{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# python与numpy基础"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"寒小阳(2016年6月)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Python介绍"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"如果你问我没有编程基础,想学习一门语言,我一定会首推给你Python
\n",
"类似伪代码的书写方式,让你能够集中精力去解决问题,而不是花费大量的时间在开发和debug上
\n",
"同时得益于Numpy/Scipy这样的科学计算库,使得其有非常高效和简易的科学计算能力。
\n",
"而活跃的社区提供的各种可视化的库,也使得 机器学习/数据挖掘 的全过程(数据采集,数据清洗,数据处理,建模,可视化)可以非常流畅地完成。
\n",
"而近年来极其热门的深度学习开源框架,基本都有python接口,google的Tensorflow更是python主导。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这个教程里面的内容包括:\n",
"\n",
"* 基本Python语法: 基本数据类型 (Containers, Lists, Dictionaries, Sets, Tuples), 函数, 类\n",
"* Numpy: Arrays/数组, Array indexing/数组取值, Datatypes, Array math, Broadcasting"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 基本python语法"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Python确实经常被人像伪代码,下面是一个快排程序,你可以感受一下:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1, 1, 2, 3, 6, 8, 9, 10]\n"
]
}
],
"source": [
"def quicksort(arr):\n",
" if len(arr) <= 1:\n",
" return arr\n",
" pivot = arr[len(arr) / 2]\n",
" left = [x for x in arr if x < pivot]\n",
" middle = [x for x in arr if x == pivot]\n",
" right = [x for x in arr if x > pivot]\n",
" return quicksort(left) + middle + quicksort(right)\n",
"\n",
"print quicksort([3,6,9, 8,10,1,2,1])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 基本数据类型"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 数值型"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"整型和浮点型以及基本的运算大家应该都知道:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"4 \n"
]
}
],
"source": [
"x = 4\n",
"print x, type(x)"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n",
"3\n",
"8\n",
"16\n"
]
}
],
"source": [
"print x + 1 # 加;\n",
"print x - 1 # 减;\n",
"print x * 2 # 乘;\n",
"print x ** 2 # 指数;"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n",
"10\n"
]
}
],
"source": [
"x += 1\n",
"print x # 自加\n",
"x *= 2\n",
"print x # 自乘"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"2.5 3.5 5.0 6.25\n"
]
}
],
"source": [
"y = 2.5\n",
"print type(y) # 输出类型\n",
"print y, y + 1, y * 2, y ** 2 # 连续输出"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"不过需要提醒一句,用习惯C++和Java的同学,Python真的没有(x++)和(x--)这俩操作"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 布尔型"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"用于指定真假的类型,布尔型,包含真(True)和假(False):"
]
},
{
"cell_type": "code",
"execution_count": 139,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n"
]
}
],
"source": [
"t, f = True, False\n",
"print type(t) # Prints \"\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"看看逻辑与或非这些操作"
]
},
{
"cell_type": "code",
"execution_count": 140,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"False\n",
"True\n",
"False\n",
"True\n"
]
}
],
"source": [
"print t and f # Logical AND;\n",
"print t or f # Logical OR;\n",
"print not t # Logical NOT;\n",
"print t != f # Logical XOR;"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 字符串型"
]
},
{
"cell_type": "code",
"execution_count": 142,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello 5\n"
]
}
],
"source": [
"hello = 'hello' # 实在想不出的时候就用hello world\n",
"world = \"world\"\n",
"print hello, len(hello) # 字符串长度"
]
},
{
"cell_type": "code",
"execution_count": 143,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello world\n"
]
}
],
"source": [
"hw = hello + ' ' + world # 字符串拼接\n",
"print hw"
]
},
{
"cell_type": "code",
"execution_count": 144,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello world 12\n"
]
}
],
"source": [
"hw12 = '%s %s %d' % (hello, world, 12) # 类似sprintf的格式化输出\n",
