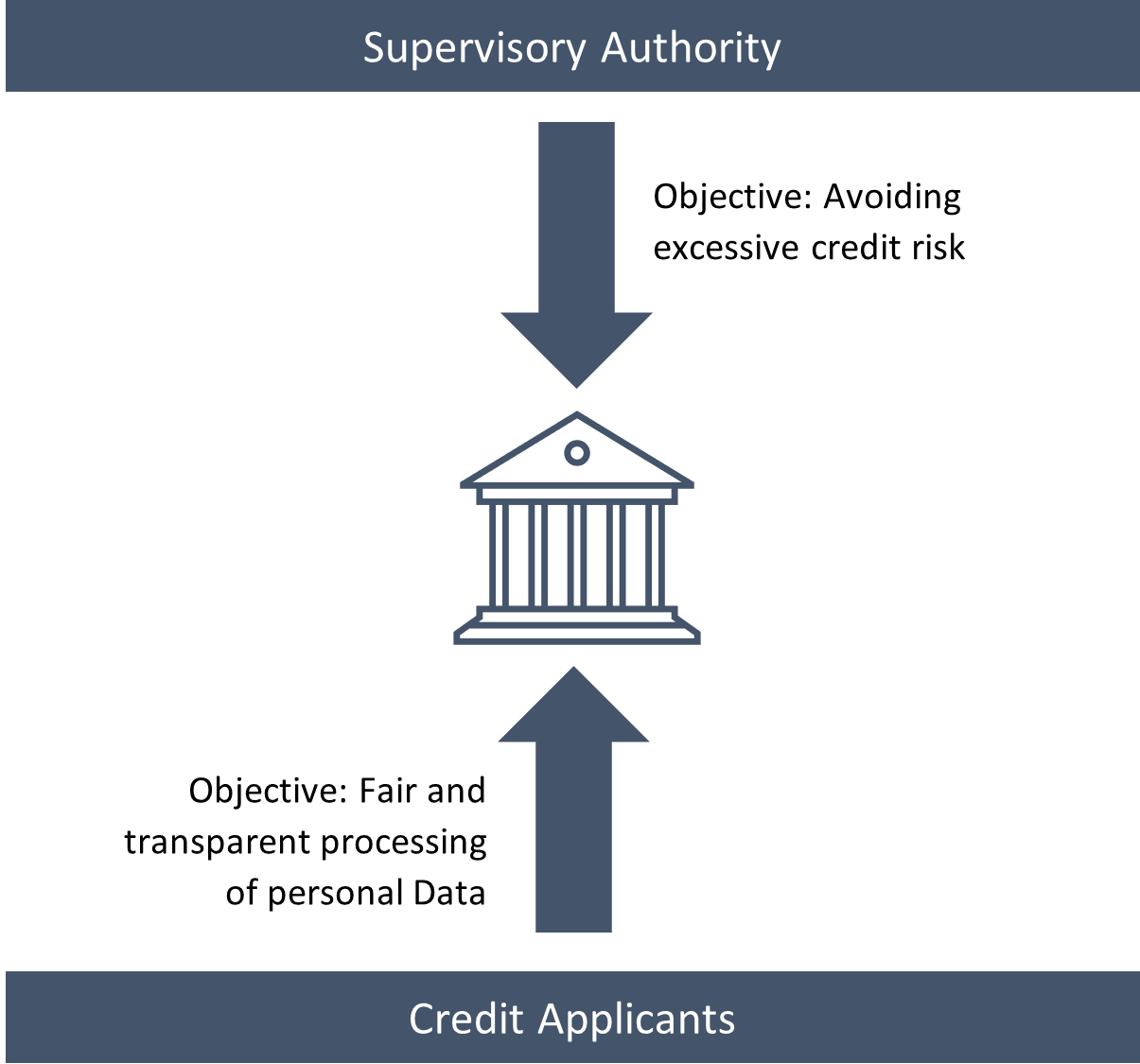
Image 1: A Bank's Primary Stakeholders; own illustration.
Group Members:
Submitted on July 22, 2022.
# install required packages
!pip install lime --quiet
!pip install alibi --quiet
!pip install shap --quiet
!pip install lime-stability --quiet
!pip install xgboost --quiet
!pip install --upgrade xgboost
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/ Requirement already satisfied: xgboost in /usr/local/lib/python3.7/dist-packages (1.6.1) Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from xgboost) (1.21.6) Requirement already satisfied: scipy in /usr/local/lib/python3.7/dist-packages (from xgboost) (1.7.3)
# required packages
# at the beginning we make sure to consider all necessary packages
## Standard packages
import pandas as pd
import numpy as np
import sklearn
import os
import matplotlib.pyplot as plt
import time
## Feature Engineering
import datetime # Transform date features
import seaborn as sns # corelation matrix
from sklearn.preprocessing import StandardScaler # Scaling Data
## Used Models
### Logit
from sklearn.linear_model import LogisticRegression
### xgboost
import xgboost as xgb
## Validation of model
from sklearn import metrics
from sklearn.metrics import accuracy_score, f1_score,confusion_matrix
from sklearn.model_selection import train_test_split
## Interpretability methods
### SHAP
import shap
### LIME
import lime
from lime.lime_tabular import LimeTabularExplainer
from lime_stability.stability import LimeTabularExplainerOvr
from lime_stability.utils import LocalModelError
### ANCHORS
from alibi.explainers import AnchorTabular
The widespread use of computational algorithms in various industries in the recent decade confirms a transformation of business processes towards a more computation-driven approach (Visani et al. 2022). Simple methods, the most famous being Linear Regression and Generalized Linear Models (William H. Greene 2003), have been followed by the advent of powerful computing tools, leading to the development of more sophisticated machine learning techniques. In particular, machine learning models can perform intelligent tasks usually done by humans. In combination with the huge availability of data sources and increased computational power, machine learning techniques have reduced the time to achieve more accurate results. Despite these advantages, machine learning models display weaknesses especially when it comes to interpretability, i.e., “the ability to explain or to present the results, in understandable terms, to a human” (Hall and Gill 2019). This issue is mainly caused by large model structures and huge numbers of iterations involved in machine learning algorithms combined with potentially many mathematical calculations, hiding the logic underlying these models and making them hard to grasp for humans. Consequently, a substantial amount of techniques have been proposed in the recent literature to make these models with an increased complexity more understandable for humans (Visani et al. 2022). Considering the importance of interpretability with a local focus i.e. trying to explain a single prediction, this paper investigates various aspects of interpretability and the challenges involved in implementing the corresponding methods within the credit risk industry. In particular, three different techniques are employed: LIME (Local Interpretable Model Agnostic Explanations), SHAP (Shapley Additive exPlanations), and the less common approach Anchor.
Article 8 of the European Union’s (EU) Charter of Fundamental Rights of the European Union stipulates the right of "Protection of personal data" (European Union 2012). Building on this fundamental right, the EU passed Regulation (EU) 2016/679, better known as General Data Protection Regulation (GDPR), in 2016. The regulation, which has been legally binding since 2018, aims to "strengthen individuals' fundamental rights in the digital age”. At the same time, according to the regulation, model performance should not be the sole criterion for the suitability of a machine learning. (European Commission 2022) Recital 71 expands on this point and specifically states that the "data subject [author's note: respective individual] should have the right not to be subject to a decision, which may include a measure, evaluating personal aspects relating to him or her which is based solely on automated processing and which produces legal effects concerning him or her or similarly significantly affects him or her, such as automatic refusal of an online credit application or e-recruiting practices without any human intervention. [...] In any case, such processing should be subject to suitable safeguards, which should include specific information to the data subject and the right to obtain human intervention, to express his or her point of view, to obtain an explanation of the decision reached after such assessment and to challenge the decision." (European Parliament and the Council 2016) Article 22 manifests the right to "not to be subject to a decision based solely on automated processing [...] [and] at least the right to obtain human intervention on the part of the controller, to express his or her point of view and to contest the decision." (European Parliament and the Council 2016) In addition, article 14 requires that the individual is provided with "meaningful information about the logic involved, as well as the significance" in order to "ensure fair and transparent processing" of personal data. (European Parliament and the Council 2016) This contradicts the approach of many common supervised machine learning algorithms, which rely purely on statistical associations rather than causalities or explanatory rules to produce out-of-sample predictions (Goodman and Flaxman 2017).
Similarly, the Consumer Financial Protection Bureau (2022) clarified that the rights set out in the Equal Credit Opportunity Act (Regulation B) also apply to decisions based on “complex algorithms”. The Equal Credit Opportunity Act (Regulation B) prohibits adverse actions such as the denial of a credit application on the basis of discriminatory behavior and grants credit applicants against which an adverse action has been taken the right to obtain a statement rationalizing this adverse decision.(Bureau of Consumer Financial Protection 2011) The Consumer Financial Protection Bureau (2022) unequivocally formulates that the law does "not permit creditors to use complex algorithms when doing so means they cannot provide the specific and accurate reasons for adverse actions.” (Consumer Financial Protection Bureau 2022) The development of interpretable algorithms is therefore not only desirable but a legal necessity.
It is evident that a bank's objective is to maximize its franchise value. The minimization of its credit risk plays a key role in this regard. The bank will hence try to reduce credit default as far as possible by screening credit applicants. Banks therefore benefit from models that predict the probability of default for a credit applicant based on observable factors. For this reason, machine learning approaches are in principle also highly interesting for banks. At the same time, model performance is not the sole criterion for the suitability of a machine learning algorithm for the use in the banking sector since the bank must also satisfy its stakeholders. The most important stakeholders in this context are a) the bank's credit applicants and b) the supervisory authority that regulates banks.
Image 1: A Bank's Primary Stakeholders; own illustration.
The considerations on the customer side have already been addressed in the section on legal implications: Credit applicants have a right to know the reasons why their credit application was (not) granted. At the same time, the topic is currently gaining relevance from a regulatory standpoint: For example, the Deutsche Bundesbank and BaFin (2021), the two central supervisory authorities of German banks, warned in a consultation paper of increased model risk due to the black-box nature of many machine learning techniques and called for a focus on interpretability. (Deutsche Bundesbank and BaFin 2021) Responses to the consultation paper indicated that respondents in the banking and insurance industry believe that the main benefit of interpretable models is to facilitate model selection by allowing the validity of the model to be verified by a human with domain knowledge. At the same time, the consultation highlights that the implementation of interpretable models is considered cost-intensive and therefore only worthwhile undertaking if the effort is counterbalanced by a significant increase in performance. (Deutsche Bundesbank and BaFin 2022)
Lipton (2016) clarifies that no universal definition of the term "interpretability" exists. Rather, machine learners seek different underlying goals when searching for interpretable algorithms. His taxonomy identifies five dimensions users wish to achieve through the application of interpretable models (see Figure 2):
Trust is partially covered by model performance: The higher a model’s predictive accuracy the less false predictions it makes and the more a user can rely on the model’s predictions. However, there is more to trust then just accuracy. First, there is a psychological component: Humans may tend to have more faith in a model they are able to grasp intellectually. Second, an algorithm may be perceived as more trustworthy if it makes wrong judgement in cases in which a human decision maker would have misjudged as well as in such cases human intervention would have failed to yield an improvement. (Lipton 2016) The more severe the consequences of a model decision, the more important trust becomes. (Ribeiro et al. 2016)
Another component of interpretability is the ability to establish causal relationships between the features and the target. In standard supervised learning techniques this is problematic. Thus, inducing causal relationships in a machine learning context is a research branch in its own right.
In addition, one would ideally want to train a machine learning model that can be applied to new data without significant performance loss. Data scientists usually try to achieve this by partitioning a given dataset into a test and training dataset. Within this context, a model is thus deemed transferable if it is able to predict the test data given what it has learned about the data’s underlying structure though studying the training dataset. In contrast to this rather narrow definition of transferability, a human decision maker typically performs better at generalizing previously obtained knowledge and applying it to entirely new context. (Lipton 2016) Here, a similar reasoning can be applied as in the case of the dimension "Trust": A model appears interpretable to humans if it is evident how the model applies known principles to new situations and if it fails to do so in scenarios in which a human would fall short as well.
The fourth dimension is the desire for a model to be as informative as possible to benefit decision makers to the maximum degree possible.
Lastly, ethical considerations constitute grounds for the use of interpretable models. Users wish to ensure that model-based decisions are made in a manner that the user, supervisor or society deems ethical. (Lipton 2016)
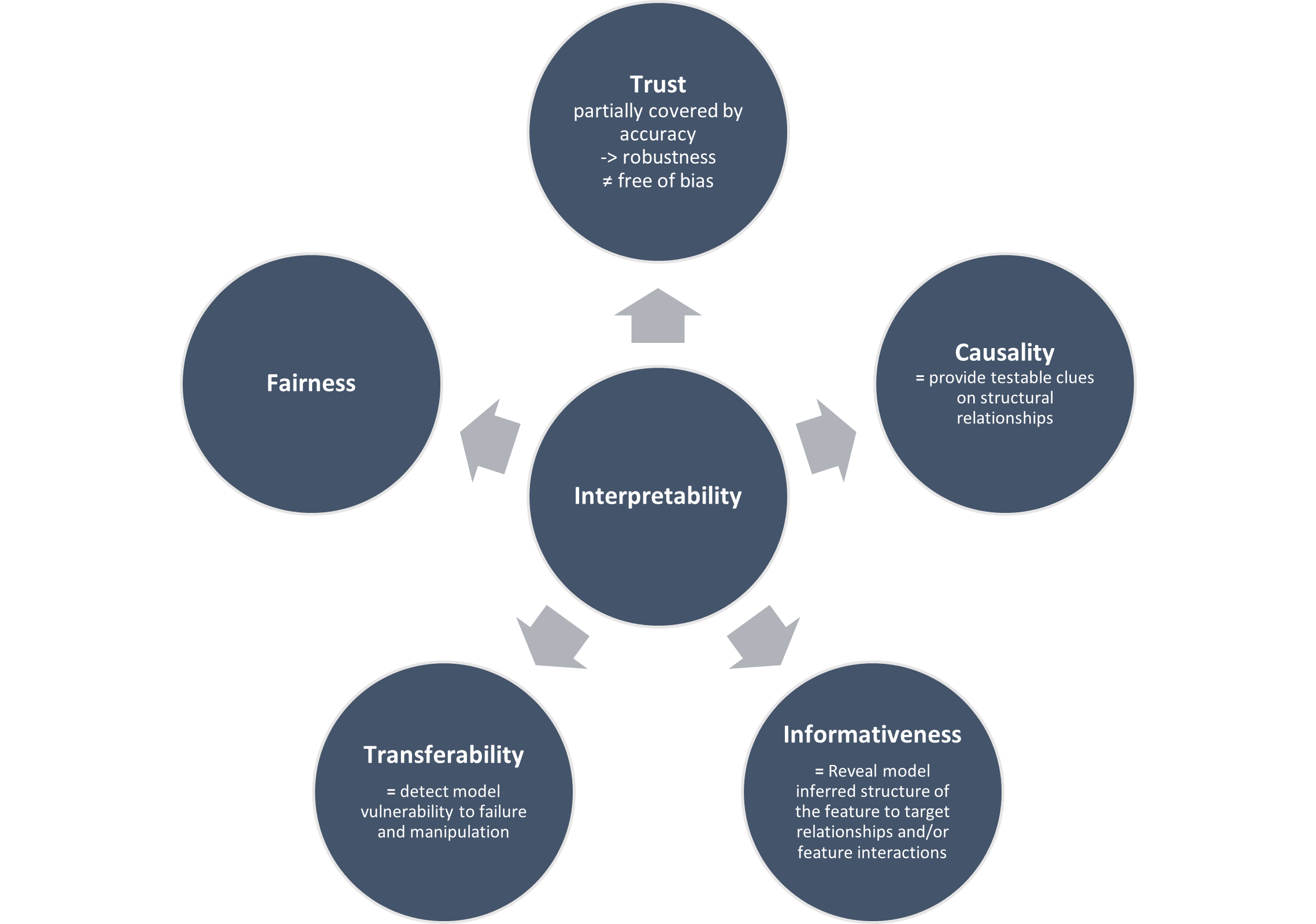
Image 2: The Five Dimensions of Interpretability; own illustration based on Lipton (2016).
Given the research question of this paper, the question arises which dimensions of Lipton’s (2016) interpretability taxonomy are of particular relevance in the area of credit risk and how the term should be defined in our given context. Considering the main stakeholders of a bank, we find the dimensions “Trust” and “Informativeness” to be of particular relevance. Trust in the credit risk context is strongly related to credit risk reduction but goes beyond it. In addition to good predictive power (and thus low credit default probability), there must also be a sense of security among stakeholders that the model is drawing its predictions on the basis of meaningful conclusions. In addition, models must be as informative as possible in order to plausibly communicate decisions to stakeholders. To illustrate this point, imagine a situation in which a credit applicant has been classified as not creditworthy on the basis of a machine learning algorithm. Naturally, the credit applicant will expect a plausible explanation for this. An interpretable machine learning technique should provide credit officers, who have to advocate model decisions in front of credit applicants, with all the necessary information. Our definition of "interpretability" is thus strongly geared to the needs of the end user. For the purposes of this paper, we thus adopt the definition of “interpretability” by Ribeiro et al. (2016) who classify an explanation as interpretable if it generates a “qualitative understanding [of the relationship] between the input variables and the response”. They aim at a model that can support human decision makers by making predictions and providing rationales for them. The human, who acts as the final authority in the decision-making process, then evaluates the model's predictions and justifications, and uses his or her domain knowledge to decide whether the decision is conclusive. (Ribeiro et al. 2016)
Having outlined the importance of interpretable machine learning models in general and in particular in credit risk, one must ask in which way interpretability can be achieved. Figure 3 gives a high-level overview. Most fundamentally, machine learning models can be divided into intrinsically interpretable models (so-called white-box-models) and black-box-models.
Intrinsically interpretable models are – as the name suggests - in themselves interpretable and thus do not require further adjustments to deliver interpretable explanations. For a model to be intrinsically explainable, it therefore needs to be sufficiently simple for a human to be able to grasp it. For example, linear regression, logistic regression and a shallow decision tree can be considered intrinsically explainable models.
A model that is not inherently explainable requires co-called post-hoc methods to render its results explainable ex-post. These post-hoc methods fall into one of two categories: They are either model-specific or model-agnostic. As the name suggests, model-specific interpretable machine learning algorithms are tailored towards specific model classes. Model-agnostic methods, on the other hand, are suited for any class of model. A further distinction can be made with regard to the scope of the interpretation offered by the post-hoc method: Does the explanation cover the entirety of the model’s decision behavior and can thus explain according to which principles the models arrive at its conclusions? Or does the explanation offered concern a single observation and can thus explain the conclusions drawn by the models for any particular case? The latter of these options is called “local interpretability” while the former is referred to as “global interpretability”. (Molnar 2022)
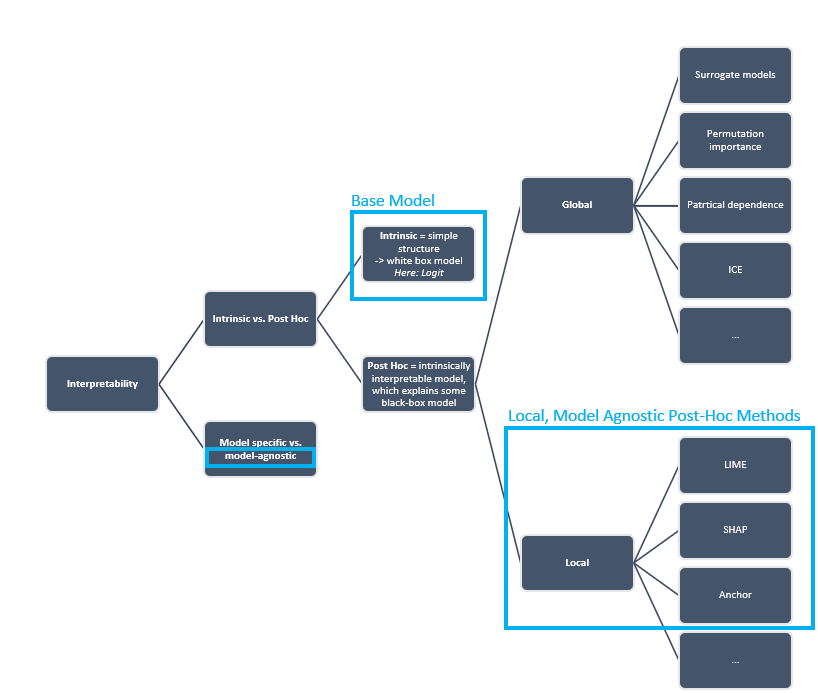
Image 3: Overview of Interpretability Methods; own illustration.
# Add Literature Table
file_name = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/LiteratureTable.csv'
Literature_Table = pd.read_csv(file_name,index_col=False, sep=";")
pd.set_option('display.max_colwidth', None)
dfStyler = Literature_Table.style.set_properties(**{'text-align': 'left'})\
.hide_index()
display(dfStyler.set_table_styles([dict(selector='th',
props=[('text-align', 'left')])]))
print("-----------------------------------------------------------------------")
print("Table 1: Literature Overview, Interpretability Methods.")
| Source | Title | Local vs. Global Interpretability | Data | Methodology | Key Insights/Conclusion |
|---|---|---|---|---|---|
| Baesens et al. (2003) | Using Neural Network Rule Extraction and Decision Tables for Credit-Risk Evaluation | Local | German credit risk dataset from UCI repository (Dua and Graff 2019) and two datasets obtained from major Benelux financial insti- tutions. | Neural Network Rule Extraction Techniques (Neurorule, Trepan, and Nefclass) and Decision Tables | Usefulness of Neural Networks due to their universal approximation property. Conclusive rules extracted by Neurorule and Trepan. Use of Decision Table to visualize reules in an intuitive graphical format. |
| Bussmann et al. (2019) | Explainable AI in Credit Risk Management | Local & Global | Lending Club data set obtained from Kaggle | Logistic Regression, XGBoost, Random Forest, Support Vector Machine, Neural Network + Post-hoc Explanability using LIME and SHAP | LIME and SHAP deliver logical and consistent explanations |
| Bussmann et al. (2021) | Explainable Machine Learning in Credit Risk Management | Local & Global | Data obtained from Modefinance, a European Credit Assessment Institution (ECAI) | XGBoost + Post-hoc Explanability using TreeSHAP (cf. Lundberg et al. 2020) | "explainable AI models can effectively advance the understanding of the determinants of financial risks and, specifically, of credit risks." |
| Demajo et al. (2021) | An Explanation Framework for Interpretable Credit Scoring | Local & Global | Home Equity Line of Credit (HELOC) and Lending Club (LC) Datasets | XGBoost + Post-hoc Explanability using SHAP+GRIP, Anchors and ProtoDash; Interpretability judged by domain experts | Domain experts judged that "the three types of explanations provided are complete and correct, effective and useful, easily understood, sufficiently detailed and trustworthy." |
| Dumitrescu et al. (2022) | Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects | Local | Simulated Data and Two Real Datasets | Logistic Regression + Decision Trees | Improvement in predictive power while maintaining its interpretability |
| Hayashi (2016) | Application of a rule extraction algorithm family based on the Re-RX algorithm to financial credit risk assessment from a Pareto optimal perspective | Global | Australian Credit Dataset, German Credit Dataset (Dua and Graff 2019) and two datasets obtained from major Benelux financial institutions. | Neural Network + Recursive rule extraction using the Re-RX algorithm family | "Continuous Re-RX, Re-RX with J48graft, and Sampling Re-RX comprise a powerful management tool that allows the creation of advanced, accurate, concise and interpretable decision support systems for credit risk evaluation." |
| Lundberg & Lee (2017) | A Unified Approach to Interpreting Model Predictions | Local | - | SHAP as additive feature importance method using Shapley values | SHAP framework identifies the class of additive feature importance methods (which includes six previous methods) and shows there is a unique solution in this class that adheres to desirable properties. |
| Lundberg et al. (2020) | From local explanations to global understanding with explainable AI for trees | Local & Global | chronic kidney disease data from the CRIC study. | Shapley values + TreeSHAP + SHAP interaction values | SHAP Extention by offering many tools for model interpretation that combine local explanations, such as dependence plots, summary plots, supervised clusterings and explanation embeddings. |
| Molnar (2018) | Interpretable machine learning: A guide for making black box models explainable. | Local & Global | - | summarizes all actual explainable ML tools | summary of all possible Explainable methods |
| Ribeiro et al.(2016) | "Why Should I Trust You?" Explaining the Predictions of any Classifier | Local and Global | Multi-polarity and Religion dataset available at their Github | LIME used on Deep Networks for Images and SVM for Text Data | Introduces LIME with the goal of local interpretability and SP LIME to measure global interpretability. The former is done by approximating the black box model using an interpretable model and the latter is proceeded via choosing representative observations from the data to provide a global view of the model. The paper moves toward achieving interpretability with the ultimate goal of gaining trust in ML models. |
| Ribeiro et al. (2018) | Anchors: High-Precision Model-Agnostic Explanations | Local | lending dataset & rcdv dataset | Usage of the anchor method on tabular data and image data to evaluate it's working method | Anchors highlight the part of the input that is sufficient for the classifier to make the prediction, making them intuitive and easy to understand. |
| Uddin et al. (2020) | Leveraging random forest in micro‐enterprises credit risk modelling for accuracy and interpretability | Global | micro-enterprises data obtained from one of the leading commercial banks of China | Random Forst + Relative variable importance | Essentiality of traditional financial variables and Relevance of alternative predictors (such as macroeconomic conditions) whos inclusion enhances existing modelling approaches |
| Visani et al. (2022) | Statistical stability indices for LIME: Obtaining reliable explanations for machine learning models | Local | An anonymised statistical sample, obtained by pooling data from several Italian financial institutions | Investigating LIME stability by performing repeated calls and comparing the results | Definition of LIME, especially the specification of kernel and the model's comlexity measure alongside with the method's feature choice makes the model strongly prone to instability of results. To address this issue, the paper introduces coefficient and variable stability index which help the practitioners to first investigate the issue and second, search for possible solutions. |
| Xia et al. (2020) | A Dynamic Credit Scoring Model Based on Survival Gradient Boosting Decision Tree Approach | Global | Data obtained from a consumer loan transactions of a major P2P lending platform in the U.S. | - | A "novel dynamic credit scoring model (i.e., SurvXGBoost) is proposed based on survival gradient boosting decision tree (GBDT) approach." and "maintains some interpretability" by indicating feature importance. |
| Yuan et al. (2022) | An Empirical Study of the Effect of Bachground Data Size on the Stability of Shapley Additive Explanations (SHAP) for Deep Learning Models | Local & Global | MIMIC-III, a freely accessible critical care database | Stability of SHAP with various background dataset sizes | Show that SHAP explanations fluctuate when using a small background sample size and that these fluctuations decrease when the background dataset sampling size increases. This finding holds true for both instance and model-level explanations. |
----------------------------------------------------------------------- Table 1: Literature Overview, Interpretability Methods.
This paper aims to answer the question whether it is possible to develop a model framework applicable within credit risk that achieves a high predictive performance as measured by the AUC whilst maintaining or even improving interpretability. A related question hence is whether there is a trade-off between performance (AUC) and interpretability.
Previous literature has highlighted the trade-off between simple, intrinsically interpretable models with limited accuracy and less transparent black-box models which exhibit a high predictive power. (Bussmann et al. 2021; Emad Azhar Ali et al. 2021) We expect that such a trade-off between interpretability and performance is also visible using our dataset when comparing a white-box model to a black-box model, as verbalized by hypotheses I and II.
I) The black-box model outperforms the white-box model (measured by the AUC).
II) The white-box model is better explainable than the black-box model.
We suspect that the trade-off formulated in hypotheses I and II can be relaxed by employing post-hoc methods, leading us to hypothesis III:
III) Through the usage of post-hoc methods, it is possible to achieve a higher performance compared to a white-box model (measured by the AUC) and having a higher degree of interpretability (compared to the black-box model) at the same time.
The analysis is performed using a credit risk dataset obtained from Freddie Mac (2021). Freddie Mac is a U.S. mortgage bank that was created by the United States Congress in 1970 to “ensure a reliable and affordable supply of mortgage funds throughout the country”. (Federal Housing Finance Agency 2022) Instead of lending to individuals directly, its business consists of purchasing loans on the secondary housing market, bundling them and selling them in the form of Mortgage-Backed Securities (MBS).(Freddie Mac 2022a) It separates its business operations into three major divisions: Single-Family Division, Multifamily Division and Capital Markets Division. The dataset used in this paper is the so-called Single Family Loan-Level Dataset (Origination Data File). As the name suggests it covers loans purchased by Freddie Mac’s Single-Family Division. (Freddie Mac 2021)
The dataset includes loans originated between 1999 and the Origination Cutoff Date.(Freddie Mac 2022c) The loans chosen for inclusion were selected at random from Freddie Mac’s loan portfolio and every loan had the same probability of inclusion. (Freddie Mac 2022b) Approximately 150.000 observations with the first payment date from 2013 to 2016 are used as training data to build the prediction models, while the test data consists of approximately 50.000 observations from 2017 to 2019.
In total, the dataset includes 31 features. These are described in the following table.
# Table of Features
file_name = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/columns_formatted.csv'
Feature_Table = pd.read_csv(file_name,index_col=False)
pd.set_option('display.max_colwidth', None)
Feature_Table = Feature_Table.drop('#', axis=1)
dfStyler = Feature_Table.style.set_properties(**{'text-align': 'left'})\
.hide_index()
display(dfStyler.set_table_styles([dict(selector='th',
props=[('text-align', 'left')])]))
print("-----------------------------------------------------------------------")
print("Table 2: Feature Description, taken from Freddie Mac (2022c)")
| Column name | Short description | Format | Long description | Values |
|---|---|---|---|---|
| fico | Credit Score | Numeric | CREDIT SCORE - A number, prepared by third parties, summarizing the borrowerÕs creditworthiness, which may be indicative of the likelihood that the borrower will timely repay future obligations. Generally, the credit score disclosed is the score known at the time of acquisition and is the score used to originate the mortgage. | 300 - 850 9999 = Not Available, if Credit Score is < 300 or > 850. |
| dt_first_pi | First Payment Date | Date | FIRST PAYMENT DATE - The date of the first scheduled mortgage payment due under the terms of the mortgage note. | YYYYMM |
| flag_fthb | First Time Homebuyer Flag | Alpha | FIRST TIME HOMEBUYER FLAG - Indicates whether the Borrower, or one of a group of Borrowers, is an individual who (1) is purchasing the mortgaged property, (2) will reside in the mortgaged property as a primary residence and (3) had no ownership interest (sole or joint) in a residential property during the three-year period preceding the date of the purchase of the mortgaged property. With certain limited exceptions, a displaced homemaker or single parent may also be considered a First-Time Homebuyer if the individual had no ownership interest in a residential property during the preceding three-year period other than an ownership interest in the marital residence with a spouse. | Y = Yes N = No 9 = Not Available or Not Applicable |
| dt_matr | Maturity Date | Date | MATURITY DATE - The month in which the final monthly payment on the mortgage is scheduled to be made as stated on the original mortgage note. | YYYYMM |
| cd_msa | Metropolitan Statistical Area (MSA) Or Metropolitan Division | Numeric | METROPOLITAN STATISTICAL AREA (MSA) OR METROPOLITAN DIVISION - This disclosure will be based on the designation of the Metropolitan Statistical Area or Metropolitan Division as of the date of issuance. Metropolitan Statistical Areas (MSAs) are defined by the United States Office of Management and Budget (OMB) and have at least one urbanized area with a population of 50,000 or more inhabitants. An MSA containing a single core with a population of 2.5 million or more may be divided into smaller groups of counties that OMB refers to as Metropolitan Divisions. If an MSA applies to a mortgaged property, the applicable five-digit value is disclosed; however, if the mortgaged property also falls within a Metropolitan Division classification, the applicable five-digit value for the Metropolitan Division takes precedence and is disclosed instead. This disclosure will not be updated to reflect any subsequent changes in designations of MSAs, Metropolitan Divisions or other classifications. Null indicates that the area in which the mortgaged property is located is (a) neither an MSA nor a Metropolitan Division, or (b) unknown. | Metropolitan Division or MSA Code. Space (5) = Indicates that the area in which the mortgaged property is located is a) neither an MSA nor a Metropolitan Division, or b) unknown. |
| mi_pct | Mortgage Insurance Percentage (MI %) | Numeric | MORTGAGE INSURANCE PERCENTAGE (MI %) - The percentage of loss coverage on the loan, at the time of Freddie Mac's purchase of the mortgage loan that a mortgage insurer is providing to cover losses incurred as a result of a default on the loan. Only primary mortgage insurance that is purchased by the Borrower, lender or Freddie Mac is disclosed. Mortgage insurance that constitutes "credit enhancement" that is not required by Freddie Mac's Charter is not disclosed. Amounts of mortgage insurance reported by Sellers that are less than 1% or greater than 55% will be disclosed as "Not Available," which will be indicated 999. No MI will be indicated by three zeros. | 1% - 55% 000 = No MI 999 = Not Available |
| cnt_units | Number of Units | Numeric | NUMBER OF UNITS - Denotes whether the mortgage is a one-, two-, three-, or four-unit property. | 1 = one-unit 2 = two-unit 3 = three-unit 4 = four-unit 99 = Not Available |
| occpy_sts | Occupancy Status | Alpha | OCCUPANCY STATUS - Denotes whether the mortgage type is owner occupied, second home, or investment property. | P = Primary Residence I = Investment Property S = Second Home 9 = Not Available |
| cltv | Original Combined Loan-to-Value (CLTV) | Numeric | ORIGINAL COMBINED LOAN-TO-VALUE (CLTV) - In the case of a purchase mortgage loan, the ratio is obtained by dividing the original mortgage loan amount on the note date plus any secondary mortgage loan amount disclosed by the Seller by the lesser of the mortgaged property's appraised value on the note date or its purchase price. In the case of a refinance mortgage loan, the ratio is obtained by dividing the original mortgage loan amount on the note date plus any secondary mortgage loan amount disclosed by the Seller by the mortgaged property's appraised value on the note date. If the secondary financing amount disclosed by the Seller includes a home equity line of credit, then the CLTV calculation reflects the disbursed amount at closing of the first lien mortgage loan, not the maximum loan amount available under the home equity line of credit. In the case of a seasoned mortgage loan, if the Seller cannot warrant that the value of the mortgaged property has not declined since the note date, Freddie Mac requires that the Seller must provide a new appraisal value, which is used in the CLTV calculation. In certain cases, where the Seller delivered a loan to Freddie Mac with a special code indicating additional secondary mortgage loan amounts, those amounts may have been included in the CLTV calculation. If the CLTV is LTV, set the CLTV to 'Not Available.' This disclosure is subject to the widely varying standards originators use to verify Borrowers' secondary mortgage loan amounts and will not be updated. | 201801 and prior: 6% - 200% 999 = Not Available 201802 and later: 1% - 998% 999 = Not Available HARP ranges: 1% - 998% 999 = Not Available |
| dti | Original Debt-to-Income (DTI) Ratio | Numeric | ORIGINAL DEBT-TO-INCOME (DTI) RATIO - Disclosure of the debt to income ratio is based on (1) the sum of the borrower's monthly debt payments, including monthly housing expenses that incorporate the mortgage payment the borrower is making at the time of the delivery of the mortgage loan to Freddie Mac, divided by (2) the total monthly income used to underwrite the loan as of the date of the origination of the such loan. Ratios greater than 65% are indicated that data is Not Available. All loans in the HARP dataset will be disclosed as Not Available. This disclosure is subject to the widely varying standards originators use to verify Borrowers' assets and liabilities and will not be updated. | 0% DTI =65% 999 = Not Available HARP ranges: 999 = Not Available |
| orig_upb | Original UPB | Numeric | ORIGINAL UPB - The UPB of the mortgage on the note date. | Amount will be rounded to the nearest $1,000. |
| ltv | Original Loan-to-Value (LTV) | Numeric | ORIGINAL LOAN-TO-VALUE (LTV) - In the case of a purchase mortgage loan, the ratio obtained by dividing the original mortgage loan amount on the note date by the lesser of the mortgaged property's appraised value on the note date or its purchase price. In the case of a refinance mortgage loan, the ratio obtained by dividing the original mortgage loan amount on the note date and the mortgaged property's appraised value on the note date. In the case of a seasoned mortgage loan, if the Seller cannot warrant that the value of the mortgaged property has not declined since the note date, Freddie Mac requires that the Seller must provide a new appraisal value, which is used in the LTV calculation. For loans in the non HARP dataset, ratios below 6% or greater than 105% will be disclosed as "Not Available," indicated by 999. For loans in the HARP dataset, LTV ratios greater than 999% will be disclosed as Not Available. | 201801 and prior: 6% - 105% 999 = Not Available 201802 and later: 1% - 998% 999 = Not Available HARP ranges: 1% - 998% 999 = Not Available |
| int_rt | Original Interest Rate | Numeric - 6,3 | ORIGINAL INTEREST RATE - The original note rate as indicated on the mortgage note. | nan |
| channel | Channel | Alpha | CHANNEL - Disclosure indicates whether a Broker or Correspondent, as those terms are defined below, originated or was involved in the origination of the mortgage loan. If a Third Party Origination is applicable, but the Seller does not specify Broker or Correspondent, the disclosure will indicate "TPO Not Specified". Similarly, if neither Third Party Origination nor Retail designations are available, the disclosure will indicate "TPO Not Specified." If a Broker, Correspondent or Third Party Origination disclosure is not applicable, the mortgage loan will be designated as Retail, as defined below. Broker is a person or entity that specializes in loan originations, receiving a commission (from a Correspondent or other lender) to match Borrowers and lenders. The Broker performs some or most of the loan processing functions, such as taking loan applications, or ordering credit reports, appraisals and title reports. Typically, the Broker does not underwrite or service the mortgage loan and generally does not use its own funds for closing; however, if the Broker funded a mortgage loan on a lender's behalf, such a mortgage loan is considered a "Broker" third party origination mortgage loan. The mortgage loan is generally closed in the name of the lender who commissioned the Broker's services. Correspondent is an entity that typically sells the Mortgages it originates to other lenders, which are not Affiliates of that entity, under a specific commitment or as part of an ongoing relationship. The Correspondent performs some, or all, of the loan processing functions, such as: taking the loan application; ordering credit reports, appraisals, and title reports; and verifying the Borrower's income and employment. The Correspondent may or may not have delegated underwriting and typically funds the mortgage loans at settlement. The mortgage loan is closed in the Correspondent's name and the Correspondent may or may not service the mortgage loan. The Correspondent may use a Broker to perform some of the processing functions or even to fund the loan on its behalf; under such circumstances, the mortgage loan is considered a "Broker" third party origination mortgage loan, rather than a "Correspondent" third party origination mortgage loan. Retail Mortgage is a mortgage loan that is originated, underwritten and funded by a lender or its Affiliates. The mortgage loan is closed in the name of the lender or its Affiliate and if it is sold to Freddie Mac, it is sold by the lender or its Affiliate that originated it. A mortgage loan that a Broker or Correspondent completely or partially originated, processed, underwrote, packaged, funded or closed is not considered a Retail mortgage loan. For purposes of the definitions of Correspondent and Retail, "Affiliate" means any entity that is related to another party as a consequence of the entity, directly or indirectly, controlling the other party, being controlled by the other party, or being under common control with the other party. | R = Retail B = Broker C = Correspondent T = TPO Not Specified 9 = Not Available |
| ppmt_pnlty | Prepayment Penalty Mortgage (PPM) Flag | Alpha | PREPAYMENT PENALTY MORTGAGE (PPM) FLAG - Denotes whether the mortgage is a PPM. A PPM is a mortgage with respect to which the borrower is, or at any time has been, obligated to pay a penalty in the event of certain repayments of principal. | Y = PPM N = Not PPM |
| prod_type | Amortization Type (Formerly Product Type) | Alpha | AMORTI ATION TYPE - Denotes that the product is a fixed-rate mortgage or adjustable-rate mortgage. | FRM - Fixed Rate Mortgage ARM - Adjustable Rate Mortgage |
| st | Property State | Alpha | PROPERTY STATE - A two-letter abbreviation indicating the state or territory within which the property securing the mortgage is located. | AL, T , VA, etc. |
| prop_type | Property Type | Alpha | PROPERTY TYPE - Denotes whether the property type secured by the mortgage is a condominium, leasehold, planned unit development (PUD), cooperative share, manufactured home, or Single-Family home. If the Property Type is Not Available, this will be indicated by 99. | CO = Condo PU = PUD MH = Manufactured Housing SF = Single-Family CP = Co-op 99 = Not Available |
| zipcode | Postal Code | Numeric | POSTAL CODE - The postal code for the location of the mortgaged property | 00, where " " represents the first three digits of the 5- digit postal code Space (5) = Unknown |
| id_loan | Loan Sequence Number | Numeric | LOAN SEQUENCE NUMBER - Unique identifier assigned to each loan. | nan |
| loan_purpose | Loan Purpose | Alpha | LOAN PURPOSE - Indicates whether the mortgage loan is a Cash- out Refinance mortgage, No Cash-out Refinance mortgage, or a Purchase mortgage. Generally, a Cash-out Refinance mortgage loan is a mortgage loan in which the use of the loan amount is not limited to specific purposes. A mortgage loan placed on a property previously owned free and clear by the Borrower is always considered a Cash-out Refinance mortgage loan. Generally, a No Cash-out Refinance mortgage loan is a mortgage loan in which the loan amount is limited to the following uses: Pay off the first mortgage, regardless of its age Pay off any junior liens secured by the mortgaged property, that were used in their entirety to acquire the subject property Pay related closing costs, financing costs and prepaid items, and Disburse cash out to the Borrower (or any other payee) not to exceed 2% of the new refinance mortgage loan or $2,000, whichever is less. As an exception to the above, for construction conversion mortgage loans and renovation mortgage loans, the amount of the interim construction financing secured by the mortgaged property is considered an amount used to pay off the first mortgage. Paying off unsecured liens or construction costs paid by the Borrower outside of the secured interim construction financing is considered cash out to the Borrower, if greater than $2000 or 2% of loan amount. This disclosure is subject to various special exceptions used by Sellers to determine whether a mortgage loan is a No Cash-out Refinance mortgage loan. | P = Purchase C = Refinance - Cash Out N = Refinance - No Cash Out R = Refinance - Not Specified 9 =Not Available |
| orig_loan_term | Original Loan Term | Numeric | ORIGINAL LOAN TERM - A calculation of the number of scheduled monthly payments of the mortgage based on the First Payment Date and Maturity Date. | Calculation: (Loan Maturity Date (MM/YY) - Loan First Payment Date (MM/YY) + 1) |
| cnt_borr | Number of Borrowers | Numeric | NUMBER OF BORROWERS - The number of Borrower(s) who are obligated to repay the mortgage note secured by the mortgaged property. Disclosure denotes only whether there is one borrower, or more than one borrower associated with the mortgage note. This disclosure will not be updated to reflect any subsequent assumption of the mortgage note. | 201801 and prior: 01 = 1 borrower 02 = > 1 borrowers 99 = Not Available 201802 and later: 01 = 1 borrower 02 = 2 borrowers 03 = 3 borrowers 09 = 9 borrowers 10 = 10 borrowers 99 = Not Available |
| seller_name | Seller Name | Alpha Numeric | SELLER NAME - The entity acting in its capacity as a seller of mortgages to Freddie Mac at the time of acquisition. Seller Name will be disclosed for sellers with a total Original UPB representing 1% or more of the total Original UPB of all loans in the Dataset for a given calendar quarter. Otherwise, the Seller Name will be set to "Other Sellers". | Name of the seller, or "Other Sellers" |
| servicer_name | Servicer Name | Alpha Numeric | SERVICER NAME - The entity acting in its capacity as the servicer of mortgages to Freddie Mac as of the last period for which loan activity is reported in the Dataset. Servicer Name will be disclosed for servicers with a total Original UPB representing 1% or more of the total Original UPB of all loans in the Dataset for a given calendar quarter. Otherwise, the Servicer Name will be set to "Other Servicers". | Name of the servicer, or "Other Servicers" |
| flag_sc | Super Conforming Flag | Alpha | SUPER CONFORMING FLAG - For mortgages that exceed conforming loan limits with origination dates on or after 10/1/2008 and were delivered to Freddie Mac on or after 1/1/2009 | Y = Yes Space (1) = Not Super Conforming |
| pre_relief | Pre-HARP Loan Sequence Number | Alpha Numeric - PYYQnXXXXXXX | PRE-RELIEF REFINANCE LOAN SEQUENCE NUMBER - The Loan Sequence Number link that associates a Relief Refinance loan to the Loan Sequence Number assigned to the loan from which it was refinanced within in the Single-Family Loan Level Dataset. Note: Populated only for loans where the Relief Refinance Indicator is set to Y. All other loans will be blank. | PYY0n Product F = FRM and A = ARM; YY0n = origination year and quarter; and, randomly assigned digits |
| pgrm_ind | Program Indicator | Alpha Numeric | PROGRAM INDICATOR - The indicator that identifies if a loan participates in and of the Freddie Mac programs listed in the valid values. Note: The standard dataset discloses these enumerations for loans originated on or after March 1, 2015. The Non-Standard dataset discloses enumerations for loans originated under the HP program between 1999 and February 28, 2015. Underwriting standards for Home Possible prior to March 1, 2015 may be different than the current standards. | H = Home Possible F = HFA Advantage 9 = Not Available or not part of Home Possible or HFA Advantage programs |
| rel_ref_ind | HARP Indicator | Alpha | RELIEF REFINANCE INDICATOR - Indicator that identifies whether the loan is part of Freddie Mac's Relief Refinance Program. Loans which are both a Relief Refinance and have an Original Loan-to-Value above 80 are HARP loans. | Y = Relief Refinance Loan Space = Non-Relief Refinance loan |
| prop_val_meth | Property Valuation Method | Numeric | PROPERTY VALUATION METHOD - The indicator denoting which method was used to obtain a property appraisal, if any. Note: Populated for loans originated on or after 1/1/2017. | 1 = ACE Loans 2 = Full Appraisal 3 = Other Appraisals (Desktop, driveby, external, AVM) 9 = Not Available |
| int_only_ind | Interest Only (I/O) Indicator | Alpha | INTEREST ONLY INDICATOR (I/O INDICATOR) - The indicator denoting whether the loan only requires interest payments for a specified period beginning with the first payment date. | Y = Yes N = No |
| TARGET | Default label | Numeric | Target label | 1 = Default, 0 otherwise |
----------------------------------------------------------------------- Table 2: Feature Description, taken from Freddie Mac (2022c)
The target feature, i.e. whether a loan defaulted or not defaulted, are not given in the original dataset. In constructing target values for the training dataset, the definition of default of the Basel Committee on Banking Supervision (2004) was used:
“A default is considered to have occurred with regard to a particular obligor when […] [t]he obligor is past due more than 90 days on any material credit obligation to the banking group.[…] Overdrafts will be considered as being past due once the customer has breached an advised limit or been advised of a limit smaller than current outstandings.“
Using this definition, the overall default ratio (defaulted loans over non defaulted loans) is given by 0.009103, i.e. approximately 0.9%. In the following, summary statistics are presented for numerical features. In addition to mean and standard deviation, the mean difference (mean of non-defaulted loans – mean of defaulted loans) is calculated. Features, for which the mean difference is negative (positive), are highlighted in red (green).
Categorical features, on the other hand, are treated one-by-one. For each category of a feature, the absolute and relative frequency in the test and training dataset is indicated. Then, for the training dataset, the proportion of defaulted and non-defaulted loans within each category is reported (for the test dataset, this is not possible, as no target values are available). Finally, the ratio of defaulted and non-defaulted loans within each category is calculated and the differences to the overall default ratio are calculated. Negative differences are highlighted in green, positive differences in red. In this way, the reader is given a quick overview of the data and can identify potential correlations between feature characteristics and the target.
As an example, consider the feature ‘servicer_name’. Here, for ‘servicer_name == SPECIALIZED LOAN SERVICING LLC’, the default ratio is equal to approximately 15.2% and thus 16.7 times higher than the average default ratio. This is on example of an interesting prima facie evidence that becomes visible through this preliminary analysis.
For further information regarding the data collection and the characteristics of the dataset, the interested reader is referred to the data provider Freddie Mac (2021).
# import train data
file_train = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/data_train.csv'
df_train = pd.read_csv(file_train,index_col=False)
# import test data
file_test = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/data_test.csv'
df_test = pd.read_csv(file_test,index_col=False)
Columns (27) have mixed types.Specify dtype option on import or set low_memory=False.
