---
description: ""
categories: [bagu]
title: golang底层知识汇总
---
> [!note]
>本文基于go1.21.2,不同版本的go可能会有差异。文中部分代码会由于不是知识点强相关而省略,但被忽略的每行代码或多或少都有它们实际的用处,甚至可能不宜删除,欢迎指出
> [!tip]
> 分析底层的相关的代码时,往往会由于平台架构而带来代码上的差异,比如我机器是darwin/arm64,使用vscode查看代码,而且我希望基于linux/amd64来看代码,可以在`.vscode/settings.json`中设置`GOOS`和`GOARCH`:
>
> ```json
> {
> "go.toolsEnvVars": {
> "GOOS": "linux",
> "GOARCH": "amd64"
> }
> }
> ```
>
>这样我在打开平台相关的代码文件比如`os_linux.go`时,go插件就能支持代码跳转
## 数组
`[10]int`和`[20]int`是不一样的类型,也就是数组的类型由元素类型和元素个数共同决定。
对于literal的数组分配,在不考虑逃逸分析的情况下:
| 类型 | 内存分配 |
| ----------- | ------------------------ |
| 元素个数<=4 | 直接分配在栈上 |
| 元素个数>4 | 放到静态区并在运行时取出 |
数组的访问和赋值大多数会被转换成直接内存读写,需要同时依赖编译时和运行时(比如有的常量下标访问在编译时检查出越界,有时候使用变量下标则在运行时检查)。
## 切片
### 数据结构
编译时的切片是`Slice`类型的,只包含元素类型,因此切片类型只由元素类型决定。而在运行时切片由`SliceHeader`表示:
```go
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
```
使用`make`初始化切片时,会调用`makeslice`最终调用`runtime.mallocgc`申请内存,申请的内存比较小就会直接初始化在Go语言调度器的P结构中上,否则初始化在堆上。
### append
当切片依赖的底层数组容量不足时,就会进行数组扩容:
- 如果期望容量>2*当前容量,那么新数组容量为期望容量
- 如果当前容量较小(<1024),那么容量翻倍
- 如果当前容量较大(>=1024),那么1.25*当前容量
确定完上述容量之后,还会进行内存对齐,用于减少内存碎片。
### copy
切片的拷贝,最终会使用`runtime.memmove`将整块内存拷贝到目标区域。相比依次拷贝元素拥有更好的性能。
## 哈希表
**装载因子 = 元素数量 / 桶数量**
开放地址法的装载因子最大为1,当趋近1时查找和插入复杂度都几乎为O(n)。拉链法的装载因子可以超过1
### 数据结构
golang map本质上是一个指针,指向`hmap`结构体,其`buckets`成员指向桶数组`buckets`,桶用类型`bmap`表示。`extra`成员记录溢出桶的使用情况,其中`overflow`指向溢出桶地址,`oldoverflow`指向旧桶数组的溢出桶地址(扩容迁移的时候用到),`nextoverflow`指向下一个空闲溢出桶