"print hw12 # prints \"hello world 12\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我能说什么,你面试的时候面试官最爱让你写的字符串操作,都是它自带的:"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hello\n",
"HELLO\n",
" hello\n",
" hello \n",
"he(ell)(ell)o\n",
"world\n"
]
}
],
"source": [
"s = \"hello\"\n",
"print s.capitalize() # 首字母大写\n",
"print s.upper() # 全大写\n",
"print s.rjust(7) # 靠右对齐\n",
"print s.center(7) # 居中输出\n",
"print s.replace('l', '(ell)') # 字符串替换\n",
"print ' world '.strip() # 去掉两侧空白"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"其他你想要的字符串操作看[这里](https://docs.python.org/2/library/stdtypes.html#string-methods)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 容器"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"内置的容器用得非常非常多,包括: lists, dictionaries, sets, and tuples."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Lists/列表"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"和你学数据结构里面数组长得一样的容器,但是操作可多多了:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[3, 1, 2] 2\n",
"2\n"
]
}
],
"source": [
"xs = [3, 1, 2] # 建一个列表\n",
"print xs, xs[2]\n",
"print xs[-1] # 用-1表示最后一个元素,输出来"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[3, 1, 'Hanxiaoyang']\n"
]
}
],
"source": [
"xs[2] = 'Hanxiaoyang' # 有意思的是,Python的list居然可以有不同类型的元素\n",
"print xs"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[3, 1, 'Hanxiaoyang', 'happy']\n"
]
}
],
"source": [
"xs.append('happy') # 可以用append在尾部添加元素\n",
"print xs "
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"happy [3, 1, 'Hanxiaoyang']\n"
]
}
],
"source": [
"x = xs.pop() # 也可以把最后一个元素“弹射”出来\n",
"print x, xs "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"关于list更多的操作和内容可以看[这里](https://docs.python.org/2/tutorial/datastructures.html#more-on-lists)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 列表切片"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这是大家最爱python list的原因之一,取东西太方便啦:"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 1, 2, 3, 4]\n",
"[2, 3]\n",
"[2, 3, 4]\n",
"[0, 1]\n",
"[0, 1, 2, 3, 4]\n",
"[0, 1, 2, 3]\n",
"[0, 1, 8, 9, 4]\n"
]
}
],
"source": [
"nums = range(5) # 0-4\n",
"print nums # 输出 \"[0, 1, 2, 3, 4]\"\n",
"print nums[2:4] # 下标2到4(不包括)的元素,注意下标从0开始\n",
"print nums[2:] # 下标2到结尾的元素; prints \"[2, 3, 4]\"\n",
"print nums[:2] # 直到下标2的元素; prints \"[0, 1]\"\n",
"print nums[:] # Get a slice of the whole list; prints [\"0, 1, 2, 3, 4]\"\n",
"print nums[:-1] # 直到倒数第一个元素; prints [\"0, 1, 2, 3]\"\n",
"nums[2:4] = [8, 9] # 也可以直接这么赋值\n",
"print nums # Prints \"[0, 1, 8, 8, 4]\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 循环"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"可以对list立面的元素做一个循环:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"喵星人\n",
"汪星人\n",
"火星人\n"
]
}
],
"source": [
"animals = ['喵星人', '汪星人', '火星人']\n",
"for animal in animals:\n",
" print animal"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"又要输出元素,又要输出下标怎么办,用 `enumerate` 函数:"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"#1: 喵星人\n",
"#2: 汪星人\n",
"#3: 火星人\n"
]
}
],
"source": [
"animals = ['喵星人', '汪星人', '火星人']\n",
"for idx, animal in enumerate(animals):\n",
" print '#%d: %s' % (idx + 1, animal)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### List comprehensions:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"如果对list里面的元素都做一样的操作,然后生成一个list,用它最快了,这绝对会成为你最爱的python操作之一:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 1, 4, 9, 16]\n"
]
}
],
"source": [
"# 求一个list里面的元素的平方,然后输出,很out的for循环写法\n",
"nums = [0, 1, 2, 3, 4]\n",
"squares = []\n",
"for x in nums:\n",
" squares.append(x ** 2)\n",
"print squares"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"用list comprehension可以这么写:"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 1, 4, 9, 16]\n"
]
}
],
"source": [
"nums = [0, 1, 2, 3, 4]\n",
"# 对每个x完成一个操作以后返回来,组成新的list\n",