# Overall Ratio Defaults/Non-Defaults as Benchmark for further analysis
# Calculate overall ratio defaults/non-defaults as benchmark
ratio_overall = df_train.groupby(by=["TARGET"])["TARGET"].count()[1]\
/df_train.groupby(by=["TARGET"])["TARGET"].count()[0]
print("Overall ratio of defaults/non-defaults: %0.6f" %ratio_overall)
Overall ratio of defaults/non-defaults: 0.009103
# Define all numerical features
numerical_cols = ['fico', 'mi_pct', 'cnt_units', 'cltv', 'dti', 'orig_upb',
'ltv', 'int_rt', 'orig_loan_term', 'cnt_borr']
# Calculate mean grouped by the target feature
df_diff = df_train.groupby(["TARGET"])[numerical_cols].mean()
df_diff=pd.concat((df_diff,df_diff.diff(periods=len(df_diff)-1).dropna()))
df_diff = df_diff.reset_index(drop = True)
df_diff.index = ('Mean_Non_Default', 'Mean_Default', 'Difference_in_Mean')
# Calculate std grouped by the target feature
df_std = df_train.groupby(["TARGET"])[numerical_cols].std()
df_std.index = ('Std_Non_Default', 'Std_Default')
# Calculate the differences in mean and std of defaulting and non-defaulting
df_diff = pd.concat([df_diff, df_std] )
df_diff = df_diff.reindex(['Mean_Non_Default', 'Std_Non_Default',
'Mean_Default', 'Std_Default', 'Difference_in_Mean'])
# Color the results depending on output
# Subset dataframe with condition to color the different results
test = df_diff[df_diff.index=='Difference_in_Mean']
# Pass the subset dataframe index and column to pd.IndexSlice
slice_ = pd.IndexSlice[test.index, test.columns]
# Color the results
df_diff.style.applymap(lambda v: 'color:green;' if (v > 0) else None,
subset = slice_)\
.applymap(lambda v: 'color:red;' if (v <= 0) else None,
subset = slice_)\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('fico'): "{:.2f}",
('mi_pct'): "{:.2f}",
('cnt_units'): "{:.2f}",
('cltv'): "{:.2f}",
('ltv'): "{:.2f}",
('int_rt'): "{:.2f}",
('orig_loan_term'): "{:.2f}",
('cnt_borr'): "{:.2f}"
})
| fico | mi_pct | cnt_units | cltv | dti | orig_upb | ltv | int_rt | orig_loan_term | cnt_borr | |
|---|---|---|---|---|---|---|---|---|---|---|
| Mean_Non_Default | 749.72 | 5.53 | 1.03 | 76.09 | 200 | 211 534 | 74.67 | 4.07 | 310.54 | 1.52 |
| Std_Non_Default | 90.39 | 10.94 | 0.24 | 21.61 | 365 | 116 687 | 20.93 | 0.55 | 79.11 | 0.50 |
| Mean_Default | 695.84 | 8.14 | 1.02 | 90.06 | 441 | 187 629 | 86.26 | 4.40 | 330.08 | 1.31 |
| Std_Default | 61.28 | 12.52 | 0.19 | 31.63 | 475 | 105 417 | 27.99 | 0.50 | 64.21 | 0.46 |
| Difference_in_Mean | -53.88 | 2.62 | -0.01 | 13.97 | 241 | -23 905 | 11.59 | 0.33 | 19.54 | -0.21 |
# cd_msa
# create table from train data
df_vis_train = df_train.groupby("cd_msa")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['cd_msa']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['cd_msa']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_cd_msa = pd.merge(df_join1,df_join2 ,on='cd_msa',how='outer')
df_cd_msa = df_cd_msa.set_index("cd_msa")
df_cd_msa = df_cd_msa[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault', 'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_cd_msa.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| cd_msa | ||||||||
| 37380.0 | 13 | 0.00009 | 1 | 0.00001 | 0.92308 | 0.07692 | 0.08333 | 0.07423 |
| 24500.0 | 30 | 0.00020 | 6 | 0.00004 | 0.93333 | 0.06667 | 0.07143 | 0.06233 |
| 46660.0 | 45 | 0.00030 | 10 | 0.00007 | 0.93333 | 0.06667 | 0.07143 | 0.06233 |
| 47020.0 | 18 | 0.00012 | 4 | 0.00003 | 0.94444 | 0.05556 | 0.05882 | 0.04972 |
| 17420.0 | 44 | 0.00029 | 23 | 0.00015 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 15260.0 | 44 | 0.00029 | 11 | 0.00007 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 12100.0 | 93 | 0.00062 | 26 | 0.00017 | 0.95699 | 0.04301 | 0.04494 | 0.03584 |
| 24220.0 | 48 | 0.00032 | 19 | 0.00013 | 0.95833 | 0.04167 | 0.04348 | 0.03438 |
| 13020.0 | 24 | 0.00016 | 8 | 0.00005 | 0.95833 | 0.04167 | 0.04348 | 0.03438 |
| 41660.0 | 25 | 0.00017 | 8 | 0.00005 | 0.96000 | 0.04000 | 0.04167 | 0.03256 |
| 17980.0 | 77 | 0.00051 | 21 | 0.00014 | 0.96104 | 0.03896 | 0.04054 | 0.03144 |
| 28100.0 | 77 | 0.00051 | 27 | 0.00018 | 0.96104 | 0.03896 | 0.04054 | 0.03144 |
| 29340.0 | 52 | 0.00035 | 22 | 0.00015 | 0.96154 | 0.03846 | 0.04000 | 0.03090 |
| 47380.0 | 53 | 0.00035 | 25 | 0.00017 | 0.96226 | 0.03774 | 0.03922 | 0.03011 |
| 33124.0 | 691 | 0.00461 | 287 | 0.00191 | 0.96237 | 0.03763 | 0.03910 | 0.02999 |
| 20764.0 | 133 | 0.00089 | 13 | 0.00009 | 0.96241 | 0.03759 | 0.03906 | 0.02996 |
| 12940.0 | 275 | 0.00183 | 89 | 0.00059 | 0.96364 | 0.03636 | 0.03774 | 0.02863 |
| 16620.0 | 56 | 0.00037 | 16 | 0.00011 | 0.96429 | 0.03571 | 0.03704 | 0.02793 |
| 25220.0 | 28 | 0.00019 | 10 | 0.00007 | 0.96429 | 0.03571 | 0.03704 | 0.02793 |
| 43340.0 | 85 | 0.00057 | 30 | 0.00020 | 0.96471 | 0.03529 | 0.03659 | 0.02748 |
| 16300.0 | 116 | 0.00077 | 30 | 0.00020 | 0.96552 | 0.03448 | 0.03571 | 0.02661 |
| 13140.0 | 92 | 0.00061 | 33 | 0.00022 | 0.96739 | 0.03261 | 0.03371 | 0.02460 |
| 19140.0 | 31 | 0.00021 | 7 | 0.00005 | 0.96774 | 0.03226 | 0.03333 | 0.02423 |
| 43580.0 | 63 | 0.00042 | 12 | 0.00008 | 0.96825 | 0.03175 | 0.03279 | 0.02368 |
| 37764.0 | 32 | 0.00021 | 5 | 0.00003 | 0.96875 | 0.03125 | 0.03226 | 0.02316 |
| 40580.0 | 32 | 0.00021 | 11 | 0.00007 | 0.96875 | 0.03125 | 0.03226 | 0.02316 |
| 26300.0 | 32 | 0.00021 | 14 | 0.00009 | 0.96875 | 0.03125 | 0.03226 | 0.02316 |
| 22744.0 | 818 | 0.00545 | 322 | 0.00215 | 0.96944 | 0.03056 | 0.03153 | 0.02242 |
| 36100.0 | 137 | 0.00091 | 53 | 0.00035 | 0.97080 | 0.02920 | 0.03008 | 0.02097 |
| 33740.0 | 35 | 0.00023 | 13 | 0.00009 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 15804.0 | 432 | 0.00288 | 172 | 0.00115 | 0.97222 | 0.02778 | 0.02857 | 0.01947 |
| 21060.0 | 36 | 0.00024 | 9 | 0.00006 | 0.97222 | 0.02778 | 0.02857 | 0.01947 |
| 18880.0 | 108 | 0.00072 | 35 | 0.00023 | 0.97222 | 0.02778 | 0.02857 | 0.01947 |
| 13644.0 | 108 | 0.00072 | 5 | 0.00003 | 0.97222 | 0.02778 | 0.02857 | 0.01947 |
| 10500.0 | 37 | 0.00025 | 8 | 0.00005 | 0.97297 | 0.02703 | 0.02778 | 0.01867 |
| 16180.0 | 37 | 0.00025 | 16 | 0.00011 | 0.97297 | 0.02703 | 0.02778 | 0.01867 |
| 16020.0 | 38 | 0.00025 | 17 | 0.00011 | 0.97368 | 0.02632 | 0.02703 | 0.01792 |
| 29180.0 | 115 | 0.00077 | 28 | 0.00019 | 0.97391 | 0.02609 | 0.02679 | 0.01768 |
| 36740.0 | 1043 | 0.00695 | 415 | 0.00277 | 0.97411 | 0.02589 | 0.02657 | 0.01747 |
| 48900.0 | 232 | 0.00155 | 68 | 0.00045 | 0.97414 | 0.02586 | 0.02655 | 0.01745 |
| 16940.0 | 39 | 0.00026 | 18 | 0.00012 | 0.97436 | 0.02564 | 0.02632 | 0.01721 |
| 30140.0 | 40 | 0.00027 | 13 | 0.00009 | 0.97500 | 0.02500 | 0.02564 | 0.01654 |
| 45540.0 | 41 | 0.00027 | 8 | 0.00005 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 23580.0 | 82 | 0.00055 | 38 | 0.00025 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 20020.0 | 41 | 0.00027 | 2 | 0.00001 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 26180.0 | 42 | 0.00028 | 4 | 0.00003 | 0.97619 | 0.02381 | 0.02439 | 0.01529 |
| 26140.0 | 42 | 0.00028 | 18 | 0.00012 | 0.97619 | 0.02381 | 0.02439 | 0.01529 |
| 46140.0 | 295 | 0.00197 | 112 | 0.00075 | 0.97627 | 0.02373 | 0.02431 | 0.01520 |
| 42680.0 | 85 | 0.00057 | 28 | 0.00019 | 0.97647 | 0.02353 | 0.02410 | 0.01499 |
| 13980.0 | 85 | 0.00057 | 11 | 0.00007 | 0.97647 | 0.02353 | 0.02410 | 0.01499 |
| 32900.0 | 87 | 0.00058 | 37 | 0.00025 | 0.97701 | 0.02299 | 0.02353 | 0.01443 |
| 22420.0 | 131 | 0.00087 | 44 | 0.00029 | 0.97710 | 0.02290 | 0.02344 | 0.01433 |
| 20700.0 | 44 | 0.00029 | 23 | 0.00015 | 0.97727 | 0.02273 | 0.02326 | 0.01415 |
| 12540.0 | 309 | 0.00206 | 136 | 0.00091 | 0.97735 | 0.02265 | 0.02318 | 0.01408 |
| 18020.0 | 45 | 0.00030 | 9 | 0.00006 | 0.97778 | 0.02222 | 0.02273 | 0.01362 |
| 47644.0 | 364 | 0.00243 | 19 | 0.00013 | 0.97802 | 0.02198 | 0.02247 | 0.01337 |
| 34580.0 | 46 | 0.00031 | 25 | 0.00017 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 34940.0 | 187 | 0.00125 | 73 | 0.00049 | 0.97861 | 0.02139 | 0.02186 | 0.01275 |
| 49740.0 | 47 | 0.00031 | 15 | 0.00010 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 31420.0 | 47 | 0.00031 | 17 | 0.00011 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 35100.0 | 47 | 0.00031 | 13 | 0.00009 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 31460.0 | 47 | 0.00031 | 29 | 0.00019 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 45780.0 | 287 | 0.00191 | 101 | 0.00067 | 0.97909 | 0.02091 | 0.02135 | 0.01225 |
| 45060.0 | 144 | 0.00096 | 46 | 0.00031 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 49340.0 | 436 | 0.00291 | 163 | 0.00109 | 0.97936 | 0.02064 | 0.02108 | 0.01197 |
| 27260.0 | 584 | 0.00389 | 216 | 0.00144 | 0.97945 | 0.02055 | 0.02098 | 0.01188 |
| 27900.0 | 49 | 0.00033 | 26 | 0.00017 | 0.97959 | 0.02041 | 0.02083 | 0.01173 |
| 11100.0 | 50 | 0.00033 | 17 | 0.00011 | 0.98000 | 0.02000 | 0.02041 | 0.01131 |
| 29460.0 | 252 | 0.00168 | 97 | 0.00065 | 0.98016 | 0.01984 | 0.02024 | 0.01114 |
| 33660.0 | 101 | 0.00067 | 37 | 0.00025 | 0.98020 | 0.01980 | 0.02020 | 0.01110 |
| 46340.0 | 52 | 0.00035 | 23 | 0.00015 | 0.98077 | 0.01923 | 0.01961 | 0.01050 |
| 39460.0 | 106 | 0.00071 | 49 | 0.00033 | 0.98113 | 0.01887 | 0.01923 | 0.01013 |
| 29740.0 | 53 | 0.00035 | 17 | 0.00011 | 0.98113 | 0.01887 | 0.01923 | 0.01013 |
| 43780.0 | 110 | 0.00073 | 43 | 0.00029 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 47940.0 | 55 | 0.00037 | 10 | 0.00007 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 39380.0 | 55 | 0.00037 | 26 | 0.00017 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 45300.0 | 1327 | 0.00885 | 529 | 0.00353 | 0.98191 | 0.01809 | 0.01842 | 0.00932 |
| 29420.0 | 113 | 0.00075 | 52 | 0.00035 | 0.98230 | 0.01770 | 0.01802 | 0.00891 |
| 39660.0 | 58 | 0.00039 | 12 | 0.00008 | 0.98276 | 0.01724 | 0.01754 | 0.00844 |
| 45940.0 | 117 | 0.00078 | 34 | 0.00023 | 0.98291 | 0.01709 | 0.01739 | 0.00829 |
| 21340.0 | 118 | 0.00079 | 33 | 0.00022 | 0.98305 | 0.01695 | 0.01724 | 0.00814 |
| 39820.0 | 118 | 0.00079 | 43 | 0.00029 | 0.98305 | 0.01695 | 0.01724 | 0.00814 |
| 29620.0 | 241 | 0.00161 | 72 | 0.00048 | 0.98340 | 0.01660 | 0.01688 | 0.00777 |
| 12220.0 | 61 | 0.00041 | 32 | 0.00021 | 0.98361 | 0.01639 | 0.01667 | 0.00756 |
| 44140.0 | 183 | 0.00122 | 58 | 0.00039 | 0.98361 | 0.01639 | 0.01667 | 0.00756 |
| 37964.0 | 682 | 0.00455 | 197 | 0.00131 | 0.98387 | 0.01613 | 0.01639 | 0.00729 |
| 31340.0 | 125 | 0.00083 | 33 | 0.00022 | 0.98400 | 0.01600 | 0.01626 | 0.00716 |
| 25420.0 | 252 | 0.00168 | 73 | 0.00049 | 0.98413 | 0.01587 | 0.01613 | 0.00703 |
| 17020.0 | 127 | 0.00085 | 59 | 0.00039 | 0.98425 | 0.01575 | 0.01600 | 0.00690 |
| 15680.0 | 64 | 0.00043 | 11 | 0.00007 | 0.98438 | 0.01562 | 0.01587 | 0.00677 |
| 26420.0 | 2835 | 0.01890 | 960 | 0.00640 | 0.98483 | 0.01517 | 0.01540 | 0.00630 |
| 44100.0 | 66 | 0.00044 | 24 | 0.00016 | 0.98485 | 0.01515 | 0.01538 | 0.00628 |
| 15940.0 | 133 | 0.00089 | 41 | 0.00027 | 0.98496 | 0.01504 | 0.01527 | 0.00616 |
| 29200.0 | 67 | 0.00045 | 37 | 0.00025 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 20100.0 | 67 | 0.00045 | 22 | 0.00015 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 11700.0 | 201 | 0.00134 | 79 | 0.00053 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 35840.0 | 474 | 0.00316 | 202 | 0.00135 | 0.98523 | 0.01477 | 0.01499 | 0.00589 |
| 47300.0 | 136 | 0.00091 | 59 | 0.00039 | 0.98529 | 0.01471 | 0.01493 | 0.00582 |
| 23844.0 | 342 | 0.00228 | 131 | 0.00087 | 0.98538 | 0.01462 | 0.01484 | 0.00573 |
| 25060.0 | 69 | 0.00046 | 29 | 0.00019 | 0.98551 | 0.01449 | 0.01471 | 0.00560 |
| 14740.0 | 139 | 0.00093 | 65 | 0.00043 | 0.98561 | 0.01439 | 0.01460 | 0.00550 |
| 48424.0 | 699 | 0.00466 | 295 | 0.00197 | 0.98569 | 0.01431 | 0.01451 | 0.00541 |
| 36420.0 | 423 | 0.00282 | 174 | 0.00116 | 0.98582 | 0.01418 | 0.01439 | 0.00529 |
| 28700.0 | 71 | 0.00047 | 20 | 0.00013 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 26620.0 | 213 | 0.00142 | 69 | 0.00046 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 35380.0 | 429 | 0.00286 | 132 | 0.00088 | 0.98601 | 0.01399 | 0.01418 | 0.00508 |
| 15500.0 | 72 | 0.00048 | 24 | 0.00016 | 0.98611 | 0.01389 | 0.01408 | 0.00498 |
| 42540.0 | 145 | 0.00097 | 24 | 0.00016 | 0.98621 | 0.01379 | 0.01399 | 0.00488 |
| 34820.0 | 363 | 0.00242 | 114 | 0.00076 | 0.98623 | 0.01377 | 0.01397 | 0.00486 |
| 24540.0 | 218 | 0.00145 | 106 | 0.00071 | 0.98624 | 0.01376 | 0.01395 | 0.00485 |
| 17460.0 | 728 | 0.00485 | 247 | 0.00165 | 0.98626 | 0.01374 | 0.01393 | 0.00482 |
| 20994.0 | 366 | 0.00244 | 195 | 0.00130 | 0.98634 | 0.01366 | 0.01385 | 0.00475 |
| 10420.0 | 297 | 0.00198 | 119 | 0.00079 | 0.98653 | 0.01347 | 0.01365 | 0.00455 |
| 19380.0 | 149 | 0.00099 | 11 | 0.00007 | 0.98658 | 0.01342 | 0.01361 | 0.00450 |
| 16974.0 | 2181 | 0.01454 | 166 | 0.00111 | 0.98670 | 0.01330 | 0.01348 | 0.00437 |
| 27140.0 | 154 | 0.00103 | 42 | 0.00028 | 0.98701 | 0.01299 | 0.01316 | 0.00405 |
| 19300.0 | 78 | 0.00052 | 38 | 0.00025 | 0.98718 | 0.01282 | 0.01299 | 0.00388 |
| 34740.0 | 78 | 0.00052 | 35 | 0.00023 | 0.98718 | 0.01282 | 0.01299 | 0.00388 |
| 39740.0 | 158 | 0.00105 | 41 | 0.00027 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 28940.0 | 316 | 0.00211 | 115 | 0.00077 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 22220.0 | 237 | 0.00158 | 95 | 0.00063 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 38860.0 | 323 | 0.00215 | 83 | 0.00055 | 0.98762 | 0.01238 | 0.01254 | 0.00344 |
| 33780.0 | 81 | 0.00054 | 21 | 0.00014 | 0.98765 | 0.01235 | 0.01250 | 0.00340 |
| 29940.0 | 82 | 0.00055 | 22 | 0.00015 | 0.98780 | 0.01220 | 0.01235 | 0.00324 |
| 14484.0 | 83 | 0.00055 | 5 | 0.00003 | 0.98795 | 0.01205 | 0.01220 | 0.00309 |
| 37460.0 | 85 | 0.00057 | 25 | 0.00017 | 0.98824 | 0.01176 | 0.01190 | 0.00280 |
| 46220.0 | 86 | 0.00057 | 26 | 0.00017 | 0.98837 | 0.01163 | 0.01176 | 0.00266 |
| 36540.0 | 351 | 0.00234 | 128 | 0.00085 | 0.98860 | 0.01140 | 0.01153 | 0.00242 |
| 39300.0 | 705 | 0.00470 | 224 | 0.00149 | 0.98865 | 0.01135 | 0.01148 | 0.00237 |
| 23420.0 | 356 | 0.00237 | 146 | 0.00097 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 24300.0 | 89 | 0.00059 | 37 | 0.00025 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 49700.0 | 89 | 0.00059 | 26 | 0.00017 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 39100.0 | 180 | 0.00120 | 107 | 0.00071 | 0.98889 | 0.01111 | 0.01124 | 0.00213 |
| 35980.0 | 90 | 0.00060 | 23 | 0.00015 | 0.98889 | 0.01111 | 0.01124 | 0.00213 |
| 20260.0 | 180 | 0.00120 | 64 | 0.00043 | 0.98889 | 0.01111 | 0.01124 | 0.00213 |
| 31140.0 | 632 | 0.00421 | 220 | 0.00147 | 0.98892 | 0.01108 | 0.01120 | 0.00210 |
| 10900.0 | 364 | 0.00243 | 102 | 0.00068 | 0.98901 | 0.01099 | 0.01111 | 0.00201 |
| 21140.0 | 92 | 0.00061 | 26 | 0.00017 | 0.98913 | 0.01087 | 0.01099 | 0.00189 |
| 36260.0 | 372 | 0.00248 | 168 | 0.00112 | 0.98925 | 0.01075 | 0.01087 | 0.00177 |
| 15980.0 | 373 | 0.00249 | 156 | 0.00104 | 0.98928 | 0.01072 | 0.01084 | 0.00174 |
| 35300.0 | 379 | 0.00253 | 101 | 0.00067 | 0.98945 | 0.01055 | 0.01067 | 0.00156 |
| 41620.0 | 772 | 0.00515 | 339 | 0.00226 | 0.98964 | 0.01036 | 0.01047 | 0.00137 |
| 33700.0 | 293 | 0.00195 | 120 | 0.00080 | 0.98976 | 0.01024 | 0.01034 | 0.00124 |
| 11540.0 | 98 | 0.00065 | 37 | 0.00025 | 0.98980 | 0.01020 | 0.01031 | 0.00121 |
| 12020.0 | 100 | 0.00067 | 32 | 0.00021 | 0.99000 | 0.01000 | 0.01010 | 0.00100 |
| 16700.0 | 406 | 0.00271 | 158 | 0.00105 | 0.99015 | 0.00985 | 0.00995 | 0.00085 |
| 11260.0 | 203 | 0.00135 | 55 | 0.00037 | 0.99015 | 0.00985 | 0.00995 | 0.00085 |
| 46520.0 | 317 | 0.00211 | 115 | 0.00077 | 0.99054 | 0.00946 | 0.00955 | 0.00045 |
| 40060.0 | 637 | 0.00425 | 202 | 0.00135 | 0.99058 | 0.00942 | 0.00951 | 0.00041 |
| 48864.0 | 319 | 0.00213 | 99 | 0.00066 | 0.99060 | 0.00940 | 0.00949 | 0.00039 |
| 14010.0 | 107 | 0.00071 | 38 | 0.00025 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 33860.0 | 107 | 0.00071 | 30 | 0.00020 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 47260.0 | 654 | 0.00436 | 171 | 0.00114 | 0.99083 | 0.00917 | 0.00926 | 0.00016 |
| 41700.0 | 654 | 0.00436 | 253 | 0.00169 | 0.99083 | 0.00917 | 0.00926 | 0.00016 |
| 17140.0 | 1428 | 0.00952 | 429 | 0.00286 | 0.99090 | 0.00910 | 0.00919 | 0.00008 |
| 23104.0 | 1001 | 0.00667 | 454 | 0.00303 | 0.99101 | 0.00899 | 0.00907 | -0.00003 |
| 13740.0 | 112 | 0.00075 | 37 | 0.00025 | 0.99107 | 0.00893 | 0.00901 | -0.00009 |
| 43620.0 | 113 | 0.00075 | 44 | 0.00029 | 0.99115 | 0.00885 | 0.00893 | -0.00017 |
| 33340.0 | 792 | 0.00528 | 265 | 0.00177 | 0.99116 | 0.00884 | 0.00892 | -0.00019 |
| 10740.0 | 340 | 0.00227 | 95 | 0.00063 | 0.99118 | 0.00882 | 0.00890 | -0.00020 |
| 39540.0 | 114 | 0.00076 | 40 | 0.00027 | 0.99123 | 0.00877 | 0.00885 | -0.00025 |
| 45820.0 | 114 | 0.00076 | 50 | 0.00033 | 0.99123 | 0.00877 | 0.00885 | -0.00025 |
| 40380.0 | 459 | 0.00306 | 147 | 0.00098 | 0.99129 | 0.00871 | 0.00879 | -0.00031 |
| 12060.0 | 2894 | 0.01930 | 1040 | 0.00693 | 0.99136 | 0.00864 | 0.00871 | -0.00039 |
| 17780.0 | 116 | 0.00077 | 34 | 0.00023 | 0.99138 | 0.00862 | 0.00870 | -0.00041 |
| 16860.0 | 234 | 0.00156 | 90 | 0.00060 | 0.99145 | 0.00855 | 0.00862 | -0.00048 |
| 13820.0 | 471 | 0.00314 | 144 | 0.00096 | 0.99151 | 0.00849 | 0.00857 | -0.00054 |
| 44180.0 | 237 | 0.00158 | 77 | 0.00051 | 0.99156 | 0.00844 | 0.00851 | -0.00059 |
| 29820.0 | 1079 | 0.00719 | 442 | 0.00295 | 0.99166 | 0.00834 | 0.00841 | -0.00069 |
| 17660.0 | 120 | 0.00080 | 47 | 0.00031 | 0.99167 | 0.00833 | 0.00840 | -0.00070 |
| 35004.0 | 1085 | 0.00723 | 332 | 0.00221 | 0.99171 | 0.00829 | 0.00836 | -0.00074 |
| 25860.0 | 121 | 0.00081 | 40 | 0.00027 | 0.99174 | 0.00826 | 0.00833 | -0.00077 |
| 49180.0 | 247 | 0.00165 | 82 | 0.00055 | 0.99190 | 0.00810 | 0.00816 | -0.00094 |
| 17860.0 | 124 | 0.00083 | 37 | 0.00025 | 0.99194 | 0.00806 | 0.00813 | -0.00097 |
| 23540.0 | 125 | 0.00083 | 33 | 0.00022 | 0.99200 | 0.00800 | 0.00806 | -0.00104 |
| 24860.0 | 376 | 0.00251 | 137 | 0.00091 | 0.99202 | 0.00798 | 0.00804 | -0.00106 |
| 48620.0 | 253 | 0.00169 | 68 | 0.00045 | 0.99209 | 0.00791 | 0.00797 | -0.00113 |
| 31700.0 | 255 | 0.00170 | 70 | 0.00047 | 0.99216 | 0.00784 | 0.00791 | -0.00120 |
| 43524.0 | 273 | 0.00182 | 13 | 0.00009 | 0.99267 | 0.00733 | 0.00738 | -0.00172 |
| 37860.0 | 138 | 0.00092 | 52 | 0.00035 | 0.99275 | 0.00725 | 0.00730 | -0.00180 |
| 38060.0 | 2773 | 0.01849 | 1132 | 0.00755 | 0.99279 | 0.00721 | 0.00726 | -0.00184 |
| 12580.0 | 1423 | 0.00949 | 394 | 0.00263 | 0.99297 | 0.00703 | 0.00708 | -0.00203 |
| 42034.0 | 144 | 0.00096 | 30 | 0.00020 | 0.99306 | 0.00694 | 0.00699 | -0.00211 |
| 40220.0 | 145 | 0.00097 | 42 | 0.00028 | 0.99310 | 0.00690 | 0.00694 | -0.00216 |
| 37100.0 | 583 | 0.00389 | 142 | 0.00095 | 0.99314 | 0.00686 | 0.00691 | -0.00219 |
| 37340.0 | 298 | 0.00199 | 125 | 0.00083 | 0.99329 | 0.00671 | 0.00676 | -0.00235 |
| 16984.0 | 2092 | 0.01395 | 1340 | 0.00893 | 0.99331 | 0.00669 | 0.00674 | -0.00237 |
| 19340.0 | 151 | 0.00101 | 36 | 0.00024 | 0.99338 | 0.00662 | 0.00667 | -0.00244 |
| 30780.0 | 311 | 0.00207 | 116 | 0.00077 | 0.99357 | 0.00643 | 0.00647 | -0.00263 |
| 19124.0 | 2346 | 0.01564 | 1031 | 0.00687 | 0.99361 | 0.00639 | 0.00644 | -0.00267 |
| 15764.0 | 1282 | 0.00855 | 421 | 0.00281 | 0.99376 | 0.00624 | 0.00628 | -0.00282 |
| 16740.0 | 1336 | 0.00891 | 461 | 0.00307 | 0.99401 | 0.00599 | 0.00602 | -0.00308 |
| 38900.0 | 1845 | 0.01230 | 735 | 0.00490 | 0.99404 | 0.00596 | 0.00600 | -0.00311 |
| 16580.0 | 168 | 0.00112 | 43 | 0.00029 | 0.99405 | 0.00595 | 0.00599 | -0.00311 |
| 31084.0 | 4557 | 0.03038 | 1279 | 0.00853 | 0.99408 | 0.00592 | 0.00596 | -0.00314 |
| 47894.0 | 2951 | 0.01968 | 772 | 0.00515 | 0.99424 | 0.00576 | 0.00579 | -0.00331 |
| 30700.0 | 175 | 0.00117 | 57 | 0.00038 | 0.99429 | 0.00571 | 0.00575 | -0.00336 |
| 34980.0 | 1227 | 0.00818 | 456 | 0.00304 | 0.99430 | 0.00570 | 0.00574 | -0.00337 |
| 24340.0 | 709 | 0.00473 | 251 | 0.00167 | 0.99436 | 0.00564 | 0.00567 | -0.00343 |
| 41180.0 | 1787 | 0.01191 | 527 | 0.00351 | 0.99440 | 0.00560 | 0.00563 | -0.00348 |
| 45104.0 | 358 | 0.00239 | 170 | 0.00113 | 0.99441 | 0.00559 | 0.00562 | -0.00349 |
| 42100.0 | 181 | 0.00121 | 53 | 0.00035 | 0.99448 | 0.00552 | 0.00556 | -0.00355 |
| 35614.0 | 2541 | 0.01694 | 850 | 0.00567 | 0.99449 | 0.00551 | 0.00554 | -0.00356 |
| 10580.0 | 365 | 0.00243 | 111 | 0.00074 | 0.99452 | 0.00548 | 0.00551 | -0.00359 |
| 12260.0 | 187 | 0.00125 | 52 | 0.00035 | 0.99465 | 0.00535 | 0.00538 | -0.00373 |
| 21660.0 | 188 | 0.00125 | 68 | 0.00045 | 0.99468 | 0.00532 | 0.00535 | -0.00376 |
| 41740.0 | 1890 | 0.01260 | 551 | 0.00367 | 0.99471 | 0.00529 | 0.00532 | -0.00378 |
| 49620.0 | 191 | 0.00127 | 57 | 0.00038 | 0.99476 | 0.00524 | 0.00526 | -0.00384 |
| 32820.0 | 385 | 0.00257 | 150 | 0.00100 | 0.99481 | 0.00519 | 0.00522 | -0.00388 |
| 14860.0 | 387 | 0.00258 | 104 | 0.00069 | 0.99483 | 0.00517 | 0.00519 | -0.00391 |
| 33460.0 | 2537 | 0.01692 | 847 | 0.00565 | 0.99488 | 0.00512 | 0.00515 | -0.00395 |
| 14454.0 | 1003 | 0.00669 | 287 | 0.00191 | 0.99501 | 0.00499 | 0.00501 | -0.00409 |
| 22020.0 | 202 | 0.00135 | 37 | 0.00025 | 0.99505 | 0.00495 | 0.00498 | -0.00413 |
| 12700.0 | 203 | 0.00135 | 63 | 0.00042 | 0.99507 | 0.00493 | 0.00495 | -0.00415 |
| 19430.0 | 205 | 0.00137 | 86 | 0.00057 | 0.99512 | 0.00488 | 0.00490 | -0.00420 |
| 35084.0 | 821 | 0.00547 | 307 | 0.00205 | 0.99513 | 0.00487 | 0.00490 | -0.00421 |
| 40140.0 | 2523 | 0.01682 | 1000 | 0.00667 | 0.99524 | 0.00476 | 0.00478 | -0.00432 |
| 39340.0 | 429 | 0.00286 | 192 | 0.00128 | 0.99534 | 0.00466 | 0.00468 | -0.00442 |
| 41540.0 | 216 | 0.00144 | 69 | 0.00046 | 0.99537 | 0.00463 | 0.00465 | -0.00445 |
| 23060.0 | 223 | 0.00149 | 75 | 0.00050 | 0.99552 | 0.00448 | 0.00450 | -0.00460 |
| 39580.0 | 937 | 0.00625 | 300 | 0.00200 | 0.99573 | 0.00427 | 0.00429 | -0.00482 |
| 12420.0 | 1221 | 0.00814 | 439 | 0.00293 | 0.99590 | 0.00410 | 0.00411 | -0.00499 |
| 39900.0 | 264 | 0.00176 | 105 | 0.00070 | 0.99621 | 0.00379 | 0.00380 | -0.00530 |
| 26900.0 | 1061 | 0.00707 | 452 | 0.00301 | 0.99623 | 0.00377 | 0.00378 | -0.00532 |
| 38300.0 | 800 | 0.00533 | 271 | 0.00181 | 0.99625 | 0.00375 | 0.00376 | -0.00534 |
| 40900.0 | 1614 | 0.01076 | 619 | 0.00413 | 0.99628 | 0.00372 | 0.00373 | -0.00537 |
| 44060.0 | 269 | 0.00179 | 106 | 0.00071 | 0.99628 | 0.00372 | 0.00373 | -0.00537 |
| 35644.0 | 272 | 0.00181 | 19 | 0.00013 | 0.99632 | 0.00368 | 0.00369 | -0.00541 |
| 18140.0 | 1093 | 0.00729 | 372 | 0.00248 | 0.99634 | 0.00366 | 0.00367 | -0.00543 |
| 19660.0 | 277 | 0.00185 | 121 | 0.00081 | 0.99639 | 0.00361 | 0.00362 | -0.00548 |
| 36084.0 | 1945 | 0.01297 | 473 | 0.00315 | 0.99640 | 0.00360 | 0.00361 | -0.00549 |
| 19804.0 | 565 | 0.00377 | 268 | 0.00179 | 0.99646 | 0.00354 | 0.00355 | -0.00555 |
| 17900.0 | 290 | 0.00193 | 102 | 0.00068 | 0.99655 | 0.00345 | 0.00346 | -0.00564 |
| 47664.0 | 1482 | 0.00988 | 685 | 0.00457 | 0.99663 | 0.00337 | 0.00339 | -0.00572 |
| 19740.0 | 2387 | 0.01591 | 941 | 0.00627 | 0.99665 | 0.00335 | 0.00336 | -0.00574 |
| 40484.0 | 308 | 0.00205 | 76 | 0.00051 | 0.99675 | 0.00325 | 0.00326 | -0.00585 |
| 17820.0 | 309 | 0.00206 | 171 | 0.00114 | 0.99676 | 0.00324 | 0.00325 | -0.00586 |
| 46700.0 | 313 | 0.00209 | 101 | 0.00067 | 0.99681 | 0.00319 | 0.00321 | -0.00590 |
| 28140.0 | 1299 | 0.00866 | 395 | 0.00263 | 0.99692 | 0.00308 | 0.00309 | -0.00601 |
| 30460.0 | 335 | 0.00223 | 106 | 0.00071 | 0.99701 | 0.00299 | 0.00299 | -0.00611 |
| 35154.0 | 707 | 0.00471 | 438 | 0.00292 | 0.99717 | 0.00283 | 0.00284 | -0.00627 |
| 15380.0 | 356 | 0.00237 | 115 | 0.00077 | 0.99719 | 0.00281 | 0.00282 | -0.00629 |
| 19780.0 | 360 | 0.00240 | 147 | 0.00098 | 0.99722 | 0.00278 | 0.00279 | -0.00632 |
| 44700.0 | 370 | 0.00247 | 175 | 0.00117 | 0.99730 | 0.00270 | 0.00271 | -0.00639 |
| 42220.0 | 375 | 0.00250 | 113 | 0.00075 | 0.99733 | 0.00267 | 0.00267 | -0.00643 |
| 31540.0 | 390 | 0.00260 | 114 | 0.00076 | 0.99744 | 0.00256 | 0.00257 | -0.00653 |
| 14260.0 | 418 | 0.00279 | 153 | 0.00102 | 0.99761 | 0.00239 | 0.00240 | -0.00670 |
| 23224.0 | 456 | 0.00304 | 160 | 0.00107 | 0.99781 | 0.00219 | 0.00220 | -0.00691 |
| 46060.0 | 477 | 0.00318 | 185 | 0.00123 | 0.99790 | 0.00210 | 0.00210 | -0.00700 |
| 25540.0 | 519 | 0.00346 | 157 | 0.00105 | 0.99807 | 0.00193 | 0.00193 | -0.00717 |
| 29404.0 | 527 | 0.00351 | 206 | 0.00137 | 0.99810 | 0.00190 | 0.00190 | -0.00720 |
| 41940.0 | 1068 | 0.00712 | 212 | 0.00141 | 0.99813 | 0.00187 | 0.00188 | -0.00723 |
| 11244.0 | 1840 | 0.01227 | 462 | 0.00308 | 0.99837 | 0.00163 | 0.00163 | -0.00747 |
| 41884.0 | 683 | 0.00455 | 105 | 0.00070 | 0.99854 | 0.00146 | 0.00147 | -0.00764 |
| 33874.0 | 909 | 0.00606 | 297 | 0.00198 | 0.99890 | 0.00110 | 0.00110 | -0.00800 |
| 42644.0 | 1857 | 0.01238 | 752 | 0.00501 | 0.99892 | 0.00108 | 0.00108 | -0.00802 |
| 47580.0 | 48 | 0.00032 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49660.0 | 160 | 0.00107 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49020.0 | 74 | 0.00049 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49420.0 | 60 | 0.00040 | 37 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48060.0 | 14 | 0.00009 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48140.0 | 66 | 0.00044 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48260.0 | 14 | 0.00009 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47460.0 | 27 | 0.00018 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48540.0 | 27 | 0.00018 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48660.0 | 13 | 0.00009 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48700.0 | 33 | 0.00022 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10540.0 | 36 | 0.00024 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 48300.0 | 96 | 0.00064 | 30 | 0.00020 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43420.0 | 22 | 0.00015 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10780.0 | 23 | 0.00015 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40340.0 | 133 | 0.00089 | 51 | 0.00034 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42044.0 | 92 | 0.00061 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11300.0 | 9 | 0.00006 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44940.0 | 26 | 0.00017 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42060.0 | 14 | 0.00009 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44600.0 | 7 | 0.00005 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44420.0 | 40 | 0.00027 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42140.0 | 79 | 0.00053 | 21 | 0.00014 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44300.0 | 58 | 0.00039 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44220.0 | 52 | 0.00035 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42200.0 | 196 | 0.00131 | 59 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42340.0 | 169 | 0.00113 | 38 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39150.0 | 56 | 0.00037 | 60 | 0.00040 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11500.0 | 32 | 0.00021 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42700.0 | 26 | 0.00017 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43100.0 | 45 | 0.00030 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43300.0 | 58 | 0.00039 | 26 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11340.0 | 16 | 0.00011 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45220.0 | 149 | 0.00099 | 66 | 0.00044 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42020.0 | 205 | 0.00137 | 53 | 0.00035 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41980.0 | 6 | 0.00004 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11180.0 | 35 | 0.00023 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47220.0 | 32 | 0.00021 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40420.0 | 113 | 0.00075 | 44 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11020.0 | 39 | 0.00026 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46540.0 | 63 | 0.00042 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46300.0 | 33 | 0.00022 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40660.0 | 34 | 0.00023 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11460.0 | 201 | 0.00134 | 77 | 0.00051 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40980.0 | 52 | 0.00035 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41780.0 | 5 | 0.00003 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41060.0 | 113 | 0.00075 | 41 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41100.0 | 126 | 0.00084 | 80 | 0.00053 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41140.0 | 25 | 0.00017 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41420.0 | 189 | 0.00126 | 97 | 0.00065 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41500.0 | 169 | 0.00113 | 66 | 0.00044 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45500.0 | 23 | 0.00015 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45460.0 | 89 | 0.00059 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43900.0 | 133 | 0.00089 | 45 | 0.00030 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 33220.0 | 32 | 0.00021 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39140.0 | 81 | 0.00054 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25180.0 | 104 | 0.00069 | 29 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22900.0 | 42 | 0.00028 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 23460.0 | 33 | 0.00022 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14540.0 | 90 | 0.00060 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 23900.0 | 29 | 0.00019 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24020.0 | 32 | 0.00021 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24140.0 | 21 | 0.00014 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14500.0 | 247 | 0.00165 | 95 | 0.00063 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24260.0 | 32 | 0.00021 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24420.0 | 39 | 0.00026 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24580.0 | 177 | 0.00118 | 60 | 0.00040 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24660.0 | 280 | 0.00187 | 97 | 0.00065 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24780.0 | 55 | 0.00037 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25260.0 | 35 | 0.00023 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22540.0 | 34 | 0.00023 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25500.0 | 55 | 0.00037 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25620.0 | 31 | 0.00021 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25940.0 | 94 | 0.00063 | 44 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25980.0 | 7 | 0.00005 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26100.0 | 17 | 0.00011 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14100.0 | 17 | 0.00011 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14060.0 | 5 | 0.00003 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26380.0 | 49 | 0.00033 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26580.0 | 89 | 0.00059 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26820.0 | 55 | 0.00037 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26980.0 | 62 | 0.00041 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27060.0 | 15 | 0.00010 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22660.0 | 261 | 0.00174 | 125 | 0.00083 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22520.0 | 52 | 0.00035 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38940.0 | 211 | 0.00141 | 87 | 0.00058 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 20220.0 | 50 | 0.00033 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16820.0 | 122 | 0.00081 | 39 | 0.00026 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16220.0 | 38 | 0.00025 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17300.0 | 69 | 0.00046 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16060.0 | 45 | 0.00030 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18580.0 | 114 | 0.00076 | 32 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18700.0 | 70 | 0.00047 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19060.0 | 14 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19180.0 | 14 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19260.0 | 4 | 0.00003 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19460.0 | 31 | 0.00021 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19500.0 | 37 | 0.00025 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15540.0 | 224 | 0.00149 | 55 | 0.00037 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 20500.0 | 290 | 0.00193 | 116 | 0.00077 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22500.0 | 50 | 0.00033 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 20524.0 | 29 | 0.00019 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 20740.0 | 77 | 0.00051 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 20940.0 | 43 | 0.00029 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15180.0 | 42 | 0.00028 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21300.0 | 29 | 0.00019 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21420.0 | 9 | 0.00006 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21500.0 | 56 | 0.00037 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21780.0 | 164 | 0.00109 | 67 | 0.00045 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21820.0 | 16 | 0.00011 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22140.0 | 26 | 0.00017 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22180.0 | 94 | 0.00063 | 29 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22380.0 | 87 | 0.00058 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27100.0 | 68 | 0.00045 | 31 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27180.0 | 35 | 0.00023 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14020.0 | 54 | 0.00036 | 30 | 0.00020 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 34620.0 | 39 | 0.00026 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 31900.0 | 35 | 0.00023 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 32580.0 | 79 | 0.00053 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 32780.0 | 110 | 0.00073 | 54 | 0.00036 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13220.0 | 22 | 0.00015 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12980.0 | 48 | 0.00032 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 33140.0 | 41 | 0.00027 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16540.0 | 35 | 0.00023 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 33260.0 | 86 | 0.00057 | 30 | 0.00020 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 33540.0 | 88 | 0.00059 | 31 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 34060.0 | 63 | 0.00042 | 31 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 34100.0 | 24 | 0.00016 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12620.0 | 30 | 0.00020 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 34900.0 | 88 | 0.00059 | 29 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27340.0 | 34 | 0.00023 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 35660.0 | 56 | 0.00037 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36140.0 | 67 | 0.00045 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36220.0 | 29 | 0.00019 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36500.0 | 113 | 0.00075 | 40 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36780.0 | 53 | 0.00035 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36980.0 | 63 | 0.00042 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 37620.0 | 16 | 0.00011 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 37700.0 | 8 | 0.00005 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 37900.0 | 176 | 0.00117 | 66 | 0.00044 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38220.0 | 14 | 0.00009 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38340.0 | 37 | 0.00025 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38540.0 | 35 | 0.00023 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 31860.0 | 53 | 0.00035 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 31740.0 | 68 | 0.00045 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13380.0 | 124 | 0.00083 | 52 | 0.00035 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13460.0 | 198 | 0.00132 | 72 | 0.00048 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27500.0 | 89 | 0.00059 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27620.0 | 47 | 0.00031 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27740.0 | 40 | 0.00027 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27780.0 | 24 | 0.00016 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27860.0 | 42 | 0.00028 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27980.0 | 49 | 0.00033 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28020.0 | 140 | 0.00093 | 45 | 0.00030 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13900.0 | 75 | 0.00050 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28420.0 | 108 | 0.00072 | 50 | 0.00033 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28660.0 | 66 | 0.00044 | 32 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28740.0 | 82 | 0.00055 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29020.0 | 34 | 0.00023 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29100.0 | 41 | 0.00027 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29140.0 | 8 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13780.0 | 35 | 0.00023 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29540.0 | 236 | 0.00157 | 60 | 0.00040 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29700.0 | 40 | 0.00027 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30020.0 | 13 | 0.00009 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30300.0 | 15 | 0.00010 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30340.0 | 26 | 0.00017 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30620.0 | 45 | 0.00030 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30860.0 | 73 | 0.00049 | 36 | 0.00024 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30980.0 | 49 | 0.00033 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 31020.0 | 37 | 0.00025 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 31180.0 | 101 | 0.00067 | 47 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10180.0 | 55 | 0.00037 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
# cnt_borr
# create table from train data
df_vis_train = df_train.groupby("cnt_borr")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['cnt_borr']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['cnt_borr']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_cnt_borr = pd.merge(df_join1,df_join2 ,on='cnt_borr',how='outer')
df_cnt_borr = df_cnt_borr.set_index("cnt_borr")
df_cnt_borr = df_cnt_borr[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_cnt_borr.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| cnt_borr | ||||||||
| 1 | 71758 | 0.47843 | 26174 | 0.17451 | 0.98700 | 0.01300 | 0.01317 | 0.00407 |
| 2 | 78227 | 0.52157 | 23841 | 0.15896 | 0.99463 | 0.00537 | 0.00540 | -0.00371 |
# flag_fthb
# create table from train data
df_vis_train = df_train.groupby("flag_fthb")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['flag_fthb']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['flag_fthb']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_flag_fthb = pd.merge(df_join1,df_join2 ,on='flag_fthb',how='outer')
df_flag_fthb = df_flag_fthb.set_index("flag_fthb")
df_flag_fthb = df_flag_fthb[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_flag_fthb.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| flag_fthb | ||||||||
| 9 | 10 | 0.00007 | Missings | Missings | 0.90000 | 0.10000 | 0.11111 | 0.10201 |
| N | 128784 | 0.85865 | 39046 | 0.26033 | 0.99096 | 0.00904 | 0.00912 | 0.00002 |
| Y | 21191 | 0.14129 | 10969 | 0.07313 | 0.99113 | 0.00887 | 0.00895 | -0.00015 |
# flag_sc
# create table from train data
df_vis_train = df_train.groupby("flag_sc")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['flag_sc']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['flag_sc']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_flag_sc = pd.merge(df_join1,df_join2 ,on='flag_sc',how='outer')
df_flag_sc = df_flag_sc.set_index("flag_sc")
df_flag_sc = df_flag_sc[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault', 'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_flag_sc.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| flag_sc | ||||||||
| Y | 5004 | 0.03336 | 1933 | 0.01289 | 0.99560 | 0.00440 | 0.00442 | -0.00469 |
# int_only_ind
# create table from train data
df_vis_train = df_train.groupby("int_only_ind")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['int_only_ind']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['int_only_ind']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_int_only_ind = pd.merge(df_join1,df_join2 ,on='int_only_ind',how='outer')
df_int_only_ind = df_int_only_ind.set_index("int_only_ind")
df_int_only_ind = df_int_only_ind[['Count_Train', 'Ratio_Cat_Train',
'Count_Test', 'Ratio_Cat_Test',
'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_int_only_ind.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| int_only_ind | ||||||||
| N | 149985 | 1.00000 | 50015 | 0.33347 | 0.99098 | 0.00902 | 0.00910 | 0.00000 |
# loan_purpose
# create table from train data
df_vis_train = df_train.groupby("loan_purpose")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['loan_purpose']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['loan_purpose']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_loan_purpose = pd.merge(df_join1,df_join2 ,on='loan_purpose',how='outer')
df_loan_purpose = df_loan_purpose.set_index("loan_purpose")
df_loan_purpose = df_loan_purpose[['Count_Train', 'Ratio_Cat_Train',
'Count_Test', 'Ratio_Cat_Test',
'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_loan_purpose.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| loan_purpose | ||||||||
| N | 60666 | 0.40448 | 10017 | 0.06679 | 0.98802 | 0.01198 | 0.01213 | 0.00303 |
| C | 27012 | 0.18010 | 11451 | 0.07635 | 0.99245 | 0.00755 | 0.00761 | -0.00149 |
| P | 62307 | 0.41542 | 28547 | 0.19033 | 0.99323 | 0.00677 | 0.00682 | -0.00228 |
# occpy_sts
# create table from train data
df_vis_train = df_train.groupby("occpy_sts")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['occpy_sts']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['occpy_sts']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_occpy_sts = pd.merge(df_join1,df_join2 ,on='occpy_sts',how='outer')
df_occpy_sts = df_occpy_sts.set_index("occpy_sts")
df_occpy_sts = df_occpy_sts[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_occpy_sts.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| occpy_sts | ||||||||
| I | 14071 | 0.09382 | 4656 | 0.03104 | 0.99026 | 0.00974 | 0.00983 | 0.00073 |
| P | 130237 | 0.86833 | 43547 | 0.29034 | 0.99087 | 0.00913 | 0.00921 | 0.00011 |
| S | 5677 | 0.03785 | 1812 | 0.01208 | 0.99524 | 0.00476 | 0.00478 | -0.00432 |
# pgrm_ind
# create table from train data
df_vis_train = df_train.groupby("pgrm_ind")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['pgrm_ind']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['pgrm_ind']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_pgrm_ind = pd.merge(df_join1,df_join2 ,on='pgrm_ind',how='outer')
df_pgrm_ind = df_pgrm_ind.set_index("pgrm_ind")
df_pgrm_ind = df_pgrm_ind[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_pgrm_ind.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| pgrm_ind | ||||||||
| F | 12 | 0.00008 | 180 | 0.00120 | 0.83333 | 0.16667 | 0.20000 | 0.19090 |
| H | 278 | 0.00185 | 3443 | 0.02296 | 0.97842 | 0.02158 | 0.02206 | 0.01296 |
| 9 | 51681 | 0.34457 | Missings | Missings | 0.99089 | 0.00911 | 0.00920 | 0.00009 |
| 9 | 98014 | 0.65349 | 46392 | 0.30931 | 0.99108 | 0.00892 | 0.00900 | -0.00011 |
# ppmt_pnlty
# create table from train data
df_vis_train = df_train.groupby("ppmt_pnlty")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['ppmt_pnlty']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['ppmt_pnlty']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_ppmt_pnlty = pd.merge(df_join1,df_join2 ,on='ppmt_pnlty',how='outer')
df_ppmt_pnlty = df_ppmt_pnlty.set_index("ppmt_pnlty")
df_ppmt_pnlty = df_ppmt_pnlty[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_ppmt_pnlty.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| ppmt_pnlty | ||||||||
| N | 149985 | 1.00000 | 50015 | 0.33347 | 0.99098 | 0.00902 | 0.00910 | 0.00000 |
# prod_type
# create table from train data
df_vis_train = df_train.groupby("prod_type")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['prod_type']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['prod_type']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_prod_type = pd.merge(df_join1,df_join2 ,on='prod_type',how='outer')
df_prod_type = df_prod_type.set_index("prod_type")
df_prod_type = df_prod_type[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_prod_type.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| prod_type | ||||||||
| FRM | 149985 | 1.00000 | 50015 | 0.33347 | 0.99098 | 0.00902 | 0.00910 | 0.00000 |
# prop_type
# create table from train data
df_vis_train = df_train.groupby("prop_type")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['prop_type']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['prop_type']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_prop_type = pd.merge(df_join1,df_join2 ,on='prop_type',how='outer')
df_prop_type = df_prop_type.set_index("prop_type")
df_prop_type = df_prop_type[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_prop_type.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| prop_type | ||||||||
| SF | 100409 | 0.66946 | 32048 | 0.21367 | 0.99038 | 0.00962 | 0.00971 | 0.00061 |
| CO | 11832 | 0.07889 | 4426 | 0.02951 | 0.99180 | 0.00820 | 0.00827 | -0.00084 |
| PU | 36756 | 0.24506 | 13232 | 0.08822 | 0.99227 | 0.00773 | 0.00779 | -0.00132 |
| MH | 649 | 0.00433 | 232 | 0.00155 | 0.99384 | 0.00616 | 0.00620 | -0.00290 |
| CP | 339 | 0.00226 | 77 | 0.00051 | 0.99410 | 0.00590 | 0.00593 | -0.00317 |
# prop_val_meth
# create table from train data
df_vis_train = df_train.groupby("prop_val_meth")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['prop_val_meth']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['prop_val_meth']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_prop_val_meth = pd.merge(df_join1,df_join2 ,on='prop_val_meth',how='outer')
df_prop_val_meth = df_prop_val_meth.set_index("prop_val_meth")
df_prop_val_meth = df_prop_val_meth[['Count_Train', 'Ratio_Cat_Train',
'Count_Test', 'Ratio_Cat_Test',
'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_prop_val_meth.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| prop_val_meth | ||||||||
| 9 | 149985 | 1.00000 | 40 | 0.00027 | 0.99098 | 0.00902 | 0.00910 | 0.00000 |
| 1 | Missings | Missings | 474 | 0.00316 | Missings | Missings | Missings | Missings |
| 2 | Missings | Missings | 47691 | 0.31797 | Missings | Missings | Missings | Missings |
| 3 | Missings | Missings | 1810 | 0.01207 | Missings | Missings | Missings | Missings |
# rel_ref_ind
# create table from train data
df_vis_train = df_train.groupby("rel_ref_ind")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['rel_ref_ind']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['rel_ref_ind']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_rel_ref_ind = pd.merge(df_join1,df_join2 ,on='rel_ref_ind',how='outer')
df_rel_ref_ind = df_rel_ref_ind.set_index("rel_ref_ind")
df_rel_ref_ind = df_rel_ref_ind[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_rel_ref_ind.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| rel_ref_ind | ||||||||
| Y | 26148 | 0.17434 | 1808 | 0.01205 | 0.97828 | 0.02172 | 0.02220 | 0.01310 |
# seller_name
# create table from train data
df_vis_train = df_train.groupby("seller_name")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['seller_name']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['seller_name']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_seller_name = pd.merge(df_join1,df_join2 ,on='seller_name',how='outer')
df_seller_name = df_seller_name.set_index("seller_name")
df_seller_name = df_seller_name[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_seller_name.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| seller_name | ||||||||
| GREENLIGHT FINANCIAL SERVICES | 93 | 0.00062 | Missings | Missings | 0.93548 | 0.06452 | 0.06897 | 0.05986 |
| PACIFIC UNION FINANCIAL, LLC | 106 | 0.00071 | Missings | Missings | 0.95283 | 0.04717 | 0.04950 | 0.04040 |
| NATIONSTAR MORTGAGE LLC | 2996 | 0.01998 | 524 | 0.00349 | 0.97029 | 0.02971 | 0.03062 | 0.02151 |
| AMERIHOME MORTGAGE COMPANY, LLC | 653 | 0.00435 | 1714 | 0.01143 | 0.97856 | 0.02144 | 0.02191 | 0.01281 |
| DITECH FINANCIAL LLC | 173 | 0.00115 | Missings | Missings | 0.98266 | 0.01734 | 0.01765 | 0.00854 |
| CITIMORTGAGE, INC. | 5249 | 0.03500 | 139 | 0.00093 | 0.98457 | 0.01543 | 0.01567 | 0.00657 |
| FLAGSTAR BANK, FSB | 2012 | 0.01341 | 1027 | 0.00685 | 0.98608 | 0.01392 | 0.01411 | 0.00501 |
| PRIMELENDING, A PLAINSCAPITAL COMPANY | 157 | 0.00105 | 173 | 0.00115 | 0.98726 | 0.01274 | 0.01290 | 0.00380 |
| CALIBER HOME LOANS, INC. | 2688 | 0.01792 | 2377 | 0.01585 | 0.98735 | 0.01265 | 0.01281 | 0.00371 |
| QUICKEN LOANS INC. | 6521 | 0.04348 | 3660 | 0.02440 | 0.98819 | 0.01181 | 0.01195 | 0.00285 |
| STEARNS LENDING, LLC | 1696 | 0.01131 | 625 | 0.00417 | 0.98880 | 0.01120 | 0.01133 | 0.00223 |
| WELLS FARGO BANK, N.A. | 21336 | 0.14225 | 6700 | 0.04467 | 0.98992 | 0.01008 | 0.01018 | 0.00108 |
| FIFTH THIRD MORTGAGE COMPANY | 204 | 0.00136 | 180 | 0.00120 | 0.99020 | 0.00980 | 0.00990 | 0.00080 |
| PNC BANK, NA | 928 | 0.00619 | Missings | Missings | 0.99030 | 0.00970 | 0.00979 | 0.00069 |
| JPMORGAN CHASE BANK, N.A. | 12394 | 0.08263 | 4280 | 0.02854 | 0.99153 | 0.00847 | 0.00854 | -0.00056 |
| FIFTH THIRD BANK | 1535 | 0.01023 | Missings | Missings | 0.99153 | 0.00847 | 0.00854 | -0.00056 |
| PENNYMAC CORP. | 2397 | 0.01598 | Missings | Missings | 0.99166 | 0.00834 | 0.00841 | -0.00069 |
| Other sellers | 49182 | 0.32791 | 18067 | 0.12046 | 0.99189 | 0.00811 | 0.00818 | -0.00092 |
| LOANDEPOT.COM, LLC | 1884 | 0.01256 | 1244 | 0.00829 | 0.99204 | 0.00796 | 0.00803 | -0.00108 |
| CALIBER FUNDING LLC | 128 | 0.00085 | Missings | Missings | 0.99219 | 0.00781 | 0.00787 | -0.00123 |
| UNITED SHORE FINANCIAL SERVICES, LLC., DBA SHORE MORTGAGE | 1806 | 0.01204 | Missings | Missings | 0.99225 | 0.00775 | 0.00781 | -0.00129 |
| PHH MORTGAGE CORPORATION | 1370 | 0.00913 | Missings | Missings | 0.99270 | 0.00730 | 0.00735 | -0.00175 |
| STEARNS LENDING, INC. | 740 | 0.00493 | Missings | Missings | 0.99324 | 0.00676 | 0.00680 | -0.00230 |
| ALLY BANK | 150 | 0.00100 | Missings | Missings | 0.99333 | 0.00667 | 0.00671 | -0.00239 |
| FRANKLIN AMERICAN MORTGAGE COMPANY | 2627 | 0.01752 | 444 | 0.00296 | 0.99353 | 0.00647 | 0.00651 | -0.00259 |
| GUARANTEED RATE, INC. | 1591 | 0.01061 | 447 | 0.00298 | 0.99371 | 0.00629 | 0.00633 | -0.00278 |
| U.S. BANK N.A. | 9741 | 0.06495 | 2087 | 0.01391 | 0.99415 | 0.00585 | 0.00589 | -0.00322 |
| BANK OF AMERICA, N.A. | 9503 | 0.06336 | 875 | 0.00583 | 0.99442 | 0.00558 | 0.00561 | -0.00349 |
| BRANCH BANKING & TRUST COMPANY | 6586 | 0.04391 | 1088 | 0.00725 | 0.99453 | 0.00547 | 0.00550 | -0.00361 |
| SUNTRUST MORTGAGE, INC. | 1953 | 0.01302 | 871 | 0.00581 | 0.99488 | 0.00512 | 0.00515 | -0.00396 |
| STONEGATE MORTGAGE CORPORATION | 645 | 0.00430 | Missings | Missings | 0.99690 | 0.00310 | 0.00311 | -0.00599 |
| PROVIDENT FUNDING ASSOCIATES, L.P. | 429 | 0.00286 | 158 | 0.00105 | 0.99767 | 0.00233 | 0.00234 | -0.00677 |
| FAIRWAY INDEPENDENT MORTGAGE CORPORATION | 303 | 0.00202 | 783 | 0.00522 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| CHICAGO MORTGAGE SOLUTIONS CORP DBA INTERBANK MORTGAGE CO. | 209 | 0.00139 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| FINANCE OF AMERICA MORTGAGE LLC | Missings | Missings | 431 | 0.00287 | Missings | Missings | Missings | Missings |
| GUILD MORTGAGE COMPANY | Missings | Missings | 109 | 0.00073 | Missings | Missings | Missings | Missings |
| HOME POINT FINANCIAL CORPORATION | Missings | Missings | 109 | 0.00073 | Missings | Missings | Missings | Missings |
| NATIONSTAR MORTGAGE LLC DBA MR. COOPER | Missings | Missings | 457 | 0.00305 | Missings | Missings | Missings | Missings |
| UNITED SHORE FINANCIAL SERVICES, LLC, DBA UNITED WHOLESALE M | Missings | Missings | 1295 | 0.00863 | Missings | Missings | Missings | Missings |
| USAA FEDERAL SAVINGS BANK | Missings | Missings | 151 | 0.00101 | Missings | Missings | Missings | Missings |
# servicer_name
# create table from train data
df_vis_train = df_train.groupby("servicer_name")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['servicer_name']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['servicer_name']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_servicer_name = pd.merge(df_join1,df_join2 ,on='servicer_name',how='outer')
df_servicer_name = df_servicer_name.set_index("servicer_name")
df_servicer_name = df_servicer_name[['Count_Train', 'Ratio_Cat_Train',
'Count_Test', 'Ratio_Cat_Test',
'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault',
'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_servicer_name.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| servicer_name | ||||||||
| SPECIALIZED LOAN SERVICING LLC | 416 | 0.00277 | 936 | 0.00624 | 0.86779 | 0.13221 | 0.15235 | 0.14325 |
| NATIONSTAR MORTGAGE LLC | 1759 | 0.01173 | Missings | Missings | 0.97101 | 0.02899 | 0.02986 | 0.02076 |
| AMERIHOME MORTGAGE COMPANY, LLC | 246 | 0.00164 | 302 | 0.00201 | 0.97154 | 0.02846 | 0.02929 | 0.02019 |
| SENECA MORTGAGE SERVICING, LLC | 178 | 0.00119 | Missings | Missings | 0.97191 | 0.02809 | 0.02890 | 0.01980 |
| CITIMORTGAGE, INC. | 1196 | 0.00797 | 139 | 0.00093 | 0.97408 | 0.02592 | 0.02661 | 0.01751 |
| ROCKET MORTGAGE, LLC | 596 | 0.00397 | 1408 | 0.00939 | 0.97987 | 0.02013 | 0.02055 | 0.01144 |
| Other servicers | 43392 | 0.28931 | 12813 | 0.08543 | 0.98477 | 0.01523 | 0.01547 | 0.00637 |
| LAKEVIEW LOAN SERVICING, LLC | 2465 | 0.01643 | 296 | 0.00197 | 0.98864 | 0.01136 | 0.01149 | 0.00239 |
| QUICKEN LOANS INC. | 3622 | 0.02415 | 1033 | 0.00689 | 0.98868 | 0.01132 | 0.01145 | 0.00235 |
| PINGORA LOAN SERVICING, LLC | 1438 | 0.00959 | 1249 | 0.00833 | 0.98887 | 0.01113 | 0.01125 | 0.00215 |
| STEARNS LENDING, LLC | 376 | 0.00251 | Missings | Missings | 0.98936 | 0.01064 | 0.01075 | 0.00165 |
| CITIZENS BANK, NA | 806 | 0.00537 | 659 | 0.00439 | 0.99007 | 0.00993 | 0.01003 | 0.00092 |
| NATIONSTAR MORTGAGE LLC DBA MR. COOPER | 4799 | 0.03200 | 1631 | 0.01087 | 0.99104 | 0.00896 | 0.00904 | -0.00006 |
| ROUNDPOINT MORTGAGE SERVICING CORPORATION | 237 | 0.00158 | 122 | 0.00081 | 0.99156 | 0.00844 | 0.00851 | -0.00059 |
| PENNYMAC CORP. | 2536 | 0.01691 | Missings | Missings | 0.99172 | 0.00828 | 0.00835 | -0.00075 |
| QUICKEN LOANS, LLC | 257 | 0.00171 | 1096 | 0.00731 | 0.99222 | 0.00778 | 0.00784 | -0.00126 |
| FREEDOM MORTGAGE CORPORATION | 1778 | 0.01185 | 1247 | 0.00831 | 0.99269 | 0.00731 | 0.00737 | -0.00174 |
| CALIBER HOME LOANS, INC. | 2804 | 0.01870 | 2015 | 0.01343 | 0.99287 | 0.00713 | 0.00718 | -0.00192 |
| COLONIAL SAVINGS, F.A. | 159 | 0.00106 | Missings | Missings | 0.99371 | 0.00629 | 0.00633 | -0.00277 |
| BRANCH BANKING & TRUST COMPANY | 1985 | 0.01323 | Missings | Missings | 0.99395 | 0.00605 | 0.00608 | -0.00302 |
| WELLS FARGO BANK, N.A. | 22398 | 0.14933 | 6720 | 0.04480 | 0.99402 | 0.00598 | 0.00602 | -0.00308 |
| JPMORGAN CHASE BANK, N.A. | 3609 | 0.02406 | Missings | Missings | 0.99418 | 0.00582 | 0.00585 | -0.00325 |
| NEW RESIDENTIAL MORTGAGE LLC | 9277 | 0.06185 | 2707 | 0.01805 | 0.99429 | 0.00571 | 0.00575 | -0.00336 |
| MATRIX FINANCIAL SERVICES CORPORATION | 1113 | 0.00742 | 2486 | 0.01657 | 0.99461 | 0.00539 | 0.00542 | -0.00368 |
| PROVIDENT FUNDING ASSOCIATES, L.P. | 476 | 0.00317 | 158 | 0.00105 | 0.99580 | 0.00420 | 0.00422 | -0.00488 |
| FIFTH THIRD BANK, NATIONAL ASSOCIATION | 1453 | 0.00969 | 872 | 0.00581 | 0.99587 | 0.00413 | 0.00415 | -0.00496 |
| U.S. BANK N.A. | 10146 | 0.06765 | 2220 | 0.01480 | 0.99616 | 0.00384 | 0.00386 | -0.00524 |
| REGIONS BANK DBA REGIONS MORTGAGE | 305 | 0.00203 | Missings | Missings | 0.99672 | 0.00328 | 0.00329 | -0.00581 |
| PNC BANK, NA | 4510 | 0.03007 | 1167 | 0.00778 | 0.99690 | 0.00310 | 0.00311 | -0.00599 |
| TRUIST BANK | 5957 | 0.03972 | 1709 | 0.01139 | 0.99799 | 0.00201 | 0.00202 | -0.00708 |
| BANK OF AMERICA, N.A. | 9390 | 0.06261 | 873 | 0.00582 | 0.99808 | 0.00192 | 0.00192 | -0.00718 |
| JPMORGAN CHASE BANK, NATIONAL ASSOCIATION | 9139 | 0.06093 | 4712 | 0.03142 | 0.99847 | 0.00153 | 0.00153 | -0.00757 |
| ARVEST CENTRAL MORTGAGE COMPANY | 261 | 0.00174 | 358 | 0.00239 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| SUNTRUST MORTGAGE, INC. | 906 | 0.00604 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| AURORA FINANCIAL GROUP, INC. | Missings | Missings | 316 | 0.00211 | Missings | Missings | Missings | Missings |
| HOME POINT FINANCIAL CORPORATION | Missings | Missings | 109 | 0.00073 | Missings | Missings | Missings | Missings |
| MUFG UNION BANK, N.A. | Missings | Missings | 511 | 0.00341 | Missings | Missings | Missings | Missings |
| USAA FEDERAL SAVINGS BANK | Missings | Missings | 151 | 0.00101 | Missings | Missings | Missings | Missings |
# st
# create table from train data
df_vis_train = df_train.groupby("st")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['st']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['st']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_st = pd.merge(df_join1,df_join2 ,on='st',how='outer')
df_st = df_st.set_index("st")
df_st = df_st[['Count_Train', 'Ratio_Cat_Train', 'Count_Test', 'Ratio_Cat_Test',
'Ratio_NonDefault', 'Ratio_Default',
'Ratio_default/nondefault', 'Difference_Overall']]
# do some color changing
subset = ['Difference_Overall']
df_st.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| st | ||||||||
| WY | 267 | 0.00178 | 69 | 0.00046 | 0.97378 | 0.02622 | 0.02692 | 0.01782 |
| LA | 1239 | 0.00826 | 386 | 0.00257 | 0.97498 | 0.02502 | 0.02566 | 0.01656 |
| PR | 43 | 0.00029 | 3 | 0.00002 | 0.97674 | 0.02326 | 0.02381 | 0.01471 |
| FL | 8989 | 0.05993 | 3412 | 0.02275 | 0.97975 | 0.02025 | 0.02067 | 0.01156 |
| OK | 1013 | 0.00675 | 381 | 0.00254 | 0.98026 | 0.01974 | 0.02014 | 0.01104 |
| AL | 1566 | 0.01044 | 481 | 0.00321 | 0.98595 | 0.01405 | 0.01425 | 0.00515 |
| RI | 504 | 0.00336 | 153 | 0.00102 | 0.98611 | 0.01389 | 0.01408 | 0.00498 |
| MS | 522 | 0.00348 | 185 | 0.00123 | 0.98659 | 0.01341 | 0.01359 | 0.00449 |
| SD | 239 | 0.00159 | 86 | 0.00057 | 0.98745 | 0.01255 | 0.01271 | 0.00361 |
| GA | 4602 | 0.03068 | 1502 | 0.01001 | 0.98805 | 0.01195 | 0.01210 | 0.00299 |
| NJ | 3606 | 0.02404 | 1350 | 0.00900 | 0.98835 | 0.01165 | 0.01178 | 0.00268 |
| MD | 3208 | 0.02139 | 847 | 0.00565 | 0.98909 | 0.01091 | 0.01103 | 0.00193 |
| TN | 2683 | 0.01789 | 1000 | 0.00667 | 0.98919 | 0.01081 | 0.01093 | 0.00182 |
| IL | 7133 | 0.04756 | 2448 | 0.01632 | 0.98935 | 0.01065 | 0.01077 | 0.00167 |
| TX | 10086 | 0.06725 | 3814 | 0.02543 | 0.98989 | 0.01011 | 0.01022 | 0.00111 |
| OH | 5282 | 0.03522 | 1685 | 0.01123 | 0.99053 | 0.00947 | 0.00956 | 0.00045 |
| NV | 1585 | 0.01057 | 625 | 0.00417 | 0.99054 | 0.00946 | 0.00955 | 0.00045 |
| CT | 1587 | 0.01058 | 431 | 0.00287 | 0.99055 | 0.00945 | 0.00954 | 0.00044 |