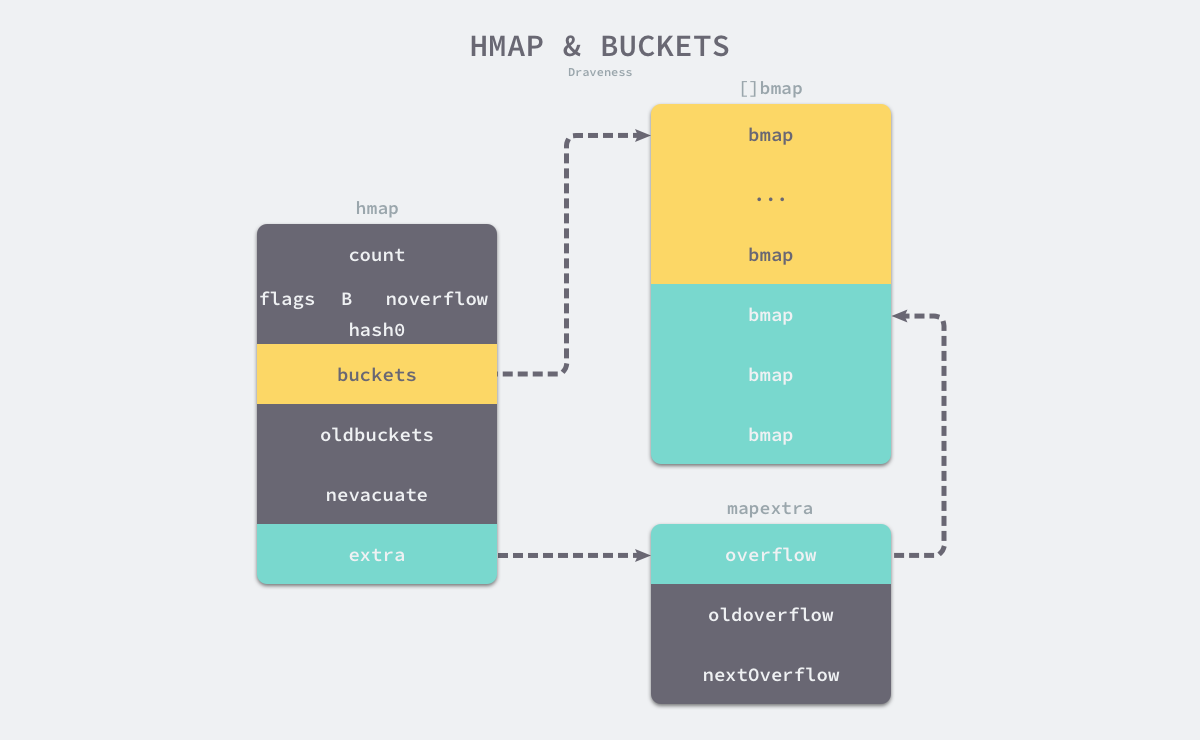
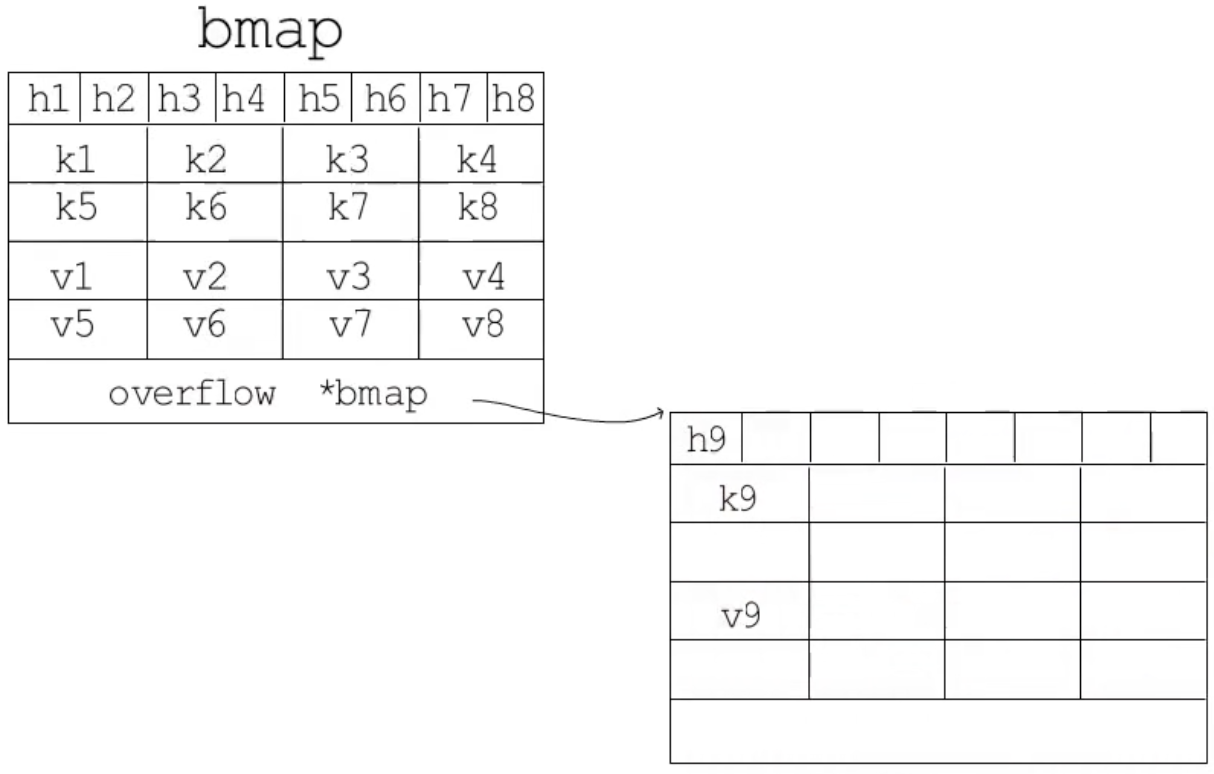
`bmap`主要的成员是`tophash`, `keys`, `values`三个数组,这样可以使内存排列更加紧凑。`tophash`类型是`[]uint8`,每个`tophash`存储了每个哈希值的高8位,访问哈希表时,只需要对比高8位就能知道键不存在,减少完整比对哈希值的开销(如果对比高8位相同,才需要比较哈希值),如果比较后发现相同,就能直接通过当前tophash偏移量定位到key偏移量。`bmap`最后还有一个`bmap`指针,指向溢出桶,当该桶存满了,增加一个溢出桶继续存入新数据。
 ### 扩容
map的扩容策略为渐进式扩容,`oldbuckets`指向旧桶数组,只读不写,buckets指向当前桶数组,nevacuate记录下一个要迁移的旧桶编号。
map的扩容规则:
- 如果负载因子>6.5,则翻倍扩容
- 如果使用太多溢出桶,则等量扩容(B<=15并且溢出桶数量大于桶数量 或者 B>15并且溢出桶数量大于215)
扩容期间,迁移`evacuate`这个动作只在write/delete时完成,read不会发生迁移,每次迁移一个桶(如果是时翻倍扩容则会每次迁移两个桶以加速迁移)。
*Q:为什么溢出桶过多是等量扩容,解决了什么问题?A:负载因子不大但是溢出桶很多是因为大量key被删除,因此等量扩容后,大量溢出桶的key会存到常规桶中,从而减少溢出桶的数量*
## 字符串
`string`字符串由`StringHeader`表示,`Data`表示字节指针:
```go
type StringHeader struct {
Data uintptr
Len int
}
```
由于字符串的内容是不可改变的,因此不需要切片中`Cap`,只需要`Len`。
`string`和`[]byte`之间的直接转换是通过拷贝实现的,长度越大需要申请的空间越大,可以用`unsafe.SliceData`和`unsafe.StringData`解决这个问题。
## 接口
接口数据结构分为两类:
1. 带方法的接口:`runtime.iface`
```go
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
```
2. 不带方法的接口:`runtime.eface`
```go
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
```
其中`_type`是go语言类型的运行时表示,包含了类型的大小、类型的hash(用于快速确定类型是否相等)等。而`itab`是接口类型的核心,可以看成是接口类型+具体类型的组合:
```go
type itab struct { // 32 字节
inter *interfacetype // 接口类型
_type *_type // 具体类型
hash uint32 // 用于interface转换成具体类型时,快速判断是否与具体类型的_type一致
