# MMSI-Bench
Sihan Yang1*,
Runsen Xu1,2*‡,
Yiman Xie1,3,
Sizhe Yang1,2,
Mo Li1,4,
Jingli Lin1,5,
Chenming Zhu1,6,
Xiaochen Chen7,
Haodong Duan1,
Xiangyu Yue1,2,
Dahua Lin1,2,
Tai Wang1†,
Jiangmiao Pang1†
1Shanghai AI Laboratory,
2The Chinese University of Hong Kong,
3Zhejiang University,
4Tsinghua University,
5Shanghai Jiaotong University,
6University of Hong Kong,
7Beijing Normal University
*Equal Contribution
‡Project Lead
†Corresponding Author
🌐 Homepage |
🤗 Dataset |
📑 Paper |
📖 arXiv
## 🔔News
✨✨✨ MMSI-Bench was used for evaluation in the experiments of [VILASR](https://arxiv.org/abs/2506.09965), [EASI](https://arxiv.org/pdf/2508.13142), [SpaceVista](https://arxiv.org/pdf/2510.09606), [Vlaser](https://arxiv.org/pdf/2510.11027), [MSSR](https://arxiv.org/abs/2510.16688), [DyVA](https://arxiv.org/pdf/2510.00855), [3DThinker](https://arxiv.org/pdf/2511.01618), [Actial](https://arxiv.org/pdf/2511.01618), [VST](https://arxiv.org/pdf/2511.05491), [SenseNova-SI](https://arxiv.org/pdf/2511.13719), [GCA](https://arxiv.org/pdf/2511.22659), [Seed1.8](https://seed.bytedance.com/en/seed1_8), [4D-RGPT](https://arxiv.org/abs/2512.17012), [SmoothOp](https://arxiv.org/pdf/2601.07695), [VisWorld-Eval](https://arxiv.org/abs/2601.19834), [CAMCUE](https://arxiv.org/pdf/2602.06041), [GeoThinker](https://arxiv.org/pdf/2602.06037), [OrthoMerge](https://arxiv.org/pdf/2602.05943), [AVIC](https://arxiv.org/pdf/2602.08236), [ReMoT](https://arxiv.org/pdf/2603.00461), [PolyV](https://arxiv.org/abs/2603.03564), [Holi-Spatial](https://arxiv.org/pdf/2603.07660), [ViewFusion](https://arxiv.org/pdf/2603.06024), [OpenSpatial](https://arxiv.org/pdf/2604.07296), [GUIDE](https://arxiv.org/pdf/2604.05695), [HY-Embodied-0.5](https://arxiv.org/pdf/2604.07430), [JoyAI-Image](https://joyai-image.s3.cn-north-1.jdcloud-oss.com/JoyAI-Image.pdf), [mni](https://arxiv.org/pdf/2604.21921), [VisionFoundry](https://arxiv.org/pdf/2604.09531).
🎉[2026-01-26]: MMSI-Bench is accepted by ICLR 2026!
🔥[2025-12-19]: MMSI-Bench is supported by [EASI](https://github.com/EvolvingLMMs-Lab/EASI?tab=readme-ov-file), a unified evaluation suite for spatial intelligence. For more model results, please refer to the [EASI Leaderboard](https://huggingface.co/spaces/lmms-lab-si/easi-leaderboard).
🔥[2025-12-16]: We released [MMSI-Video-Bench](https://rbler1234.github.io/MMSI-VIdeo-Bench.github.io/), a holistic benchmark for video-based spatial intelligence.
🔥[2025-11-27]: The correspondence between the images in MMSI-Bench and the original dataset can be found in the [file](https://drive.google.com/file/d/1UKmhyMaC2OW94jxHIkSuw4YBofqHYPaA/view?usp=drive_link).
🔥[2025-10-23]: We added the normalized human response time for each MMSI-Bench sample and its difficulty level to our dataset on Hugging Face. To keep the task categories balanced across difficulty levels, we performed stratified sampling by difficulty within each task category.
🔥[2025-06-28]: MMSI-Bench is now officially supported by [OpenCompass Spatial Leaderboard](https://huggingface.co/spaces/opencompass/openlmm_spatial_leaderboard) as a key benchmark for spatial understanding. It includes a *circular* testing protocol that effectively reduces the impact of random guessing. The best-performing non-thinking model so far, [Seed-VL 1.5](https://www.google.com.hk/search?q=seed-vl-1.5), achieves **20.3%** accuracy.
