
XHS-Downloader
简体中文 | English






🔥 RedNote Link Extraction/Content Collection Tool:Extract account-published, favorites, and liked notes links; extract search result notes links and user links; collect RedNote notes information; extract RedNote notes download addresses; download RedNote notes files!
🔥 "RedNote", "XiaoHongShu" and "小红书" have the same meaning, and this project is collectively referred to as "RedNote".
⭐ Due to the author's limited energy, I was unable to update the English document in a timely manner, and the content may have become outdated, partial translation is machine translation, the translation result may be incorrect, Suggest referring to Chinese documentation. If you want to contribute to translation, we warmly welcome you.
Watch Demo on Bilibili;Watch Demo on YouTube
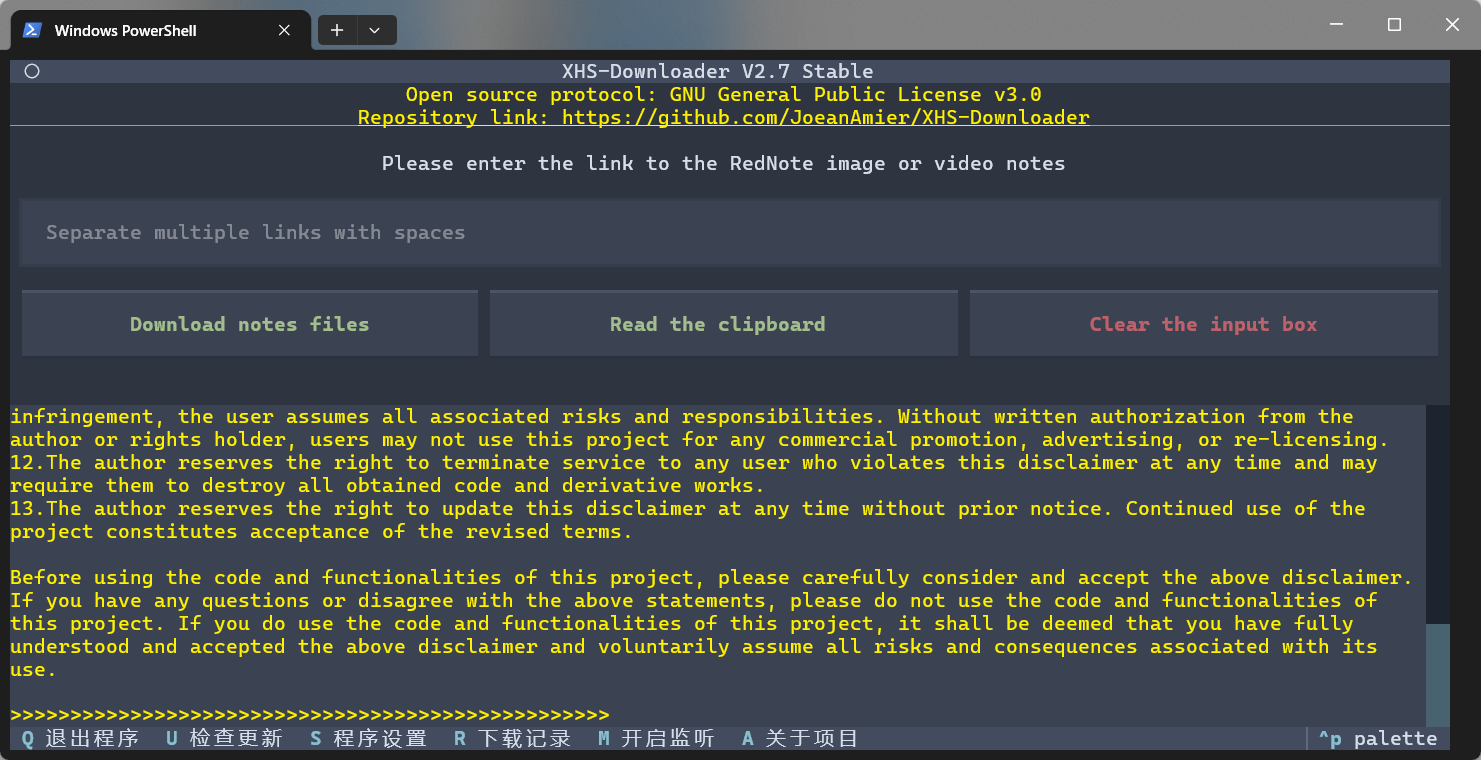
https://www.xiaohongshu.com/explore/NoteID?xsec_token=XXXhttps://www.xiaohongshu.com/discovery/item/NoteID?xsec_token=XXXhttps://www.xiaohongshu.com/user/profile/AuthorID/NoteID?xsec_token=XXXhttps://xhslink.com/ShareCodeSupports entering multiple notes links at once, separated by spaces; the program will automatically extract valid links without additional processing!
⭐ It is recommended to use the Windows Terminal (default terminal for Windows 11) to run the program for the best display effect!
If you only need to download notes files, it is recommended to choose Program Run; if you have other needs, it is recommended to choose Source Code Run!
⚠️ When Cookie is not set, video works can only be downloaded in low resolution; it is recommended to configure Cookie to obtain higher quality (no need to log in to the account)!
⭐ Mac OS, Windows 10 and above users can go to Releases or Actions to download the program package, unzip it, open the program folder, and double-click to run main to use.
⭐ This project includes GitHub Actions for automatic building executable files. Users can use GitHub Actions to build the latest source code into executable files at any time!
⭐ For the automatic building executable files tutorial, please refer to the Build of Executable File Guide section of this document. If you need a more detailed step-by-step tutorial with illustrations, please check out this article!
Note: Due to the macOS platform's executable file main not being code-signed, it will be restricted by system security measures on first run. Please execute the command xattr -cr project_folder_path in the terminal to remove the security flag, after which it can run normally.
If you use the program in this way, the default download path for files is: .\_internal\Volume\Download; the configuration file path is: .\_internal\Volume\settings.json
Method 1: Download and extract the files, then copy the old version of the _internal\Volume folder into the new version's _internal folder.
Method 2: Download and extract the files (do not run the program), then copy all files and directly overwrite the old version.