_ [4]byte
fun [1]uintptr // 虚函数表,进行动态派发
}
```
关于接口,这部分大多是汇编层面的分析,直接看下不同情况下函数调用的benchmark:
| 直接调用 | 动态派发 | |
| :------: | :-------: | --------- |
| 指针 | ~3.03纳秒 | ~3.58纳秒 |
| 结构体 | ~3.09纳秒 | ~6.98纳秒 |
最好的是使用指针实现+直接调用,不过设计好的项目一般善于面向接口编程,因此指针调用+动态派发也很常用。
## channel
- 未初始化的channel(`nil`),无论是接收还是发送都会直接阻塞
- 不能关闭`nil`的或者已经关闭的channel
- 不能向已经关闭的channel发送数据
channel(`chan`)在运行时使用`runtime.hchan`表示:
```go
type hchan struct {
qcount uint // chan中的元素个数
dataqsiz uint // 循环队列长度
buf unsafe.Pointer // 缓冲区指针
elemsize uint16 // 元素大小
elemtype *_type // 元素类型
sendx uint // 发送操作处理到的位置
recvx uint // 接收操作处理到的位置
recvq waitq // 接收阻塞的goroutine队列,使用双向链表waitq表示,每个节点代表一个goroutine
sendq waitq // 发送阻塞的goroutine队列
lock mutex
}
```
`hchan`包含了一把保护其他成员的互斥锁,从某种程度上来说channel是有锁队列,虽然在某些关键路径上进行了无锁化的优化,但并不是完全的无锁队列。
### 初始化
调用`runtime.makechan`创建管道,分三种情况:
- 当缓冲区大小为0,那么只会给`hchan`分配内存
- 当元素类型不是指针,就会给`hchan`和`buf`分配一段连续的内存
- 否则会给`hchan`和`buf`单独分配内存
最后初始化`elementType`, `elementSize`, `dataqsiz`字段
### 发送
发送操作最终转换为调用`runtime.chansend`,分成三种情况。
当存在阻塞的接收者,将接收者从`recvq`中出队,然后调用`runtime.sned`将数据发送给它:
```go
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
goready(gp, skip+1)
}
```
调用`runtime.sendDirect`将数据拷贝到`x = <-c`的`x`所在内存中,然后调用`runtime.goready`将接收者的goroutine标记成可运行状态(注意不是马上运行),**放到发送方处理器的`runnext`上等待执行**,处理器在下一次调度时唤醒这个阻塞的接收者。
当缓冲区未满,将数据放入缓冲区:
```go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx) // 计算下一个存储数据的位置
