# HDM: Improved UViT-like Architecture with a Special Recipe for Fast Pre-training on Consumer-Level Hardware
## Abstract
We introduce HDM (Home-made Diffusion Model), an efficient text-to-image diffusion model designed for training on consumer-level hardware. HDM achieves competitive 1024×1024 generation quality while reducing training costs to $535-620 using four RTX5090 GPUs, representing a significant cost reduction compared to traditional datacenter approaches.
Our key contributions include:
1. XUT (Cross-U-Transformer), a novel U-shaped transformer architecture using cross-attention for skip connections
2. a comprehensive training recipe incorporating TREAD acceleration and shifted square crop strategies
3. demonstration that small models with proper training strategies can achieve reasonable performance on consumer hardware.
## 1. Introduction
Text-to-image (T2I) generation represents one of the most important and challenging tasks in generative modeling. Current approaches in the field predominantly focus on scaling models to ever-larger sizes to achieve better performance [1,2]. However, this trend toward larger models creates significant barriers to entry, requiring substantial computational resources that are often beyond the reach of individual researchers and smaller organizations.
We argue that while large models can achieve superior performance, smaller models can still attain reasonable results through carefully designed training strategies and architectural innovations. Rather than pursuing scale alone, we focus on efficiency optimizations that democratize access to high-quality text-to-image generation.
Our approach centers on a UViT/HDiT-inspired architecture [3,4] enhanced with novel skip connection mechanisms. Since we successfully achieve state-of-the-art efficiency in pretraining text-to-image models using consumer-level hardware—literally training the model at home—we call it Home-made Diffusion Model (HDM).
## 2. Preliminary
### 2.1 Diffusion Models
Diffusion models have emerged as the dominant paradigm for high-quality image generation. The foundational DDPM framework [5] establishes a forward noising process that gradually corrupts data with Gaussian noise:
$q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\alpha_t}x_{t-1}, \alpha_t I)$
and a learned reverse process that generates samples by iteratively denoising:
$p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))$
More recently, flow matching approaches [6] provide an alternative formulation with improved training dynamics. Flow matching defines a continuous-time generative process through ordinary differential equations (ODEs):
$\frac{dx}{dt} = v_t(x)$
where $v_t(x)$ is a learned vector field. The flow matching objective minimizes:
$$
\mathcal{L}\_{FM} = \mathbb{E}\_{t,x_0,x_1}\|v_\theta(x_t, t) - (x_1 - x_0)\|^2
$$
This formulation can achieve similar results with potentially improved training dynamics and sampling efficiency.
### 2.2 Text-Guided Diffusion Models
The evolution of text encoders in diffusion models has progressed through several generations. Early models like Stable Diffusion relied primarily on CLIP text encoders [7], while more recent approaches like SD3/SD3.5 incorporate T5-XXL for enhanced text understanding [8]. A notable trend involves using causal language models as text encoders, with models like LLaMA, Gemma, and Qwen demonstrating effectiveness in this role [9]. Qwen has specifically released embedding models based on their language model architectures, though we maintain the causal LM structure and utilize the final hidden state as our text embedding.
### 2.3 UViT/HDiT Architectures
Standard Diffusion Transformers (DiT) [10] prove insufficient for complex image generation tasks. Following UNet principles, we adopt U-shaped transformer architectures that combine the benefits of hierarchical feature learning with transformer scalability. UViT and HDiT represent two distinct philosophical approaches to U-shaped transformers:
- **UViT** [3] maintains consistent resolution throughout the network, relying solely on U-shaped connections to facilitate multi-scale feature learning. UViT also propose that all the condition information (include timesteps, class condition, text condition and more) should be treated as input tokens. Instead of using adaLN or cross-attention. But HunYuan-DiT, a open sourced T2I base model which utilize UViT architecture, still used adaLN and cross-attention for text condition.