"squares = [x ** 2 for x in nums]\n",
"print squares"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"你甚至可以加条件,去筛出你想要的元素,去做你想要的操作:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 4, 16]\n"
]
}
],
"source": [
"nums = [0, 1, 2, 3, 4]\n",
"# 把所有的偶数取出来,平方后返回\n",
"even_squares = [x ** 2 for x in nums if x % 2 == 0]\n",
"print even_squares"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 字典"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"存储键值对(key => value)的数据结构, 类似Java中的`Map`,这真的是我使用频度相当高的数据结构:"
]
},
{
"cell_type": "code",
"execution_count": 158,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"cute\n",
"True\n"
]
}
],
"source": [
"d = {'cat': 'cute', 'dog': 'furry'} # 建立字典\n",
"print d['cat'] # 根据key取value\n",
"print 'cat' in d # 查一个元素是否在字典中"
]
},
{
"cell_type": "code",
"execution_count": 159,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"wet\n"
]
}
],
"source": [
"d['fish'] = 'wet' # 设定键值对\n",
"print d['fish'] # 这时候肯定是输出修改后的内容"
]
},
{
"cell_type": "code",
"execution_count": 161,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "KeyError",
"evalue": "'monkey'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m\n\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0;32mprint\u001b[0m \u001b[0md\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'monkey'\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;31m# KeyError: 'monkey' not a key of d\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mKeyError\u001b[0m: 'monkey'"
]
}
],
"source": [
"print d['monkey'] # 不是d的键,肯定输不出东西"
]
},
{
"cell_type": "code",
"execution_count": 162,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"N/A\n",
"wet\n"
]
}
],
"source": [
"print d.get('monkey', 'N/A') # 可以默认输出'N/A'(取不到key对应的value值的时候)\n",
"print d.get('fish', 'N/A') "
]
},
{
"cell_type": "code",
"execution_count": 163,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"N/A\n"
]
}
],
"source": [
"del d['fish'] # 删除字典中的键值对\n",
"print d.get('fish', 'N/A') # 这会儿就没有了"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"同样的,你其他想了解的字典相关的操作和内容可以看 [这里](https://docs.python.org/2/library/stdtypes.html#dict)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"你可以这样循环python字典取出你想要的内容:"
]
},
{
"cell_type": "code",
"execution_count": 164,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"A person has 2 legs\n",
"A spider has 8 legs\n",
"A cat has 4 legs\n"
]
}
],
"source": [
"d = {'person': 2, 'cat': 4, 'spider': 8}\n",
"for animal in d:\n",
" legs = d[animal]\n",
" print 'A %s has %d legs' % (animal, legs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"用iteritems函数可以同时取出键值对:"
]
},
{
"cell_type": "code",
"execution_count": 165,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"A person has 2 legs\n",
"A spider has 8 legs\n",
"A cat has 4 legs\n"
]
}
],
"source": [
"d = {'person': 2, 'cat': 4, 'spider': 8}\n",
"for animal, legs in d.iteritems():\n",
" print 'A %s has %d legs' % (animal, legs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Dictionary comprehensions: 和list comprehension有点像啦,但是生成的是字典:"
]
},
{
"cell_type": "code",
"execution_count": 166,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{0: 0, 2: 4, 4: 16}\n"
]
}
],
"source": [
"nums = [0, 1, 2, 3, 4]\n",
"even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}\n",
"print even_num_to_square"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"你可以理解成没有相同元素的列表(当然,显然和list是不同的):"
]
},
{
"cell_type": "code",
"execution_count": 167,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n",
"False\n"
]
}
],
"source": [
"animals = {'cat', 'dog'}\n",
"print 'cat' in animals # Check if an element is in a set; prints \"True\"\n",
"print 'fish' in animals # prints \"False\"\n"
]
},
{