typedmemmove(c.elemtype, qp, ep) // 拷贝元素到该位置
// 更新数据在队列中的索引
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 增加队列大小
c.qcount++
unlock(&c.lock)
return true
}
...
}
```
当缓冲区满,阻塞等待。
```go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if !block {
unlock(&c.lock)
return false
}
// 将g和发送的数据绑定到sudog,将sudog入队sendq,然后将该sudog设置到goroutine的waiting上,阻塞等待。
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
mysg.g = gp
mysg.c = c
gp.waiting = mysg
c.sendq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)
// 被唤醒后进行一些收尾工作,释放sudog
gp.waiting = nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true
}
```
### 接收
接收会被转换为调用`runtime.chanrecv1`或`runtime.chanrecv2`,最终都会调用`runtime.chanrecv`
接收存在两种特殊情况:当`chan`为`nil`,接收操作直接被阻塞并且永远不会被唤醒;当`chan`已经被关闭,接收操作直接返回,并且接收值所在内存区域被清空(即`<-c`返回零值)。
除了这两种特殊情况,就是下面普通的三种情况:
当存在阻塞的发送者,通过`runtime.recv`从发送者那里(sudog)获取数据:
```go
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if ep != nil {
recvDirect(c.elemtype, sg, ep)
}
} else {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
goready(gp, skip+1)
}
```
如果缓冲区不存在数据,使用`recvDirect`直接从发送者`sudog`那里拿,否则拿缓冲区队头的数据,然后将发送者的数据放到缓冲区队尾。最终都会调用`goready`将发送方goroutine设置为可运行状态,等待调度器下一次调度。
*Q:为什么优先从缓冲区拿数据?A:为了遵循FIFO,先进先出的特性。因为缓冲区的数据肯定是先来的,缓冲区满了之后才会有发送者阻塞在后面的发送操作上*
当没有阻塞的发送者,并且缓冲区不为空:
```go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
return true, true
}
...
