---
date: 2026-02-15T21:24:54+08:00
title: K8S的HorizontalPodAutoscaler
tags: [k8s]
categories: [k8s]
draft: false
---
## 介绍
K8S 的 HorizontalPodautoscaler(HPA)用于根据实际负载,动态地调整 workload 资源的 pod 数量,比如 Deployment、StatefulSet 等。
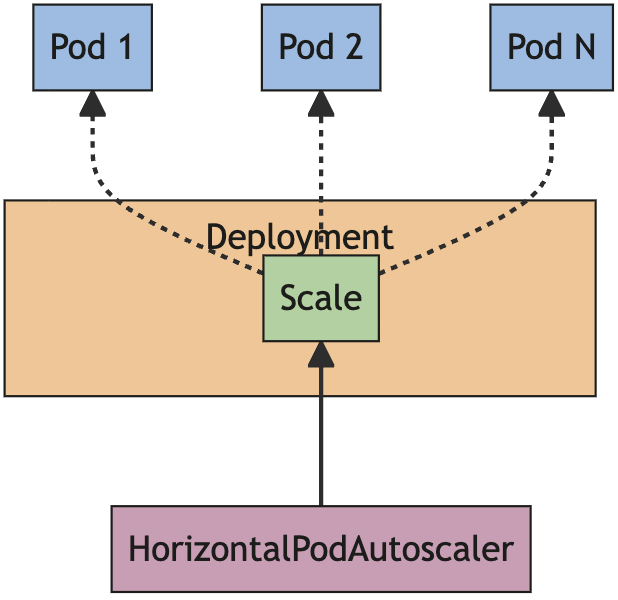 一个实际的例子可以参考:
HPA 的工作流程是:
```
找到目标 → 选出 Pod → 获取指标 → 求平均 → 算比例 → 推导副本数
```
## 找到目标
在 HPA 中设置 `scaleTargetRef` 用于找到目标对象:
``` yaml
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
```
然后读取该对象的 `.spec.selector`,找出所有匹配的 pod。
因此我们也可以发现,HPA 并不是直接管理 Pod,而是通过 Deployment/StatefulSet 的 selector 间接管理。
## 获取指标
指标有三种来源:
1. Pod 资源指标,比如内存、CPU
2. Pod 自定义指标,比如每个 Pod QPS
3. 外部指标,比如某个 Ingress 的总 QPS、kafka topic lag
## 计算副本数
1. 计算每个目标 pod 的指标,比如 CPU 利用率
2. 计算上述指标的平均值,得到 $currentMetricValue$
3. 结合目标指标值,以及当前副本数,计算目标副本数:
$$
desiredReplicas =\lceil currentReplicas\times \frac{currentmetircValue}{desiredMetricValue}\rceil
$$
举个例子,当前副本数为 3,每个 pod 的 cpu request 值为 100m,实际使用:
```
Pod1: 80m
Pod2: 60m
Pod3: 100m
```
利用率分别为:
```
80%
60%
100%
```
求平均得到:
```
(80 + 60 + 100) / 3 = 80%
```
如果 desiredMetricValue 为 50%,则根据公式计算得到目标副本数为:
```
desiredReplicas = ceil(3 * 80 / 50) = ceil(4.8) = 5
```
## 其它规则
### 是否参与计算
- 对于 deletetion timestamp 不为空的 pod,以及 failed pod,将不会参与计算。
- 对于缺失指标的 pod、not ready pod(包括启动 30s 内的 pod、启动 5min 内最近一次指标采集发生在最近一次 ready 之前的 pod、启动 5min 分钟后处于 not ready 的 pod),将被 set aside,即参与 **保留计算**。(这里的 30s 和 5min 是默认值,由 HPA 控制器的启动参数决定)
### 保留计算
保留计算的目的是抑制扩缩容,用于 HPA 内部防抖动。
步骤是先用正常的 pod 进行计算得到基础缩放比例,随后,
- 对于指标缺失的 pod,如果趋势是 scale up,那么将该 pod 的指标视为 0%;如果趋势是 scale down,那么将该 pod 的指标视为 100%。
- 对于 not ready pod,如果趋势是 scale up,那么将该 pod 的指标视为 0%;趋势是 scale down 则不参与计算。
最后用这些指标以及正常 pod 的指标来计算得到最终的目标副本数。
### 原始指标与实际指标
原始指标指的是用正常 pod 计算得到的指标,这是你 `kubectl get hpa -o yaml` 所能看到的数值。
实际指标指的是保留计算后得到的指标,它才是影响最终扩缩容的指标,目的是 HPA 内部用于防抖动。因此在排查问题时,你可能会看到:
```
HPA status: 85%
target: 50%
```
却发现:
```
没有 scale up
```
因为实际指标很可能小于 50%。
### 多个指标
如果 HPA 指定了多个指标,则会分别计算,最终取最大的目标副本数;如果部分指标无法获取,并且那些可获取的指标建议缩容,那 HPA 将采取更保守的做法,即不会缩容。
### 缩容前的观测时间窗
HPA 每次调谐循环都会算出一个 desiredReplicas,例如:
| 时间 | 计算结果 |
| ----- | -------- |
| 00:00 | 10 |
| 00:15 | 8 |
| 00:30 | 6 |
| 00:45 | 9 |
| 01:00 | 7 |
如果没有额外机制,直接触发缩容,副本数会频繁上下跳动。而我们可以指定--horizontal-pod-autoscaler-downscale-stabilization = 5m,含义是在准备缩容前,HPA 会查看最近 5 分钟内的所有“副本推荐值”,并选择其中最大的一个。
假设最近 5 分钟的推荐值为:
```
10, 8, 6, 9, 7
```