"cell_type": "code",
"execution_count": 170,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n",
"2\n"
]
}
],
"source": [
"animals.add('fish') # 添加元素\n",
"print 'fish' in animals\n",
"print len(animals) # 元素个数"
]
},
{
"cell_type": "code",
"execution_count": 171,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3\n",
"2\n"
]
}
],
"source": [
"animals.add('cat') # 如果元素已经在set里了,操作不会怎么样\n",
"print len(animals) \n",
"animals.remove('cat') # 删除一个元素\n",
"print len(animals) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"循环的方式和list很像啦:"
]
},
{
"cell_type": "code",
"execution_count": 63,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"#1: fish\n",
"#2: dog\n",
"#3: cat\n"
]
}
],
"source": [
"animals = {'cat', 'dog', 'fish'}\n",
"for idx, animal in enumerate(animals):\n",
" print '#%d: %s' % (idx + 1, animal)\n",
"# Prints \"#1: fish\", \"#2: dog\", \"#3: cat\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set comprehensions: 熟悉的感觉:"
]
},
{
"cell_type": "code",
"execution_count": 172,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"set([0, 1, 2, 3, 4, 5])\n"
]
}
],
"source": [
"from math import sqrt\n",
"print {int(sqrt(x)) for x in range(30)}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 元组"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"和list很像,但是可以作为字典的key或者set的元素出现,但是一整个list不可以作为字典的key或者set的元素的:"
]
},
{
"cell_type": "code",
"execution_count": 173,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"5\n",
"1\n"
]
}
],
"source": [
"d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys\n",
"t = (5, 6) # Create a tuple\n",
"print type(t)\n",
"print d[t] \n",
"print d[(1, 2)]"
]
},
{
"cell_type": "code",
"execution_count": 176,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "TypeError",
"evalue": "'tuple' object does not support item assignment",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m\n\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mt\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m: 'tuple' object does not support item assignment"
]
}
],
"source": [
"t[0] = 1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 函数"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"用 `def` 就可以定义一个函数,就像下面这样:"
]
},
{
"cell_type": "code",
"execution_count": 178,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"negative\n",
"zero\n",
"positive\n"
]
}
],
"source": [
"def sign(x):\n",
" if x > 0:\n",
" return 'positive'\n",
" elif x < 0:\n",
" return 'negative'\n",
" else:\n",
" return 'zero'\n",
"\n",
"for x in [-1, 0, 1]:\n",
" print sign(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"函数名字后面接的括号里,可以有多个参数,你自己可以试试:"
]
},
{
"cell_type": "code",
"execution_count": 179,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hello, Bob!\n",
"HELLO, FRED\n"
]
}
],
"source": [
"def hello(name, loud=False):\n",
" if loud:\n",
" print 'HELLO, %s' % name.upper()\n",
" else:\n",
" print 'Hello, %s!' % name\n",
"\n",
"hello('Bob')\n",
"hello('Fred', loud=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 类"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Python的类,怎么说呢,比较简单粗暴:"
]
},
{
"cell_type": "code",
"execution_count": 76,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hello, Fred\n",
"HELLO, FRED!\n"
]
}
],
"source": [
"class Greeter:\n",
"\n",
" # 构造函数\n",
" def __init__(self, name):\n",
" self.name = name # Create an instance variable\n",
"\n",
" # 类的成员函数\n",
" def greet(self, loud=False):\n",
" if loud:\n",
" print 'HELLO, %s!' % self.name.upper()\n",
" else:\n",
" print 'Hello, %s' % self.name\n",
"\n",
"g = Greeter('Fred') # 构造一个类\n",
"g.greet() # 调用函数; prints \"Hello, Fred\"\n",
