[English](README.md) · [简体中文](README_zh-CN.md) · [日本語](README_ja.md)
👋 加入我们 Discord 和 微信
如果觉得有帮助,欢迎在 GitHub 上点个 ⭐ 支持!
# Dingo 介绍
**Dingo 是一款全面的 AI 数据、模型和应用质量评估工具**,专为机器学习工程师、数据工程师和 AI 研究人员设计。它帮助你系统化地评估和改进训练数据、微调数据集和生产AI系统的质量。
---
## 🚀 企业级 Dingo SaaS 版本
需要 **生产级数据质量平台** 吗?试试 [Dingo SaaS](https://dingo.openxlab.org.cn) 企业版!
### ✨ 相比开源版,SaaS 版提供:
- 🌐 **Web UI** - 可视化评估界面,无需写代码
- 🔐 **权限管理** - JWT + Google OAuth 2.0
- 📊 **可视化报告** - 交互式图表、趋势分析、导出功能
- 🔌 **RESTful API** - 与现有系统无缝集成
SaaS — Dashboard
SaaS — Playground
SaaS — Evaluation output
### 📝 如何获得免费 SaaS 代码
👉 **[点击申请 Dingo SaaS 代码仓库访问权限](https://aicarrier.feishu.cn/share/base/form/shrcn9RqYttByQ5H1np6Yrnmhuf)**
审核时间:1-5 个工作日 | 适合企业数据治理、团队协作
---
## 为什么选择 Dingo?
🎯 **生产级质量检查** - 从预训练数据集到 RAG 系统,确保你的 AI 获得高质量数据
🗄️ **多数据源集成** - 无缝连接本地文件、SQL 数据库(PostgreSQL/MySQL/SQLite)、HuggingFace 数据集和 S3 存储
🔍 **多字段评估** - 对不同字段并行应用不同的质量规则(例如:对 `isbn` 字段进行 ISBN 验证,对 `title` 字段进行文本质量检查)
🤖 **RAG 系统评估** - 使用 5 个学术支持的指标全面评估检索和生成质量
🧠 **LLM、规则和智能体混合** - 结合快速启发式规则(30+ 内置规则)和基于 LLM 的深度评估
🚀 **灵活执行** - 本地运行快速迭代,或使用 Spark 扩展到数十亿级数据集
📊 **丰富报告** - 详细的质量报告,带有 GUI 可视化和字段级洞察
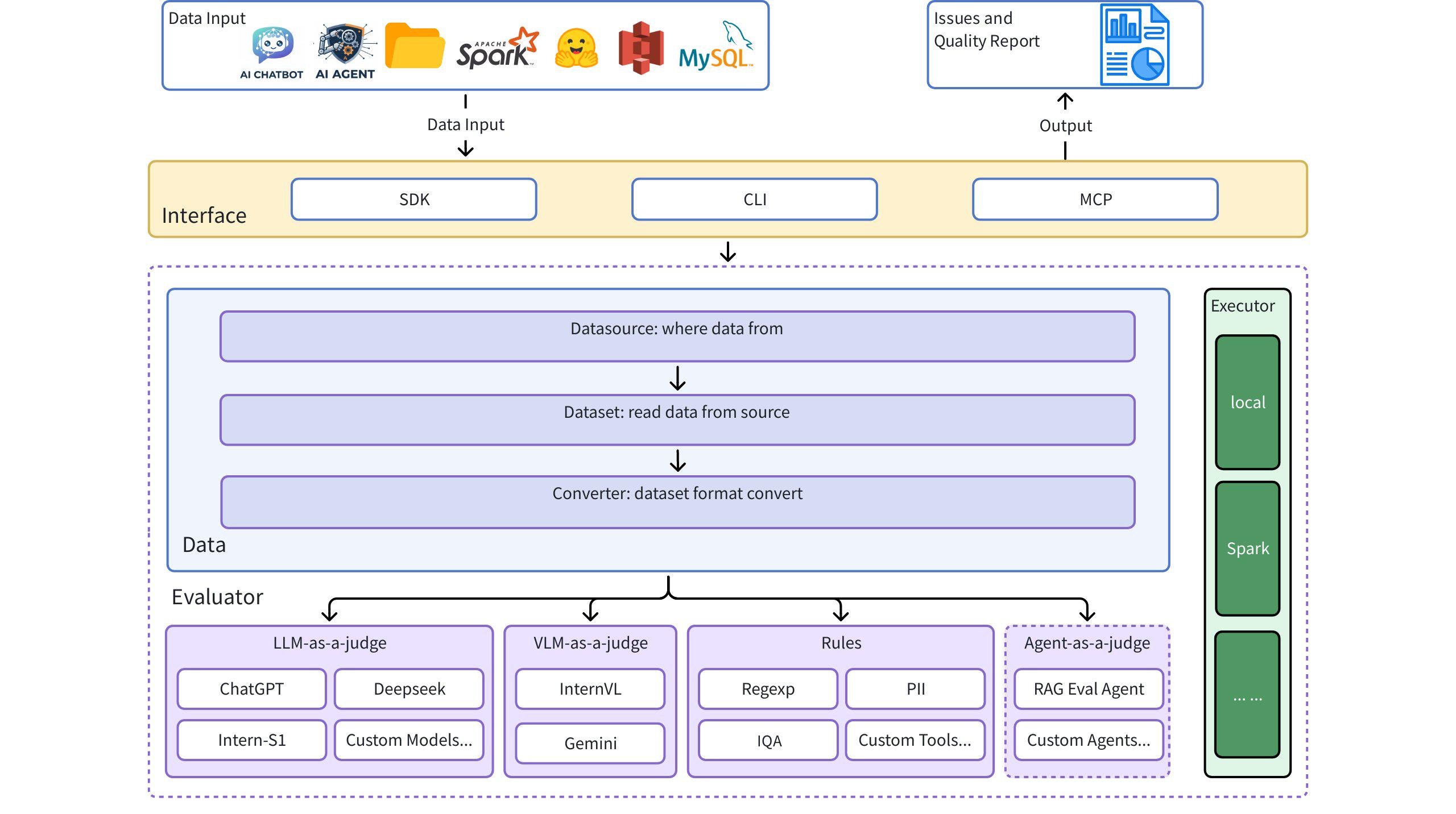
## 架构图
# 快速启动
## 安装
```shell
# 核心包(包含规则评估、LLM 评估、MCP 服务、数据源支持)
pip install dingo-python
# 安装 HHEM 幻觉检测模型(需要 transformers + torch)
pip install "dingo-python[hhem]"
# 安装全部功能(HHEM + Agent)
pip install "dingo-python[all]"
```
## Dingo 使用示例
### 1. 评估LLM对话数据
```python
