
Sessions, files, and Product Stashes for agent work.
Stash is a workspace for coding-agent sessions, pages, and publishable Product Stashes.
It captures every coding-agent run across your team and makes
the important work easy to search, organize, and share.






When we tested this internally, we found that it sped up long-running instances of Claude Code by 49%.
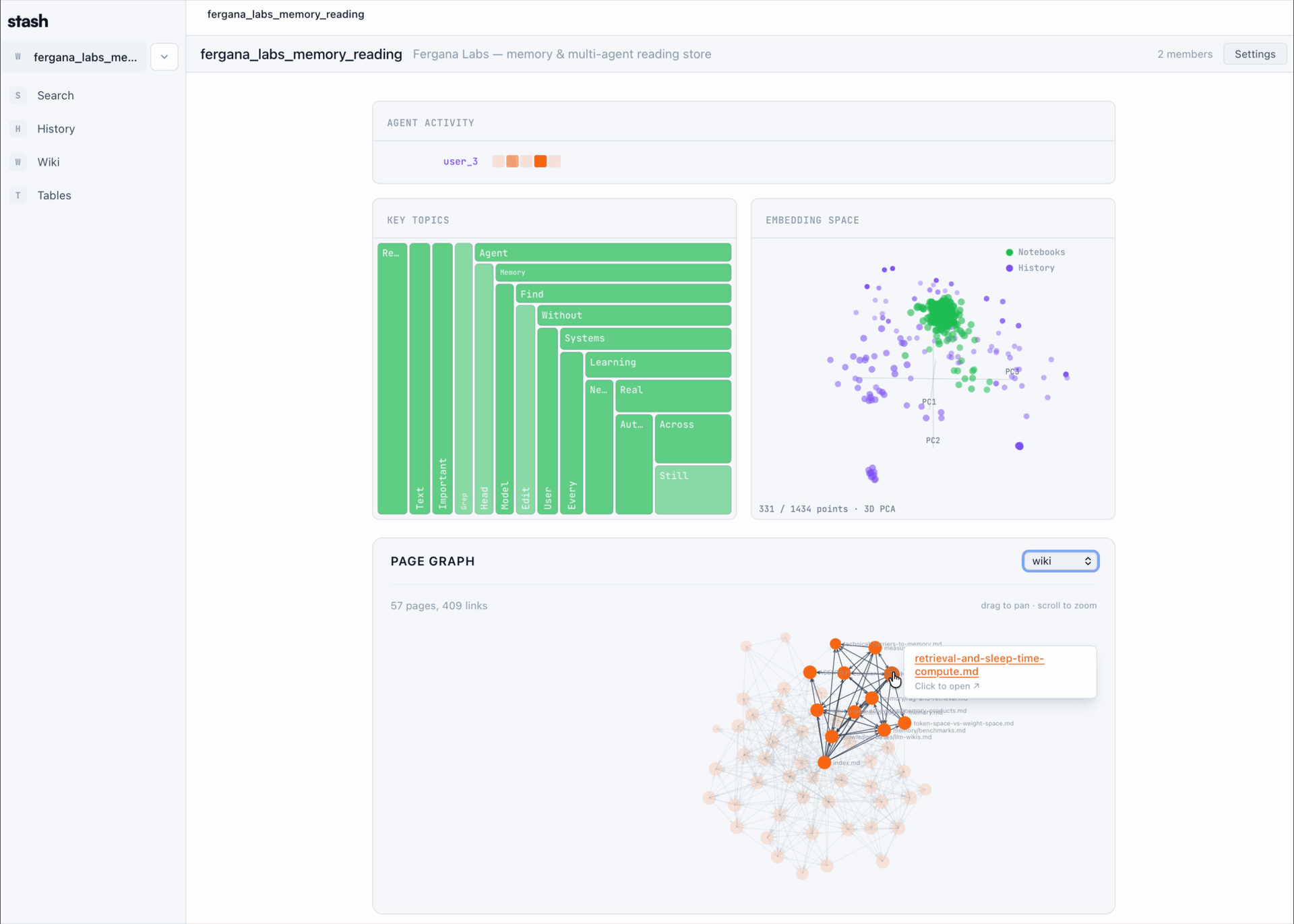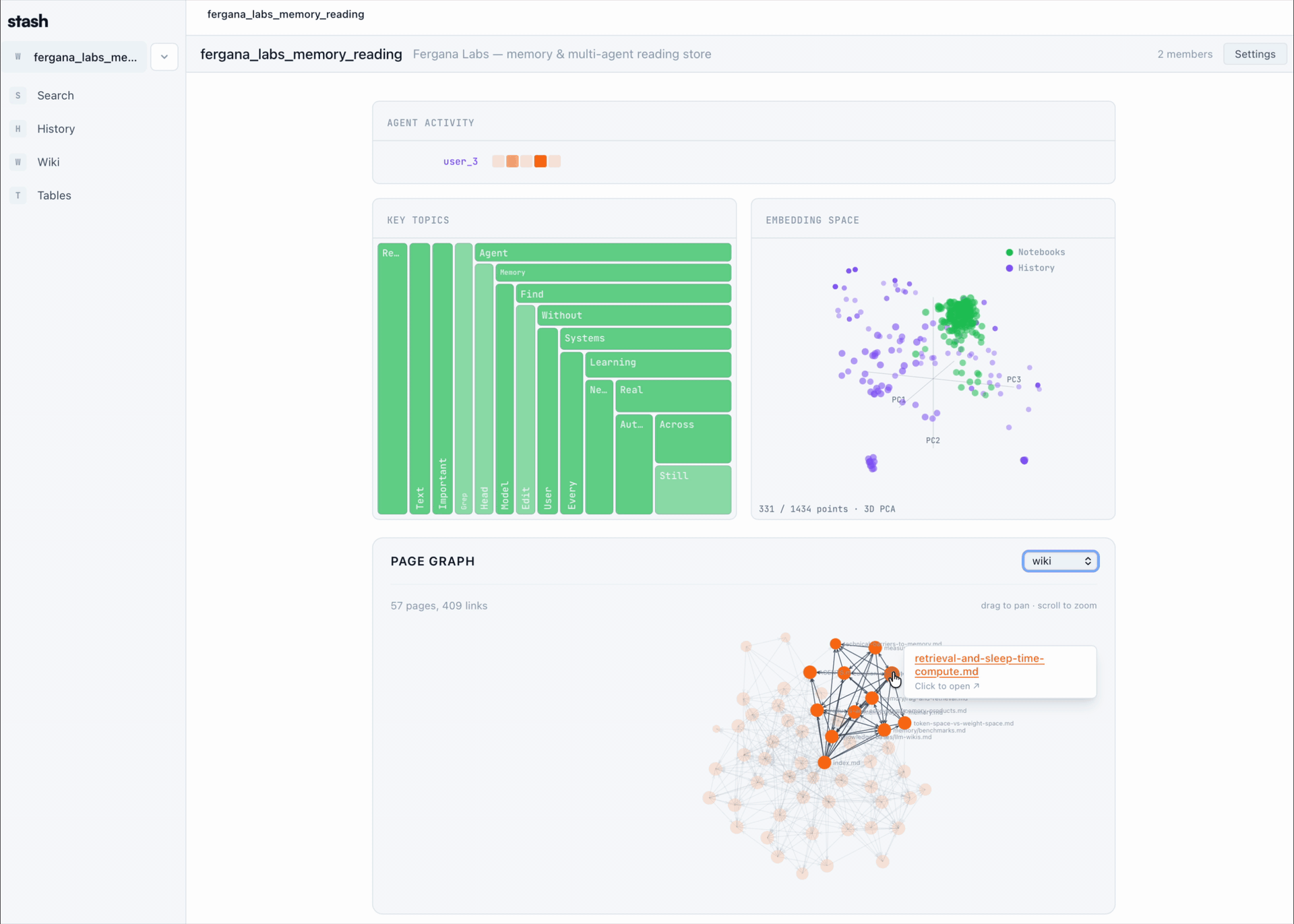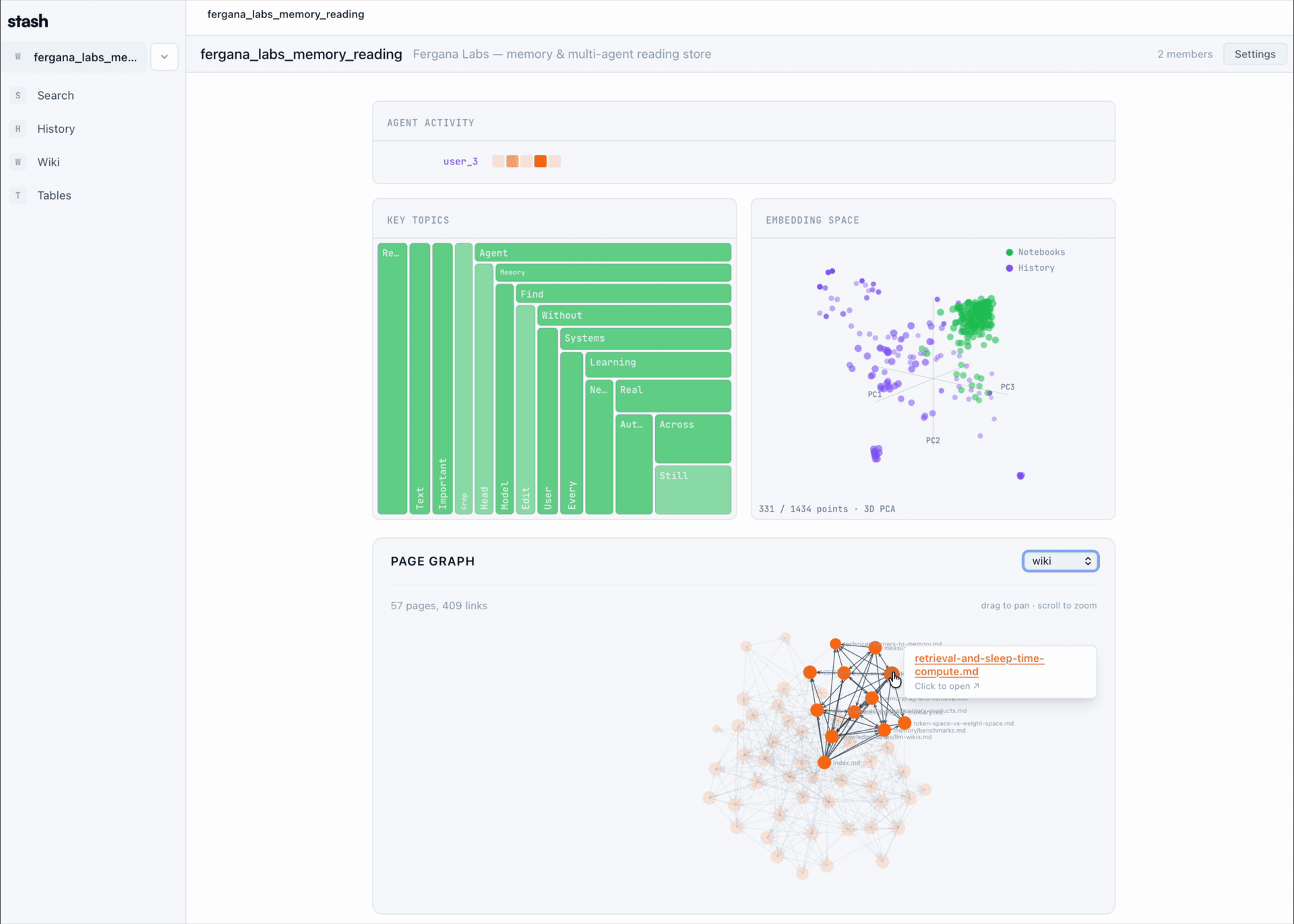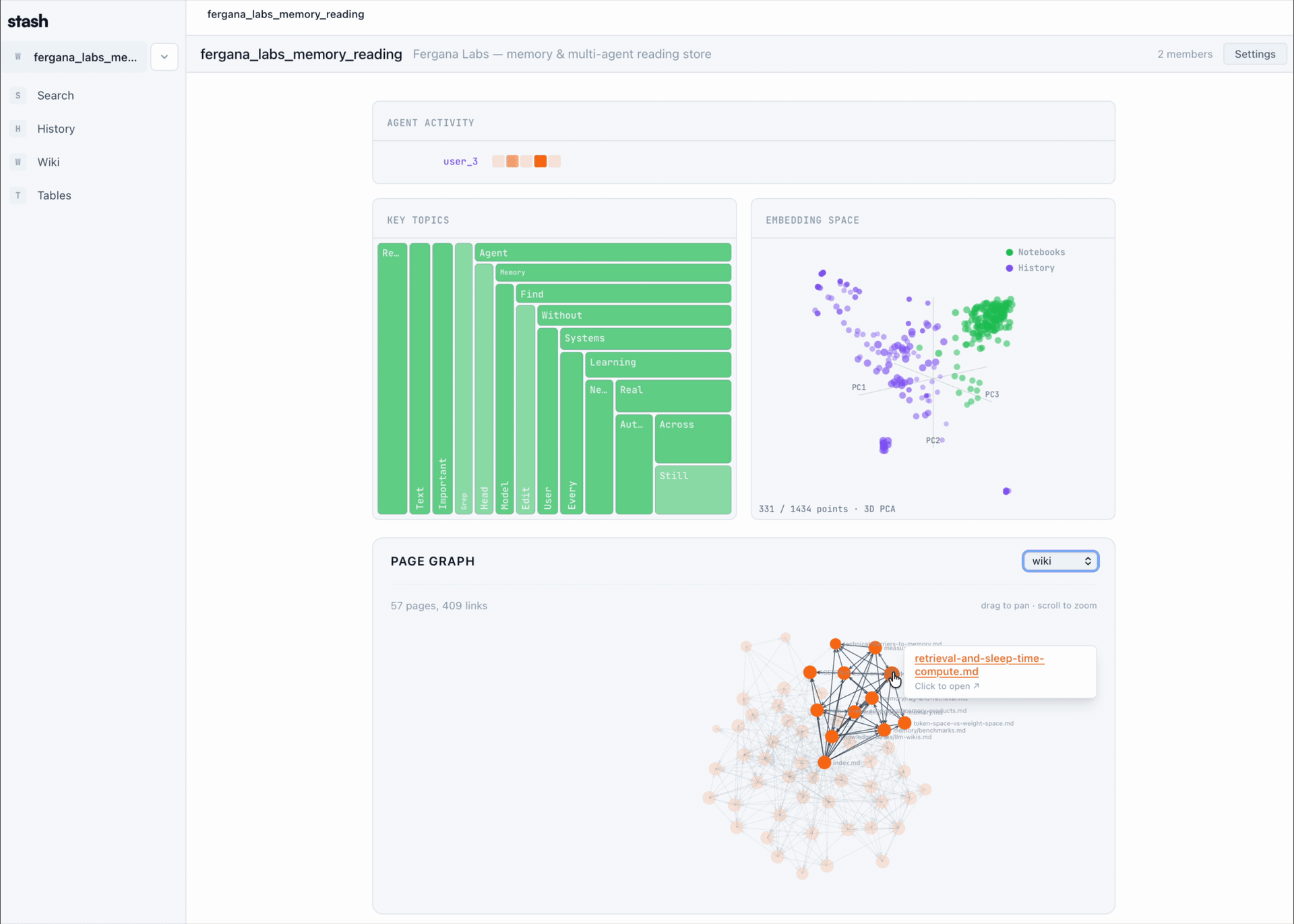

## How it works
- Stash installs a hook for your coding agents that automatically uploads session transcripts to a shared store.