| KY | 1952 | 0.01301 | 601 | 0.00401 | 0.99078 | 0.00922 | 0.00931 | 0.00020 |
| IA | 1324 | 0.00883 | 391 | 0.00261 | 0.99094 | 0.00906 | 0.00915 | 0.00004 |
| PA | 4581 | 0.03054 | 1364 | 0.00909 | 0.99105 | 0.00895 | 0.00903 | -0.00007 |
| NM | 681 | 0.00454 | 196 | 0.00131 | 0.99119 | 0.00881 | 0.00889 | -0.00021 |
| AZ | 4058 | 0.02706 | 1558 | 0.01039 | 0.99138 | 0.00862 | 0.00870 | -0.00040 |
| ME | 582 | 0.00388 | 170 | 0.00113 | 0.99141 | 0.00859 | 0.00867 | -0.00044 |
| VA | 4550 | 0.03034 | 1168 | 0.00779 | 0.99143 | 0.00857 | 0.00865 | -0.00046 |
| MA | 3621 | 0.02414 | 1089 | 0.00726 | 0.99144 | 0.00856 | 0.00864 | -0.00047 |
| UT | 2037 | 0.01358 | 868 | 0.00579 | 0.99165 | 0.00835 | 0.00842 | -0.00069 |
| IN | 3272 | 0.02182 | 1210 | 0.00807 | 0.99175 | 0.00825 | 0.00832 | -0.00078 |
| MO | 3190 | 0.02127 | 961 | 0.00641 | 0.99185 | 0.00815 | 0.00822 | -0.00089 |
| DE | 508 | 0.00339 | 141 | 0.00094 | 0.99213 | 0.00787 | 0.00794 | -0.00117 |
| SC | 2171 | 0.01447 | 723 | 0.00482 | 0.99217 | 0.00783 | 0.00789 | -0.00121 |
| AR | 901 | 0.00601 | 317 | 0.00211 | 0.99223 | 0.00777 | 0.00783 | -0.00127 |
| MI | 5574 | 0.03716 | 1959 | 0.01306 | 0.99229 | 0.00771 | 0.00777 | -0.00133 |
| NC | 4766 | 0.03178 | 1548 | 0.01032 | 0.99245 | 0.00755 | 0.00761 | -0.00149 |
| HI | 536 | 0.00357 | 187 | 0.00125 | 0.99254 | 0.00746 | 0.00752 | -0.00158 |
| MT | 568 | 0.00379 | 195 | 0.00130 | 0.99296 | 0.00704 | 0.00709 | -0.00201 |
| NY | 5264 | 0.03510 | 1667 | 0.01111 | 0.99297 | 0.00703 | 0.00708 | -0.00202 |
| WI | 3010 | 0.02007 | 951 | 0.00634 | 0.99302 | 0.00698 | 0.00703 | -0.00208 |
| WV | 431 | 0.00287 | 147 | 0.00098 | 0.99304 | 0.00696 | 0.00701 | -0.00209 |
| NE | 723 | 0.00482 | 234 | 0.00156 | 0.99308 | 0.00692 | 0.00696 | -0.00214 |
| AK | 317 | 0.00211 | 86 | 0.00057 | 0.99369 | 0.00631 | 0.00635 | -0.00275 |
| MN | 3757 | 0.02505 | 1199 | 0.00799 | 0.99388 | 0.00612 | 0.00616 | -0.00294 |
| NH | 837 | 0.00558 | 235 | 0.00157 | 0.99403 | 0.00597 | 0.00601 | -0.00309 |
| CA | 21922 | 0.14616 | 6541 | 0.04361 | 0.99457 | 0.00543 | 0.00546 | -0.00365 |
| OR | 2765 | 0.01844 | 1035 | 0.00690 | 0.99494 | 0.00506 | 0.00509 | -0.00401 |
| ND | 401 | 0.00267 | 98 | 0.00065 | 0.99501 | 0.00499 | 0.00501 | -0.00409 |
| KS | 1440 | 0.00960 | 386 | 0.00257 | 0.99514 | 0.00486 | 0.00488 | -0.00422 |
| CO | 4161 | 0.02774 | 1686 | 0.01124 | 0.99519 | 0.00481 | 0.00483 | -0.00427 |
| DC | 429 | 0.00286 | 104 | 0.00069 | 0.99534 | 0.00466 | 0.00468 | -0.00442 |
| ID | 908 | 0.00605 | 323 | 0.00215 | 0.99559 | 0.00441 | 0.00442 | -0.00468 |
| WA | 4123 | 0.02749 | 1695 | 0.01130 | 0.99588 | 0.00412 | 0.00414 | -0.00496 |
| VT | 443 | 0.00295 | 117 | 0.00078 | 0.99774 | 0.00226 | 0.00226 | -0.00684 |
| GU | 21 | 0.00014 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| VI | 7 | 0.00005 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
# zipcode
# create table from train data
df_vis_train = df_train.groupby("zipcode")["TARGET"]\
.value_counts(normalize=True).unstack()
df_vis_train = df_vis_train.fillna(0)
df_vis_train["Count_Train"] = df_train.groupby(['zipcode']).size()
df_vis_train['Ratio_Cat_Train'] = df_vis_train.Count_Train / df_train.shape[0]
df_vis_train["Ratio_default/nondefault"] = df_vis_train[1]/df_vis_train[0]
# calculate difference to overall ratio
df_vis_train["Difference_Overall"] = df_vis_train["Ratio_default/nondefault"] \
- ratio_overall
df_vis_train = df_vis_train.sort_values(by=['Ratio_default/nondefault'],
ascending=False)
df_vis_train = df_vis_train.rename(columns={0: 'Ratio_NonDefault',
1: 'Ratio_Default'})
# create table from test data
# calculate number of observation in each category
Count = df_test.groupby(['zipcode']).size()
df_vis_test = pd.DataFrame(data = Count, columns=['Count_Test'])
df_vis_test['Ratio_Cat_Test'] = df_vis_test.Count_Test / df_train.shape[0]
# full outer join both tables
df_join1 = df_vis_train.reset_index()
df_join2 = df_vis_test.reset_index()
# change order and index names
df_zipcode = pd.merge(df_join1,df_join2 ,on='zipcode',how='outer')
df_zipcode = df_zipcode.set_index("zipcode")
df_zipcode = df_zipcode[['Count_Train', 'Ratio_Cat_Train', 'Count_Test',
'Ratio_Cat_Test', 'Ratio_NonDefault',
'Ratio_Default', 'Ratio_default/nondefault',
'Difference_Overall']]
print(df_zipcode.Count_Train.max())
# do some color changing
subset = ['Difference_Overall']
df_zipcode.style.applymap(lambda v: 'color:red;' if (v > 0) else None,
subset = subset)\
.applymap(lambda v: 'color:green;' if (v <= 0) else None,
subset = subset)\
.applymap(lambda x: 'color: blue' if pd.isna(x) else '')\
.format(precision=0, na_rep='Missings', thousands=" ",
formatter={('Count_Train'): "{:.0f}",
('Ratio_Cat_Train'): "{:.5f}",
('Count_Test'): "{:.0f}",
('Ratio_Cat_Test'): "{:.5f}",
('Ratio_NonDefault'): "{:.5f}",
('Ratio_Default'): "{:.5f}",
('Ratio_default/nondefault'): "{:.5f}",
('Difference_Overall'): "{:.5f}"
})
1934.0
| Count_Train | Ratio_Cat_Train | Count_Test | Ratio_Cat_Test | Ratio_NonDefault | Ratio_Default | Ratio_default/nondefault | Difference_Overall | |
|---|---|---|---|---|---|---|---|---|
| zipcode | ||||||||
| 41700 | 4 | 0.00003 | 1 | 0.00001 | 0.75000 | 0.25000 | 0.33333 | 0.32423 |
| 41200 | 4 | 0.00003 | 1 | 0.00001 | 0.75000 | 0.25000 | 0.33333 | 0.32423 |
| 2200 | 4 | 0.00003 | 2 | 0.00001 | 0.75000 | 0.25000 | 0.33333 | 0.32423 |
| 76800 | 13 | 0.00009 | 4 | 0.00003 | 0.84615 | 0.15385 | 0.18182 | 0.17272 |
| 8400 | 16 | 0.00011 | 1 | 0.00001 | 0.87500 | 0.12500 | 0.14286 | 0.13375 |
| 48500 | 24 | 0.00016 | 2 | 0.00001 | 0.87500 | 0.12500 | 0.14286 | 0.13375 |
| 57300 | 8 | 0.00005 | 3 | 0.00002 | 0.87500 | 0.12500 | 0.14286 | 0.13375 |
| 68900 | 11 | 0.00007 | 6 | 0.00004 | 0.90909 | 0.09091 | 0.10000 | 0.09090 |
| 82500 | 11 | 0.00007 | 3 | 0.00002 | 0.90909 | 0.09091 | 0.10000 | 0.09090 |
| 82400 | 25 | 0.00017 | 6 | 0.00004 | 0.92000 | 0.08000 | 0.08696 | 0.07785 |
| 75800 | 13 | 0.00009 | 4 | 0.00003 | 0.92308 | 0.07692 | 0.08333 | 0.07423 |
| 66800 | 14 | 0.00009 | 4 | 0.00003 | 0.92857 | 0.07143 | 0.07692 | 0.06782 |
| 36400 | 14 | 0.00009 | 2 | 0.00001 | 0.92857 | 0.07143 | 0.07692 | 0.06782 |
| 8900 | 28 | 0.00019 | 6 | 0.00004 | 0.92857 | 0.07143 | 0.07692 | 0.06782 |
| 8100 | 36 | 0.00024 | 11 | 0.00007 | 0.94444 | 0.05556 | 0.05882 | 0.04972 |
| 900 | 18 | 0.00012 | 2 | 0.00001 | 0.94444 | 0.05556 | 0.05882 | 0.04972 |
| 70700 | 151 | 0.00101 | 47 | 0.00031 | 0.94702 | 0.05298 | 0.05594 | 0.04684 |
| 31600 | 57 | 0.00038 | 12 | 0.00008 | 0.94737 | 0.05263 | 0.05556 | 0.04645 |
| 82800 | 19 | 0.00013 | 6 | 0.00004 | 0.94737 | 0.05263 | 0.05556 | 0.04645 |
| 18300 | 77 | 0.00051 | 28 | 0.00019 | 0.94805 | 0.05195 | 0.05479 | 0.04569 |
| 58200 | 40 | 0.00027 | 15 | 0.00010 | 0.95000 | 0.05000 | 0.05263 | 0.04353 |
| 73400 | 20 | 0.00013 | 7 | 0.00005 | 0.95000 | 0.05000 | 0.05263 | 0.04353 |
| 16300 | 20 | 0.00013 | 3 | 0.00002 | 0.95000 | 0.05000 | 0.05263 | 0.04353 |
| 63400 | 20 | 0.00013 | 2 | 0.00001 | 0.95000 | 0.05000 | 0.05263 | 0.04353 |
| 73500 | 20 | 0.00013 | 6 | 0.00004 | 0.95000 | 0.05000 | 0.05263 | 0.04353 |
| 25300 | 41 | 0.00027 | 9 | 0.00006 | 0.95122 | 0.04878 | 0.05128 | 0.04218 |
| 67100 | 41 | 0.00027 | 12 | 0.00008 | 0.95122 | 0.04878 | 0.05128 | 0.04218 |
| 43600 | 104 | 0.00069 | 40 | 0.00027 | 0.95192 | 0.04808 | 0.05051 | 0.04140 |
| 59400 | 42 | 0.00028 | 7 | 0.00005 | 0.95238 | 0.04762 | 0.05000 | 0.04090 |
| 48900 | 63 | 0.00042 | 22 | 0.00015 | 0.95238 | 0.04762 | 0.05000 | 0.04090 |
| 74100 | 106 | 0.00071 | 46 | 0.00031 | 0.95283 | 0.04717 | 0.04950 | 0.04040 |
| 74400 | 43 | 0.00029 | 12 | 0.00008 | 0.95349 | 0.04651 | 0.04878 | 0.03968 |
| 1600 | 65 | 0.00043 | 25 | 0.00017 | 0.95385 | 0.04615 | 0.04839 | 0.03928 |
| 74300 | 22 | 0.00015 | 7 | 0.00005 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 71000 | 22 | 0.00015 | 6 | 0.00004 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 17100 | 66 | 0.00044 | 22 | 0.00015 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 1300 | 22 | 0.00015 | 5 | 0.00003 | 0.95455 | 0.04545 | 0.04762 | 0.03852 |
| 18200 | 45 | 0.00030 | 7 | 0.00005 | 0.95556 | 0.04444 | 0.04651 | 0.03741 |
| 52400 | 68 | 0.00045 | 13 | 0.00009 | 0.95588 | 0.04412 | 0.04615 | 0.03705 |
| 39000 | 70 | 0.00047 | 26 | 0.00017 | 0.95714 | 0.04286 | 0.04478 | 0.03567 |
| 42700 | 47 | 0.00031 | 17 | 0.00011 | 0.95745 | 0.04255 | 0.04444 | 0.03534 |
| 76700 | 24 | 0.00016 | 18 | 0.00012 | 0.95833 | 0.04167 | 0.04348 | 0.03438 |
| 90400 | 24 | 0.00016 | 4 | 0.00003 | 0.95833 | 0.04167 | 0.04348 | 0.03438 |
| 56700 | 25 | 0.00017 | 12 | 0.00008 | 0.96000 | 0.04000 | 0.04167 | 0.03256 |
| 18100 | 50 | 0.00033 | 12 | 0.00008 | 0.96000 | 0.04000 | 0.04167 | 0.03256 |
| 89800 | 25 | 0.00017 | 9 | 0.00006 | 0.96000 | 0.04000 | 0.04167 | 0.03256 |
| 33100 | 602 | 0.00401 | 245 | 0.00163 | 0.96013 | 0.03987 | 0.04152 | 0.03242 |
| 31900 | 52 | 0.00035 | 14 | 0.00009 | 0.96154 | 0.03846 | 0.04000 | 0.03090 |
| 85900 | 52 | 0.00035 | 18 | 0.00012 | 0.96154 | 0.03846 | 0.04000 | 0.03090 |
| 3300 | 26 | 0.00017 | 11 | 0.00007 | 0.96154 | 0.03846 | 0.04000 | 0.03090 |
| 60200 | 54 | 0.00036 | 21 | 0.00014 | 0.96296 | 0.03704 | 0.03846 | 0.02936 |
| 76900 | 27 | 0.00018 | 10 | 0.00007 | 0.96296 | 0.03704 | 0.03846 | 0.02936 |
| 37700 | 82 | 0.00055 | 40 | 0.00027 | 0.96341 | 0.03659 | 0.03797 | 0.02887 |
| 47100 | 137 | 0.00091 | 56 | 0.00037 | 0.96350 | 0.03650 | 0.03788 | 0.02878 |
| 76400 | 28 | 0.00019 | 14 | 0.00009 | 0.96429 | 0.03571 | 0.03704 | 0.02793 |
| 82700 | 28 | 0.00019 | 5 | 0.00003 | 0.96429 | 0.03571 | 0.03704 | 0.02793 |
| 73100 | 169 | 0.00113 | 73 | 0.00049 | 0.96450 | 0.03550 | 0.03681 | 0.02771 |
| 21900 | 57 | 0.00038 | 14 | 0.00009 | 0.96491 | 0.03509 | 0.03636 | 0.02726 |
| 31800 | 29 | 0.00019 | 9 | 0.00006 | 0.96552 | 0.03448 | 0.03571 | 0.02661 |
| 77900 | 29 | 0.00019 | 6 | 0.00004 | 0.96552 | 0.03448 | 0.03571 | 0.02661 |
| 77700 | 29 | 0.00019 | 14 | 0.00009 | 0.96552 | 0.03448 | 0.03571 | 0.02661 |
| 64700 | 29 | 0.00019 | 9 | 0.00006 | 0.96552 | 0.03448 | 0.03571 | 0.02661 |
| 36100 | 59 | 0.00039 | 18 | 0.00012 | 0.96610 | 0.03390 | 0.03509 | 0.02598 |
| 35500 | 30 | 0.00020 | 7 | 0.00005 | 0.96667 | 0.03333 | 0.03448 | 0.02538 |
| 65500 | 30 | 0.00020 | 5 | 0.00003 | 0.96667 | 0.03333 | 0.03448 | 0.02538 |
| 65400 | 30 | 0.00020 | 4 | 0.00003 | 0.96667 | 0.03333 | 0.03448 | 0.02538 |
| 5600 | 31 | 0.00021 | 18 | 0.00012 | 0.96774 | 0.03226 | 0.03333 | 0.02423 |
| 65300 | 31 | 0.00021 | 6 | 0.00004 | 0.96774 | 0.03226 | 0.03333 | 0.02423 |
| 60900 | 95 | 0.00063 | 30 | 0.00020 | 0.96842 | 0.03158 | 0.03261 | 0.02351 |
| 70600 | 64 | 0.00043 | 28 | 0.00019 | 0.96875 | 0.03125 | 0.03226 | 0.02316 |
| 71100 | 66 | 0.00044 | 24 | 0.00016 | 0.96970 | 0.03030 | 0.03125 | 0.02215 |
| 34400 | 204 | 0.00136 | 69 | 0.00046 | 0.97059 | 0.02941 | 0.03030 | 0.02120 |
| 23700 | 34 | 0.00023 | 2 | 0.00001 | 0.97059 | 0.02941 | 0.03030 | 0.02120 |
| 51100 | 34 | 0.00023 | 7 | 0.00005 | 0.97059 | 0.02941 | 0.03030 | 0.02120 |
| 34700 | 344 | 0.00229 | 151 | 0.00101 | 0.97093 | 0.02907 | 0.02994 | 0.02084 |
| 74800 | 35 | 0.00023 | 10 | 0.00007 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 19600 | 70 | 0.00047 | 21 | 0.00014 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 43900 | 35 | 0.00023 | 12 | 0.00008 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 6200 | 70 | 0.00047 | 20 | 0.00013 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 35800 | 70 | 0.00047 | 28 | 0.00019 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 18700 | 35 | 0.00023 | 8 | 0.00005 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 51200 | 35 | 0.00023 | 7 | 0.00005 | 0.97143 | 0.02857 | 0.02941 | 0.02031 |
| 77600 | 71 | 0.00047 | 20 | 0.00013 | 0.97183 | 0.02817 | 0.02899 | 0.01988 |
| 23800 | 107 | 0.00071 | 37 | 0.00025 | 0.97196 | 0.02804 | 0.02885 | 0.01974 |
| 13000 | 108 | 0.00072 | 26 | 0.00017 | 0.97222 | 0.02778 | 0.02857 | 0.01947 |
| 96100 | 111 | 0.00074 | 40 | 0.00027 | 0.97297 | 0.02703 | 0.02778 | 0.01867 |
| 7100 | 37 | 0.00025 | 21 | 0.00014 | 0.97297 | 0.02703 | 0.02778 | 0.01867 |
| 33000 | 668 | 0.00445 | 238 | 0.00159 | 0.97305 | 0.02695 | 0.02769 | 0.01859 |
| 85100 | 225 | 0.00150 | 105 | 0.00070 | 0.97333 | 0.02667 | 0.02740 | 0.01829 |
| 70500 | 151 | 0.00101 | 36 | 0.00024 | 0.97351 | 0.02649 | 0.02721 | 0.01811 |
| 31200 | 38 | 0.00025 | 9 | 0.00006 | 0.97368 | 0.02632 | 0.02703 | 0.01792 |
| 63600 | 38 | 0.00025 | 8 | 0.00005 | 0.97368 | 0.02632 | 0.02703 | 0.01792 |
| 8600 | 76 | 0.00051 | 18 | 0.00012 | 0.97368 | 0.02632 | 0.02703 | 0.01792 |
| 36600 | 77 | 0.00051 | 21 | 0.00014 | 0.97403 | 0.02597 | 0.02667 | 0.01756 |
| 76600 | 39 | 0.00026 | 11 | 0.00007 | 0.97436 | 0.02564 | 0.02632 | 0.01721 |
| 3400 | 39 | 0.00026 | 7 | 0.00005 | 0.97436 | 0.02564 | 0.02632 | 0.01721 |
| 22600 | 117 | 0.00078 | 41 | 0.00027 | 0.97436 | 0.02564 | 0.02632 | 0.01721 |
| 47900 | 118 | 0.00079 | 50 | 0.00033 | 0.97458 | 0.02542 | 0.02609 | 0.01698 |
| 54000 | 121 | 0.00081 | 40 | 0.00027 | 0.97521 | 0.02479 | 0.02542 | 0.01632 |
| 3100 | 81 | 0.00054 | 21 | 0.00014 | 0.97531 | 0.02469 | 0.02532 | 0.01621 |
| 34100 | 246 | 0.00164 | 89 | 0.00059 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 24200 | 41 | 0.00027 | 16 | 0.00011 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 3900 | 41 | 0.00027 | 12 | 0.00008 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 20600 | 205 | 0.00137 | 44 | 0.00029 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 40400 | 82 | 0.00055 | 20 | 0.00013 | 0.97561 | 0.02439 | 0.02500 | 0.01590 |
| 70000 | 168 | 0.00112 | 41 | 0.00027 | 0.97619 | 0.02381 | 0.02439 | 0.01529 |
| 11900 | 126 | 0.00084 | 35 | 0.00023 | 0.97619 | 0.02381 | 0.02439 | 0.01529 |
| 17800 | 42 | 0.00028 | 11 | 0.00007 | 0.97619 | 0.02381 | 0.02439 | 0.01529 |
| 70400 | 171 | 0.00114 | 62 | 0.00041 | 0.97661 | 0.02339 | 0.02395 | 0.01485 |
| 24400 | 43 | 0.00029 | 16 | 0.00011 | 0.97674 | 0.02326 | 0.02381 | 0.01471 |
| 82900 | 43 | 0.00029 | 11 | 0.00007 | 0.97674 | 0.02326 | 0.02381 | 0.01471 |
| 24100 | 86 | 0.00057 | 30 | 0.00020 | 0.97674 | 0.02326 | 0.02381 | 0.01471 |
| 32700 | 474 | 0.00316 | 185 | 0.00123 | 0.97679 | 0.02321 | 0.02376 | 0.01466 |
| 8000 | 476 | 0.00317 | 177 | 0.00118 | 0.97689 | 0.02311 | 0.02366 | 0.01455 |
| 93300 | 261 | 0.00174 | 98 | 0.00065 | 0.97701 | 0.02299 | 0.02353 | 0.01443 |
| 49600 | 131 | 0.00087 | 59 | 0.00039 | 0.97710 | 0.02290 | 0.02344 | 0.01433 |
| 33300 | 394 | 0.00263 | 144 | 0.00096 | 0.97716 | 0.02284 | 0.02338 | 0.01427 |
| 51000 | 44 | 0.00029 | 5 | 0.00003 | 0.97727 | 0.02273 | 0.02326 | 0.01415 |
| 44300 | 88 | 0.00059 | 36 | 0.00024 | 0.97727 | 0.02273 | 0.02326 | 0.01415 |
| 31500 | 88 | 0.00059 | 22 | 0.00015 | 0.97727 | 0.02273 | 0.02326 | 0.01415 |
| 31700 | 89 | 0.00059 | 18 | 0.00012 | 0.97753 | 0.02247 | 0.02299 | 0.01389 |
| 32800 | 401 | 0.00267 | 142 | 0.00095 | 0.97756 | 0.02244 | 0.02296 | 0.01386 |
| 33700 | 357 | 0.00238 | 136 | 0.00091 | 0.97759 | 0.02241 | 0.02292 | 0.01382 |
| 36200 | 45 | 0.00030 | 17 | 0.00011 | 0.97778 | 0.02222 | 0.02273 | 0.01362 |
| 52800 | 45 | 0.00030 | 9 | 0.00006 | 0.97778 | 0.02222 | 0.02273 | 0.01362 |
| 44100 | 361 | 0.00241 | 130 | 0.00087 | 0.97784 | 0.02216 | 0.02266 | 0.01356 |
| 28400 | 363 | 0.00242 | 120 | 0.00080 | 0.97796 | 0.02204 | 0.02254 | 0.01343 |
| 93600 | 227 | 0.00151 | 109 | 0.00073 | 0.97797 | 0.02203 | 0.02252 | 0.01342 |
| 90300 | 46 | 0.00031 | 21 | 0.00014 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 1400 | 92 | 0.00061 | 41 | 0.00027 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 4900 | 46 | 0.00031 | 12 | 0.00008 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 6700 | 138 | 0.00092 | 33 | 0.00022 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 22700 | 46 | 0.00031 | 10 | 0.00007 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 36500 | 138 | 0.00092 | 62 | 0.00041 | 0.97826 | 0.02174 | 0.02222 | 0.01312 |
| 8200 | 139 | 0.00093 | 39 | 0.00026 | 0.97842 | 0.02158 | 0.02206 | 0.01296 |
| 32200 | 375 | 0.00250 | 124 | 0.00083 | 0.97867 | 0.02133 | 0.02180 | 0.01270 |
| 81100 | 47 | 0.00031 | 20 | 0.00013 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 79100 | 47 | 0.00031 | 15 | 0.00010 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 70800 | 141 | 0.00094 | 39 | 0.00026 | 0.97872 | 0.02128 | 0.02174 | 0.01264 |
| 32400 | 142 | 0.00095 | 45 | 0.00030 | 0.97887 | 0.02113 | 0.02158 | 0.01248 |
| 37400 | 95 | 0.00063 | 43 | 0.00029 | 0.97895 | 0.02105 | 0.02151 | 0.01240 |
| 89700 | 48 | 0.00032 | 20 | 0.00013 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 21600 | 96 | 0.00064 | 23 | 0.00015 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 71200 | 48 | 0.00032 | 20 | 0.00013 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 71900 | 48 | 0.00032 | 20 | 0.00013 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 37800 | 144 | 0.00096 | 51 | 0.00034 | 0.97917 | 0.02083 | 0.02128 | 0.01217 |
| 62200 | 194 | 0.00129 | 49 | 0.00033 | 0.97938 | 0.02062 | 0.02105 | 0.01195 |
| 10300 | 246 | 0.00164 | 78 | 0.00052 | 0.97967 | 0.02033 | 0.02075 | 0.01164 |
| 33500 | 397 | 0.00265 | 130 | 0.00087 | 0.97985 | 0.02015 | 0.02057 | 0.01146 |
| 81500 | 100 | 0.00067 | 37 | 0.00025 | 0.98000 | 0.02000 | 0.02041 | 0.01131 |
| 4100 | 100 | 0.00067 | 16 | 0.00011 | 0.98000 | 0.02000 | 0.02041 | 0.01131 |
| 68000 | 100 | 0.00067 | 40 | 0.00027 | 0.98000 | 0.02000 | 0.02041 | 0.01131 |
| 50400 | 51 | 0.00034 | 15 | 0.00010 | 0.98039 | 0.01961 | 0.02000 | 0.01090 |
| 24500 | 153 | 0.00102 | 40 | 0.00027 | 0.98039 | 0.01961 | 0.02000 | 0.01090 |
| 60400 | 767 | 0.00511 | 306 | 0.00204 | 0.98044 | 0.01956 | 0.01995 | 0.01084 |
| 38400 | 52 | 0.00035 | 16 | 0.00011 | 0.98077 | 0.01923 | 0.01961 | 0.01050 |
| 50600 | 52 | 0.00035 | 8 | 0.00005 | 0.98077 | 0.01923 | 0.01961 | 0.01050 |
| 62800 | 52 | 0.00035 | 15 | 0.00010 | 0.98077 | 0.01923 | 0.01961 | 0.01050 |
| 27900 | 105 | 0.00070 | 35 | 0.00023 | 0.98095 | 0.01905 | 0.01942 | 0.01031 |
| 64800 | 53 | 0.00035 | 25 | 0.00017 | 0.98113 | 0.01887 | 0.01923 | 0.01013 |
| 16600 | 53 | 0.00035 | 18 | 0.00012 | 0.98113 | 0.01887 | 0.01923 | 0.01013 |
| 34600 | 376 | 0.00251 | 144 | 0.00096 | 0.98138 | 0.01862 | 0.01897 | 0.00987 |
| 54500 | 54 | 0.00036 | 13 | 0.00009 | 0.98148 | 0.01852 | 0.01887 | 0.00976 |
| 63700 | 54 | 0.00036 | 22 | 0.00015 | 0.98148 | 0.01852 | 0.01887 | 0.00976 |
| 46300 | 379 | 0.00253 | 131 | 0.00087 | 0.98153 | 0.01847 | 0.01882 | 0.00971 |
| 84400 | 109 | 0.00073 | 56 | 0.00037 | 0.98165 | 0.01835 | 0.01869 | 0.00959 |
| 33400 | 766 | 0.00511 | 311 | 0.00207 | 0.98172 | 0.01828 | 0.01862 | 0.00951 |
| 30200 | 383 | 0.00255 | 120 | 0.00080 | 0.98172 | 0.01828 | 0.01862 | 0.00951 |
| 31400 | 110 | 0.00073 | 25 | 0.00017 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 43700 | 55 | 0.00037 | 18 | 0.00012 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 38100 | 165 | 0.00110 | 75 | 0.00050 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 51500 | 55 | 0.00037 | 15 | 0.00010 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 82000 | 55 | 0.00037 | 20 | 0.00013 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 87000 | 55 | 0.00037 | 14 | 0.00009 | 0.98182 | 0.01818 | 0.01852 | 0.00942 |
| 32000 | 277 | 0.00185 | 109 | 0.00073 | 0.98195 | 0.01805 | 0.01838 | 0.00928 |
| 14600 | 167 | 0.00111 | 60 | 0.00040 | 0.98204 | 0.01796 | 0.01829 | 0.00919 |
| 77000 | 951 | 0.00634 | 299 | 0.00199 | 0.98212 | 0.01788 | 0.01820 | 0.00910 |
| 62500 | 56 | 0.00037 | 18 | 0.00012 | 0.98214 | 0.01786 | 0.01818 | 0.00908 |
| 33900 | 456 | 0.00304 | 187 | 0.00125 | 0.98246 | 0.01754 | 0.01786 | 0.00875 |
| 8300 | 57 | 0.00038 | 18 | 0.00012 | 0.98246 | 0.01754 | 0.01786 | 0.00875 |
| 36300 | 57 | 0.00038 | 9 | 0.00006 | 0.98246 | 0.01754 | 0.01786 | 0.00875 |
| 98400 | 171 | 0.00114 | 76 | 0.00051 | 0.98246 | 0.01754 | 0.01786 | 0.00875 |
| 44600 | 171 | 0.00114 | 54 | 0.00036 | 0.98246 | 0.01754 | 0.01786 | 0.00875 |
| 33800 | 289 | 0.00193 | 98 | 0.00065 | 0.98270 | 0.01730 | 0.01761 | 0.00850 |
| 21200 | 410 | 0.00273 | 129 | 0.00086 | 0.98293 | 0.01707 | 0.01737 | 0.00827 |
| 19000 | 529 | 0.00353 | 172 | 0.00115 | 0.98299 | 0.01701 | 0.01731 | 0.00820 |
| 75600 | 59 | 0.00039 | 14 | 0.00009 | 0.98305 | 0.01695 | 0.01724 | 0.00814 |
| 79900 | 119 | 0.00079 | 33 | 0.00022 | 0.98319 | 0.01681 | 0.01709 | 0.00799 |
| 96000 | 179 | 0.00119 | 71 | 0.00047 | 0.98324 | 0.01676 | 0.01705 | 0.00794 |
| 43300 | 60 | 0.00040 | 16 | 0.00011 | 0.98333 | 0.01667 | 0.01695 | 0.00785 |
| 29500 | 360 | 0.00240 | 105 | 0.00070 | 0.98333 | 0.01667 | 0.01695 | 0.00785 |
| 1500 | 243 | 0.00162 | 79 | 0.00053 | 0.98354 | 0.01646 | 0.01674 | 0.00763 |
| 10900 | 247 | 0.00165 | 116 | 0.00077 | 0.98381 | 0.01619 | 0.01646 | 0.00736 |
| 29800 | 62 | 0.00041 | 20 | 0.00013 | 0.98387 | 0.01613 | 0.01639 | 0.00729 |
| 22400 | 124 | 0.00083 | 37 | 0.00025 | 0.98387 | 0.01613 | 0.01639 | 0.00729 |
| 7300 | 62 | 0.00041 | 33 | 0.00022 | 0.98387 | 0.01613 | 0.01639 | 0.00729 |
| 39400 | 62 | 0.00041 | 25 | 0.00017 | 0.98387 | 0.01613 | 0.01639 | 0.00729 |
| 2800 | 373 | 0.00249 | 114 | 0.00076 | 0.98391 | 0.01609 | 0.01635 | 0.00725 |
| 49500 | 249 | 0.00166 | 93 | 0.00062 | 0.98394 | 0.01606 | 0.01633 | 0.00722 |
| 23300 | 125 | 0.00083 | 29 | 0.00019 | 0.98400 | 0.01600 | 0.01626 | 0.00716 |
| 31000 | 125 | 0.00083 | 49 | 0.00033 | 0.98400 | 0.01600 | 0.01626 | 0.00716 |
| 20700 | 378 | 0.00252 | 147 | 0.00098 | 0.98413 | 0.01587 | 0.01613 | 0.00703 |
| 77300 | 763 | 0.00509 | 254 | 0.00169 | 0.98427 | 0.01573 | 0.01598 | 0.00688 |
| 23000 | 129 | 0.00086 | 48 | 0.00032 | 0.98450 | 0.01550 | 0.01575 | 0.00665 |
| 86400 | 129 | 0.00086 | 54 | 0.00036 | 0.98450 | 0.01550 | 0.01575 | 0.00665 |
| 80400 | 263 | 0.00175 | 108 | 0.00072 | 0.98479 | 0.01521 | 0.01544 | 0.00634 |
| 37300 | 198 | 0.00132 | 86 | 0.00057 | 0.98485 | 0.01515 | 0.01538 | 0.00628 |
| 12300 | 66 | 0.00044 | 18 | 0.00012 | 0.98485 | 0.01515 | 0.01538 | 0.00628 |
| 92400 | 66 | 0.00044 | 29 | 0.00019 | 0.98485 | 0.01515 | 0.01538 | 0.00628 |
| 98300 | 399 | 0.00266 | 179 | 0.00119 | 0.98496 | 0.01504 | 0.01527 | 0.00616 |
| 93500 | 266 | 0.00177 | 85 | 0.00057 | 0.98496 | 0.01504 | 0.01527 | 0.00616 |
| 35900 | 67 | 0.00045 | 15 | 0.00010 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 6900 | 67 | 0.00045 | 19 | 0.00013 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 14800 | 67 | 0.00045 | 25 | 0.00017 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 12400 | 67 | 0.00045 | 27 | 0.00018 | 0.98507 | 0.01493 | 0.01515 | 0.00605 |
| 65800 | 136 | 0.00091 | 29 | 0.00019 | 0.98529 | 0.01471 | 0.01493 | 0.00582 |
| 57700 | 68 | 0.00045 | 17 | 0.00011 | 0.98529 | 0.01471 | 0.01493 | 0.00582 |
| 28700 | 205 | 0.00137 | 84 | 0.00056 | 0.98537 | 0.01463 | 0.01485 | 0.00575 |
| 40000 | 137 | 0.00091 | 45 | 0.00030 | 0.98540 | 0.01460 | 0.01481 | 0.00571 |
| 79700 | 137 | 0.00091 | 46 | 0.00031 | 0.98540 | 0.01460 | 0.01481 | 0.00571 |
| 77400 | 824 | 0.00549 | 264 | 0.00176 | 0.98544 | 0.01456 | 0.01478 | 0.00568 |
| 81000 | 69 | 0.00046 | 29 | 0.00019 | 0.98551 | 0.01449 | 0.01471 | 0.00560 |
| 43400 | 69 | 0.00046 | 25 | 0.00017 | 0.98551 | 0.01449 | 0.01471 | 0.00560 |
| 19100 | 345 | 0.00230 | 113 | 0.00075 | 0.98551 | 0.01449 | 0.01471 | 0.00560 |
| 91400 | 139 | 0.00093 | 60 | 0.00040 | 0.98561 | 0.01439 | 0.01460 | 0.00550 |
| 61000 | 140 | 0.00093 | 52 | 0.00035 | 0.98571 | 0.01429 | 0.01449 | 0.00539 |
| 1700 | 281 | 0.00187 | 113 | 0.00075 | 0.98577 | 0.01423 | 0.01444 | 0.00534 |
| 48700 | 71 | 0.00047 | 17 | 0.00011 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 7600 | 213 | 0.00142 | 71 | 0.00047 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 44000 | 355 | 0.00237 | 118 | 0.00079 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 85600 | 142 | 0.00095 | 65 | 0.00043 | 0.98592 | 0.01408 | 0.01429 | 0.00518 |
| 37000 | 579 | 0.00386 | 208 | 0.00139 | 0.98618 | 0.01382 | 0.01401 | 0.00491 |
| 35000 | 145 | 0.00097 | 39 | 0.00026 | 0.98621 | 0.01379 | 0.01399 | 0.00488 |
| 78100 | 145 | 0.00097 | 53 | 0.00035 | 0.98621 | 0.01379 | 0.01399 | 0.00488 |
| 93200 | 218 | 0.00145 | 96 | 0.00064 | 0.98624 | 0.01376 | 0.01395 | 0.00485 |
| 34200 | 509 | 0.00339 | 216 | 0.00144 | 0.98625 | 0.01375 | 0.01394 | 0.00484 |
| 67400 | 73 | 0.00049 | 23 | 0.00015 | 0.98630 | 0.01370 | 0.01389 | 0.00479 |
| 29100 | 73 | 0.00049 | 25 | 0.00017 | 0.98630 | 0.01370 | 0.01389 | 0.00479 |
| 32900 | 368 | 0.00245 | 145 | 0.00097 | 0.98641 | 0.01359 | 0.01377 | 0.00467 |
| 34900 | 221 | 0.00147 | 89 | 0.00059 | 0.98643 | 0.01357 | 0.01376 | 0.00466 |
| 60600 | 1327 | 0.00885 | 432 | 0.00288 | 0.98644 | 0.01356 | 0.01375 | 0.00465 |
| 95900 | 295 | 0.00197 | 126 | 0.00084 | 0.98644 | 0.01356 | 0.01375 | 0.00464 |
| 52300 | 74 | 0.00049 | 25 | 0.00017 | 0.98649 | 0.01351 | 0.01370 | 0.00460 |
| 77500 | 449 | 0.00299 | 170 | 0.00113 | 0.98664 | 0.01336 | 0.01354 | 0.00444 |
| 1000 | 151 | 0.00101 | 47 | 0.00031 | 0.98675 | 0.01325 | 0.01342 | 0.00432 |
| 27800 | 152 | 0.00101 | 43 | 0.00029 | 0.98684 | 0.01316 | 0.01333 | 0.00423 |
| 88000 | 76 | 0.00051 | 20 | 0.00013 | 0.98684 | 0.01316 | 0.01333 | 0.00423 |
| 62900 | 77 | 0.00051 | 25 | 0.00017 | 0.98701 | 0.01299 | 0.01316 | 0.00405 |
| 39100 | 77 | 0.00051 | 19 | 0.00013 | 0.98701 | 0.01299 | 0.01316 | 0.00405 |
| 70100 | 154 | 0.00103 | 47 | 0.00031 | 0.98701 | 0.01299 | 0.01316 | 0.00405 |
| 91900 | 311 | 0.00207 | 95 | 0.00063 | 0.98714 | 0.01286 | 0.01303 | 0.00393 |
| 11700 | 622 | 0.00415 | 193 | 0.00129 | 0.98714 | 0.01286 | 0.01303 | 0.00393 |
| 32500 | 235 | 0.00157 | 80 | 0.00053 | 0.98723 | 0.01277 | 0.01293 | 0.00383 |
| 28500 | 157 | 0.00105 | 46 | 0.00031 | 0.98726 | 0.01274 | 0.01290 | 0.00380 |
| 40300 | 158 | 0.00105 | 41 | 0.00027 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 75700 | 79 | 0.00053 | 36 | 0.00024 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 65600 | 79 | 0.00053 | 25 | 0.00017 | 0.98734 | 0.01266 | 0.01282 | 0.00372 |
| 54800 | 159 | 0.00106 | 52 | 0.00035 | 0.98742 | 0.01258 | 0.01274 | 0.00364 |
| 48200 | 160 | 0.00107 | 69 | 0.00046 | 0.98750 | 0.01250 | 0.01266 | 0.00356 |
| 45300 | 240 | 0.00160 | 65 | 0.00043 | 0.98750 | 0.01250 | 0.01266 | 0.00356 |
| 50100 | 80 | 0.00053 | 26 | 0.00017 | 0.98750 | 0.01250 | 0.01266 | 0.00356 |
| 36800 | 80 | 0.00053 | 39 | 0.00026 | 0.98750 | 0.01250 | 0.01266 | 0.00356 |
| 46500 | 241 | 0.00161 | 83 | 0.00055 | 0.98755 | 0.01245 | 0.01261 | 0.00350 |
| 39500 | 81 | 0.00054 | 30 | 0.00020 | 0.98765 | 0.01235 | 0.01250 | 0.00340 |
| 66600 | 81 | 0.00054 | 40 | 0.00027 | 0.98765 | 0.01235 | 0.01250 | 0.00340 |
| 6600 | 81 | 0.00054 | 14 | 0.00009 | 0.98765 | 0.01235 | 0.01250 | 0.00340 |
| 46000 | 408 | 0.00272 | 163 | 0.00109 | 0.98775 | 0.01225 | 0.01241 | 0.00330 |
| 53000 | 411 | 0.00274 | 132 | 0.00088 | 0.98783 | 0.01217 | 0.01232 | 0.00321 |
| 8700 | 248 | 0.00165 | 133 | 0.00089 | 0.98790 | 0.01210 | 0.01224 | 0.00314 |
| 25400 | 83 | 0.00055 | 21 | 0.00014 | 0.98795 | 0.01205 | 0.01220 | 0.00309 |
| 99500 | 166 | 0.00111 | 37 | 0.00025 | 0.98795 | 0.01205 | 0.01220 | 0.00309 |
| 35400 | 83 | 0.00055 | 24 | 0.00016 | 0.98795 | 0.01205 | 0.01220 | 0.00309 |
| 99000 | 83 | 0.00055 | 26 | 0.00017 | 0.98795 | 0.01205 | 0.01220 | 0.00309 |
| 72700 | 250 | 0.00167 | 95 | 0.00063 | 0.98800 | 0.01200 | 0.01215 | 0.00304 |
| 76500 | 84 | 0.00056 | 41 | 0.00027 | 0.98810 | 0.01190 | 0.01205 | 0.00295 |
| 91500 | 85 | 0.00057 | 29 | 0.00019 | 0.98824 | 0.01176 | 0.01190 | 0.00280 |
| 2300 | 255 | 0.00170 | 97 | 0.00065 | 0.98824 | 0.01176 | 0.01190 | 0.00280 |
| 30000 | 1448 | 0.00965 | 476 | 0.00317 | 0.98826 | 0.01174 | 0.01188 | 0.00278 |
| 76000 | 597 | 0.00398 | 270 | 0.00180 | 0.98827 | 0.01173 | 0.01186 | 0.00276 |
| 55100 | 512 | 0.00341 | 175 | 0.00117 | 0.98828 | 0.01172 | 0.01186 | 0.00275 |
| 90600 | 430 | 0.00287 | 120 | 0.00080 | 0.98837 | 0.01163 | 0.01176 | 0.00266 |
| 48300 | 860 | 0.00573 | 315 | 0.00210 | 0.98837 | 0.01163 | 0.01176 | 0.00266 |
| 45200 | 517 | 0.00345 | 142 | 0.00095 | 0.98839 | 0.01161 | 0.01174 | 0.00264 |
| 24000 | 174 | 0.00116 | 33 | 0.00022 | 0.98851 | 0.01149 | 0.01163 | 0.00252 |
| 91300 | 1044 | 0.00696 | 266 | 0.00177 | 0.98851 | 0.01149 | 0.01163 | 0.00252 |
| 89100 | 787 | 0.00525 | 302 | 0.00201 | 0.98856 | 0.01144 | 0.01157 | 0.00247 |
| 29000 | 175 | 0.00117 | 56 | 0.00037 | 0.98857 | 0.01143 | 0.01156 | 0.00246 |
| 55800 | 88 | 0.00059 | 32 | 0.00021 | 0.98864 | 0.01136 | 0.01149 | 0.00239 |
| 6300 | 88 | 0.00059 | 28 | 0.00019 | 0.98864 | 0.01136 | 0.01149 | 0.00239 |
| 60100 | 1059 | 0.00706 | 394 | 0.00263 | 0.98867 | 0.01133 | 0.01146 | 0.00236 |
| 47000 | 89 | 0.00059 | 23 | 0.00015 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 19700 | 178 | 0.00119 | 55 | 0.00037 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 31300 | 89 | 0.00059 | 16 | 0.00011 | 0.98876 | 0.01124 | 0.01136 | 0.00226 |
| 57100 | 90 | 0.00060 | 36 | 0.00024 | 0.98889 | 0.01111 | 0.01124 | 0.00213 |
| 7700 | 362 | 0.00241 | 130 | 0.00087 | 0.98895 | 0.01105 | 0.01117 | 0.00207 |
| 98900 | 91 | 0.00061 | 45 | 0.00030 | 0.98901 | 0.01099 | 0.01111 | 0.00201 |
| 94800 | 91 | 0.00061 | 35 | 0.00023 | 0.98901 | 0.01099 | 0.01111 | 0.00201 |
| 37600 | 92 | 0.00061 | 29 | 0.00019 | 0.98913 | 0.01087 | 0.01099 | 0.00189 |
| 22500 | 93 | 0.00062 | 21 | 0.00014 | 0.98925 | 0.01075 | 0.01087 | 0.00177 |
| 59100 | 93 | 0.00062 | 31 | 0.00021 | 0.98925 | 0.01075 | 0.01087 | 0.00177 |
| 30500 | 374 | 0.00249 | 168 | 0.00112 | 0.98930 | 0.01070 | 0.01081 | 0.00171 |
| 83800 | 187 | 0.00125 | 66 | 0.00044 | 0.98930 | 0.01070 | 0.01081 | 0.00171 |
| 84100 | 375 | 0.00250 | 117 | 0.00078 | 0.98933 | 0.01067 | 0.01078 | 0.00168 |
| 30600 | 188 | 0.00125 | 64 | 0.00043 | 0.98936 | 0.01064 | 0.01075 | 0.00165 |
| 15000 | 189 | 0.00126 | 61 | 0.00041 | 0.98942 | 0.01058 | 0.01070 | 0.00159 |
| 45100 | 190 | 0.00127 | 69 | 0.00046 | 0.98947 | 0.01053 | 0.01064 | 0.00154 |
| 42000 | 95 | 0.00063 | 31 | 0.00021 | 0.98947 | 0.01053 | 0.01064 | 0.00154 |
| 1900 | 288 | 0.00192 | 97 | 0.00065 | 0.98958 | 0.01042 | 0.01053 | 0.00142 |
| 6500 | 97 | 0.00065 | 22 | 0.00015 | 0.98969 | 0.01031 | 0.01042 | 0.00131 |
| 91100 | 99 | 0.00066 | 27 | 0.00018 | 0.98990 | 0.01010 | 0.01020 | 0.00110 |
| 72100 | 101 | 0.00067 | 37 | 0.00025 | 0.99010 | 0.00990 | 0.01000 | 0.00090 |
| 20900 | 205 | 0.00137 | 41 | 0.00027 | 0.99024 | 0.00976 | 0.00985 | 0.00075 |
| 6800 | 206 | 0.00137 | 55 | 0.00037 | 0.99029 | 0.00971 | 0.00980 | 0.00070 |
| 83700 | 206 | 0.00137 | 56 | 0.00037 | 0.99029 | 0.00971 | 0.00980 | 0.00070 |
| 87100 | 315 | 0.00210 | 90 | 0.00060 | 0.99048 | 0.00952 | 0.00962 | 0.00051 |
| 87500 | 106 | 0.00071 | 35 | 0.00023 | 0.99057 | 0.00943 | 0.00952 | 0.00042 |
| 65000 | 106 | 0.00071 | 25 | 0.00017 | 0.99057 | 0.00943 | 0.00952 | 0.00042 |
| 84000 | 1063 | 0.00709 | 487 | 0.00325 | 0.99059 | 0.00941 | 0.00950 | 0.00039 |
| 6400 | 428 | 0.00285 | 118 | 0.00079 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 35600 | 107 | 0.00071 | 29 | 0.00019 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 38600 | 107 | 0.00071 | 34 | 0.00023 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 11000 | 107 | 0.00071 | 18 | 0.00012 | 0.99065 | 0.00935 | 0.00943 | 0.00033 |
| 21700 | 322 | 0.00215 | 77 | 0.00051 | 0.99068 | 0.00932 | 0.00940 | 0.00030 |
| 28200 | 542 | 0.00361 | 174 | 0.00116 | 0.99077 | 0.00923 | 0.00931 | 0.00021 |
| 78200 | 439 | 0.00293 | 175 | 0.00117 | 0.99089 | 0.00911 | 0.00920 | 0.00009 |
| 92500 | 887 | 0.00591 | 352 | 0.00235 | 0.99098 | 0.00902 | 0.00910 | -0.00000 |
| 23600 | 111 | 0.00074 | 32 | 0.00021 | 0.99099 | 0.00901 | 0.00909 | -0.00001 |
| 29400 | 446 | 0.00297 | 161 | 0.00107 | 0.99103 | 0.00897 | 0.00905 | -0.00005 |
| 27100 | 112 | 0.00075 | 37 | 0.00025 | 0.99107 | 0.00893 | 0.00901 | -0.00009 |
| 72200 | 113 | 0.00075 | 34 | 0.00023 | 0.99115 | 0.00885 | 0.00893 | -0.00017 |
| 75100 | 226 | 0.00151 | 143 | 0.00095 | 0.99115 | 0.00885 | 0.00893 | -0.00017 |
| 85700 | 455 | 0.00303 | 143 | 0.00095 | 0.99121 | 0.00879 | 0.00887 | -0.00023 |
| 44400 | 114 | 0.00076 | 29 | 0.00019 | 0.99123 | 0.00877 | 0.00885 | -0.00025 |
| 41000 | 342 | 0.00228 | 99 | 0.00066 | 0.99123 | 0.00877 | 0.00885 | -0.00025 |
| 80600 | 229 | 0.00153 | 85 | 0.00057 | 0.99127 | 0.00873 | 0.00881 | -0.00029 |
| 81600 | 115 | 0.00077 | 31 | 0.00021 | 0.99130 | 0.00870 | 0.00877 | -0.00033 |
| 27000 | 116 | 0.00077 | 36 | 0.00024 | 0.99138 | 0.00862 | 0.00870 | -0.00041 |
| 53900 | 116 | 0.00077 | 46 | 0.00031 | 0.99138 | 0.00862 | 0.00870 | -0.00041 |
| 60500 | 815 | 0.00543 | 285 | 0.00190 | 0.99141 | 0.00859 | 0.00866 | -0.00044 |
| 48800 | 350 | 0.00233 | 106 | 0.00071 | 0.99143 | 0.00857 | 0.00865 | -0.00046 |
| 47200 | 117 | 0.00078 | 32 | 0.00021 | 0.99145 | 0.00855 | 0.00862 | -0.00048 |
| 53100 | 472 | 0.00315 | 162 | 0.00108 | 0.99153 | 0.00847 | 0.00855 | -0.00056 |
| 22300 | 237 | 0.00158 | 55 | 0.00037 | 0.99156 | 0.00844 | 0.00851 | -0.00059 |
| 64000 | 356 | 0.00237 | 115 | 0.00077 | 0.99157 | 0.00843 | 0.00850 | -0.00060 |
| 85300 | 834 | 0.00556 | 337 | 0.00225 | 0.99161 | 0.00839 | 0.00846 | -0.00064 |
| 30700 | 121 | 0.00081 | 26 | 0.00017 | 0.99174 | 0.00826 | 0.00833 | -0.00077 |
| 95800 | 485 | 0.00323 | 220 | 0.00147 | 0.99175 | 0.00825 | 0.00832 | -0.00079 |
| 97200 | 850 | 0.00567 | 274 | 0.00183 | 0.99176 | 0.00824 | 0.00830 | -0.00080 |
| 76200 | 365 | 0.00243 | 166 | 0.00111 | 0.99178 | 0.00822 | 0.00829 | -0.00082 |
| 19900 | 246 | 0.00164 | 61 | 0.00041 | 0.99187 | 0.00813 | 0.00820 | -0.00091 |
| 54700 | 123 | 0.00082 | 29 | 0.00019 | 0.99187 | 0.00813 | 0.00820 | -0.00091 |
| 89000 | 370 | 0.00247 | 159 | 0.00106 | 0.99189 | 0.00811 | 0.00817 | -0.00093 |
| 59800 | 124 | 0.00083 | 54 | 0.00036 | 0.99194 | 0.00806 | 0.00813 | -0.00097 |
| 55000 | 500 | 0.00333 | 155 | 0.00103 | 0.99200 | 0.00800 | 0.00806 | -0.00104 |
| 40200 | 378 | 0.00252 | 127 | 0.00085 | 0.99206 | 0.00794 | 0.00800 | -0.00110 |
| 96700 | 384 | 0.00256 | 142 | 0.00095 | 0.99219 | 0.00781 | 0.00787 | -0.00123 |
| 22200 | 128 | 0.00085 | 34 | 0.00023 | 0.99219 | 0.00781 | 0.00787 | -0.00123 |
| 28000 | 387 | 0.00258 | 131 | 0.00087 | 0.99225 | 0.00775 | 0.00781 | -0.00129 |
| 42100 | 129 | 0.00086 | 35 | 0.00023 | 0.99225 | 0.00775 | 0.00781 | -0.00129 |
| 30100 | 645 | 0.00430 | 248 | 0.00165 | 0.99225 | 0.00775 | 0.00781 | -0.00129 |
| 17000 | 260 | 0.00173 | 71 | 0.00047 | 0.99231 | 0.00769 | 0.00775 | -0.00135 |
| 2900 | 131 | 0.00087 | 39 | 0.00026 | 0.99237 | 0.00763 | 0.00769 | -0.00141 |
| 63000 | 524 | 0.00349 | 132 | 0.00088 | 0.99237 | 0.00763 | 0.00769 | -0.00141 |
| 23100 | 265 | 0.00177 | 69 | 0.00046 | 0.99245 | 0.00755 | 0.00760 | -0.00150 |
| 56500 | 133 | 0.00089 | 33 | 0.00022 | 0.99248 | 0.00752 | 0.00758 | -0.00153 |
| 35700 | 133 | 0.00089 | 37 | 0.00025 | 0.99248 | 0.00752 | 0.00758 | -0.00153 |
| 10000 | 134 | 0.00089 | 20 | 0.00013 | 0.99254 | 0.00746 | 0.00752 | -0.00158 |
| 61700 | 134 | 0.00089 | 46 | 0.00031 | 0.99254 | 0.00746 | 0.00752 | -0.00158 |
| 21000 | 537 | 0.00358 | 119 | 0.00079 | 0.99255 | 0.00745 | 0.00750 | -0.00160 |
| 17300 | 135 | 0.00090 | 47 | 0.00031 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 72000 | 135 | 0.00090 | 57 | 0.00038 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 90500 | 135 | 0.00090 | 18 | 0.00012 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 65700 | 135 | 0.00090 | 56 | 0.00037 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 91200 | 135 | 0.00090 | 35 | 0.00023 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 12000 | 135 | 0.00090 | 32 | 0.00021 | 0.99259 | 0.00741 | 0.00746 | -0.00164 |
| 92300 | 677 | 0.00451 | 237 | 0.00158 | 0.99261 | 0.00739 | 0.00744 | -0.00166 |
| 77800 | 136 | 0.00091 | 45 | 0.00030 | 0.99265 | 0.00735 | 0.00741 | -0.00170 |
| 49700 | 137 | 0.00091 | 34 | 0.00023 | 0.99270 | 0.00730 | 0.00735 | -0.00175 |
| 85200 | 1242 | 0.00828 | 463 | 0.00309 | 0.99275 | 0.00725 | 0.00730 | -0.00180 |
| 32100 | 278 | 0.00185 | 100 | 0.00067 | 0.99281 | 0.00719 | 0.00725 | -0.00186 |
| 97400 | 281 | 0.00187 | 99 | 0.00066 | 0.99288 | 0.00712 | 0.00717 | -0.00193 |
| 32600 | 141 | 0.00094 | 37 | 0.00025 | 0.99291 | 0.00709 | 0.00714 | -0.00196 |
| 54400 | 141 | 0.00094 | 44 | 0.00029 | 0.99291 | 0.00709 | 0.00714 | -0.00196 |
| 65200 | 141 | 0.00094 | 40 | 0.00027 | 0.99291 | 0.00709 | 0.00714 | -0.00196 |
| 23400 | 283 | 0.00189 | 63 | 0.00042 | 0.99293 | 0.00707 | 0.00712 | -0.00199 |
| 35100 | 142 | 0.00095 | 33 | 0.00022 | 0.99296 | 0.00704 | 0.00709 | -0.00201 |
| 73000 | 288 | 0.00192 | 109 | 0.00073 | 0.99306 | 0.00694 | 0.00699 | -0.00211 |
| 44200 | 292 | 0.00195 | 98 | 0.00065 | 0.99315 | 0.00685 | 0.00690 | -0.00221 |
| 2000 | 295 | 0.00197 | 72 | 0.00048 | 0.99322 | 0.00678 | 0.00683 | -0.00228 |
| 55300 | 889 | 0.00593 | 278 | 0.00185 | 0.99325 | 0.00675 | 0.00680 | -0.00231 |
| 97000 | 600 | 0.00400 | 245 | 0.00163 | 0.99333 | 0.00667 | 0.00671 | -0.00239 |
| 33600 | 301 | 0.00201 | 125 | 0.00083 | 0.99336 | 0.00664 | 0.00669 | -0.00241 |
| 68500 | 151 | 0.00101 | 52 | 0.00035 | 0.99338 | 0.00662 | 0.00667 | -0.00244 |
| 96800 | 152 | 0.00101 | 45 | 0.00030 | 0.99342 | 0.00658 | 0.00662 | -0.00248 |
| 43000 | 622 | 0.00415 | 219 | 0.00146 | 0.99357 | 0.00643 | 0.00647 | -0.00263 |
| 95300 | 624 | 0.00416 | 263 | 0.00175 | 0.99359 | 0.00641 | 0.00645 | -0.00265 |
| 21100 | 313 | 0.00209 | 96 | 0.00064 | 0.99361 | 0.00639 | 0.00643 | -0.00267 |
| 22100 | 314 | 0.00209 | 80 | 0.00053 | 0.99363 | 0.00637 | 0.00641 | -0.00269 |
| 60000 | 1256 | 0.00837 | 418 | 0.00279 | 0.99363 | 0.00637 | 0.00641 | -0.00269 |
| 29600 | 472 | 0.00315 | 159 | 0.00106 | 0.99364 | 0.00636 | 0.00640 | -0.00271 |
| 38000 | 159 | 0.00106 | 60 | 0.00040 | 0.99371 | 0.00629 | 0.00633 | -0.00277 |
| 28300 | 160 | 0.00107 | 56 | 0.00037 | 0.99375 | 0.00625 | 0.00629 | -0.00281 |
| 75000 | 1634 | 0.01089 | 630 | 0.00420 | 0.99388 | 0.00612 | 0.00616 | -0.00295 |
| 93000 | 491 | 0.00327 | 117 | 0.00078 | 0.99389 | 0.00611 | 0.00615 | -0.00296 |
| 8500 | 164 | 0.00109 | 66 | 0.00044 | 0.99390 | 0.00610 | 0.00613 | -0.00297 |
| 48600 | 164 | 0.00109 | 41 | 0.00027 | 0.99390 | 0.00610 | 0.00613 | -0.00297 |
| 54900 | 165 | 0.00110 | 61 | 0.00041 | 0.99394 | 0.00606 | 0.00610 | -0.00301 |
| 28100 | 330 | 0.00220 | 119 | 0.00079 | 0.99394 | 0.00606 | 0.00610 | -0.00301 |
| 49800 | 167 | 0.00111 | 53 | 0.00035 | 0.99401 | 0.00599 | 0.00602 | -0.00308 |
| 46700 | 168 | 0.00112 | 52 | 0.00035 | 0.99405 | 0.00595 | 0.00599 | -0.00311 |
| 64100 | 337 | 0.00225 | 122 | 0.00081 | 0.99407 | 0.00593 | 0.00597 | -0.00313 |
| 2600 | 170 | 0.00113 | 49 | 0.00033 | 0.99412 | 0.00588 | 0.00592 | -0.00319 |
| 46800 | 171 | 0.00114 | 59 | 0.00039 | 0.99415 | 0.00585 | 0.00588 | -0.00322 |
| 14000 | 174 | 0.00116 | 47 | 0.00031 | 0.99425 | 0.00575 | 0.00578 | -0.00332 |
| 14500 | 176 | 0.00117 | 55 | 0.00037 | 0.99432 | 0.00568 | 0.00571 | -0.00339 |
| 56300 | 178 | 0.00119 | 63 | 0.00042 | 0.99438 | 0.00562 | 0.00565 | -0.00345 |
| 61800 | 179 | 0.00119 | 45 | 0.00030 | 0.99441 | 0.00559 | 0.00562 | -0.00349 |
| 48100 | 904 | 0.00603 | 354 | 0.00236 | 0.99447 | 0.00553 | 0.00556 | -0.00354 |
| 11400 | 184 | 0.00123 | 52 | 0.00035 | 0.99457 | 0.00543 | 0.00546 | -0.00364 |
| 99200 | 185 | 0.00123 | 72 | 0.00048 | 0.99459 | 0.00541 | 0.00543 | -0.00367 |
| 95700 | 373 | 0.00249 | 125 | 0.00083 | 0.99464 | 0.00536 | 0.00539 | -0.00371 |
| 30300 | 563 | 0.00375 | 170 | 0.00113 | 0.99467 | 0.00533 | 0.00536 | -0.00375 |
| 84600 | 188 | 0.00125 | 59 | 0.00039 | 0.99468 | 0.00532 | 0.00535 | -0.00376 |
| 22000 | 377 | 0.00251 | 91 | 0.00061 | 0.99469 | 0.00531 | 0.00533 | -0.00377 |
| 89500 | 189 | 0.00126 | 64 | 0.00043 | 0.99471 | 0.00529 | 0.00532 | -0.00378 |
| 27500 | 760 | 0.00507 | 245 | 0.00163 | 0.99474 | 0.00526 | 0.00529 | -0.00381 |
| 63100 | 571 | 0.00381 | 149 | 0.00099 | 0.99475 | 0.00525 | 0.00528 | -0.00382 |
| 12500 | 191 | 0.00127 | 74 | 0.00049 | 0.99476 | 0.00524 | 0.00526 | -0.00384 |
| 4000 | 191 | 0.00127 | 55 | 0.00037 | 0.99476 | 0.00524 | 0.00526 | -0.00384 |
| 92100 | 790 | 0.00527 | 206 | 0.00137 | 0.99494 | 0.00506 | 0.00509 | -0.00401 |
| 45800 | 198 | 0.00132 | 72 | 0.00048 | 0.99495 | 0.00505 | 0.00508 | -0.00403 |
| 49400 | 399 | 0.00266 | 139 | 0.00093 | 0.99499 | 0.00501 | 0.00504 | -0.00407 |
| 75200 | 401 | 0.00267 | 155 | 0.00103 | 0.99501 | 0.00499 | 0.00501 | -0.00409 |
| 7000 | 603 | 0.00402 | 229 | 0.00153 | 0.99502 | 0.00498 | 0.00500 | -0.00410 |
| 37900 | 203 | 0.00135 | 68 | 0.00045 | 0.99507 | 0.00493 | 0.00495 | -0.00415 |
| 43100 | 203 | 0.00135 | 68 | 0.00045 | 0.99507 | 0.00493 | 0.00495 | -0.00415 |
| 37100 | 417 | 0.00278 | 161 | 0.00107 | 0.99520 | 0.00480 | 0.00482 | -0.00428 |
| 78600 | 627 | 0.00418 | 254 | 0.00169 | 0.99522 | 0.00478 | 0.00481 | -0.00430 |
| 20000 | 429 | 0.00286 | 104 | 0.00069 | 0.99534 | 0.00466 | 0.00468 | -0.00442 |
| 94500 | 1934 | 0.01289 | 466 | 0.00311 | 0.99535 | 0.00465 | 0.00468 | -0.00443 |
| 1800 | 436 | 0.00291 | 139 | 0.00093 | 0.99541 | 0.00459 | 0.00461 | -0.00449 |
| 45000 | 440 | 0.00293 | 119 | 0.00079 | 0.99545 | 0.00455 | 0.00457 | -0.00454 |
| 91000 | 222 | 0.00148 | 54 | 0.00036 | 0.99550 | 0.00450 | 0.00452 | -0.00458 |
| 94600 | 224 | 0.00149 | 69 | 0.00046 | 0.99554 | 0.00446 | 0.00448 | -0.00462 |
| 7400 | 224 | 0.00149 | 101 | 0.00067 | 0.99554 | 0.00446 | 0.00448 | -0.00462 |
| 8800 | 449 | 0.00299 | 155 | 0.00103 | 0.99555 | 0.00445 | 0.00447 | -0.00463 |
| 18900 | 225 | 0.00150 | 53 | 0.00035 | 0.99556 | 0.00444 | 0.00446 | -0.00464 |
| 28600 | 225 | 0.00150 | 58 | 0.00039 | 0.99556 | 0.00444 | 0.00446 | -0.00464 |
| 11300 | 229 | 0.00153 | 81 | 0.00054 | 0.99563 | 0.00437 | 0.00439 | -0.00472 |
| 3800 | 231 | 0.00154 | 63 | 0.00042 | 0.99567 | 0.00433 | 0.00435 | -0.00476 |
| 85000 | 693 | 0.00462 | 263 | 0.00175 | 0.99567 | 0.00433 | 0.00435 | -0.00476 |
| 74000 | 234 | 0.00156 | 77 | 0.00051 | 0.99573 | 0.00427 | 0.00429 | -0.00481 |
| 97100 | 235 | 0.00157 | 87 | 0.00058 | 0.99574 | 0.00426 | 0.00427 | -0.00483 |
| 2700 | 236 | 0.00157 | 71 | 0.00047 | 0.99576 | 0.00424 | 0.00426 | -0.00485 |
| 35200 | 236 | 0.00157 | 82 | 0.00055 | 0.99576 | 0.00424 | 0.00426 | -0.00485 |
| 93700 | 238 | 0.00159 | 81 | 0.00054 | 0.99580 | 0.00420 | 0.00422 | -0.00488 |
| 68100 | 238 | 0.00159 | 79 | 0.00053 | 0.99580 | 0.00420 | 0.00422 | -0.00488 |
| 43500 | 240 | 0.00160 | 70 | 0.00047 | 0.99583 | 0.00417 | 0.00418 | -0.00492 |
| 15200 | 241 | 0.00161 | 75 | 0.00050 | 0.99585 | 0.00415 | 0.00417 | -0.00494 |
| 80000 | 726 | 0.00484 | 295 | 0.00197 | 0.99587 | 0.00413 | 0.00415 | -0.00495 |
| 27200 | 246 | 0.00164 | 70 | 0.00047 | 0.99593 | 0.00407 | 0.00408 | -0.00502 |
| 20800 | 496 | 0.00331 | 100 | 0.00067 | 0.99597 | 0.00403 | 0.00405 | -0.00505 |
| 48400 | 249 | 0.00166 | 92 | 0.00061 | 0.99598 | 0.00402 | 0.00403 | -0.00507 |
| 95200 | 254 | 0.00169 | 103 | 0.00069 | 0.99606 | 0.00394 | 0.00395 | -0.00515 |
| 80900 | 254 | 0.00169 | 131 | 0.00087 | 0.99606 | 0.00394 | 0.00395 | -0.00515 |
| 19300 | 256 | 0.00171 | 73 | 0.00049 | 0.99609 | 0.00391 | 0.00392 | -0.00518 |
| 94900 | 257 | 0.00171 | 62 | 0.00041 | 0.99611 | 0.00389 | 0.00391 | -0.00520 |
| 53200 | 261 | 0.00174 | 99 | 0.00066 | 0.99617 | 0.00383 | 0.00385 | -0.00526 |
| 95000 | 522 | 0.00348 | 120 | 0.00080 | 0.99617 | 0.00383 | 0.00385 | -0.00526 |
| 55400 | 797 | 0.00531 | 248 | 0.00165 | 0.99624 | 0.00376 | 0.00378 | -0.00532 |
| 48000 | 801 | 0.00534 | 286 | 0.00191 | 0.99625 | 0.00375 | 0.00376 | -0.00534 |
| 18000 | 267 | 0.00178 | 85 | 0.00057 | 0.99625 | 0.00375 | 0.00376 | -0.00534 |
| 98000 | 1071 | 0.00714 | 372 | 0.00248 | 0.99627 | 0.00373 | 0.00375 | -0.00535 |
| 23200 | 284 | 0.00189 | 83 | 0.00055 | 0.99648 | 0.00352 | 0.00353 | -0.00557 |
| 92000 | 884 | 0.00589 | 262 | 0.00175 | 0.99661 | 0.00339 | 0.00341 | -0.00570 |
| 19400 | 301 | 0.00201 | 77 | 0.00051 | 0.99668 | 0.00332 | 0.00333 | -0.00577 |
| 90700 | 315 | 0.00210 | 99 | 0.00066 | 0.99683 | 0.00317 | 0.00318 | -0.00592 |
| 78700 | 647 | 0.00431 | 203 | 0.00135 | 0.99691 | 0.00309 | 0.00310 | -0.00600 |
| 66000 | 342 | 0.00228 | 73 | 0.00049 | 0.99708 | 0.00292 | 0.00293 | -0.00617 |
| 95400 | 342 | 0.00228 | 111 | 0.00074 | 0.99708 | 0.00292 | 0.00293 | -0.00617 |
| 37200 | 349 | 0.00233 | 118 | 0.00079 | 0.99713 | 0.00287 | 0.00287 | -0.00623 |
| 2100 | 698 | 0.00465 | 174 | 0.00116 | 0.99713 | 0.00287 | 0.00287 | -0.00623 |
| 53500 | 357 | 0.00238 | 104 | 0.00069 | 0.99720 | 0.00280 | 0.00281 | -0.00629 |
| 66200 | 375 | 0.00250 | 92 | 0.00061 | 0.99733 | 0.00267 | 0.00267 | -0.00643 |
| 80100 | 771 | 0.00514 | 284 | 0.00189 | 0.99741 | 0.00259 | 0.00260 | -0.00650 |
| 92200 | 391 | 0.00261 | 171 | 0.00114 | 0.99744 | 0.00256 | 0.00256 | -0.00654 |
| 80200 | 814 | 0.00543 | 319 | 0.00213 | 0.99754 | 0.00246 | 0.00246 | -0.00664 |
| 94000 | 449 | 0.00299 | 68 | 0.00045 | 0.99777 | 0.00223 | 0.00223 | -0.00687 |
| 95600 | 902 | 0.00601 | 309 | 0.00206 | 0.99778 | 0.00222 | 0.00222 | -0.00688 |
| 20100 | 939 | 0.00626 | 199 | 0.00133 | 0.99787 | 0.00213 | 0.00213 | -0.00697 |
| 90200 | 484 | 0.00323 | 122 | 0.00081 | 0.99793 | 0.00207 | 0.00207 | -0.00703 |
| 80500 | 496 | 0.00331 | 228 | 0.00152 | 0.99798 | 0.00202 | 0.00202 | -0.00708 |
| 98200 | 508 | 0.00339 | 258 | 0.00172 | 0.99803 | 0.00197 | 0.00197 | -0.00713 |
| 91700 | 1116 | 0.00744 | 355 | 0.00237 | 0.99821 | 0.00179 | 0.00180 | -0.00731 |
| 95100 | 654 | 0.00436 | 135 | 0.00090 | 0.99847 | 0.00153 | 0.00153 | -0.00757 |
| 92600 | 987 | 0.00658 | 227 | 0.00151 | 0.99899 | 0.00101 | 0.00101 | -0.00809 |
| 69100 | 31 | 0.00021 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 69000 | 12 | 0.00008 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 75900 | 38 | 0.00025 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 93900 | 173 | 0.00115 | 65 | 0.00043 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 94300 | 23 | 0.00015 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 94100 | 270 | 0.00180 | 44 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 92700 | 209 | 0.00139 | 49 | 0.00033 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 69200 | 2 | 0.00001 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 69300 | 21 | 0.00014 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 93400 | 322 | 0.00215 | 98 | 0.00065 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 93100 | 99 | 0.00066 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 70300 | 59 | 0.00039 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 92800 | 840 | 0.00560 | 231 | 0.00154 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 94400 | 78 | 0.00052 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 91800 | 40 | 0.00027 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 91600 | 130 | 0.00087 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 90800 | 235 | 0.00157 | 66 | 0.00044 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 90000 | 697 | 0.00465 | 182 | 0.00121 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 68800 | 52 | 0.00035 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 96900 | 21 | 0.00014 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 68700 | 33 | 0.00022 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67700 | 3 | 0.00002 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99800 | 40 | 0.00027 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67300 | 11 | 0.00007 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99700 | 20 | 0.00013 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99600 | 78 | 0.00052 | 37 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67500 | 28 | 0.00019 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67600 | 17 | 0.00011 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99400 | 8 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99300 | 147 | 0.00098 | 61 | 0.00041 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99100 | 38 | 0.00025 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 98800 | 143 | 0.00095 | 50 | 0.00033 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 98600 | 422 | 0.00281 | 197 | 0.00131 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 98500 | 233 | 0.00155 | 90 | 0.00060 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 98100 | 624 | 0.00416 | 240 | 0.00160 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 68600 | 24 | 0.00016 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67800 | 59 | 0.00039 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67900 | 8 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97900 | 7 | 0.00005 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97800 | 42 | 0.00028 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97700 | 233 | 0.00155 | 86 | 0.00057 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97600 | 27 | 0.00018 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 68300 | 23 | 0.00015 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97500 | 171 | 0.00114 | 69 | 0.00046 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 97300 | 319 | 0.00213 | 146 | 0.00097 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 68400 | 25 | 0.00017 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 95500 | 56 | 0.00037 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 94700 | 85 | 0.00057 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 89400 | 163 | 0.00109 | 71 | 0.00047 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 71400 | 13 | 0.00009 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 89300 | 3 | 0.00002 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79800 | 7 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83100 | 12 | 0.00008 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83000 | 17 | 0.00011 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 82600 | 47 | 0.00031 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 82300 | 7 | 0.00005 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 82200 | 3 | 0.00002 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 81400 | 30 | 0.00020 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 81300 | 31 | 0.00021 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 81200 | 71 | 0.00047 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 80800 | 51 | 0.00034 | 32 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 80700 | 20 | 0.00013 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 80300 | 75 | 0.00050 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 74500 | 11 | 0.00007 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 74600 | 4 | 0.00003 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 74700 | 12 | 0.00008 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79600 | 46 | 0.00031 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 88400 | 1 | 0.00001 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79500 | 14 | 0.00009 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79400 | 90 | 0.00060 | 41 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 74900 | 13 | 0.00009 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79300 | 28 | 0.00019 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79000 | 25 | 0.00017 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78900 | 10 | 0.00007 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78800 | 12 | 0.00008 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 75400 | 63 | 0.00042 | 37 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 75500 | 19 | 0.00013 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78500 | 134 | 0.00089 | 59 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78400 | 78 | 0.00052 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78300 | 54 | 0.00036 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 78000 | 150 | 0.00100 | 47 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 76300 | 13 | 0.00009 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83200 | 58 | 0.00039 | 26 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 73900 | 2 | 0.00001 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 73800 | 4 | 0.00003 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83300 | 79 | 0.00053 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 71300 | 31 | 0.00021 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 76100 | 303 | 0.00202 | 142 | 0.00095 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 88300 | 24 | 0.00016 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 71600 | 27 | 0.00018 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 71700 | 13 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 71800 | 14 | 0.00009 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 88200 | 46 | 0.00031 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 88100 | 15 | 0.00010 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 87900 | 3 | 0.00002 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 87700 | 5 | 0.00003 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72300 | 24 | 0.00016 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72400 | 51 | 0.00034 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 87400 | 28 | 0.00019 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72500 | 23 | 0.00015 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72600 | 45 | 0.00030 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 87300 | 7 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 86300 | 156 | 0.00104 | 69 | 0.00046 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72800 | 23 | 0.00015 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 86000 | 92 | 0.00061 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 72900 | 34 | 0.00023 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 85500 | 38 | 0.00025 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 84700 | 186 | 0.00124 | 104 | 0.00069 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 84500 | 24 | 0.00016 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 84300 | 92 | 0.00061 | 45 | 0.00030 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83600 | 276 | 0.00184 | 115 | 0.00077 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83500 | 11 | 0.00007 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 83400 | 91 | 0.00061 | 29 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 73600 | 6 | 0.00004 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 73700 | 24 | 0.00016 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67200 | 161 | 0.00107 | 41 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 600 | 12 | 0.00008 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 67000 | 67 | 0.00045 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19800 | 84 | 0.00056 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17900 | 30 | 0.00020 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18400 | 83 | 0.00055 | 23 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18500 | 19 | 0.00013 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18600 | 48 | 0.00032 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 18800 | 14 | 0.00009 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 19500 | 113 | 0.00075 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21400 | 79 | 0.00053 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 32300 | 168 | 0.00112 | 73 | 0.00049 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21500 | 19 | 0.00013 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 21800 | 91 | 0.00061 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22800 | 69 | 0.00046 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 22900 | 149 | 0.00099 | 43 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 23500 | 64 | 0.00043 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 23900 | 22 | 0.00015 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17700 | 39 | 0.00026 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17600 | 83 | 0.00055 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17500 | 146 | 0.00097 | 40 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17400 | 86 | 0.00057 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 17200 | 60 | 0.00040 | 21 | 0.00014 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16900 | 11 | 0.00007 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16800 | 74 | 0.00049 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16700 | 4 | 0.00003 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16500 | 36 | 0.00024 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16400 | 22 | 0.00015 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16200 | 8 | 0.00005 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16100 | 45 | 0.00030 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 16000 | 92 | 0.00061 | 32 | 0.00021 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15900 | 31 | 0.00021 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15800 | 8 | 0.00005 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15700 | 9 | 0.00006 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15600 | 92 | 0.00061 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24300 | 29 | 0.00019 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24600 | 7 | 0.00005 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24700 | 5 | 0.00003 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26600 | 4 | 0.00003 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30800 | 74 | 0.00049 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30400 | 53 | 0.00035 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29900 | 115 | 0.00077 | 46 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29700 | 197 | 0.00131 | 63 | 0.00042 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29300 | 154 | 0.00103 | 52 | 0.00035 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 29200 | 117 | 0.00078 | 36 | 0.00024 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28900 | 26 | 0.00017 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 28800 | 79 | 0.00053 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27700 | 145 | 0.00097 | 62 | 0.00041 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27600 | 370 | 0.00247 | 105 | 0.00070 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27400 | 141 | 0.00094 | 46 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 27300 | 145 | 0.00097 | 44 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26800 | 3 | 0.00002 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26700 | 18 | 0.00012 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26500 | 69 | 0.00046 | 33 | 0.00022 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24800 | 1 | 0.00001 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26400 | 6 | 0.00004 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26300 | 20 | 0.00013 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26200 | 11 | 0.00007 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26100 | 18 | 0.00012 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 26000 | 22 | 0.00015 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25900 | 4 | 0.00003 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25800 | 22 | 0.00015 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25700 | 15 | 0.00010 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25600 | 5 | 0.00003 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25500 | 39 | 0.00026 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25200 | 13 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25100 | 13 | 0.00009 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 25000 | 7 | 0.00005 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 24900 | 12 | 0.00008 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15500 | 17 | 0.00011 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15400 | 24 | 0.00016 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15300 | 66 | 0.00044 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4700 | 4 | 0.00003 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 7800 | 217 | 0.00145 | 83 | 0.00055 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 7500 | 33 | 0.00022 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 7200 | 24 | 0.00016 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 6100 | 100 | 0.00067 | 35 | 0.00023 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 6000 | 312 | 0.00208 | 87 | 0.00058 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5900 | 3 | 0.00002 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5800 | 35 | 0.00023 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5700 | 41 | 0.00027 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5400 | 247 | 0.00165 | 58 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5300 | 33 | 0.00022 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5200 | 8 | 0.00005 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5100 | 22 | 0.00015 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 5000 | 23 | 0.00015 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4800 | 26 | 0.00017 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4600 | 21 | 0.00014 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10100 | 4 | 0.00003 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4500 | 36 | 0.00024 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4400 | 43 | 0.00029 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4300 | 24 | 0.00016 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 4200 | 50 | 0.00033 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 3700 | 42 | 0.00028 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 3600 | 4 | 0.00003 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 3500 | 10 | 0.00007 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 3200 | 100 | 0.00067 | 43 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 3000 | 304 | 0.00203 | 78 | 0.00052 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 2500 | 71 | 0.00047 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 2400 | 243 | 0.00162 | 39 | 0.00026 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 1200 | 37 | 0.00025 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 1100 | 34 | 0.00023 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 800 | 7 | 0.00005 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 7900 | 142 | 0.00095 | 38 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10200 | 3 | 0.00002 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 15100 | 115 | 0.00077 | 47 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13100 | 27 | 0.00018 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14900 | 13 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14700 | 22 | 0.00015 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14400 | 131 | 0.00087 | 36 | 0.00024 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14300 | 11 | 0.00007 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14200 | 152 | 0.00101 | 49 | 0.00033 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 14100 | 56 | 0.00037 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13900 | 8 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13800 | 22 | 0.00015 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13700 | 22 | 0.00015 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13600 | 23 | 0.00015 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13500 | 14 | 0.00009 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13400 | 32 | 0.00021 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13300 | 34 | 0.00023 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 13200 | 33 | 0.00022 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12900 | 38 | 0.00025 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10400 | 83 | 0.00055 | 35 | 0.00023 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12800 | 76 | 0.00051 | 26 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12700 | 24 | 0.00016 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12600 | 30 | 0.00020 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12200 | 51 | 0.00034 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 12100 | 124 | 0.00083 | 42 | 0.00028 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11800 | 35 | 0.00023 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11600 | 10 | 0.00007 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11500 | 282 | 0.00188 | 82 | 0.00055 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11200 | 437 | 0.00291 | 118 | 0.00079 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 11100 | 15 | 0.00010 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10800 | 20 | 0.00013 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10700 | 59 | 0.00039 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10600 | 48 | 0.00032 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 10500 | 279 | 0.00186 | 83 | 0.00055 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 30900 | 63 | 0.00042 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36000 | 65 | 0.00043 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 66900 | 2 | 0.00001 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58000 | 75 | 0.00050 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 56600 | 64 | 0.00043 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 57000 | 41 | 0.00027 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 57200 | 14 | 0.00009 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 57400 | 11 | 0.00007 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 57500 | 6 | 0.00004 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 57600 | 1 | 0.00001 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58100 | 80 | 0.00053 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36700 | 16 | 0.00011 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58300 | 13 | 0.00009 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58400 | 18 | 0.00012 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58500 | 84 | 0.00056 | 21 | 0.00014 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58600 | 26 | 0.00017 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58700 | 52 | 0.00035 | 17 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 58800 | 13 | 0.00009 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 56400 | 105 | 0.00070 | 37 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 56200 | 70 | 0.00047 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 56100 | 17 | 0.00011 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 56000 | 116 | 0.00077 | 35 | 0.00023 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 55900 | 185 | 0.00123 | 64 | 0.00043 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 55700 | 70 | 0.00047 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 55600 | 8 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 54600 | 71 | 0.00047 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 54300 | 95 | 0.00063 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 54200 | 86 | 0.00057 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 54100 | 139 | 0.00093 | 45 | 0.00030 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 53800 | 11 | 0.00007 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 53700 | 151 | 0.00101 | 41 | 0.00027 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 53400 | 77 | 0.00051 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52700 | 80 | 0.00053 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52600 | 18 | 0.00012 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52500 | 12 | 0.00008 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59000 | 40 | 0.00027 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59200 | 12 | 0.00008 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59300 | 7 | 0.00005 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 62400 | 47 | 0.00031 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 66700 | 11 | 0.00007 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 66500 | 76 | 0.00051 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 66400 | 27 | 0.00018 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 66100 | 44 | 0.00029 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 65100 | 18 | 0.00012 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 64600 | 15 | 0.00010 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 64500 | 20 | 0.00013 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 64400 | 17 | 0.00011 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 63900 | 4 | 0.00003 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 63800 | 16 | 0.00011 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 63500 | 6 | 0.00004 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 63300 | 424 | 0.00283 | 157 | 0.00105 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 62700 | 43 | 0.00029 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 62600 | 50 | 0.00033 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 62300 | 17 | 0.00011 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59500 | 2 | 0.00001 | 7 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 62000 | 154 | 0.00103 | 59 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61900 | 39 | 0.00026 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61600 | 67 | 0.00045 | 28 | 0.00019 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61500 | 108 | 0.00072 | 35 | 0.00023 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61400 | 48 | 0.00032 | 21 | 0.00014 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61300 | 53 | 0.00035 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61200 | 78 | 0.00052 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 61100 | 70 | 0.00047 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 60800 | 26 | 0.00017 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 60700 | 71 | 0.00047 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 60300 | 58 | 0.00039 | 19 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59900 | 78 | 0.00052 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59700 | 127 | 0.00085 | 42 | 0.00028 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 59600 | 43 | 0.00029 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52200 | 54 | 0.00036 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52100 | 32 | 0.00021 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 52000 | 57 | 0.00038 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40700 | 31 | 0.00021 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43200 | 348 | 0.00232 | 102 | 0.00068 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42600 | 16 | 0.00011 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42500 | 29 | 0.00019 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42400 | 40 | 0.00027 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42300 | 76 | 0.00051 | 27 | 0.00018 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 42200 | 29 | 0.00019 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41800 | 3 | 0.00002 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41600 | 9 | 0.00006 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41500 | 4 | 0.00003 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41400 | 1 | 0.00001 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41300 | 5 | 0.00003 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 41100 | 34 | 0.00023 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40900 | 7 | 0.00005 | 3 | 0.00002 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40800 | 1 | 0.00001 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40600 | 21 | 0.00014 | 9 | 0.00006 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44500 | 53 | 0.00035 | 13 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40500 | 229 | 0.00153 | 76 | 0.00051 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 40100 | 41 | 0.00027 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39800 | 13 | 0.00009 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39700 | 22 | 0.00015 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39600 | 16 | 0.00011 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39300 | 14 | 0.00009 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 39200 | 37 | 0.00025 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38900 | 5 | 0.00003 | 6 | 0.00004 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38800 | 28 | 0.00019 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38700 | 3 | 0.00002 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38500 | 57 | 0.00038 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38300 | 62 | 0.00041 | 20 | 0.00013 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 38200 | 29 | 0.00019 | 5 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 36900 | 2 | 0.00001 | Missings | Missings | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 43800 | 10 | 0.00007 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44700 | 64 | 0.00043 | 22 | 0.00015 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 51600 | 5 | 0.00003 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47800 | 92 | 0.00061 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 51400 | 13 | 0.00009 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 51300 | 50 | 0.00033 | 16 | 0.00011 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50800 | 5 | 0.00003 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50700 | 22 | 0.00015 | 4 | 0.00003 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50500 | 44 | 0.00029 | 14 | 0.00009 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50300 | 129 | 0.00086 | 47 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50200 | 140 | 0.00093 | 58 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 50000 | 124 | 0.00083 | 44 | 0.00029 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49900 | 24 | 0.00016 | 11 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49300 | 268 | 0.00179 | 82 | 0.00055 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49200 | 159 | 0.00106 | 61 | 0.00041 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49100 | 44 | 0.00029 | 15 | 0.00010 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 49000 | 350 | 0.00233 | 108 | 0.00072 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 700 | 13 | 0.00009 | 1 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47700 | 106 | 0.00071 | 42 | 0.00028 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44800 | 92 | 0.00061 | 25 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47600 | 59 | 0.00039 | 26 | 0.00017 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47500 | 67 | 0.00045 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47400 | 91 | 0.00061 | 37 | 0.00025 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 47300 | 118 | 0.00079 | 39 | 0.00026 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46900 | 116 | 0.00077 | 47 | 0.00031 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46600 | 46 | 0.00031 | 18 | 0.00012 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46400 | 21 | 0.00014 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46200 | 362 | 0.00241 | 161 | 0.00107 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 46100 | 366 | 0.00244 | 140 | 0.00093 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45700 | 18 | 0.00012 | 10 | 0.00007 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45600 | 59 | 0.00039 | 24 | 0.00016 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45500 | 43 | 0.00029 | 12 | 0.00008 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 45400 | 209 | 0.00139 | 59 | 0.00039 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 44900 | 32 | 0.00021 | 8 | 0.00005 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 99900 | 13 | 0.00009 | 2 | 0.00001 | 1.00000 | 0.00000 | 0.00000 | -0.00910 |
| 79200 | Missings | Missings | 2 | 0.00001 | Missings | Missings | Missings | Missings |
Image 4: Illustration of Multi-Stage Model Design; own illustration.
To answer our research question and test our hypothesis, we develop a multi-stage model as illustrated in Figure 4. In the initial modelling stage, the data is cleaned, and features are engineered. In Stage II a white-box and a black-box model are compared along their predictive performance (as measured by the AUC) and their interpretability to test Hypothesis I and II. As our baseline model, we choose Logistic Regression, which is seen as inherently interpretable thanks to its simplicity (Bussmann et al. 2019; Dumitrescu et al. 2022; Li et al. 2020). It is frequently employed as a benchmark both in the machine learning research community (Emad Azhar Ali et al. 2021; Altinbas and Akkaya 2017) and in financial institutions to evaluate credit risk in a way that is easy to communicate to regulators (Dumitrescu et al. 2022, 2022; Lipton 2016; Liu et al. 2022, p. 5326), as pioneered by Steenackers and Goovaerts (1989). This simplicity comes with shortcomings, such as strong assumptions (a linear relationship between features and targets) and biased results in the presence of outliers. Machine learning algorithms are seen as a potential remedy.(Emad Azhar Ali et al. 2021; Xia et al. 2020) Therefore, we choose extreme gradient boosting (XGBoost) as our competing model, which we suspect to have a higher predictive power but lower inherent interpretability (as formulated in Hypotheses I and II).
To enhance the interpretability of the XGBoost machine, we employ three different model-agnostic, post-hoc interpretability methods in Stage III:
The consecutive section gives a brief overview of the theoretical backgrounds of the methods employed.
Logistic Regression is one of the most popular models for the classification of binary target variables. As in any model within the class of binary response models, logit ensures that the conditional probability $P_i$ that $y_i=1$ given the information set $\Omega_i$ lies within the 0-1-interval. In general, this is achieved by specifying that $P_i \equiv E(y_i | \Omega_i) = F(X_i\beta)$, where $X_i \beta $ serves as an index function, hence mapping a feature vector $X_i$ and the parameter vector $\beta$ to a scalar index. $F_i()$ is a function that transforms its input values $X_i \beta$ in a way that ensures that they are bounded by 0 and 1. In the case of logit, this transformation function $F_i()$ is the logistic function $\Lambda (x) = \frac{1}{1+e^{-x}}$. The conditional probability of $y_i=1$ is then given by $P_i = \frac{exp(X_t \beta)}{1+ X_t \beta} = \frac{1}{1+exp(X_t \beta)}$. Usually, logit models (as well as other forms of binary response models) are solved using maximum likelihood estimation. (Davidson and MacKinnon 2004)
As the question of default versus non-default of a given loan constitutes a binary classification problem, it is well suited for the application of logit. The downside of logit, however, is that contrary to linear regression, it is not possible to directly interpret the coefficients $\beta$. Instead, one may interpret the change in the log odds (“How much do the log odds of the target change with a one unit change in the features?”). The odds, or more technically the odds of success, are defined as the probability of success over the probability of failure. In the credit risk application, this translates to the probability of defaulting over the probability of not-defaulting. The log odds are simply the logarithm of the odds. For standardized data, the intuitive interpretation for single coefficients is not given anymore. Therefore, one may question the interpretability of this type of model outcome, as it requires statistical knowledge regarding odd-ratios. Nevertheless, as mentioned above, logit is frequently used in machine learning and in credit risk applications. Therefore, it constitutes a natural benchmark against which alternative modelling approaches can be evaluated.
The gradient boosting algorithm (XGBoost) belongs to the ensemble methods. These methods are characterized by the fact that they build powerful predictive models by using base learners as their foundation. In terms of application, the gradient boosting algorithm can be applied to both regression and classification problems. With regard to the inner flow structure, the base learners used are modified by means of boosting. This process is controlled by a learning rate set by the user. Within the further explanation of the algorithm, reference is made to the application with regard to a classification problem, as this is addressed within the project. The starting point of the algorithm is an initial prediction that has to be made. This initial prediction is calculated based on the log odds of all individuals within the target variable. Due to the classification problem, this value must now be converted into a probability. This is achieved by the usage of the logistic function. This conversion represents the first difference in terms of application to regression problems.
After a matching format was achieved pseudo residuals are generated based on the difference of observed and predicted values. These residuals form the target value of the base learner to be generated. This base learner determines the corresponding output values on the basis of the feature values of the different individuals. Similar to the previous step, these values must also be converted into probabilities. This step represents the second difference in terms of applying it to a regression problem.
After ensuring consistent formats, the initial predictions can be updated. This is achieved by combining the initial predictions with the predictions of the first base learner. Here, the predicted value of the base learner is modified using the previously determined learning rate and added to the initial predicted value. This process is now reinitiated with the updated prediction value and repeated until the specified number of base learners is reached which leads to the determination of the algorithm. (Friedman 2001)
Inspired by Baesens et al. (2003), we also experimented with neural networks. However, we were unable to achieve a higher AUC as the one for XGBoost (maximum AUC using Neural Networks: 0.65). We rationalize this by noting that applying neural networks to tabular data remains challenging (Borisov et al. 2021). This is in line with the results of Lundberg et al. (2020) who state that “[w]hile deep learning models are more appropriate in fields like image recognition, speech recognition, and natural language processing, tree-based models consistently outperform standard deep models on tabular-style datasets where features are individually meaningful and do not have strong multi-scale temporal or spatial structures”.
Lundberg et al. (2020) add that the low bias of tree-based models increases their inherent interpretability. They contrast the view that linear models are generally more interpretable as this viewpoint neglects the potential model mismatch when using a linear model that simplifies the true feature-target-relationship too much. (Lundberg et al. 2020) These considerations support our choice of XGBoost for the research question at hand.
With regard to the model agnostic methods, the anchor method is assigned to the post-hoc methods and can be docked de facto to any black-box model in order to make the model interpretable. Within the inner procedure of this method, a rule is defined for a given instance with respect to the features passed to the model, which should indicate which features either have an effect on the target variable or not when their values are changed. The resulting rules have an IF-THEN form and can be reused due to their scaling, which leads to the idea of coverage, where the identified rule is applied to other instances of the dataset.
The Anchor as object of this method can be defined formally as follows: $𝔼_{\mathcal{D}_x(z|A)}[1_{\hat{f}(x)=\hat{f}(z)}]\ge\tau,A(x) = 1$, where
In an informal way, the previous rule and its notation can be understood as follows. Given a data point $x$ to be explained, a rule $A$ is to be found so that it can be applied to $x$ and in addition is simultaneously applicable to a set of neighbors which are limited by $\tau$ in view of precision. The evaluation of the rule with regard to a sufficient accuracy is achieved by ${\mathcal{D}_x(z|A)}$, whereby the output of the learning model is used as a correspondence $1_{\hat{f}(x)=\hat{f}(z)}$. With regard to formal completeness, the anchor method explained in the previous section is sufficient, but within the practical application, efficiency problems with regard to computability arise with larger datasets due to the fact that an evaluation of the dataset in notion of the form $\mathcal{D}_x(z|A)$ would be computationally too costly. For this aim Ribeiro et al. (2018) introduced a further parameter which is integrated into their probabilistic definition in the following form: P(prec(A) ≥ $\tau$ ) ≥ 1 − δ. By introducing this parameter and defining the precision as follows: prec(A) = $𝔼_{\mathcal{D}_x(z|A)}[1_{\hat{f}(x)=\hat{f}(z)}]$, statistical confidence with respect to the precision can be achieved which means the defined anchors can satisfy the precision constraint with high probability.
In the context of the current form, it is now logically possible that more than one anchor can be identified within Anchor Determination, which can fulfill the described constraint. With regard to this property, the component of coverage is used to resolve this conflict, which is defined as follows: $cov(A)=𝔼_{\mathcal{D}(z)}[A(z)]$. The final goal of the anchor definition is now to maximize the coverage value with regard to all explained components. This gives the solution to the previous problem, since now the anchor that maximizes the coverage value is chosen from the pool of identified anchors.(Molnar 2022; Ribeiro et al. 2018)
Ribeiro et al. (2016) introduce Locally Interpretable Model-agnostic Explanations (LIME) to explain any black-box machine learning model by a "locally faithful" interpretable model. The algorithm therefore belongs to the group of model-agnostic methods. Within the implementation interpretable representation of the data is used regardless of the actual features of the original model. Considering the ultimate goal of explaining the model in a way that is understandable to humans, the fidelity-interpretability trade-off emerges as a challenge for interpretability. In this regard, the desired interpretability method should provide understandable explanations while using a model that is adequately faithful to the black-box model in its predictions. In doing so, LIME uses an objective function that incorporates interpretability and local fidelity without any assumption about the black-box model. The former is measured by a loss function and the latter by adding a complexity measure into the following objective function: $$ξ(x) = argmin_{g\in G}\mathcal{L} \left( f, g, \pi_{X_i} \right) + Ω(g)$$ Where the locally weighted square loss is used as the loss function $$ \mathcal{L} \left( f, g, \pi_{X_i} \right) = \sum_{j=1}^{J} \pi_{X_i}\left( Z_i \right) \left( f\left( Z_j \right)- g \left( Z_j \right) \right)^2 $$ with $ \pi_{X_i}\left( Z_i \right)=\exp \left( - \frac{D\left(X_i,Z_j\right)}{\sigma^2}\right)$ as an exponential kernel defined on a distance function $D\left(X_i,Z_j\right)$ (e.g. cosine distance for text, $L2$ distance for images) with width $σ$. In principle, minimizing the loss function while keeping $Ω(g)$ low enough ensures an interpretable yet locally faithful model.
Figure 5 represents the intuition of LIME in local model training using tabular data. In this example, a classification prediction by Random Forest is explained using a linear classifier.
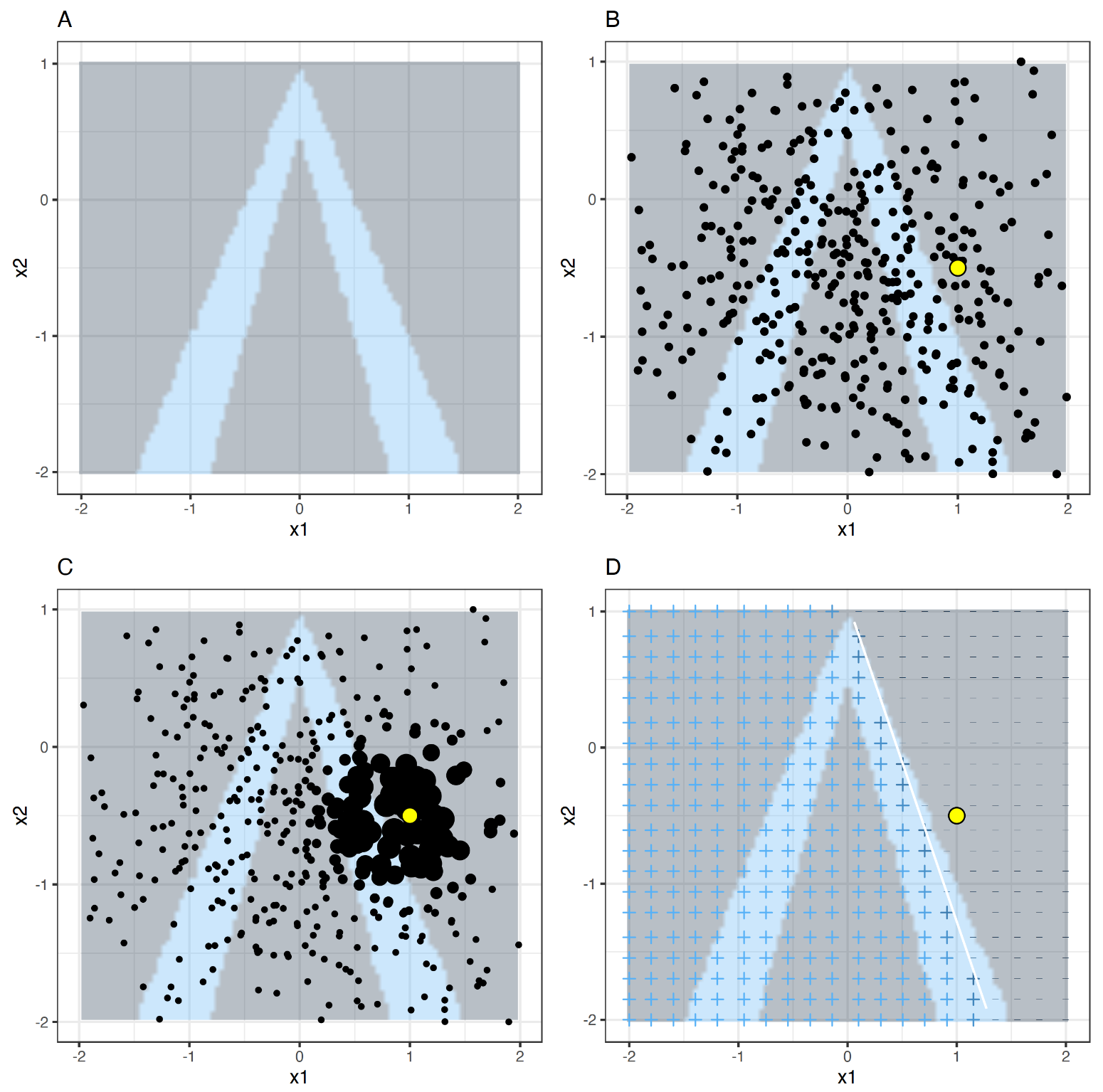
Image 5: The intuition of LIME in local model training using tabular data (Molnar 2022)
A) Random forest predictions given features x1 and x2. Predicted classes: 1 (dark) or 0 (light).
B) Instance of interest (big dot) and data sampled from a normal distribution (small dots).
C) Assign higher weight to points near the instance of interest.
D) Signs of the grid show the classifications of the locally learned model from the weighted samples. The white line marks the decision boundary (P(class=1) = 0.5).
Accordingly, LIME explains the instance of interest in a 5-stage process:
Stability of LIME
Regardless of its advantages, LIME may suffer from a lack of stability, i.e. repeated applications of the method under the same conditions may obtain different results. Instability is particularly an issue when it comes to interpretability as it makes the interpretations less reliable which, consequently, diminishes the trust in the method. The issue is however frequently overlooked.
To enlighten the stability problem with LIME, its origin could be found in the sensitivity of the method's definition when it comes to the dimensionality of the dataset. In this regard, the weighting kernel used in LIME with a huge number of variables makes the local explanation unable to discriminate among relevant and irrelevant features and which negatively affects the data point weighting, namely step 3, in the explanation process. During the process, the kernel function is applied before variable selection which makes the kernel function unable to distinguish between near and distant points, considering all of them approximately at the same distance. This leads to a loss of the locality and consequently declined performance of the algorithm. Therefore, recognizing the issue, as well as having the tool for spotting it becomes an important task when employing LIME. In doing so, Visani et al. (2022) introduce two complementary measures: Variable Stability Index (VSI) and Coefficient Stability Index (CSI): "By construction, VSI measures the concordance of the variables retrieved, whereas CSI tests the similarity among coefficients for the same variable, in repeated LIME calls. Both of them range from 0 to 100". While both of these indices point to stability, each value checks a particular stability instance. A high VSI ensures the practitioner that LIME explanations are almost always the same, while a low value for VSI shows that the results are prone to change with repeated calls of the same decision, making the explanation unreliable. On the other hand, high CSI guarantees trustworthy LIME coefficients while low values alert to potential risks of changing the magnitude and consequently the sign of the contribution of a feature in different calls. Considering the fact that a LIME coefficient represents the impact of the feature on the particular machine learning decision, obtaining different values lead to completely different explanations. It should be mentioned that while high values for both indices ensures stability, low values for only one metric do not. More importantly, having these two measures could better guide the practitioner in finding the source of instability.(Molnar 2022)
SHAP (Shapley Additive exPlanations) introduced by Lundberg and Lee (2017) is a game theoretic approach to explain the output of any machine learning model and therefore also belong to the model-agnostic methods. The goal is to explain the prediction of an observation $X_i$ by computing the contribution of each feature to the prediction.
SHAP is based on Shapley values, a cooperative game theory method, introduced by Shapley (1953). The basic concept of Shapley values is to assign payouts to players depending on their contribution to the total payout. Players cooperate in a coalition and receive a certain profit from this cooperation. Transferring this concept to machine learning algorithms, the “game” is the prediction task for a single observation of the dataset. The “gain” is the actual prediction made for this observation minus the average prediction over all instances. The “players” represent the specific feature values of the observation that cooperate to receive the “gain” or to predict a certain value. Hence the Shapley values represent a fair distribution of the prediction among the features.
Young (1985) demonstrated that Shapley values are the only set of values that satisfy three desired properties for local explanation models: 1.local accuracy (known as ‘efficiency’ in game theory) states that when approximating the original model $f$ for a specific input $x$, the explanation’s attribution values should sum up to the output $f(x)$. 2.Consistency (known as ‘monotonicity’ in game theory) states that if a model changes so that some feature’s contribution increases or stays the same regardless of the other inputs, that input’s attribution should not decrease.
Lundberg and Lee (2017) specified the Shapley values as an additive feature attribution method, and defined SHAP as: $f(z) = g(z’)=\phi_0 + \sum_{i=1}^{M}\phi_i z_i’$, where $f(\cdot)$ is the original model, $g(\cdot)$ is the explanation model, $z’ \in {0,1}^M$ is the coalition vector, $M$ is the maximum coalition size and $\phi_i \in \mathbb{R}$ is the feature attribution for a feature $i$ or the Shapley value for feature $i$. Figure 1 illustrates how the expected model prediction $E\left[ f(z) \right]$ that would be predicted if we did not know any features of the current output $f(x)$ would change when conditioning on a specific feature $\phi_i$ with one specific feature order. When using non-linear models or non-independent features, the order in which the features are added to the explanation model matters. The SHAP values are calculated by averaging $\phi_i$ over all possible sequences.

Image 6: Attribution of SHAP value to prediction (Lundberg and Lee 2017)
SHAP values represent a local interpretation of the feature importance. When using local interpretability models, stability and trust in single explanations is not always given. To improve the trustworthiness and the interpretability of the model, Lundberg et al. (2020) introduce an extension of SHAP values, the TreeExplainer. TreeExplainer is an explanation method specially for trees, which enables the tractable computation of optimal local explanations. The authors call it “fast local explanations with guaranteed consistency”. To compute the impact of a specific feature subset during the Shapley value calculation, TreeExplainer uses interventional expectations over a user supplied background dataset (feature perturbation = “interventional”). But it can also avoid the need for a user-supplied background dataset by relying only on the path coverage information stored in the model (feature perturbation = “tree_path_dependent”). Lundberg et al. (2020) show that by efficiently and exactly computing the Shapley values and therefore guaranteeing that explanations are always consistent and locally accurate, the results over previous local explanation methods are improved in several ways:
TreeExplainer also extends local explanations to measuring interaction effects and therefore presenting a richer type of local explanation. These interaction values use the ‘Shapley interaction index’ from game theory to capture local interaction effects. They are computed by generalizing the original Shapley value properties and allocate credit not just among each individual player of a game but also among all pairs of players. By enabling the additional consideration of interaction effects for individual model predictions, TreeExplainer can uncover important patterns that might otherwise have been missed.
Another key extension is not to calculate Shapley values for only one specific observation, but for the whole dataset. By combining many local explanations, a global structure is constructed while retaining local faithfulness to the original model and therefore a rich summary of both an entire model and individual features can be created.
As described in the Data Section, the Single Family Loan-Level Dataset contains 31 features, 14 of which are numerical. Two features are dates, and the remaining 15 features are categorical.
As a first step, missing values are imputed or dropped (see Section “Dealing with Missing Data”). Next, the data formats of variables are inspected and adjusted where appropriate.
These steps are first conducted for the training dataset. Afterwards, the same steps are taken for the test dataset for consistency reasons. In addition, for categorical feature the possibility of a category mismatch, i.e. that the test data includes categories unseen in the training dataset, is taken into account. Next, categorical features in both test and training data are dummy encoded and the training data is split into features and target values.
Lastly, the numerical features of both datasets are standardized.
In the original version of the Single Family Loan-Level dataset, missing values are encoded using numerical codes. For example, for the feature ‘ltv’ (Original Loan-to-Value), “not available” is encoded as 999. Evidently, this is suboptimal when performing analyses as any algorithm would interpret this as a regular numerical value equal to 999 instead of as missing. Therefore, encoding missing values as system missings constitutes the initial step of our data preprocessing process. For categorical features, a separate category for missing values is added. After having implemented these changes, it becomes apparent that merely five numerical features contain missing values, three of which only contain a neglectable number (<= 10) of missings. Observations containing one or more of these three variables (‘fico’, ‘cltv’ and ‘ltv’) are dropped. The features remaining two numerical features with missing values, ‘dti’ and ‘cd_msa’, on the other hand, contain a significant amount of missing values (26153 and 20971, respectively). With respect to ‘cd_msa’, an identifier for the Metropolitan Area a creditor lives in, we choose to disregard this variable, as its meaning practically equals that of the Zip code, which has no missing values. For ‘dti’, on the other hand, an observation may be missing for one of two reasons: Either its ‘dti’ ratio exceeds 65%, or it belongs to the HARP dataset. HARP is short for Home Affordable Refinance Program and “was created by the Federal Housing Finance Agency specifically to help homeowners who are current on their mortgage payments, but who are underwater on their mortgages. That is, they owe almost as much or more than the current value of their homes.” For a mortgage to be eligible for the HARP relief program, it had to be owned by Fannie Mae or Freddie Mac (Federal Housing Finance Agency 2013), who had been placed in federal conservatorship during the financial crisis (Lockhart 9/7/2008). Upon further inspection of the dataset, it becomes clear that merely 5 individuals for whom the ‘dti’ is missing or not part of the HARP dataset and thus have a ‘dti’ ratio exceeding 65%. The vast majority of observations with a missing ‘dti’ ratio hence received emergency relief via the HARP program. As a result, we deem it unreasonable to impute the median ‘dti’ value for those missing values. Unfortunately, it is impossible to predict the value of those missing values in a sensible way, as the ‘dti’ ratio is missing for the entire subpopulation of HARP program receivers per design. Consequently, we decided to impute missing ‘dti’ values with the cut-off value of 65% as we deem this the most prudent decision given the fact illustrated above.
# Recode missings
## To better handle the different kinds of encodings for missing values in
## the dataset, the missings are all transformed into one uniform encoding
## as NAN values
print("BEFORE RECODING -------------------------------------------------")
print(df_train.isna().sum(axis=0)) # before to compare later
print("INFO")
df_train.info()
# Determine which values are encoded as missings in each feature
missing_as_9999 = ['fico']
missing_as_999 = ['mi_pct', 'cltv', 'dti', 'ltv']
missing_as_99 = ['cnt_units', 'cnt_borr']
missing_as_9 = ['pgrm_ind', 'prop_val_meth']
missing_as_99_str = ['prop_type']
missing_as_9_str = ['pgrm_ind', 'loan_purpose', 'channel',
'occpy_sts', 'flag_fthb']
# Create lists to iterate through them
missings = [missing_as_9999, missing_as_999, missing_as_99,
missing_as_9, missing_as_99_str, missing_as_9_str]
missing_numbers =[9999, 999, 99, 9, "99", "9"]
j = -1 #inititalize counter
# Looping through the different kinds of missings and replace them
for i in missing_numbers:
j= j+1
def missings_recode(variable):
if variable== i:
return np.nan
else:
return variable
for var in missings[j]:
print(df_train[var].dtypes)
desired_type = df_train[var].dtypes # store this datatype
desired_type = str(desired_type).replace("int64", "Int64")
df_train[var] = df_train[var].apply(missings_recode)
# apply desired type
df_train[var] = df_train[var].astype(desired_type)
# check whether everything was recoded accordingly
print("AFTER RECODING -------------------------------------------------")
print(df_train.isna().sum(axis=0))
df_train.info()
BEFORE RECODING ------------------------------------------------- fico 0 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 20971 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 0 dti 0 orig_upb 0 ltv 0 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 144981 pre_relief 123837 pgrm_ind 0 rel_ref_ind 123837 prop_val_meth 0 int_only_ind 0 TARGET 0 dtype: int64 INFO <class 'pandas.core.frame.DataFrame'> RangeIndex: 149985 entries, 0 to 149984 Data columns (total 32 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fico 149985 non-null int64 1 dt_first_pi 149985 non-null int64 2 flag_fthb 149985 non-null object 3 dt_matr 149985 non-null int64 4 cd_msa 129014 non-null float64 5 mi_pct 149985 non-null int64 6 cnt_units 149985 non-null int64 7 occpy_sts 149985 non-null object 8 cltv 149985 non-null int64 9 dti 149985 non-null int64 10 orig_upb 149985 non-null int64 11 ltv 149985 non-null int64 12 int_rt 149985 non-null float64 13 channel 149985 non-null object 14 ppmt_pnlty 149985 non-null object 15 prod_type 149985 non-null object 16 st 149985 non-null object 17 prop_type 149985 non-null object 18 zipcode 149985 non-null int64 19 id_loan 149985 non-null int64 20 loan_purpose 149985 non-null object 21 orig_loan_term 149985 non-null int64 22 cnt_borr 149985 non-null int64 23 seller_name 149985 non-null object 24 servicer_name 149985 non-null object 25 flag_sc 5004 non-null object 26 pre_relief 26148 non-null object 27 pgrm_ind 149985 non-null object 28 rel_ref_ind 26148 non-null object 29 prop_val_meth 149985 non-null int64 30 int_only_ind 149985 non-null object 31 TARGET 149985 non-null int64 dtypes: float64(2), int64(15), object(15) memory usage: 36.6+ MB int64 int64 int64 int64 int64 int64 int64 object int64 object object object object object object AFTER RECODING ------------------------------------------------- fico 10 dt_first_pi 0 flag_fthb 10 dt_matr 0 cd_msa 20971 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 4 dti 26153 orig_upb 0 ltv 4 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 144981 pre_relief 123837 pgrm_ind 149695 rel_ref_ind 123837 prop_val_meth 149985 int_only_ind 0 TARGET 0 dtype: int64 <class 'pandas.core.frame.DataFrame'> RangeIndex: 149985 entries, 0 to 149984 Data columns (total 32 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fico 149975 non-null Int64 1 dt_first_pi 149985 non-null int64 2 flag_fthb 149975 non-null object 3 dt_matr 149985 non-null int64 4 cd_msa 129014 non-null float64 5 mi_pct 149985 non-null Int64 6 cnt_units 149985 non-null Int64 7 occpy_sts 149985 non-null object 8 cltv 149981 non-null Int64 9 dti 123832 non-null Int64 10 orig_upb 149985 non-null int64 11 ltv 149981 non-null Int64 12 int_rt 149985 non-null float64 13 channel 149985 non-null object 14 ppmt_pnlty 149985 non-null object 15 prod_type 149985 non-null object 16 st 149985 non-null object 17 prop_type 149985 non-null object 18 zipcode 149985 non-null int64 19 id_loan 149985 non-null int64 20 loan_purpose 149985 non-null object 21 orig_loan_term 149985 non-null int64 22 cnt_borr 149985 non-null Int64 23 seller_name 149985 non-null object 24 servicer_name 149985 non-null object 25 flag_sc 5004 non-null object 26 pre_relief 26148 non-null object 27 pgrm_ind 290 non-null object 28 rel_ref_ind 26148 non-null object 29 prop_val_meth 0 non-null Int64 30 int_only_ind 149985 non-null object 31 TARGET 149985 non-null int64 dtypes: Int64(8), float64(2), int64(7), object(15) memory usage: 37.8+ MB
# identify and visualize missing values
print(df_train.isnull().sum(axis=0))
sns.heatmap(df_train.isnull(), cbar=False);
fico 10 dt_first_pi 0 flag_fthb 10 dt_matr 0 cd_msa 20971 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 4 dti 26153 orig_upb 0 ltv 4 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 144981 pre_relief 123837 pgrm_ind 149695 rel_ref_ind 123837 prop_val_meth 149985 int_only_ind 0 TARGET 0 dtype: int64

# creating new category for NANs for categorical/boolean features
## pgrm_ind
df_train['pgrm_ind'].fillna('N', inplace = True)
## pre_relief
df_train['pre_relief'].fillna('N', inplace = True)
## flag_sc
df_train['flag_sc'].fillna('N', inplace = True)
## flag_fthb
df_train['flag_fthb'].fillna('N', inplace = True)
## rel_ref_ind
df_train['rel_ref_ind'].fillna('N', inplace = True)
## prop_val_meth
### first change data type from int to object, otherwise .fillna does not work
df_train.prop_val_meth = df_train.prop_val_meth.astype('object')
df_train['prop_val_meth'].fillna('N', inplace = True)
# handeling numeric missing values
missing_numerics =['fico', 'cltv', 'ltv', 'dti', 'cd_msa']
for var in missing_numerics:
print(f"missings in {var}:")
print(df_train[var].isnull().sum(axis=0))
# dti by far biggest number
# msa will be dropped anyway
missings in fico: 10 missings in cltv: 4 missings in ltv: 4 missings in dti: 26153 missings in cd_msa: 20971
# multiple missings in rows?
print(df_train.isnull().sum(axis=1).head())
df_train.isnull().sum(axis=1).unique()
0 0 1 0 2 0 3 1 4 0 dtype: int64
array([0, 1, 2, 3])
# drop mssings in ['fico', 'cltv', 'ltv'], because so few missings
df_train = df_train.dropna(subset=['fico', 'cltv', 'ltv'])
#check wether it worked
missing_numerics =['fico', 'cltv', 'ltv']
for var in missing_numerics:
print(f"missings in {var}:")
print(df_train[var].isnull().sum(axis=0))
print(df_train.isnull().sum(axis=1).unique())
missings in fico: 0 missings in cltv: 0 missings in ltv: 0 [0 1 2]
Dti = ORIGINAL DEBT-TO-INCOME (DTI) RATIO
print(df_train['rel_ref_ind'].unique())
print(df_train['dti'].unique())
['N' 'Y'] <IntegerArray> [ 36, 26, 37, 21, 10, 31, 28, 33, 20, 44, 41, 23, 27, 19, 17, 38, 43, 46, 18, 35, 29, 45, 25, 32, 40, 50, 39, 30, 22, <NA>, 42, 34, 47, 16, 13, 24, 12, 48, 11, 49, 14, 9, 15, 3, 8, 7, 2, 4, 1, 6, 5] Length: 51, dtype: Int64
print("number of dti that need filling")
print(sum(df_train['dti'].isnull()))
print("got HARP")
print(sum(df_train['rel_ref_ind']=="Y") )
print("got HARP and missing dti") # <- reason for missing is HARP
print(sum((df_train['dti'].isnull()) & (df_train['rel_ref_ind']=="Y") ))
print("missing dti with missing harp indicator")
print(sum((df_train['dti'].isnull()) & (df_train['rel_ref_ind'].isnull())))
print("missing dti with harp indicator==N") # <- had >65% dti
sum((df_train['dti'].isnull()) & (df_train['rel_ref_ind']=="N"))
number of dti that need filling 26148 got HARP 26143 got HARP and missing dti 26143 missing dti with missing harp indicator 0 missing dti with harp indicator==N
5
print(df_train['TARGET'].unique())
data_sub0 = df_train.loc[df_train['TARGET'] == 0]
print(f"Target values in sub0: {data_sub0['TARGET'].unique()}")
print(f"unique values of rel_ref_ind in sub0: \
{data_sub0['rel_ref_ind'].unique()}")
data_sub0 = data_sub0.dropna(subset=['dti'])
print(f"unique values of rel_ref_ind in sub0 after dropping missings in dti: \
{data_sub0['rel_ref_ind'].unique()}")
#Using distplot function, create a graph
sns.distplot( a=data_sub0["dti"], hist=True, kde = False, rug = False)
[0 1] Target values in sub0: [0] unique values of rel_ref_ind in sub0: ['N' 'Y'] unique values of rel_ref_ind in sub0 after dropping missings in dti: ['N']
`distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
<matplotlib.axes._subplots.AxesSubplot at 0x7fafba067bd0>

data_sub1 = df_train.loc[df_train['TARGET'] == 1]
print(f"Target values in sub1: {data_sub1['TARGET'].unique()}")
print(f"unique values of rel_ref_ind in sub1: \
{data_sub1['rel_ref_ind'].unique()}")
data_sub1 = data_sub1.dropna(subset=['dti'])
print(f"unique values of rel_ref_ind in sub1 after dropping missings in dti: \
{data_sub1['rel_ref_ind'].unique()}")
sns.distplot( a=data_sub1["dti"], hist=True, kde = False, rug = False)
Target values in sub1: [1] unique values of rel_ref_ind in sub1: ['Y' 'N'] unique values of rel_ref_ind in sub1 after dropping missings in dti: ['N']
`distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
<matplotlib.axes._subplots.AxesSubplot at 0x7fafb8544a10>

# recode rel_ref_ind
print(df_train['rel_ref_ind'].unique())
print(data_sub0['rel_ref_ind'].unique())
a_dict = {"Y":1, "N":0}
data_sub0 = data_sub0.replace(dict(rel_ref_ind=a_dict))
print(data_sub0['rel_ref_ind'].unique())
# hist of rel_ref_ind if TARGET==0
sns.distplot( a=data_sub0["rel_ref_ind"], hist=True, kde = False, rug = False)
['N' 'Y'] ['N'] [0]
`distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
<matplotlib.axes._subplots.AxesSubplot at 0x7fafb852e4d0>

# recode again
print(data_sub1['rel_ref_ind'].unique())
data_sub1 = data_sub1.replace(dict(rel_ref_ind=a_dict))
# hist of rel_ref_ind if TARGET==1
sns.distplot( a=data_sub1["rel_ref_ind"], hist=True, kde = False, rug = False)
['N']
`distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
<matplotlib.axes._subplots.AxesSubplot at 0x7fafb844ba50>

# correlation between dti and target
print(df_train[['TARGET', 'dti']].corr())
TARGET dti TARGET 1.000000 0.030039 dti 0.030039 1.000000
# impute missing dti with cut-off (=65)
df_train['dti'].head()
df_train['dti'].fillna(65, inplace = True)
print(df_train.isnull().sum(axis=0))
fico 0 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 20966 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 0 dti 0 orig_upb 0 ltv 0 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 0 pre_relief 0 pgrm_ind 0 rel_ref_ind 0 prop_val_meth 0 int_only_ind 0 TARGET 0 dtype: int64
# Recode missings
## To better handle the different kinds of encodings for missing values in
## the dataset, the missings are all transformed into one uniform encoding as
## NAN values
print("BEFORE RECODING -------------------------------------------------")
print(df_test.isna().sum(axis=0)) # before to compare later
print("INFO")
df_test.info()
# Determine which values are encoded as missings in each feature
missing_as_9999 = ['fico']
missing_as_999 = ['mi_pct', 'cltv', 'dti', 'ltv']
missing_as_99 = ['cnt_units', 'cnt_borr']
missing_as_9 = ['pgrm_ind', 'prop_val_meth']
missing_as_99_str = ['prop_type']
missing_as_9_str = ['pgrm_ind', 'loan_purpose', 'channel',
'occpy_sts', 'flag_fthb']
# Create lists to iterate through them
missings = [missing_as_9999, missing_as_999, missing_as_99,
missing_as_9, missing_as_99_str, missing_as_9_str]
missing_numbers =[9999, 999, 99, 9, "99", "9"]
j = -1 #inititalize counter
# Looping through the different kinds of missings and replace them
for i in missing_numbers:
j= j+1
def missings_recode(variable):
if variable== i:
return np.nan
else:
return variable
for var in missings[j]:
print(df_test[var].dtypes)
desired_type = df_test[var].dtypes # store this datatype
desired_type = str(desired_type).replace("int64", "Int64")
df_test[var] = df_test[var].apply(missings_recode)
# apply desired type
df_test[var] = df_test[var].astype(desired_type)
# check whether everything was recoded accordingly
print("AFTER RECODING -------------------------------------------------")
print(df_test.isna().sum(axis=0))
df_test.info()
BEFORE RECODING ------------------------------------------------- fico 0 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 5372 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 0 dti 0 orig_upb 0 ltv 0 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 48082 pre_relief 48207 pgrm_ind 0 rel_ref_ind 48207 prop_val_meth 0 int_only_ind 0 dtype: int64 INFO <class 'pandas.core.frame.DataFrame'> RangeIndex: 50015 entries, 0 to 50014 Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fico 50015 non-null int64 1 dt_first_pi 50015 non-null int64 2 flag_fthb 50015 non-null object 3 dt_matr 50015 non-null int64 4 cd_msa 44643 non-null float64 5 mi_pct 50015 non-null int64 6 cnt_units 50015 non-null int64 7 occpy_sts 50015 non-null object 8 cltv 50015 non-null int64 9 dti 50015 non-null int64 10 orig_upb 50015 non-null int64 11 ltv 50015 non-null int64 12 int_rt 50015 non-null float64 13 channel 50015 non-null object 14 ppmt_pnlty 50015 non-null object 15 prod_type 50015 non-null object 16 st 50015 non-null object 17 prop_type 50015 non-null object 18 zipcode 50015 non-null int64 19 id_loan 50015 non-null int64 20 loan_purpose 50015 non-null object 21 orig_loan_term 50015 non-null int64 22 cnt_borr 50015 non-null int64 23 seller_name 50015 non-null object 24 servicer_name 50015 non-null object 25 flag_sc 1933 non-null object 26 pre_relief 1808 non-null object 27 pgrm_ind 50015 non-null object 28 rel_ref_ind 1808 non-null object 29 prop_val_meth 50015 non-null int64 30 int_only_ind 50015 non-null object dtypes: float64(2), int64(14), object(15) memory usage: 11.8+ MB int64 int64 int64 int64 int64 int64 int64 object int64 object object object object object object AFTER RECODING ------------------------------------------------- fico 10 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 5372 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 2 dti 1813 orig_upb 0 ltv 2 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 48082 pre_relief 48207 pgrm_ind 46392 rel_ref_ind 48207 prop_val_meth 40 int_only_ind 0 dtype: int64 <class 'pandas.core.frame.DataFrame'> RangeIndex: 50015 entries, 0 to 50014 Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fico 50005 non-null Int64 1 dt_first_pi 50015 non-null int64 2 flag_fthb 50015 non-null object 3 dt_matr 50015 non-null int64 4 cd_msa 44643 non-null float64 5 mi_pct 50015 non-null Int64 6 cnt_units 50015 non-null Int64 7 occpy_sts 50015 non-null object 8 cltv 50013 non-null Int64 9 dti 48202 non-null Int64 10 orig_upb 50015 non-null int64 11 ltv 50013 non-null Int64 12 int_rt 50015 non-null float64 13 channel 50015 non-null object 14 ppmt_pnlty 50015 non-null object 15 prod_type 50015 non-null object 16 st 50015 non-null object 17 prop_type 50015 non-null object 18 zipcode 50015 non-null int64 19 id_loan 50015 non-null int64 20 loan_purpose 50015 non-null object 21 orig_loan_term 50015 non-null int64 22 cnt_borr 50015 non-null Int64 23 seller_name 50015 non-null object 24 servicer_name 50015 non-null object 25 flag_sc 1933 non-null object 26 pre_relief 1808 non-null object 27 pgrm_ind 3623 non-null object 28 rel_ref_ind 1808 non-null object 29 prop_val_meth 49975 non-null Int64 30 int_only_ind 50015 non-null object dtypes: Int64(8), float64(2), int64(6), object(15) memory usage: 12.2+ MB
# identify and visualize missing values
print(df_test.isnull().sum(axis=0))
sns.heatmap(df_test.isnull(), cbar=False);
fico 10 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 5372 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 2 dti 1813 orig_upb 0 ltv 2 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 48082 pre_relief 48207 pgrm_ind 46392 rel_ref_ind 48207 prop_val_meth 40 int_only_ind 0 dtype: int64

# creating new category for categorical/boolean features
## pgrm_ind
df_test['pgrm_ind'].fillna('N', inplace = True)
## pre_relief
df_test['pre_relief'].fillna('N', inplace = True)
## flag_sc
df_test['flag_sc'].fillna('N', inplace = True)
## flag_fthb
df_test['flag_fthb'].fillna('N', inplace = True)
## rel_ref_ind
df_test['rel_ref_ind'].fillna('N', inplace = True)
## prop_val_meth
### first change data type from int to object, otherwise .fillna does not work
df_test.prop_val_meth = df_test.prop_val_meth.astype('object')
df_test['prop_val_meth'].fillna('N', inplace = True)
# handeling numeric missing values
missing_numerics =['fico', 'cltv', 'ltv', 'dti', 'cd_msa']
for var in missing_numerics:
print(f"missings in {var}:")
print(df_test[var].isnull().sum(axis=0))
# dti by far biggest number
# msa will be dropped anyway
missings in fico: 10 missings in cltv: 2 missings in ltv: 2 missings in dti: 1813 missings in cd_msa: 5372
# multiple missings in rows?
print(df_test.isnull().sum(axis=1).head())
df_test.isnull().sum(axis=1).unique()
0 0 1 0 2 0 3 0 4 0 dtype: int64
array([0, 2, 1, 3])
# replacing missings for numeric data
## fico
df_test['fico'].fillna(df_test['fico'].median(), inplace = True)
## cltv
df_test['cltv'].fillna(df_test['cltv'].median(), inplace = True)
## ltv
df_test['ltv'].fillna(df_test['ltv'].median(), inplace = True)
# check wether it worked
missing_numerics =['fico', 'cltv', 'ltv']
for var in missing_numerics:
print(f"missings in {var}:")
print(df_test[var].isnull().sum(axis=0))
print(df_test.isnull().sum(axis=1).unique())
missings in fico: 0 missings in cltv: 0 missings in ltv: 0 [0 2 1]
Dti = ORIGINAL DEBT-TO-INCOME (DTI) RATIO
print(df_test['rel_ref_ind'].unique())
print(df_test['dti'].unique())
['N' 'Y'] <IntegerArray> [ 48, 44, 41, 32, 16, <NA>, 29, 26, 34, 43, 36, 40, 49, 42, 39, 33, 46, 30, 45, 38, 27, 28, 23, 35, 17, 25, 24, 13, 37, 6, 50, 21, 47, 31, 18, 20, 15, 19, 22, 12, 14, 9, 10, 7, 11, 3, 5, 4, 8, 2, 1] Length: 51, dtype: Int64
print("number of dti that need filling")
print(sum(df_test['dti'].isnull()))
print("got HARP")
print(sum(df_test['rel_ref_ind']=="Y") )
print("got HARP and missing dti") # <- reason for missing is HARP
print(sum((df_test['dti'].isnull()) & (df_test['rel_ref_ind']=="Y") ))
print("missing dti with missing harp indicator")
print(sum((df_test['dti'].isnull()) & (df_test['rel_ref_ind'].isnull())))
print("missing dti with harp indicator==N") # <- had >65% dti
sum((df_test['dti'].isnull()) & (df_test['rel_ref_ind']=="N"))
number of dti that need filling 1813 got HARP 1808 got HARP and missing dti 1808 missing dti with missing harp indicator 0 missing dti with harp indicator==N
5
# impute missing dti with cut-off (=65)
df_test['dti'].head()
df_test['dti'].fillna(65, inplace = True)
print(df_test.isnull().sum(axis=0))
fico 0 dt_first_pi 0 flag_fthb 0 dt_matr 0 cd_msa 5372 mi_pct 0 cnt_units 0 occpy_sts 0 cltv 0 dti 0 orig_upb 0 ltv 0 int_rt 0 channel 0 ppmt_pnlty 0 prod_type 0 st 0 prop_type 0 zipcode 0 id_loan 0 loan_purpose 0 orig_loan_term 0 cnt_borr 0 seller_name 0 servicer_name 0 flag_sc 0 pre_relief 0 pgrm_ind 0 rel_ref_ind 0 prop_val_meth 0 int_only_ind 0 dtype: int64
After having dealt with missing values, data formats are adapted where needed. As an initial step, the feature ‘id’ is used to index the data. Float variables are expressed in 'mi_pct', 'cltv', 'dti', 'ltv' and 'int_rt' are expressed in percentage terms and hence converted into float. Date variables 'dt_first_pi' and 'dt_matr' are converted into pandas datetime variables and categorical variables are encoded as such. The same applies to Boolean features.
