# FasterTransformer Decoder
The FasterTransformer Decoder contains the transformer decoder block, whole decoding progress, and GPT model.
## Table Of Contents
- [FasterTransformer Decoder](#fastertransformer-decoder)
- [Table Of Contents](#table-of-contents)
- [Introduction](#introduction)
- [Model architecture](#model-architecture)
- [Workflow](#workflow)
- [Decoder](#decoder)
- [Decoding](#decoding)
- [Optimization](#optimization)
- [Setup](#setup)
- [Requirements](#requirements)
- [Build the FasterTransformer](#build-the-fastertransformer)
- [Prepare](#prepare)
- [Build the project](#build-the-project)
- [How to use](#how-to-use)
- [Decoder and decoding process](#decoder-and-decoding-process)
- [Translation process](#translation-process)
- [Performance](#performance)
- [End-to-end translation performance on TensorFlow](#end-to-end-translation-performance-on-tensorflow)
- [Beamsearch performance on A100 and TensorFlow](#beamsearch-performance-on-a100-and-tensorflow)
- [Sampling performance on A100 and TensorFlow](#sampling-performance-on-a100-and-tensorflow)
- [Beamsearch performance on V100 and TensorFlow](#beamsearch-performance-on-v100-and-tensorflow)
- [Sampling performance on V100 and TensorFlow](#sampling-performance-on-v100-and-tensorflow)
- [Beamsearch performance on T4 and TensorFlow](#beamsearch-performance-on-t4-and-tensorflow)
- [Sampling performance on T4 and TensorFlow](#sampling-performance-on-t4-and-tensorflow)
- [End-to-end translation performance on PyTorch](#end-to-end-translation-performance-on-pytorch)
- [Beamsearch performance on A100 and PyTorch](#beamsearch-performance-on-a100-and-pytorch)
- [Beamsearch performance on V100 and PyTorch](#beamsearch-performance-on-v100-and-pytorch)
- [Beamsearch performance on T4 and PyTorch](#beamsearch-performance-on-t4-and-pytorch)
## Introduction
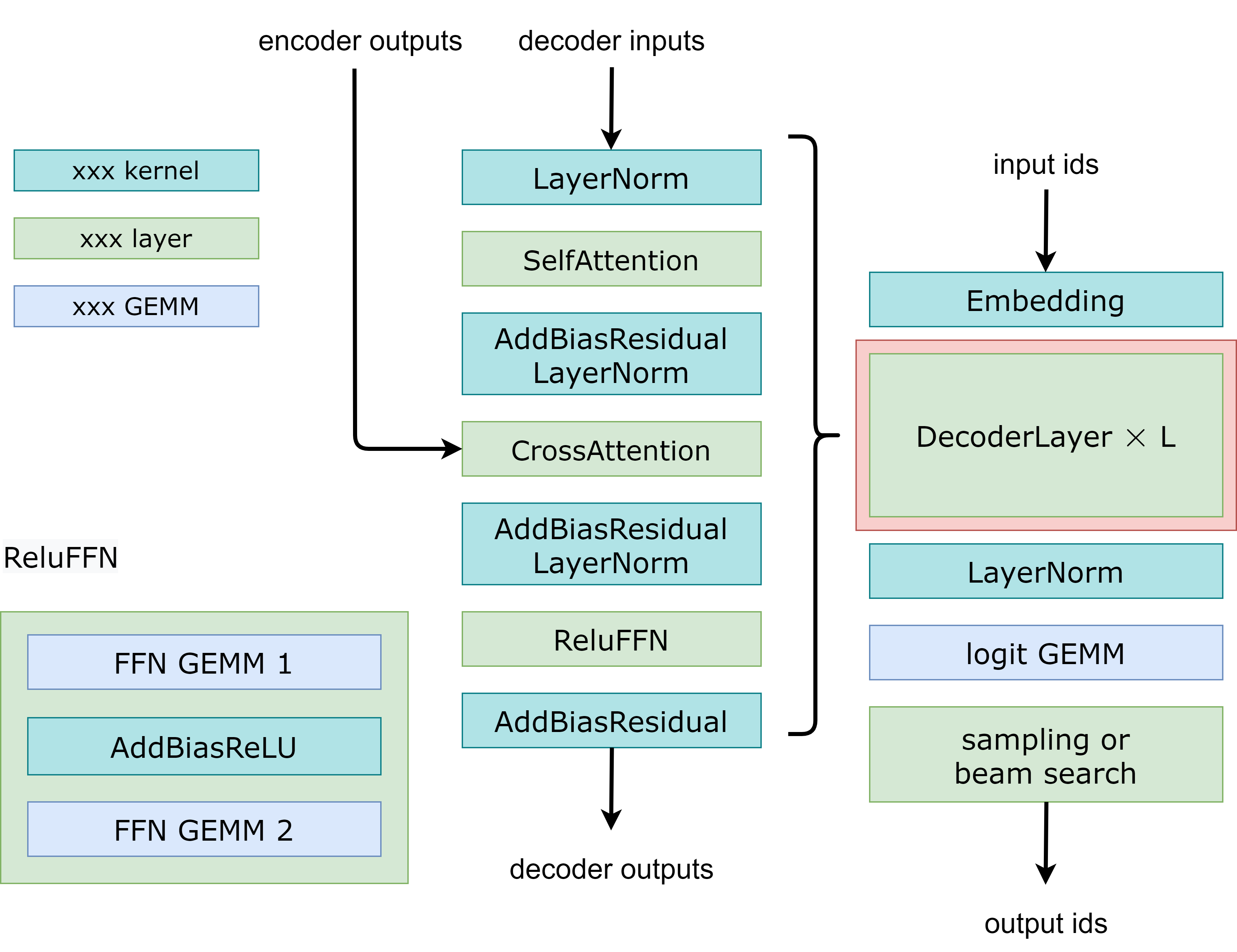
This document describes what FasterTransformer provides for the `Decoder/Decoding` model, explaining the workflow and optimization. We also provide a guide to help users to run the `Decoder/Decoding` model on FasterTransformer. Finally, we provide benchmark to demonstrate the speed of FasterTransformer on `Decoder/Decoding`. In this document, `Decoder` means the decoder transformer blocks, which contains two attention blocks and a feed-forward network. The module in the red block of Fig.1 demonstrates the Decoder block. On the other hand, `Decoding` refers to the whole translating process, including position encoding, embedding lookup, several layers of Decoder and beam search or sampling methods to choose the token. Fig. 1 shows the different between decoding with beam search and sampling.