from dingo.config.input_args import EvaluatorLLMArgs
from dingo.io.input import Data
from dingo.model.llm.text_quality.llm_text_quality_v4 import LLMTextQualityV4
from dingo.model.rule.rule_common import RuleSpecialCharacter
data = Data(
data_id='123',
prompt="hello, introduce the world",
content="�I am 8 years old. ^I love apple because:"
)
def llm():
LLMTextQualityV4.dynamic_config = EvaluatorLLMArgs(
key='YOUR_API_KEY',
api_url='https://api.openai.com/v1/chat/completions',
model='gpt-4o',
)
res = LLMTextQualityV4.eval(data)
print(res)
def rule():
res = RuleSpecialCharacter().eval(data)
print(res)
rule()
```
### 2. 评估数据集
```python
from dingo.config import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
if __name__ == '__main__':
input_data = {
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"dataset": {
"source": "hugging_face",
"format": "plaintext" # Format: plaintext
},
"executor": {
"result_save": {
"bad": True # Save evaluation results
}
},
"evaluator": [
{
"evals": [
{"name": "RuleColonEnd"},
{"name": "RuleSpecialCharacter"}
]
}
]
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
```
## 命令行界面
### 使用规则集评估
```shell
dingo eval --input .github/env/local_plaintext.json
```
### 使用LLM评估(例如GPT-4o)
```shell
dingo eval --input .github/env/local_json.json
```
---
# MCP 服务端
Dingo 内置了模型上下文协议 (MCP) 服务端,支持 AI Agent 集成:
```bash
# 启动 MCP 服务端(SSE 传输,默认端口 8000)
dingo serve