🔥[2025-06-18]: MMSI-Bench has been supported in the [LMMs-Eval](https://github.com/EvolvingLMMs-Lab/lmms-eval) repository.
🔥[2025-06-9]: MMSI-Bench has been supported in the [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) repository. Note: The VLMEvalKit repository uses its default answer extraction method, while this repository uses MMSI-Bench-specific post-prompts and regular expressions for answer extraction.
🔥[2025-05-30]: We released our paper, benchmark, and evaluation codes.
## Introduction
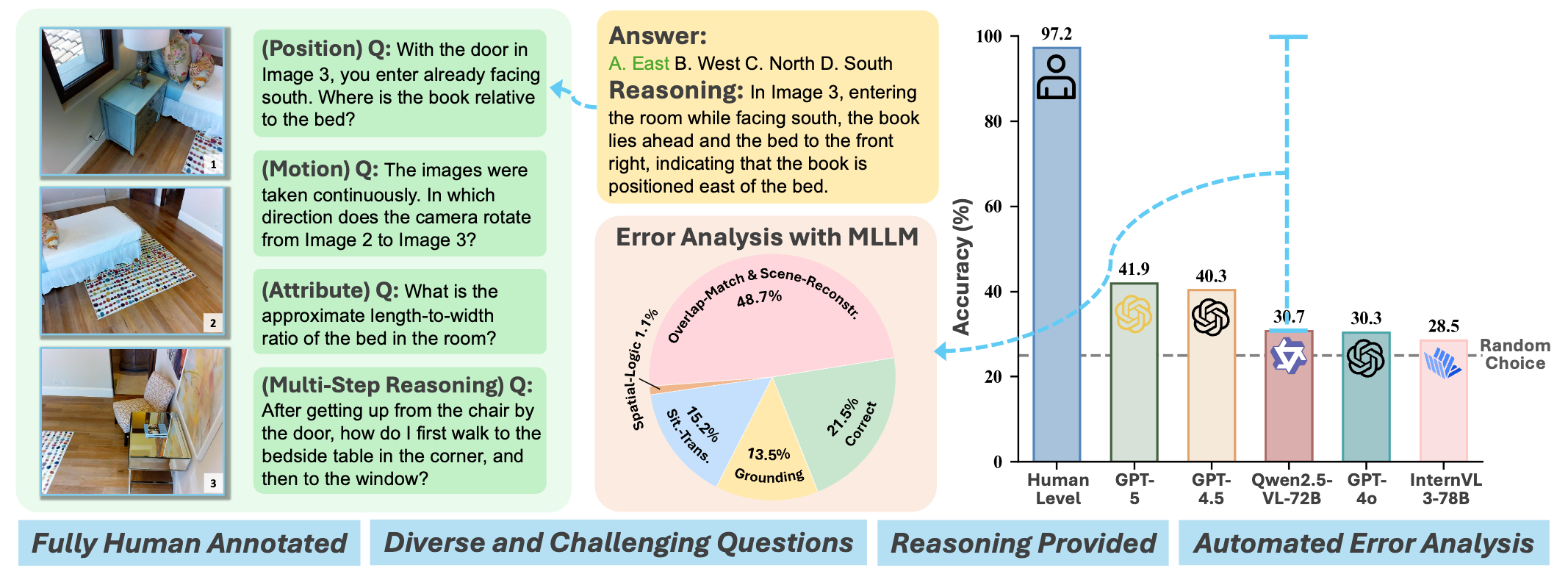
We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours crafting 1,000 challenging, unambiguous multiple-choice questions, each paired with a step-by-step reasoning process. We conduct extensive experiments and evaluate 34 MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI’s o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research.
## Why MMSI-Bench?
There are several concurrent works on building spatial intelligence benchmarks for MLLMs. Our MMSI-Bench possesses the following unique features:
**1. Multi-image.** We target multi-image spatial reasoning: each of the ten fundamental tasks involves two images, while the multi-step reasoning tasks use more.
**2. High quality.** Every question is fully human-designed—selecting images, crafting questions, carefully designing distractors, and annotating step-by-step reasoning processes.
**3. Aligned with real-world scenarios.** All images depict real-world scenes from domains such as autonomous driving, robotic manipulation, and scene scanning, and every question demands real-world scene understanding and reasoning. We do not use any synthetic data.
**4. Comprehensive and challenging.** We benchmark 34 MLLMs—nearly all leading proprietary and open-source models—and observe a large gap between model and human performance. Most open-source models perform at roughly random-choice level. To the best of our knowledge, our benchmark shows the largest reported model-human gap.