≥3.12python -m venv venv to create a virtual environment (optional).\venv\Scripts\activate.ps1 or venv\Scripts\activate to activate the virtual environment (optional)pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt to install the required modules for the programpython .\main.py or python main.py to start XHS-Downloaderuv sync --no-dev to synchronize environment dependenciesuv run main.py to start XHS-DownloaderDockerfiledocker pull joeanamier/xhs-downloaderdocker pull ghcr.io/joeanamier/xhs-downloaderdocker run --name ContainerName(optional) -p HostPort:5556 -v xhs_downloader_volume:/app/Volume -it <image name>docker run --name ContainerName(optional) -p HostPort:5556 -v xhs_downloader_volume:/app/Volume -it <image name> python main.py apidocker run --name ContainerName(optional) -p HostPort:5556 -v xhs_downloader_volume:/app/Volume -it <image name> python main.py mcp<image name> here must be consistent with the image name you used in the first step (joeanamier/xhs-downloader or ghcr.io/joeanamier/xhs-downloader)
docker start -i ContainerName/ContainerIDdocker restart -i ContainerName/ContainerIDWhen running the project via Docker, the command line call mode is not supported. The clipboard reading and clipboard monitoring functions are unavailable, but pasting content notes fine. Please provide feedback if other features are not functioning properly!