# 自定义端口
dingo serve --port 9000
# stdio 传输(适用于 Claude Desktop)
dingo serve --transport stdio
```
详细配置和 Cursor/Claude Desktop 集成说明,请参阅专门文档:
[English](README_mcp.md) · [简体中文](README_mcp_zh-CN.md) · [日本語](README_mcp_ja.md)
## 视频演示
为了帮助您快速上手 Dingo MCP,我们制作了视频演示:
https://github.com/user-attachments/assets/aca26f4c-3f2e-445e-9ef9-9331c4d7a37b
此视频展示了关于 Dingo MCP 服务端与 Cursor 一起使用的分步演示。
---
# 📚 数据质量指标
Dingo 提供 **100+ 评估指标**,跨多个维度,结合基于规则的速度和基于 LLM 的深度。
## 指标类别
| 类别 | 示例 | 使用场景 |
|----------|----------|----------|
| **预训练文本质量** | 完整性、有效性、相似性、安全性 | LLM 预训练数据过滤 |
| **SFT 数据质量** | 诚实、有帮助、无害 (3H) | 指令微调数据 |
| **RAG 评估** | 忠实度、上下文精度、答案相关性 | RAG 系统评估 |
| **幻觉检测** | HHEM-2.1-Open、事实性检查 | 生产 AI 可靠性 |
| **分类** | 主题分类、内容标注 | 数据组织 |
| **多模态** | 图文相关性、VLM 质量、OCR 视觉评估 | 视觉语言数据 |
| **安全性** | PII 检测、Perspective API 毒性 | 隐私和安全 |
📊 **[查看完整指标文档 →](docs/metrics.md)**
📖 **[RAG 评估指南 →](docs/rag_evaluation_metrics_zh.md)**
🔍 **[幻觉检测指南 →](docs/hallucination_guide.md)**
✅ **[事实性评估指南 →](docs/factcheck_guide.md)**
👁️ **[VLM 渲染判断指南 →](docs/vlm_render_judge_guide.md)** | **[English](docs/en/vlm_render_judge_guide.md)**
大部分指标都有学术研究支持,以确保科学严谨性。
## 快速使用指标
```python
llm_config = {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
input_data = {
"evaluator": [
{
"fields": {"content": "content"},
"evals": [
{"name": "RuleAbnormalChar"}, # 基于规则(快速)
{"name": "LLMTextQualityV5", "config": llm_config} # 基于LLM(深度)
]
}
]