**5. Reasoning processes.** Each sample is annotated with a step-by-step reasoning trace that justifies the correct answer and helps diagnose model errors.
## Example
MMSI-Bench is structured around three fundamental spatial elements: camera (the agent), object (entities in the environment), and region (semantic areas such as rooms). Building on these, it covers six types of positional relationships (camera-camera, camera-object, camera-region, object-object, object-region, and region-region), two types of attribute reasoning (measurement and appearance), two types of motion reasoning (camera motion and object motion), and a multi-step reasoning category, for a total of eleven task types.

## 🏆 MMSI-Bench Leaderboard
| Model | Avg. (%) | Type |
|------------------------------|:--------:|:-------------|
| 🥇 **Human Level** | 97.2 | Baseline |
| 🥈 Gemini-3-pro | 49.2 | Proprietary |
| 🥉 SenseNova-SI-1.2-InternVL3-8B | 42.6 | Open-source |
| GPT-5 | 41.9 | Proprietary |
| o3 | 41.0 | Proprietary |
| GPT-4.5 | 40.3 | Proprietary |
| SenseNova-SI-1.1-Qwen3-VL-8B | 38.1 | Open-source |
| Gemini-2.5-Pro--Thinking | 37.0 | Proprietary |
| Gemini-2.5-Pro | 36.9 | Proprietary |
| SenseNova-SI-1.1-BAGEL-7B-MoT | 34.5 | Open-source |
| Doubao-1.5-pro | 33.0 | Proprietary |
| SenseNova-SI-1.1-Qwen2.5-VL-7B | 32.8 | Open-source |
| GPT-4.1 | 30.9 | Proprietary |
| SenseNova-SI-1.1-Qwen2.5-VL-3B | 30.8 | Open-source |
| Qwen2.5-VL-72B | 30.7 | Open-source |
| NVILA-15B | 30.5 | Open-source |
| GPT-4o | 30.3 | Proprietary |
| Claude-3.7-Sonnet--Thinking | 30.2 | Proprietary |
| Seed1.5-VL | 29.7 | Proprietary |
| InternVL2.5-2B | 29.0 | Open-source |
| InternVL2.5-8B | 28.7 | Open-source |
| DeepSeek-VL2-Small | 28.6 | Open-source |
| InternVL3-78B | 28.5 | Open-source |
| InternVL2.5-78B | 28.5 | Open-source |
| LLaVA-OneVision-72B | 28.4 | Open-source |
| NVILA-8B | 28.1 | Open-source |
| InternVL2.5-26B | 28.0 | Open-source |
| DeepSeek-VL2 | 27.1 | Open-source |
| InternVL3-1B | 27.0 | Open-source |
| InternVL3-9B | 26.7 | Open-source |
| Qwen2.5-VL-3B | 26.5 | Open-source |
| InternVL2.5-4B | 26.3 | Open-source |
| InternVL2.5-1B | 26.1 | Open-source |
| Qwen2.5-VL-7B | 25.9 | Open-source |
| InternVL3-8B | 25.7 | Open-source |
| InternVL3-2B | 25.3 | Open-source |
| Llama-3.2-11B-Vision | 25.4 | Open-source |
| 🃏 **Random Guessing** | 25.0 | Baseline |
| LLaVA-OneVision-7B | 24.5 | Open-source |
| DeepSeek-VL2-Tiny | 24.0 | Open-source |
| Blind GPT-4o | 22.7 | Baseline |
## Load Dataset
```
from datasets import load_dataset
dataset = load_dataset("RunsenXu/MMSI-Bench")
print(dataset)
# After downloading the parquet file, read each record, decode images from binary, and save them as JPG files.
import pandas as pd
import os
df = pd.read_parquet('MMSI_Bench.parquet')
output_dir = './images'
os.makedirs(output_dir, exist_ok=True)
for idx, row in df.iterrows():
id_val = row['id']
images = row['images']
question_type = row['question_type']
question = row['question']
answer = row['answer']
thought = row['thought']
mean_normed_duration_seconds = row['mean_normed_duration_seconds']
difficulty = row['difficulty']
image_paths = []
if images is not None:
for n, img_data in enumerate(images):
image_path = f"{output_dir}/{id_val}_{n}.jpg"
with open(image_path, "wb") as f:
f.write(img_data)
image_paths.append(image_path)
else:
image_paths = []
print(f"id: {id_val}")
print(f"images: {image_paths}")
print(f"question_type: {question_type}")
print(f"question: {question}")
print(f"answer: {answer}")
print(f"thought: {thought}")
print(f"mean_normed_duration_seconds: {mean_normed_duration_seconds}")
print(f"difficulty: {difficulty}")
print("-" * 50)
```
## Quick Start
Please refer to the [evaluation guidelines](https://github.com/open-compass/VLMEvalKit/blob/main/docs/en/Quickstart.md) of [VLMEvalKit](https://github.com/open-compass/VLMEvalKit)
### Installation
```
git clone https://github.com/OpenRobotLab/MMSI-Bench.git
cd MMSI-Bench
pip install -e .