"g.greet(loud=True) # 调用函数; prints \"HELLO, FRED!\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Numpy"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我们要开始接触高效计算库Numpy了,你要是之前在实验室用MATLAB之类的语法,你会发现Numpy和它们长得不要太像,爱MATLAB的同学,参考文档可以看[这里](http://wiki.scipy.org/NumPy_for_Matlab_Users)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"python里面调用一个包,用import对吧, 所以我们import `numpy` 包:"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Arrays/数组"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"看你数组的维度啦,我自己的话比较简单粗暴,一般直接把1维数组就看做向量/vector,2维数组看做2维矩阵,3维数组看做3维矩阵..."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"可以调用np.array去从list初始化一个数组:"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" (3,) 1 2 3\n",
"[5 2 3]\n"
]
}
],
"source": [
"a = np.array([1, 2, 3]) # 1维数组\n",
"print type(a), a.shape, a[0], a[1], a[2]\n",
"a[0] = 5 # 重新赋值\n",
"print a "
]
},
{
"cell_type": "code",
"execution_count": 198,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[1 2 3]\n",
" [4 5 6]]\n"
]
}
],
"source": [
"b = np.array([[1,2,3],[4,5,6]]) # 2维数组\n",
"print b"
]
},
{
"cell_type": "code",
"execution_count": 199,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(2, 3)\n",
"1 2 4\n"
]
}
],
"source": [
"print b.shape #可以看形状的(非常常用!!!) \n",
"print b[0, 0], b[0, 1], b[1, 0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"有一些内置的创建数组的函数:"
]
},
{
"cell_type": "code",
"execution_count": 186,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0. 0.]\n",
" [ 0. 0.]]\n"
]
}
],
"source": [
"a = np.zeros((2,2)) # 创建2x2的全0数组\n",
"print a"
]
},
{
"cell_type": "code",
"execution_count": 187,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1. 1.]]\n"
]
}
],
"source": [
"b = np.ones((1,2)) # 创建1x2的全0数组\n",
"print b"
]
},
{
"cell_type": "code",
"execution_count": 188,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 7. 7.]\n",
" [ 7. 7.]]\n"
]
}
],
"source": [
"c = np.full((2,2), 7) # 定值数组\n",
"print c "
]
},
{
"cell_type": "code",
"execution_count": 190,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1. 0.]\n",
" [ 0. 1.]]\n"
]
}
],
"source": [
"d = np.eye(2) # 对角矩阵(对角元素为1)\n",
"print d"
]
},
{
"cell_type": "code",
"execution_count": 192,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0.09477679 0.79267634]\n",
" [ 0.78291274 0.38962829]]\n"
]
}
],
"source": [
"e = np.random.random((2,2)) # 2x2的随机数组(矩阵)\n",
"print e"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Array indexing/数组取值"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Numpy提供了蛮多种取值的方式的."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"可以像list一样切片(多维数组可以从各个维度同时切片):"
]
},
{
"cell_type": "code",
"execution_count": 203,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[2 3]\n",
" [6 7]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"# 创建一个如下格式的3x4数组\n",
"# [[ 1 2 3 4]\n",
"# [ 5 6 7 8]\n",
"# [ 9 10 11 12]]\n",
"a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\n",
"\n",
"# 在两个维度上分别按照[:2]和[1:3]进行切片,取需要的部分\n",
"# [[2 3]\n",
"# [6 7]]\n",
"b = a[:2, 1:3]\n",
"print b"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"虽然,怎么说呢,不建议你这样去赋值,但是你确实可以修改切片出来的对象,然后完成对原数组的赋值."
]
},
{
"cell_type": "code",
"execution_count": 202,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n",
"77\n"
]
}
],
"source": [
"print a[0, 1] \n",
"b[0, 0] = 77 # b[0, 0]改了,很遗憾a[0, 1]也被修改了\n",
"print a[0, 1] "
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1 2 3 4]\n",
" [ 5 6 7 8]\n",
" [ 9 10 11 12]]\n"
]
}
],
"source": [
"# 创建3x4的2维数组/矩阵\n",
"a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\n",
"print a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"你就放心大胆地去取你想要的数咯:"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[5 6 7 8] (4,)\n",
"[[5 6 7 8]] (1, 4)\n",
"[[5 6 7 8]] (1, 4)\n"
]
}
],
"source": [
"row_r1 = a[1, :] # 第2行,但是得到的是1维输出(列向量)\n",