}
```
**自定义**:所有 prompts 都定义在 `dingo/model/llm/` 目录中(按类别组织:`text_quality/`、`rag/`、`hhh/` 等)。可针对特定领域需求进行扩展或修改。
---
# 🎓 实践者关键概念
## 让 Dingo 适用于生产环境的原因?
### 1. **多字段评估流水线**
在单次运行中对不同字段应用不同的质量检查:
```python
"evaluator": [
{"fields": {"content": "isbn"}, "evals": [{"name": "RuleIsbn"}]},
{"fields": {"content": "title"}, "evals": [{"name": "RuleAbnormalChar"}]},
{"fields": {"content": "description"}, "evals": [{"name": "LLMTextQualityV5"}]}
]
```
**为什么重要**:无需为每个字段编写单独的脚本即可评估结构化数据(如数据库表)。
### 2. **大数据集流式处理**
SQL 数据源使用 SQLAlchemy 的服务器端游标:
```python
# 处理数十亿行数据而不会内存溢出
for data in dataset.get_data(): # 每次yield一行
result = evaluator.eval(data)
```
**为什么重要**:无需导出到中间文件即可处理生产数据库。
### 3. **内存中的字段隔离**
RAG 评估防止不同字段组合之间的上下文泄漏:
```
outputs/
├── user_input,response,retrieved_contexts/ # Faithfulness 组
└── user_input,response/ # Answer Relevancy 组
```
**为什么重要**:评估多个字段组合时保证指标计算准确。
### 4. **混合规则-LLM 策略**
结合快速规则(100% 覆盖)和采样 LLM 检查(10% 覆盖):
```python
"evals": [
{"name": "RuleAbnormalChar"}, # 快速,在所有数据上运行
{"name": "LLMTextQualityV5"} # 昂贵,按需采样
]
```
**为什么重要**:平衡生产规模评估的成本和覆盖率。
### 5. **通过注册实现可扩展性**
清晰的插件架构用于自定义规则、prompt 和模型:
```python
@Model.rule_register('QUALITY_BAD_CUSTOM', ['default'])
class MyCustomRule(BaseRule):
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
# 示例:检查内容是否为空
if not input_data.content:
return EvalDetail(
metric=cls.__name__,
status=True, # 发现问题
label=[f'{cls.metric_type}.{cls.__name__}'],
reason=["内容为空"]
)
return EvalDetail(
metric=cls.__name__,
status=False, # 未发现问题
label=['QUALITY_GOOD']
)
```
**为什么重要**:适应特定领域需求而无需分叉代码库。
---
# 🌟 功能亮点
## 📊 多源数据集成
**多样化数据源** - 连接到你的数据所在之处
✅ **本地文件**:JSONL、CSV、TXT、Parquet
✅ **SQL 数据库**:PostgreSQL、MySQL、SQLite、Oracle、SQL Server(支持流式处理)
✅ **云存储**:S3 和 S3 兼容存储
✅ **ML 平台**:直接集成 HuggingFace 数据集
**企业级 SQL 支持** - 生产数据库集成
✅ 数十亿级数据集的内存高效流式处理
✅ 连接池和自动资源清理
✅ 复杂 SQL 查询(JOIN、WHERE、聚合)
✅ 通过 SQLAlchemy 支持多种方言
**多字段质量检查** - 不同字段使用不同规则
✅ 并行评估流水线(例如:ISBN 验证 + 文本质量同时进行)
✅ 字段别名和嵌套字段提取(`user.profile.name`)
✅ 每个字段独立结果报告
✅ 灵活数据转换的 ETL 流水线架构
---
## 🤖 RAG 系统评估
**5 个学术支持的指标** - 基于 RAGAS、DeepEval、TruLens 研究
✅ **忠实度(Faithfulness)**:答案-上下文一致性(幻觉检测)
✅ **答案相关性(Answer Relevancy)**:答案-查询对齐
✅ **上下文精度(Context Precision)**:检索精度
✅ **上下文召回(Context Recall)**:检索召回
✅ **上下文相关性(Context Relevancy)**:上下文-查询相关性
**全面报告** - 自动聚合统计
✅ 每个指标的平均值、最小值、最大值、标准差
✅ 按字段分组的结果
✅ 批量和单次评估模式
📖 **[查看 RAG 评估指南 →](docs/rag_evaluation_metrics_zh.md)**
---
## 🧠 混合评估系统
**基于规则** - 快速、确定性、成本效益高
✅ 30+ 内置规则(文本质量、格式、PII 检测)
✅ 正则表达式、启发式、统计检查
✅ 自定义规则注册
**基于 LLM** - 深度语义理解
✅ OpenAI(GPT-4o、GPT-3.5)、DeepSeek、Kimi
✅ 本地模型(Llama3、Qwen)
✅ 视觉语言模型(InternVL、Gemini)
✅ 自定义 prompt 注册
**基于智能体** - 多步推理与工具
✅ 网络搜索集成(Tavily)
✅ 自适应上下文收集
✅ 多源事实验证
✅ 自定义智能体与工具注册