- It exposes a CLI, MCP server, and app-level virtual filesystem shell that let humans and agents query sessions, browse Stash with bash-shaped commands, write pages, and create Product Stashes.
- Product Stashes bundle pages and sessions into shareable links. You can publish them publicly, list them in Discover, or fork external Stashes into your workspace.
## Why shared beats individual
When five engineers run Claude on the same repo, they generate valuable session transcripts. However, their coding agent can only access transcripts generated on the machine where the agent is currently running. As a result, engineering effort is duplicated and eng velocity is decreased. This is especially true as coding agents begin to run autonomously for significant periods of time.
With Stash, every agent on the repo has context about every session created from that repo. Here are some use cases:
- **Code Faster / Don't Duplicate Work**: "Has anyone else tried fixing the memory leak in our API gateway? What was attempted?"
- **Look Organized During Standup**: "What did I get done this week? What other work did I do that isn't tracked in Git?"
- **Don't Be Blocked on Collaborators**: "Why did Sam increase the timeout to 30s? The git history is unhelpful."
- **Align With Your Team Faster**: "Please add a feedback endpoint to our API" -> Claude: "FYI, Sam decided not to add a feedback endpoint since we want to encourage churned users to hop on a call directly"
> "raw data from a given number of sources is collected, then compiled by an LLM into a .md knowledge base, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance it… **I think there is room here for an incredible new product instead of a hacky collection of scripts.**"
>
> — Andrej Karpathy, *LLM Knowledge Bases*
**Stash is that product. For teams of coding agents working on the same repo.** Your agents' streamed sessions are the raw data. Files is where humans and agents write durable pages. Product Stashes are the publishable bundles you share with collaborators or add back into a workspace. AI usage becomes a shared, searchable asset, not individual effort.
## Quick Start
```bash
pip install stashai
stash connect
```
`stash connect` walks you through account creation, picks a workspace, and
wires up coding-agent plugins. That's it.
Prefer a one-liner?