"row_r2 = a[1:2, :] # 1x2的2维输出\n",
"row_r3 = a[[1], :] # 同上\n",
"print row_r1, row_r1.shape \n",
"print row_r2, row_r2.shape\n",
"print row_r3, row_r3.shape"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[ 2 6 10] (3,)\n",
"\n",
"[[ 2]\n",
" [ 6]\n",
" [10]] (3, 1)\n"
]
}
],
"source": [
"# 试试在第2个维度上切片也一样的:\n",
"col_r1 = a[:, 1]\n",
"col_r2 = a[:, 1:2]\n",
"print col_r1, col_r1.shape\n",
"print\n",
"print col_r2, col_r2.shape"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"下面这个高级了,更自由地取值和组合,但是要看清楚一点:"
]
},
{
"cell_type": "code",
"execution_count": 220,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1 4 5]\n",
"[1 4 5]\n"
]
}
],
"source": [
"a = np.array([[1,2], [3, 4], [5, 6]])\n",
"\n",
"# 其实意思就是取(0,0),(1,1),(2,0)的元素组起来\n",
"print a[[0, 1, 2], [0, 1, 0]]\n",
"\n",
"# 下面这个比较直白啦\n",
"print np.array([a[0, 0], a[1, 1], a[2, 0]])"
]
},
{
"cell_type": "code",
"execution_count": 221,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2 2]\n",
"[2 2]\n"
]
}
],
"source": [
"# 再来试试\n",
"print a[[0, 0], [1, 1]]\n",
"\n",
"# 还是一样\n",
"print np.array([a[0, 1], a[0, 1]])"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1 2 3]\n",
" [ 4 5 6]\n",
" [ 7 8 9]\n",
" [10 11 12]]\n"
]
}
],
"source": [
"# 再来熟悉一下\n",
"# 先创建一个2维数组\n",
"a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
"print a"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[ 1 6 7 11]\n"
]
}
],
"source": [
"# 用下标生成一个向量\n",
"b = np.array([0, 2, 0, 1])\n",
"\n",
"# 你能看明白下面做的事情吗?\n",
"print a[np.arange(4), b] # Prints \"[ 1 6 7 11]\""
]
},
{
"cell_type": "code",
"execution_count": 218,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[21 2 3]\n",
" [ 4 5 26]\n",
" [27 8 9]\n",
" [10 31 12]]\n"
]
}
],
"source": [
"# 既然可以取出来,我们当然可以对这些元素操作咯\n",
"a[np.arange(4), b] += 10\n",
"print a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"比较fashion的取法之一,用条件判定去取(但是很好用):"
]
},
{
"cell_type": "code",
"execution_count": 223,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[False False]\n",
" [ True True]\n",
" [ True True]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1,2], [3, 4], [5, 6]])\n",
"\n",
"bool_idx = (a > 2) # 就是判定一下是否大于2\n",
"\n",
"print bool_idx # 返回一个布尔型的3x2数组"
]
},
{
"cell_type": "code",
"execution_count": 225,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[3 4 5 6]\n",
"[3 4 5 6]\n"
]
}
],
"source": [
"# 用刚才的布尔型数组作为下标就可以去除符合条件的元素啦\n",
"print a[bool_idx]\n",
"\n",
"# 其实一句话也可以完成是不是?\n",
"print a[a > 2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"那个,真的,其实还有很多细节,其他的方式去取值,你可以看看官方文档。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我们一起来来总结一下,看下面切片取值方式(对应颜色是取出来的结果):"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Datatypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我们可以用dtype来看numpy数组中元素的类型:"
]
},
{
"cell_type": "code",
"execution_count": 226,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"int64 float64 int64\n"
]
}
],
"source": [
"x = np.array([1, 2]) # numpy构建数组的时候自己会确定类型\n",
"y = np.array([1.0, 2.0])\n",
"z = np.array([1, 2], dtype=np.int64)# 指定用int64构建\n",
"\n",
"print x.dtype, y.dtype, z.dtype"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"更多的内容可以读读[文档](http://docs.scipy.org/doc/numpy/reference/arrays.dtypes.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 数学运算"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"下面这些运算才是你在科学运算中经常经常会用到的,比如逐个元素的运算如下:"
]
},
{
"cell_type": "code",
"execution_count": 227,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 6. 8.]\n",
" [ 10. 12.]]\n",
"[[ 6. 8.]\n",
" [ 10. 12.]]\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]], dtype=np.float64)\n",
"y = np.array([[5,6],[7,8]], dtype=np.float64)\n",
"\n",
"# 逐元素求和有下面2种方式\n",
"print x + y\n",