}
```
`chanrecv`会将缓冲区的数据取出(使用`typedmemmove`将队列的数据拷贝到内存中),然后做些收尾工作。
当没有等待的接收者,缓冲区也为空的情况下,接收者将会被阻塞:
```go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if !block {
unlock(&c.lock)
return false, false
}
// 将g、c、ep绑定到sudog,将sudog入队recvq,然后阻塞
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
gp.waiting = mysg
mysg.g = gp
mysg.c = c
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// 此时sudog被唤醒,做些收尾工作,释放sudog
gp.waiting = nil
closed := gp.param == nil
gp.param = nil
releaseSudog(mysg)
return true, !closed
}
```
类似阻塞发送者那样,基于`sudog`进行等待队列的管理。
### 关闭
关闭管道会出队所有`recvq`和`sendq`的元素,并将他们唤醒。
### select
golang中的`select`支持了类似系统调用`select`那样的多路复用:对channel的多路复用。
- `select`多个同时满足的`case`会**随机**地选择其中一个执行
- `default`分支实现了非阻塞的channel读写
`select`在运行时对应的是`runtime.scase`结构体,每个`case`对应一个`scase`:
```go
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
```
针对不同的select结构,编译器会有不同的优化。
当没有`case`,即`select{}`的时候,直接`gopark`进入永久阻塞
当只存在一个`case`的时候,编译器会改写为直接对channel的操作,比如`select { case v, ok := <-ch: }`改写为`v, ok := <-ch`
当只存在两个`case`并且其中一个是`default`的时候,会转化为`runtime.chansend`/`runtime.chanrecv`,传入的`block`参数为`false`,表明当没有接收者并且缓冲空间不足时会直接返回而不是阻塞。
当存在多个`case`时:
```go
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, revcOK := selectgo(selv, order, 3)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
if chosen == 2 {
...
break
}
```
每个`case`被转换成`scase`,调用`runtime.selectgo`选择一个将会执行的`case`,生成多个`if`用于判断是不是自己被选中的`case`,每个`if`对应一个`case`。
最重要的处理逻辑都在`selectgo`中。`selectgo`首先会确认**轮询顺序**和**加锁顺序**
- 轮询顺序:为了避免`case`饥饿,使用`runtime.fastrandn`确定随机轮询顺序来避免`case`饥饿
- 加锁顺序:为了避免死锁,按照channel的地址顺序来确定(用堆排序实现)。
*Q:为什么需要确定加锁顺序,不限制加锁顺序的话什么情况下会出现死锁?A:比如有ch1和ch2,并且有两个goroutine同时对这两个channel进行select:`select { case <-ch1: break; case <-ch2: break }`,不限制加锁顺序的话,可能g1的加锁顺序为ch1, ch2,而g2的加锁顺序为ch2, ch1,如果g1锁完ch1后,此时调度到g2,g2去锁ch2,这样就发生了死锁*
确定完轮询顺序和加锁顺序后,就对channels进行加锁,然后进行循环,循环一共有三轮,每轮做的事情都不一样:
1. 直接执行:查看有没有可以直接执行的`case`,比如`case <-ch`有对应的发送者在等待,有的话就`goto`到对应分支执行相应的操作,比如`bufrecv`, `bufsend`,`recv`...等(这些分支实际上对应的就是`runtime.chansend`, `runtime.chanrecv`逻辑,只不过因为这里还包含了`select`的相关操作,所以不能直接调用`runtime.chansend`/`runtime.chanrecv`等函数)。轮询下来后如果没有满足条件的`case`,并且如果没有default(block=true),那么进入下一轮
2. 入队阻塞:对于每个`case`都生成一个绑定当前goroutine的`sudog`并加入各个channel的等待队列(接收就入队`recvq`,发送就入队`sendq`,这是为了当任意channel有更新时当前goroutine都能得到唤醒)。最后调用`gopark`阻塞当前协程
3. 唤醒执行:此时协程被其中一个channel唤醒,循环出队其他的channel并释放对应的`sudog`,解锁channel,最后返回。
## GMP
内容比较多,放在[另一篇](https://nosae.top/posts/go-gmp%E8%B0%83%E5%BA%A6%E5%99%A8/)
## 参考链接🔗
[【幼麟实验室】Golang合辑](https://www.bilibili.com/video/BV1hv411x7we/?p=4&share_source=copy_web&vd_source=c0d41b92058c38bc23233feb8c73c581)
[【draveness】面向信仰编程](https://draveness.me/golang/)
[【小徐先生1212】解说Golang GMP 实现原理](https://www.bilibili.com/video/BV1oT411Y7m3/)