```bash
bash -c "$(curl -fsSL https://raw.githubusercontent.com/Fergana-Labs/stash/main/install.sh)"
```
The installer just runs `uv tool install stashai` and then `stash connect`.
Use this when you don't already have a Python toolchain on your machine.
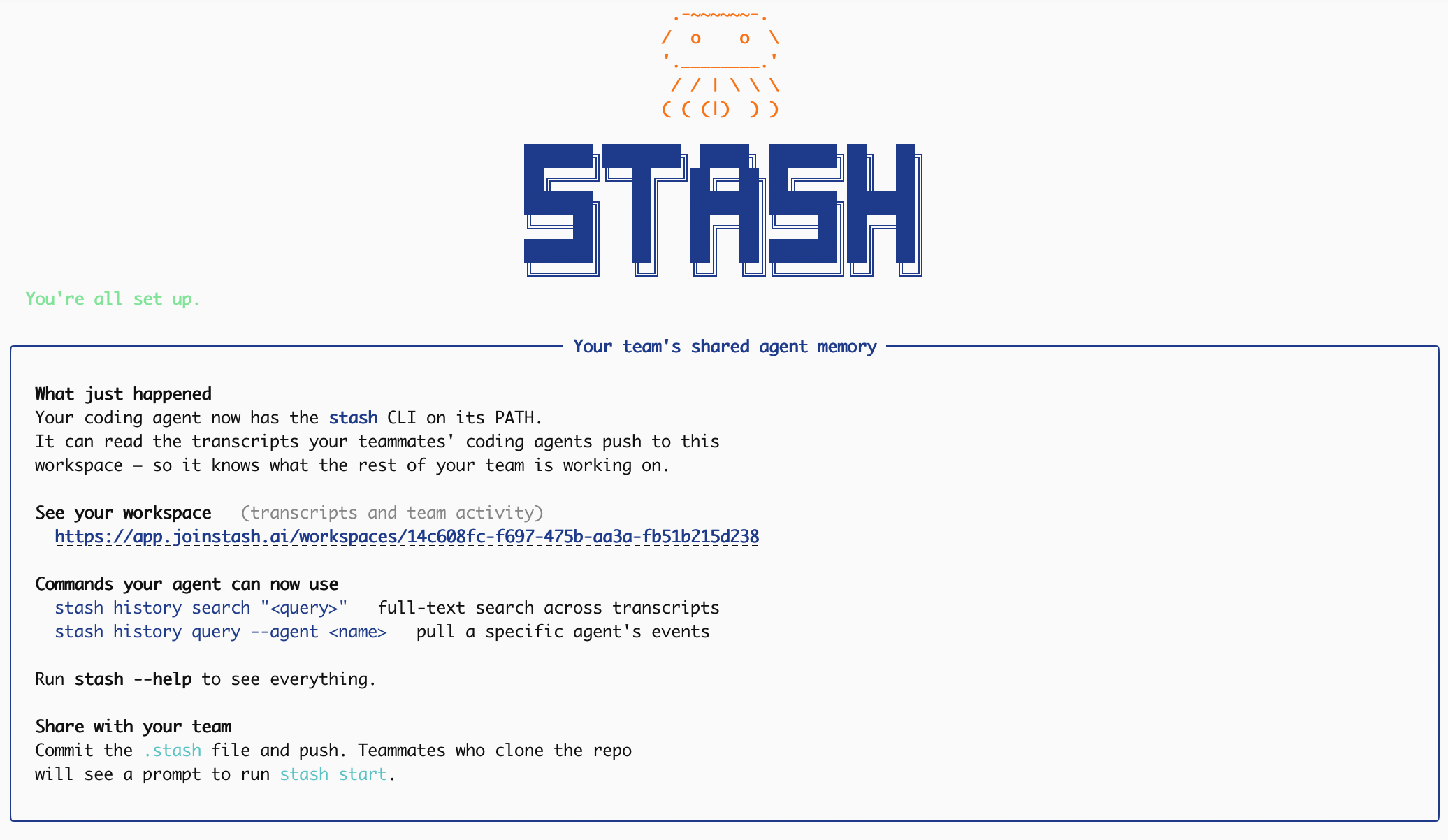
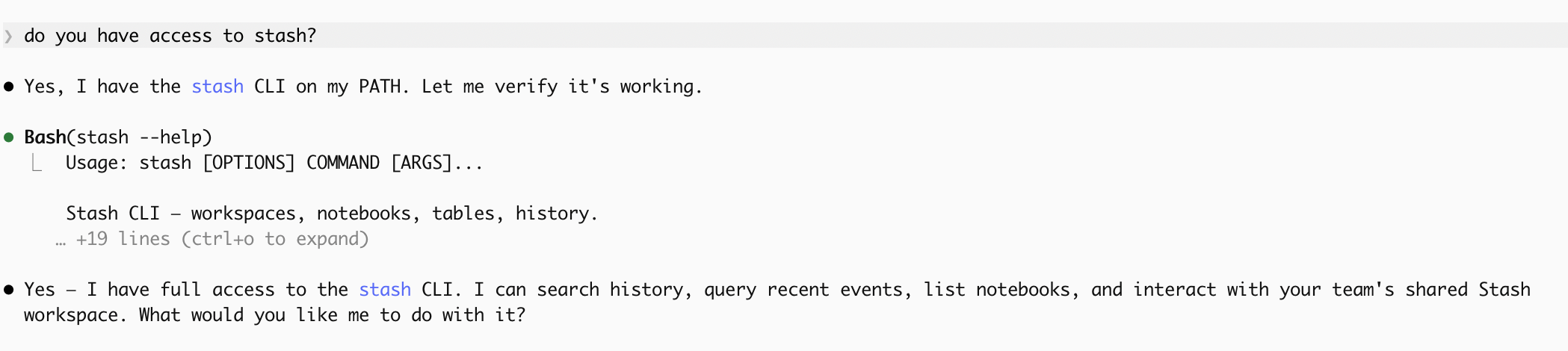
Then try it: ask your coding agent if it has access to Stash.
Agents can browse Stash with an app-level virtual filesystem shell:
```bash
stash vfs ls /
stash vfs "tree /workspaces -L 2"
stash vfs "find /workspaces -maxdepth 3 -type f | head -n 20"
stash vfs "rg \"database migration\" /workspaces"
```
## Integrations
Stash supports the following coding agents:
- **Claude Code**
- **Cursor**
- **Codex**
- **OpenCode**
- **Gemini CLI**
- **Openclaw**
Stash supports opt in per-coding agent. Mix and match — different teammates can use different agents against the same shared brain.
## CLI Reference
See [here](https://www.joinstash.ai/docs/cli) for a CLI reference.
## Self-Hosted
To self host, just run docker compose on infrastructure of your choice.
```bash
git clone https://github.com/Fergana-Labs/stash.git
cd stash
cp .env.example .env # fill in credentials + API keys
# edit Caddyfile → replace app.example.com with your domain
docker compose -f docker-compose.prod.yml up -d
```
Set `EMBEDDING_PROVIDER` to use a third-party embedding provider (otherwise we'll just use local `sentence-transformers`). Set `S3_ENDPOINT`, `S3_BUCKET`, and `S3_ACCESS_KEY` to use S3-compatible object storage (R2, S3, MinIO) for file uploads.
> Local development? Use `docker compose up -d` (no `-f` flag) — simple setup with hardcoded dev credentials.