Feature ‘pre_relief_prog’ originally had the following format: PYYQnXXXXXXX, where ‘P’ is the type of product, ‘YY’ is the year, ‘Qn’ the quarter and the final digits are randomly assigned. We choose to extract the product type only and encode it as a categorical feature.
We drop features which only take on one unique value as they do not add additional information while increasing dimensionality. In addition, ‘ltv’ is dropped due to its high correlation to ‘cltv’ which we view as logical given the fact that cltv is the Original Combined Loan-to-Value and ltv the Original Loan-to-Value.
Finally, we drop features ‘zipcode' in addition to ‘cd_msa'. While there are no missing values in ‘zipcode’, its coverage is very low such that each individual value of ‘zipcode’ is only populated by a minor number of observations. In the interest of reduced dimensionality, we thus only use the more granular geographical indicator of state (‘st’). In addition, we aggregate states containing less than 1500 observations (<~1% of observations) into a new category 'Other'. We follow the same approach for the variable 'seller_name' (new category ‘Other sellers’) and ‘servicer_name’ (new category ‘Other servicer’).
# set id_loan as index #########################################################
df_train.set_index(df_train.id_loan, inplace = True)
df_train = df_train.drop('id_loan', axis = 1)
# dealing with numeric features ################################################
## converting 64 to 32
int32_vars = ['fico', 'orig_upb']
for var in int32_vars:
df_train[var] = df_train[var].astype('int32')
## converting % values to float
float_vars = ['mi_pct', 'cltv', 'dti', 'ltv', 'int_rt', ]
for var in float_vars:
df_train[var] = df_train[var].astype('float64')
df_train[var] = df_train[var]/100.0
# renaming percentage features to ..._pct
if (var != 'mi_pct'):
df_train = df_train.rename(columns = {var : var+'_pct'})
## dropping features based on high correlation
## because ltv and cltv have a really high correlation (>0.95), drop one of them
df_train = df_train.drop('ltv_pct', axis = 1)
# dealing with time features ###################################################
## all time features
time_vars = ['dt_first_pi', 'dt_matr']
## convert to datetime
for var in time_vars:
df_train[var] = df_train[var].apply(lambda x: pd.to_datetime(str(x),
format='%Y%m'))
df_train[var].apply(lambda x : (x-datetime.datetime(1970,1,1))\
.total_seconds())
df_train[var] = df_train[var].astype('int64')
## calculate the difference new with unix coding, need to test
## whether the results are similar or not
df_train.orig_loan_term = df_train.dt_matr - df_train.dt_first_pi
## drop date features because they are just adding noise
## keep the difference as a feature, so the information is not completly lost
df_train = df_train.drop('dt_matr', axis = 1)
df_train = df_train.drop('dt_first_pi', axis = 1)
# dealing with cat features ####################################################
## cnt_units
df_train.cnt_units = df_train.cnt_units.astype('category')
## occpy_sts
df_train.occpy_sts = df_train.occpy_sts.astype('category')
## channel
df_train.channel = df_train.channel.astype('category')
## prop_type
df_train.prop_type = df_train.prop_type.astype('category')
## loan_purpose
df_train.loan_purpose = df_train.loan_purpose.astype('category')
## pgrm_ind
df_train.loc[(df_train['pgrm_ind'] == 'F'), 'pgrm_ind'] = 'Y'
df_train.loc[(df_train['pgrm_ind'] == 'H'), 'pgrm_ind'] = 'Y'
df_train.pgrm_ind = df_train.pgrm_ind.astype('category')
## prop_val_meth
df_train.prop_val_meth = df_train.prop_val_meth.astype('category')
## seller_name
df_train.seller_name = df_train.seller_name.astype('category')
## servicer_name
df_train.servicer_name = df_train.servicer_name.astype('category')
## st
df_train.st = df_train.st.astype('category')
# dealing with other features ##################################################
## pre_relief
## extracting first letter to get product type and create new column with it
df_train['pre_relief_prog'] = df_train['pre_relief'].astype(str).str[0]
df_train['pre_relief_prog'] = df_train.pre_relief_prog.astype('category')
df_train = df_train.drop('pre_relief', axis = 1)
# dealing with geographic features #############################################
## cd_msa
### drop cd_msa feature, not additional information out of it
df_train = df_train.drop('cd_msa', axis = 1)
## zipcode
### drop zipcode because there are too few observations in each category
## for the model, to gain much information, the overall geographical
## aspect is representet in states
df_train = df_train.drop('zipcode', axis = 1)
# dealing with boolean features ################################################
## flag_fthb
df_train['flag_fthb'] = df_train['flag_fthb'].map({'Y' : 1, 'N': 0})
df_train['flag_fthb'] = df_train['flag_fthb'].astype('uint8')
## ppmt_pnlty
df_train['ppmt_pnlty'] = df_train['ppmt_pnlty'].map({'Y' : 1, 'N': 0})
df_train['ppmt_pnlty'] = df_train['ppmt_pnlty'].astype('uint8')
## prod_type
df_train['prod_type'] = df_train['prod_type'].map({'FRM' : 1, 'ARM': 0})
df_train['prod_type'] = df_train['prod_type'].astype('uint8')
## cnt_borr
df_train.loc[(df_train['cnt_borr'] == 1), 'cnt_borr'] = 0
df_train.loc[(df_train['cnt_borr'] > 1), 'cnt_borr'] = 1
df_train['cnt_borr'] = df_train['cnt_borr'].astype('uint8')
## flag_sc
df_train['flag_sc'] = df_train['flag_sc'].map({'Y' : 1, 'N': 0})
df_train['flag_sc'] = df_train['flag_sc'].astype('uint8')
## rel_ref_ind
df_train['rel_ref_ind'] = df_train['rel_ref_ind'].map({'Y' : 1, 'N': 0})
df_train['rel_ref_ind'] = df_train['rel_ref_ind'].astype('uint8')
## int_only_ind
df_train['int_only_ind'] = df_train['int_only_ind'].map({'Y' : 1, 'N': 0})
df_train['int_only_ind'] = df_train['int_only_ind'].astype('uint8')
## target
df_train['TARGET'] = df_train['TARGET'].astype('uint8')
# drop freatures with only 1 unique value, no useful information there #########
drop = df_train.loc[:, df_train.nunique() == 1]
drop = drop.columns
print("Variables we drop because there is only one unique value \
in the training set: ", drop)
for col in drop:
df_train = df_train.drop(labels=col, axis=1)
casting datetime64[ns] values to int64 with .astype(...) is deprecated and will raise in a future version. Use .view(...) instead.
Variables we drop because there is only one unique value in the training set: Index(['ppmt_pnlty', 'prod_type', 'prop_val_meth', 'int_only_ind'], dtype='object')
# Change categories with less observations than 1% of training data to 'others'
# calculate number of observations for each state.
# and replace states with less than 1500 (<~1% of observations)
# observations by category 'Other'.
st_count = df_train['st'].value_counts()
df_train['st'] = np.where(df_train['st']\
.isin(st_count[st_count.lt(1500)].index),\
'Other',df_train['st'])
# calculate number of observations for each servicers.
# and replace servicers with less than 1500 (<~1% of observations)
# observations by category 'Other Servicers'.
servicers_count = df_train['servicer_name'].value_counts()
df_train['servicer_name'] = np.where(df_train['servicer_name']\
.isin(servicers_count[servicers_count.lt(1500)].index),'Other servicers',\
df_train['servicer_name'])
# calculate number of observations for each sellers.
# and replace sellers with less than (<~1% of observations) 1500
# observations by category 'Other Sellers'.
sellers_count = df_train['seller_name'].value_counts()
df_train['seller_name'] = np.where(df_train['seller_name']\
.isin(sellers_count[sellers_count.lt(1500)].index),'Other sellers',\
df_train['seller_name'])
# set id_loan as index #########################################################
df_test.set_index(df_test.id_loan, inplace = True)
df_test = df_test.drop('id_loan', axis = 1)
# dealing with numeric features ################################################
## converting 64 to 32
int32_vars = ['fico', 'orig_upb']
for var in int32_vars:
df_test[var] = df_test[var].astype('int32')
## converting % values to float
float_vars = ['mi_pct', 'cltv', 'dti', 'ltv', 'int_rt', ]
for var in float_vars:
df_test[var] = df_test[var].astype('float64')
df_test[var] = df_test[var]/100.0
# renaming percentage features to ..._pct
if (var != 'mi_pct'):
df_test = df_test.rename(columns = {var : var+'_pct'})
## dropping features based on correlation
## because ltv and cltv have a really high correlation (>0.95)
## in the train data, drop one of them
df_test = df_test.drop('ltv_pct', axis = 1)
# dealing with time features ###################################################
## determine all time features
time_vars = ['dt_first_pi', 'dt_matr']
for var in time_vars:
df_test[var] = df_test[var].apply(lambda x: pd.to_datetime(str(x),
format='%Y%m'))
df_test[var].apply(lambda x : (x-datetime.datetime(1970,1,1))\
.total_seconds())
df_test[var] = df_test[var].astype('int64')
## calculate the difference new with unix coding, need to test whether
## the results are similar or not
df_test.orig_loan_term = df_test.dt_matr - df_test.dt_first_pi
## drop time features, no information gain
## keep the difference as a feature, so the information is not completly lost
df_test = df_test.drop('dt_matr', axis = 1)
df_test = df_test.drop('dt_first_pi', axis = 1)
# dealing with cat features ####################################################
## cnt_units
df_test.cnt_units = df_test.cnt_units.astype('category')
## occpy_sts
df_test.occpy_sts = df_test.occpy_sts.astype('category')
## channel
df_test.channel = df_test.channel.astype('category')
## prop_type
df_test.prop_type = df_test.prop_type.astype('category')
## loan_purpose
df_test.loan_purpose = df_test.loan_purpose.astype('category')
## pgrm_ind
df_test.loc[(df_test['pgrm_ind'] == 'F'), 'pgrm_ind'] = 'Y'
df_test.loc[(df_test['pgrm_ind'] == 'H'), 'pgrm_ind'] = 'Y'
df_test.pgrm_ind = df_test.pgrm_ind.astype('category')
## prop_val_meth
df_test.prop_val_meth = df_test.prop_val_meth.astype('category')
## seller_name
df_test.seller_name = df_test.seller_name.astype('category')
## servicer_name
df_test.servicer_name = df_test.servicer_name.astype('category')
## st
df_test.st = df_test.st.astype('category')
# dealing with other features ##################################################
## pre_relief
## extracting first letter to get product type and create new column with it
df_test['pre_relief_prog'] = df_test['pre_relief'].astype(str).str[0]
df_test['pre_relief_prog'] = df_test.pre_relief_prog.astype('category')
df_test = df_test.drop('pre_relief', axis = 1)
# dealing with geographic features #############################################
## cd_msa
## drop cd_msa feature, not additional information out of it
df_test = df_test.drop('cd_msa', axis = 1)
## zipcode
### drop zipcode because there are too few observations in each category
### for the model to gain much information, the overall geographical aspect
### is representet in states
df_test = df_test.drop('zipcode', axis = 1)
# dealing with boolean features ################################################
## flag_fthb
df_test['flag_fthb'] = df_test['flag_fthb'].map({'Y' : 1, 'N': 0})
df_test['flag_fthb'] = df_test['flag_fthb'].astype('uint8')
## ppmt_pnlty
df_test['ppmt_pnlty'] = df_test['ppmt_pnlty'].map({'Y' : 1, 'N': 0})
df_test['ppmt_pnlty'] = df_test['ppmt_pnlty'].astype('uint8')
## prod_type
df_test['prod_type'] = df_test['prod_type'].map({'FRM' : 1, 'ARM': 0})
df_test['prod_type'] = df_test['prod_type'].astype('uint8')
## cnt_borr
df_test.loc[(df_test['cnt_borr'] == 1), 'cnt_borr'] = 0
df_test.loc[(df_test['cnt_borr'] > 1), 'cnt_borr'] = 1
df_test['cnt_borr'] = df_test['cnt_borr'].astype('uint8')
## flag_sc
df_test['flag_sc'] = df_test['flag_sc'].map({'Y' : 1, 'N': 0})
df_test['flag_sc'] = df_test['flag_sc'].astype('uint8')
## rel_ref_ind
df_test['rel_ref_ind'] = df_test['rel_ref_ind'].map({'Y' : 1, 'N': 0})
df_test['rel_ref_ind'] = df_test['rel_ref_ind'].astype('uint8')
## int_only_ind
df_test['int_only_ind'] = df_test['int_only_ind'].map({'Y' : 1, 'N': 0})
df_test['int_only_ind'] = df_test['int_only_ind'].astype('uint8')
# drop same features as for training data because they just had 1 unique
# value in training data
print("Variables we drop because there is only one unique value \
in the training set: ", drop)
for col in drop:
df_test = df_test.drop(labels=col, axis=1)
casting datetime64[ns] values to int64 with .astype(...) is deprecated and will raise in a future version. Use .view(...) instead.
Variables we drop because there is only one unique value in the training set: Index(['ppmt_pnlty', 'prod_type', 'prop_val_meth', 'int_only_ind'], dtype='object')
To ensure that the algorithm is capable of handling unknown categories we compare test and training data and encode any new categories as “Other”. This is the most reasonable modeling choice in our opinion as the algorithm is unable to interpret new categories in a sensible way if it has not been trained on them.
Afterwards, we dummy encode all categorical variables.
# Identify shared unique values for the specific categorical features
# seller_name ##################################################################
print("Seller_name")
# Common Categories in seller_name
seller_name_train = df_train['seller_name'].unique()
seller_name_test = df_test['seller_name'].unique()
# Difference in the number of unique values in the 2 datasets
print("Number of unique seller_names in train data: ",len(seller_name_train))
print("Number of unique seller_names in test data: ", len(seller_name_test))
# Create empty list to save the common values
Common_Sellers = []
# Loop through both lists and find shared values
for i in seller_name_train:
for j in seller_name_test:
if(isinstance(i, str) and i == j):
Common_Sellers.append(i)
# Print shared unique values and number of unique values
print("Shared Unique seller_names: ",Common_Sellers)
print("Number of shared unique seller_names: ", len(Common_Sellers))
# servicer_name ################################################################
print("Servicer_name")
# Common Categories in servicer_name
servicer_name_train = df_train['servicer_name'].unique()
servicer_name_test = df_test['servicer_name'].unique()
# Difference in 2 datasets
print("Number of unique servicer_name in train data: ",len(servicer_name_train))
print("Number of unique servicer_name in test data: ", len(servicer_name_test))
# Create empty list to save the common values
Common_Servicer = []
# Loop through both lists and find shared values
for i in servicer_name_train:
for j in servicer_name_test:
if(isinstance(i, str) and i == j):
Common_Servicer.append(i)
# Print shared unique values and number of unique values
print("Shared Unique servicer_name: ", Common_Servicer)
print("Number of shared unique servicer_name: ", len(Common_Servicer))
# st ###########################################################################
print("ST")
# Common Categories in st
st_train = df_train['st'].unique()
st_test = df_test['st'].unique()
# Number of unique values in the two datasets
print("Number of unique states in train data: ", len(st_train))
print("Number of unique states in test data: ", len(st_test))
# Create empty list to save the common values
Common_st = []
# Loop through both lists and find shared values
for i in st_train:
for j in st_test:
if(isinstance(i, str) and i == j):
Common_st.append(i)
# Print shared unique values and number of unique values
print("Shared Unique states: ", Common_st)
print("Number of shared unique states: ", len(Common_st))
Seller_name Number of unique seller_names in train data: 19 Number of unique seller_names in test data: 27 Shared Unique seller_names: ['QUICKEN LOANS INC.', 'Other sellers', 'BRANCH BANKING & TRUST COMPANY', 'U.S. BANK N.A.', 'WELLS FARGO BANK, N.A.', 'LOANDEPOT.COM, LLC', 'JPMORGAN CHASE BANK, N.A.', 'SUNTRUST MORTGAGE, INC.', 'FRANKLIN AMERICAN MORTGAGE COMPANY', 'BANK OF AMERICA, N.A.', 'CITIMORTGAGE, INC.', 'STEARNS LENDING, LLC', 'NATIONSTAR MORTGAGE LLC', 'FLAGSTAR BANK, FSB', 'CALIBER HOME LOANS, INC.', 'GUARANTEED RATE, INC.'] Number of shared unique seller_names: 16 Servicer_name Number of unique servicer_name in train data: 17 Number of unique servicer_name in test data: 29 Shared Unique servicer_name: ['Other servicers', 'FREEDOM MORTGAGE CORPORATION', 'TRUIST BANK', 'U.S. BANK N.A.', 'WELLS FARGO BANK, N.A.', 'QUICKEN LOANS INC.', 'JPMORGAN CHASE BANK, NATIONAL ASSOCIATION', 'LAKEVIEW LOAN SERVICING, LLC', 'NEW RESIDENTIAL MORTGAGE LLC', 'PNC BANK, NA', 'BANK OF AMERICA, N.A.', 'NATIONSTAR MORTGAGE LLC DBA MR. COOPER', 'CALIBER HOME LOANS, INC.'] Number of shared unique servicer_name: 13 ST Number of unique states in train data: 30 Number of unique states in test data: 54 Shared Unique states: ['VA', 'CA', 'FL', 'CT', 'TX', 'MO', 'PA', 'MD', 'TN', 'IL', 'OR', 'GA', 'MI', 'KY', 'NY', 'SC', 'OH', 'WI', 'WA', 'MA', 'MN', 'AZ', 'AL', 'CO', 'NC', 'UT', 'NV', 'NJ', 'IN'] Number of shared unique states: 29
# Change all categories not shared to 'Others'
# seller_name ##################################################################
print("Number of Transformations for the feature seller_name")
## Change values of non-shared categories to Other sellers
## Train data
counter = 0
for seller in df_train['seller_name'] :
if(seller not in Common_Sellers):
counter +=1
df_train['seller_name'] = df_train['seller_name']\
.replace([seller], 'Other sellers')
## Print number of transformations
print("Training transformation:" , counter)
## Test data
counter = 0
for seller in df_test['seller_name'] :
if(seller not in Common_Sellers):
counter +=1
df_test['seller_name'] = df_test['seller_name']\
.replace([seller], 'Other sellers')
## Print number of transformations
print("Test transformation:" , counter)
# servicer_name ################################################################
print("Number of Transformations for the feature servicer_name")
## Change values of non-shared categories to Other servicers
## Train data
counter = 0
for servicer in df_train['servicer_name'] :
if(servicer not in Common_Servicer):
counter +=1
df_train['servicer_name'] = df_train['servicer_name']\
.replace([servicer], 'Other servicers')
## Print number of transformations
print("Training transformation:" , counter)
## Test data
counter = 0
for servicer in df_test['servicer_name'] :
if(servicer not in Common_Servicer):
counter +=1
df_test['servicer_name'] = df_test['servicer_name']\
.replace([servicer], 'Other servicers')
## Print number of transformations
print("Test transformation:" , counter)
# st ###########################################################################
print("Number of Transformations for the feature st")
## Change values of non-shared categories to Other
## Train data
counter = 0
for st in df_train['st'] :
if(st not in Common_st):
counter +=1
df_train['st'] = df_train['st'].replace([st], 'Other')
## Print number of transformations
print("Training transformation:" , counter)
## Test data
counter = 0
for st in df_test['st'] :
if(st not in Common_st):
counter +=1
df_test['st'] = df_test['st'].replace([st], 'Other')
## Print number of transformations
print("Test transformation:" , counter)
Number of Transformations for the feature seller_name Training transformation: 3 Test transformation: 5560 Number of Transformations for the feature servicer_name Training transformation: 4 Test transformation: 10872 Number of Transformations for the feature st Training transformation: 14884 Test transformation: 4597
# dummy coding for all categorical columns for training data
dummy = ['cnt_units', 'occpy_sts', 'channel', 'prop_type', 'loan_purpose',
'pgrm_ind', 'pre_relief_prog', 'seller_name', 'st', 'servicer_name']
df_train = pd.get_dummies(df_train, columns = dummy, drop_first = True)
# dummy coding for all categorical columns for test data
dummy = ['cnt_units', 'occpy_sts', 'channel', 'prop_type', 'loan_purpose',
'pgrm_ind', 'pre_relief_prog', 'seller_name', 'st', 'servicer_name']
df_test = pd.get_dummies(df_test, columns = dummy, drop_first = True)
# Summary of Preprocessing Steps
file_name = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/columns_preprocessing.csv'
Preprocessing_Table = pd.read_csv(file_name,index_col=False)
pd.set_option('display.max_colwidth', None)
Preprocessing_Table = Preprocessing_Table.drop('#', axis =1)
dfStyler = Preprocessing_Table.style.set_properties(**{'text-align': 'left'})\
.hide_index()
display(dfStyler.set_table_styles([dict(selector='th',
props=[('text-align', 'left')])]))
print("-----------------------------------------------------------------------")
print("Table 3: Summary of Preprocessing Steps")
| Column name | Short description | Original Format | Original Values | Adapted Format | Handeling Missing Values | Further Modifications |
|---|---|---|---|---|---|---|
| fico | Credit Score | Numeric (Int64) | 300 - 850 9999 = Not Available, if Credit Score is < 300 or > 850. | Numeric (int32) | 1) np.nan = Not Available 2) Dropped | - |
| dt_first_pi | First Payment Date | Date (int64) | YYYYMM | pandas datetime (int64) | - | Dropped |
| flag_fthb | First Time Homebuyer Flag | Alpha (object) | Y = Yes N = No 9 = Not Available or Not Applicable | uint8 | 1) np.nan = Not Available or Not Applicable 2) 'N' = np.nan | Y=1 N=0 |
| dt_matr | Maturity Date | Date (int64) | YYYYMM | pandas datetime (int64) | - | Dropped; use difference between Original Loan Term and Maturity Date instead: df_train.orig_loan_term = df_train.dt_matr - df_train.dt_first_pi |
| cd_msa | Metropolitan Statistical Area (MSA) Or Metropolitan Division | Numeric (float64) | Metropolitan Division or MSA Code. Space (5) = Indicates that the area in which the mortgaged property is located is a) neither an MSA nor a Metropolitan Division, or b) unknown. | - | - | Dropped |
| mi_pct | Mortgage Insurance Percentage (MI %) | Numeric (Int64) | 1% - 55% 000 = No MI 999 = Not Available | Numeric (float64) | np.nan = Not Available | Devided by 100 |
| cnt_units | Number of Units | Numeric (Int64) | 1 = one-unit 2 = two-unit 3 = three-unit 4 = four-unit 99 = Not Available | Category | np.nan = Not Available | - |
| occpy_sts | Occupancy Status | Alpha (object) | P = Primary Residence I = Investment Property S = Second Home 9 = Not Available | Category | np.nan = Not Available | - |
| cltv | Original Combined Loan-to-Value (CLTV) | Numeric (Int64) | 201801 and prior: 6% - 200% 999 = Not Available 201802 and later: 1% - 998% 999 = Not Available HARP ranges: 1% - 998% 999 = Not Available | Numeric (float64) | 1) np.nan = Not Available 2) Dropped | Devided by 100; renamed cltv_pct |
| dti | Original Debt-to-Income (DTI) Ratio | Numeric (Int64) | 0% DTI =65% 999 = Not Available HARP ranges: 999 = Not Available | Numeric (float64) | 1) np.nan = Not Available 2) Impute cut-off value of 65% | Devided by 100; renamed dti_pct |
| orig_upb | Original UPB | Numeric (int64) | Amount will be rounded to the nearest $1,000. | Numeric (int32) | - | - |
| ltv | Original Loan-to-Value (LTV) | Numeric (Int64) | 201801 and prior: 6% - 105% 999 = Not Available 201802 and later: 1% - 998% 999 = Not Available HARP ranges: 1% - 998% 999 = Not Available | Numeric (float64) | 1) np.nan = Not Available 2) Dropped | Devided by 100; renamed ltv_pct Dropped due to high correlation with cltv |
| int_rt | Original Interest Rate | Numeric (float64) | - | - | - | Devided by 100; renamed int_rt_pct |
| channel | Channel | Alpha (object) | R = Retail B = Broker C = Correspondent T = TPO Not Specified 9 = Not Available | Category | np.nan = Not Available | - |
| ppmt_pnlty | Prepayment Penalty Mortgage (PPM) Flag | Alpha (object) | Y = PPM N = Not PPM | uint8 | - | Y=1 N=0 Dropped (only one unique value) |
| prod_type | Amortization Type (Formerly Product Type) | Alpha (object) | FRM - Fixed Rate Mortgage ARM - Adjustable Rate Mortgage | uint8 | - | FRM: 1 ARM: 0 Dropped (only one unique value) |
| st | Property State | Alpha (object) | AL, T , VA, etc. | Category | - | Consoldiate states with less than 1500 observations into "Other" |
| prop_type | Property Type | Alpha (object) | CO = Condo PU = PUD MH = Manufactured Housing SF = Single-Family CP = Co-op 99 = Not Available | Category | np.nan = Not Available | - |
| zipcode | Postal Code | Numeric (int64) | 00, where " " represents the first three digits of the 5- digit postal code Space (5) = Unknown | - | - | Dropped |
| id_loan | Loan Sequence Number | Numeric (int64) | - | - | - | Used as index |
| loan_purpose | Loan Purpose | Alpha (object) | P = Purchase C = Refinance - Cash Out N = Refinance - No Cash Out R = Refinance - Not Specified 9 =Not Available | Category | np.nan = Not Available | - |
| orig_loan_term | Original Loan Term | Numeric (int64) | Calculation: (Loan Maturity Date (MM/YY) - Loan First Payment Date (MM/YY) + 1) | int64 | - | Overwrite with difference between Original Loan Term and Maturity Date: df_train.orig_loan_term = df_train.dt_matr - df_train.dt_first_pi |
| cnt_borr | Number of Borrowers | Numeric (Int64) | 201801 and prior: 01 = 1 borrower 02 = > 1 borrowers 99 = Not Available 201802 and later: 01 = 1 borrower 02 = 2 borrowers 03 = 3 borrowers 09 = 9 borrowers 10 = 10 borrowers 99 = Not Available | uint8 | np.nan = Not Available or Not Applicable | cnt_borr==1: 0 cnt_borr>1: 1 |
| seller_name | Seller Name | Alpha Numeric (object) | Name of the seller, or "Other Sellers" | Category | - | Consolidate categories with less than 1500 observations into "Other Seller" |
| servicer_name | Servicer Name | Alpha Numeric (object) | Name of the servicer, or "Other Servicers" | Category | - | Consolidate categories with less than 1500 observations into "Other Servicer" |
| flag_sc | Super Conforming Flag | Alpha (object) | Y = Yes Space (1) = Not Super Conforming | uint8 | N' = np.nan | Y=1 N=0 |
| pre_relief | Pre-HARP Loan Sequence Number | Alpha Numeric - PYYQnXXXXXXX (object) | PYY0n Product F = FRM and A = ARM; YY0n = origination year and quarter; and, randomly assigned digits | Category | N' = np.nan | Extract only property type 'P' from 'PYYQnXXXXXXX'; renamed pre_relief_prog |
| pgrm_ind | Program Indicator | Alpha Numeric (object) | H = Home Possible F = HFA Advantage 9 = Not Available or not part of Home Possible or HFA Advantage programs | Category | 1) np.nan = Not Available or not part of Home Possible or HFA Advantage programs 2) 'N' = np.nan | Consoldiate categories 'H' and 'F' into 'Y' |
| rel_ref_ind | HARP Indicator | Alpha (object) | Y = Relief Refinance Loan Space = Non-Relief Refinance loan | uint8 | N' = np.nan | Y=1 N=0 |
| prop_val_meth | Property Valuation Method | Numeric (object) | 1 = ACE Loans 2 = Full Appraisal 3 = Other Appraisals (Desktop, driveby, external, AVM) 9 = Not Available | Category | 1) np.nan = Not Available 2) 'N' = np.nan | Dropped (only one unique value) |
| int_only_ind | Interest Only (I/O) Indicator | Alpha (object) | Y = Yes N = No | uint8 | - | Y=1 N=0 Dropped (only one unique value) |
| TARGET | Default label | Numeric (int64) | 1 = Default, 0 otherwise | uint8 | - | Y=1 N=0 |
----------------------------------------------------------------------- Table 3: Summary of Preprocessing Steps
As the final preprocessing steps, the data is split into a target- and a feature-dataset and the numerical features of both datasets are standardized. An important observation is that the data is – as one would expect and as has been mentioned previously – highly imbalanced: Only approximately 0.9% of observations default on their loan.
# Split train data into features and target
X_train = df_train.drop(['TARGET'], axis=1)
y_train = df_train[['TARGET']]
# Scale train data
standard = StandardScaler()
# determine numerical featrues which have to be scaled
numerical_cols = df_train.select_dtypes(include=\
[np.float64,np.int64, np.int32]).columns
# Make copy of dataset and scale it
X_train_scaled = X_train.copy()
X_train_scaled[numerical_cols] = standard.fit_transform(X_train_scaled\
[numerical_cols])
# Scale test data
# determine numerical featrues which have to be scaled
numerical_cols = df_test.select_dtypes(include=\
[np.float64,np.int64, np.int32]).columns
# Make copy of dataset and scale it
X_test = df_test.copy()
X_test_scaled = df_test.copy()
X_test_scaled[numerical_cols] = standard.transform(X_test_scaled\
[numerical_cols])
# setting seed for reproducable outputs
seed = 5
To build our base model, we fit a logistic regression from the package sklearn (David Cournapeau 2022) using the ridge regularization and maximal iterations of 500 on the scaled training data. Afterwards we predict the probability of defaulting for the test data observations. On Kaggle, the simple logit achieves an AUC value of 0.71312 on the public score, which will represent our baseline to beat with the XGBoost model. To interpret logit, we can look at the coefficients output of the model. The values shown below represent the average impact of a change in the features on the log odds. Only the sign of the coefficients can be directly interpreted. For example, the negative coefficient for the feature ‘fico’ means that for a c.p. higher value of ‘fico’ the probability of defaulting decreases which is consistent with our findings in the Data Analysis part.
To evaluate the degree of the feature influence, we look at the example of the dummy variable ‘servicer_name_Other_servicers’. If this dummy goes from 0 to 1, the log odds change is equal to 2.648731. To interpret this, we first calculate the odds with $odds = exp(2.648731) = 14.13609$. This means, that having this feature attribution ($‘\text{servicer_name_Other_servicers}’ = 1$), on average and c.p., multiplies the probability of defaulting by 14.13609 compared to people not having this feature attribution ($’\text{servicer_name_Other_servicers}’ = 0$).
# Fit logistic regression model
logit_tuned = LogisticRegression(fit_intercept=True,
max_iter=500,
penalty = 'l2',
random_state = seed)
logit_tuned.fit(X_train_scaled, y_train.values.ravel())
# rearrange order of features of test data, otherwise prediction does not work
cols_when_model_builds = logit_tuned.feature_names_in_
X_test_scaled = X_test_scaled[cols_when_model_builds]
# predict prop for scaled test data
predictions_prop_logit = logit_tuned.predict_proba(X_test_scaled)[:, 1]
# create wanted output format to upload to kaggle
final_result_logit = pd.DataFrame({'id_loan': X_test_scaled.index,
'TARGET': predictions_prop_logit})
# create csv
final_result_logit.to_csv('submission_logit.csv', index=False)
with pd.option_context('display.max_rows', None):
coefficients = pd.DataFrame(zip(X_test_scaled.columns,
np.transpose(logit_tuned.coef_.tolist()[0])),
columns=['features', 'coef'])
display(coefficients)
| features | coef | |
|---|---|---|
| 0 | fico | -0.575718 |
| 1 | flag_fthb | 0.108373 |
| 2 | mi_pct | 0.140078 |
| 3 | cltv_pct | 0.210306 |
| 4 | dti_pct | 0.428599 |
| 5 | orig_upb | -0.065771 |
| 6 | int_rt_pct | 0.239278 |
| 7 | orig_loan_term | 0.110838 |
| 8 | cnt_borr | -0.818664 |
| 9 | flag_sc | 0.018283 |
| 10 | rel_ref_ind | -0.020941 |
| 11 | cnt_units_2 | -0.417532 |
| 12 | cnt_units_3 | -0.647562 |
| 13 | cnt_units_4 | -0.072452 |
| 14 | occpy_sts_P | -0.024677 |
| 15 | occpy_sts_S | -0.156358 |
| 16 | channel_C | 0.110683 |
| 17 | channel_R | -0.163075 |
| 18 | prop_type_CP | 0.217262 |
| 19 | prop_type_MH | -0.032544 |
| 20 | prop_type_PU | 0.260105 |
| 21 | prop_type_SF | 0.354199 |
| 22 | loan_purpose_N | -0.310896 |
| 23 | loan_purpose_P | -0.570328 |
| 24 | pgrm_ind_Y | 0.750346 |
| 25 | pre_relief_prog_F | -0.129186 |
| 26 | pre_relief_prog_N | 0.051269 |
| 27 | seller_name_BRANCH BANKING & TRUST COMPANY | -1.471682 |
| 28 | seller_name_CALIBER HOME LOANS, INC. | 0.135019 |
| 29 | seller_name_CITIMORTGAGE, INC. | -0.914296 |
| 30 | seller_name_FLAGSTAR BANK, FSB | -0.936513 |
| 31 | seller_name_FRANKLIN AMERICAN MORTGAGE COMPANY | -1.557307 |
| 32 | seller_name_GUARANTEED RATE, INC. | -1.062020 |
| 33 | seller_name_JPMORGAN CHASE BANK, N.A. | -0.974412 |
| 34 | seller_name_LOANDEPOT.COM, LLC | -1.143579 |
| 35 | seller_name_NATIONSTAR MORTGAGE LLC | -0.811019 |
| 36 | seller_name_Other sellers | -1.449026 |
| 37 | seller_name_QUICKEN LOANS INC. | -1.548005 |
| 38 | seller_name_STEARNS LENDING, LLC | -0.587617 |
| 39 | seller_name_SUNTRUST MORTGAGE, INC. | -1.520261 |
| 40 | seller_name_U.S. BANK N.A. | 1.493363 |
| 41 | seller_name_WELLS FARGO BANK, N.A. | 1.357865 |
| 42 | st_AZ | -0.228960 |
| 43 | st_CA | -0.500678 |
| 44 | st_CO | -0.600718 |
| 45 | st_CT | 0.088731 |
| 46 | st_FL | 0.481450 |
| 47 | st_GA | -0.036790 |
| 48 | st_IL | -0.147373 |
| 49 | st_IN | -0.270770 |
| 50 | st_KY | 0.006386 |
| 51 | st_MA | 0.119735 |
| 52 | st_MD | 0.145042 |
| 53 | st_MI | -0.527370 |
| 54 | st_MN | -0.342316 |
| 55 | st_MO | -0.127068 |
| 56 | st_NC | -0.184554 |
| 57 | st_NJ | 0.290828 |
| 58 | st_NV | -0.281246 |
| 59 | st_NY | -0.201873 |
| 60 | st_OH | -0.178349 |
| 61 | st_OR | -0.622058 |
| 62 | st_Other | 0.058612 |
| 63 | st_PA | -0.056300 |
| 64 | st_SC | -0.188443 |
| 65 | st_TN | -0.001231 |
| 66 | st_TX | 0.062260 |
| 67 | st_UT | -0.159345 |
| 68 | st_VA | -0.082156 |
| 69 | st_WA | -0.643938 |
| 70 | st_WI | -0.344999 |
| 71 | servicer_name_CALIBER HOME LOANS, INC. | 0.654652 |
| 72 | servicer_name_FREEDOM MORTGAGE CORPORATION | 1.882752 |
| 73 | servicer_name_JPMORGAN CHASE BANK, NATIONAL ASSOCIATION | -0.021488 |
| 74 | servicer_name_LAKEVIEW LOAN SERVICING, LLC | 2.007397 |
| 75 | servicer_name_NATIONSTAR MORTGAGE LLC DBA MR. COOPER | 0.757496 |
| 76 | servicer_name_NEW RESIDENTIAL MORTGAGE LLC | 1.232764 |
| 77 | servicer_name_Other servicers | 2.648731 |
| 78 | servicer_name_PNC BANK, NA | 1.106743 |
| 79 | servicer_name_QUICKEN LOANS INC. | 2.438266 |
| 80 | servicer_name_TRUIST BANK | 0.915886 |
| 81 | servicer_name_U.S. BANK N.A. | -1.328144 |
| 82 | servicer_name_WELLS FARGO BANK, N.A. | -1.007737 |
odds_servicer_name_Other = np.exp(coefficients[coefficients.features == \
'servicer_name_Other servicers'].coef.values[0])
odds_servicer_name_Other
14.136094054935588
As a more advanced technique, we choose XGBoost (xgboost developers 2021). Within the practical application of our project, in addition to the number of base learners and the learning rate, six other hyperparameters were used within the model specification. In order to achieve the maximum possible predictive power within the model specification, a grid search was used as a tuning method in order to achieve the best possible combination of hyperparameter values. The concrete values can be seen within the code. Compared to the previously used logit model, the AUC value could be increased up to 0.73865 on Kaggle. The significance of this increase is discussed in the resume. In addition to the performance, however, due to the complexity of the model, a decrease in interpretability could be observed, which is potentially solved and discussed within the next section.(Friedman 2001)
# Fitting model
## model was tuned by splitting the training data into train and validation
## grid search and cross validation with different parameters was testet
## best model on validation set got now picked to predict the final model with
## the complete training set
xgb_tuned = xgb.XGBClassifier(
colsample_bytree=0.316666666666,
early_stop = 10 ,
learning_rate= 0.125,
max_depth=4,
n_estimators=125,
use_label_encoder=False,
eval_metric = 'logloss',
random_state = seed)
xgb_tuned.fit(X_train_scaled, y_train.values.ravel())
# rearrange order of features, otherwise the prediction does not work
cols_when_model_builds = xgb_tuned.get_booster().feature_names
X_train_scaled = X_train_scaled[cols_when_model_builds]
X_train = X_train[cols_when_model_builds]
X_test_scaled = X_test_scaled[cols_when_model_builds]
X_test = X_test[cols_when_model_builds]
# predict prob for XGBoost
predictions_prop_xgb = xgb_tuned.predict_proba(X_test_scaled)[:, 1]
# create wanted output format to upload to kaggle
final_result_xgb = pd.DataFrame({'id_loan': X_test_scaled.index,
'TARGET': predictions_prop_xgb})
# create csv
final_result_xgb.to_csv('submission_gxb.csv', index=False)
[07:20:06] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
# defining interesting observations to see interpretable outputs
# interesting here are pretty high probability
# Chose row/ observation and extract values
## id = 97993, f_xgb(x) = 0,000073524774
test_point_low = X_test_scaled.index.get_loc(97993)
observation_low = X_test_scaled.iloc[test_point_low,:]
## id = 5563, f_xgb(x) = 0,08390787
test_point_middle = X_test_scaled.index.get_loc(5563)
observation_middle = X_test_scaled.iloc[test_point_middle,:]
## id = 36483, f_xgb(x) = 0,7579817
test_point_high = X_test_scaled.index.get_loc(36483)
observation_high = X_test_scaled.iloc[test_point_high,:]
# All features to give in parameter specification of local
# interpretability models
X_var_labels = X_test_scaled.columns.values
Within the practical application the anchor method (Robert Samoilescu 2018) delivered an unsatisfying result. Within the observations made regarding the individuals, it was noticed that the method could not provide an explanation regarding predictions with a probability lower than 0.5. For observations with a prediction value higher than 0.5, the method could provide an explanation, but within the coverage value it featured a value below zero and contained at best a relevant feature count between 10 and 20. Occasionally, dentified anchors contained the entire feature set. The poor quality of the results can be traced back to the high dimension of the feature set and the extremely high ratio between the defaulting and non-defaulting observations (99.1 : 0.9). This is confirmed by the formal definition of the probabilistic parameter given above in the formal anchor definition.
# define prediction function we want to interpret
pred_fun = xgb_tuned.predict_proba
# Build explanation model
#explainer = AnchorTabular(pred_fun, X_train_scaled.columns, seed=seed)
explainer = AnchorTabular(pred_fun, feature_names=X_var_labels, seed=seed)
explainer.fit(X_train_scaled.to_numpy())
AnchorTabular(meta={
'name': 'AnchorTabular',
'type': ['blackbox'],
'explanations': ['local'],
'params': {'disc_perc': (25, 50, 75), 'seed': 5},
'version': '0.7.0'}
)
# Print prediction the anchor method would make
class_names=['0','1']
print('Prediction for the observation with high probability: ', \
class_names[explainer.predictor(observation_high.to_numpy()\
.reshape(1, -1))[0]])
# Explain local observation
explanation = explainer.explain(observation_high.to_numpy(),
threshold=0.9, max_anchor_size = None)
# Print the output
print('Anchor Rules: %s' % (' AND '.join(explanation.anchor)))
print('Precision: %.2f' % explanation.precision)
print('Coverage: %.2f' % explanation.coverage)
Prediction for the observation with high probability: 1 Anchor Rules: seller_name_WELLS FARGO BANK, N.A. > 0.00 AND st_FL > 0.00 AND fico <= -0.64 AND servicer_name_Other servicers > 0.00 AND seller_name_Other sellers <= 0.00 AND -0.90 < orig_loan_term <= 0.62 AND rel_ref_ind <= 0.00 AND seller_name_JPMORGAN CHASE BANK, N.A. <= 0.00 AND cltv_pct > -0.48 AND dti_pct > -0.13 AND int_rt_pct > -0.58 AND orig_upb > 0.59 AND pre_relief_prog_F <= 0.00 AND servicer_name_WELLS FARGO BANK, N.A. <= 0.00 AND servicer_name_JPMORGAN CHASE BANK, NATIONAL ASSOCIATION <= 0.00 AND servicer_name_TRUIST BANK <= 0.00 AND st_MI <= 0.00 AND channel_R <= 0.00 AND st_CA <= 0.00 AND occpy_sts_S <= 0.00 AND seller_name_FRANKLIN AMERICAN MORTGAGE COMPANY <= 0.00 AND cnt_units_2 <= 0.00 AND st_WA <= 0.00 AND st_IL <= 0.00 AND st_WI <= 0.00 AND st_MO <= 0.00 AND st_CO <= 0.00 AND seller_name_BRANCH BANKING & TRUST COMPANY <= 0.00 Precision: 0.90 Coverage: 0.00
# print anchor to see all rules needed to make a 0.95 % precision on that
# this observation is of class 1
explanation.anchor
['seller_name_WELLS FARGO BANK, N.A. > 0.00', 'st_FL > 0.00', 'fico <= -0.64', 'servicer_name_Other servicers > 0.00', 'seller_name_Other sellers <= 0.00', '-0.90 < orig_loan_term <= 0.62', 'rel_ref_ind <= 0.00', 'seller_name_JPMORGAN CHASE BANK, N.A. <= 0.00', 'cltv_pct > -0.48', 'dti_pct > -0.13', 'int_rt_pct > -0.58', 'orig_upb > 0.59', 'pre_relief_prog_F <= 0.00', 'servicer_name_WELLS FARGO BANK, N.A. <= 0.00', 'servicer_name_JPMORGAN CHASE BANK, NATIONAL ASSOCIATION <= 0.00', 'servicer_name_TRUIST BANK <= 0.00', 'st_MI <= 0.00', 'channel_R <= 0.00', 'st_CA <= 0.00', 'occpy_sts_S <= 0.00', 'seller_name_FRANKLIN AMERICAN MORTGAGE COMPANY <= 0.00', 'cnt_units_2 <= 0.00', 'st_WA <= 0.00', 'st_IL <= 0.00', 'st_WI <= 0.00', 'st_MO <= 0.00', 'st_CO <= 0.00', 'seller_name_BRANCH BANKING & TRUST COMPANY <= 0.00']
As anchor method did not provide useful interpretation for our model, we therefore apply LIME. In order to investigate potential stability issues in our application, the version of LIME by Visani et al. (2022) is used as this implementation includes a function that checks the previously described stability indices: VSI and CSI.
Below is the LIME result employed on our XGBoost model using the 10 most important features. Accordingly, LIME predicts a value of 76% probability of default for this specific applicant with a predicted value of 75.6% by XGBoost. Clearly, almost the same probability values resulted from LIME and the original model confirms the well-performed loss minimization in LIME. The results presented show the highest contribution by Wells Fargo Bank being the seller of the mortgage with 5%, while the relatively low fico score as a measure of the applicant's creditworthiness comes next with the value of 3% in worsening the applicant's probability of default. On the positive side, the most impactful feature is the fact that the U.S. Bank is not the seller of the mortgage.
## Build explanation model
explainer = LimeTabularExplainerOvr(training_data = X_train_scaled.to_numpy(),
feature_names=X_var_labels,
class_names=['0','1'],
verbose=True,
random_state = seed)
## Visualize output
# 10 most important features
k=10
# define prediction function we want to interpret
pred_fun = xgb_tuned.predict_proba
exp = explainer.explain_instance(data_row=observation_high.to_numpy(),
predict_fn=pred_fun, num_features=k)
exp.show_in_notebook(show_table=True)
Intercept 0.05384397044723785 Prediction_local [0.1175635] Right: 0.7579817
Although the outcome of LIME is somewhat informative to explain the high probability of default for this specific applicant e.g. low creditworthiness being an indicator of the applicant's weak financial standpoint contributing to the high risk of default, the almost negligibly small magnitude of all the 10 variables could be a sign of instability. Following the hints leading to this issue, stability indices for 10, 20, 50 and 100 LIME iterations using the same observation have been checked. The graph below represents the outcome of this experiment.
# Graph for stability indices
n_calls = [10, 20, 50, 100]
CSI =[]
VSI =[]
for call in n_calls:
stability = explainer.check_stability(data_row=observation_high, \
predict_fn=pred_fun, n_calls = call)
CSI.append(stability[0])
VSI.append(stability[1])
# Plot Results
plt.plot(n_calls,CSI, label = "CSI")
plt.plot(n_calls,VSI, label = "VSI")
plt.xlabel('Number of Calls')
plt.ylabel('Stability Indices')
plt.title('LIME Stability')
plt.legend()
plt.show()

Accordingly, relatively steady and high values for CSI show the reliable sign and thus form of contribution (positive/negative) of LIME explanations while lower but steady VSI values require more caution: The variables in our results and consequently our whole explanation is relatively less reliable in terms of the important features describing the probability of default. To be more precise, the magnitude and therefore the order of the most important features in explaining the target could fluctuate in different calls of LIME for the same observation which makes the interpretation less reliable. This issue is relevant in our case due to high dimensionality of the dataset which could cause problems mentioned in LIME limitations and thus explain the not-so-informative LIME results to some extent. The problem becomes even more concerning when we repeat the stability check for the same number of iterations, as the value of each index for a certain number of LIME calls fluctuates as well. The stability concerns in LIME lead us to try another method, SHAP, with the aim of interpretability improvement.
Lastly, we use the presented TreeExplainer (Scott Lundberg 2017). First, we define the explainer function and calculate the SHAP values for the whole test data. As the feature perturbation method, we use the default value “interventional”. To achieve stable results, we use the whole training data as background data. We now inspect the output of three different observations of the test data, one for which XGBoost predicted a high probability of defaulting (f(x) = 0,7579817), the second with a slightly higher probability of defaulting compared to the base value (f(x) = 0,08390787) and one with a lower probability of defaulting (f(x) = 0,000073524774). The base value represents the average model prediction for the training data with E[f(X)] = 0.012. The figure below shows the waterfall plot with the 15 most important features pushing the base value towards the final prediction for the three observations. The different local feature contributions show similar results regarding the most important features. The level of the contribution depends on the specific feature values and feature combinations. The result of SHAP for the most important features are consistent with our intuitive thoughts after the Data Analysis part. For example, a high ‘fico’ score (e.g., 809 for the low probability prediction) influences the base value negatively and therefore decreases the probability of defaulting, while a low ‘fico’ score (e.g., 620 for the high probability prediction) influences the base value positively and therefore increases the probability of defaulting.
# Build explanation model
# longer runtime, because the model uses every single observation to create
# a global explanation as well, to improve interpretability and faithfulness
# of interpretations of single observations
explainer_xgb = shap.TreeExplainer(xgb_tuned, data=X_train_scaled,
feature_perturbation='interventional',
model_output='probability')
shap_values_xgb = explainer_xgb.shap_values(X_test_scaled)
# Generate waterfall plot
plt_low = shap.plots._waterfall\
.waterfall_legacy(explainer_xgb.expected_value, shap_values_xgb[test_point_low],
features=X_test.values[test_point_low],
feature_names=X_var_labels, max_display=15, show=True)
plt_middle = shap.plots._waterfall\
.waterfall_legacy(explainer_xgb.expected_value,
shap_values_xgb[test_point_middle],
features=X_test.values[test_point_middle],
feature_names=X_var_labels, max_display=15, show=True)
plt_high = shap.plots._waterfall\
.waterfall_legacy(explainer_xgb.expected_value,
shap_values_xgb[test_point_high],
features=X_test.values[test_point_high],
feature_names=X_var_labels, max_display=15, show=True)
99%|===================| 49733/50015 [02:46<00:00]



To gain additional insights into the results, we plot the summary plot, which constructs the global structure and therefore adds a rich summary of the entire model to the individual feature importances. The most important feature over all observations is the ‘fico’ value, followed by the dummy feature ‘servicer_name_Other_servicers’, and the feature ‘cnt_borr’. Comparing the global with the three local plots, we can see many similarities in the global feature importance and the feature importance for these three observations.
# Generate summary bar plot to see global feature importance built with many
# local ones
shap.summary_plot(shap_values_xgb, X_test_scaled,plot_type="bar" , show=True)

Stability of SHAP To eliminate computing complexity, the SHAP package in python includes various explainers for different ML models. For many of those, like the TreeExplainer when using the feature perturbation “interventional” (default value for this function), background data is required and serves as a prior expectation towards the instances to be explained. The official SHAP documentation suggests 100 to 1000 randomly drawn samples from the training data as an adequate background dataset, while other studies employ different sample sizes. The question now is, what is the effect of different background dataset sizes on SHAP TreeExplainer and are the results different when using the feature perturbation approach “tree_path_dependet”, which does not require any background data. Instead, it just follows the trees and use the number of training examples that went down each leaf to represent the background distribution.
To answer this question, we therefore simulate 100 iterations of SHAP using different sample sizes of the background data (50, 500, 1500, 15000, 150000) to test the stability of SHAP with changing sample sizes. We observe that the order of feature importance fluctuates when using different background data, especially when using small sample sizes. The results suggest that users should take into account how background data affects SHAP results, with improved SHAP stability as the background sample size increases. By using the whole training dataset as background data, the SHAP results are stable.
The code and further explanations can be found in the Appendix.
With respect to the research question and hypotheses stated previously, we can thus summarize that we indeed see a trade-off between performance (AUC) and interpretability when comparing Logistic Regression as an intrinsically interpretable method and XGBoost as a black-box model. One might criticize that the AUC improvement appears relatively small. However, this has to be put into perspective, as even a small change in predictive performance may translate into a substantial monetary value for the bank. We expand on this point in the consecutive section. Overall, the results of Stage II confirm hypotheses I and II. In Stage III, we are able to construct a model framework applicable within credit risk that achieves a high predictive performance as measure by the AUC whilst maintaining or even improving interpretability; thereby relaxing said tradeoff and confirming hypothesis III. To this end, we use XGBoost as a black-box model and add model-agnostic, local post-hoc methods. Within our framework, SHAP delievers the most interpretable and stable results among the three methods considered.
Even a small increase in predictive performance may transfer into a significant monetary value for financial institutions within credit risk (Emad Azhar Ali et al. 2021; Hayashi 2016; Altinbas and Akkaya 2017). This is due to the fact that the costs of a type I error, i.e. the cost associated with granting a credit to a defaulting customer, differ substantially from the costs of a type II error, i.e. the profit lost by rejecting a non-defaulting customer. As quantifying the exact cost differences requires a large amount of information (such as regulatory capital requirements or exposure at default), the literature makes use of “rules of thumb” regarding appropriates ratios of misclassification costs.(Dumitrescu et al. 2022) However, the magnitudes of the ratios used in the literature vary widely. For example, West (2000) proposes a ratio of 1:5, while others assume as much as 1:20 Kao et al. (2012). For this reason, we quantify the costs once with a ratio of 1:5 (as the lower limit of the expected costs), once with 1:10 (as the middle part of the expected costs) and once with 1:20 (as the upper limit of the expected costs). We make no claim to completeness or precision in this section. Instead, we aim to provide an order of magnitude to illustrate how the increase in the AUC achieved by using XGBoost instead of Logistic Regression translates into costs.
For this purpose, we split the original training data into training and validation data (70:30) to be able to calculate the corresponding costs of falsely negative predicted observations (FN) and falsely positive predicted observations (FP) and calculate costs corresponding to our predictions using the rules of thumb. Using for example the ratio of 1:5, this means that one FP prediction (giving a loan to a person who will default) costs the bank the same amount as making 5 FN predictions (not giving a loan to a person, who would have not defaulted).
To determines the threshold for which an observation is predicted as defaulting ($p >= threshold$) or as non-defaulting ($p < threshold$), we follow the approach of Charles Elkan (2001) by calculating the cost-minimal threshold by $ 𝑝(𝑏|𝒙) ≥ 𝜏^∗ = \frac{𝐶(𝑏,𝐺)}{ 𝐶 (𝑏,𝐺) + 𝐶(𝑔,𝐵)} $ and calculating the different thresholds using the three ratios. We do not use an empirical approach to tune the models using a cost matrix as this would go beyond the scope of this paper.
To get representative results, we simulate 100 iterations of splitting the original training data into the new training and new validation data (70:30) and build a new Logistic Regression as well as XGBoost with the same parameters as above using the new training data of each iteration. Using these models, we predict the probabilities of the validation observations for each round and calculate the confusion matrix as well as the AUC values for each iteration.
Afterwards we calculate the average values for AUC, the TP, TN, FP and FN values, visualize them and calculate the costs using the ratios and the corresponding theoretical optimal thresholds.
The average AUC values do not differ as much in this simulation as above, with Logistic Regression achieving 0.8535 and XGBoost achieving 0.8611. The average values for the confusion matrix are shown in the graph below. The results do not give consistent results. While the AUC of XGBoost is higher for each iteration and on average than of Logistic Regression, the corresponding costs are not lower for XGBoost for each cost structure.