[【lunar@qq.com】Golang 1.21.4 GMP调度器底层实现个人走读](https://blog.csdn.net/qq_58339096/article/details/134350312)
[【panjf2000】Go 网络模型 netpoll 全揭秘](https://strikefreedom.top/archives/go-netpoll-io-multiplexing-reactor)
[【boya】深入golang runtime的调度](https://zboya.github.io/post/go_scheduler)
[【stack overflow】Benefits of runtime.LockOSThread in Golang](https://stackoverflow.com/questions/25361831/benefits-of-runtime-lockosthread-in-golang)
### 扩容
map的扩容策略为渐进式扩容,`oldbuckets`指向旧桶数组,只读不写,buckets指向当前桶数组,nevacuate记录下一个要迁移的旧桶编号。
map的扩容规则:
- 如果负载因子>6.5,则翻倍扩容
- 如果使用太多溢出桶,则等量扩容(B<=15并且溢出桶数量大于桶数量 或者 B>15并且溢出桶数量大于215)
扩容期间,迁移`evacuate`这个动作只在write/delete时完成,read不会发生迁移,每次迁移一个桶(如果是时翻倍扩容则会每次迁移两个桶以加速迁移)。
*Q:为什么溢出桶过多是等量扩容,解决了什么问题?A:负载因子不大但是溢出桶很多是因为大量key被删除,因此等量扩容后,大量溢出桶的key会存到常规桶中,从而减少溢出桶的数量*
## 字符串
`string`字符串由`StringHeader`表示,`Data`表示字节指针:
```go
type StringHeader struct {
Data uintptr
Len int
}
```
由于字符串的内容是不可改变的,因此不需要切片中`Cap`,只需要`Len`。
`string`和`[]byte`之间的直接转换是通过拷贝实现的,长度越大需要申请的空间越大,可以用`unsafe.SliceData`和`unsafe.StringData`解决这个问题。
## 接口
接口数据结构分为两类:
1. 带方法的接口:`runtime.iface`
```go
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
```
2. 不带方法的接口:`runtime.eface`
```go
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
```
其中`_type`是go语言类型的运行时表示,包含了类型的大小、类型的hash(用于快速确定类型是否相等)等。而`itab`是接口类型的核心,可以看成是接口类型+具体类型的组合:
```go
type itab struct { // 32 字节
inter *interfacetype // 接口类型
_type *_type // 具体类型
hash uint32 // 用于interface转换成具体类型时,快速判断是否与具体类型的_type一致
_ [4]byte
fun [1]uintptr // 虚函数表,进行动态派发
}
```
关于接口,这部分大多是汇编层面的分析,直接看下不同情况下函数调用的benchmark:
| 直接调用 | 动态派发 | |
| :------: | :-------: | --------- |
| 指针 | ~3.03纳秒 | ~3.58纳秒 |
| 结构体 | ~3.09纳秒 | ~6.98纳秒 |
最好的是使用指针实现+直接调用,不过设计好的项目一般善于面向接口编程,因此指针调用+动态派发也很常用。
## channel
- 未初始化的channel(`nil`),无论是接收还是发送都会直接阻塞
- 不能关闭`nil`的或者已经关闭的channel
- 不能向已经关闭的channel发送数据
channel(`chan`)在运行时使用`runtime.hchan`表示:
```go
type hchan struct {
qcount uint // chan中的元素个数
dataqsiz uint // 循环队列长度
buf unsafe.Pointer // 缓冲区指针
elemsize uint16 // 元素大小
elemtype *_type // 元素类型
sendx uint // 发送操作处理到的位置
recvx uint // 接收操作处理到的位置
recvq waitq // 接收阻塞的goroutine队列,使用双向链表waitq表示,每个节点代表一个goroutine
sendq waitq // 发送阻塞的goroutine队列
lock mutex
}
```
`hchan`包含了一把保护其他成员的互斥锁,从某种程度上来说channel是有锁队列,虽然在某些关键路径上进行了无锁化的优化,但并不是完全的无锁队列。
### 初始化
调用`runtime.makechan`创建管道,分三种情况:
- 当缓冲区大小为0,那么只会给`hchan`分配内存
- 当元素类型不是指针,就会给`hchan`和`buf`分配一段连续的内存
- 否则会给`hchan`和`buf`单独分配内存
最后初始化`elementType`, `elementSize`, `dataqsiz`字段
### 发送
发送操作最终转换为调用`runtime.chansend`,分成三种情况。
当存在阻塞的接收者,将接收者从`recvq`中出队,然后调用`runtime.sned`将数据发送给它:
```go
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
goready(gp, skip+1)
}
```
调用`runtime.sendDirect`将数据拷贝到`x = <-c`的`x`所在内存中,然后调用`runtime.goready`将接收者的goroutine标记成可运行状态(注意不是马上运行),**放到发送方处理器的`runnext`上等待执行**,处理器在下一次调度时唤醒这个阻塞的接收者。
当缓冲区未满,将数据放入缓冲区:
```go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx) // 计算下一个存储数据的位置
typedmemmove(c.elemtype, qp, ep) // 拷贝元素到该位置
// 更新数据在队列中的索引
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 增加队列大小
c.qcount++
unlock(&c.lock)
return true
}
...
}
```
当缓冲区满,阻塞等待。
```go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if !block {
unlock(&c.lock)
return false
}
// 将g和发送的数据绑定到sudog,将sudog入队sendq,然后将该sudog设置到goroutine的waiting上,阻塞等待。
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
mysg.g = gp
mysg.c = c
gp.waiting = mysg
c.sendq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)
// 被唤醒后进行一些收尾工作,释放sudog
gp.waiting = nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true
}
```
### 接收
接收会被转换为调用`runtime.chanrecv1`或`runtime.chanrecv2`,最终都会调用`runtime.chanrecv`
接收存在两种特殊情况:当`chan`为`nil`,接收操作直接被阻塞并且永远不会被唤醒;当`chan`已经被关闭,接收操作直接返回,并且接收值所在内存区域被清空(即`<-c`返回零值)。
除了这两种特殊情况,就是下面普通的三种情况:
当存在阻塞的发送者,通过`runtime.recv`从发送者那里(sudog)获取数据:
```go
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if ep != nil {
recvDirect(c.elemtype, sg, ep)
}
} else {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
goready(gp, skip+1)
}
```
如果缓冲区不存在数据,使用`recvDirect`直接从发送者`sudog`那里拿,否则拿缓冲区队头的数据,然后将发送者的数据放到缓冲区队尾。最终都会调用`goready`将发送方goroutine设置为可运行状态,等待调度器下一次调度。
*Q:为什么优先从缓冲区拿数据?A:为了遵循FIFO,先进先出的特性。因为缓冲区的数据肯定是先来的,缓冲区满了之后才会有发送者阻塞在后面的发送操作上*
当没有阻塞的发送者,并且缓冲区不为空:
```go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
return true, true
}
...
}
```
`chanrecv`会将缓冲区的数据取出(使用`typedmemmove`将队列的数据拷贝到内存中),然后做些收尾工作。
当没有等待的接收者,缓冲区也为空的情况下,接收者将会被阻塞:
```go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if !block {
unlock(&c.lock)
return false, false
}
// 将g、c、ep绑定到sudog,将sudog入队recvq,然后阻塞
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
gp.waiting = mysg
mysg.g = gp
mysg.c = c
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// 此时sudog被唤醒,做些收尾工作,释放sudog
gp.waiting = nil
closed := gp.param == nil
gp.param = nil
releaseSudog(mysg)
return true, !closed
}
```
类似阻塞发送者那样,基于`sudog`进行等待队列的管理。
### 关闭
关闭管道会出队所有`recvq`和`sendq`的元素,并将他们唤醒。
### select
golang中的`select`支持了类似系统调用`select`那样的多路复用:对channel的多路复用。
- `select`多个同时满足的`case`会**随机**地选择其中一个执行
- `default`分支实现了非阻塞的channel读写
`select`在运行时对应的是`runtime.scase`结构体,每个`case`对应一个`scase`:
```go
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
```
针对不同的select结构,编译器会有不同的优化。
当没有`case`,即`select{}`的时候,直接`gopark`进入永久阻塞
当只存在一个`case`的时候,编译器会改写为直接对channel的操作,比如`select { case v, ok := <-ch: }`改写为`v, ok := <-ch`
当只存在两个`case`并且其中一个是`default`的时候,会转化为`runtime.chansend`/`runtime.chanrecv`,传入的`block`参数为`false`,表明当没有接收者并且缓冲空间不足时会直接返回而不是阻塞。
当存在多个`case`时:
```go
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, revcOK := selectgo(selv, order, 3)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
if chosen == 2 {
...