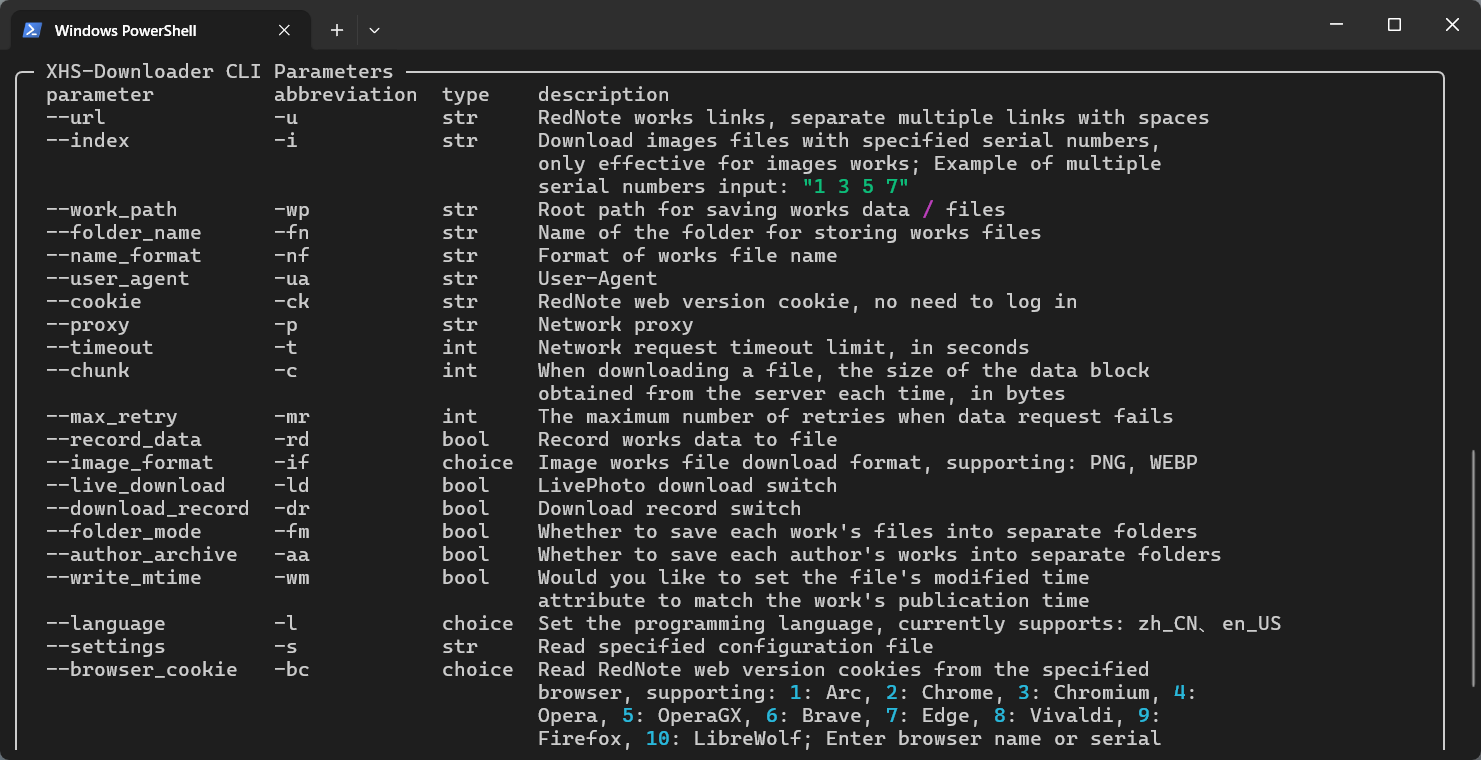
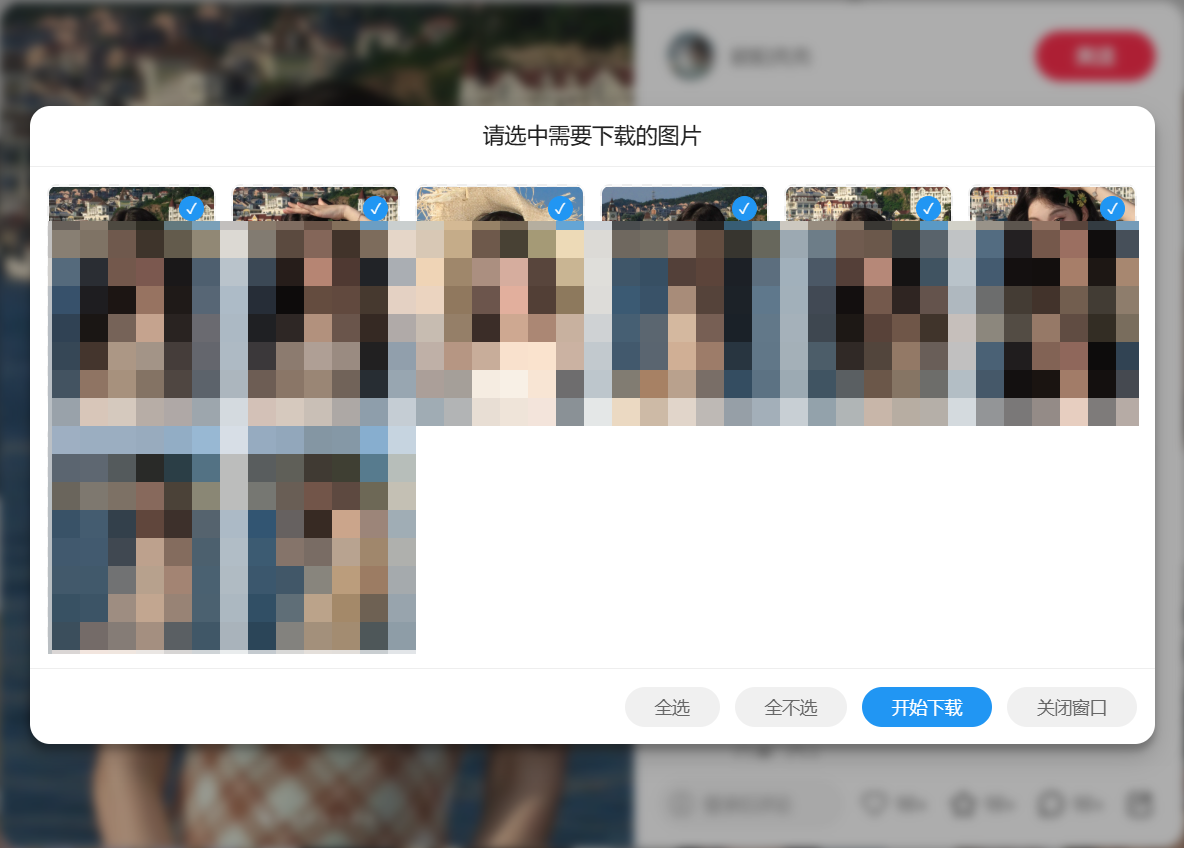
The project supports command line mode. If you want to download specific images from a text and image notes, you can use this mode to set the image sequence number you want to download!
Note: When the --index parameter is not set, multiple notes links can be passed in. All links must be enclosed in quotation marks and separated by spaces. When the --index parameter is set, multiple notes links are not supported. Even if multiple links are passed in, the program will only process the first link!
The bool type parameters support setting with true, false, 1, 0, yes, no, on or off (case insensitive).
This feature is no longer available. Please refer to the Obtain Cookie tutorial!
You can use the command line to read cookies from browser and write them to the configuration file!
Command example: python .\main.py --browser_cookie Chrome --update_settings
Compatibility note: The third-party module this feature depends on has not been updated for a long time and may not properly support the latest browser versions. If the feature is not working properly, please try obtaining cookies manually!
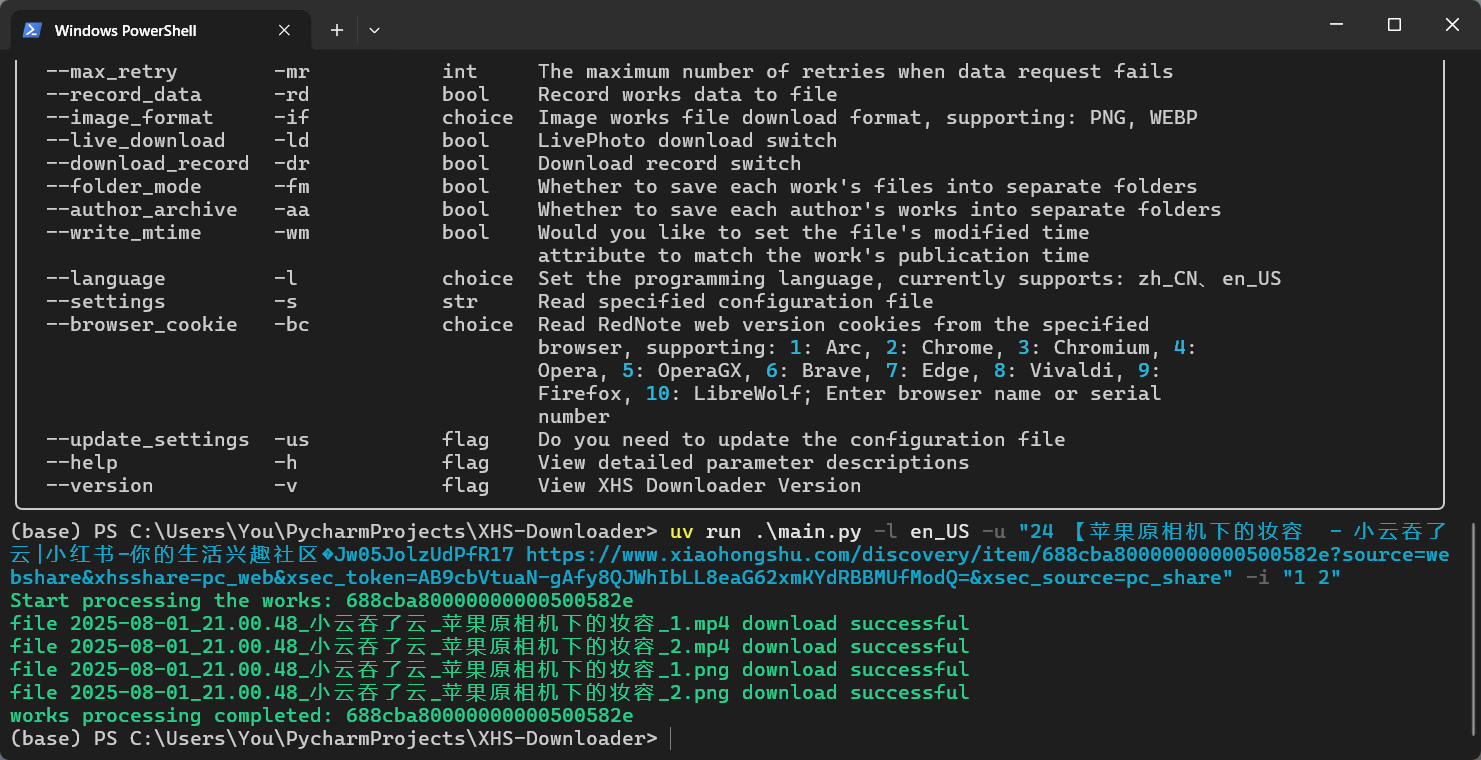
Server modes include API mode and MCP mode!