These results suggest that when building credit-risk models with imbalanced data, a cost sensitive algorithm should be used rather than only focusing on an improvement of the AUC value. This result should be addressed by future research. In the following section, we point out further limitations and thus potentials for future investigations.
from sklearn.model_selection import train_test_split, KFold
iterations = 100
standard = StandardScaler()
numerical_cols = X_train.select_dtypes(include=[np.float64,
np.int64,
np.int32]).columns
xgb_costAnalysis = xgb.XGBClassifier(
colsample_bytree=0.316666666666,
early_stop = 10 ,
learning_rate= 0.1,
max_depth=4,
n_estimators=125,
use_label_encoder=False,
eval_metric = 'logloss',
random_state = seed
)
# Fit logistic regression model
logit_costAnalysis = LogisticRegression(fit_intercept=True,max_iter=500,
penalty = 'l2')
# 1:5 threshold cost matrix for our scenario
cost_matrix_05 = pd.DataFrame({'actual_GOOD(0)': [0, 1],
'actual_BAD(1)': [5, 0]},
index= ['predicted_GOOD(0)', 'predicted_BAD(1)'])
# 1:10 threshold cost matrix for our scenario
cost_matrix_10 = pd.DataFrame({'actual_GOOD(0)': [0, 1],
'actual_BAD(1)': [10, 0]},
index= ['predicted_GOOD(0)', 'predicted_BAD(1)'])
# 1:20 threshold cost matrix for our scenario (project-specific)
cost_matrix_20 = pd.DataFrame({'actual_GOOD(0)': [0, 1],
'actual_BAD(1)': [20, 0]},
index= ['predicted_GOOD(0)', 'predicted_BAD(1)'])
# Bayes optimal threshold 1:5 ratio
threshold_bayes_05 = (cost_matrix_05.iloc[1,0] # C(b,G)
/(cost_matrix_05.iloc[1,0] # C(b,G)
+cost_matrix_05.iloc[0,1])).round(5) # C(g,B)
# Bayes optimal threshold 1:10 ratio
threshold_bayes_10 = (cost_matrix_10.iloc[1,0] # C(b,G)
/(cost_matrix_10.iloc[1,0] # C(b,G)
+cost_matrix_10.iloc[0,1])).round(5) # C(g,B)
# Bayes optimal threshold 1:20 ratio
threshold_bayes_20 = (cost_matrix_20.iloc[1,0] # C(b,G)
/(cost_matrix_20.iloc[1,0] # C(b,G)
+cost_matrix_20.iloc[0,1])).round(5) # C(g,B)
fn_logit_05 = []
fn_logit_10 = []
fn_logit_20 = []
fp_logit_05 = []
fp_logit_10 = []
fp_logit_20 = []
fn_xgb_05 = []
fn_xgb_10 = []
fn_xgb_20 = []
fp_xgb_05 = []
fp_xgb_10 = []
fp_xgb_20 = []
tn_logit_05 = []
tn_logit_10 = []
tn_logit_20 = []
tp_logit_05 = []
tp_logit_10 = []
tp_logit_20 = []
tn_xgb_05 = []
tn_xgb_10 = []
tn_xgb_20 = []
tp_xgb_05 = []
tp_xgb_10 = []
tp_xgb_20 = []
cv_auc_logit = []
cv_auc_xgb = []
y = y_train.copy()
y = y.reset_index()
X = X_train.copy()
X = X.reset_index()
X = X.drop('id_loan', axis = 1)
y = y.drop('id_loan', axis = 1)
for i in range(0,iterations):
print('This is iteration number '+ str(i+1))
X_train_costAnalysis, X_test_costAnalysis, \
y_train_costAnalysis, y_test_costAnalysis = \
train_test_split(X, y, test_size=0.3, random_state=i)
# Scale Data
X_train_scaled_costAnalysis = X_train_costAnalysis.copy()
X_test_scaled_costAnalysis = X_test_costAnalysis.copy()
X_train_scaled_costAnalysis[numerical_cols] = \
standard.fit_transform(X_train_scaled_costAnalysis[numerical_cols])
X_test_scaled_costAnalysis[numerical_cols] = \
standard.transform(X_test_scaled_costAnalysis[numerical_cols])
# Fit models
logit_costAnalysis.fit(X_train_scaled_costAnalysis,
y_train_costAnalysis.values.ravel())
xgb_costAnalysis.fit(X_train_scaled_costAnalysis,
y_train_costAnalysis.values.ravel())
# Make probability predictions
# rearrange order of features, otherwise the prediction does not work
cols_when_model_builds = xgb_costAnalysis.get_booster().feature_names
X_test_scaled_costAnalysis = \
X_test_scaled_costAnalysis[cols_when_model_builds]
pred_proba_xgb_costAnalysis = \
xgb_costAnalysis.predict_proba(X_test_scaled_costAnalysis)[:,1]
# rearrange order of features, otherwise the prediction does not work
cols_when_model_builds = logit_costAnalysis.feature_names_in_
X_test_scaled_costAnalysis = \
X_test_scaled_costAnalysis[cols_when_model_builds]
pred_proba_logit_costAnalysis = \
logit_costAnalysis.predict_proba(X_test_scaled_costAnalysis)[:,1]
# Make predictions based on bayes threshold
pred_bayes_xgb_05 = np.where(pred_proba_xgb_costAnalysis \
>= threshold_bayes_05, 1, 0)
pred_bayes_xgb_10 = np.where(pred_proba_xgb_costAnalysis \
>= threshold_bayes_10, 1, 0)
pred_bayes_xgb_20 = np.where(pred_proba_xgb_costAnalysis \
>= threshold_bayes_20, 1, 0)
pred_bayes_logit_05 = np.where(pred_proba_logit_costAnalysis \
>= threshold_bayes_05, 1, 0)
pred_bayes_logit_10 = np.where(pred_proba_logit_costAnalysis \
>= threshold_bayes_10, 1, 0)
pred_bayes_logit_20 = np.where(pred_proba_logit_costAnalysis \
>= threshold_bayes_20, 1, 0)
cmat_bayes_xgb_05 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_xgb_05)
cmat_bayes_xgb_10 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_xgb_10)
cmat_bayes_xgb_20 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_xgb_20)
cmat_bayes_logit_05 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_logit_05)
cmat_bayes_logit_10 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_logit_10)
cmat_bayes_logit_20 = metrics.confusion_matrix(y_test_costAnalysis,
pred_bayes_logit_20)
# Append to specific list to calculate the overall average over all
# iterations
fn_logit_05.append(cmat_bayes_logit_05[0][1])
fn_logit_10.append(cmat_bayes_logit_10[0][1])
fn_logit_20.append(cmat_bayes_logit_20[0][1])
fp_logit_05.append(cmat_bayes_logit_05[1][0])
fp_logit_10.append(cmat_bayes_logit_10[1][0])
fp_logit_20.append(cmat_bayes_logit_20[1][0])
fn_xgb_05.append(cmat_bayes_xgb_05[0][1])
fn_xgb_10.append(cmat_bayes_xgb_10[0][1])
fn_xgb_20.append(cmat_bayes_xgb_20[0][1])
fp_xgb_05.append(cmat_bayes_xgb_05[1][0])
fp_xgb_10.append(cmat_bayes_xgb_10[1][0])
fp_xgb_20.append(cmat_bayes_xgb_20[1][0])
tn_logit_05.append(cmat_bayes_logit_05[1][1])
tn_logit_10.append(cmat_bayes_logit_10[1][1])
tn_logit_20.append(cmat_bayes_logit_20[1][1])
tp_logit_05.append(cmat_bayes_logit_05[0][0])
tp_logit_10.append(cmat_bayes_logit_10[0][0])
tp_logit_20.append(cmat_bayes_logit_20[0][0])
tn_xgb_05.append(cmat_bayes_xgb_05[1][1])
tn_xgb_10.append(cmat_bayes_xgb_10[1][1])
tn_xgb_20.append(cmat_bayes_xgb_20[1][1])
tp_xgb_05.append(cmat_bayes_xgb_05[0][0])
tp_xgb_10.append(cmat_bayes_xgb_10[0][0])
tp_xgb_20.append(cmat_bayes_xgb_20[0][0])
# AUC values
# Logit
auc_logit = metrics.roc_auc_score(y_test_costAnalysis,
pred_proba_logit_costAnalysis)
cv_auc_logit.append(auc_logit)
print('The logit AUC on test set is: {:.4f}'.format(cv_auc_logit[i]))
# XGB
auc_xgb = metrics.roc_auc_score(y_test_costAnalysis,
pred_proba_xgb_costAnalysis)
cv_auc_xgb.append(auc_xgb)
print('The XGB AUC on test set is: {:.4f}'.format(cv_auc_xgb[i]))
print('')
# if it is the final iteration, calculate overall mean of AUC
print('The final average AUC of XGB is: {:.4f}'.format(sum(cv_auc_logit) \
/ float(len(cv_auc_logit))))
print('The final average AUC of Logit is: {:.4f}'.format(sum(cv_auc_xgb) \
/ float(len(cv_auc_xgb))))
This is iteration number 1
[07:52:19] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8576
The XGB AUC on test set is: 0.8642
This is iteration number 2
[07:52:41] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8481
The XGB AUC on test set is: 0.8577
This is iteration number 3
[07:53:03] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8512
The XGB AUC on test set is: 0.8634
This is iteration number 4
[07:53:46] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8456
The XGB AUC on test set is: 0.8487
This is iteration number 5
[07:54:08] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8491
The XGB AUC on test set is: 0.8525
This is iteration number 6
[07:54:29] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8567
The XGB AUC on test set is: 0.8654
This is iteration number 7
[07:54:52] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8685
The XGB AUC on test set is: 0.8734
This is iteration number 8
[07:55:13] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8609
The XGB AUC on test set is: 0.8694
This is iteration number 9
[07:55:39] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8375
The XGB AUC on test set is: 0.8539
This is iteration number 10
[07:56:03] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8481
The XGB AUC on test set is: 0.8583
This is iteration number 11
[07:56:24] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8534
The XGB AUC on test set is: 0.8623
This is iteration number 12
[07:56:46] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8654
The XGB AUC on test set is: 0.8709
This is iteration number 13
[07:57:07] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8580
The XGB AUC on test set is: 0.8642
This is iteration number 14
[07:57:29] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8604
The XGB AUC on test set is: 0.8657
This is iteration number 15
[07:57:53] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8521
The XGB AUC on test set is: 0.8505
This is iteration number 16
[07:58:14] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8473
The XGB AUC on test set is: 0.8564
This is iteration number 17
[07:58:35] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8402
The XGB AUC on test set is: 0.8514
This is iteration number 18
[07:58:58] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8549
The XGB AUC on test set is: 0.8596
This is iteration number 19
[07:59:19] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8628
The XGB AUC on test set is: 0.8752
This is iteration number 20
[07:59:40] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8530
The XGB AUC on test set is: 0.8572
This is iteration number 21
[08:00:04] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8512
The XGB AUC on test set is: 0.8558
This is iteration number 22
[08:00:26] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8602
The XGB AUC on test set is: 0.8685
This is iteration number 23
[08:00:48] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8576
The XGB AUC on test set is: 0.8676
This is iteration number 24
[08:01:10] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8494
The XGB AUC on test set is: 0.8591
This is iteration number 25
[08:01:30] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8532
The XGB AUC on test set is: 0.8585
This is iteration number 26
[08:01:53] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8602
The XGB AUC on test set is: 0.8647
This is iteration number 27
[08:02:16] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8574
The XGB AUC on test set is: 0.8693
This is iteration number 28
[08:02:38] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8508
The XGB AUC on test set is: 0.8578
This is iteration number 29
[08:02:59] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8460
The XGB AUC on test set is: 0.8620
This is iteration number 30
[08:03:21] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8465
The XGB AUC on test set is: 0.8563
This is iteration number 31
[08:03:43] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8517
The XGB AUC on test set is: 0.8633
This is iteration number 32
[08:04:05] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8414
The XGB AUC on test set is: 0.8539
This is iteration number 33
[08:04:29] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8501
The XGB AUC on test set is: 0.8587
This is iteration number 34
[08:04:52] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8461
The XGB AUC on test set is: 0.8596
This is iteration number 35
[08:05:15] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8449
The XGB AUC on test set is: 0.8563
This is iteration number 36
[08:05:36] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8459
The XGB AUC on test set is: 0.8524
This is iteration number 37
[08:05:56] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8681
The XGB AUC on test set is: 0.8711
This is iteration number 38
[08:06:18] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8488
The XGB AUC on test set is: 0.8544
This is iteration number 39
[08:06:42] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8680
The XGB AUC on test set is: 0.8739
This is iteration number 40
[08:07:03] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8507
The XGB AUC on test set is: 0.8604
This is iteration number 41
[08:07:24] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8683
The XGB AUC on test set is: 0.8780
This is iteration number 42
[08:07:45] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8442
The XGB AUC on test set is: 0.8520
This is iteration number 43
[08:08:06] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8442
The XGB AUC on test set is: 0.8528
This is iteration number 44
[08:08:27] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8479
The XGB AUC on test set is: 0.8560
This is iteration number 45
[08:08:49] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8404
The XGB AUC on test set is: 0.8463
This is iteration number 46
[08:09:13] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8606
The XGB AUC on test set is: 0.8690
This is iteration number 47
[08:09:34] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8473
The XGB AUC on test set is: 0.8632
This is iteration number 48
[08:09:54] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8548
The XGB AUC on test set is: 0.8520
This is iteration number 49
[08:10:16] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8523
The XGB AUC on test set is: 0.8605
This is iteration number 50
[08:10:37] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8446
The XGB AUC on test set is: 0.8478
This is iteration number 51
[08:10:58] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8571
The XGB AUC on test set is: 0.8612
This is iteration number 52
[08:11:22] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8472
The XGB AUC on test set is: 0.8579
This is iteration number 53
[08:11:43] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8532
The XGB AUC on test set is: 0.8666
This is iteration number 54
[08:12:04] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8588
The XGB AUC on test set is: 0.8663
This is iteration number 55
[08:12:25] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8489
The XGB AUC on test set is: 0.8545
This is iteration number 56
[08:12:47] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8634
The XGB AUC on test set is: 0.8643
This is iteration number 57
[08:13:09] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8525
The XGB AUC on test set is: 0.8567
This is iteration number 58
[08:13:34] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8544
The XGB AUC on test set is: 0.8553
This is iteration number 59
[08:13:55] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8512
The XGB AUC on test set is: 0.8585
This is iteration number 60
[08:14:15] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8581
The XGB AUC on test set is: 0.8645
This is iteration number 61
[08:14:37] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8525
The XGB AUC on test set is: 0.8603
This is iteration number 62
[08:14:59] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8599
The XGB AUC on test set is: 0.8641
This is iteration number 63
[08:15:20] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8564
The XGB AUC on test set is: 0.8643
This is iteration number 64
[08:15:44] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8590
The XGB AUC on test set is: 0.8623
This is iteration number 65
[08:16:05] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8650
The XGB AUC on test set is: 0.8672
This is iteration number 66
[08:16:25] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8541
The XGB AUC on test set is: 0.8702
This is iteration number 67
[08:16:46] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8544
The XGB AUC on test set is: 0.8614
This is iteration number 68
[08:17:08] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8457
The XGB AUC on test set is: 0.8576
This is iteration number 69
[08:17:29] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8558
The XGB AUC on test set is: 0.8661
This is iteration number 70
[08:17:53] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8577
The XGB AUC on test set is: 0.8626
This is iteration number 71
[08:18:13] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8561
The XGB AUC on test set is: 0.8576
This is iteration number 72
[08:18:34] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8512
The XGB AUC on test set is: 0.8637
This is iteration number 73
[08:18:55] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8571
The XGB AUC on test set is: 0.8640
This is iteration number 74
[08:19:16] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8631
The XGB AUC on test set is: 0.8734
This is iteration number 75
[08:19:41] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8608
The XGB AUC on test set is: 0.8648
This is iteration number 76
[08:20:04] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8729
The XGB AUC on test set is: 0.8749
This is iteration number 77
[08:20:25] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8493
The XGB AUC on test set is: 0.8576
This is iteration number 78
[08:20:47] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8634
The XGB AUC on test set is: 0.8781
This is iteration number 79
[08:21:07] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8464
The XGB AUC on test set is: 0.8536
This is iteration number 80
[08:21:28] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8456
The XGB AUC on test set is: 0.8604
This is iteration number 81
[08:21:49] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8584
The XGB AUC on test set is: 0.8605
This is iteration number 82
[08:22:10] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8614
The XGB AUC on test set is: 0.8654
This is iteration number 83
[08:22:31] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8472
The XGB AUC on test set is: 0.8559
This is iteration number 84
[08:22:52] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8447
The XGB AUC on test set is: 0.8473
This is iteration number 85
[08:23:14] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8681
The XGB AUC on test set is: 0.8727
This is iteration number 86
[08:23:35] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8411
The XGB AUC on test set is: 0.8500
This is iteration number 87
[08:23:56] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8554
The XGB AUC on test set is: 0.8596
This is iteration number 88
[08:24:17] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8485
The XGB AUC on test set is: 0.8505
This is iteration number 89
[08:24:41] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8639
The XGB AUC on test set is: 0.8695
This is iteration number 90
[08:25:03] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8448
The XGB AUC on test set is: 0.8581
This is iteration number 91
[08:25:24] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8406
The XGB AUC on test set is: 0.8537
This is iteration number 92
[08:25:45] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8402
The XGB AUC on test set is: 0.8512
This is iteration number 93
[08:26:06] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8407
The XGB AUC on test set is: 0.8544
This is iteration number 94
[08:26:26] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8536
The XGB AUC on test set is: 0.8673
This is iteration number 95
[08:26:51] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8551
The XGB AUC on test set is: 0.8668
This is iteration number 96
[08:27:13] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8577
The XGB AUC on test set is: 0.8614
This is iteration number 97
[08:27:35] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8626
The XGB AUC on test set is: 0.8704
This is iteration number 98
[08:28:01] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8566
The XGB AUC on test set is: 0.8559
This is iteration number 99
[08:28:22] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8628
The XGB AUC on test set is: 0.8675
This is iteration number 100
[08:28:44] WARNING: ../src/learner.cc:627:
Parameters: { "early_stop" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
The logit AUC on test set is: 0.8539
The XGB AUC on test set is: 0.8601
The final average AUC of XGB is: 0.8535
The final average AUC of Logit is: 0.8611
# Calculate the average FN, FP, TP and TN to later on
# define the confusion matrix
average_fn_logit_05 = sum(fn_logit_05) / float(len(fn_logit_05))
average_fn_logit_10 = sum(fn_logit_10) / float(len(fn_logit_10))
average_fn_logit_20 = sum(fn_logit_20) / float(len(fn_logit_20))
average_fp_logit_05 = sum(fp_logit_05) / float(len(fp_logit_05))
average_fp_logit_10 = sum(fp_logit_10) / float(len(fp_logit_10))
average_fp_logit_20 = sum(fp_logit_20) / float(len(fp_logit_20))
average_fn_xgb_05 = sum(fn_xgb_05) / float(len(fn_xgb_05))
average_fn_xgb_10 = sum(fn_xgb_10) / float(len(fn_xgb_10))
average_fn_xgb_20 = sum(fn_xgb_20) / float(len(fn_xgb_20))
average_fp_xgb_05 = sum(fp_xgb_05) / float(len(fp_xgb_05))
average_fp_xgb_10 = sum(fp_xgb_10) / float(len(fp_xgb_10))
average_fp_xgb_20 = sum(fp_xgb_20) / float(len(fp_xgb_20))
average_tn_logit_05 = sum(tn_logit_05) / float(len(tn_logit_05))
average_tn_logit_10 = sum(tn_logit_10) / float(len(tn_logit_10))
average_tn_logit_20 = sum(tn_logit_20) / float(len(tn_logit_20))
average_tp_logit_05 = sum(tp_logit_05) / float(len(tp_logit_05))
average_tp_logit_10 = sum(tp_logit_10) / float(len(tp_logit_10))
average_tp_logit_20 = sum(tp_logit_20) / float(len(tp_logit_20))
average_tn_xgb_05 = sum(tn_xgb_05) / float(len(tn_xgb_05))
average_tn_xgb_10 = sum(tn_xgb_10) / float(len(tn_xgb_10))
average_tn_xgb_20 = sum(tn_xgb_20) / float(len(tn_xgb_20))
average_tp_xgb_05 = sum(tp_xgb_05) / float(len(tp_xgb_05))
average_tp_xgb_10 = sum(tp_xgb_10) / float(len(tp_xgb_10))
average_tp_xgb_20 = sum(tp_xgb_20) / float(len(tp_xgb_20))
# Create empty bodys for each confusion matrix
cmat_bayes_xgb_05 = np.zeros((2, 2))
cmat_bayes_xgb_10 = np.zeros((2, 2))
cmat_bayes_xgb_20 = np.zeros((2, 2))
cmat_bayes_logit_05 = np.zeros((2, 2))
cmat_bayes_logit_10 = np.zeros((2, 2))
cmat_bayes_logit_20 = np.zeros((2, 2))
# fill the cmats with the average values out of 100 iterations
cmat_bayes_xgb_05[0][0] = average_tp_xgb_05
cmat_bayes_xgb_05[1][0] = average_fp_xgb_05
cmat_bayes_xgb_05[0][1] = average_fn_xgb_05
cmat_bayes_xgb_05[1][1] = average_tn_xgb_05
cmat_bayes_xgb_10[0][0] = average_tp_xgb_10
cmat_bayes_xgb_10[1][0] = average_fp_xgb_10
cmat_bayes_xgb_10[0][1] = average_fn_xgb_10
cmat_bayes_xgb_10[1][1] = average_tn_xgb_10
cmat_bayes_xgb_20[0][0] = average_tp_xgb_20
cmat_bayes_xgb_20[1][0] = average_fp_xgb_20
cmat_bayes_xgb_20[0][1] = average_fn_xgb_20
cmat_bayes_xgb_20[1][1] = average_tn_xgb_20
cmat_bayes_logit_05[0][0] = average_tp_logit_05
cmat_bayes_logit_05[1][0] = average_fp_logit_05
cmat_bayes_logit_05[0][1] = average_fn_logit_05
cmat_bayes_logit_05[1][1] = average_tn_logit_05
cmat_bayes_logit_10[0][0] = average_tp_logit_10
cmat_bayes_logit_10[1][0] = average_fp_logit_10
cmat_bayes_logit_10[0][1] = average_fn_logit_10
cmat_bayes_logit_10[1][1] = average_tn_logit_10
cmat_bayes_logit_20[0][0] = average_tp_logit_20
cmat_bayes_logit_20[1][0] = average_fp_logit_20
cmat_bayes_logit_20[0][1] = average_fn_logit_20
cmat_bayes_logit_20[1][1] = average_tn_logit_20
# Plot Confusion Matrix using Heatmap
plt.rcParams['figure.figsize'] = (24, 10)
import seaborn as sns
fig, ax_lst = plt.subplots(2,3)
cmat_list = [cmat_bayes_logit_05, cmat_bayes_logit_10, cmat_bayes_logit_20,
cmat_bayes_xgb_05, cmat_bayes_xgb_10, cmat_bayes_xgb_20]
csm_types = ["Bayes_logit_05", "Bayes_logit_10", "Bayes_logit_20",
"Bayes_xgb_05", "Bayes_xgb_10", "Bayes_xgb_20"]
for i, j, ax in zip(cmat_list, csm_types, ax_lst.flat):
# Plot heatmap
ax.set_title(j)
sns.heatmap(i, ax=ax, annot=True, fmt='g', cbar=False,
xticklabels=['predicted 0', 'predicted 1'],
yticklabels=['true 0', 'true 1'])
plt.show()

print("Logit:")
print("The error cost for the 1:5 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_logit_05*(cost_matrix_05.T)))))
print("The error cost for the 1:10 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_logit_10*(cost_matrix_10.T)))))
print("The error cost for the 1:20 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_logit_20*(cost_matrix_20.T)))))
print("XGBoost:")
print("The error cost for the 1:5 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_xgb_05*(cost_matrix_05.T)))))
print("The error cost for the 1:10 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_xgb_10*(cost_matrix_10.T)))))
print("The error cost for the 1:20 bayes cutoff is: {}".\
format(np.sum(np.sum(cmat_bayes_xgb_20*(cost_matrix_20.T)))))
Logit: The error cost for the 1:5 bayes cutoff is: 1915.96 The error cost for the 1:10 bayes cutoff is: 3622.01 The error cost for the 1:20 bayes cutoff is: 6623.960000000001 XGBoost: The error cost for the 1:5 bayes cutoff is: 1930.0699999999997 The error cost for the 1:10 bayes cutoff is: 3631.82 The error cost for the 1:20 bayes cutoff is: 6550.580000000001
While the credit risk model framework presented above is successful in relaxing the initial performance-interpretability-tradeoff, it still has several limitations which should be addressed by future research: Firstly, the model does not include any macroeconomic and systemic explanatory variables which might be relevant and might help to increase predictive performance (Uddin et al. 2020; Altinbas and Akkaya 2017; Hu et al. 2021; Xia et al. 2020). Secondly, the predictive power of credit risk models may be adversely affected by the widely accepted fact that credit applications can actively influence the parameters on the basis of which banks make their predictions in order to appear more creditworthy. For instance, as explained by Lipton (2016), credit seekers may seemingly “improve” their debt ratio by “simply […] requesting periodic increases to credit lines while keeping spending patterns constant”. Providers of credit ratings such as FICO even openly advise credit applicants on how to improve their score.(Lipton 2016) Moreover, as has been demonstrated above, there is severe concern about model stability. Given the fact that financial intermediaries play a significant role in our financial system, this is particularly worrying. In the case of Freddie Mac, this became painfully clear during the financial crisis of 2007/2008, when Freddie Mac (together with Fanny Mae) was taken under conservatorship by the Federal Housing Finance Agency (Lockhart 9/7/2008) to prevent the institutions from failing after having accumulated losses amounting to $5.2 trillion of home mortgage debt in total.(Frame et al. 2015) In addition, the data’s high imbalance and dimensionality is likely to have complicated the analysis and exacerbated stability concerns. This issue, however, is far from a theoretical concern, but should rather be seen as a real-life problem when dealing with credit risk data. Further research should hence focus on finding ways to improve stability, especially in the presence of highly imbalanced and high dimensional data. In conclusion, this analysis shows the potential of machine learning in the credit risk domain, but at the same time indicates that the application of these methods in the real world should be evaluated with caution.
💡 Altinbas, Hazar; Akkaya, Goktug Cenk (2017): Improving the performance of statistical learning methods with a combined meta-heuristic for consumer credit risk assessment. In Risk Manag 19 (4), pp. 255–280. DOI: 10.1057/s41283-017-0021-0.
💡 Baesens, Bart; Setiono, Rudy; Mues, Christophe; Vanthienen, Jan (2003): Using Neural Network Rule Extraction and Decision Tables for Credit-Risk Evaluation. In Management Science 49 (3), pp. 312–329. DOI: 10.1287/mnsc.49.3.312.12739.
💡Basel Committee on Banking Supervision (2004): International Convergence of Capital Measurement and Capital Standards. A Revised Framework.
💡Borisov, Vadim; Leemann, Tobias; Seßler, Kathrin; Haug, Johannes; Pawelczyk, Martin; Kasneci, Gjergji (2021): Deep Neural Networks and Tabular Data: A Survey. Available online at http://arxiv.org/pdf/2110.01889v3.
💡 Bureau of Consumer Financial Protection (2011): Equal Credit Opportunity Act (Regulation B), Part 1002. Source: 12 U.S.C. 5512, 5581; 15 U.S.C. 1691b. In : 76 FR 79445.
💡 Bussmann, Niklas; Giudici, Paolo; Marinelli, Dimitri; Papenbrock, Jochen (2019): Explainable AI in Credit Risk Management. In SSRN Journal. DOI: 10.2139/ssrn.3506274.
💡 Bussmann, Niklas; Giudici, Paolo; Marinelli, Dimitri; Papenbrock, Jochen (2021): Explainable Machine Learning in Credit Risk Management. In Comput Econ 57 (1), pp. 203–216. DOI: 10.1007/s10614-020-10042-0.
💡 Charles Elkan (2001): The Foundations of Cost-Sensitive Learning. Available online at https://www.researchgate.net/publication/2365611_The_Foundations_of_Cost-Sensitive_Learning.
💡 Consumer Financial Protection Bureau (2022): CFPB Circular 2022-03. Available online at https://files.consumerfinance.gov/f/documents/cfpb_2022-03_circular_2022-05.pdf, checked on 7/2/2022.
💡 David Cournapeau (2022): scikit-learn. Machine Learning in Python. With assistance of Jérémie du Boisberranger, Joris Van den Bossche,Loïc Estève,Thomas J. Fan, Alexandre Gramfort, Olivier Grisel, Yaroslav Halchenko, Nicolas Hug. scikitlearnofficial. Available online at https://scikit-learn.org/stable/, updated on May 2022.
💡 Davidson, Russell; MacKinnon, James G. (2004): Econometric theory and methods. New York, NY: Oxford Univ. Press.
💡 Demajo, Lara Marie; Vella, Vince; Dingli, Alexiei (2021): An Explanation Framework for Interpretable Credit Scoring. In IJAIA 12 (1), pp. 19–38. DOI: 10.5121/ijaia.2021.12102.
💡 Deutsche Bundesbank; BaFin (2021): Consultation paper: Machine learning in risk models – Characteristics and supervisory priorities.
💡 Deutsche Bundesbank; BaFin (2022): Machine learning in risk models – Characteristics and supervisory priorities.
💡 Dumitrescu, Elena; Hué, Sullivan; Hurlin, Christophe; Tokpavi, Sessi (2022): Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. In European Journal of Operational Research 297 (3), pp. 1178–1192. DOI: 10.1016/j.ejor.2021.06.053.
💡 E. Hoerl, Robert W. Kennard (1970): Ridge Regression: Biased Estimation for Nonorthogonal Problems, Technometrics. Available online at https://doi.org/10.1080/.
💡 Emad Azhar Ali, Syed; Sajjad Hussain Rizvi, Syed; Lai, Fong-Woon; Faizan Ali, Rao; Ali Jan, Ahmad (2021): Predicting Delinquency on Mortgage Loans: An Exhaustive Parametric Comparison of Machine Learning Techniques. In Int J Ind Eng Manag Volume 12 (Issue 1), pp. 1–13. DOI: 10.24867/IJIEM-2021-1-272.
💡 European Commission (2022): Data protection in the EU. Available online at https://ec.europa.eu/info/law/law-topic/data-protection/data-protection-eu_en, updated on 6/7/2022, checked on 6/21/2022.
💡 European Parliament and the Council (2016): REGULATION (EU) 2016/ 679 - on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/ 46/ EC (General Data Protection Regulation).
💡 European Union (2012): Charter of Fundamental Rights of the European Union, revised C 326/02. Available online at https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:12012P/TXT, checked on 6/21/2022.
💡 Federal Housing Finance Agency (2013): HARP: Your best route to a better mortgage. Available online at https://web.archive.org/web/20130924120848/https://www.harp.gov/, updated on 10/4/2013, checked on 7/13/2022.
💡 Federal Housing Finance Agency (2022): About Fannie Mae & Freddie Mac | Federal Housing Finance Agency. Available online at https://www.fhfa.gov/about-fannie-mae-freddie-mac, updated on 7/3/2022, checked on 7/3/2022.
💡 Frame, W. Scott; Fuster, Andreas; Tracy, Joseph; Vickery, James (2015): The Rescue of Fannie Mae and Freddie Mac. In Journal of Economic Perspectives 29 (2), pp. 25–52. DOI: 10.1257/jep.29.2.25.
💡 Freddie Mac (2021): Single Family Loan-Level Dataset. Available online at https://www.freddiemac.com/research/datasets/sf-loanlevel-dataset, updated on 7/2/2022, checked on 7/3/2022.
💡 Freddie Mac (2022a): About Freddie Mac. Available online at https://www.freddiemac.com/about, updated on 7/2/2022, checked on 7/3/2022.
💡 Freddie Mac (2022b): Single Family Loan-Level Dataset Frequently Asked Questions (FAQs).
💡 Freddie Mac (2022c): Single-Family Loan-Level Dataset General User Guide.
💡 Friedman, Jerome H. (2001): Greedy Function Approximation: A Gradient Boosting Machine. 1999 Reitz Lecture. In The Annals of Statistics 29 (5), pp. 1189–1232.
💡 Goodman, Bryce; Flaxman, Seth (2017): European Union regulations on algorithmic decision-making and a "right to explanation". In AIMag 38 (3), pp. 50–57. DOI: 10.1609/aimag.v38i3.2741.
💡 Hall, Patrick; Gill, Navdeep (2019): An Introduction to Machine Learning Interpretability. An Applied Perspective on Fairness, Accountability, Transparency, and Explainable AI. 2nd: O'Reilly Media, Inc. Available online at https://www.oreilly.com/library/view/an-introduction-to/9781098115487/.
💡Hayashi, Yoichi (2016): Application of a rule extraction algorithm family based on the Re-RX algorithm to financial credit risk assessment from a Pareto optimal perspective. In Operations Research Perspectives 3, pp. 32–42. DOI: 10.1016/j.orp.2016.08.001.
💡 Hu, Linwei; Chen, Jie; Vaughan, Joel; Aramideh, Soroush; Yang, Hanyu; Wang, Kelly et al. (2021): Supervised Machine Learning Techniques: An Overview with Applications to Banking. In International Statistical Review 89 (3), pp. 573–604. DOI: 10.1111/insr.12448.
💡 Kao, Ling-Jing; Chiu, Chih-Chou; Chiu, Fon-Yu (2012): A Bayesian latent variable model with classification and regression tree approach for behavior and credit scoring. In Knowledge-Based Systems 36, pp. 245–252. DOI: 10.1016/j.knosys.2012.07.004.
💡 Li, Wei; Ding, Shuai; Wang, Hao; Chen, Yi; Yang, Shanlin (2020): Heterogeneous ensemble learning with feature engineering for default prediction in peer-to-peer lending in China. In World Wide Web 23 (1), pp. 23–45. DOI: 10.1007/s11280-019-00676-y.
💡 Lipton, Zachary C. (2016): The Mythos of Model Interpretability. Available online at http://arxiv.org/pdf/1606.03490v3.
💡 Liu, Wan’an; Fan, Hong; Xia, Min (2022): Multi-grained and multi-layered gradient boosting decision tree for credit scoring. In Appl Intell 52 (5), pp. 5325–5341. DOI: 10.1007/s10489-021-02715-6.
💡 Lockhart, James B. (9/7/2008): Statement of FHFA Director James B. Lockhart. Federal Housing Finance Agency.
💡 Lundberg, Scott; Lee, Su-In (2017): A Unified Approach to Interpreting Model Predictions. Available online at http://arxiv.org/pdf/1705.07874v2.
💡 Lundberg, Scott M.; Erion, Gabriel; Chen, Hugh; DeGrave, Alex; Prutkin, Jordan M.; Nair, Bala et al. (2020): From local explanations to global understanding with explainable AI for trees. In Nature Machine Intelligence (2), pp. 56–67. Available online at https://www.nature.com/articles/s42256-019-0138-9.
💡 Molnar, Christoph (2022): Interpretable Machine Learning. Available online at https://christophm.github.io/interpretable-ml-book/.
💡 Ribeiro, Marco; Singh, Sameer; Guestrin, Carlos (2016): “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, pp. 97–101. DOI: 10.18653/v1/N16-3020.
💡 Ribeiro, Marco Tulio; Singh, Sameer; Guestrin, Carlos (2018): Anchors: High Precision Model-Agnostic Explanations. In AAAI.
💡 Robert Samoilescu (2018): Alibi. Available online at https://github.com/SeldonIO/alibi, updated on 7/20/2022.
💡 Scott Lundberg (2017): SHAP (0.41.0). Available online at https://github.com/slundberg/shap, updated on 1/16/2022.
💡 Shapley, L. S. (1953): 17. A Value for n-Person Games. In Harold William Kuhn, Albert William Tucker (Eds.): Contributions to the Theory of Games (AM-28), Volume II: Princeton University Press, pp. 307–318.
💡 Steenackers, A.; Goovaerts, M. J. (1989): A credit scoring model for personal loans. In Insurance: Mathematics and Economics 8 (1), pp. 31–34. DOI: 10.1016/0167-6687(89)90044-9.
💡 Uddin, Mohammad S.; Chi, Guotai; Al Janabi, Mazin A. M.; Habib, Tabassum (2020): Leveraging random forest in micro‐enterprises credit risk modelling for accuracy and interpretability. In Int. J Fin Econ, Article ijfe.2346. DOI: 10.1002/ijfe.2346.
💡 Visani, Giorgio; Bagli, Enrico; Chesani, Federico; Poluzzi, Alessandro; Capuzzo, Davide (2022): Statistical stability indices for LIME: obtaining reliable explanations for Machine Learning models. In Journal of the Operational Research Society 73 (1), pp. 91–101. DOI: 10.1080/01605682.2020.1865846.
💡 West, David (2000): Neural network credit scoring models. In Computers & Operations Research 27 (11-12), pp. 1131–1152. DOI: 10.1016/S0305-0548(99)00149-5.
💡 William H. Greene (2003): Econometric Analysis. 5th Edition: Pearson Education, Inc.
💡 xgboost developers (2021): XGBoost. With assistance of Andrew Ziem, Philip Hyunsu Cho, Jiaming Yuan. Available online at https://xgboost.readthedocs.io/en/stable/python/python_intro.html, updated on 12/16/2021.
💡 Xia, Yufei; He, Lingyun; Li, Yinguo; Fu, Yating; Xu, Yixin (2020): A DYNAMIC CREDIT SCORING MODEL BASED ON SURVIVAL GRADIENT BOOSTING DECISION TREE APPROACH. In Technological and Economic Development of Economy 27 (1), pp. 96–119. DOI: 10.3846/tede.2020.13997.
💡 Young, H. P. (1985): Monotonic solutions of cooperative games. In Int J Game Theory 14 (2), pp. 65–72. DOI: 10.1007/BF01769885.
💡 Yuan, Han; Liu, Mingxuan; Kang, Lican; Miao, Chenkui; Wu, Ying (2022): An empirical study of the effect of background data size on the stability of SHapley Additive exPlanations (SHAP) for deep learning models.
❌Disclaimer, the following section has a very long runtime (> 20 hours), therefore it is all commented. The results of the analysis can be seen in the Resuls section.
# Additional libraries needed
from __future__ import print_function
import torch
import math
import collections
import statistics
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number
# # in each background dataset
# # In our example, x=100 and y=0, which means 100 background datasets
# # will be used.
# # In each background dataset, there are 0 samples
# # Create empty lists to save results later
# orderlist0 = []
# shaplist0 = []
# shaplistsum0 = []
# # i here stands for the simulation times: 100
# # The “tree_path_dependent” approach is to just follow the trees and use the
# # number of training examples that went down each leaf to represent the
# # background distribution.
# for i in range(1, 101):
# # Calculate SHAP with tree_path_dependent approach
# e = shap.TreeExplainer(xgb_tuned, data=None,
# feature_perturbation='tree_path_dependent',
# model_output='raw')
# shap_values = e.shap_values(X_test_scaled)
# shaplist0.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_0_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum0.append(shap_0_sum)
# order_0 = np.argsort(-shap_0_sum) + 1
# orderlist0.append(order_0)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum0.csv', shaplistsum0, delimiter=',')
# np.savetxt('orderlist0.csv', orderlist0, delimiter=',')
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number
# # in each background dataset
# # In our example, x=100 and y=50, which means 100 background datasets
# # will be used.
# # In each background dataset, there are 50 samples
# # Create empty lists to save results later
# orderlist1 = []
# shaplist1 = []
# shaplistsum1 = []
# # i here stands for the simulation times: 100
# # In this loop, 50 samples from train dataset will be randomly extracted as
# # the background dataset
# # Based on each background dataset, calculate the SHAP values and global
# # ranking for following stability evaluation
# for i in range(1, 101):
# # With a given seed, the sample will always draw the same rows.
# # If random_state is None or np.random, then a randomly-initialized
# # RandomState object is returned.
# # Select 50 samples from train data randomly as the background data
# sample = X_train_scaled.sample(n=50, random_state=i)
# e = shap.TreeExplainer(xgb_tuned, data=sample,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist1.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_1_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum1.append(shap_1_sum)
# order_1 = np.argsort(-shap_1_sum) + 1
# orderlist1.append(order_1)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum1.csv', shaplistsum1, delimiter=',')
# np.savetxt('orderlist1.csv', orderlist1, delimiter=',')
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number in each
# # background dataset
# # In our example, x=100 and y=500, which means 100 background
# datasets will be used.
# # In each background dataset, there are 500 samples
# # Create empty lists to save results later
# orderlist2 = []
# shaplist2 = []
# shaplistsum2 = []
# # i here stands for the simulation times: 100
# # In this loop, 500 samples from train dataset will be randomly extracted
# # as the background dataset
# # Based on each background dataset, calculate the SHAP values and global
# # ranking for following stability evaluation
# for i in range(1, 101):
# # With a given seed, the sample will always draw the same rows.
# # If random_state is None or np.random, then a randomly-initialized
# # RandomState object is returned.
# # Select 500 samples from train data randomly as the background data
# sample = X_train_scaled.sample(n=500, random_state=i)
# e = shap.TreeExplainer(xgb_tuned, data=sample,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist2.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_2_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum2.append(shap_2_sum)
# order_2 = np.argsort(-shap_2_sum) + 1
# orderlist2.append(order_2)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum2.csv', shaplistsum2, delimiter=',')
# np.savetxt('orderlist2.csv', orderlist2, delimiter=',')
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number in
# # each background dataset
# # In our example, x=100 and y=1500, which means 100 background
# # datasets will be used.
# # In each background dataset, there are 1500 samples
# # Create empty lists to save results later
# orderlist3 = []
# shaplist3 = []
# shaplistsum3 = []
# # i here stands for the simulation times: 100
# # In this loop, 1500 samples from train dataset will be randomly extracted
# # as the background dataset
# # Based on each background dataset, calculate the SHAP values and global
# # ranking for following stability evaluation
# for i in range(1, 101):
# # With a given seed, the sample will always draw the same rows.
# # If random_state is None or np.random, then a randomly-initialized
# # RandomState object is returned.
# # Select 1500 samples from train data randomly as the background data
# sample = X_train_scaled.sample(n=1500, random_state=i)
# e = shap.TreeExplainer(xgb_tuned, data=sample,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist3.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_3_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum3.append(shap_3_sum)
# order_3 = np.argsort(-shap_3_sum) + 1
# orderlist3.append(order_3)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum3.csv', shaplistsum3, delimiter=',')
# np.savetxt('orderlist3.csv', orderlist3, delimiter=',')
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number in
# # each background dataset
# # In our example, x=100 and y=15000, which means 100 background
# # datasets will be used.
# # In each background dataset, there are 15000 samples
# # Create empty lists to save results later
# orderlist4 = []
# shaplist4 = []
# shaplistsum4 = []
# # i here stands for the simulation times: 100
# # In this loop, 15000 samples from train dataset will be randomly
# # extracted as the background dataset
# # Based on each background dataset, calculate the SHAP values and global
# # ranking for following stability evaluation
# for i in range(1, 101):
# # With a given seed, the sample will always draw the same rows.
# # If random_state is None or np.random, then a randomly-initialized
# # RandomState object is returned.
# # Select 15000 samples from train data randomly as the background data
# sample = X_train_scaled.sample(n=15000, random_state=i)
# e = shap.TreeExplainer(xgb_tuned, data=sample,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist4.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_4_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum4.append(shap_4_sum)
# order_4 = np.argsort(-shap_4_sum) + 1
# orderlist4.append(order_4)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum4.csv', shaplistsum4, delimiter=',')
# np.savetxt('orderlist4.csv', orderlist4, delimiter=',')
# # Calculate SHAP values and global variable rankings under each
# # background dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number in
# # each background dataset
# # In our example, x=100 and y=75000, which means 100 background
# # datasets will be used.
# # In each background dataset, there are 75000 samples
# # Create empty lists to save results later
# orderlist5 = []
# shaplist5 = []
# shaplistsum5 = []
# # i here stands for the simulation times: 100
# # In this loop, 75000 samples from train dataset will be randomly extracted
# # as the background dataset
# # Based on each background dataset, calculate the SHAP values and global
# # ranking for following stability evaluation
# for i in range(1, 101):
# # With a given seed, the sample will always draw the same rows.
# # If random_state is None or np.random, then a randomly-initialized
# # RandomState object is returned.
# # Select 75000 samples from train data randomly as the background data
# sample = X_train_scaled.sample(n=75000, random_state=i)
# e = shap.TreeExplainer(xgb_tuned, data=sample,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist5.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_5_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum5.append(shap_5_sum)
# order_5 = np.argsort(-shap_5_sum) + 1
# orderlist5.append(order_5)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum5.csv', shaplistsum5, delimiter=',')
# np.savetxt('orderlist5.csv', orderlist5, delimiter=',')
# # Calculate SHAP values and global variable rankings under each background
# # dataset
# # Background datasets are named as x repetition sample size y
# # x stands for the simulation times and y means the sample number
# # in each background dataset
# # In our example, x=100 and y=~150000, which means 100 background
# # datasets will be used.
# # In each background dataset, there are ~150000 samples
# # Create empty lists to save results afterwards
# orderlist6 = []
# shaplist6 = []
# shaplistsum6 = []
# # i here stands for the simulation times: 100
# # In this loop, the whole training data is used as background dataset
# # Based on the background dataset, calculate the SHAP values and global ranking
# # for following stability evaluation
# for i in range(1, 101):
# # Calculate SHAP with whole training data as background data
# e = shap.TreeExplainer(xgb_tuned, data=X_train_scaled,
# feature_perturbation='interventional',
# model_output='probability')
# shap_values = e.shap_values(X_test_scaled)
# shaplist6.append(shap_values)
# # Calculate the SHAP values of all samples in the test dataset
# # Add the absolute values together to get the feature importance rankings
# shap_6_sum = np.absolute(shap_values).sum(axis=0)
# shaplistsum6.append(shap_6_sum)
# order_6 = np.argsort(-shap_6_sum) + 1
# orderlist6.append(order_6)
# print("background dataset "+str(i)+" has been processed")
# np.savetxt('SHAP_sum6.csv', shaplistsum6, delimiter=',')
# np.savetxt('orderlist6.csv', orderlist6, delimiter=',')
The first table is this section shows the global feature importance ranking for 100 simulations using different background data sizes. The rows represent the ranking from the highest global feature importance (Ranking = 1) to the lowest global feature importance (Ranking = 83). The columns represent the different approaches. For each sample size, we simulate 100 random draws from the training data with the same parameters to see whether we get consistent results. The table shows all possible features which got assigned the specific ranking in at least one iteration.
When using no background data and just the tree path dependent approach explained earlier, as well as using the whole training dataset, we get the same ranking for all 100 simulations, so there is no variation in the ranking. When using different sample sizes as background data randomly drawn from the training data, we see for the most and the least important features some variation (~ 3 unique values for the rankings 1-5 and rankings 79-83) while we observe much more variation in the middle with many more unique values for each possible ranking position.
The results suggest that users should take into account how background data affects SHAP results, and therefore test the stability of their used approach before using it to interpret their model.
# reading orderlist data
file = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/final_data_var.csv'
final_data_var = pd.read_csv(file, sep=',', index_col = 'features')
file = 'https://raw.githubusercontent.com/Group2Interpretability/\
APA_Interpretability/main/Input/final_order.csv'
final_order = pd.read_csv(file, sep=',', index_col='Ranking of \
Feature (from most to least important)')
# producing the final order table
with pd.option_context('display.max_rows', None,
'display.max_columns', None):
display(final_order.style.set_properties(**{'text-align': 'left'})\
.set_table_styles([dict(selector='th',
props=[('text-align', 'left')])]))
print("-----------------------------------------------------------------------")
print("Table 4: Ranking Variation over 100 SHAP iterations.")