- **HDiT** [4] incorporates explicit downsampling/upsampling operations and employs local attention mechanisms (NATTEN) in higher-resolution layers while using global attention in lower-resolution layers to provide significant speed up (compare to standard DiT). This approach provide a more UNet-like intuition on multi-scale feature learning.
### 2.4 Efficient Pretraining Strategies
Recent advances in efficient diffusion training include several notable approaches. SANA [11] achieves dramatic sequence length reduction through DC-AE compression and employs linear attention to avoid quadratic complexity, though with some notable quality trade-offs. REPA/REPA-E [12] focus on convergence acceleration but are not specifically designed for extremely constrained training budgets. TREAD [13] provides both convergence acceleration and step speed improvements, making it particularly suitable for resource-constrained scenarios.
## 3. HDM Methodology
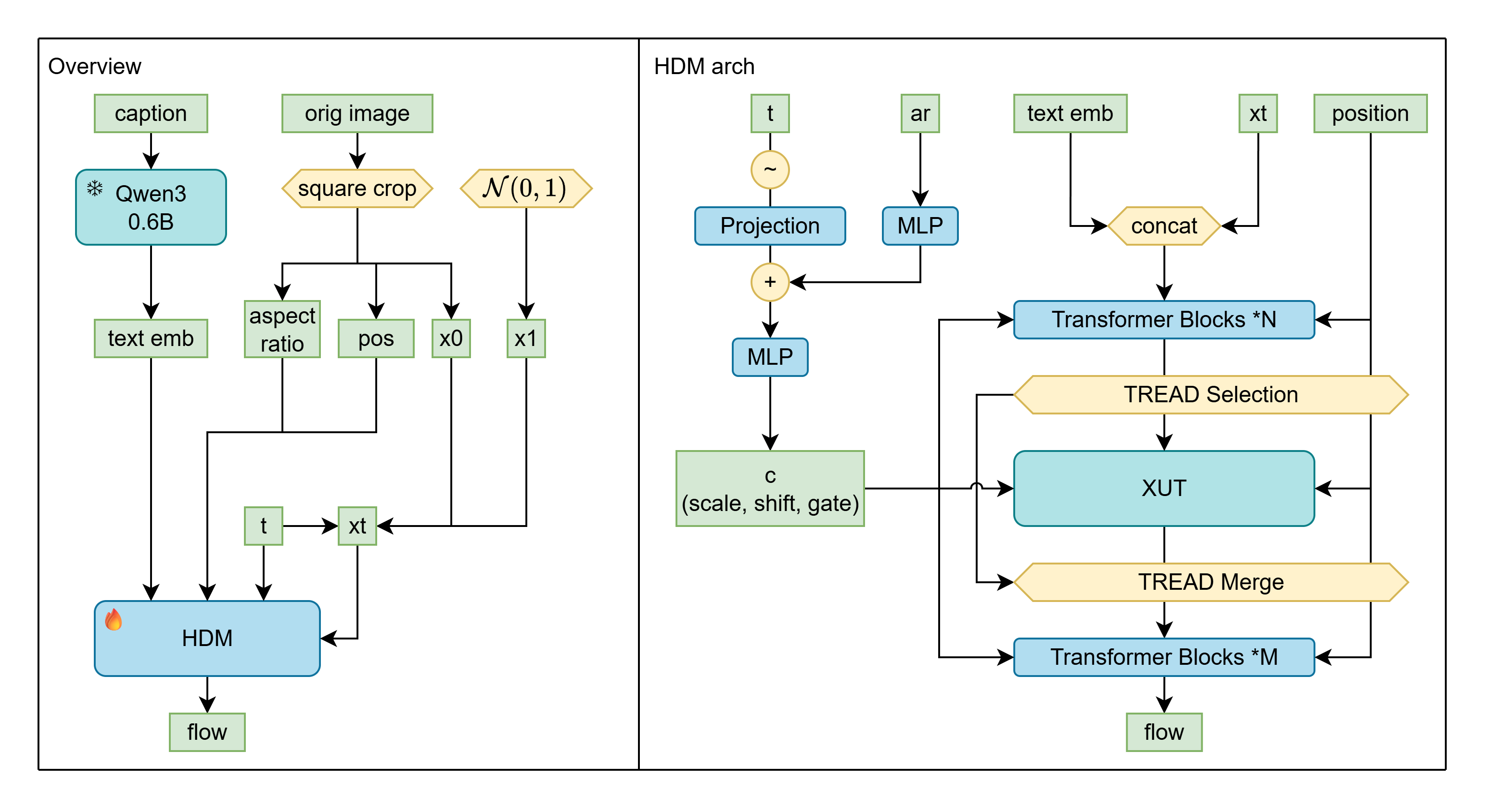
*Figure 1: HDM system overview showing the complete pipeline from input processing through XUT backbone to final output. The architecture integrates text encoding via Qwen3-0.6B, shifted square crop processing, and our novel XUT backbone with TREAD acceleration.*
### 3.1 XUT (Cross-U-Transformer) Architecture
Our XUT architecture draws inspiration from UViT/HDiT while introducing a novel approach to skip connections. We conceptualize the U-shaped architecture as: encoder → middle → decoder with feature merging. Traditional implementations typically use concatenation or addition for the merge operation. In XUT, we employ cross-attention to perform feature merging, leading us to term this the Cross-U-Transformer (XUT).