Start: Run the command: python .\main.py api
Stop: Press Ctrl + C to stop the server
Open http://127.0.0.1:5556/docs or http://127.0.0.1:5556/redoc; you will see automatically generated interactive API documentation!
Request endpoint:
/xhs/detail
Request method:
POST
Request format:
JSON
Request parameters:
| Parameter | Type | Description | Default |
|---|---|---|---|
| url | str | RedNote notes link, auto-extraction, does not support multiple links; Required parameter | None |
| download | bool | Whether to download the notes file; set to true will take more time; Optional parameter |
false |
| index | list[int] | Download specific image files by index, only effective for text and image notes; not effective when the download parameter is set to false; Optional parameter |
null |
| cookie | str | Cookie used when requesting data; Optional parameter | Settings cookie Value |
| proxy | str | Proxy used when requesting data; Optional parameter | Settings proxy Value |
| skip | bool | Whether to skip notes with download records; set to true will not return notes data with download records; Optional parameter |
false |
Code example:
async def example_api():
"""通过 API 设置参数,适合二次开发"""
server = "http://127.0.0.1:5556/xhs/detail"
data = {
"url": "", # 必需参数
"download": True,
"index": [
3,
6,
9,
],
"proxy": "http://127.0.0.1:10808",
}
response = post(server, json=data, timeout=10)
print(response.json())
Start: Run the command: python .\main.py mcp
Stop: Press Ctrl + C to stop the server
MCP URL:http://127.0.0.1:5556/mcp/
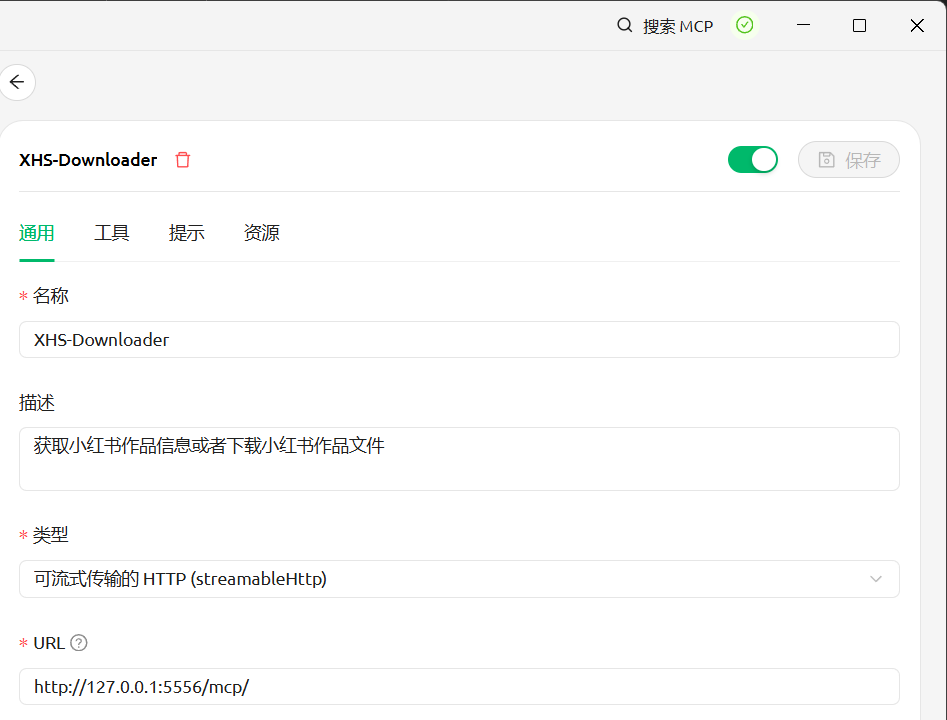
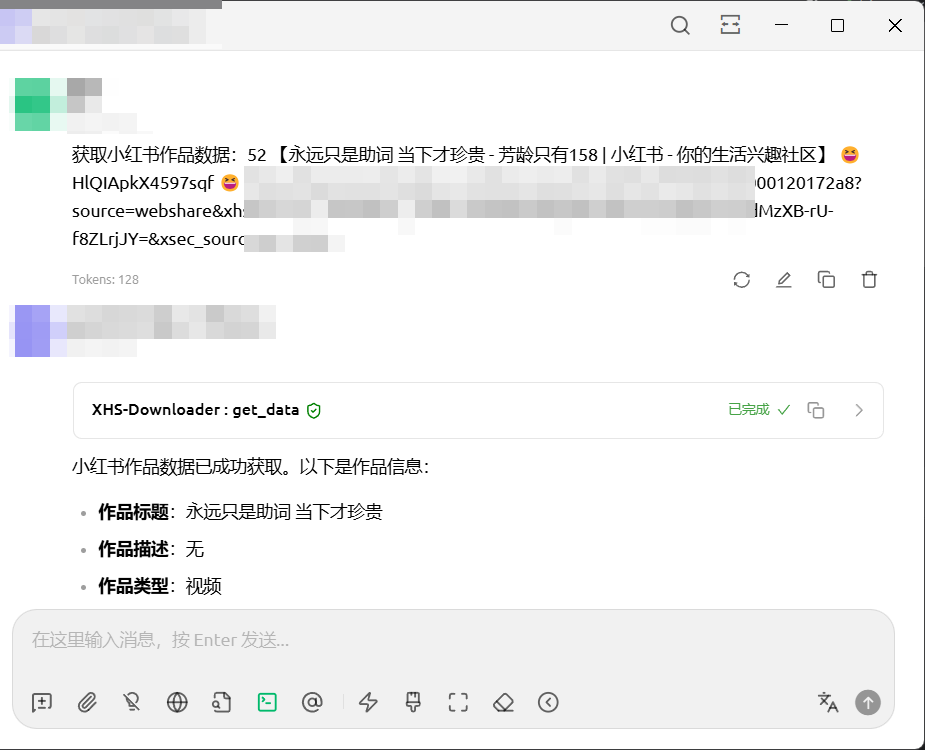
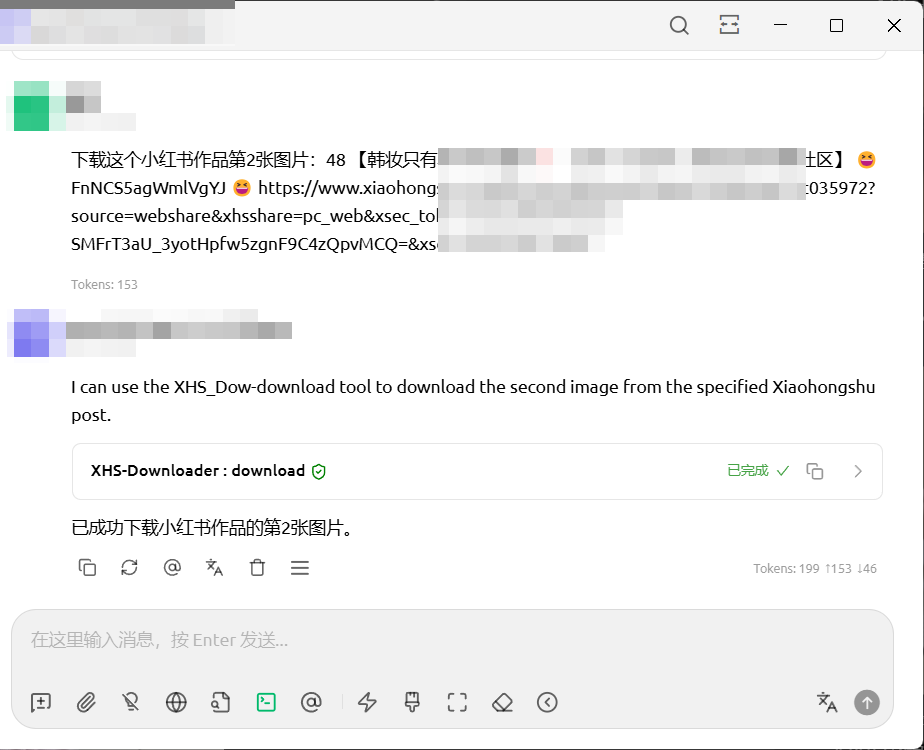
When downloading images, you can specify the sequence numbers of the images to download. By default, post information is not returned. If you need the post information, please explicitly state so during the conversation.
./Volume/Download/ExploreData.db file./Volume/ExploreID.db fileIf your browser has the Tampermonkey extension installed, you can use the userscript to try the project's features!
Userscript links (right-click to copy the link): master branch, develop branch

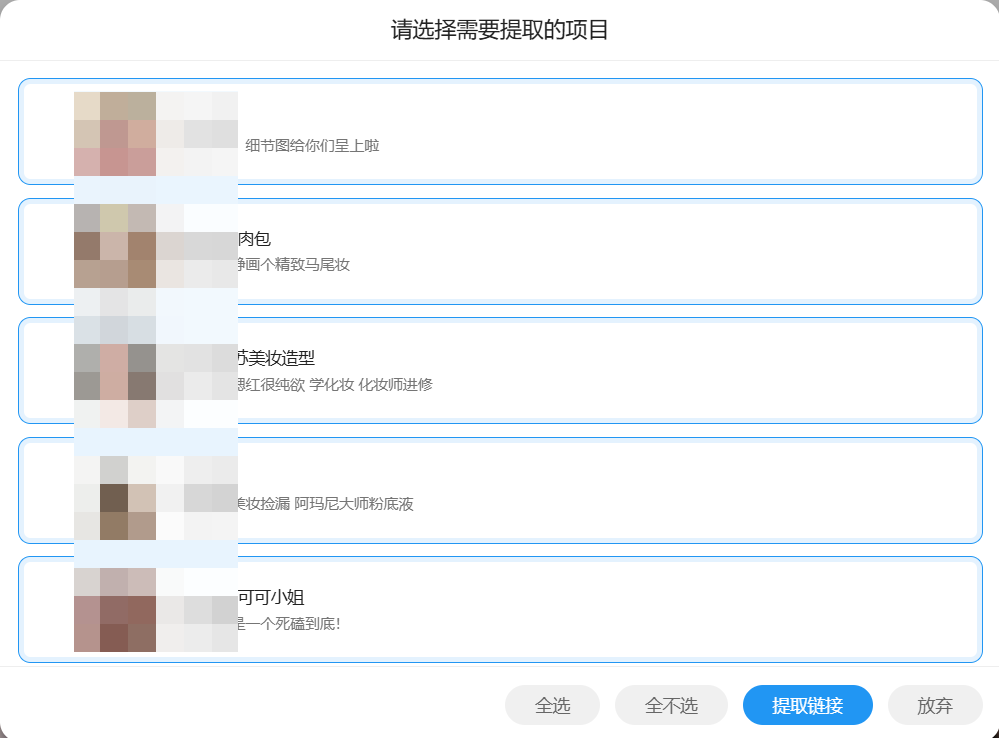
Note: Using the XHS-Downloader user script to batch extract notes links, in combination with the XHS-Downloader program, can achieve batch downloading of notes files!
Modify user script language

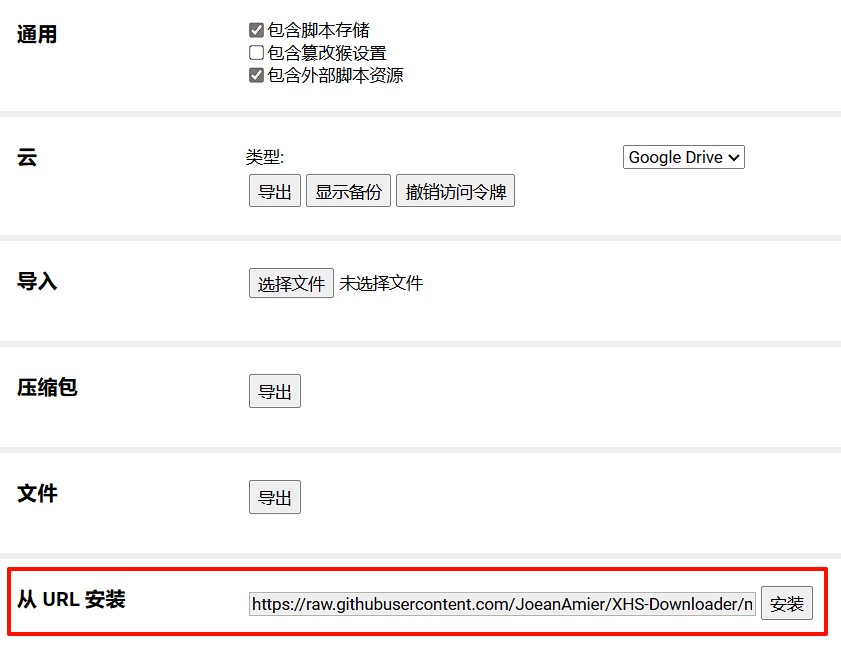
⭐ This project supports interaction with the main program through a browser userscript, enabling one-click push of download tasks.