| Possible Rankings with m=none | Possible Rankings with m=50 | Possible Rankings with m=500 | Possible Rankings with m=1500 | Possible Rankings with m=15000 | Possible Rankings with m=75000 | Possible Rankings with m=all | |
|---|---|---|---|---|---|---|---|
| Ranking of Feature (from most to least important) | |||||||
| 1 | ['fico'] | ['fico' 'servicer_name_Other servicers'] | ['fico' 'servicer_name_Other servicers'] | ['servicer_name_Other servicers' 'fico'] | ['fico' 'servicer_name_Other servicers'] | ['servicer_name_Other servicers' 'fico'] | ['servicer_name_Other servicers'] |
| 2 | ['servicer_name_Other servicers'] | ['servicer_name_Other servicers' 'fico' 'seller_name_WELLS FARGO BANK, N.'] | ['servicer_name_Other servicers' 'fico'] | ['fico' 'servicer_name_Other servicers'] | ['servicer_name_Other servicers' 'fico'] | ['fico' 'servicer_name_Other servicers'] | ['fico'] |
| 3 | ['cnt_borr'] | ['cnt_borr' 'seller_name_WELLS FARGO BANK, N.' 'fico' 'cltv_pct'] | ['cnt_borr' 'seller_name_WELLS FARGO BANK, N.'] | ['cnt_borr' 'seller_name_WELLS FARGO BANK, N.'] | ['cnt_borr' 'seller_name_WELLS FARGO BANK, N.'] | ['seller_name_WELLS FARGO BANK, N.' 'cnt_borr'] | ['cnt_borr'] |
| 4 | ['cltv_pct'] | ['cltv_pct' 'seller_name_WELLS FARGO BANK, N.' 'cnt_borr' 'seller_name_CALIBER HOME LOANS, '] | ['cltv_pct' 'seller_name_WELLS FARGO BANK, N.' 'cnt_borr'] | ['seller_name_WELLS FARGO BANK, N.' 'cltv_pct' 'cnt_borr' 'seller_name_CALIBER HOME LOANS, '] | ['cltv_pct' 'cnt_borr' 'seller_name_WELLS FARGO BANK, N.' 'seller_name_CALIBER HOME LOANS, '] | ['cnt_borr' 'cltv_pct' 'seller_name_WELLS FARGO BANK, N.'] | ['seller_name_WELLS FARGO BANK, N.'] |
| 5 | ['dti_pct'] | ['seller_name_WELLS FARGO BANK, N.' 'cltv_pct' 'dti_pct' 'int_rt_pct' 'st_FL'] | ['seller_name_WELLS FARGO BANK, N.' 'cltv_pct' 'int_rt_pct' 'dti_pct' 'st_FL'] | ['cltv_pct' 'seller_name_WELLS FARGO BANK, N.' 'int_rt_pct' 'dti_pct' 'st_FL'] | ['seller_name_WELLS FARGO BANK, N.' 'cltv_pct' 'st_FL' 'dti_pct'] | ['cltv_pct' 'seller_name_WELLS FARGO BANK, N.' 'dti_pct' 'st_FL'] | ['cltv_pct'] |
| 6 | ['int_rt_pct'] | ['dti_pct' 'int_rt_pct' 'st_FL' 'seller_name_WELLS FARGO BANK, N.' 'cltv_pct'] | ['dti_pct' 'int_rt_pct' 'st_FL' 'orig_upb' 'seller_name_WELLS FARGO BANK, N.' 'seller_name_CALIBER HOME LOANS, '] | ['dti_pct' 'int_rt_pct' 'st_FL' 'seller_name_WELLS FARGO BANK, N.' 'seller_name_CALIBER HOME LOANS, '] | ['int_rt_pct' 'dti_pct' 'cltv_pct'] | ['dti_pct' 'int_rt_pct' 'seller_name_WELLS FARGO BANK, N.' 'st_FL' 'cltv_pct'] | ['dti_pct'] |
| 7 | ['seller_name_WELLS FARGO BANK, N.'] | ['int_rt_pct' 'dti_pct' 'seller_name_WELLS FARGO BANK, N.' 'st_FL'] | ['int_rt_pct' 'dti_pct' 'seller_name_U.S. BANK N.A.' 'seller_name_WELLS FARGO BANK, N.' 'st_FL'] | ['int_rt_pct' 'dti_pct' 'seller_name_U.S. BANK N.A.' 'st_FL' 'seller_name_WELLS FARGO BANK, N.' 'cltv_pct'] | ['dti_pct' 'int_rt_pct' 'st_FL' 'seller_name_WELLS FARGO BANK, N.'] | ['int_rt_pct' 'seller_name_WELLS FARGO BANK, N.' 'st_FL' 'dti_pct'] | ['int_rt_pct'] |
| 8 | ['loan_purpose_P'] | ['st_FL' 'loan_purpose_P' 'int_rt_pct' 'dti_pct' 'orig_loan_term' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.'] | ['st_FL' 'loan_purpose_P' 'seller_name_U.S. BANK N.A.' 'orig_loan_term' 'int_rt_pct' 'dti_pct' 'seller_name_CALIBER HOME LOANS, ' 'pre_relief_prog_N'] | ['st_FL' 'loan_purpose_P' 'int_rt_pct' 'seller_name_WELLS FARGO BANK, N.' 'dti_pct' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'seller_name_Other sellers'] | ['st_FL' 'loan_purpose_P' 'seller_name_U.S. BANK N.A.' 'int_rt_pct' 'dti_pct' 'orig_loan_term'] | ['st_FL' 'loan_purpose_P' 'int_rt_pct' 'orig_loan_term' 'seller_name_U.S. BANK N.A.' 'orig_upb' 'seller_name_CALIBER HOME LOANS, '] | ['st_FL'] |
| 9 | ['st_FL'] | ['seller_name_Other sellers' 'st_FL' 'loan_purpose_P' 'orig_loan_term' 'orig_upb' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'dti_pct'] | ['loan_purpose_P' 'st_FL' 'seller_name_U.S. BANK N.A.' 'seller_name_Other sellers' 'orig_upb' 'pre_relief_prog_N' 'dti_pct' 'orig_loan_term'] | ['loan_purpose_P' 'st_FL' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_Other sellers' 'orig_loan_term' 'pre_relief_prog_N' 'int_rt_pct'] | ['loan_purpose_P' 'orig_upb' 'st_FL' 'orig_loan_term' 'seller_name_Other sellers' 'int_rt_pct' 'seller_name_U.S. BANK N.A.'] | ['loan_purpose_P' 'seller_name_Other sellers' 'orig_upb' 'st_FL' 'pre_relief_prog_N' 'dti_pct' 'orig_loan_term'] | ['loan_purpose_P'] |
| 10 | ['servicer_name_JPMORGAN CHASE BAN'] | ['loan_purpose_P' 'orig_upb' 'seller_name_Other sellers' 'orig_loan_term' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_CALIBER HOME LOANS, ' 'pre_relief_prog_N' 'st_FL' 'pgrm_ind_Y'] | ['orig_upb' 'orig_loan_term' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_Other sellers' 'st_FL' 'loan_purpose_P' 'pre_relief_prog_N' 'mi_pct'] | ['orig_upb' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_Other sellers' 'orig_loan_term' 'loan_purpose_P' 'pre_relief_prog_N' 'st_FL'] | ['seller_name_Other sellers' 'orig_upb' 'orig_loan_term' 'seller_name_CALIBER HOME LOANS, ' 'loan_purpose_P' 'pre_relief_prog_N' 'st_FL' 'servicer_name_JPMORGAN CHASE BAN'] | ['orig_loan_term' 'seller_name_Other sellers' 'orig_upb' 'servicer_name_JPMORGAN CHASE BAN' 'loan_purpose_P' 'st_FL' 'pre_relief_prog_N' 'pgrm_ind_Y' 'mi_pct'] | ['seller_name_Other sellers'] |
| 11 | ['orig_loan_term'] | ['pre_relief_prog_N' 'orig_loan_term' 'orig_upb' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_Other sellers' 'st_FL' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'pgrm_ind_Y' 'loan_purpose_P'] | ['seller_name_Other sellers' 'orig_upb' 'servicer_name_JPMORGAN CHASE BAN' 'orig_loan_term' 'pre_relief_prog_N' 'st_FL' 'loan_purpose_P' 'seller_name_CALIBER HOME LOANS, '] | ['orig_loan_term' 'seller_name_Other sellers' 'orig_upb' 'mi_pct' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_U.S. BANK N.A.' 'st_FL' 'pgrm_ind_Y'] | ['orig_loan_term' 'st_FL' 'orig_upb' 'seller_name_Other sellers' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'mi_pct'] | ['seller_name_Other sellers' 'orig_upb' 'orig_loan_term' 'st_FL' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.'] | ['orig_upb'] |
| 12 | ['seller_name_Other sellers'] | ['orig_upb' 'seller_name_U.S. BANK N.A.' 'pgrm_ind_Y' 'mi_pct' 'seller_name_Other sellers' 'orig_loan_term' 'servicer_name_JPMORGAN CHASE BAN' 'loan_purpose_P' 'st_FL' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N'] | ['orig_loan_term' 'seller_name_Other sellers' 'mi_pct' 'orig_upb' 'pre_relief_prog_N' 'st_FL' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_U.S. BANK N.A.' 'pgrm_ind_Y'] | ['seller_name_Other sellers' 'orig_loan_term' 'pre_relief_prog_N' 'orig_upb' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'st_FL' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'pgrm_ind_Y'] | ['orig_upb' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_Other sellers' 'orig_loan_term' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'pgrm_ind_Y'] | ['orig_upb' 'orig_loan_term' 'st_FL' 'seller_name_Other sellers' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'pgrm_ind_Y'] | ['orig_loan_term'] |
| 13 | ['orig_upb'] | ['mi_pct' 'pgrm_ind_Y' 'servicer_name_JPMORGAN CHASE BAN' 'orig_upb' 'orig_loan_term' 'seller_name_U.S. BANK N.A.' 'seller_name_Other sellers' 'st_WA' 'pre_relief_prog_N' 'servicer_name_WELLS FARGO BANK, ' 'st_FL' 'seller_name_CALIBER HOME LOANS, '] | ['mi_pct' 'seller_name_Other sellers' 'seller_name_CALIBER HOME LOANS, ' 'orig_loan_term' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'orig_upb' 'pgrm_ind_Y' 'st_FL'] | ['mi_pct' 'orig_loan_term' 'orig_upb' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_Other sellers' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'st_FL' 'servicer_name_QUICKEN LOANS INC.'] | ['pre_relief_prog_N' 'orig_loan_term' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'orig_upb' 'pgrm_ind_Y' 'seller_name_Other sellers' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'st_FL'] | ['pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_JPMORGAN CHASE BAN' 'pgrm_ind_Y' 'seller_name_Other sellers' 'orig_upb' 'orig_loan_term' 'mi_pct' 'prop_type_SF'] | ['pre_relief_prog_N'] |
| 14 | ['mi_pct'] | ['orig_loan_term' 'seller_name_Other sellers' 'servicer_name_JPMORGAN CHASE BAN' 'st_CA' 'pre_relief_prog_N' 'mi_pct' 'orig_upb' 'st_FL' 'pgrm_ind_Y' 'servicer_name_WELLS FARGO BANK, ' 'rel_ref_ind' 'seller_name_CALIBER HOME LOANS, ' 'prop_type_SF' 'seller_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.'] | ['pre_relief_prog_N' 'pgrm_ind_Y' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_U.S. BANK N.A.' 'orig_upb' 'prop_type_SF' 'orig_loan_term' 'seller_name_CALIBER HOME LOANS, ' 'st_FL' 'seller_name_Other sellers'] | ['pgrm_ind_Y' 'servicer_name_JPMORGAN CHASE BAN' 'mi_pct' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'orig_upb' 'prop_type_SF' 'orig_loan_term' 'seller_name_Other sellers'] | ['servicer_name_JPMORGAN CHASE BAN' 'orig_loan_term' 'pgrm_ind_Y' 'mi_pct' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.'] | ['mi_pct' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN' 'prop_type_SF' 'pgrm_ind_Y' 'orig_loan_term' 'seller_name_U.S. BANK N.A.' 'orig_upb' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_Other sellers'] | ['servicer_name_JPMORGAN CHASE BAN'] |
| 15 | ['prop_type_SF'] | ['pgrm_ind_Y' 'mi_pct' 'orig_loan_term' 'prop_type_SF' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'st_CA' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_Other sellers' 'servicer_name_TRUIST BANK' 'seller_name_CALIBER HOME LOANS, ' 'orig_upb' 'channel_R' 'st_FL' 'rel_ref_ind'] | ['pgrm_ind_Y' 'seller_name_CALIBER HOME LOANS, ' 'mi_pct' 'pre_relief_prog_N' 'prop_type_SF' 'servicer_name_JPMORGAN CHASE BAN' 'orig_loan_term' 'seller_name_U.S. BANK N.A.' 'servicer_name_WELLS FARGO BANK, ' 'orig_upb' 'st_Other' 'rel_ref_ind'] | ['servicer_name_WELLS FARGO BANK, ' 'pgrm_ind_Y' 'pre_relief_prog_N' 'orig_loan_term' 'mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'prop_type_SF' 'rel_ref_ind' 'st_CA'] | ['mi_pct' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'pgrm_ind_Y' 'prop_type_SF' 'orig_loan_term' 'seller_name_U.S. BANK N.A.' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_QUICKEN LOANS INC.'] | ['servicer_name_JPMORGAN CHASE BAN' 'pgrm_ind_Y' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'mi_pct' 'servicer_name_WELLS FARGO BANK, ' 'rel_ref_ind' 'prop_type_SF' 'st_CA' 'orig_loan_term' 'st_Other'] | ['mi_pct'] |
| 16 | ['pre_relief_prog_N'] | ['rel_ref_ind' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'pre_relief_prog_N' 'pgrm_ind_Y' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_U.S. BANK N.A.' 'orig_loan_term' 'seller_name_CALIBER HOME LOANS, ' 'prop_type_SF' 'mi_pct' 'channel_R' 'orig_upb'] | ['servicer_name_JPMORGAN CHASE BAN' 'servicer_name_WELLS FARGO BANK, ' 'prop_type_SF' 'pgrm_ind_Y' 'mi_pct' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'orig_loan_term' 'st_CA'] | ['servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'pgrm_ind_Y' 'prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'rel_ref_ind' 'mi_pct' 'servicer_name_QUICKEN LOANS INC.'] | ['pgrm_ind_Y' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_WELLS FARGO BANK, ' 'pre_relief_prog_N' 'prop_type_SF' 'mi_pct' 'orig_loan_term' 'rel_ref_ind' 'channel_R' 'seller_name_CALIBER HOME LOANS, ' 'st_CA'] | ['pgrm_ind_Y' 'pre_relief_prog_N' 'mi_pct' 'prop_type_SF' 'orig_loan_term' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_WELLS FARGO BANK, ' 'channel_R'] | ['pgrm_ind_Y'] |
| 17 | ['st_CA'] | ['seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'pgrm_ind_Y' 'loan_purpose_N' 'prop_type_SF' 'channel_R' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_CALIBER HOME LOANS, ' 'mi_pct' 'rel_ref_ind' 'st_Other' 'servicer_name_WELLS FARGO BANK, '] | ['seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'pgrm_ind_Y' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_JPMORGAN CHASE BAN' 'prop_type_SF' 'channel_R' 'orig_loan_term' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'mi_pct'] | ['prop_type_SF' 'st_CA' 'servicer_name_JPMORGAN CHASE BAN' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'pgrm_ind_Y' 'channel_R' 'pre_relief_prog_N' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'mi_pct'] | ['seller_name_U.S. BANK N.A.' 'pgrm_ind_Y' 'seller_name_CALIBER HOME LOANS, ' 'prop_type_SF' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'rel_ref_ind' 'mi_pct'] | ['prop_type_SF' 'pgrm_ind_Y' 'pre_relief_prog_N' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_CALIBER HOME LOANS, ' 'orig_loan_term' 'rel_ref_ind' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'mi_pct' 'st_CA'] | ['servicer_name_WELLS FARGO BANK, '] |
| 18 | ['pgrm_ind_Y'] | ['st_CA' 'prop_type_SF' 'orig_loan_term' 'rel_ref_ind' 'channel_R' 'pgrm_ind_Y' 'servicer_name_JPMORGAN CHASE BAN' 'st_Other' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'loan_purpose_N'] | ['servicer_name_WELLS FARGO BANK, ' 'prop_type_SF' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'seller_name_U.S. BANK N.A.' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'pgrm_ind_Y'] | ['pre_relief_prog_N' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_JPMORGAN CHASE BAN' 'prop_type_SF' 'seller_name_U.S. BANK N.A.' 'pgrm_ind_Y' 'rel_ref_ind' 'st_Other' 'st_CA' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_QUICKEN LOANS INC.'] | ['prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'channel_R' 'rel_ref_ind' 'pgrm_ind_Y' 'seller_name_CALIBER HOME LOANS, ' 'st_CA' 'servicer_name_QUICKEN LOANS INC.'] | ['seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'rel_ref_ind' 'prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'channel_R' 'pre_relief_prog_N' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_JPMORGAN CHASE BAN' 'st_CA' 'pgrm_ind_Y'] | ['prop_type_SF'] |
| 19 | ['channel_R'] | ['seller_name_CALIBER HOME LOANS, ' 'st_CA' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'channel_R' 'rel_ref_ind' 'st_MI' 'pre_relief_prog_N' 'loan_purpose_N' 'prop_type_SF' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_JPMORGAN CHASE BAN' 'seller_name_QUICKEN LOANS INC.' 'st_Other'] | ['seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'st_CA' 'prop_type_SF' 'loan_purpose_N' 'channel_R' 'rel_ref_ind' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_JPMORGAN CHASE BAN' 'st_NJ' 'st_Other' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N'] | ['channel_R' 'servicer_name_WELLS FARGO BANK, ' 'prop_type_SF' 'servicer_name_JPMORGAN CHASE BAN' 'rel_ref_ind' 'seller_name_U.S. BANK N.A.' 'st_CA' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'pgrm_ind_Y'] | ['servicer_name_WELLS FARGO BANK, ' 'channel_R' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_JPMORGAN CHASE BAN' 'servicer_name_TRUIST BANK' 'rel_ref_ind' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N' 'prop_type_SF' 'loan_purpose_N'] | ['rel_ref_ind' 'channel_R' 'prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_JPMORGAN CHASE BAN' 'st_CA' 'loan_purpose_N' 'pgrm_ind_Y'] | ['rel_ref_ind'] |
| 20 | ['loan_purpose_N'] | ['channel_R' 'prop_type_SF' 'rel_ref_ind' 'seller_name_CALIBER HOME LOANS, ' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN' 'loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'st_TX' 'seller_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'st_Other'] | ['prop_type_SF' 'servicer_name_JPMORGAN CHASE BAN' 'servicer_name_WELLS FARGO BANK, ' 'channel_R' 'st_CA' 'st_Other' 'rel_ref_ind' 'seller_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_CALIBER HOME LOANS, ' 'pre_relief_prog_N' 'loan_purpose_N' 'pgrm_ind_Y'] | ['seller_name_U.S. BANK N.A.' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'prop_type_SF' 'st_CA' 'rel_ref_ind' 'st_Other' 'pre_relief_prog_N' 'loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_CALIBER HOME LOANS, '] | ['rel_ref_ind' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.'] | ['channel_R' 'servicer_name_JPMORGAN CHASE BAN' 'loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'st_CA' 'prop_type_SF' 'rel_ref_ind' 'pre_relief_prog_N' 'servicer_name_QUICKEN LOANS INC.' 'st_Other'] | ['channel_R'] |
| 21 | ['seller_name_CALIBER HOME LOANS, '] | ['prop_type_SF' 'seller_name_CALIBER HOME LOANS, ' 'loan_purpose_N' 'rel_ref_ind' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'st_CA' 'st_Other' 'servicer_name_JPMORGAN CHASE BAN' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'st_TX' 'channel_C' 'st_MI'] | ['rel_ref_ind' 'channel_R' 'seller_name_U.S. BANK N.A.' 'servicer_name_WELLS FARGO BANK, ' 'prop_type_SF' 'loan_purpose_N' 'st_Other' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_JPMORGAN CHASE BAN'] | ['st_CA' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'rel_ref_ind' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'st_Other'] | ['channel_R' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'rel_ref_ind' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_N' 'st_Other' 'loan_purpose_N' 'st_NJ' 'servicer_name_JPMORGAN CHASE BAN'] | ['servicer_name_WELLS FARGO BANK, ' 'st_CA' 'seller_name_U.S. BANK N.A.' 'prop_type_SF' 'pre_relief_prog_N' 'channel_R' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'st_Other' 'st_TX' 'rel_ref_ind'] | ['loan_purpose_N'] |
| 22 | ['servicer_name_WELLS FARGO BANK, '] | ['servicer_name_JPMORGAN CHASE BAN' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'st_CA' 'pre_relief_prog_F' 'rel_ref_ind' 'st_Other' 'pre_relief_prog_N' 'prop_type_SF' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_TX' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'channel_C' 'servicer_name_QUICKEN LOANS INC.' 'st_NJ'] | ['st_CA' 'loan_purpose_N' 'channel_R' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'rel_ref_ind' 'st_TX' 'st_WA' 'st_NJ' 'servicer_name_WELLS FARGO BANK, ' 'pre_relief_prog_N' 'st_MI' 'st_Other' 'prop_type_SF' 'servicer_name_QUICKEN LOANS INC.'] | ['seller_name_CALIBER HOME LOANS, ' 'st_CA' 'loan_purpose_N' 'st_TX' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'prop_type_SF' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_QUICKEN LOANS INC.' 'channel_R' 'st_Other' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'pre_relief_prog_N'] | ['loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'rel_ref_ind' 'st_Other' 'seller_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'st_MI' 'pre_relief_prog_N' 'servicer_name_JPMORGAN CHASE BAN'] | ['st_Other' 'loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'st_CA' 'channel_R' 'rel_ref_ind' 'seller_name_CALIBER HOME LOANS, ' 'st_TX' 'st_MI' 'seller_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_N'] | ['seller_name_CALIBER HOME LOANS, '] |
| 23 | ['seller_name_U.S. BANK N.A.'] | ['loan_purpose_N' 'channel_C' 'rel_ref_ind' 'servicer_name_WELLS FARGO BANK, ' 'st_MI' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'st_Other' 'seller_name_CALIBER HOME LOANS, ' 'channel_R' 'seller_name_U.S. BANK N.A.' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'prop_type_SF' 'seller_name_QUICKEN LOANS INC.' 'flag_fthb' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_TRUIST BANK'] | ['channel_R' 'st_CA' 'st_Other' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_JPMORGAN CHASE BAN' 'pre_relief_prog_N' 'st_TX' 'channel_C'] | ['seller_name_STEARNS LENDING, LLC' 'seller_name_CALIBER HOME LOANS, ' 'pre_relief_prog_N' 'loan_purpose_N' 'st_CA' 'st_Other' 'channel_R' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'servicer_name_WELLS FARGO BANK, ' 'st_MI' 'servicer_name_QUICKEN LOANS INC.' 'st_TX'] | ['st_CA' 'rel_ref_ind' 'loan_purpose_N' 'st_TX' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'servicer_name_QUICKEN LOANS INC.' 'st_Other' 'channel_R' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'st_MI' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'st_NJ'] | ['seller_name_CALIBER HOME LOANS, ' 'rel_ref_ind' 'channel_R' 'loan_purpose_N' 'st_CA' 'st_Other' 'st_MI' 'pre_relief_prog_N' 'seller_name_U.S. BANK N.A.' 'st_TX' 'servicer_name_QUICKEN LOANS INC.' 'st_CO' 'servicer_name_WELLS FARGO BANK, '] | ['st_CA'] |
| 24 | ['st_Other'] | ['servicer_name_WELLS FARGO BANK, ' 'pre_relief_prog_N' 'channel_C' 'loan_purpose_N' 'seller_name_U.S. BANK N.A.' 'st_CA' 'st_TX' 'seller_name_CALIBER HOME LOANS, ' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'st_Other' 'servicer_name_NEW RESIDENTIAL MO' 'st_WA' 'st_NJ' 'st_MI' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_JPMORGAN CHASE BAN'] | ['loan_purpose_N' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'st_CA' 'st_Other' 'servicer_name_TRUIST BANK' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_WELLS FARGO BANK, ' 'pre_relief_prog_F' 'st_TX' 'channel_C' 'pre_relief_prog_N' 'st_MI'] | ['loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'st_CA' 'seller_name_CALIBER HOME LOANS, ' 'st_Other' 'st_TX' 'st_WA' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'channel_C' 'flag_fthb' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.'] | ['seller_name_CALIBER HOME LOANS, ' 'st_Other' 'loan_purpose_N' 'st_MI' 'st_CA' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'st_TX' 'seller_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK' 'channel_C' 'servicer_name_QUICKEN LOANS INC.' 'st_CO'] | ['st_CA' 'rel_ref_ind' 'st_TX' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, ' 'st_Other' 'st_NJ' 'servicer_name_WELLS FARGO BANK, ' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'st_MI' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'channel_C' 'seller_name_STEARNS LENDING, LLC' 'channel_R'] | ['seller_name_U.S. BANK N.A.'] |
| 25 | ['rel_ref_ind'] | ['pre_relief_prog_F' 'st_TX' 'seller_name_U.S. BANK N.A.' 'st_Other' 'seller_name_CALIBER HOME LOANS, ' 'st_CA' 'servicer_name_TRUIST BANK' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_QUICKEN LOANS INC.' 'loan_purpose_N' 'pre_relief_prog_N' 'rel_ref_ind' 'st_MI' 'channel_C' 'flag_fthb' 'servicer_name_QUICKEN LOANS INC.'] | ['servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'st_Other' 'st_TX' 'st_CA' 'loan_purpose_N' 'servicer_name_WELLS FARGO BANK, ' 'channel_C' 'servicer_name_TRUIST BANK' 'seller_name_CALIBER HOME LOANS, ' 'seller_name_U.S. BANK N.A.' 'flag_fthb' 'st_WA' 'pre_relief_prog_F' 'st_MI' 'seller_name_QUICKEN LOANS INC.' 'seller_name_STEARNS LENDING, LLC' 'channel_R'] | ['rel_ref_ind' 'st_Other' 'pre_relief_prog_F' 'st_TX' 'seller_name_CALIBER HOME LOANS, ' 'channel_C' 'seller_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'st_CA' 'st_NJ' 'servicer_name_WELLS FARGO BANK, ' 'flag_fthb' 'st_MI' 'servicer_name_TRUIST BANK' 'pre_relief_prog_N' 'st_WA'] | ['st_TX' 'channel_C' 'loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'st_Other' 'seller_name_QUICKEN LOANS INC.' 'st_CA' 'flag_fthb' 'servicer_name_TRUIST BANK' 'pre_relief_prog_F' 'st_WA' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, ' 'st_MI' 'st_NJ'] | ['loan_purpose_N' 'channel_C' 'st_Other' 'rel_ref_ind' 'seller_name_CALIBER HOME LOANS, ' 'st_CA' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'seller_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'seller_name_U.S. BANK N.A.' 'flag_fthb' 'st_MI' 'servicer_name_TRUIST BANK'] | ['st_Other'] |
| 26 | ['st_TX'] | ['channel_C' 'st_Other' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'seller_name_U.S. BANK N.A.' 'rel_ref_ind' 'seller_name_JPMORGAN CHASE BANK,' 'st_MI' 'loan_purpose_N' 'flag_fthb' 'servicer_name_TRUIST BANK' 'st_CA' 'pre_relief_prog_F' 'servicer_name_WELLS FARGO BANK, ' 'seller_name_QUICKEN LOANS INC.' 'pre_relief_prog_N' 'seller_name_CALIBER HOME LOANS, ' 'st_NJ' 'st_CO'] | ['st_TX' 'st_Other' 'loan_purpose_N' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'channel_C' 'seller_name_U.S. BANK N.A.' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'servicer_name_TRUIST BANK' 'flag_fthb' 'channel_R' 'st_CA'] | ['channel_C' 'st_Other' 'rel_ref_ind' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'loan_purpose_N' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'pre_relief_prog_F' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MI' 'channel_R' 'st_CA' 'flag_fthb' 'seller_name_U.S. BANK N.A.'] | ['channel_C' 'seller_name_QUICKEN LOANS INC.' 'st_Other' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'seller_name_U.S. BANK N.A.' 'st_WA' 'rel_ref_ind' 'pre_relief_prog_F' 'st_MI' 'flag_fthb' 'loan_purpose_N' 'seller_name_CALIBER HOME LOANS, '] | ['pre_relief_prog_F' 'st_TX' 'seller_name_JPMORGAN CHASE BANK,' 'st_Other' 'channel_C' 'servicer_name_TRUIST BANK' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'loan_purpose_N' 'seller_name_U.S. BANK N.A.' 'seller_name_CALIBER HOME LOANS, '] | ['pre_relief_prog_F'] |
| 27 | ['channel_C'] | ['servicer_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_Other' 'st_TX' 'seller_name_JPMORGAN CHASE BANK,' 'channel_C' 'rel_ref_ind' 'st_CA' 'flag_fthb' 'seller_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'st_NJ' 'loan_purpose_N' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_PNC BANK, NA' 'st_MI' 'st_CO' 'servicer_name_U.S. BANK N.A.'] | ['channel_C' 'st_TX' 'st_Other' 'seller_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'flag_fthb' 'pre_relief_prog_F' 'st_WA' 'seller_name_JPMORGAN CHASE BANK,' 'st_MI' 'servicer_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK'] | ['st_TX' 'st_MI' 'channel_C' 'st_Other' 'servicer_name_TRUIST BANK' 'seller_name_QUICKEN LOANS INC.' 'flag_fthb' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'loan_purpose_N' 'seller_name_U.S. BANK N.A.' 'st_NJ'] | ['pre_relief_prog_F' 'st_CA' 'flag_fthb' 'st_MI' 'channel_C' 'st_TX' 'st_Other' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'seller_name_U.S. BANK N.A.' 'loan_purpose_N' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.'] | ['channel_C' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'rel_ref_ind' 'servicer_name_TRUIST BANK' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'st_Other' 'pre_relief_prog_F' 'st_MI' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_STEARNS LENDING, LLC' 'st_CA' 'st_NJ'] | ['channel_C'] |
| 28 | ['servicer_name_QUICKEN LOANS INC.'] | ['st_Other' 'servicer_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK' 'flag_fthb' 'channel_C' 'seller_name_QUICKEN LOANS INC.' 'st_TX' 'st_WA' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_PNC BANK, NA' 'rel_ref_ind' 'loan_purpose_N' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MI' 'seller_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'st_CO'] | ['st_Other' 'channel_C' 'st_TX' 'servicer_name_TRUIST BANK' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'st_MI' 'servicer_name_LAKEVIEW LOAN SERV' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'st_NJ'] | ['st_Other' 'channel_C' 'servicer_name_TRUIST BANK' 'flag_fthb' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'st_WA' 'st_MI' 'st_TX' 'seller_name_CITIMORTGAGE, INC.' 'rel_ref_ind'] | ['servicer_name_QUICKEN LOANS INC.' 'channel_C' 'st_Other' 'servicer_name_TRUIST BANK' 'st_TX' 'st_CA' 'rel_ref_ind' 'flag_fthb' 'pre_relief_prog_F' 'st_WA' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'st_NJ'] | ['st_TX' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_QUICKEN LOANS INC.' 'flag_fthb' 'pre_relief_prog_F' 'st_Other' 'channel_C' 'servicer_name_TRUIST BANK' 'st_MI' 'rel_ref_ind' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'st_WA' 'seller_name_U.S. BANK N.A.' 'servicer_name_U.S. BANK N.A.'] | ['flag_fthb'] |
| 29 | ['seller_name_QUICKEN LOANS INC.'] | ['st_TX' 'flag_fthb' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_TRUIST BANK' 'channel_C' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'servicer_name_PNC BANK, NA' 'rel_ref_ind' 'servicer_name_NEW RESIDENTIAL MO' 'st_Other' 'st_MI' 'st_WA' 'st_PA' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_U.S. BANK N.A.'] | ['pre_relief_prog_F' 'flag_fthb' 'st_TX' 'servicer_name_QUICKEN LOANS INC.' 'channel_C' 'st_Other' 'servicer_name_U.S. BANK N.A.' 'st_MI' 'servicer_name_TRUIST BANK' 'seller_name_QUICKEN LOANS INC.' 'seller_name_U.S. BANK N.A.' 'servicer_name_NEW RESIDENTIAL MO' 'st_WA'] | ['servicer_name_QUICKEN LOANS INC.' 'flag_fthb' 'servicer_name_TRUIST BANK' 'st_TX' 'channel_C' 'pre_relief_prog_F' 'st_WA' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'st_Other' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ'] | ['st_Other' 'channel_C' 'st_TX' 'pre_relief_prog_F' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_WA' 'rel_ref_ind' 'st_NJ'] | ['seller_name_QUICKEN LOANS INC.' 'st_Other' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_TRUIST BANK' 'seller_name_STEARNS LENDING, LLC' 'flag_fthb' 'rel_ref_ind' 'st_MI' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'st_NJ' 'channel_C' 'pre_relief_prog_F' 'st_WA'] | ['servicer_name_TRUIST BANK'] |
| 30 | ['servicer_name_TRUIST BANK'] | ['flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_Other' 'pre_relief_prog_F' 'rel_ref_ind' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_QUICKEN LOANS INC.' 'st_MI' 'st_NJ' 'st_TX' 'st_WA' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_NEW RESIDENTIAL MO' 'channel_C' 'servicer_name_U.S. BANK N.A.' 'st_CO' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_STEARNS LENDING, LLC'] | ['st_MI' 'pre_relief_prog_F' 'flag_fthb' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_QUICKEN LOANS INC.' 'st_TX' 'servicer_name_TRUIST BANK' 'st_NJ' 'channel_C' 'rel_ref_ind' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'st_Other' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NEW RESIDENTIAL MO'] | ['servicer_name_FREEDOM MORTGAGE C' 'st_NJ' 'st_CO' 'servicer_name_QUICKEN LOANS INC.' 'st_MI' 'rel_ref_ind' 'st_MD' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'pre_relief_prog_F' 'channel_C' 'st_TX' 'servicer_name_U.S. BANK N.A.' 'st_Other' 'st_WA'] | ['seller_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'flag_fthb' 'servicer_name_TRUIST BANK' 'channel_C' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'pre_relief_prog_N' 'st_MI' 'st_NJ' 'servicer_name_U.S. BANK N.A.' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_JPMORGAN CHASE BANK,' 'st_Other' 'st_WA' 'st_CO' 'seller_name_STEARNS LENDING, LLC' 'seller_name_CITIMORTGAGE, INC.'] | ['servicer_name_QUICKEN LOANS INC.' 'flag_fthb' 'pre_relief_prog_F' 'st_MI' 'channel_C' 'servicer_name_U.S. BANK N.A.' 'st_Other' 'st_TX' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'seller_name_U.S. BANK N.A.' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'st_WA' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C'] | ['servicer_name_QUICKEN LOANS INC.'] |
| 31 | ['pre_relief_prog_F'] | ['seller_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'flag_fthb' 'pre_relief_prog_F' 'st_NJ' 'st_MI' 'st_WA' 'st_TX' 'servicer_name_TRUIST BANK' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_U.S. BANK N.A.' 'st_MD' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_QUICKEN LOANS INC.' 'st_Other' 'st_CO' 'channel_C' 'seller_name_STEARNS LENDING, LLC'] | ['flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'st_MI' 'seller_name_CITIMORTGAGE, INC.' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_TX' 'servicer_name_U.S. BANK N.A.' 'st_WA' 'st_Other' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'channel_C' 'seller_name_JPMORGAN CHASE BANK,'] | ['flag_fthb' 'st_TX' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_NEW RESIDENTIAL MO' 'st_WA' 'st_NJ' 'servicer_name_FREEDOM MORTGAGE C' 'st_MI' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_Other' 'servicer_name_U.S. BANK N.A.' 'servicer_name_LAKEVIEW LOAN SERV'] | ['servicer_name_NEW RESIDENTIAL MO' 'flag_fthb' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'st_WA' 'st_MI' 'servicer_name_TRUIST BANK' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'st_TX' 'st_NJ' 'st_Other'] | ['flag_fthb' 'st_MI' 'st_TX' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_QUICKEN LOANS INC.' 'st_WA' 'servicer_name_TRUIST BANK' 'channel_C' 'servicer_name_U.S. BANK N.A.' 'st_NJ' 'st_Other' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_LAKEVIEW LOAN SERV' 'rel_ref_ind'] | ['st_MI'] |
| 32 | ['st_MI'] | ['st_CO' 'st_MI' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'servicer_name_QUICKEN LOANS INC.' 'st_NJ' 'servicer_name_CALIBER HOME LOANS' 'st_TX' 'pre_relief_prog_F' 'seller_name_STEARNS LENDING, LLC' 'seller_name_U.S. BANK N.A.' 'servicer_name_PNC BANK, NA' 'flag_fthb' 'seller_name_JPMORGAN CHASE BANK,' 'st_WA' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_LAKEVIEW LOAN SERV' 'cnt_units_2' 'servicer_name_NEW RESIDENTIAL MO' 'rel_ref_ind' 'st_PA'] | ['seller_name_QUICKEN LOANS INC.' 'st_WA' 'st_MI' 'flag_fthb' 'servicer_name_TRUIST BANK' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_U.S. BANK N.A.' 'pre_relief_prog_F' 'st_TX' 'st_NJ' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'servicer_name_PNC BANK, NA'] | ['st_MI' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_U.S. BANK N.A.' 'st_NJ' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'st_WA' 'servicer_name_TRUIST BANK' 'flag_fthb' 'st_TX' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC'] | ['flag_fthb' 'st_NJ' 'st_MI' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_TX' 'servicer_name_FREEDOM MORTGAGE C' 'st_WA' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_U.S. BANK N.A.' 'servicer_name_PNC BANK, NA' 'servicer_name_NEW RESIDENTIAL MO'] | ['servicer_name_FREEDOM MORTGAGE C' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_MI' 'flag_fthb' 'pre_relief_prog_F' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'st_Other' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA'] | ['st_TX'] |
| 33 | ['flag_fthb'] | ['st_MI' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'flag_fthb' 'servicer_name_U.S. BANK N.A.' 'st_TX' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_TRUIST BANK' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'channel_C' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ'] | ['servicer_name_PNC BANK, NA' 'servicer_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'seller_name_STEARNS LENDING, LLC' 'st_MI' 'servicer_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'cnt_units_2' 'st_CO' 'st_TX' 'servicer_name_FREEDOM MORTGAGE C' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NJ' 'seller_name_JPMORGAN CHASE BANK,'] | ['pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'servicer_name_U.S. BANK N.A.' 'flag_fthb' 'st_MI' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_LAKEVIEW LOAN SERV' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'st_TX' 'st_CO' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_FLAGSTAR BANK, FSB'] | ['servicer_name_U.S. BANK N.A.' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_QUICKEN LOANS INC.' 'st_WA' 'st_MI' 'pre_relief_prog_F' 'servicer_name_TRUIST BANK' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'st_NJ' 'seller_name_STEARNS LENDING, LLC' 'flag_fthb' 'seller_name_JPMORGAN CHASE BANK,'] | ['st_MI' 'pre_relief_prog_F' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'servicer_name_TRUIST BANK' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_U.S. BANK N.A.' 'servicer_name_PNC BANK, NA' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_JPMORGAN CHASE BANK,' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C'] | ['seller_name_QUICKEN LOANS INC.'] |
| 34 | ['st_WA'] | ['servicer_name_NEW RESIDENTIAL MO' 'cnt_units_2' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_QUICKEN LOANS INC.' 'st_WA' 'st_TX' 'servicer_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK' 'servicer_name_PNC BANK, NA' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MI' 'pre_relief_prog_F' 'st_NJ' 'seller_name_QUICKEN LOANS INC.' 'flag_fthb' 'seller_name_STEARNS LENDING, LLC' 'prop_type_PU' 'st_MA'] | ['servicer_name_U.S. BANK N.A.' 'st_MI' 'st_CO' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'servicer_name_PNC BANK, NA' 'pre_relief_prog_F' 'seller_name_QUICKEN LOANS INC.' 'seller_name_STEARNS LENDING, LLC' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'flag_fthb' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_TRUIST BANK' 'st_TX' 'prop_type_PU' 'seller_name_NATIONSTAR MORTGAGE '] | ['servicer_name_TRUIST BANK' 'st_MI' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'flag_fthb' 'prop_type_PU' 'servicer_name_QUICKEN LOANS INC.' 'st_TX' 'st_WA' 'st_MD' 'pre_relief_prog_F' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'st_CO' 'servicer_name_PNC BANK, NA' 'st_NJ' 'occpy_sts_P'] | ['st_MI' 'servicer_name_TRUIST BANK' 'servicer_name_NEW RESIDENTIAL MO' 'flag_fthb' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'seller_name_QUICKEN LOANS INC.' 'pre_relief_prog_F' 'servicer_name_FREEDOM MORTGAGE C' 'st_NJ' 'rel_ref_ind' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_PNC BANK, NA' 'st_MD' 'occpy_sts_P' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FLAGSTAR BANK, FSB'] | ['servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'prop_type_PU' 'servicer_name_U.S. BANK N.A.' 'st_WA' 'seller_name_QUICKEN LOANS INC.' 'st_NJ' 'servicer_name_TRUIST BANK' 'st_MI' 'pre_relief_prog_F' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_QUICKEN LOANS INC.' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'st_CO'] | ['st_WA'] |
| 35 | ['servicer_name_U.S. BANK N.A.'] | ['st_PA' 'st_NJ' 'servicer_name_NEW RESIDENTIAL MO' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'st_MI' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_PNC BANK, NA' 'prop_type_PU' 'pre_relief_prog_F' 'servicer_name_NATIONSTAR MORTGAG' 'st_TX' 'seller_name_QUICKEN LOANS INC.' 'rel_ref_ind' 'flag_fthb' 'servicer_name_TRUIST BANK' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_QUICKEN LOANS INC.' 'occpy_sts_P' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'cnt_units_2'] | ['servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_PNC BANK, NA' 'occpy_sts_P' 'prop_type_PU' 'servicer_name_TRUIST BANK' 'st_NJ' 'seller_name_JPMORGAN CHASE BANK,' 'st_MI' 'servicer_name_U.S. BANK N.A.' 'pre_relief_prog_F' 'st_WA' 'servicer_name_QUICKEN LOANS INC.' 'st_MD' 'seller_name_STEARNS LENDING, LLC' 'seller_name_FLAGSTAR BANK, FSB' 'st_TX' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_CALIBER HOME LOANS' 'st_CO' 'flag_fthb' 'seller_name_QUICKEN LOANS INC.'] | ['seller_name_QUICKEN LOANS INC.' 'seller_name_STEARNS LENDING, LLC' 'pre_relief_prog_F' 'prop_type_PU' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_TRUIST BANK' 'servicer_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'st_MI' 'st_WA' 'st_MD' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'flag_fthb' 'st_PA' 'st_CO'] | ['st_NJ' 'servicer_name_TRUIST BANK' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'servicer_name_FREEDOM MORTGAGE C' 'st_PA' 'st_MI' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_QUICKEN LOANS INC.' 'prop_type_PU' 'seller_name_STEARNS LENDING, LLC' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_QUICKEN LOANS INC.' 'seller_name_JPMORGAN CHASE BANK,'] | ['servicer_name_TRUIST BANK' 'st_MI' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_PNC BANK, NA' 'servicer_name_U.S. BANK N.A.' 'st_WA' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'pre_relief_prog_F' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FLAGSTAR BANK, FSB' 'st_NJ' 'st_PA' 'flag_fthb' 'servicer_name_QUICKEN LOANS INC.' 'st_CO' 'prop_type_PU' 'seller_name_QUICKEN LOANS INC.'] | ['servicer_name_U.S. BANK N.A.'] |
| 36 | ['st_NJ'] | ['servicer_name_TRUIST BANK' 'servicer_name_PNC BANK, NA' 'st_WA' 'servicer_name_CALIBER HOME LOANS' 'prop_type_PU' 'seller_name_CITIMORTGAGE, INC.' 'st_MI' 'st_OR' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_FREEDOM MORTGAGE C' 'pre_relief_prog_F' 'st_MA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'servicer_name_U.S. BANK N.A.' 'servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_P' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FLAGSTAR BANK, FSB' 'flag_fthb' 'st_CO'] | ['st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'seller_name_NATIONSTAR MORTGAGE ' 'prop_type_PU' 'servicer_name_TRUIST BANK' 'st_MI' 'flag_fthb' 'st_OR' 'st_CO' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_P' 'st_TN' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2'] | ['servicer_name_NEW RESIDENTIAL MO' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_PNC BANK, NA' 'occpy_sts_P' 'st_NJ' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'st_MI' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_LAKEVIEW LOAN SERV' 'pre_relief_prog_F' 'servicer_name_TRUIST BANK' 'seller_name_FLAGSTAR BANK, FSB' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'cnt_units_2'] | ['st_WA' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_TRUIST BANK' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NEW RESIDENTIAL MO' 'occpy_sts_P' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'st_MI' 'seller_name_CITIMORTGAGE, INC.' 'st_NJ' 'st_CO' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_PNC BANK, NA' 'seller_name_FLAGSTAR BANK, FSB' 'pre_relief_prog_F' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_QUICKEN LOANS INC.'] | ['servicer_name_U.S. BANK N.A.' 'st_NJ' 'st_WA' 'st_PA' 'servicer_name_TRUIST BANK' 'prop_type_PU' 'pre_relief_prog_F' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_STEARNS LENDING, LLC' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_PNC BANK, NA' 'seller_name_CITIMORTGAGE, INC.' 'st_CO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'st_MI' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_QUICKEN LOANS INC.' 'st_GA' 'servicer_name_CALIBER HOME LOANS'] | ['servicer_name_FREEDOM MORTGAGE C'] |
| 37 | ['servicer_name_FREEDOM MORTGAGE C'] | ['servicer_name_FREEDOM MORTGAGE C' 'st_CO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MI' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'prop_type_PU' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'cnt_units_2' 'st_MD' 'servicer_name_U.S. BANK N.A.' 'servicer_name_QUICKEN LOANS INC.' 'servicer_name_PNC BANK, NA' 'servicer_name_TRUIST BANK' 'pre_relief_prog_F' 'occpy_sts_P' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'st_Other'] | ['servicer_name_TRUIST BANK' 'st_NJ' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_NEW RESIDENTIAL MO' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'st_MN' 'st_CO' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'st_PA' 'pre_relief_prog_F' 'occpy_sts_P' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MI' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV'] | ['servicer_name_U.S. BANK N.A.' 'st_WA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'st_MA' 'st_MI' 'pre_relief_prog_F' 'servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NEW RESIDENTIAL MO' 'prop_type_PU' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_TRUIST BANK' 'seller_name_QUICKEN LOANS INC.' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_STEARNS LENDING, LLC' 'occpy_sts_P' 'st_MD'] | ['servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_PU' 'servicer_name_FREEDOM MORTGAGE C' 'pre_relief_prog_F' 'seller_name_FLAGSTAR BANK, FSB' 'st_NJ' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_U.S. BANK N.A.' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'servicer_name_TRUIST BANK' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS' 'st_MD' 'st_OR'] | ['st_WA' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_U.S. BANK N.A.' 'servicer_name_PNC BANK, NA' 'st_MI' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_TRUIST BANK' 'pre_relief_prog_F' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OR' 'st_CO'] | ['cnt_units_2'] |
| 38 | ['servicer_name_NEW RESIDENTIAL MO'] | ['servicer_name_U.S. BANK N.A.' 'pre_relief_prog_F' 'occpy_sts_P' 'st_MD' 'servicer_name_FREEDOM MORTGAGE C' 'cnt_units_2' 'st_CO' 'st_NJ' 'servicer_name_PNC BANK, NA' 'servicer_name_TRUIST BANK' 'st_WA' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_PU' 'servicer_name_NATIONSTAR MORTGAG' 'st_MI' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_NEW RESIDENTIAL MO' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'flag_fthb' 'seller_name_STEARNS LENDING, LLC' 'st_NC'] | ['seller_name_STEARNS LENDING, LLC' 'prop_type_PU' 'st_NJ' 'servicer_name_TRUIST BANK' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_U.S. BANK N.A.' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'servicer_name_PNC BANK, NA' 'st_WA' 'occpy_sts_P' 'st_MI' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'cnt_units_2' 'st_OR' 'st_PA'] | ['servicer_name_PNC BANK, NA' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'st_WA' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'prop_type_PU' 'servicer_name_FREEDOM MORTGAGE C' 'st_NJ' 'servicer_name_TRUIST BANK' 'st_MA' 'st_MI' 'st_OR' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_P' 'servicer_name_NATIONSTAR MORTGAG'] | ['prop_type_PU' 'servicer_name_PNC BANK, NA' 'st_WA' 'seller_name_JPMORGAN CHASE BANK,' 'st_PA' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_U.S. BANK N.A.' 'servicer_name_TRUIST BANK' 'seller_name_FLAGSTAR BANK, FSB' 'st_NJ' 'occpy_sts_P' 'st_CO' 'cnt_units_2' 'pre_relief_prog_F'] | ['st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_TRUIST BANK' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'seller_name_JPMORGAN CHASE BANK,' 'st_CO' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'st_WA' 'occpy_sts_P' 'st_OR' 'servicer_name_U.S. BANK N.A.' 'pre_relief_prog_F' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NEW RESIDENTIAL MO' 'st_MI' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'occpy_sts_S' 'st_MA'] | ['st_CO'] |
| 39 | ['servicer_name_PNC BANK, NA'] | ['st_NJ' 'prop_type_PU' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'servicer_name_U.S. BANK N.A.' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'st_MI' 'occpy_sts_P' 'seller_name_STEARNS LENDING, LLC' 'pre_relief_prog_F' 'st_WA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_NATIONSTAR MORTGAGE ' 'cnt_units_2' 'st_MA' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_FLAGSTAR BANK, FSB' 'st_PA' 'servicer_name_TRUIST BANK' 'st_TN' 'seller_name_CITIMORTGAGE, INC.'] | ['st_PA' 'cnt_units_2' 'prop_type_PU' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'occpy_sts_P' 'servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_FREEDOM MORTGAGE C' 'st_NJ' 'st_MD' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_TRUIST BANK' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_U.S. BANK N.A.' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MA' 'st_OR' 'pre_relief_prog_F' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_WA' 'cnt_units_2' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'occpy_sts_P' 'prop_type_PU' 'servicer_name_TRUIST BANK' 'servicer_name_PNC BANK, NA' 'seller_name_FLAGSTAR BANK, FSB' 'st_NJ' 'st_PA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_STEARNS LENDING, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_CALIBER HOME LOANS'] | ['servicer_name_TRUIST BANK' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'st_NJ' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_P' 'servicer_name_PNC BANK, NA' 'st_MI' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'seller_name_STEARNS LENDING, LLC' 'st_WA' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'st_MD' 'servicer_name_CALIBER HOME LOANS'] | ['st_CO' 'servicer_name_PNC BANK, NA' 'st_NJ' 'st_WA' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'servicer_name_NEW RESIDENTIAL MO' 'occpy_sts_P' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_STEARNS LENDING, LLC' 'st_PA' 'st_MI' 'servicer_name_U.S. BANK N.A.' 'seller_name_FLAGSTAR BANK, FSB' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OR'] | ['servicer_name_PNC BANK, NA'] |
| 40 | ['seller_name_JPMORGAN CHASE BANK,'] | ['seller_name_STEARNS LENDING, LLC' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_PU' 'st_CO' 'st_WA' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MA' 'servicer_name_PNC BANK, NA' 'st_NJ' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_U.S. BANK N.A.' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'st_OR' 'occpy_sts_P' 'servicer_name_NATIONSTAR MORTGAG' 'st_NC'] | ['seller_name_JPMORGAN CHASE BANK,' 'servicer_name_TRUIST BANK' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NJ' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'st_OR' 'prop_type_PU' 'occpy_sts_P' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'cnt_units_2' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS'] | ['prop_type_PU' 'st_NJ' 'st_CO' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_P' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_TRUIST BANK' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'cnt_units_2' 'st_WA' 'seller_name_STEARNS LENDING, LLC' 'st_PA' 'st_MA' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'st_MD'] | ['servicer_name_FREEDOM MORTGAGE C' 'st_OR' 'st_NJ' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'seller_name_JPMORGAN CHASE BANK,' 'occpy_sts_P' 'prop_type_PU' 'st_MN' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NEW RESIDENTIAL MO' 'cnt_units_2' 'st_VA' 'st_PA' 'pre_relief_prog_F' 'servicer_name_LAKEVIEW LOAN SERV' 'st_WA' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_CALIBER HOME LOANS'] | ['servicer_name_PNC BANK, NA' 'prop_type_PU' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_STEARNS LENDING, LLC' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_U.S. BANK N.A.' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_TRUIST BANK' 'occpy_sts_P' 'st_PA' 'cnt_units_2' 'st_MD' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'st_MA' 'pre_relief_prog_F'] | ['prop_type_PU'] |
| 41 | ['st_CO'] | ['st_WA' 'occpy_sts_P' 'st_NJ' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'servicer_name_PNC BANK, NA' 'st_MD' 'cnt_units_2' 'st_CO' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_U.S. BANK N.A.' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'servicer_name_CALIBER HOME LOANS' 'st_PA' 'seller_name_FLAGSTAR BANK, FSB'] | ['prop_type_PU' 'occpy_sts_P' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'st_WA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NJ' 'occpy_sts_S' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'st_MN' 'st_GA'] | ['seller_name_CITIMORTGAGE, INC.' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'st_NJ' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_JPMORGAN CHASE BANK,' 'occpy_sts_P' 'cnt_units_2' 'servicer_name_PNC BANK, NA' 'st_WA' 'st_CO' 'servicer_name_U.S. BANK N.A.' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'st_MA' 'st_PA'] | ['st_CO' 'occpy_sts_P' 'cnt_units_2' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C' 'st_WA' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'prop_type_PU' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV'] | ['seller_name_STEARNS LENDING, LLC' 'st_WA' 'occpy_sts_P' 'servicer_name_PNC BANK, NA' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'st_NJ' 'cnt_units_2' 'occpy_sts_S' 'st_OR' 'prop_type_PU' 'seller_name_FLAGSTAR BANK, FSB' 'st_MD' 'servicer_name_U.S. BANK N.A.' 'st_PA' 'st_NC' 'st_MA'] | ['seller_name_NATIONSTAR MORTGAGE '] |
| 42 | ['prop_type_PU'] | ['prop_type_PU' 'st_WA' 'occpy_sts_P' 'servicer_name_PNC BANK, NA' 'servicer_name_FREEDOM MORTGAGE C' 'st_MA' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'st_NJ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'servicer_name_CALIBER HOME LOANS' 'st_MN' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'cnt_units_2' 'servicer_name_TRUIST BANK' 'st_MO' 'occpy_sts_S' 'seller_name_STEARNS LENDING, LLC'] | ['servicer_name_CALIBER HOME LOANS' 'st_NC' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'occpy_sts_P' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'st_TN' 'seller_name_STEARNS LENDING, LLC' 'st_OR' 'st_MN' 'servicer_name_TRUIST BANK' 'st_NJ' 'cnt_units_2' 'seller_name_FLAGSTAR BANK, FSB' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_U.S. BANK N.A.' 'occpy_sts_S' 'st_WA' 'st_MD' 'servicer_name_PNC BANK, NA' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_CO' 'servicer_name_PNC BANK, NA' 'servicer_name_FREEDOM MORTGAGE C' 'cnt_units_2' 'occpy_sts_P' 'seller_name_STEARNS LENDING, LLC' 'st_WA' 'st_NY' 'servicer_name_NEW RESIDENTIAL MO' 'st_MA' 'st_NJ' 'servicer_name_NATIONSTAR MORTGAG' 'prop_type_PU' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_U.S. BANK N.A.' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S'] | ['occpy_sts_P' 'st_WA' 'prop_type_PU' 'st_CO' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NJ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'servicer_name_U.S. BANK N.A.' 'st_MD'] | ['prop_type_PU' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'st_NJ' 'st_OR' 'servicer_name_PNC BANK, NA' 'seller_name_FLAGSTAR BANK, FSB' 'occpy_sts_P' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'st_WA' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'seller_name_NATIONSTAR MORTGAGE '] | ['servicer_name_NEW RESIDENTIAL MO'] |
| 43 | ['seller_name_STEARNS LENDING, LLC'] | ['servicer_name_CALIBER HOME LOANS' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'occpy_sts_S' 'occpy_sts_P' 'st_CT' 'st_CO' 'st_MA' 'st_NJ' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_PU' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NEW RESIDENTIAL MO' 'st_IL' 'st_OR' 'st_NC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'st_WA' 'servicer_name_U.S. BANK N.A.' 'st_GA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'cnt_units_2' 'servicer_name_PNC BANK, NA'] | ['st_MA' 'servicer_name_FREEDOM MORTGAGE C' 'occpy_sts_P' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NJ' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'seller_name_SUNTRUST MORTGAGE, I' 'st_OR' 'seller_name_JPMORGAN CHASE BANK,' 'cnt_units_2' 'st_MO' 'seller_name_CITIMORTGAGE, INC.' 'st_CO' 'st_MD' 'servicer_name_CALIBER HOME LOANS' 'st_WA' 'prop_type_PU' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_NJ' 'st_CO' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_NEW RESIDENTIAL MO' 'occpy_sts_P' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'st_OR' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.' 'prop_type_PU' 'st_PA' 'st_WA' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'cnt_units_2' 'st_MA' 'servicer_name_U.S. BANK N.A.' 'st_MD'] | ['seller_name_JPMORGAN CHASE BANK,' 'st_CO' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_STEARNS LENDING, LLC' 'st_MD' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_PNC BANK, NA' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_LAKEVIEW LOAN SERV' 'cnt_units_2' 'occpy_sts_P' 'st_OR' 'occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'st_MA' 'prop_type_PU' 'st_TN'] | ['servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'st_NJ' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'occpy_sts_P' 'servicer_name_FREEDOM MORTGAGE C' 'st_OR' 'servicer_name_PNC BANK, NA' 'servicer_name_U.S. BANK N.A.' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'seller_name_STEARNS LENDING, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'seller_name_JPMORGAN CHASE BANK,' 'st_WA' 'prop_type_PU' 'seller_name_CITIMORTGAGE, INC.' 'st_MA'] | ['seller_name_CITIMORTGAGE, INC.'] |
| 44 | ['occpy_sts_P'] | ['st_MA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'cnt_units_2' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_PNC BANK, NA' 'servicer_name_FREEDOM MORTGAGE C' 'st_NC' 'occpy_sts_P' 'st_CO' 'servicer_name_CALIBER HOME LOANS' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'st_MD' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FRANKLIN AMERICAN MO' 'prop_type_PU' 'st_NJ' 'servicer_name_U.S. BANK N.A.' 'st_GA' 'st_WA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NV' 'st_OR'] | ['seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_FREEDOM MORTGAGE C' 'prop_type_PU' 'occpy_sts_P' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_PNC BANK, NA' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'st_AZ' 'st_NJ' 'st_GA' 'servicer_name_U.S. BANK N.A.' 'st_OR' 'seller_name_CITIMORTGAGE, INC.' 'cnt_units_2' 'st_MA' 'st_MD' 'st_PA' 'st_WA'] | ['seller_name_NATIONSTAR MORTGAGE ' 'occpy_sts_P' 'st_NJ' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'st_MA' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'prop_type_PU' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_STEARNS LENDING, LLC' 'occpy_sts_S' 'st_OR' 'seller_name_CITIMORTGAGE, INC.' 'st_PA' 'st_MN' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'st_MD' 'prop_type_MH'] | ['seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_NEW RESIDENTIAL MO' 'st_OR' 'st_CO' 'occpy_sts_P' 'st_MD' 'cnt_units_2' 'st_VA' 'seller_name_STEARNS LENDING, LLC' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MA' 'prop_type_PU' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_PNC BANK, NA' 'st_NJ' 'occpy_sts_S' 'servicer_name_CALIBER HOME LOANS' 'st_NV' 'st_PA' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.'] | ['occpy_sts_P' 'seller_name_STEARNS LENDING, LLC' 'prop_type_PU' 'servicer_name_FREEDOM MORTGAGE C' 'st_MA' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'st_CO' 'seller_name_NATIONSTAR MORTGAGE ' 'cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'seller_name_JPMORGAN CHASE BANK,' 'st_NJ' 'servicer_name_CALIBER HOME LOANS' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'st_TN'] | ['occpy_sts_P'] |
| 45 | ['servicer_name_LAKEVIEW LOAN SERV'] | ['occpy_sts_P' 'seller_name_JPMORGAN CHASE BANK,' 'cnt_units_2' 'st_CO' 'seller_name_STEARNS LENDING, LLC' 'st_NJ' 'servicer_name_NATIONSTAR MORTGAG' 'pre_relief_prog_F' 'servicer_name_NEW RESIDENTIAL MO' 'st_NC' 'st_MA' 'st_MD' 'seller_name_FLAGSTAR BANK, FSB' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NV' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_PNC BANK, NA' 'st_AZ' 'st_IL' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'st_GA' 'st_WA' 'st_MN' 'servicer_name_U.S. BANK N.A.' 'st_PA' 'st_OR'] | ['st_CO' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_STEARNS LENDING, LLC' 'st_NC' 'st_NJ' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'st_GA' 'servicer_name_NEW RESIDENTIAL MO' 'occpy_sts_P' 'st_MD' 'servicer_name_FREEDOM MORTGAGE C' 'st_OR' 'occpy_sts_S' 'st_MA' 'servicer_name_U.S. BANK N.A.' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'cnt_units_2'] | ['servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'st_MA' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_NEW RESIDENTIAL MO' 'st_OR' 'st_NC' 'cnt_units_2' 'occpy_sts_P' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'seller_name_STEARNS LENDING, LLC' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_FREEDOM MORTGAGE C' 'st_MD' 'st_MN' 'st_NJ'] | ['servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_PNC BANK, NA' 'seller_name_FLAGSTAR BANK, FSB' 'st_CO' 'seller_name_STEARNS LENDING, LLC' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_P' 'st_NJ' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_FREEDOM MORTGAGE C' 'st_OR' 'st_MA' 'st_GA' 'servicer_name_CALIBER HOME LOANS' 'seller_name_JPMORGAN CHASE BANK,' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'servicer_name_NEW RESIDENTIAL MO' 'cnt_units_2' 'st_MD' 'st_VA'] | ['servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_P' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_STEARNS LENDING, LLC' 'st_CO' 'st_NV' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'cnt_units_2' 'st_OR' 'seller_name_FLAGSTAR BANK, FSB' 'st_MA' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_PNC BANK, NA' 'st_GA' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NJ' 'st_WA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_TN' 'occpy_sts_S' 'servicer_name_U.S. BANK N.A.'] | ['st_NJ'] |
| 46 | ['cnt_units_2'] | ['servicer_name_PNC BANK, NA' 'servicer_name_CALIBER HOME LOANS' 'st_GA' 'st_NJ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'servicer_name_NEW RESIDENTIAL MO' 'cnt_units_2' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_JPMORGAN CHASE BANK,' 'st_MN' 'st_OR' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_FLAGSTAR BANK, FSB' 'st_MA' 'occpy_sts_P' 'st_PA' 'occpy_sts_S' 'st_MD' 'st_WI' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NC' 'servicer_name_NATIONSTAR MORTGAG'] | ['seller_name_CITIMORTGAGE, INC.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_FREEDOM MORTGAGE C' 'st_CO' 'servicer_name_CALIBER HOME LOANS' 'seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_P' 'seller_name_JPMORGAN CHASE BANK,' 'occpy_sts_S' 'st_MN' 'st_IL' 'st_NC' 'st_MD' 'st_PA' 'cnt_units_2' 'servicer_name_PNC BANK, NA' 'seller_name_FRANKLIN AMERICAN MO' 'st_NJ' 'seller_name_NATIONSTAR MORTGAGE '] | ['occpy_sts_P' 'st_MD' 'seller_name_JPMORGAN CHASE BANK,' 'st_PA' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'st_OR' 'st_CO' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'st_NC' 'servicer_name_FREEDOM MORTGAGE C' 'st_MA' 'st_NJ' 'occpy_sts_S' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_NEW RESIDENTIAL MO'] | ['seller_name_STEARNS LENDING, LLC' 'cnt_units_2' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'st_MN' 'st_PA' 'st_NJ' 'st_NY' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_P' 'occpy_sts_S' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NEW RESIDENTIAL MO' 'st_MD' 'st_CO' 'st_NC' 'st_MA' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'st_GA' 'servicer_name_PNC BANK, NA'] | ['seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'st_CO' 'st_MA' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_STEARNS LENDING, LLC' 'seller_name_FLAGSTAR BANK, FSB' 'st_NV' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_PNC BANK, NA' 'occpy_sts_P' 'cnt_units_2' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NC' 'servicer_name_FREEDOM MORTGAGE C' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'st_PA'] | ['seller_name_JPMORGAN CHASE BANK,'] |