The architecture repeats this abstract pattern $n_{\text{depth}}$ times, with each depth containing $n_{\text{enc}}$ transformer blocks in encoder and $n_{\text{dec}}$ transformer blocks in decoder. This results in $(n_{\text{enc}} + n_{\text{dec}}) \times n_{\text{depth}}$ transformer blocks total, plus $n_{\text{depth}}$ cross-attention blocks placed in the first decoder transformer block of each depth.
Formally, for depth level $d$, we define:
$h_d^{\text{enc}} = \text{EncoderBlocks}^{(d)}(h_{d-1}^{\text{out}})$
$h_d^{\text{dec}} = \text{CrossAttn}(h_d^{\text{enc}}, h_{n_{\text{depth}}-d}^{\text{enc}}) + \text{DecoderBlocks}^{(d)}(h_d^{\text{enc}})$
where $h_0^{\text{out}}$ represents the input features and cross-attention enables selective information transfer from corresponding encoder depths.
For example, with $n_{\text{enc}}=1$, $n_{\text{dec}}=2$, $n_{\text{depth}}=2$:
```
input → trns → a → trns → b → trns(b,b) → c → trns → c' → trns(c',a) → d → trns → output
```
where $a, b, c, d$ represent hidden states and trns denotes transformer blocks with cross-attention when specified in trns(q, kv) form.
**Rationale for Cross-Attention**: U-shaped skip connections facilitate multi-scale feature learning by transmitting early features to later layers. In transformer architectures, cross-attention provides the most intuitive mechanism for "sending features" between distant layers, offering superior semantic understanding compared to naive concatenation or addition.