break
}
```
每个`case`被转换成`scase`,调用`runtime.selectgo`选择一个将会执行的`case`,生成多个`if`用于判断是不是自己被选中的`case`,每个`if`对应一个`case`。
最重要的处理逻辑都在`selectgo`中。`selectgo`首先会确认**轮询顺序**和**加锁顺序**
- 轮询顺序:为了避免`case`饥饿,使用`runtime.fastrandn`确定随机轮询顺序来避免`case`饥饿
- 加锁顺序:为了避免死锁,按照channel的地址顺序来确定(用堆排序实现)。
*Q:为什么需要确定加锁顺序,不限制加锁顺序的话什么情况下会出现死锁?A:比如有ch1和ch2,并且有两个goroutine同时对这两个channel进行select:`select { case <-ch1: break; case <-ch2: break }`,不限制加锁顺序的话,可能g1的加锁顺序为ch1, ch2,而g2的加锁顺序为ch2, ch1,如果g1锁完ch1后,此时调度到g2,g2去锁ch2,这样就发生了死锁*
确定完轮询顺序和加锁顺序后,就对channels进行加锁,然后进行循环,循环一共有三轮,每轮做的事情都不一样:
1. 直接执行:查看有没有可以直接执行的`case`,比如`case <-ch`有对应的发送者在等待,有的话就`goto`到对应分支执行相应的操作,比如`bufrecv`, `bufsend`,`recv`...等(这些分支实际上对应的就是`runtime.chansend`, `runtime.chanrecv`逻辑,只不过因为这里还包含了`select`的相关操作,所以不能直接调用`runtime.chansend`/`runtime.chanrecv`等函数)。轮询下来后如果没有满足条件的`case`,并且如果没有default(block=true),那么进入下一轮
2. 入队阻塞:对于每个`case`都生成一个绑定当前goroutine的`sudog`并加入各个channel的等待队列(接收就入队`recvq`,发送就入队`sendq`,这是为了当任意channel有更新时当前goroutine都能得到唤醒)。最后调用`gopark`阻塞当前协程
3. 唤醒执行:此时协程被其中一个channel唤醒,循环出队其他的channel并释放对应的`sudog`,解锁channel,最后返回。
## GMP
内容比较多,放在[另一篇](https://nosae.top/posts/go-gmp%E8%B0%83%E5%BA%A6%E5%99%A8/)
## 参考链接🔗
[【幼麟实验室】Golang合辑](https://www.bilibili.com/video/BV1hv411x7we/?p=4&share_source=copy_web&vd_source=c0d41b92058c38bc23233feb8c73c581)
[【draveness】面向信仰编程](https://draveness.me/golang/)
[【小徐先生1212】解说Golang GMP 实现原理](https://www.bilibili.com/video/BV1oT411Y7m3/)
[【lunar@qq.com】Golang 1.21.4 GMP调度器底层实现个人走读](https://blog.csdn.net/qq_58339096/article/details/134350312)
[【panjf2000】Go 网络模型 netpoll 全揭秘](https://strikefreedom.top/archives/go-netpoll-io-multiplexing-reactor)
[【boya】深入golang runtime的调度](https://zboya.github.io/post/go_scheduler)
[【stack overflow】Benefits of runtime.LockOSThread in Golang](https://stackoverflow.com/questions/25361831/benefits-of-runtime-lockosthread-in-golang)