| 47 | ['seller_name_FLAGSTAR BANK, FSB'] | ['seller_name_JPMORGAN CHASE BANK,' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'st_MA' 'st_CO' 'servicer_name_CALIBER HOME LOANS' 'occpy_sts_P' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_FLAGSTAR BANK, FSB' 'occpy_sts_S' 'servicer_name_FREEDOM MORTGAGE C' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OR' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_U.S. BANK N.A.' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'st_IL' 'servicer_name_NEW RESIDENTIAL MO' 'cnt_units_2' 'st_GA' 'st_AZ' 'st_NC' 'st_OH' 'prop_type_MH' 'st_NY'] | ['servicer_name_FREEDOM MORTGAGE C' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'seller_name_JPMORGAN CHASE BANK,' 'st_MA' 'cnt_units_2' 'seller_name_STEARNS LENDING, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'st_OR' 'st_CO' 'occpy_sts_S' 'occpy_sts_P' 'servicer_name_NEW RESIDENTIAL MO' 'st_MN' 'servicer_name_PNC BANK, NA' 'st_NJ' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'seller_name_FLAGSTAR BANK, FSB' 'st_MD' 'st_NC' 'seller_name_SUNTRUST MORTGAGE, I' 'st_TN' 'st_GA' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_VA'] | ['st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_JPMORGAN CHASE BANK,' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_P' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NEW RESIDENTIAL MO' 'st_OR' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'st_MA' 'occpy_sts_S' 'seller_name_FLAGSTAR BANK, FSB' 'st_NV' 'prop_type_MH' 'seller_name_FRANKLIN AMERICAN MO' 'st_PA' 'st_CO' 'st_NY' 'st_GA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NJ'] | ['seller_name_FLAGSTAR BANK, FSB' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'st_MA' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'st_NC' 'st_CO' 'occpy_sts_P' 'seller_name_NATIONSTAR MORTGAGE ' 'st_GA' 'cnt_units_2' 'st_OH' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OR' 'servicer_name_CALIBER HOME LOANS' 'st_IL' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'st_PA' 'st_MN' 'prop_type_MH' 'st_MO' 'st_NJ' 'st_NV'] | ['seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_CALIBER HOME LOANS' 'seller_name_FLAGSTAR BANK, FSB' 'occpy_sts_P' 'st_OR' 'st_IL' 'st_NC' 'st_GA' 'st_MN' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_STEARNS LENDING, LLC' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_JPMORGAN CHASE BANK,' 'st_MA' 'occpy_sts_S' 'servicer_name_PNC BANK, NA' 'cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'st_CO' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NJ'] | ['seller_name_FLAGSTAR BANK, FSB'] |
| 48 | ['seller_name_CITIMORTGAGE, INC.'] | ['occpy_sts_S' 'st_MO' 'st_PA' 'seller_name_STEARNS LENDING, LLC' 'st_OR' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_PNC BANK, NA' 'servicer_name_NATIONSTAR MORTGAG' 'st_MN' 'st_MA' 'occpy_sts_P' 'cnt_units_2' 'st_CO' 'st_MD' 'st_NC' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'seller_name_FRANKLIN AMERICAN MO' 'st_NJ' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_JPMORGAN CHASE BANK,' 'st_GA' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_IL' 'st_TN'] | ['st_NJ' 'st_MA' 'occpy_sts_S' 'servicer_name_CALIBER HOME LOANS' 'st_NC' 'cnt_units_2' 'seller_name_FLAGSTAR BANK, FSB' 'st_MN' 'st_MD' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_NEW RESIDENTIAL MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'st_PA' 'seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'seller_name_STEARNS LENDING, LLC' 'occpy_sts_P' 'servicer_name_PNC BANK, NA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_CO' 'st_GA'] | ['st_MA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_CITIMORTGAGE, INC.' 'st_OR' 'st_GA' 'seller_name_NATIONSTAR MORTGAGE ' 'cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'st_VA' 'servicer_name_CALIBER HOME LOANS' 'seller_name_JPMORGAN CHASE BANK,' 'st_NC' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_P' 'occpy_sts_S' 'st_CO' 'st_MD' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_PNC BANK, NA' 'st_MN' 'st_PA' 'st_MO' 'st_NJ'] | ['cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_PNC BANK, NA' 'seller_name_JPMORGAN CHASE BANK,' 'st_MA' 'st_OR' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'st_MN' 'st_MD' 'occpy_sts_P' 'occpy_sts_S' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'st_GA' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MO' 'st_OH' 'servicer_name_FREEDOM MORTGAGE C' 'seller_name_NATIONSTAR MORTGAGE ' 'st_CT' 'st_NV'] | ['st_OR' 'seller_name_JPMORGAN CHASE BANK,' 'st_GA' 'st_MN' 'cnt_units_2' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'st_CO' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_STEARNS LENDING, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MA' 'occpy_sts_S' 'servicer_name_PNC BANK, NA' 'servicer_name_NATIONSTAR MORTGAG' 'prop_type_MH' 'occpy_sts_P' 'st_MO' 'st_NC' 'servicer_name_FREEDOM MORTGAGE C'] | ['seller_name_STEARNS LENDING, LLC'] |
| 49 | ['st_OR'] | ['seller_name_CITIMORTGAGE, INC.' 'st_MA' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_FLAGSTAR BANK, FSB' 'st_NC' 'st_OR' 'st_MD' 'st_UT' 'cnt_units_2' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_CALIBER HOME LOANS' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_STEARNS LENDING, LLC' 'st_MN' 'st_CO' 'servicer_name_PNC BANK, NA' 'st_GA' 'st_AZ' 'occpy_sts_S' 'seller_name_SUNTRUST MORTGAGE, I' 'st_WI' 'seller_name_BRANCH BANKING & TRU' 'servicer_name_NEW RESIDENTIAL MO' 'st_CT' 'st_PA'] | ['occpy_sts_P' 'servicer_name_CALIBER HOME LOANS' 'st_MA' 'cnt_units_2' 'st_OR' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_PNC BANK, NA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NC' 'st_IL' 'seller_name_STEARNS LENDING, LLC' 'seller_name_FLAGSTAR BANK, FSB' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'st_GA' 'st_CO' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'st_PA' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_NEW RESIDENTIAL MO'] | ['seller_name_JPMORGAN CHASE BANK,' 'seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NC' 'seller_name_CITIMORTGAGE, INC.' 'cnt_units_2' 'st_MA' 'occpy_sts_S' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'st_MN' 'servicer_name_PNC BANK, NA' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'st_NV' 'st_CO' 'st_MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_OH' 'occpy_sts_P' 'st_TN'] | ['servicer_name_NATIONSTAR MORTGAG' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_CALIBER HOME LOANS' 'st_MA' 'occpy_sts_P' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'st_OR' 'cnt_units_2' 'st_OH' 'st_MD' 'st_CO' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'servicer_name_PNC BANK, NA' 'seller_name_BRANCH BANKING & TRU' 'st_IL' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY'] | ['servicer_name_CALIBER HOME LOANS' 'cnt_units_2' 'occpy_sts_S' 'seller_name_FLAGSTAR BANK, FSB' 'st_MO' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'st_PA' 'st_MA' 'seller_name_JPMORGAN CHASE BANK,' 'st_GA' 'seller_name_STEARNS LENDING, LLC' 'st_NC' 'seller_name_FRANKLIN AMERICAN MO' 'st_MN' 'st_MD' 'servicer_name_NEW RESIDENTIAL MO' 'st_CO' 'st_OR' 'st_IL' 'st_TN'] | ['st_PA'] |
| 50 | ['servicer_name_NATIONSTAR MORTGAG'] | ['seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'st_CO' 'st_MN' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'st_NC' 'seller_name_JPMORGAN CHASE BANK,' 'st_MA' 'servicer_name_CALIBER HOME LOANS' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FRANKLIN AMERICAN MO' 'st_OR' 'occpy_sts_S' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OH' 'st_VA' 'st_GA' 'st_IL' 'servicer_name_PNC BANK, NA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_STEARNS LENDING, LLC' 'st_PA'] | ['cnt_units_2' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_STEARNS LENDING, LLC' 'servicer_name_CALIBER HOME LOANS' 'st_NC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'st_IL' 'st_MO' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'st_CO' 'st_GA' 'st_MD' 'st_PA' 'st_OH' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_P'] | ['cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'st_NC' 'st_PA' 'st_OR' 'occpy_sts_S' 'seller_name_FLAGSTAR BANK, FSB' 'st_MA' 'seller_name_JPMORGAN CHASE BANK,' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'st_MN' 'st_CO' 'seller_name_CITIMORTGAGE, INC.' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_PNC BANK, NA' 'servicer_name_NEW RESIDENTIAL MO' 'st_TN' 'st_MO' 'occpy_sts_P' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_MA' 'st_NC' 'st_OR' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'st_TN' 'st_GA' 'servicer_name_PNC BANK, NA' 'cnt_units_2' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_SUNTRUST MORTGAGE, I' 'st_PA' 'st_OH' 'st_IL' 'servicer_name_NEW RESIDENTIAL MO' 'st_MD' 'st_CO' 'seller_name_STEARNS LENDING, LLC'] | ['cnt_units_2' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'st_GA' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_S' 'st_MA' 'st_MN' 'servicer_name_PNC BANK, NA' 'st_MO' 'seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'st_AZ' 'st_TN' 'st_IL' 'st_PA'] | ['st_MN'] |
| 51 | ['st_MA'] | ['cnt_units_2' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FLAGSTAR BANK, FSB' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'st_MN' 'servicer_name_PNC BANK, NA' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'st_MD' 'st_NC' 'st_MA' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'st_IL' 'occpy_sts_S' 'seller_name_BRANCH BANKING & TRU' 'seller_name_JPMORGAN CHASE BANK,' 'seller_name_NATIONSTAR MORTGAGE ' 'st_PA' 'cnt_units_3' 'seller_name_SUNTRUST MORTGAGE, I' 'st_CO' 'st_MO'] | ['servicer_name_NATIONSTAR MORTGAG' 'seller_name_JPMORGAN CHASE BANK,' 'st_OR' 'seller_name_FLAGSTAR BANK, FSB' 'st_MA' 'cnt_units_2' 'st_NC' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_CALIBER HOME LOANS' 'occpy_sts_S' 'seller_name_STEARNS LENDING, LLC' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'st_TN' 'servicer_name_PNC BANK, NA' 'st_PA' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'st_MN' 'st_CO' 'st_OH' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'st_CT'] | ['servicer_name_CALIBER HOME LOANS' 'st_OH' 'st_MD' 'occpy_sts_S' 'st_OR' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'st_TN' 'st_NC' 'st_AZ' 'st_MA' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_IL' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_PNC BANK, NA' 'seller_name_CITIMORTGAGE, INC.' 'st_CT' 'servicer_name_LAKEVIEW LOAN SERV'] | ['servicer_name_CALIBER HOME LOANS' 'st_MN' 'occpy_sts_S' 'cnt_units_2' 'st_GA' 'seller_name_FLAGSTAR BANK, FSB' 'st_MA' 'servicer_name_NATIONSTAR MORTGAG' 'st_IL' 'st_OR' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'servicer_name_PNC BANK, NA' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MO' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'st_OH'] | ['st_MD' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'st_OH' 'st_MA' 'st_TN' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_LOANDEPOT.COM, LLC' 'prop_type_MH' 'st_IL' 'cnt_units_3' 'cnt_units_2' 'servicer_name_PNC BANK, NA' 'st_NY' 'st_NV' 'st_NC'] | ['st_MD'] |
| 52 | ['st_MD'] | ['st_OR' 'st_OH' 'servicer_name_PNC BANK, NA' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'seller_name_FLAGSTAR BANK, FSB' 'st_NC' 'occpy_sts_S' 'st_MN' 'st_MA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_NATIONSTAR MORTGAGE ' 'st_CO' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_JPMORGAN CHASE BANK,' 'cnt_units_2' 'st_MD' 'st_PA' 'st_TN' 'servicer_name_NEW RESIDENTIAL MO'] | ['seller_name_FLAGSTAR BANK, FSB' 'servicer_name_PNC BANK, NA' 'st_GA' 'st_OR' 'st_PA' 'st_MD' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'cnt_units_2' 'st_MN' 'st_MA' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_S' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NC' 'seller_name_FRANKLIN AMERICAN MO' 'st_OH' 'st_CO' 'st_WI' 'st_NY' 'st_IL' 'servicer_name_LAKEVIEW LOAN SERV'] | ['seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'st_MD' 'st_GA' 'occpy_sts_S' 'st_AZ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'st_MN' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_JPMORGAN CHASE BANK,' 'st_NC' 'seller_name_FRANKLIN AMERICAN MO' 'cnt_units_2' 'seller_name_STEARNS LENDING, LLC' 'prop_type_MH' 'st_IL' 'st_PA'] | ['st_OR' 'st_MA' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'st_MD' 'st_OH' 'servicer_name_CALIBER HOME LOANS' 'st_MN' 'st_IL' 'st_AZ' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'servicer_name_PNC BANK, NA' 'st_PA' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'st_MO' 'seller_name_JPMORGAN CHASE BANK,'] | ['seller_name_CITIMORTGAGE, INC.' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'cnt_units_2' 'st_OR' 'st_MN' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS' 'st_PA' 'st_AZ' 'st_GA' 'st_NC' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_OH' 'occpy_sts_S' 'st_NV' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_MH' 'st_IL' 'st_NY'] | ['st_MA'] |
| 53 | ['st_MN'] | ['seller_name_FLAGSTAR BANK, FSB' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_CALIBER HOME LOANS' 'st_OH' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MD' 'st_NC' 'st_GA' 'st_AZ' 'st_MN' 'occpy_sts_S' 'cnt_units_2' 'st_VA' 'st_OR' 'servicer_name_PNC BANK, NA' 'st_NV' 'st_MA' 'prop_type_MH' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NEW RESIDENTIAL MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_PA' 'st_WI' 'st_UT' 'st_MO' 'st_TN' 'seller_name_BRANCH BANKING & TRU'] | ['st_MN' 'st_MD' 'seller_name_SUNTRUST MORTGAGE, I' 'st_IL' 'servicer_name_CALIBER HOME LOANS' 'st_GA' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S' 'st_NC' 'st_OR' 'cnt_units_2' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_CT' 'st_MA' 'st_OH' 'st_AZ' 'st_TN' 'st_MO' 'st_PA'] | ['st_NC' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FLAGSTAR BANK, FSB' 'st_OR' 'st_MN' 'st_MA' 'st_AZ' 'st_IL' 'st_TN' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'st_PA' 'st_NY'] | ['occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'servicer_name_NATIONSTAR MORTGAG' 'cnt_units_2' 'st_OR' 'servicer_name_CALIBER HOME LOANS' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'st_MD' 'st_IL' 'st_OH' 'seller_name_FRANKLIN AMERICAN MO' 'st_MA' 'st_MN' 'seller_name_JPMORGAN CHASE BANK,' 'prop_type_MH' 'st_PA' 'seller_name_FLAGSTAR BANK, FSB' 'st_MO'] | ['seller_name_FLAGSTAR BANK, FSB' 'seller_name_NATIONSTAR MORTGAGE ' 'cnt_units_2' 'st_OH' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'st_MD' 'servicer_name_CALIBER HOME LOANS' 'st_NC' 'occpy_sts_S' 'st_NY' 'st_GA' 'st_AZ' 'servicer_name_PNC BANK, NA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MN' 'st_MA' 'seller_name_FRANKLIN AMERICAN MO' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV'] | ['servicer_name_LAKEVIEW LOAN SERV'] |
| 54 | ['occpy_sts_S'] | ['servicer_name_NATIONSTAR MORTGAG' 'seller_name_FLAGSTAR BANK, FSB' 'st_NY' 'st_GA' 'st_MO' 'occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'st_TN' 'st_OR' 'st_NV' 'st_MN' 'st_CT' 'st_MA' 'st_PA' 'cnt_units_2' 'st_IL' 'st_AZ' 'servicer_name_CALIBER HOME LOANS' 'st_OH' 'st_UT' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_CO' 'st_MD' 'seller_name_LOANDEPOT.COM, LLC' 'st_WI' 'st_VA'] | ['seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'cnt_units_2' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'seller_name_FLAGSTAR BANK, FSB' 'st_PA' 'st_MA' 'st_IL' 'servicer_name_CALIBER HOME LOANS' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'st_NY' 'st_OH' 'st_OR' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'st_MO' 'st_KY' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_VA'] | ['st_MN' 'st_MA' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_CALIBER HOME LOANS' 'seller_name_CITIMORTGAGE, INC.' 'st_OR' 'st_AZ' 'st_MD' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'st_NV' 'st_OH' 'st_WI' 'cnt_units_2' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_TN' 'st_NC' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'st_CT' 'st_NY' 'occpy_sts_S'] | ['st_MN' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'st_AZ' 'st_IL' 'cnt_units_2' 'servicer_name_LAKEVIEW LOAN SERV' 'st_PA' 'occpy_sts_S' 'servicer_name_CALIBER HOME LOANS' 'st_MA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'st_MD' 'st_NC' 'st_MO' 'st_NV' 'st_OR' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_MA' 'occpy_sts_S' 'cnt_units_2' 'st_NC' 'st_GA' 'st_MD' 'seller_name_FLAGSTAR BANK, FSB' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'servicer_name_CALIBER HOME LOANS' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'st_OH' 'st_CT' 'st_PA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NV'] | ['servicer_name_CALIBER HOME LOANS'] |
| 55 | ['seller_name_NATIONSTAR MORTGAGE '] | ['st_MN' 'occpy_sts_S' 'st_MA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_PA' 'cnt_units_2' 'st_IL' 'st_OH' 'st_UT' 'st_MD' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'st_AZ' 'seller_name_LOANDEPOT.COM, LLC' 'servicer_name_NATIONSTAR MORTGAG' 'st_GA' 'st_WI' 'servicer_name_CALIBER HOME LOANS' 'st_OR' 'seller_name_BRANCH BANKING & TRU' 'st_NV' 'st_MO' 'st_NY' 'seller_name_FLAGSTAR BANK, FSB'] | ['st_IL' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'st_MD' 'occpy_sts_S' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MA' 'st_OH' 'st_GA' 'st_AZ' 'cnt_units_2' 'st_NY' 'st_NC' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_CALIBER HOME LOANS' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'st_NV' 'st_PA' 'st_WI'] | ['servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'st_MO' 'occpy_sts_S' 'cnt_units_2' 'servicer_name_NATIONSTAR MORTGAG' 'st_IL' 'st_MN' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_CITIMORTGAGE, INC.' 'st_PA' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NC' 'st_MA' 'st_MD' 'st_OR' 'servicer_name_CALIBER HOME LOANS' 'st_NV' 'seller_name_FLAGSTAR BANK, FSB' 'st_WI' 'st_GA' 'st_NY'] | ['st_GA' 'st_OH' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'prop_type_MH' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FLAGSTAR BANK, FSB' 'cnt_units_2' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'servicer_name_CALIBER HOME LOANS' 'st_MD' 'st_NC' 'st_MA' 'st_AZ' 'st_NV' 'st_TN' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG' 'st_NY' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_GA' 'st_OH' 'st_OR' 'st_MD' 'st_AZ' 'st_NV' 'occpy_sts_S' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'st_NY' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS' 'st_CT' 'st_IL' 'seller_name_BRANCH BANKING & TRU' 'st_WI' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FLAGSTAR BANK, FSB'] | ['servicer_name_NATIONSTAR MORTGAG'] |
| 56 | ['st_GA'] | ['st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_TN' 'st_OR' 'seller_name_BRANCH BANKING & TRU' 'st_MD' 'st_NY' 'st_PA' 'servicer_name_NATIONSTAR MORTGAG' 'st_MN' 'st_IL' 'st_AZ' 'occpy_sts_S' 'st_NV' 'cnt_units_2' 'st_NC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'st_MA' 'servicer_name_CALIBER HOME LOANS' 'st_MO' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO'] | ['servicer_name_LAKEVIEW LOAN SERV' 'seller_name_CITIMORTGAGE, INC.' 'st_CT' 'st_GA' 'cnt_units_2' 'st_UT' 'st_AZ' 'st_IL' 'st_NY' 'st_NC' 'st_OH' 'st_MD' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MA' 'st_OR' 'occpy_sts_S' 'seller_name_SUNTRUST MORTGAGE, I' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'st_MN' 'st_NV' 'st_WI' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_OR' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'st_OH' 'st_MO' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S' 'st_PA' 'cnt_units_2' 'st_MD' 'flag_sc' 'st_MA' 'st_GA' 'st_AZ' 'st_NV' 'st_NC' 'seller_name_FLAGSTAR BANK, FSB' 'servicer_name_CALIBER HOME LOANS' 'seller_name_SUNTRUST MORTGAGE, I' 'st_WI' 'seller_name_BRANCH BANKING & TRU' 'prop_type_MH' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_PA' 'st_MD' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'st_NV' 'st_OR' 'st_MA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'occpy_sts_S' 'st_OH' 'st_NY' 'st_IL' 'servicer_name_NATIONSTAR MORTGAG' 'st_AZ' 'seller_name_JPMORGAN CHASE BANK,' 'cnt_units_2' 'servicer_name_CALIBER HOME LOANS'] | ['st_AZ' 'st_MO' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_S' 'st_NC' 'cnt_units_2' 'st_MA' 'st_OR' 'st_MD' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'st_NV' 'servicer_name_LAKEVIEW LOAN SERV' 'st_PA' 'st_WI' 'seller_name_FLAGSTAR BANK, FSB' 'st_TN' 'prop_type_MH'] | ['st_OR'] |
| 57 | ['st_NC'] | ['st_UT' 'st_IL' 'servicer_name_NATIONSTAR MORTGAG' 'cnt_units_2' 'st_NC' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_OR' 'st_MA' 'st_GA' 'st_TN' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'occpy_sts_S' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FLAGSTAR BANK, FSB' 'st_OH' 'servicer_name_CALIBER HOME LOANS' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_CITIMORTGAGE, INC.' 'st_NV' 'seller_name_FRANKLIN AMERICAN MO' 'st_MN'] | ['st_MO' 'st_MN' 'st_NC' 'st_GA' 'st_OH' 'seller_name_SUNTRUST MORTGAGE, I' 'st_AZ' 'cnt_units_2' 'st_WI' 'st_PA' 'st_MA' 'st_IL' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_OR' 'occpy_sts_S' 'st_MD' 'st_NY' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_BRANCH BANKING & TRU'] | ['st_IL' 'occpy_sts_S' 'st_OH' 'st_GA' 'st_MN' 'st_NC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'cnt_units_2' 'st_CT' 'st_MA' 'st_PA' 'st_OR' 'st_NV' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO' 'st_NY' 'st_AZ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_SUNTRUST MORTGAGE, I' 'st_WI' 'prop_type_MH'] | ['seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_S' 'st_MA' 'st_OH' 'st_MD' 'st_OR' 'st_MN' 'servicer_name_NATIONSTAR MORTGAG' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FRANKLIN AMERICAN MO' 'st_VA' 'st_MO' 'cnt_units_2' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_GA' 'st_NC' 'st_IL' 'st_NV' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'flag_sc' 'st_PA' 'st_WI' 'seller_name_FLAGSTAR BANK, FSB'] | ['seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'st_NC' 'st_MA' 'occpy_sts_S' 'st_MD' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'st_WI' 'cnt_units_2' 'seller_name_SUNTRUST MORTGAGE, I' 'st_PA' 'prop_type_MH' 'st_AZ' 'st_NV' 'st_NY'] | ['st_AZ'] |
| 58 | ['servicer_name_CALIBER HOME LOANS'] | ['st_OH' 'st_NC' 'st_OR' 'st_AZ' 'st_MN' 'st_MA' 'seller_name_CITIMORTGAGE, INC.' 'st_WI' 'st_IL' 'occpy_sts_S' 'st_GA' 'st_PA' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'cnt_units_2' 'flag_sc' 'seller_name_FLAGSTAR BANK, FSB' 'st_TN' 'st_NY' 'seller_name_NATIONSTAR MORTGAGE ' 'prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'servicer_name_NATIONSTAR MORTGAG' 'st_NV'] | ['st_NC' 'st_GA' 'st_IL' 'st_MN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MD' 'st_OH' 'seller_name_CITIMORTGAGE, INC.' 'st_WI' 'st_NV' 'servicer_name_NATIONSTAR MORTGAG' 'st_MA' 'st_AZ' 'st_OR' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'cnt_units_2' 'st_PA' 'prop_type_MH' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'st_NY' 'servicer_name_CALIBER HOME LOANS'] | ['seller_name_FRANKLIN AMERICAN MO' 'st_MN' 'st_NY' 'st_IL' 'st_PA' 'st_NC' 'st_AZ' 'occpy_sts_S' 'st_MD' 'st_NV' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'st_GA' 'cnt_units_2' 'seller_name_FLAGSTAR BANK, FSB' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MO' 'st_OR' 'st_WI' 'servicer_name_LAKEVIEW LOAN SERV' 'st_TN' 'st_MA' 'seller_name_BRANCH BANKING & TRU' 'servicer_name_NATIONSTAR MORTGAG'] | ['st_NC' 'st_MN' 'st_MD' 'st_NY' 'st_OH' 'occpy_sts_S' 'st_MA' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'seller_name_BRANCH BANKING & TRU' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'st_UT' 'servicer_name_LAKEVIEW LOAN SERV' 'cnt_units_2' 'st_AZ' 'st_MO' 'flag_sc' 'st_PA' 'st_GA' 'st_NV' 'st_WI' 'prop_type_MH' 'seller_name_FRANKLIN AMERICAN MO' 'st_TN'] | ['st_NC' 'st_PA' 'st_OH' 'st_NY' 'cnt_units_2' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MD' 'st_MO' 'st_MA' 'seller_name_BRANCH BANKING & TRU' 'st_GA' 'st_MN' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'st_WI'] | ['st_CT'] |
| 59 | ['seller_name_SUNTRUST MORTGAGE, I'] | ['st_AZ' 'st_MN' 'st_MA' 'st_GA' 'st_IL' 'servicer_name_NATIONSTAR MORTGAG' 'occpy_sts_S' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MD' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'prop_type_MH' 'st_NY' 'st_OH' 'seller_name_BRANCH BANKING & TRU' 'cnt_units_2' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NC' 'st_OR' 'st_VA' 'st_WI' 'st_PA' 'st_MO'] | ['occpy_sts_S' 'seller_name_SUNTRUST MORTGAGE, I' 'st_PA' 'st_OH' 'st_MO' 'st_NY' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'st_OR' 'st_WI' 'cnt_units_2' 'st_AZ' 'st_MA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NC' 'st_IL' 'st_NV' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'st_MN'] | ['st_GA' 'st_PA' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'st_MD' 'st_IL' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'st_AZ' 'st_OR' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MA' 'st_NC' 'st_MN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'cnt_units_2' 'occpy_sts_S' 'st_OH' 'st_NV' 'st_TN'] | ['st_OH' 'st_IL' 'occpy_sts_S' 'st_NC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_PA' 'st_WI' 'st_MN' 'cnt_units_2' 'st_AZ' 'st_MD' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_BRANCH BANKING & TRU' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'servicer_name_CALIBER HOME LOANS' 'st_NV' 'st_TN'] | ['st_MN' 'st_WI' 'st_NV' 'st_PA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'servicer_name_LAKEVIEW LOAN SERV' 'st_GA' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'st_OH' 'seller_name_BRANCH BANKING & TRU' 'st_AZ' 'st_NC' 'st_MO' 'st_MA' 'st_MD' 'st_VA' 'st_OR' 'st_IL' 'st_TN' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'cnt_units_2'] | ['st_NC'] |
| 60 | ['st_IL'] | ['seller_name_SUNTRUST MORTGAGE, I' 'prop_type_MH' 'st_AZ' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'st_GA' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'st_OH' 'st_MN' 'st_NC' 'st_IL' 'st_NY' 'st_UT' 'st_OR' 'seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'st_MO' 'st_PA' 'st_MA' 'st_WI' 'seller_name_LOANDEPOT.COM, LLC' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'st_TN' 'st_NV'] | ['st_OR' 'st_OH' 'st_WI' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_NATIONSTAR MORTGAG' 'st_PA' 'st_MD' 'st_NV' 'st_NC' 'st_MO' 'st_MA' 'st_IL' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MN' 'seller_name_BRANCH BANKING & TRU' 'st_AZ' 'st_NY' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'occpy_sts_S' 'st_VA' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_WI' 'servicer_name_NATIONSTAR MORTGAG' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'st_GA' 'st_OH' 'st_MA' 'st_NC' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NY' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'prop_type_MH' 'occpy_sts_S' 'st_MD' 'st_OR' 'cnt_units_2' 'st_PA' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'st_CT' 'st_NV'] | ['st_IL' 'st_OH' 'servicer_name_NATIONSTAR MORTGAG' 'st_NC' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NY' 'st_GA' 'st_AZ' 'seller_name_BRANCH BANKING & TRU' 'st_OR' 'st_MD' 'st_NV' 'st_MA' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_CITIMORTGAGE, INC.' 'prop_type_MH' 'st_PA' 'st_MO' 'seller_name_NATIONSTAR MORTGAGE ' 'occpy_sts_S' 'st_MN' 'flag_sc' 'st_WI' 'st_TN'] | ['st_PA' 'seller_name_FRANKLIN AMERICAN MO' 'st_IL' 'st_WI' 'seller_name_LOANDEPOT.COM, LLC' 'st_OH' 'occpy_sts_S' 'st_VA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NC' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_BRANCH BANKING & TRU' 'prop_type_MH' 'st_MD' 'st_GA' 'st_MN' 'st_NV' 'st_AZ' 'st_OR' 'cnt_units_2' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'st_MA' 'seller_name_FLAGSTAR BANK, FSB'] | ['st_OH'] |
| 61 | ['st_OH'] | ['st_MD' 'st_OR' 'st_NV' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_NATIONSTAR MORTGAG' 'st_WI' 'st_MN' 'st_TN' 'occpy_sts_S' 'st_GA' 'st_NY' 'seller_name_NATIONSTAR MORTGAGE ' 'st_PA' 'st_OH' 'st_MO' 'flag_sc' 'st_CT' 'st_AZ' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NC' 'seller_name_SUNTRUST MORTGAGE, I' 'cnt_units_2' 'st_MA' 'st_IL' 'seller_name_LOANDEPOT.COM, LLC'] | ['st_TN' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'st_NC' 'st_PA' 'st_AZ' 'servicer_name_LAKEVIEW LOAN SERV' 'st_NY' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_WI' 'st_NV' 'seller_name_FRANKLIN AMERICAN MO' 'st_MD' 'st_IL' 'occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'st_MA' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR'] | ['st_MO' 'st_NC' 'st_IL' 'st_WI' 'seller_name_SUNTRUST MORTGAGE, I' 'st_AZ' 'st_GA' 'st_OH' 'st_NV' 'st_NY' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_BRANCH BANKING & TRU' 'st_PA' 'st_MN' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_NATIONSTAR MORTGAG' 'st_OR' 'seller_name_FRANKLIN AMERICAN MO'] | ['seller_name_CITIMORTGAGE, INC.' 'st_PA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_TN' 'st_GA' 'st_MO' 'st_OH' 'st_WI' 'st_IL' 'servicer_name_NATIONSTAR MORTGAG' 'st_NC' 'st_NY' 'st_NV' 'st_MN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_VA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'st_MA' 'seller_name_BRANCH BANKING & TRU' 'occpy_sts_S'] | ['st_IL' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'st_OR' 'seller_name_FRANKLIN AMERICAN MO' 'st_OH' 'occpy_sts_S' 'servicer_name_LAKEVIEW LOAN SERV' 'st_WI' 'seller_name_BRANCH BANKING & TRU' 'st_AZ' 'seller_name_CITIMORTGAGE, INC.' 'st_MO' 'st_NV' 'st_MN' 'st_NC' 'st_MA' 'cnt_units_2' 'seller_name_NATIONSTAR MORTGAGE ' 'st_PA' 'servicer_name_NATIONSTAR MORTGAG' 'prop_type_MH' 'st_MD'] | ['occpy_sts_S'] |
| 62 | ['st_AZ'] | ['st_NC' 'seller_name_BRANCH BANKING & TRU' 'st_MD' 'servicer_name_LAKEVIEW LOAN SERV' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'st_MN' 'flag_sc' 'st_MO' 'st_AZ' 'st_OH' 'st_TN' 'st_NV' 'st_NY' 'st_WI' 'prop_type_MH' 'seller_name_SUNTRUST MORTGAGE, I' 'occpy_sts_S' 'st_MA' 'servicer_name_NATIONSTAR MORTGAG' 'st_IN' 'seller_name_CITIMORTGAGE, INC.' 'st_GA'] | ['st_OH' 'st_IL' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'servicer_name_NATIONSTAR MORTGAG' 'st_NV' 'st_PA' 'st_WI' 'flag_sc' 'servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'st_NC' 'prop_type_MH' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MO' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_BRANCH BANKING & TRU' 'st_MN' 'occpy_sts_S' 'st_MD' 'st_MA'] | ['st_AZ' 'st_NY' 'seller_name_BRANCH BANKING & TRU' 'flag_sc' 'st_MN' 'st_NC' 'st_IL' 'st_MO' 'servicer_name_LAKEVIEW LOAN SERV' 'seller_name_FRANKLIN AMERICAN MO' 'cnt_units_3' 'st_TN' 'occpy_sts_S' 'st_MA' 'st_OH' 'st_PA' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_GA' 'st_NV' 'st_OR' 'st_WI' 'st_MD'] | ['st_MD' 'st_KY' 'st_WI' 'st_PA' 'st_IL' 'st_NV' 'st_NC' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_BRANCH BANKING & TRU' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'servicer_name_LAKEVIEW LOAN SERV' 'st_MO' 'st_OH' 'st_MN' 'prop_type_MH' 'st_AZ' 'occpy_sts_S' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_TN' 'servicer_name_NATIONSTAR MORTGAG' 'flag_sc' 'seller_name_LOANDEPOT.COM, LLC'] | ['occpy_sts_S' 'st_NC' 'st_AZ' 'seller_name_FRANKLIN AMERICAN MO' 'servicer_name_LAKEVIEW LOAN SERV' 'st_GA' 'seller_name_BRANCH BANKING & TRU' 'st_NY' 'st_NV' 'st_OH' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MD' 'st_MN' 'st_IL' 'st_MO' 'st_TN' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'servicer_name_NATIONSTAR MORTGAG' 'st_PA' 'st_WI' 'prop_type_MH'] | ['st_GA'] |
| 63 | ['st_PA'] | ['servicer_name_LAKEVIEW LOAN SERV' 'st_NC' 'st_NY' 'st_OH' 'prop_type_MH' 'st_GA' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_PA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_IL' 'servicer_name_NATIONSTAR MORTGAG' 'flag_sc' 'st_AZ' 'st_WI' 'st_NV' 'st_MN' 'seller_name_FRANKLIN AMERICAN MO' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_LOANDEPOT.COM, LLC'] | ['st_AZ' 'st_MD' 'st_MO' 'st_IL' 'st_TN' 'st_GA' 'st_NC' 'st_WI' 'st_OH' 'st_NY' 'st_PA' 'st_UT' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_BRANCH BANKING & TRU' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MN' 'flag_sc' 'st_VA' 'occpy_sts_S' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_LOANDEPOT.COM, LLC' 'st_NV' 'seller_name_FRANKLIN AMERICAN MO' 'st_KY' 'prop_type_MH' 'servicer_name_NATIONSTAR MORTGAG'] | ['flag_sc' 'st_GA' 'st_NV' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'st_OH' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'st_NC' 'st_PA' 'st_WI' 'st_MN' 'seller_name_SUNTRUST MORTGAGE, I' 'st_AZ' 'st_MD' 'st_IL' 'st_CT' 'servicer_name_NATIONSTAR MORTGAG' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_TN' 'st_VA' 'servicer_name_LAKEVIEW LOAN SERV'] | ['seller_name_FRANKLIN AMERICAN MO' 'st_NY' 'st_UT' 'st_AZ' 'st_TN' 'st_NC' 'seller_name_SUNTRUST MORTGAGE, I' 'st_IL' 'st_WI' 'st_OH' 'prop_type_MH' 'flag_sc' 'st_GA' 'st_MN' 'st_PA' 'servicer_name_LAKEVIEW LOAN SERV' 'st_KY' 'st_MO' 'st_NV' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_BRANCH BANKING & TRU' 'seller_name_CITIMORTGAGE, INC.' 'st_MD' 'st_OR' 'servicer_name_NATIONSTAR MORTGAG'] | ['st_OH' 'occpy_sts_S' 'st_PA' 'st_IL' 'st_NV' 'servicer_name_LAKEVIEW LOAN SERV' 'flag_sc' 'seller_name_BRANCH BANKING & TRU' 'seller_name_NATIONSTAR MORTGAGE ' 'st_AZ' 'servicer_name_NATIONSTAR MORTGAG' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MN' 'st_CT' 'st_NY' 'st_NC' 'st_WI' 'st_MD' 'st_TN' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'prop_type_MH'] | ['st_NV'] |
| 64 | ['seller_name_FRANKLIN AMERICAN MO'] | ['st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'occpy_sts_S' 'st_MN' 'st_MO' 'st_PA' 'seller_name_BRANCH BANKING & TRU' 'st_OH' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'prop_type_MH' 'flag_sc' 'st_KY' 'servicer_name_LAKEVIEW LOAN SERV' 'st_AZ' 'servicer_name_NATIONSTAR MORTGAG' 'st_NV' 'st_MD' 'st_WI' 'seller_name_FRANKLIN AMERICAN MO' 'st_NY' 'seller_name_CITIMORTGAGE, INC.' 'st_NC' 'st_IL' 'st_MA' 'cnt_units_3'] | ['st_MD' 'st_PA' 'st_IL' 'st_TN' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'st_MN' 'st_UT' 'st_NY' 'st_CT' 'servicer_name_NATIONSTAR MORTGAG' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_AZ' 'st_WI' 'st_NV' 'st_GA' 'seller_name_CITIMORTGAGE, INC.' 'flag_sc' 'prop_type_MH' 'servicer_name_LAKEVIEW LOAN SERV' 'st_OH' 'st_NC'] | ['occpy_sts_S' 'seller_name_BRANCH BANKING & TRU' 'prop_type_MH' 'st_IL' 'st_TN' 'st_MO' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'seller_name_FRANKLIN AMERICAN MO' 'st_OH' 'st_AZ' 'flag_sc' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NC' 'st_NV' 'st_WI' 'st_KY' 'st_PA' 'st_MN' 'seller_name_CITIMORTGAGE, INC.'] | ['prop_type_MH' 'seller_name_FRANKLIN AMERICAN MO' 'flag_sc' 'st_IL' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_BRANCH BANKING & TRU' 'st_AZ' 'st_NC' 'st_NY' 'seller_name_CITIMORTGAGE, INC.' 'st_WI' 'st_MD' 'st_PA' 'st_OH' 'st_MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'st_GA' 'servicer_name_LAKEVIEW LOAN SERV' 'occpy_sts_S' 'st_NV' 'st_MN' 'st_VA' 'servicer_name_NATIONSTAR MORTGAG'] | ['st_WI' 'servicer_name_NATIONSTAR MORTGAG' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'st_OH' 'st_PA' 'st_NV' 'st_NY' 'st_MO' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'st_IL' 'st_TN' 'seller_name_BRANCH BANKING & TRU' 'st_NC' 'st_AZ' 'occpy_sts_S' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'st_MD'] | ['prop_type_MH'] |
| 65 | ['st_NY'] | ['st_IL' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'occpy_sts_S' 'seller_name_BRANCH BANKING & TRU' 'flag_sc' 'seller_name_LOANDEPOT.COM, LLC' 'st_TN' 'st_PA' 'st_NC' 'seller_name_SUNTRUST MORTGAGE, I' 'st_MO' 'st_MN' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA' 'st_WI' 'st_AZ' 'st_UT' 'st_NV' 'st_NY' 'seller_name_NATIONSTAR MORTGAGE ' 'servicer_name_LAKEVIEW LOAN SERV' 'st_IN'] | ['st_GA' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'flag_sc' 'st_PA' 'st_NV' 'seller_name_BRANCH BANKING & TRU' 'seller_name_FRANKLIN AMERICAN MO' 'st_WI' 'cnt_units_3' 'st_MO' 'st_MD' 'prop_type_MH' 'st_NC' 'st_TN' 'st_KY' 'servicer_name_NATIONSTAR MORTGAG'] | ['st_NY' 'st_MO' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'st_TN' 'st_NV' 'st_PA' 'st_GA' 'flag_sc' 'st_MD' 'seller_name_SUNTRUST MORTGAGE, I' 'st_OH' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_BRANCH BANKING & TRU' 'seller_name_NATIONSTAR MORTGAGE ' 'st_IL' 'st_WI' 'st_NC' 'st_UT' 'prop_type_MH' 'st_KY' 'st_VA' 'occpy_sts_S'] | ['st_AZ' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'flag_sc' 'st_OH' 'st_IL' 'st_GA' 'st_NV' 'st_WI' 'prop_type_MH' 'st_PA' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_NY' 'st_MN' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MD' 'st_NC'] | ['st_NY' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO' 'st_TN' 'st_MO' 'st_PA' 'st_AZ' 'st_OH' 'st_MN' 'st_WI' 'st_IL' 'flag_sc' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NV' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_BRANCH BANKING & TRU' 'prop_type_MH' 'st_GA' 'st_MA' 'st_MD'] | ['seller_name_BRANCH BANKING & TRU'] |
| 66 | ['st_WI'] | ['flag_sc' 'st_GA' 'st_MO' 'st_PA' 'st_TN' 'st_AZ' 'cnt_units_3' 'st_WI' 'st_IL' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_BRANCH BANKING & TRU' 'st_OH' 'seller_name_FRANKLIN AMERICAN MO' 'st_NV' 'seller_name_LOANDEPOT.COM, LLC' 'st_NC' 'st_UT' 'st_CT' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.'] | ['st_WI' 'prop_type_MH' 'st_NV' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NY' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MO' 'st_PA' 'st_IL' 'flag_sc' 'st_KY' 'st_AZ' 'seller_name_BRANCH BANKING & TRU' 'st_MD' 'st_NC' 'seller_name_LOANDEPOT.COM, LLC' 'st_OH' 'st_VA' 'st_GA'] | ['st_OH' 'st_KY' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_BRANCH BANKING & TRU' 'seller_name_NATIONSTAR MORTGAGE ' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO' 'st_MO' 'st_NY' 'st_IL' 'seller_name_LOANDEPOT.COM, LLC' 'st_WI' 'st_PA' 'st_UT' 'st_TN' 'st_NV' 'st_AZ' 'st_NC' 'st_VA' 'st_GA' 'prop_type_MH' 'st_CT'] | ['st_MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'occpy_sts_S' 'st_PA' 'st_WI' 'st_NC' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'seller_name_SUNTRUST MORTGAGE, I' 'flag_sc' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_CITIMORTGAGE, INC.' 'st_CT' 'st_GA' 'st_OH' 'prop_type_MH' 'st_NV'] | ['flag_sc' 'st_IL' 'st_NY' 'st_AZ' 'st_VA' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_BRANCH BANKING & TRU' 'st_PA' 'st_NV' 'st_WI' 'st_NC' 'seller_name_CITIMORTGAGE, INC.' 'st_MO' 'seller_name_SUNTRUST MORTGAGE, I' 'prop_type_MH' 'seller_name_LOANDEPOT.COM, LLC' 'st_OH' 'st_GA' 'st_MN' 'seller_name_NATIONSTAR MORTGAGE '] | ['seller_name_SUNTRUST MORTGAGE, I'] |
| 67 | ['st_NV'] | ['st_NY' 'seller_name_BRANCH BANKING & TRU' 'st_NV' 'st_TN' 'flag_sc' 'st_KY' 'st_IL' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_SUNTRUST MORTGAGE, I' 'st_GA' 'st_PA' 'st_MO' 'seller_name_CITIMORTGAGE, INC.' 'st_WI' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_MN' 'st_OH'] | ['flag_sc' 'st_TN' 'st_WI' 'st_NV' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_PA' 'st_OH' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'st_IL' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_LOANDEPOT.COM, LLC' 'st_MN' 'st_KY' 'st_GA' 'prop_type_MH'] | ['seller_name_SUNTRUST MORTGAGE, I' 'flag_sc' 'st_NY' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_TN' 'st_WI' 'st_AZ' 'st_OH' 'st_PA' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'st_IL' 'st_CT' 'prop_type_MH' 'st_UT' 'st_NV' 'st_KY' 'st_GA'] | ['st_WI' 'flag_sc' 'st_PA' 'st_MO' 'st_NY' 'seller_name_BRANCH BANKING & TRU' 'seller_name_CITIMORTGAGE, INC.' 'st_NV' 'st_AZ' 'st_TN' 'st_OH' 'st_IL' 'st_KY' 'prop_type_MH' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_FRANKLIN AMERICAN MO' 'st_GA'] | ['st_MO' 'st_NV' 'st_TN' 'st_OH' 'flag_sc' 'st_AZ' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_SUNTRUST MORTGAGE, I' 'st_WI' 'st_PA' 'seller_name_BRANCH BANKING & TRU' 'st_NY' 'st_KY' 'st_IL' 'seller_name_LOANDEPOT.COM, LLC' 'prop_type_MH' 'st_GA' 'seller_name_CITIMORTGAGE, INC.'] | ['st_MO'] |
| 68 | ['st_TN'] | ['st_WI' 'seller_name_SUNTRUST MORTGAGE, I' 'flag_sc' 'st_NV' 'st_OH' 'st_PA' 'seller_name_FRANKLIN AMERICAN MO' 'st_TN' 'st_NY' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'st_KY' 'st_AZ' 'seller_name_CITIMORTGAGE, INC.' 'st_IL' 'st_UT' 'prop_type_MH'] | ['st_NY' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_BRANCH BANKING & TRU' 'prop_type_MH' 'st_WI' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'st_PA' 'flag_sc' 'st_AZ' 'st_NV' 'st_TN' 'st_MO' 'st_GA' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'st_NC' 'st_CT'] | ['st_PA' 'prop_type_MH' 'st_WI' 'flag_sc' 'st_OH' 'st_NY' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_BRANCH BANKING & TRU' 'st_NV' 'st_MO' 'st_TN' 'seller_name_CITIMORTGAGE, INC.' 'st_AZ' 'st_UT' 'st_GA' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_IL'] | ['st_TN' 'st_NV' 'st_AZ' 'st_WI' 'seller_name_BRANCH BANKING & TRU' 'seller_name_FRANKLIN AMERICAN MO' 'st_NY' 'st_MO' 'flag_sc' 'st_PA' 'seller_name_SUNTRUST MORTGAGE, I' 'st_IL' 'st_MN' 'prop_type_MH' 'seller_name_NATIONSTAR MORTGAGE ' 'st_OH' 'seller_name_LOANDEPOT.COM, LLC' 'st_GA'] | ['seller_name_SUNTRUST MORTGAGE, I' 'prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'flag_sc' 'st_NY' 'st_PA' 'st_WI' 'st_OH' 'st_AZ' 'st_TN' 'st_NV' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_LOANDEPOT.COM, LLC' 'st_IL' 'seller_name_NATIONSTAR MORTGAGE ' 'st_KY'] | ['st_TN'] |
| 69 | ['st_MO'] | ['st_MO' 'flag_sc' 'seller_name_BRANCH BANKING & TRU' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'st_WI' 'st_IL' 'st_NY' 'st_NV' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_LOANDEPOT.COM, LLC' 'st_PA' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'st_UT' 'st_CT'] | ['seller_name_SUNTRUST MORTGAGE, I' 'flag_sc' 'st_NY' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'st_NV' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'st_KY' 'st_MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'st_CT' 'prop_type_MH' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'st_PA' 'st_UT'] | ['st_TN' 'st_NV' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'st_MO' 'st_WI' 'seller_name_BRANCH BANKING & TRU' 'seller_name_SUNTRUST MORTGAGE, I' 'st_NY' 'prop_type_MH' 'st_OH' 'seller_name_NATIONSTAR MORTGAGE ' 'st_GA' 'st_IL' 'st_PA' 'st_UT' 'seller_name_LOANDEPOT.COM, LLC'] | ['st_NY' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NV' 'st_WI' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_PA' 'prop_type_MH' 'seller_name_SUNTRUST MORTGAGE, I' 'st_UT' 'st_TN' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_TN' 'st_AZ' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NV' 'st_IL' 'st_MO' 'st_NY' 'st_WI' 'st_IN' 'st_UT' 'seller_name_SUNTRUST MORTGAGE, I' 'st_CT' 'flag_sc' 'seller_name_BRANCH BANKING & TRU' 'seller_name_FRANKLIN AMERICAN MO' 'st_PA' 'prop_type_MH'] | ['st_NY'] |
| 70 | ['seller_name_LOANDEPOT.COM, LLC'] | ['seller_name_BRANCH BANKING & TRU' 'st_PA' 'seller_name_LOANDEPOT.COM, LLC' 'flag_sc' 'st_NV' 'st_OH' 'st_MO' 'st_WI' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'prop_type_MH' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_CITIMORTGAGE, INC.'] | ['st_NV' 'flag_sc' 'st_WI' 'st_MO' 'st_TN' 'st_NY' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_PA' 'prop_type_MH' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_FRANKLIN AMERICAN MO' 'st_KY' 'st_AZ' 'st_UT'] | ['seller_name_BRANCH BANKING & TRU' 'st_TN' 'st_AZ' 'seller_name_FRANKLIN AMERICAN MO' 'st_NV' 'st_NY' 'flag_sc' 'st_PA' 'st_UT' 'seller_name_LOANDEPOT.COM, LLC' 'st_MO' 'st_WI' 'prop_type_MH' 'st_IN' 'seller_name_CITIMORTGAGE, INC.' 'st_OH' 'st_CT'] | ['flag_sc' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'seller_name_FRANKLIN AMERICAN MO' 'st_AZ' 'prop_type_MH' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'st_KY' 'st_NV' 'st_WI' 'seller_name_SUNTRUST MORTGAGE, I' 'st_PA' 'st_NY' 'seller_name_LOANDEPOT.COM, LLC' 'cnt_units_3' 'st_UT' 'st_MN'] | ['st_NV' 'st_UT' 'st_WI' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NY' 'st_KY' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'prop_type_MH' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_CITIMORTGAGE, INC.' 'st_MO' 'st_PA' 'cnt_units_3' 'seller_name_SUNTRUST MORTGAGE, I'] | ['st_IL'] |
| 71 | ['seller_name_BRANCH BANKING & TRU'] | ['st_NV' 'st_WI' 'st_MO' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_BRANCH BANKING & TRU' 'flag_sc' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_TN' 'st_PA' 'st_KY' 'st_UT' 'st_AZ' 'st_VA' 'cnt_units_3'] | ['seller_name_LOANDEPOT.COM, LLC' 'st_WI' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NV' 'prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'st_UT' 'st_TN' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.' 'st_NY' 'st_MO' 'st_AZ'] | ['st_NV' 'seller_name_NATIONSTAR MORTGAGE ' 'st_TN' 'seller_name_LOANDEPOT.COM, LLC' 'prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO' 'st_NY' 'st_WI' 'st_MO' 'st_OH' 'st_KY' 'st_UT' 'seller_name_SUNTRUST MORTGAGE, I' 'seller_name_CITIMORTGAGE, INC.'] | ['st_NV' 'st_WI' 'seller_name_LOANDEPOT.COM, LLC' 'flag_sc' 'st_KY' 'seller_name_BRANCH BANKING & TRU' 'st_MO' 'st_TN' 'st_AZ' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_FRANKLIN AMERICAN MO' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'st_VA' 'prop_type_MH' 'st_NY'] | ['seller_name_BRANCH BANKING & TRU' 'flag_sc' 'st_MO' 'seller_name_CITIMORTGAGE, INC.' 'st_TN' 'st_WI' 'st_UT' 'st_NV' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'prop_type_MH' 'st_OH' 'st_NY' 'st_KY' 'st_CT'] | ['flag_sc'] |
| 72 | ['prop_type_MH'] | ['seller_name_FRANKLIN AMERICAN MO' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'st_NV' 'st_KY' 'seller_name_CITIMORTGAGE, INC.' 'st_MO' 'seller_name_BRANCH BANKING & TRU' 'st_VA' 'st_PA' 'prop_type_MH' 'st_TN' 'cnt_units_3' 'st_IN' 'flag_sc'] | ['seller_name_BRANCH BANKING & TRU' 'seller_name_LOANDEPOT.COM, LLC' 'st_MO' 'flag_sc' 'seller_name_FRANKLIN AMERICAN MO' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'st_NV' 'prop_type_MH' 'st_NY' 'st_TN' 'seller_name_CITIMORTGAGE, INC.' 'st_KY'] | ['seller_name_LOANDEPOT.COM, LLC' 'st_WI' 'st_PA' 'seller_name_NATIONSTAR MORTGAGE ' 'prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'seller_name_FRANKLIN AMERICAN MO' 'flag_sc' 'st_UT' 'st_KY' 'st_MO' 'st_VA' 'st_NV' 'seller_name_CITIMORTGAGE, INC.'] | ['seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'flag_sc' 'st_WI' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO' 'st_IN' 'st_UT' 'prop_type_MH' 'st_VA'] | ['seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_WI' 'flag_sc' 'st_TN' 'prop_type_MH' 'st_NV' 'st_UT' 'st_NY' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_KY' 'st_MO' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_WI'] |
| 73 | ['st_UT'] | ['seller_name_LOANDEPOT.COM, LLC' 'st_TN' 'st_UT' 'st_IN' 'prop_type_MH' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'st_KY' 'st_VA' 'flag_sc' 'st_WI' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_BRANCH BANKING & TRU' 'cnt_units_3' 'st_CT'] | ['prop_type_MH' 'seller_name_BRANCH BANKING & TRU' 'seller_name_LOANDEPOT.COM, LLC' 'st_IN' 'flag_sc' 'st_VA' 'seller_name_FRANKLIN AMERICAN MO' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'st_WI' 'st_CT' 'st_NV' 'st_KY' 'seller_name_CITIMORTGAGE, INC.' 'st_PA'] | ['st_VA' 'seller_name_FRANKLIN AMERICAN MO' 'seller_name_NATIONSTAR MORTGAGE ' 'prop_type_MH' 'st_WI' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_UT' 'st_KY' 'st_CT' 'st_NV' 'st_IN' 'st_TN' 'st_MO'] | ['seller_name_BRANCH BANKING & TRU' 'seller_name_LOANDEPOT.COM, LLC' 'st_KY' 'st_VA' 'prop_type_MH' 'st_TN' 'st_WI' 'seller_name_CITIMORTGAGE, INC.' 'st_UT' 'seller_name_NATIONSTAR MORTGAGE ' 'flag_sc'] | ['prop_type_MH' 'st_TN' 'seller_name_LOANDEPOT.COM, LLC' 'st_KY' 'seller_name_BRANCH BANKING & TRU' 'seller_name_NATIONSTAR MORTGAGE ' 'st_NV' 'seller_name_CITIMORTGAGE, INC.' 'st_UT' 'st_IL' 'st_VA' 'st_WI' 'st_CT' 'cnt_units_3' 'st_IN'] | ['seller_name_FRANKLIN AMERICAN MO'] |
| 74 | ['flag_sc'] | ['st_VA' 'st_KY' 'prop_type_MH' 'st_UT' 'seller_name_CITIMORTGAGE, INC.' 'seller_name_LOANDEPOT.COM, LLC' 'st_IN' 'seller_name_BRANCH BANKING & TRU' 'cnt_units_3' 'st_WI'] | ['st_UT' 'st_VA' 'prop_type_MH' 'st_KY' 'st_IN' 'cnt_units_3' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_FRANKLIN AMERICAN MO' 'st_WI' 'flag_sc' 'seller_name_CITIMORTGAGE, INC.'] | ['prop_type_MH' 'seller_name_LOANDEPOT.COM, LLC' 'st_KY' 'st_VA' 'st_UT' 'st_IN' 'st_NV' 'st_CT' 'seller_name_BRANCH BANKING & TRU' 'cnt_units_3' 'st_WI' 'seller_name_FRANKLIN AMERICAN MO'] | ['st_VA' 'prop_type_MH' 'st_KY' 'st_UT' 'seller_name_LOANDEPOT.COM, LLC' 'st_IN' 'st_CT' 'seller_name_CITIMORTGAGE, INC.' 'cnt_units_3' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_IN' 'seller_name_LOANDEPOT.COM, LLC' 'st_VA' 'prop_type_MH' 'st_CT' 'st_KY' 'st_UT' 'st_WI' 'st_TN' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.'] | ['seller_name_LOANDEPOT.COM, LLC'] |
| 75 | ['st_CT'] | ['st_KY' 'st_VA' 'prop_type_MH' 'st_UT' 'cnt_units_3' 'st_IN' 'st_CT'] | ['st_KY' 'st_UT' 'st_VA' 'prop_type_MH' 'cnt_units_3' 'st_CT' 'st_IN'] | ['st_KY' 'cnt_units_3' 'st_VA' 'st_IN' 'st_UT' 'st_CT' 'prop_type_MH' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_BRANCH BANKING & TRU' 'st_WI'] | ['st_UT' 'prop_type_MH' 'st_VA' 'st_KY' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_CITIMORTGAGE, INC.' 'st_IN' 'cnt_units_3' 'seller_name_LOANDEPOT.COM, LLC' 'st_CT'] | ['st_UT' 'st_KY' 'prop_type_MH' 'st_VA' 'st_CT' 'st_IN' 'seller_name_LOANDEPOT.COM, LLC' 'seller_name_NATIONSTAR MORTGAGE ' 'seller_name_BRANCH BANKING & TRU' 'cnt_units_3'] | ['st_UT'] |
| 76 | ['st_VA'] | ['prop_type_MH' 'st_UT' 'st_IN' 'st_KY' 'st_VA' 'st_CT' 'cnt_units_4' 'cnt_units_3'] | ['st_VA' 'st_KY' 'st_UT' 'st_IN' 'st_CT' 'prop_type_MH' 'cnt_units_3'] | ['st_UT' 'st_IN' 'st_VA' 'st_KY' 'st_CT' 'prop_type_MH' 'seller_name_FRANKLIN AMERICAN MO' 'cnt_units_3'] | ['st_KY' 'st_VA' 'st_UT' 'st_CT' 'cnt_units_3' 'st_IN' 'prop_type_MH' 'seller_name_NATIONSTAR MORTGAGE '] | ['st_VA' 'st_IN' 'st_UT' 'st_CT' 'st_KY' 'prop_type_MH' 'cnt_units_3'] | ['st_KY'] |
| 77 | ['st_KY'] | ['st_CT' 'st_VA' 'st_IN' 'st_KY' 'st_UT' 'cnt_units_4'] | ['st_CT' 'st_IN' 'st_KY' 'st_VA' 'st_UT' 'cnt_units_3' 'prop_type_MH'] | ['st_CT' 'st_IN' 'st_KY' 'cnt_units_3' 'st_VA' 'st_UT'] | ['st_CT' 'st_IN' 'st_UT' 'st_VA' 'cnt_units_3' 'prop_type_MH' 'st_KY'] | ['st_KY' 'st_IN' 'st_UT' 'st_CT' 'cnt_units_3' 'st_VA'] | ['st_IN'] |
| 78 | ['st_IN'] | ['st_IN' 'st_CT' 'st_UT' 'st_VA' 'cnt_units_3' 'cnt_units_4' 'st_KY'] | ['st_IN' 'st_VA' 'st_KY' 'st_CT' 'st_UT' 'cnt_units_3' 'cnt_units_4'] | ['st_IN' 'st_VA' 'st_CT' 'st_KY' 'st_UT' 'cnt_units_3' 'cnt_units_4'] | ['cnt_units_3' 'st_IN' 'st_CT' 'st_KY' 'st_VA' 'cnt_units_4'] | ['st_CT' 'st_IN' 'cnt_units_3' 'st_UT' 'st_KY' 'st_VA'] | ['st_VA'] |
| 79 | ['cnt_units_3'] | ['cnt_units_3' 'cnt_units_4' 'st_IN' 'st_CT' 'st_KY'] | ['cnt_units_3' 'cnt_units_4' 'st_IN' 'st_CT'] | ['cnt_units_3' 'st_IN' 'st_CT' 'cnt_units_4' 'st_KY'] | ['st_IN' 'cnt_units_3' 'st_CT' 'cnt_units_4' 'st_UT' 'st_KY'] | ['cnt_units_4' 'cnt_units_3' 'st_IN' 'st_CT' 'st_VA'] | ['cnt_units_3'] |
| 80 | ['cnt_units_4'] | ['cnt_units_4' 'cnt_units_3' 'st_CT'] | ['cnt_units_4' 'cnt_units_3'] | ['cnt_units_4' 'cnt_units_3' 'st_CT'] | ['cnt_units_4' 'cnt_units_3'] | ['cnt_units_3' 'cnt_units_4' 'st_IN'] | ['cnt_units_4'] |
| 81 | ['seller_name_GUARANTEED RATE, INC'] | ['seller_name_GUARANTEED RATE, INC' 'st_SC' 'prop_type_CP'] | ['st_SC' 'prop_type_CP' 'seller_name_GUARANTEED RATE, INC'] | ['st_SC' 'prop_type_CP' 'seller_name_GUARANTEED RATE, INC'] | ['seller_name_GUARANTEED RATE, INC' 'st_SC' 'prop_type_CP'] | ['seller_name_GUARANTEED RATE, INC' 'st_SC' 'prop_type_CP'] | ['st_SC'] |
| 82 | ['st_SC'] | ['st_SC' 'prop_type_CP' 'seller_name_GUARANTEED RATE, INC'] | ['seller_name_GUARANTEED RATE, INC' 'prop_type_CP' 'st_SC'] | ['prop_type_CP' 'seller_name_GUARANTEED RATE, INC' 'st_SC'] | ['prop_type_CP' 'seller_name_GUARANTEED RATE, INC' 'st_SC'] | ['st_SC' 'prop_type_CP' 'seller_name_GUARANTEED RATE, INC'] | ['seller_name_GUARANTEED RATE, INC'] |
| 83 | ['prop_type_CP'] | ['prop_type_CP' 'seller_name_GUARANTEED RATE, INC' 'st_SC'] | ['prop_type_CP' 'st_SC' 'seller_name_GUARANTEED RATE, INC'] | ['seller_name_GUARANTEED RATE, INC' 'st_SC' 'prop_type_CP'] | ['st_SC' 'prop_type_CP' 'seller_name_GUARANTEED RATE, INC'] | ['prop_type_CP' 'seller_name_GUARANTEED RATE, INC' 'st_SC'] | ['prop_type_CP'] |
----------------------------------------------------------------------- Table 4: Ranking Variation over 100 SHAP iterations.
The second table shows the variance in the SHAP values for each feature over the 100 simulations. We observe for lower background sample sizes (m = 50, m = 500) higher variances as for higher background data sizes. In our case, after using more than 1500 observations, the variance does not significally decrease anymore.
As described above, when using the whole training data as background data, or using the tree path dependent approach with no background data, SHAP TreeExplainer gives stable results for each iteration.
# producing the final variance table
with pd.option_context('display.max_rows', None,
'display.max_columns', None):
display(final_data_var.style.format(precision=0, na_rep='Missings',
thousands=" ",
formatter={('Variance sum (m=none)'): "{:.3f}",
('Variance sum (m=50)'): "{:.3f}",
('Variance sum (m=500)'): "{:.3f}",
('Variance sum (m=1500)'): "{:.3f}",
('Variance sum (m=15000)'): "{:.3f}",
('Variance sum (m=75000)'): "{:.3f}",
('Variance sum (m=all)'): "{:.3f}"
})\
.set_table_styles([dict(selector='th',
props=[('text-align', 'right')])])
)
print("-----------------------------------------------------------------------")
print("Table 5: Variance in SHAP values over 100 iterations.")
| Variance sum (m=none) | Variance sum (m=50) | Variance sum (m=500) | Variance sum (m=1500) | Variance sum (m=15000) | Variance sum (m=75000) | Variance sum (m=all) | |
|---|---|---|---|---|---|---|---|
| features | |||||||
| fico | 0.000 | 983.416 | 501.573 | 453.535 | 453.343 | 489.776 | 0.000 |
| flag_fthb | 0.000 | 2.179 | 1.017 | 1.237 | 0.999 | 1.120 | 0.000 |
| mi_pct | 0.000 | 19.140 | 6.416 | 8.681 | 5.005 | 6.102 | 0.000 |
| cltv_pct | 0.000 | 303.590 | 75.057 | 82.316 | 58.467 | 50.203 | 0.000 |
| dti_pct | 0.000 | 59.649 | 33.841 | 28.724 | 24.350 | 23.756 | 0.000 |
| orig_upb | 0.000 | 14.460 | 32.944 | 5.726 | 8.327 | 19.849 | 0.000 |
| int_rt_pct | 0.000 | 123.468 | 65.723 | 59.527 | 53.363 | 52.144 | 0.000 |
| orig_loan_term | 0.000 | 58.314 | 31.509 | 22.702 | 27.541 | 25.967 | 0.000 |
| cnt_borr | 0.000 | 256.535 | 144.850 | 124.290 | 113.747 | 111.913 | 0.000 |
| flag_sc | 0.000 | 0.012 | 0.009 | 0.007 | 0.009 | 0.006 | 0.000 |
| rel_ref_ind | 0.000 | 22.371 | 12.570 | 13.943 | 11.095 | 9.213 | 0.000 |
| cnt_units_2 | 0.000 | 0.999 | 0.585 | 0.387 | 0.409 | 0.258 | 0.000 |
| cnt_units_3 | 0.000 | 0.014 | 0.002 | 0.003 | 0.001 | 0.013 | 0.000 |
| cnt_units_4 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| occpy_sts_P | 0.000 | 0.565 | 0.302 | 0.303 | 0.238 | 0.183 | 0.000 |
| occpy_sts_S | 0.000 | 0.174 | 0.133 | 0.128 | 0.111 | 0.123 | 0.000 |
| channel_C | 0.000 | 2.260 | 0.819 | 0.945 | 0.930 | 0.816 | 0.000 |
| channel_R | 0.000 | 7.560 | 3.828 | 3.825 | 3.765 | 3.580 | 0.000 |
| prop_type_CP | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| prop_type_MH | 0.000 | 0.029 | 0.008 | 0.079 | 0.085 | 0.031 | 0.000 |
| prop_type_PU | 0.000 | 0.340 | 0.225 | 0.178 | 0.194 | 0.177 | 0.000 |
| prop_type_SF | 0.000 | 10.549 | 6.430 | 5.037 | 4.625 | 5.842 | 0.000 |
| loan_purpose_N | 0.000 | 8.610 | 5.533 | 4.418 | 5.083 | 5.849 | 0.000 |
| loan_purpose_P | 0.000 | 26.371 | 14.842 | 12.072 | 9.992 | 11.216 | 0.000 |
| pgrm_ind_Y | 0.000 | 11.792 | 4.076 | 3.302 | 3.665 | 3.898 | 0.000 |
| pre_relief_prog_F | 0.000 | 7.389 | 3.919 | 4.179 | 3.670 | 3.612 | 0.000 |
| pre_relief_prog_N | 0.000 | 70.661 | 46.001 | 53.886 | 36.410 | 35.098 | 0.000 |
| seller_name_BRANCH BANKING & TRUST COMPANY | 0.000 | 0.033 | 0.014 | 0.019 | 0.024 | 0.018 | 0.000 |
| seller_name_CALIBER HOME LOANS, INC. | 0.000 | 149.222 | 70.386 | 153.683 | 112.893 | 56.083 | 0.000 |
| seller_name_CITIMORTGAGE, INC. | 0.000 | 2.464 | 1.662 | 1.153 | 0.955 | 0.999 | 0.000 |
| seller_name_FLAGSTAR BANK, FSB | 0.000 | 0.834 | 1.150 | 0.870 | 0.517 | 0.741 | 0.000 |
| seller_name_FRANKLIN AMERICAN MORTGAGE COMPANY | 0.000 | 0.151 | 0.096 | 0.104 | 0.073 | 0.073 | 0.000 |
| seller_name_GUARANTEED RATE, INC. | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| seller_name_JPMORGAN CHASE BANK, N.A. | 0.000 | 3.417 | 1.741 | 0.855 | 1.195 | 1.788 | 0.000 |
| seller_name_LOANDEPOT.COM, LLC | 0.000 | 0.017 | 0.003 | 0.003 | 0.002 | 0.014 | 0.000 |
| seller_name_NATIONSTAR MORTGAGE LLC | 0.000 | 2.059 | 1.042 | 0.614 | 0.736 | 0.458 | 0.000 |
| seller_name_Other sellers | 0.000 | 41.812 | 23.506 | 20.098 | 18.996 | 19.475 | 0.000 |
| seller_name_QUICKEN LOANS INC. | 0.000 | 6.665 | 2.567 | 3.527 | 2.463 | 2.234 | 0.000 |
| seller_name_STEARNS LENDING, LLC | 0.000 | 3.079 | 1.641 | 1.667 | 0.952 | 2.781 | 0.000 |
| seller_name_SUNTRUST MORTGAGE, INC. | 0.000 | 0.105 | 0.138 | 0.094 | 0.082 | 0.093 | 0.000 |
| seller_name_U.S. BANK N.A. | 0.000 | 89.276 | 102.938 | 59.759 | 67.911 | 35.445 | 0.000 |
| seller_name_WELLS FARGO BANK, N.A. | 0.000 | 3146.988 | 1094.212 | 1367.169 | 1153.266 | 1060.752 | 0.000 |
| st_AZ | 0.000 | 0.089 | 0.063 | 0.058 | 0.034 | 0.040 | 0.000 |
| st_CA | 0.000 | 11.245 | 5.848 | 4.796 | 4.943 | 5.350 | 0.000 |
| st_CO | 0.000 | 2.347 | 0.822 | 0.754 | 1.726 | 1.821 | 0.000 |
| st_CT | 0.000 | 0.106 | 0.025 | 0.030 | 0.036 | 0.015 | 0.000 |
| st_FL | 0.000 | 262.714 | 113.953 | 159.954 | 117.501 | 115.484 | 0.000 |
| st_GA | 0.000 | 0.189 | 0.126 | 0.066 | 0.115 | 0.160 | 0.000 |
| st_IL | 0.000 | 0.099 | 0.062 | 0.033 | 0.060 | 0.042 | 0.000 |
| st_IN | 0.000 | 0.002 | 0.000 | 0.001 | 0.001 | 0.001 | 0.000 |
| st_KY | 0.000 | 0.002 | 0.007 | 0.005 | 0.003 | 0.002 | 0.000 |
| st_MA | 0.000 | 0.612 | 0.171 | 0.300 | 0.142 | 0.171 | 0.000 |
| st_MD | 0.000 | 0.853 | 0.816 | 1.454 | 0.715 | 0.316 | 0.000 |
| st_MI | 0.000 | 6.265 | 3.868 | 3.541 | 3.262 | 3.931 | 0.000 |
| st_MN | 0.000 | 0.267 | 0.227 | 0.169 | 0.142 | 0.123 | 0.000 |
| st_MO | 0.000 | 0.083 | 0.072 | 0.047 | 0.070 | 0.059 | 0.000 |
| st_NC | 0.000 | 0.238 | 0.121 | 0.093 | 0.105 | 0.099 | 0.000 |
| st_NJ | 0.000 | 3.783 | 5.074 | 2.793 | 3.065 | 3.185 | 0.000 |
| st_NV | 0.000 | 0.076 | 0.022 | 0.051 | 0.097 | 0.059 | 0.000 |
| st_NY | 0.000 | 0.035 | 0.018 | 0.067 | 0.024 | 0.021 | 0.000 |
| st_OH | 0.000 | 0.052 | 0.058 | 0.062 | 0.060 | 0.033 | 0.000 |
| st_OR | 0.000 | 0.363 | 0.329 | 0.209 | 0.233 | 0.372 | 0.000 |
| st_Other | 0.000 | 7.947 | 6.374 | 3.146 | 3.163 | 5.323 | 0.000 |
| st_PA | 0.000 | 1.057 | 0.506 | 0.439 | 0.722 | 0.506 | 0.000 |
| st_SC | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| st_TN | 0.000 | 0.160 | 0.310 | 0.078 | 0.090 | 0.093 | 0.000 |
| st_TX | 0.000 | 4.432 | 2.594 | 2.222 | 2.114 | 3.514 | 0.000 |
| st_UT | 0.000 | 0.042 | 0.011 | 0.008 | 0.007 | 0.003 | 0.000 |
| st_VA | 0.000 | 0.027 | 0.028 | 0.029 | 0.127 | 0.009 | 0.000 |
| st_WA | 0.000 | 6.667 | 3.374 | 2.608 | 2.058 | 1.087 | 0.000 |
| st_WI | 0.000 | 0.067 | 0.037 | 0.023 | 0.013 | 0.024 | 0.000 |
| servicer_name_CALIBER HOME LOANS, INC. | 0.000 | 0.579 | 0.315 | 0.289 | 0.202 | 0.153 | 0.000 |
| servicer_name_FREEDOM MORTGAGE CORPORATION | 0.000 | 1.867 | 0.493 | 1.043 | 0.774 | 1.176 | 0.000 |
| servicer_name_JPMORGAN CHASE BANK, NATIONAL ASSOCIATION | 0.000 | 35.349 | 17.946 | 12.957 | 14.639 | 13.999 | 0.000 |
| servicer_name_LAKEVIEW LOAN SERVICING, LLC | 0.000 | 2.777 | 1.804 | 1.633 | 1.040 | 0.973 | 0.000 |
| servicer_name_NATIONSTAR MORTGAGE LLC DBA MR. COOPER | 0.000 | 0.701 | 0.268 | 0.326 | 0.299 | 0.253 | 0.000 |
| servicer_name_NEW RESIDENTIAL MORTGAGE LLC | 0.000 | 1.688 | 1.114 | 0.841 | 1.102 | 1.565 | 0.000 |
| servicer_name_Other servicers | 0.000 | 2047.783 | 1036.953 | 980.926 | 924.628 | 999.035 | 0.000 |
| servicer_name_PNC BANK, NA | 0.000 | 1.769 | 0.999 | 0.754 | 0.995 | 1.191 | 0.000 |
| servicer_name_QUICKEN LOANS INC. | 0.000 | 20.379 | 14.267 | 11.050 | 11.048 | 8.975 | 0.000 |
| servicer_name_TRUIST BANK | 0.000 | 6.484 | 3.436 | 2.901 | 2.666 | 2.898 | 0.000 |
| servicer_name_U.S. BANK N.A. | 0.000 | 1.860 | 1.444 | 0.763 | 0.813 | 0.880 | 0.000 |
| servicer_name_WELLS FARGO BANK, N.A. | 0.000 | 9.133 | 4.598 | 4.263 | 3.735 | 4.673 | 0.000 |
----------------------------------------------------------------------- Table 5: Variance in SHAP values over 100 iterations.