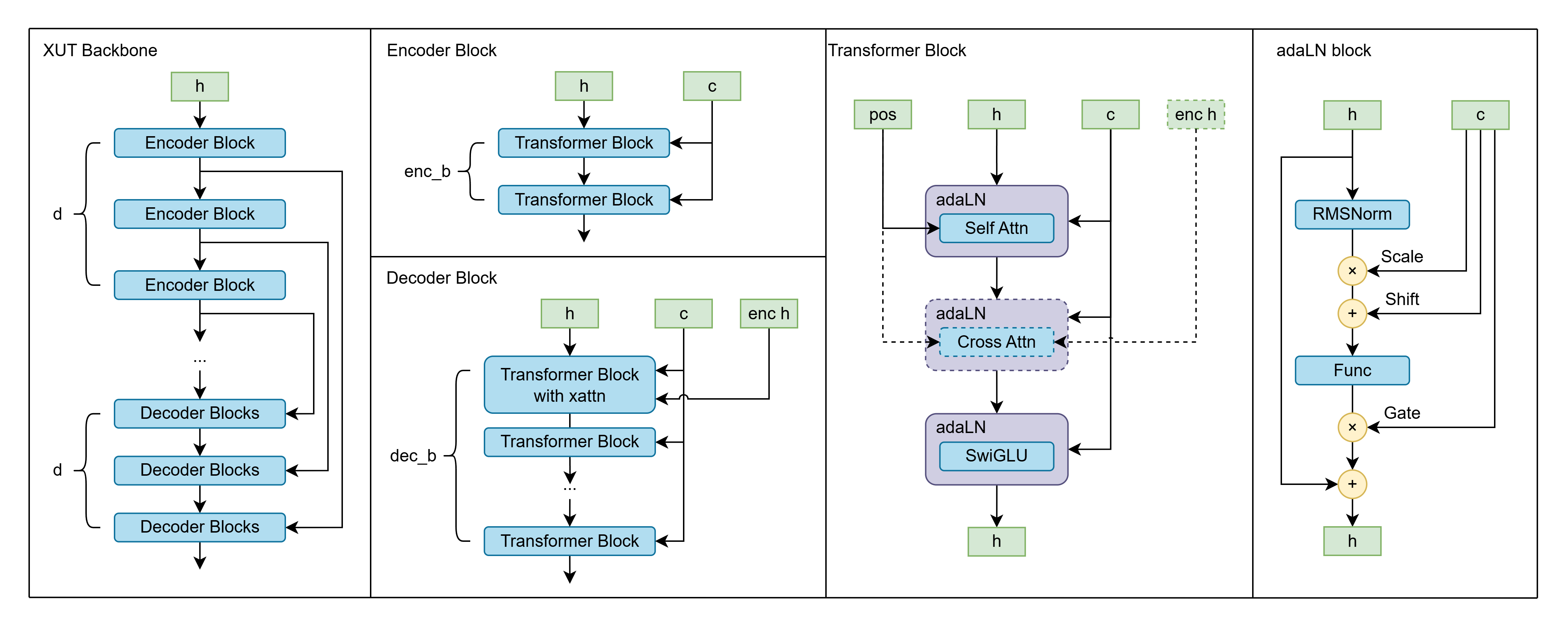
*Figure 2: Detailed XUT backbone architecture showing the encoder-decoder structure with cross-attention skip connections. The diagram illustrates how cross-attention mechanisms replace traditional concatenation-based skip connections in U-shaped architectures, enabling more sophisticated feature integration between encoder and decoder layers.*
### 3.2 Text Encoder Strategy
Text encoding represents a critical component in text-to-image generation. While early models relied on CLIP encoders and recent models incorporate T5-XXL [8], we observe a trend toward using causal language models as text encoders. Some research also demonstrates that fine-tuned LLMs can effectively serve as embedding models, for example: Qwen has released dedicated embedding models based on their architectures.
In HDM, we employ Qwen3-0.6B as our text encoder, representing one of the smallest causal language models suitable for this task. We maintain the unidirectional attention mechanism and directly use the final hidden state as our text embedding, leveraging the implicit positional information inherent in causal attention patterns.
### 3.3 Minimal Architecture Design
Modern text-to-image models employ various strategies for handling text and image modalities separately. DiT uses cross-attention to inject text features into image features, while MMDiT employs separate adaptive layer normalization (adaLN) modulation and MLPs with joint attention [14].
HDM pursues architectural minimalism by directly concatenating text and image features as input to the entire backbone. This approach aligns with UViT's philosophy of incorporating class tokens and timestep tokens into the input sequence, though we retain adaLN for conditional information.
**Shared adaLN**: As same as DiT-air or Chroma, We implement shared adaLN across all layers. Traditional adaLN applies layer-specific modulation:
$\text{adaLN}^{(l)}(x, c) = \gamma^{(l)}(c) \odot \frac{x - \mu(x)}{\sigma(x)} + \beta^{(l)}(c)$
where $\gamma^{(l)}(c)$ and $\beta^{(l)}(c)$ are layer-specific learned functions of condition $c$.