**可扩展架构**
✅ 基于插件的规则/prompt/模型注册
✅ 清晰的关注点分离(agents、tools、orchestration)
✅ 特定领域定制
---
## 🚀 灵活执行与集成
**多种接口**
✅ CLI 用于快速检查
✅ Python SDK 用于集成
✅ MCP(模型上下文协议)服务器用于 IDE(Cursor 等)
**可扩展执行**
✅ 本地执行器用于快速迭代
✅ Spark 执行器用于分布式处理
✅ 可配置并发和批处理
**数据源**
✅ **本地文件**:JSONL、CSV、TXT、Parquet 格式
✅ **Hugging Face**:直接与 HF 数据集中心集成
✅ **S3 存储**:AWS S3 和 S3 兼容存储
✅ **SQL 数据库**:PostgreSQL、MySQL、SQLite、Oracle、SQL Server(大规模数据流式处理)
**模态**
✅ 文本(聊天、文档、代码)
✅ 图像(支持 VLM)
✅ 多模态(文本+图像一致性)
---
## 📈 丰富的报告和可视化
**多层级报告**
✅ 带有总体评分的 Summary JSON
✅ 字段级分解
✅ 每条规则违规的详细信息
✅ 类型和名称分布
**GUI 可视化(通过 [Dingo SaaS](https://github.com/MigoXLab/dingo-saas))**
✅ Web UI 交互式数据探索
✅ 可视化报告与趋势分析
✅ 异常追踪
**指标聚合**
✅ 自动统计(avg、min、max、std_dev)
✅ 按字段分组的指标
✅ 总体质量评分
---
# 📖 用户指南
## 自定义规则、Prompt 和模型
Dingo 提供灵活的扩展机制来满足特定领域需求。
**示例:**
- [自定义规则](examples/register/sdk_register_rule.py)
- [自定义模型](examples/register/sdk_register_llm.py)
### 自定义规则示例
```python
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.io import Data
from dingo.io.output.eval_detail import EvalDetail
@Model.rule_register('QUALITY_BAD_CUSTOM', ['default'])
class DomainSpecificRule(BaseRule):
"""检查特定领域的模式"""
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
text = input_data.content
# 你的自定义逻辑
is_valid = your_validation_logic(text)
return EvalDetail(
metric=cls.__name__,
status=not is_valid, # False = 良好, True = 有问题
label=['QUALITY_GOOD' if is_valid else 'QUALITY_BAD_CUSTOM'],
reason=["验证详情..."]
)
```
### 自定义LLM集成
```python
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# 自定义实现
pass
```
查看更多示例:
- [注册规则](examples/register/sdk_register_rule.py)
- [注册模型](examples/register/sdk_register_llm.py)
### 智能体评估与工具
Dingo 支持基于智能体的评估器,可以使用外部工具进行多步推理和自适应上下文收集。提供两种实现模式:
**模式 1:基于 LangChain**(如 `AgentFactCheck`)
- 框架驱动,自主多步推理
- 使用 LangChain 1.0 的 `create_agent` 和 ReAct 模式
- 适用于:复杂推理任务,快速原型开发
- 代码更少,更声明式
**模式 2:自定义工作流**(如 `AgentHallucination`)
- 开发者驱动,显式工作流控制
- 手动调用工具和 LLM
- 适用于:组合现有评估器,特定领域工作流
- 完全控制,显式行为
两种模式共享相同的配置接口,对用户透明。
**内置智能体:**
- `AgentFactCheck`: 基于 LangChain 的事实核查,自主搜索控制
- `AgentHallucination`: 自定义工作流的幻觉检测,自适应上下文收集
- `ArticleFactChecker`: 两阶段文章事实核查 —— 先提取可验证声明,再并发调用网络搜索与 Arxiv 逐条验证,支持可配置的并发控制
**快速示例:**
```python
from dingo.io import Data
from dingo.io.output.eval_detail import EvalDetail
from dingo.model import Model
from dingo.model.llm.agent.base_agent import BaseAgent
@Model.llm_register('MyAgent')
class MyAgent(BaseAgent):
"""支持工具的自定义智能体"""
available_tools = ["tavily_search", "my_custom_tool"]
max_iterations = 5
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
# 使用工具进行事实核查
search_result = cls.execute_tool('tavily_search', query=input_data.content)
# 使用LLM进行多步推理
result = cls.send_messages([...])
return EvalDetail(...)
