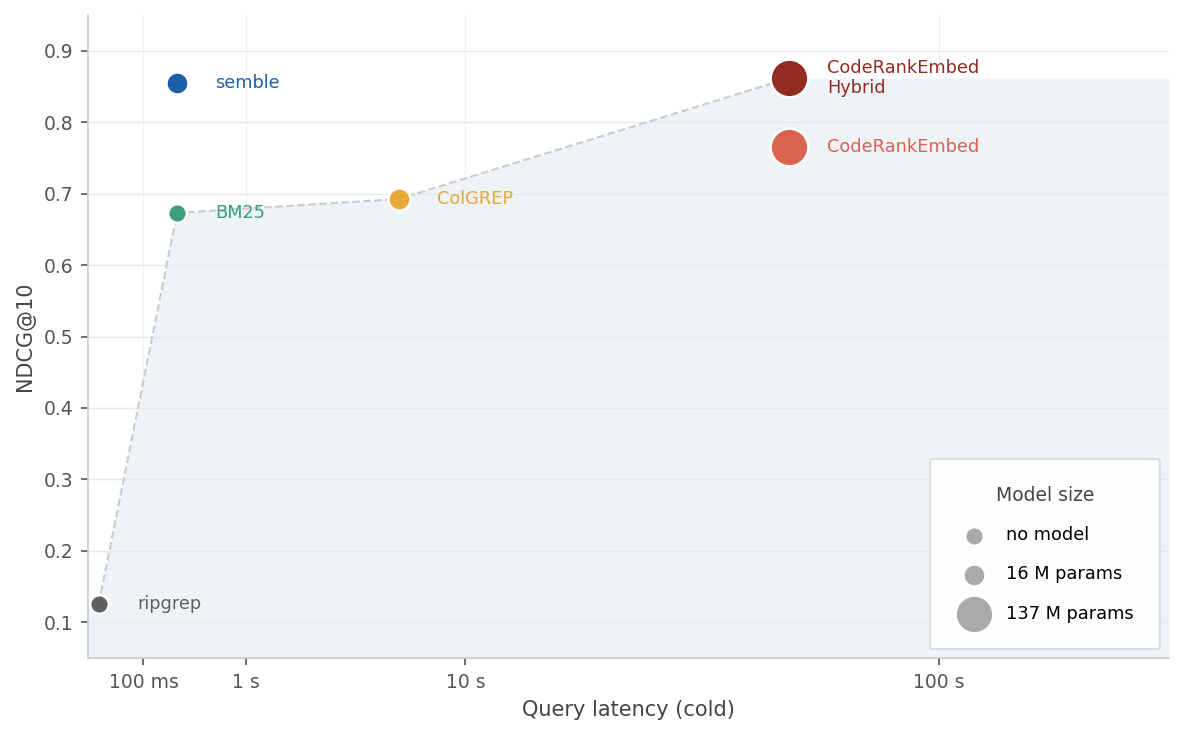
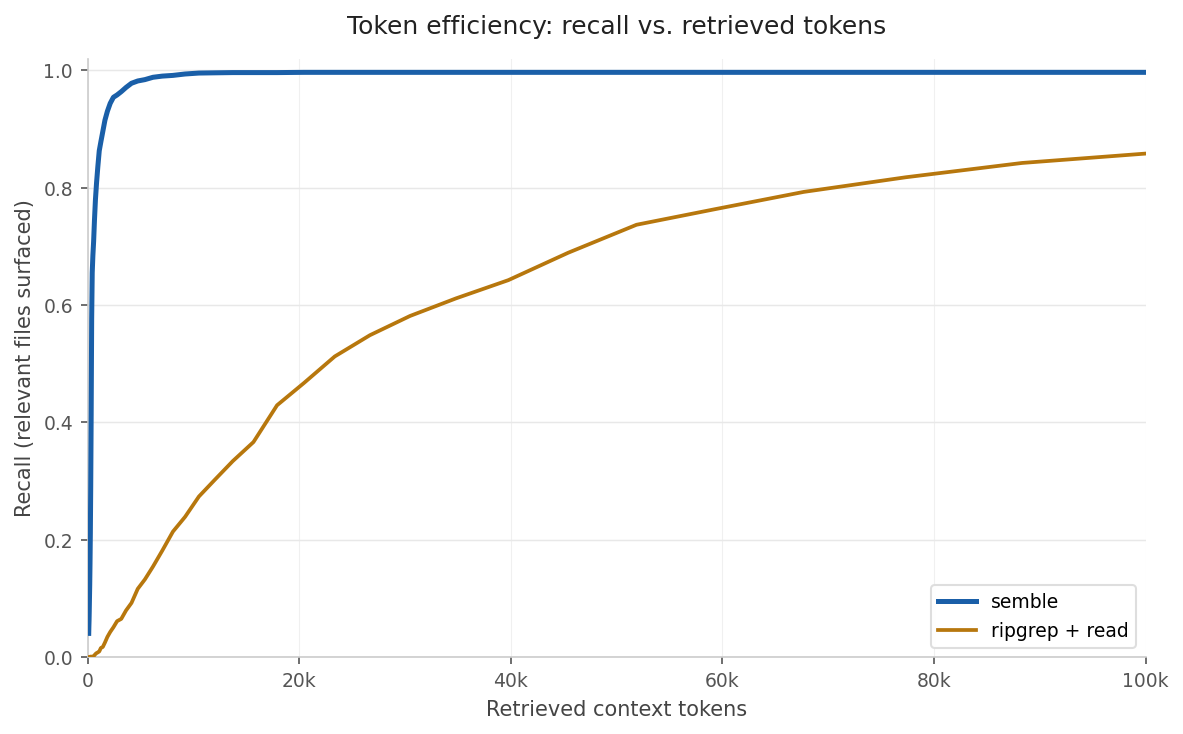
Semble is a code search library built for agents. It returns the exact code snippets they need instantly, using ~98% fewer tokens than grep+read. Indexing and searching a full codebase end-to-end takes under a second, with ~200x faster indexing and ~10x faster queries than a code-specialized transformer, at 99% of its retrieval quality (see [benchmarks](#benchmarks)). Everything runs on CPU with no API keys, GPU, or external services. Run it as an [MCP server](#mcp-server) or call it from the shell via [AGENTS.md](#bash-agentsmd) and any agent (Claude Code, Cursor, Codex, OpenCode, etc.) gets instant access to any repo.
## Quickstart
Your agent queries Semble in natural language (e.g. `"How is authentication handled?"`) and gets back only the relevant code snippets, without grepping or reading full files. Set it up as an MCP server or via AGENTS.md:
### MCP (Claude Code)
Add Semble to Claude Code (requires [uv](https://docs.astral.sh/uv/getting-started/installation/)):
```bash
claude mcp add semble -s user -- uvx --from "semble[mcp]" semble
```
Using Codex, OpenCode, or Cursor? See [MCP Server](#mcp-server) for setup instructions.
### Bash / AGENTS.md
Install Semble, then add the snippet below to your `AGENTS.md` or `CLAUDE.md`:
```bash
pip install semble # Install with pip
uv tool install semble # Or install with uv
```