Our shared adaLN uses global parameters across all layers:
$\text{adaLN}_{\text{shared}}(x, c) = \gamma(c) \odot \frac{x - \mu(x)}{\sigma(x)} + \beta(c)$
where $\gamma(c)$ and $\beta(c)$ are generated by a single learned MLP from input conditions (timestep and other conditioning). This strategy significantly reduces parameters while preserving performance [15].
### 3.4 Positional Encoding Strategy
For spatial position encoding in H×W images, we maintain specific mathematical constraints on the range parameters. For H-axis range ($r_H$) and W-axis range ($r_W$):
$r_H \times r_W = 1.0$
$\frac{r_H}{r_W} = \frac{H}{W}$
Solving these constraints yields:
$r_H = \sqrt{\frac{H}{W}}, \quad r_W = \sqrt{\frac{W}{H}}$
This formulation enables arbitrary aspect ratio handling while maintaining consistent positional encoding properties. We apply 2D axial RoPE [16] to the first half of dimensions:
$$
\text{RoPE}(x, pos) = \begin{pmatrix}
x_1 \cos(pos/\theta_1) - x_2 \sin(pos/\theta_1) \\
x_1 \sin(pos/\theta_1) + x_2 \cos(pos/\theta_1) \\
\vdots
\end{pmatrix}
$$
For text sequences, we employ NoPE (No Position Embedding) [17], as the causal attention mechanism's inherent property of later tokens attending to more previous tokens provides implicit positional information.
### 3.5 Shifted Square Crop Training
Aspect ratio handling during training presents significant challenges, particularly for text-to-image tasks. Standard Aspect Ratio Bucketing (ARB) approaches group similar aspect ratios but require complex batch pre-computation and specialized dataset implementations.
We propose **Shifted Square Crop**, inspired by patch diffusion pretraining [18]. Given an original image $I_{\text{orig}}$ with dimensions $(H_{\text{orig}}, W_{\text{orig}})$ and target training size $X$:
1. **Resize**: Scale image such that $\min(H_{\text{orig}}, W_{\text{orig}}) = X$:
$I_{\text{resized}} = \text{Resize}(I_{\text{orig}}, \text{scale}=\frac{X}{\min(H_{\text{orig}}, W_{\text{orig}})})$
2. **Position Mapping**: Create position map $P \in \mathbb{R}^{H_{\text{resized}} \times W_{\text{resized}} \times 2}$ where:
$P[i,j] = \left(\frac{i \cdot r_H}{H_{\text{resized}}}, \frac{j \cdot r_W}{W_{\text{resized}}}\right)$
3. **Random Cropping**: Select random crop coordinates $(x_0, y_0)$ and extract:
$I_{\text{crop}} = I_{\text{resized}}[y_0:y_0+X, x_0:x_0+X]$
$P_{\text{crop}} = P[y_0:y_0+X, x_0:x_0+X]$
4. **Training**: Use the $(I_{\text{crop}}, P_{\text{crop}})$ pair for training
During inference, we use the uncropped position map $P_{\text{full}}$ to achieve arbitrary aspect ratio generation, following the principles established in patch diffusion work [18].
### 3.6 TREAD Integration
To accelerate convergence and improve step efficiency, we integrate TREAD (Token Routing for Efficient Architecture-agnostic Diffusion) [13]. While alternatives or similar techniques like REPA or REPA-E offer convergence improvements, they require additional ViT models for reference feature generation and extra MLPs for feature fitting, reducing overall efficiency. REPA-E particularly demands additional VAE backward passes.
TREAD provides superior efficiency by implementing architecture-agnostic token routing without requiring auxiliary models, making it ideal for resource-constrained training scenarios.
