 |
|
Методы OpenCV - алгоритм кластеризации k-means
k-means (метод k-средних) — метод кластеризации, стремящийся минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров.
Кластеризация — задача машинного обучения, состоящая в разбиении заданной выборки объектов (данных) на непересекающиеся подмножества/группы (кластеры) на основе близости их признаков/значений. Т.о., каждый кластер состоит из схожих объектов.
Кластеризация позволяет:
* лучше понять данные (выявив структурные группы),
* компактное хранение данных,
* выявление новых объектов.
В , алгоритм k-means реализован в cxcore, т.к. он был реализован задолго до появления библиотеки ML.
K-means пытается найти кластеры в наборе данных.
Это реализуется функцией cvKMeans2().
Алгоритм работы k-means:
1. Принимает входные данные и желаемое число кластеров
2. Случайным образом выбирает центры кластеров
3. Ассоциирует каждую точку данных с ближайшим центром кластера
4. Перемещает центр кластера в центроид его точек данных.
5. Возвращается на шаг 3 пока не достигнута сходимость (центр кластера не двигается)
Проблемы алгоритма k-means:
1. не гарантирует определения лучшего из возможных расположений центров кластеров (достижение глобального минимума суммарного квадратичного отклонения). Однако, гарантирует сходимость к какому-либо решению, т.е. итерации не зациклятся в бесконечном цикле.
2. не определяет сколько кластеров стоит использовать (т.е. число кластеров надо знать заранее)
3. результат зависит от выбора исходных центров кластеров
4. K-means предполагает, что пространственная ковариационная составляющая, либо не имеет значения, либо уже была отнормирована.
CVAPI(int) cvKMeans2( const CvArr* samples, int cluster_count, CvArr* labels,
CvTermCriteria termcrit, int attempts CV_DEFAULT(1),
CvRNG* rng CV_DEFAULT(0), int flags CV_DEFAULT(0),
CvArr* _centers CV_DEFAULT(0), double* compactness CV_DEFAULT(0) );samples — матрица примеров (float) — одна строчка — один вектор
cluster_count — число кластеров
labels — возвращаемый вектор (int), хранящий индекс кластера каждого вектора
termcrit — критерий завершения итераций
attempts — число попыток достижения лучшей компактности
rng — внешний ГСЧ
flags — флаг — 0 или:
#define CV_KMEANS_USE_INITIAL_LABELS 1 // для первой попытки будет использовать предуставновленное значение вектора labels (далее - будет использоваться ГСЧ)_centers — возвращаемый массив центров кластеров
compactness — компактность — возвращаемый параметр, который высчитывается по формуле:
Summ( || samples(i) - centers(labels(i)) ||^2 )— высчитывается после каждой попытки и лучшее (минимальное) значение выбирается и соответствующие labels возвращаются
//
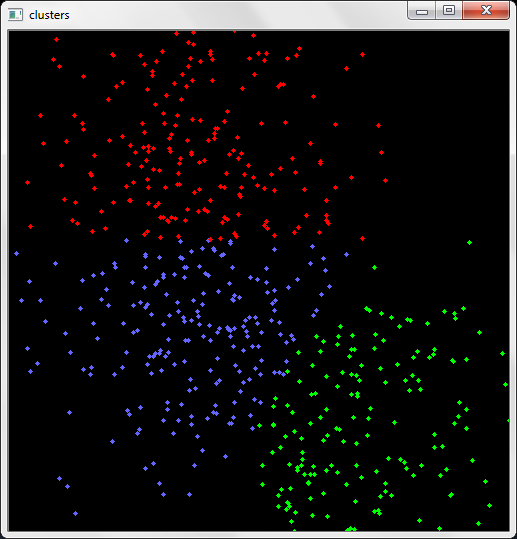
// Несколько модифицированный пример Example 13-1.