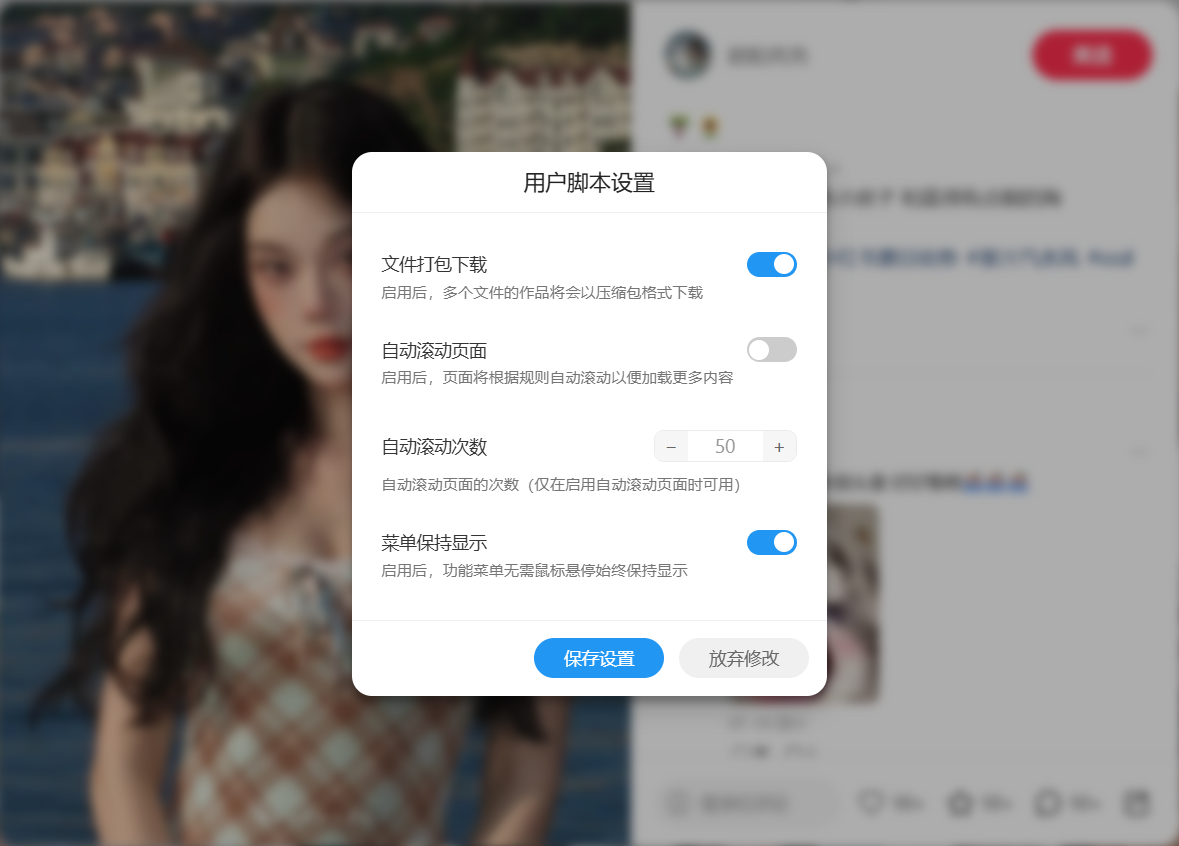
script_server parameter to truePush Download Task option in the userscript menuThe automatic page scroll feature has been refactored and is turned off by default! Enabling this feature may be detected as automated behavior by RedNote, potentially resulting in account risk control or banning.
If you have other needs, you can perform code calls or modifications based on the comments in example.py!
async def example():
"""通过代码设置参数,适合二次开发"""
# 示例链接
demo_link = "https://www.xiaohongshu.com/explore/XXX?xsec_token=XXX"
# 实例对象
work_path = "D:\\" # 作品数据/文件保存根路径,默认值:项目根路径
folder_name = "Download" # 作品文件储存文件夹名称(自动创建),默认值:Download
name_format = "作品标题 作品描述"
user_agent = "" # User-Agent
cookie = "" # 小红书网页版 Cookie,无需登录,可选参数,登录状态对数据采集有影响
proxy = None # 网络代理
timeout = 5 # 请求数据超时限制,单位:秒,默认值:10
chunk = 1024 * 1024 * 10 # 下载文件时,每次从服务器获取的数据块大小,单位:字节
max_retry = 2 # 请求数据失败时,重试的最大次数,单位:秒,默认值:5
record_data = False # 是否保存作品数据至文件
image_format = "WEBP" # 图文作品文件下载格式,支持:AUTO、PNG、WEBP、JPEG、HEIC
folder_mode = False # 是否将每个作品的文件储存至单独的文件夹
image_download = True # 图文、图集作品文件下载开关
video_download = True # 视频作品文件下载开关
live_download = False # 图文动图文件下载开关
download_record = True # 是否记录下载成功的作品 ID
language = "zh_CN" # 设置程序提示语言
author_archive = True # 是否将每个作者的作品存至单独的文件夹
write_mtime = True # 是否将作品文件的 修改时间 修改为作品的发布时间
read_cookie = None # 读取浏览器 Cookie,支持设置浏览器名称(字符串)或者浏览器序号(整数),设置为 None 代表不读取
# async with XHS() as xhs:
# pass # 使用默认参数
async with XHS(
work_path=work_path,
folder_name=folder_name,
name_format=name_format,
user_agent=user_agent,
cookie=cookie,
proxy=proxy,
timeout=timeout,
chunk=chunk,
max_retry=max_retry,
record_data=record_data,
image_format=image_format,
folder_mode=folder_mode,
image_download=image_download,
video_download=video_download,
live_download=live_download,
download_record=download_record,
language=language,
read_cookie=read_cookie,
author_archive=author_archive,
write_mtime=write_mtime,
) as xhs: # 使用自定义参数
download = True # 是否下载作品文件,默认值:False
# 返回作品详细信息,包括下载地址
# 获取数据失败时返回空字典
print(
await xhs.extract(
demo_link,
download,
index=[
1,
2,
5,
],
)
)
The project uses pyperclip to implement clipboard reading functionality, which varies across different systems.