### 3.7 Dataset and Preprocessing
For our initial HDM version, we utilize Danbooru2023, an anime-style image-tag dataset containing approximately 7.6M images. This dataset choice reflects our focus on consumer-level training feasibility while providing high-quality anime-style generation capabilities.
We employ Pixtral-11M to generate natural language captions for each image, using these captions as text conditions for training. This preprocessing step enhances the model's ability to understand and generate images based on natural language descriptions.
### 3.8 Inference Methodology
Our training methodology necessitates specific inference procedures:
**Setup Requirements**:
- Disable TREAD selection during inference
- Generate random noise X1 for target image size
- Create full-size position map
- Perform flow matching sampling
**Position Map Manipulation**: Due to training with cropped position maps, we observe interesting inference behaviors. The Danbooru dataset's aspect ratio bias means horizontal image generation may produce "cropped" appearances, as if extracted from larger vertical/square images. However, position map manipulation enables "camera" control:
- **X-shift**: Positive values move camera right, negative values move left
- **Y-shift**: Positive values move camera down, negative values move up
- **Zoom**: Positive values zoom in, negative values zoom out
This capability emerges naturally from our training strategy and positional encoding approach.
| X Shift +0.25 | No Shift | X Shift -0.25 |
|---------------|----------|---------------|
|  |  |  |
|  |  |  |
| Y Shift +0.25 | No Shift | Y Shift -0.25 |
|---------------|----------|---------------|
|  |  |  |
| Zoom 0.75 | No Zoom | Zoom 1.33 |
|-----------|---------|-----------|
|  |  |  |
*Table 1: Demonstration of position map manipulation effects on generated images.
Top table show x-axis shifts (left: +0.25, center: no shift, right: -0.25)
middle table show y-axis shifts (left: +0.25, center: no shift, right: -0.25)
bottom table shows zoom effects (left: 0.75x, center: no zoom, right: 1.33x)
These examples illustrate the camera-like control achievable through position map manipulation.*
**Auto-Guidance with TREAD selection mechanism**: Intuitively, a model with TREAD selection enabled can direclty be seen as a weaker version of itself. With the idea of Auto-Guidance[19] and suggested in the official code of TREAD[20], we use TREAD selection rate for cond(cr) and uncond(ur) to have cr < ur and cr < 0.5 (TREAD selection rate in Training)
## 4. Training
### 4.1 Model Scale
To achieve efficient pretraining and inference on consumer hardware, we minimize model size while maintaining capability. We propose two HDM backbone scales:
| Hyperparameter | XUT-small | XUT-base | XUT-large |
|---|---|---|---|
| Dimension | 896 | 1024 | 1280 |
| Context Dim (TE model) | 640 (Gemma3-270M) | 1024 (Qwen3-0.6B) | 1152 (Gemma3-1B) |
| MLP Dimension | 3072 | 3072 | 4096 |
| Attention Heads | 14 | 16 | 10 |
| Attention Head Dim | 64 | 64 | 128 |
| XUT Depth (d) | 4 | 4 | 4 |
| Encoder Blocks (enc_b) | 1 | 1 | 1 |
| Decoder Blocks (dec_b) | 2 | 3 | 3 |
| N (depth before TREAD) | 1 | 1 | 1 |
| M (depth after TREAD merge)| 3 | 3 | 3 |
| Total Transformer Blocks | 16 | 20 | 20 |
| Total Attention Layers | 20 | 24 | 24 |
| Sequence Length at 256² | 256 | 256 | 256 |
| Parameters (XUT part) | 237M | 343M | 555M |
This technical report focuses on XUT-base validation to establish the complete training recipe and design principles.