即使当前计算是 7,HPA 也会使用 10 这个值。
从整体上看,取这段时间窗口内最大值的目的是:**HPA 必须确定系统持续低负载一段时间后再决定缩容,而不是一次波动就缩容**。
总的来说,缩容前的观测时间窗可以一定程度上避免:Pod 不断销毁重建、连接抖动、冷启动放大等问题。
一个实际的例子可以参考:
HPA 的工作流程是:
```
找到目标 → 选出 Pod → 获取指标 → 求平均 → 算比例 → 推导副本数
```
## 找到目标
在 HPA 中设置 `scaleTargetRef` 用于找到目标对象:
``` yaml
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
```
然后读取该对象的 `.spec.selector`,找出所有匹配的 pod。
因此我们也可以发现,HPA 并不是直接管理 Pod,而是通过 Deployment/StatefulSet 的 selector 间接管理。
## 获取指标
指标有三种来源:
1. Pod 资源指标,比如内存、CPU
2. Pod 自定义指标,比如每个 Pod QPS
3. 外部指标,比如某个 Ingress 的总 QPS、kafka topic lag
## 计算副本数
1. 计算每个目标 pod 的指标,比如 CPU 利用率
2. 计算上述指标的平均值,得到 $currentMetricValue$
3. 结合目标指标值,以及当前副本数,计算目标副本数:
$$
desiredReplicas =\lceil currentReplicas\times \frac{currentmetircValue}{desiredMetricValue}\rceil
$$
举个例子,当前副本数为 3,每个 pod 的 cpu request 值为 100m,实际使用:
```
Pod1: 80m
Pod2: 60m
Pod3: 100m
```
利用率分别为:
```
80%
60%
100%
```
求平均得到:
```
(80 + 60 + 100) / 3 = 80%
```
如果 desiredMetricValue 为 50%,则根据公式计算得到目标副本数为:
```
desiredReplicas = ceil(3 * 80 / 50) = ceil(4.8) = 5
```
## 其它规则
### 是否参与计算
- 对于 deletetion timestamp 不为空的 pod,以及 failed pod,将不会参与计算。
- 对于缺失指标的 pod、not ready pod(包括启动 30s 内的 pod、启动 5min 内最近一次指标采集发生在最近一次 ready 之前的 pod、启动 5min 分钟后处于 not ready 的 pod),将被 set aside,即参与 **保留计算**。(这里的 30s 和 5min 是默认值,由 HPA 控制器的启动参数决定)
### 保留计算
保留计算的目的是抑制扩缩容,用于 HPA 内部防抖动。
步骤是先用正常的 pod 进行计算得到基础缩放比例,随后,
- 对于指标缺失的 pod,如果趋势是 scale up,那么将该 pod 的指标视为 0%;如果趋势是 scale down,那么将该 pod 的指标视为 100%。
- 对于 not ready pod,如果趋势是 scale up,那么将该 pod 的指标视为 0%;趋势是 scale down 则不参与计算。
最后用这些指标以及正常 pod 的指标来计算得到最终的目标副本数。
### 原始指标与实际指标
原始指标指的是用正常 pod 计算得到的指标,这是你 `kubectl get hpa -o yaml` 所能看到的数值。
实际指标指的是保留计算后得到的指标,它才是影响最终扩缩容的指标,目的是 HPA 内部用于防抖动。因此在排查问题时,你可能会看到:
```
HPA status: 85%
target: 50%
```
却发现:
```
没有 scale up
```
因为实际指标很可能小于 50%。
### 多个指标
如果 HPA 指定了多个指标,则会分别计算,最终取最大的目标副本数;如果部分指标无法获取,并且那些可获取的指标建议缩容,那 HPA 将采取更保守的做法,即不会缩容。
### 缩容前的观测时间窗
HPA 每次调谐循环都会算出一个 desiredReplicas,例如:
| 时间 | 计算结果 |
| ----- | -------- |
| 00:00 | 10 |
| 00:15 | 8 |
| 00:30 | 6 |
| 00:45 | 9 |
| 01:00 | 7 |
如果没有额外机制,直接触发缩容,副本数会频繁上下跳动。而我们可以指定--horizontal-pod-autoscaler-downscale-stabilization = 5m,含义是在准备缩容前,HPA 会查看最近 5 分钟内的所有“副本推荐值”,并选择其中最大的一个。
假设最近 5 分钟的推荐值为:
```
10, 8, 6, 9, 7
```
即使当前计算是 7,HPA 也会使用 10 这个值。
从整体上看,取这段时间窗口内最大值的目的是:**HPA 必须确定系统持续低负载一段时间后再决定缩容,而不是一次波动就缩容**。
总的来说,缩容前的观测时间窗可以一定程度上避免:Pod 不断销毁重建、连接抖动、冷启动放大等问题。