On Windows, no additional modules are needed.
On Mac, this module makes use of the pbcopy and pbpaste commands, which should come with the os.
On Linux, this module makes use of the xclip or xsel commands, which should come with the os. Otherwise run "sudo apt-get install xclip" or "sudo apt-get install xsel" (Note: xsel does not always seem to work.)
Otherwise on Linux, you will need the qtpy or PyQT5 modules installed.
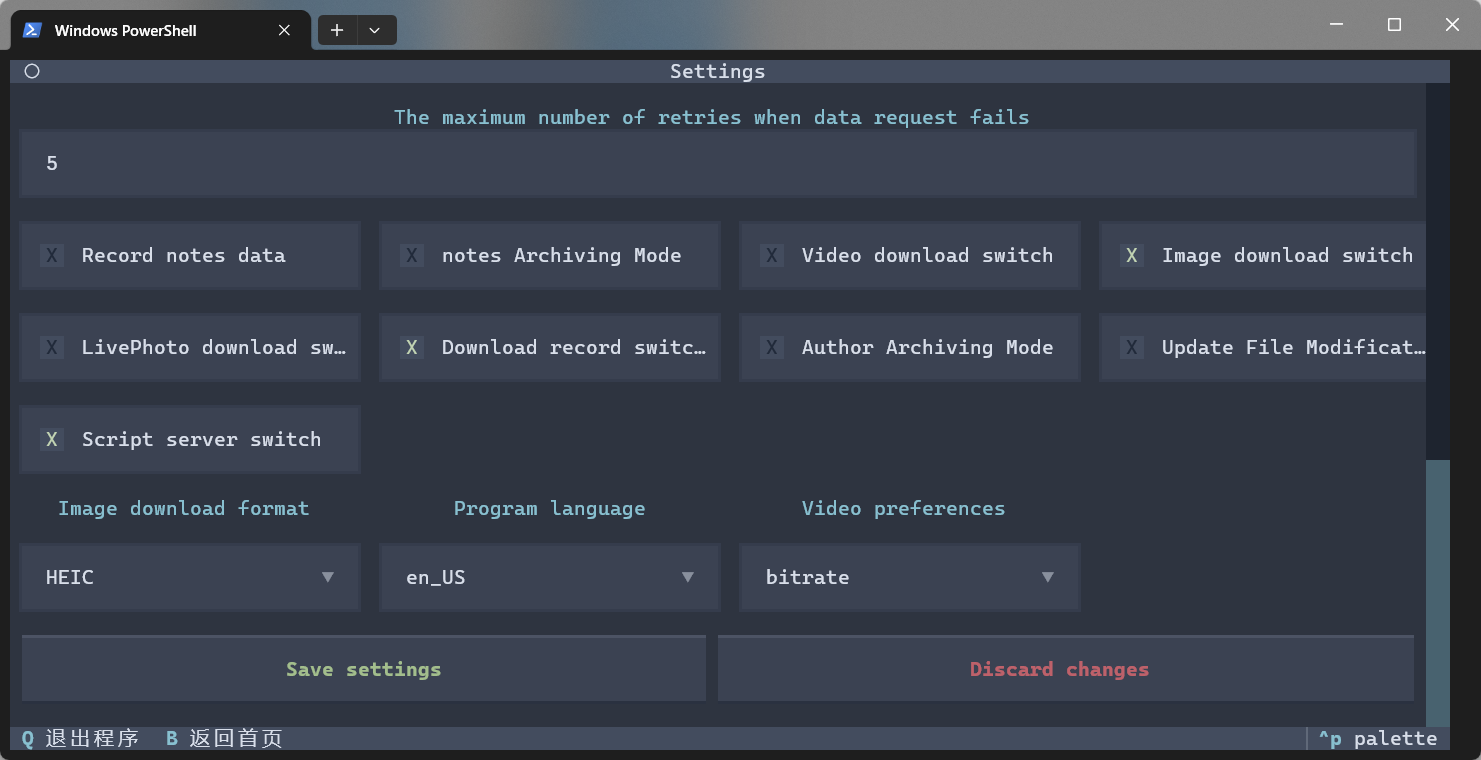
The ./Volume/settings.json file in the project's root directory is automatically generated on the first run. You can use it to customize the program's operating parameters. If an invalid parameter value is set, the program will revert to its default value.
If you are unable to modify settings through the program's interface, you can edit this configuration file directly. If your computer lacks a suitable program for editing JSON files, we recommend using an online tool. Remember to restart the software after making changes for them to take effect.