### 4.2 Training Recipe
Our XUT-base training employs progressive resolution scaling, beginning at 256² and advancing to higher resolutions. We utilize four RTX5090 GPUs with distributed data parallel (DDP) training.
| Stage | 256² | 512² | 768² | 1024² |
|---|---|---|---|---|
| Dataset | Danbooru 2023 | Danbooru2023 + extra* | - | curated** |
| Image Count | 7.624M | 8.469M | - | 3.649M |
| Epochs | 20 | 5 | 1 | 1 |
| Samples Seen | 152.5M | 42.34M | 8.469M | 3.649M |
| Patches Seen | 39B | 43.5B | 19.5B | 15B |
| Learning Rate (muP, base_dim=1) | 0.5 | 0.1 | 0.05 | 0.02 |
| Batch Size (per GPU) | 128 | 64 | 64 | 16 |
| Gradient Checkpointing | No | Yes | Yes | Yes |
| Gradient Accumulation | 4 | 2 | 2 | 4 |
| Global Batch Size | 2048 | 512 | 512 | 256 |
| TREAD Selection Rate | 0.5 | 0.5 | 0.5 | 0.0 |
| Context Length | 256 | 256 | 256 | 512 |
| Training Wall Time | 174h | 120h | 42h | 49h |
*Extra dataset includes internal collections such as PVC figure photographs and filtered Pixiv artist sets.
**Curated dataset uses Danbooru 2023 filtered for quality indicators: "masterpiece," "best quality" vs. "low quality," "worst quality," and temporal tags "newest," "recent" vs. "old" to enhance negative prompting effectiveness.
TREAD is disabled in the final stage following author recommendations for improved CFG generation quality.
### 4.3 Pretraining Cost Analysis
Based on vast.ai pricing, renting four RTX5090 rigs for 385 hours costs approximately $535-620. Our pretraining utilizes self-hosted consumer-level hardware, establishing a new cost efficiency benchmark for 1024×1024 text-to-image model training compared to previous datacenter GPU costs of $1000-1500.
**Important Note**: All training proceeds without latent caching or text embedding caching, as full dataset caching would require disk space exceeding typical consumer setups. With f16/bf16 precision, caching all text embeddings and f8c16 latents for our Danbooru dataset would require >12TB storage, while the dataset itself occupies only 1.4-1.8TB. Future plans involving 40M datasets would further exacerbate storage requirements.
## 5. Results
### Prompt following with composition consistency
We have observed that this model can achieve this kind of ability which "it will not change global composition when you change the tag but not adding/removing concepts" under same seed/sampler settings.
***Example1***
with following base prompt:
```
1girl,
mejiro ardan \(umamusume\), umamusume,
ningen mame,
ninjin nouko, solo, horse ears, animal ears, horse girl, tail, long hair, horse tail, blue hair, purple eyes, full body, white background, simple background, looking at viewer, braid, shirt, black footwear, white shirt, open mouth, breasts, smile, long sleeves, crown braid, waving, boots, toes, standing, blush, long shirt, single off shoulder, single bare shoulder, very long shirt, t-shirt, bra strap, micro shorts, black shorts, large breasts, shorts,
a character from the series "Umamusume," created by the artist ningen mame. She is dressed in a casual outfit consisting of a white top and dark shorts, paired with black boots. Her pose is dynamic, as she stands confidently with her hands on her hips, exuding an air of determination or readiness. The overall style of the artwork is characterized by vibrant colors and detailed, expressive features typical of ningen mame's work.
masterpiece, newest, safe, absurdres
```
and negative prompt:
```
low quality, worst quality, text, signature, jpeg artifacts, bad anatomy, old, early, copyright name, watermark, artist name, signature, weibo username, mosaic censoring, bar censor, censored, text, speech bubbles, realistic, jacket, open jacket
```
We have following result
| 1. Base | 2. + neg: "jacket" | 3. + neg: "open jacet" | 4. pos: "open mouth" -> "closed mouth"|
|-|-|-|-|
|||||
***Example2***
To ensure the "composition consistency" is not a thing comes from highly detailed, long text ctx. (Which may served as register token or super strong condition signal to force model to output same result).