// Использование K-means
//
// из книги:
// Learning OpenCV: Computer Vision with the OpenCV Library
// by Gary Bradski and Adrian Kaehler
// Published by O'Reilly Media, October 3, 2008
#include "cxcore.h"
#include "highgui.h"
#define MAX_CLUSTERS 5
int main( int argc, char* argv[] )
{
// изображение для показа точек
IplImage* img = cvCreateImage( cvSize( 500, 500 ), 8, 3 );
// таблица цветов кластеров
CvScalar color_tab[MAX_CLUSTERS];
color_tab[0] = CV_RGB(255,0,0);
color_tab[1] = CV_RGB(0,255,0);
color_tab[2] = CV_RGB(100,100,255);
color_tab[3] = CV_RGB(255,0,255);
color_tab[4] = CV_RGB(255,255,0);
// инициализация состояния ГПСЧ
CvRNG rng = cvRNG(0xffffffff);
cvNamedWindow( "clusters", 1 );
for(;;){
int k, cluster_count = cvRandInt(&rng)%MAX_CLUSTERS + 1;
int i, sample_count = cvRandInt(&rng)%1000 + 1;
CvMat* points = cvCreateMat( sample_count, 1, CV_32FC2 );
CvMat* clusters = cvCreateMat( sample_count, 1, CV_32SC1 );
// генерация случайного гауссового распределения точек
for( k = 0; k < cluster_count; k++ ){
CvPoint center;
CvMat point_chunk;
center.x = cvRandInt(&rng)%img->width;
center.y = cvRandInt(&rng)%img->height;
cvGetRows( points, &point_chunk,
k*sample_count/cluster_count,
k == cluster_count - 1 ? sample_count :
(k+1)*sample_count/cluster_count );
cvRandArr( &rng, &point_chunk, CV_RAND_NORMAL,
cvScalar(center.x,center.y,0,0),
cvScalar(img->width/6, img->height/6,0,0) );
}
// точки перемешиваются
for( i = 0; i < sample_count/2; i++ ){
CvPoint2D32f* pt1 = (CvPoint2D32f*)points->data.fl +
cvRandInt(&rng)%sample_count;
CvPoint2D32f* pt2 = (CvPoint2D32f*)points->data.fl +
cvRandInt(&rng)%sample_count;
CvPoint2D32f temp;
CV_SWAP( *pt1, *pt2, temp );
}
// определение кластеров
cvKMeans2( points, cluster_count, clusters,
cvTermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER,
10, 1.0 ));
cvZero( img );
// показываем точки
for( i = 0; i < sample_count; i++ ){
CvPoint2D32f pt = ((CvPoint2D32f*)points->data.fl)[i];
// индекс кластера
int cluster_idx = clusters->data.i[i];
cvCircle( img, cvPointFrom32f(pt), 2, color_tab[cluster_idx], CV_FILLED );
}
cvReleaseMat( &points );
cvReleaseMat( &clusters );
// показываем
cvShowImage( "clusters", img );
int key = cvWaitKey(330);
if( key == 27 ){ // 'ESC'
break;
}
}
// освобождаем ресурсы
cvReleaseImage(&img);
// удаляем окна
cvDestroyAllWindows();
return 0;
} 
CVAPI(CvMat*) cvGetRows( const CvArr* arr, CvMat* submat,
int start_row, int end_row,
int delta_row CV_DEFAULT(1));
CV_INLINE CvMat* cvGetRow( const CvArr* arr, CvMat* submat, int row )
{
return cvGetRows( arr, submat, row, row + 1, 1 );
}— возвращает массив строк
arr — исходный массив
submat — указатель возвращаемый заголовок массива
start_row — индекс (от 0) начальной строки
end_row — индекс последней строки (не включая)
delta_row — индекс шага (т.е. выбирается каждая delta_row-ая строка между [start_row:end_row) )
CVAPI(CvMat*) cvGetCols( const CvArr* arr, CvMat* submat,
int start_col, int end_col );
CV_INLINE CvMat* cvGetCol( const CvArr* arr, CvMat* submat, int col )
{
return cvGetCols( arr, submat, col, col + 1 );
}arr — исходный массив
submat — указатель возвращаемый заголовок массива
start_col — индекс (от 0) начального столбца
end_col — индекс последнего столбца (не включая)
//
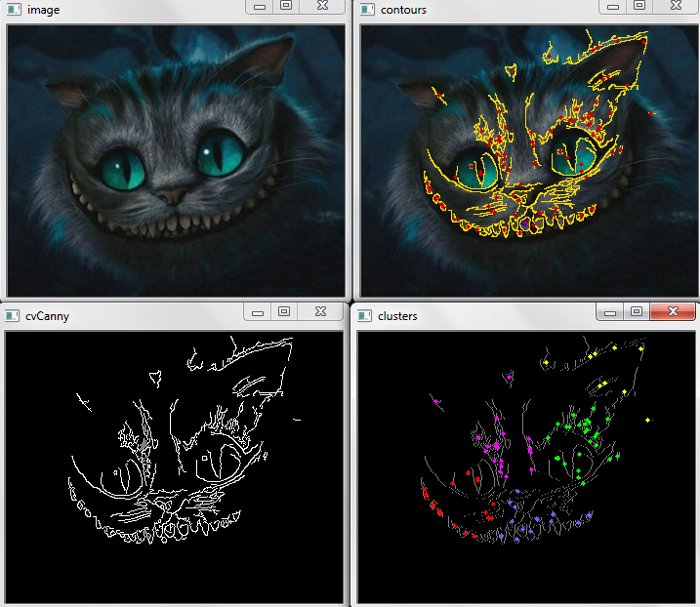
// K-means для центров масс контуров изображения
//
#include <cv.h>
#include <highgui.h>
#define MAX_CLUSTERS 5
int main( int argc, char* argv[] )
{
// для хранения изображения
IplImage* image=0, *gray=0, *bin=0, *dst=0;