```
有关选择和实现智能体模式的详细指导,请参阅[智能体开发指南](docs/agent_development_guide.md)。
**配置示例:**
```json
{
"evaluator": [{
"evals": [{
"name": "AgentHallucination",
"config": {
"key": "openai-api-key",
"model": "gpt-4",
"parameters": {
"agent_config": {
"max_iterations": 5,
"tools": {
"tavily_search": {"api_key": "tavily-key"}
}
}
}
}
}]
}]
}
```
**了解更多:**
- [智能体开发指南](docs/agent_development_guide.md)
- [AgentHallucination 示例](examples/agent/agent_hallucination_example.py)
- [AgentFactCheck LangChain示例](examples/agent/agent_executor_example.py)
- [ArticleFactChecker 示例](examples/agent/agent_article_fact_checking_example.py) - 文章级两阶段事实核查
## 执行引擎
### 本地执行
```python
from dingo.config import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# 获取结果
summary = executor.get_summary() # 整体评估摘要
bad_data = executor.get_bad_info_list() # 有问题数据列表
good_data = executor.get_good_info_list() # 高质量数据列表
```
### Spark执行
```python
from dingo.config import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# 初始化Spark
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # 以Data对象形式的数据
input_data = {
"executor": {
"result_save": {"bad": True}
},
"evaluator": [
{
"fields": {"content": "content"},
"evals": [
{"name": "RuleColonEnd"},
{"name": "RuleSpecialCharacter"}
]
}
]
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()
```
## 评估报告
评估后,Dingo生成:
1. **概要报告**(`summary.json`):总体指标和分数
2. **详细报告**:每个规则违反的具体问题
报告说明:
1. **score**: `num_good` / `total`
2. **type_ratio**: 类型的数量 / 总数, 例如: `QUALITY_BAD_COMPLETENESS` / `total`
概要示例:
```json
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"content": {
"QUALITY_BAD_COMPLETENESS.RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE.RuleSpecialCharacter": 0.5
}
}
}
```
# 🔮 未来计划
**即将推出的功能**:
- [ ] **Agent-as-a-Judge** - 多轮迭代评估
- [ ] **SaaS 平台** - 托管评估服务,提供 API 访问和仪表板
- [ ] **音频和视频模态** - 扩展到文本/图像之外
- [ ] **多样性指标** - 统计多样性评估
- [ ] **实时监控** - 生产流水线中的持续质量检查
## 局限性
当前内置的检测规则和模型方法主要关注常见的数据质量问题。对于特殊评估需求,我们建议定制化检测规则。
# 致谢
- [RedPajama-Data](https://github.com/togethercomputer/RedPajama-Data)
- [mlflow](https://github.com/mlflow/mlflow)
- [deepeval](https://github.com/confident-ai/deepeval)
- [ragas](https://github.com/explodinggradients/ragas)
# 贡献
我们感谢所有的贡献者为改进和提升 `Dingo` 所作出的努力。请参考[贡献指南](docs/en/CONTRIBUTING.md)来了解参与项目贡献的相关指引。
# 开源许可证
该项目采用 [Apache 2.0 开源许可证](LICENSE)。
本项目部分功能使用fasttext进行语言检测功能。fasttext采用MIT许可证,与我们的Apache 2.0许可证兼容,为各种使用场景提供了灵活性。
# Citation
If you find this project useful, please consider citing our tool:
```
@misc{dingo,
title={Dingo: A Comprehensive AI Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/MigoXLab/dingo}},
year={2024}
}
```