"print np.add(x, y)"
]
},
{
"cell_type": "code",
"execution_count": 228,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[-4. -4.]\n",
" [-4. -4.]]\n",
"[[-4. -4.]\n",
" [-4. -4.]]\n"
]
}
],
"source": [
"# 逐元素作差\n",
"print x - y\n",
"print np.subtract(x, y)"
]
},
{
"cell_type": "code",
"execution_count": 229,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 5. 12.]\n",
" [ 21. 32.]]\n",
"[[ 5. 12.]\n",
" [ 21. 32.]]\n"
]
}
],
"source": [
"# 逐元素相乘\n",
"print x * y\n",
"print np.multiply(x, y)"
]
},
{
"cell_type": "code",
"execution_count": 230,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0.2 0.33333333]\n",
" [ 0.42857143 0.5 ]]\n",
"[[ 0.2 0.33333333]\n",
" [ 0.42857143 0.5 ]]\n"
]
}
],
"source": [
"# 逐元素相除\n",
"# [[ 0.2 0.33333333]\n",
"# [ 0.42857143 0.5 ]]\n",
"print x / y\n",
"print np.divide(x, y)"
]
},
{
"cell_type": "code",
"execution_count": 231,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1. 1.41421356]\n",
" [ 1.73205081 2. ]]\n"
]
}
],
"source": [
"# 逐元素求平方根!!!\n",
"# [[ 1. 1.41421356]\n",
"# [ 1.73205081 2. ]]\n",
"print np.sqrt(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"那如果我要做矩阵的乘法运算怎么办!!!恩,别着急,照着下面写就可以了:"
]
},
{
"cell_type": "code",
"execution_count": 232,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"219\n",
"219\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]])\n",
"y = np.array([[5,6],[7,8]])\n",
"\n",
"v = np.array([9,10])\n",
"w = np.array([11, 12])\n",
"\n",
"# 求向量内积\n",
"print v.dot(w)\n",
"print np.dot(v, w)"
]
},
{
"cell_type": "code",
"execution_count": 233,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[29 67]\n",
"[29 67]\n"
]
}
],
"source": [
"# 矩阵的乘法\n",
"print x.dot(v)\n",
"print np.dot(x, v)"
]
},
{
"cell_type": "code",
"execution_count": 234,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[19 22]\n",
" [43 50]]\n",
"[[19 22]\n",
" [43 50]]\n"
]
}
],
"source": [
"# 矩阵的乘法\n",
"# [[19 22]\n",
"# [43 50]]\n",
"print x.dot(y)\n",
"print np.dot(x, y)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"你猜你做科学运算会最常用到的矩阵内元素的运算是什么?对啦,是求和,用 `sum`可以完成:"
]
},
{
"cell_type": "code",
"execution_count": 235,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"10\n",
"[4 6]\n",
"[3 7]\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]])\n",
"\n",
"print np.sum(x) # 数组/矩阵中所有元素求和; prints \"10\"\n",
"print np.sum(x, axis=0) # 按行去求和; prints \"[4 6]\"\n",
"print np.sum(x, axis=1) # 按列去求和; prints \"[3 7]\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我想说最基本的运算就是上面这个样子,更多的运算可能得查查[文档](http://docs.scipy.org/doc/numpy/reference/routines.math.html).\n",
"\n",
"其实除掉基本运算,我们经常还需要做一些操作,比如矩阵的变形,转置和重排等等:"
]
},
{
"cell_type": "code",
"execution_count": 236,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[1 2]\n",
" [3 4]]\n",
"[[1 3]\n",
" [2 4]]\n"
]
}
],
"source": [
"# 转置和数学公式一直,简单粗暴\n",
"print x\n",
"print x.T"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1 2 3]\n",
"[1 2 3]\n",
"[[1 2 3]]\n",
"[[1]\n",
" [2]\n",
" [3]]\n"
]
}
],
"source": [
"# 需要说明一下,1维的vector转置还是自己\n",
"v = np.array([1,2,3])\n",
"print v \n",
"print v.T\n",
"\n",
"# 2维的就不一样了\n",
"w = np.array([[1,2,3]])\n",
"print w \n",
"print w.T"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Broadcasting"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这个没想好哪个中文词最贴切,我们暂且叫它“传播吧”:
\n",
"作用是什么呢,我们设想一个场景,如果要用小的矩阵去和大的矩阵做一些操作,但是希望小矩阵能循环和大矩阵的那些块做一样的操作,那急需要Broadcasting啦"
]
},
{
"cell_type": "code",
"execution_count": 238,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 2 2 4]\n",
" [ 5 5 7]\n",
" [ 8 8 10]\n",
" [11 11 13]]\n"
]
}
],
"source": [
"# 我们要做一件事情,给x的每一行都逐元素加上一个向量,然后生成y\n",
"x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
"v = np.array([1, 0, 1])\n",