| Parameter | Type | Description | Default Value |
|---|---|---|---|
| mapping_data | str: str | #Author alias mapping data, format: author ID: author alias |
null |
| work_path | str | Root path for saving notes data/files | Project root path/Volume |
| folder_name | str | Name of the folder for storing notes files | Download |
| name_format | str | #Format of notes file name, separated by spaces between fields, supports fields: 收藏数量、评论数量、分享数量、点赞数量、作品标签、作品ID、作品标题、作品描述、作品类型、发布时间、最后更新时间、作者昵称、作者ID |
发布时间 作者昵称 作品标题 |
| user_agent | str | Browser User Agent | Built-in Chrome User Agent |
| cookie | str | RedNote web version cookie, No login required, non essential parameters! | None |
| proxy | str | Set program proxy | null |
| timeout | int | Request data timeout limit, in seconds | 10 |
| chunk | int | Size of data chunk to fetch from the server each time when downloading files, in bytes | 2097152(2 MB) |
| max_retry | int | Maximum number of retries when requesting data fails | 5 |
| record_data | bool | Whether to save notes data to a file, saved in SQLite format |
false |
| image_format | str | Download format for image notes files, supported: AUTO、PNG、WEBP、JPEG、HEICSome notes do not have files in HEIC format, and the downloaded files may be in WEBP format When set to AUTO, it represents dynamic format, and the actual format depends on the server's response data |
JPEG |
| image_download | bool | Switch for downloading image and atlas notes files | true |
| video_download | bool | Switch for downloading video notes files | true |
| live_download | bool | Switch for downloading animated image files | false |
| video_preference | str | Video notes file download preference; Meaning: resolution: resolution priority; bitrate: bitrate priority; size: file size priority |
resolution |
| folder_mode | bool | Whether to store each notes files in a separate folder; the folder name matches the file name | false |
| download_record | bool | Do record the ID of successfully downloaded notes? If enabled, the program will automatically skip downloading notes with records | true |
| author_archive | bool | #Whether to save each author's notes into a separate folder; The folder name is authorID_nickname |
false |
| write_mtime | bool | Whether to modify the modified time attribute of the notes file to the publication time of the notes. |
false |
| language | str | Set program language. Currently supported: zh_CN, en_US |
zh_CN |
| script_server | bool | Whether to enable the user script server for receiving download tasks from the browser user script (effective in TUI, MCP, and API modes) | false |
name_format instructions (Currently only supports Chinese values) :
收藏数量: Number of Collections评论数量: Number of Comments分享数量: Number of Shares点赞数量: Number of Likes作品标签: Notes Tags作品ID: Notes ID作品标题: Notes Title作品描述: Notes Description作品类型: Notes Type发布时间: Publish Time最后更新时间: Last Updated Time作者昵称: Author Nickname作者ID: Author IDAdditional Notes: The parameters user_agent examples are provided for reference; Strongly recommend setting according to actual browser information!
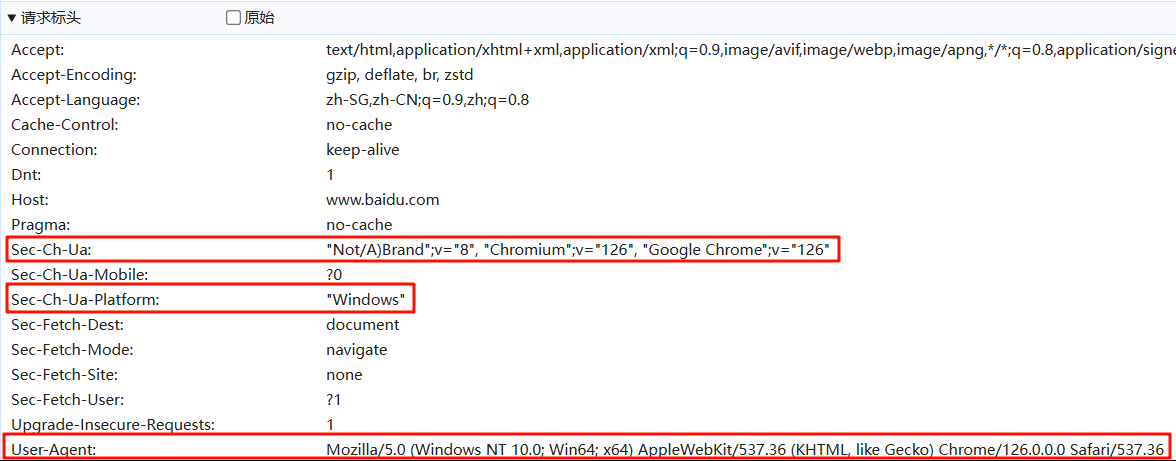
https://www.xiaohongshu.com/exploreF12 to open the developer toolsNetwork tabPreserve logFilter input box, enter cookie-name:web_sessionFetch/XHR filterNetwork tab, select any data packet (if no packets appear, repeat step 7)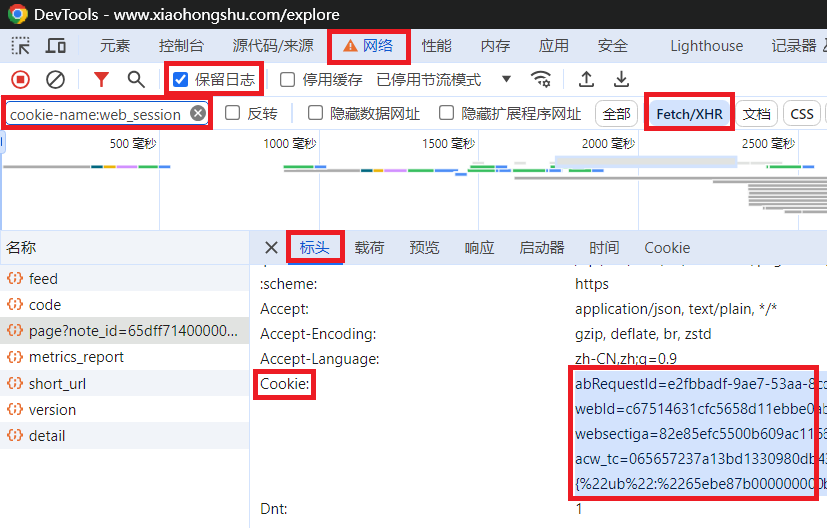
XHS-Downloader will store the IDs of downloaded notes in a database. When downloading the same notes again, XHS-Downloader will automatically skip the file download (even if the notes file does not exist). If you want to re-download the notes file, please delete the corresponding notes ID from the database and then use XHS-Downloader to download the notes file again!
This feature is enabled by default. If it is turned off, XHS-Downloader will check if the file exists. If the file exists, it will skip the download!
If XHS-Downloader has been helpful to you, please consider giving it a Star ⭐, Thank you for your support!
| 微信(WeChat) | 支付宝(Alipay) |
|---|---|
 |
 |
If you are willing, you may consider making a donation to provide additional support for XHS-Downloader!
Welcome to contributing to this project! To keep the codebase clean, efficient, and easy to maintain, please read the following guidelines carefully to ensure that your contributions can be accepted and integrated smoothly.
develop branch as the basis for your modifications; this helps avoid merge conflicts and ensures your changes are based on the latest state of the project.<type>: <short description>develop branch; this provides maintainers with a buffer zone for additional testing and review before final merging into the master branch.Reference materials:
✨ Other Open Source Projects by the Author:
ZMTO: A professional cloud infrastructure provider offering sophisticated solutions with reliable technology and expert support. We also empower qualified open source initiatives with enterprise-grade VPS infrastructure, driving sustainable development and innovation in the open source ecosystem.