We provide following example with truncated prompt from example1:
base prompt:
```
1girl,
mejiro ardan \(umamusume\), umamusume,
ningen mame,
solo, horse ears, animal ears, horse girl, tail, long hair, horse tail, blue hair, purple eyes, full body, white background, simple background, looking at viewer, braid, shirt, white footwear, white shirt, closed mouth, breasts, smile, long sleeves, crown braid, waving, boots, toes, standing, blush, long shirt, t-shirt, bra strap,
masterpiece, newest, safe, absurdres
```
Negative prompt: same as Example1
We get following results
| 1. Base Prompt | 2. pos: "closed mouth" -> "open mouth" | 3. pos: "white footwear" -> "black footwear"|
|-|-|-|
||||
## 6. Conclusion
TBD
## References
[1] Rombach, R., et al. "High-resolution image synthesis with latent diffusion models." CVPR 2022.
[2] Podell, D., et al. "SDXL: Improving latent diffusion models for high-resolution image synthesis." ICLR 2024.
[3] Bao, H., et al. "All are worth words: A ViT backbone for diffusion models." CVPR 2023.
[4] Crowson, K., et al. "Scalable high-resolution pixel-space image synthesis with hourglass diffusion transformers." arXiv preprint arXiv:2401.11605, 2024.
[5] Ho, J., et al. "Denoising diffusion probabilistic models." NeurIPS 2020.
[6] Liu, X., et al. "Flow matching for generative modeling." ICLR 2023.
[7] Radford, A., et al. "Learning transferable visual representations from natural language supervision." ICML 2021.
[8] Esser, P., et al. "Scaling rectified flow transformers for high-resolution image synthesis." arXiv preprint arXiv:2403.03206, 2024.
[9] Yang, A., et al. "Qwen2 technical report." arXiv preprint arXiv:2407.10671, 2024.
[10] Peebles, W., Xie, S. "Scalable diffusion models with transformers." ICCV 2023.
[11] Luo, S., et al. "SANA: Efficient high-resolution image synthesis with linear diffusion transformers." arXiv preprint arXiv:2410.10629, 2024.
[12] Xu, Z., et al. "REPA: Reference-enhanced progressive augmentation for efficient text-to-image synthesis." arXiv preprint arXiv:2401.15678, 2024.
[13] Krause, F., et al. "TREAD: Token routing for efficient architecture-agnostic diffusion training." arXiv preprint arXiv:2501.04765, 2025.
[14] Esser, P., et al. "Scaling rectified flow transformers for high-resolution image synthesis." arXiv preprint arXiv:2403.03206, 2024.
[15] Anonymous. "DiT-Air: Revisiting the efficiency of diffusion model architecture design in text to image generation." arXiv preprint arXiv:2503.10618, 2025.
[16] Su, J., et al. "RoFormer: Enhanced transformer with rotary position embedding." Neurocomputing, 2024.
[17] Kazemnejad, A., et al. "The impact of positional encoding on length generalization in transformers." arXiv preprint arXiv:2404.12224, 2024.
[18] Ando, R., et al. "Patch diffusion: Faster and more data-efficient training of diffusion models." arXiv preprint arXiv:2304.12526, 2023.
[19] Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, & Samuli Laine. (2024). Guiding a Diffusion Model with a Bad Version of Itself.
[20] https://github.com/CompVis/tread/blob/master/inference.py
## Appendix
### A. Future Plans
- Expand to more general datasets, currently considering gbc-10m + coyo11m + laion-coco-13m + danbooru (total 40M images)
- Scale up model size to approximately 500M parameters with ~1B parameter text encoder
- Scale down model size to approximately 250M parameters with ~500M or smaller parameter text encoder
- Investigate "Hires Fix Model" or "Refiner" approaches for enhanced quality
- Investigate PixNerd or other pixel space appraoch on XUT.
### B. Acknowledgements
We thank Felix Krause (TREAD author), Stefan Andreas Baumann (TREAD author) for providing insights and assistance during HDM development. We acknowledge AngelBottomless (Illustrious series model author), Mahouko (Birch Lab), and Uptightmoose for valuable insights throughout the HDM planning process.