### Local seed data
Once PostgreSQL is running, populate a realistic local dataset for UI smoke testing:
```bash
python scripts/seed_dev_data.py
```
The seeder creates demo users, one shared workspace, folders/pages, sessions, tables, stashes, and
sample table/file-collection data when S3 storage is configured. If `S3_*` is not set, file rows are
skipped with a warning.
## Privacy
Stash is built for engineering teams working in private repos.
- **No LLM calls from the server.** Search runs inside your agent (Claude Code, Cursor, etc.) using the keys it already has. The Stash backend itself makes no model calls.
- **Permissioned workspaces.** Only invited members can access a workspace. Public visibility is controlled by Product Stashes.
- **Transcripts are opt-in.** If you don't want to share your agent trasncripts, you can give your agent shared *read* access to the workspace's memory without uploading any of your own session data.
## FAQ
**What LLMs does Stash use?**
None on the server. Agents can use the CLI and MCP server to search sessions, write pages, and create Product Stashes, but there is no background page-writing agent in v0.
**Can I use this without Claude Code?**
Yes. You can use the CLI with anything, and Stash has native plugins for Cursor, Codex, Opencode, Gemini CLI, and more.
## Contributing
Contributions are welcome. See [CONTRIBUTING.md](CONTRIBUTING.md) to get started.
Found a bug? [Open an issue](https://github.com/Fergana-Labs/stash/issues).
## License
[MIT](LICENSE) — Copyright (c) 2026 Fergana Labs
---
Built by Fergana Labs.