"y = np.empty_like(x) # 生成一个和x维度一致的空数组/矩阵\n",
"\n",
"# 比较粗暴的方式是,用for循环逐个相加\n",
"for i in range(4):\n",
" y[i, :] = x[i, :] + v\n",
"\n",
"print y"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这种方法当然可以啦,问题是不高效嘛,如果你的x矩阵行数非常多,那就很慢的咯:
\n",
"咱们调整一下,先生成好要加的内容"
]
},
{
"cell_type": "code",
"execution_count": 240,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[1 0 1]\n",
" [1 0 1]\n",
" [1 0 1]\n",
" [1 0 1]]\n"
]
}
],
"source": [
"vv = np.tile(v, (4, 1)) # 重复4遍v,叠起来\n",
"print vv # Prints \"[[1 0 1]\n",
" # [1 0 1]\n",
" # [1 0 1]\n",
" # [1 0 1]]\""
]
},
{
"cell_type": "code",
"execution_count": 241,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 2 2 4]\n",
" [ 5 5 7]\n",
" [ 8 8 10]\n",
" [11 11 13]]\n"
]
}
],
"source": [
"y = x + vv # 这样求和大家都能看明白对吧\n",
"print y"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Numpy broadcasting allows us to perform this computation without actually creating multiple copies of v. Consider this version, using broadcasting:"
]
},
{
"cell_type": "code",
"execution_count": 242,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 2 2 4]\n",
" [ 5 5 7]\n",
" [ 8 8 10]\n",
" [11 11 13]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"# 因为broadcasting的存在,你上面的操作可以简单地汇总成一个求和操作\n",
"x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
"v = np.array([1, 0, 1])\n",
"y = x + v # Add v to each row of x using broadcasting\n",
"print y"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"当操作两个array时,numpy会逐个比较它们的shape,在下述情况下,两arrays会兼容和输出broadcasting结果:
\n",
"\n",
"1. 相等\n",
"2. 其中一个为1,(进而可进行拷贝拓展已至,shape匹配)\n",
"\n",
"比如求和的时候有:\n",
"```python\n",
"Image (3d array): 256 x 256 x 3\n",
"Scale (1d array): 3\n",
"Result (3d array): 256 x 256 x 3\n",
"\n",
"A (4d array): 8 x 1 x 6 x 1\n",
"B (3d array): 7 x 1 x 5\n",
"Result (4d array): 8 x 7 x 6 x 5\n",
"\n",
"A (2d array): 5 x 4\n",
"B (1d array): 1\n",
"Result (2d array): 5 x 4\n",
"\n",
"A (2d array): 15 x 3 x 5\n",
"B (1d array): 15 x 1 x 5\n",
"Result (2d array): 15 x 3 x 5\n",
"```\n",
"\n",
"下面是一些 broadcasting 的例子:"
]
},
{
"cell_type": "code",
"execution_count": 243,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 4 5]\n",
" [ 8 10]\n",
" [12 15]]\n"
]
}
],
"source": [
"# 我们来理解一下broadcasting的这种用法\n",
"v = np.array([1,2,3]) # v 形状是 (3,)\n",
"w = np.array([4,5]) # w 形状是 (2,)\n",
"# 先把v变形成3x1的数组/矩阵,然后就可以broadcasting加在w上了:\n",
"print np.reshape(v, (3, 1)) * w"
]
},
{
"cell_type": "code",
"execution_count": 244,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[2 4 6]\n",
" [5 7 9]]\n"
]
}
],
"source": [
"# 那如果要把一个矩阵的每一行都加上一个向量呢\n",
"x = np.array([[1,2,3], [4,5,6]])\n",
"v = np.array([1,2,3])\n",
"# 恩,其实是一样的啦\n",
"print x + v"
]
},
{
"cell_type": "code",
"execution_count": 245,
"metadata": {
"collapsed": false,
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 5 6 7]\n",
" [ 9 10 11]]\n"
]
}
],
"source": [
"x = np.array([[1,2,3], [4,5,6]]) # 2x3的\n",
"w = np.array([4,5]) # w 形状是 (2,)\n",
"\n",
"# 自己算算看?\n",
"print (x.T + w).T"
]
},
{
"cell_type": "code",
"execution_count": 246,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 5 6 7]\n",
" [ 9 10 11]]\n"
]
}
],
"source": [
"# 上面那个操作太复杂了,其实我们可以直接这么做嘛\n",
"print x + np.reshape(w, (2, 1))"
]
},
{
"cell_type": "code",
"execution_count": 247,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 2 4 6]\n",
" [ 8 10 12]]\n"
]
}
],
"source": [
"# broadcasting当然可以逐元素运算了\n",
"print x * 2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"总结一下broadcasting,可以看看下面的图:
\n",
"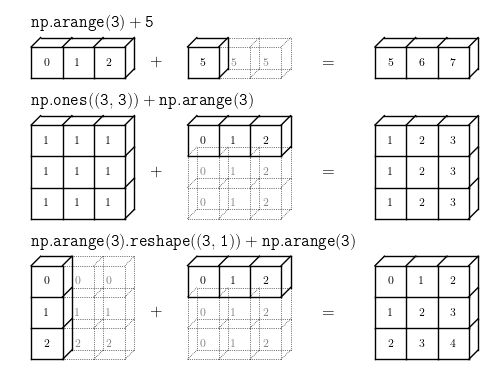"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"更多的numpy细节和用法可以查看一下官网[numpy指南](http://docs.scipy.org/doc/numpy/reference/)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 0
}