```
### Run Evaluation
```
# api model
python run.py --model Seed1.5-VL --data MMSI_Bench
# huggingface model
python run.py --model Qwen2.5-VL-7B-Instruct --data MMSI_Bench
```
### Supporting Custom Models
When you need to evaluate a model that is not supported by VLMEvalKit, you should refer to the existing inference scripts in `vlmeval/vlm` to implement the inference script for your model. It is mandatory to implement support for the `generate_inner` API.
All existing models are implemented in `vlmeval/vlm`. For a minimal implementation, your model class must include the method `generate_inner(msgs, dataset=None)`. In this function, you will feed a multi-modal message (`msgs`) to your Vision Language Model (VLM) and return the model's prediction as a string.
The optional `dataset` argument can be used as a flag for the model to switch between different inference strategies based on the dataset being evaluated.
The `msgs` argument is a list of dictionaries, where each dictionary has two keys: `type` and `value`.
* `type`: We currently support two types: `"image"` and `"text"`.
* `value`:
* When `type` is `'text'`, the value is the text message (a single string).
* When `type` is `'image'`, the value can be the local path to an image file or a URL pointing to an image.
### Answer Extraction
We use the following post-prompt and extraction logic to extract the model's answer. If the extraction fails, we use the default settings of VLMEvalKit to extract the answer with an LLM.
```
post_prompt: "\nAnswer with the option's letter from the given choices directly. Enclose the option's letter within ``."
```
```
def extract_single_choice_with_word_boundary(pred, gt):
pattern_1 = r'``([^`]*)``'
match = re.search(pattern_1, pred)
if match:
pred = match.group(1)
pattern_2 = r'`([^`]*)`'
match = re.search(pattern_2, pred)
if match:
pred = match.group(1)
pattern_add = r'\{([^}]*)\}'
match = re.search(pattern_add, pred)
if match:
pred = match.group(1)
pattern_3 = r'\b[A-D]\b(?!\s[a-zA-Z])'
match = re.search(pattern_3, pred)
if match:
pred = match.group()
else:
return None
answer = gt.lower().replace("\n", " ").strip()
predict = pred.lower().replace("\n", " ").strip()
try:
if answer == predict[0]:
return 1.0
except Exception as e:
return 0.0
return 0.0
```
## 🔗 Citation
If you find our work and this codebase helpful, please consider starring this repo 🌟 and cite:
```bibtex
@inproceedings{yang2025mmsi,
title={MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence},
author={Yang, Sihan and Xu, Runsen and Xie, Yiman and Yang, Sizhe and Li, Mo and Lin, Jingli and Zhu, Chenming and Chen, Xiaochen and Duan, Haodong and Yue, Xiangyu and Lin, Dahua and Wang, Tai and Pang, Jiangmiao},
booktitle={ICLR},
year={2025}
}
```
## 📄 License
Shield: [![CC BY 4.0][cc-by-shield]][cc-by]
This work is licensed under a
[Creative Commons Attribution 4.0 International License][cc-by].
[][cc-by]
[cc-by]: https://creativecommons.org/licenses/by/4.0/
## Acknowledgment
MMSI-Bench makes use of data from existing image datasets: [ScanNet](http://www.scan-net.org/), [nuScenes](https://www.nuscenes.org/), [Matterport3D](https://niessner.github.io/Matterport/), [Ego4D](https://ego4d-data.org/), [AgiBot-World](https://agibot-world.cn/), [DTU](https://roboimagedata.compute.dtu.dk/?page_id=36), [DAVIS-2017](https://davischallenge.org/) ,and [Waymo](https://waymo.com/open/). We thank these teams for their open-source contributions.
## Contact
- Sihan Yang: sihany077@gmail.com
- Runsen Xu: runsxu@gmail.com