaaS](https://github.com/MigoXLab/dingo-saas) 経由)**
✅ Web UI によるインタラクティブなデータ探索
✅ トレンド分析付きビジュアルレポート
✅ 異常追跡
**メトリクス集計**
✅ 自動統計(avg、min、max、std_dev)
✅ フィールド別にグループ化されたメトリクス
✅ 全体品質スコア
---
# 📖 ユーザーガイド
## カスタムルール、プロンプト、モデル
Dingo はドメイン固有のニーズに対応する柔軟な拡張メカニズムを提供します。
**例:**
- [カスタムルール](examples/register/sdk_register_rule.py)
- [カスタムモデル](examples/register/sdk_register_llm.py)
### カスタムルール例
```python
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.io import Data
from dingo.io.output.eval_detail import EvalDetail
@Model.rule_register('QUALITY_BAD_CUSTOM', ['default'])
class DomainSpecificRule(BaseRule):
"""ドメイン固有のパターンをチェック"""
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
text = input_data.content
# あなたのカスタムロジック
is_valid = your_validation_logic(text)
return EvalDetail(
metric=cls.__name__,
status=not is_valid, # False = 良好, True = 問題あり
label=['QUALITY_GOOD' if is_valid else 'QUALITY_BAD_CUSTOM'],
reason=["検証の詳細..."]
)
```
### カスタムLLM統合
```python
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# ここにカスタム実装
pass
```
詳細な例については以下をご覧ください:
- [ルール登録](examples/register/sdk_register_rule.py)
- [モデル登録](examples/register/sdk_register_llm.py)
### エージェントベース評価とツール
Dingo はエージェントベースの評価器をサポートし、外部ツールを使用した多段階推論と適応型コンテキスト収集が可能です。2つの実装パターンが利用できます:
**パターン 1:LangChain ベース**(例:`AgentFactCheck`)
- フレームワーク駆動、自律的多段階推論
- LangChain 1.0 の `create_agent` と ReAct パターンを使用
- 適用:複雑な推論タスク、迅速なプロトタイピング
- コードが少なく、より宣言的
**パターン 2:カスタムワークフロー**(例:`AgentHallucination`)
- 開発者駆動、明示的なワークフロー制御
- 手動でのツール呼び出しと LLM インタラクション
- 適用:既存の評価器の組み合わせ、ドメイン固有のワークフロー
- 完全な制御、明示的な動作
両パターンは同じ設定インターフェースを共有し、ユーザーに対して透過的です。
**組み込みエージェント:**
- `AgentFactCheck`: LangChain ベースのファクトチェック、自律的検索制御
- `AgentHallucination`: カスタムワークフローの幻覚検出、適応型コンテキスト収集
- `ArticleFactChecker`: 2段階の記事ファクトチェック — 検証可能な主張を抽出し、Web 検索と Arxiv を使用して並行検証、設定可能な並行制御
**クイック例:**
```python
from dingo.io import Data
from dingo.io.output.eval_detail import EvalDetail
from dingo.model import Model
from dingo.model.llm.agent.base_agent import BaseAgent
@Model.llm_register('MyAgent')
class MyAgent(BaseAgent):
"""ツールサポート付きカスタムエージェント"""
available_tools = ["tavily_search", "my_custom_tool"]
max_iterations = 5
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
# ツールを使用してファクトチェック
search_result = cls.execute_tool('tavily_search', query=input_data.content)
# LLM を使用した多段階推論
result = cls.send_messages([...])
return EvalDetail(...)
```
エージェントパターンの選択と実装の詳細については、[エージェント開発ガイド](docs/agent_development_guide.md)をご参照ください。
**設定例:**
```json
{
"evaluator": [{
"evals": [{
"name": "AgentHallucination",
"config": {
"key": "openai-api-key",
"model": "gpt-4",
"parameters": {
"agent_config": {
"max_iterations": 5,
"tools": {
"tavily_search": {"api_key": "tavily-key"}
}
}
}
}
}]
}]
}
```
**詳しく学ぶ:**
- [エージェント開発ガイド](docs/agent_development_guide.md)
- [AgentHallucination 例](examples/agent/agent_hallucination_example.py)
- [AgentFactCheck LangChain例](examples/agent/agent_executor_example.py)
- [ArticleFactChecker 例](examples/agent/agent_article_fact_checking_example.py) - 記事レベルの2段階ファクトチェック
## 実行エンジン
### ローカル実行
```python
from dingo.config import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# 結果を取得
summary = executor.get_summary() # 全体的な評価サマリー
bad_data = executor.get_bad_info_list() # 問題のあるデータのリスト
good_data = executor.get_good_info_list() # 高品質データのリスト
```
### Spark実行
```python
from dingo.config import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# Sparkを初期化
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # Dataオブジェクトとしてのデータ
input_data = {
"executor": {
"result_save": {"bad": True}
},
"evaluator": [
{
"fields": {"content": "content"},
"evals": [
{"name": "RuleColonEnd"},
{"name": "RuleSpecialCharacter"}
]
}
]
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()
```
## 評価レポート
評価後、Dingoは以下を生成します:
1. **サマリーレポート** (`summary.json`): 全体的なメトリクスとスコア
2. **詳細レポート**: 各ルール違反の具体的な問題
レポートの説明:
1. **score**: `num_good` / `total`
2. **type_ratio**: タイプの数 / 総数, 例: `QUALITY_BAD_COMPLETENESS` / `total`
サマリー例:
```json
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"content": {
"QUALITY_BAD_COMPLETENESS.RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE.RuleSpecialCharacter": 0.5
}
}
}
```
# 🔮 今後の計画
**近日公開予定の機能**:
- [ ] **Agent-as-a-Judge** - 多ラウンド反復評価
- [ ] **SaaS プラットフォーム** - API アクセスとダッシュボードを備えたホスト型評価サービス
- [ ] **音声・動画モダリティ** - テキスト/画像を超えた拡張
- [ ] **多様性メトリクス** - 統計的多様性評価
- [ ] **リアルタイム監視** - 本番パイプラインでの継続的品質チェック
## 制限事項
現在の組み込み検出ルールとモデル手法は、一般的なデータ品質問題に焦点を当てています。専門的な評価ニーズについては、検出ルールのカスタマイズを推奨します。
# 謝辞
- [RedPajama-Data](https://github.com/togethercomputer/RedPajama-Data)
- [mlflow](https://github.com/mlflow/mlflow)
- [deepeval](https://github.com/confident-ai/deepeval)
- [ragas](https://github.com/explodinggradients/ragas)
# 貢献
`Dingo`の改善と強化に努力してくださったすべての貢献者に感謝いたします。プロジェクトへの貢献に関するガイダンスについては、[貢献ガイド](docs/en/CONTRIBUTING.md)をご参照ください。
# ライセンス
このプロジェクトは[Apache 2.0オープンソースライセンス](LICENSE)を使用しています。
このプロジェクトは言語検出を含む一部の機能でfasttextを使用しています。fasttextはMITライセンスの下でライセンスされており、これは当社のApache 2.0ライセンスと互換性があり、様々な使用シナリオに柔軟性を提供します。
# 引用
このプロジェクトが有用だと思われる場合は、当社のツールの引用をご検討ください:
```
@misc{dingo,
title={Dingo: A Comprehensive AI Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/MigoXLab/dingo}},
year={2024}
}
```