//
// загрузка изображения
//
char img_name[] = "Image0.jpg";
// имя картинки задаётся первым параметром
char* image_filename = argc >= 2 ? argv[1] : img_name;
// получаем картинку
image = cvLoadImage(image_filename, 1);
printf("[i] image: %s\n", image_filename);
if(!image){
printf("[!] Error: cant load test image: %s\n", image_filename);
return -1;
}
// показываем картинку
cvNamedWindow("image");
cvShowImage("image", image);
// создание изображений
dst = cvCloneImage(image);
gray = cvCreateImage( cvGetSize(image), IPL_DEPTH_8U, 1);
bin = cvCreateImage( cvGetSize(image), IPL_DEPTH_8U, 1);
cvConvertImage(image, gray, CV_BGR2GRAY);
cvCanny(gray, bin, 50, 200, 3);
cvNamedWindow("cvCanny");
cvShowImage("cvCanny", bin);
// для хранения контуров
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* contours=0, *seq=0;
// находим контуры
int contoursCont = cvFindContours( bin, storage, &contours, sizeof(CvContour), CV_RETR_LIST, CV_CHAIN_APPROX_SIMPLE, cvPoint(0,0));
if(!contours){
printf("[!] Error: cant find contours!\n");
return -2;
}
printf("[i] contours: %d \n", contoursCont);
// нарисуем контуры
for(seq = contours; seq!=0; seq = seq->h_next){
cvDrawContours(image, seq, CV_RGB(255,216,0), CV_RGB(0,0,250), 0, 1, 4); // рисуем контур
}
cvNamedWindow("contours");
cvShowImage("contours", image);
cvConvertImage(bin, dst, CV_GRAY2BGR);
//
// таблица цветов кластеров
//
CvScalar color_tab[MAX_CLUSTERS];
color_tab[0] = CV_RGB(255,0,0);
color_tab[1] = CV_RGB(0,255,0);
color_tab[2] = CV_RGB(100,100,255);
color_tab[3] = CV_RGB(255,0,255);
color_tab[4] = CV_RGB(255,255,0);
cvNamedWindow("clusters");
{
int cluster_count = MAX_CLUSTERS;
int sample_count = contoursCont;
int i, j, k;
CvMat* points = cvCreateMat( sample_count, 1, CV_32FC2 );
CvMat* clusters = cvCreateMat( sample_count, 1, CV_32SC1 );
// определяем точки контуров
for(k=0, seq = contours; seq!=0; seq = seq->h_next, k++){
CvPoint2D32f center = cvPoint2D32f(0, 0);
#if 0
float radius=0;
// определяем окружность заключающую в себе контур
cvMinEnclosingCircle(seq, ¢er, &radius);
#else
// находим центр масс
int count=0;
for(i=0; i<seq->total; ++i ) {
CvPoint* p = CV_GET_SEQ_ELEM( CvPoint, seq, i );
center.x+=p->x;
center.y+=p->y;
count++;
}
center.x=center.x/count;
center.y=center.y/count;
#endif
// отметим точку
cvCircle( image, cvPointFrom32f(center), 2, CV_RGB(200,0,0), CV_FILLED );
// запихиваем в массив
cvSet1D( points, k, cvScalar(center.x, center.y, 0) );
}
cvShowImage("contours", image);
// определение кластеров
cvKMeans2( points, cluster_count, clusters,
cvTermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 10, 1.0 ));
// показываем точки
for( i = 0; i < sample_count; i++ ){
CvPoint2D32f pt = ((CvPoint2D32f*)points->data.fl)[i];
// индекс кластера
int cluster_idx = clusters->data.i[i];
cvCircle( dst, cvPointFrom32f(pt), 2, color_tab[cluster_idx], CV_FILLED );
}
cvReleaseMat( &points );
cvReleaseMat( &clusters );
// показываем
cvShowImage( "clusters", dst );
int key = cvWaitKey(0);
//if( key == 27 ){ // ESC
// break;
//}
}
//
// освобождаем ресурсы
//
cvReleaseImage(&image);
cvReleaseImage(&gray);
cvReleaseImage(&bin);
cvReleaseImage(&dst);
cvReleaseMemStorage(&storage);
// удаляем окна
cvDestroyAllWindows();
return 0;
}
Ссылки
По теме


Материалы сайта являются авторскими. Копирование и публикация материалов без разрешения запрещены!
Комментарии (0)
RSS свернуть / развернутьТолько зарегистрированные и авторизованные пользователи могут оставлять комментарии.