Although the decoding process of most methods is similar, we find that there are lots of different kinds to compute the probability and implement the beam search. Therefore, if your chosen beam search algorithm is different from our implementation and it is hard for you to modify the beam search kernel, TensorFlow/PyTorch decoding with FasterTransformer Decoder is the recommended choice. However, the performance of the TensorFlow/PyTorch decoding with the FasterTransformer Decoder is worse than the performance of the FasterTransformer Decoding, especially for small batch sizes.
## Model architecture
### Workflow
Fig 1 demonstrates the workflow of FasterTransformer Decoder and Decoding. They receive some results from encoder as the inputs of CrossAttention, using the start ids or the generated ids of previous step as the inputs of Decoding and generates the respective output ids as response.
Fig. 1 Flowchart of Decoding and GPT.
The following examples demonstrating how to run multi-GPU and multi-node GPT model.
1. `examples/cpp/decoding.cc`: An example to run the Decoding with random weights and inputs in C++.
2. `examples/tensorflow/decoding/translate_example.py`: An example to run the end-to-end translation task with FasterTransformer Decoder/Decoding in TensorFlow. We also use the FasterTransformer encoder op in this example.
### Decoder
The source codes are put in `src/fastertransformer/models/decoder/Decoder.cc`. The arguments, inputs, and outputs of decoder are:
* Arguments:
1. Maximum batch size
2. Head number
3. Size per head
4. Intermediate size. The inter size of feed forward network. It is often set to 4 * head_num * size_per_head.
5. Number of decoder layers
6. CUDA stream.
7. Pointer of cuBLAS wrapper, which is declared in `src/fastertransformer/utils/cublasMMWrapper.h`.
8. Pointer of memory allocator, which is declared in `src/fastertransformer/utils/allocator.h`
9. “is_free_buffer_after_forward” flag. If setting to be true, FasterTransformer will allocate buffer before forward, and free buffer after forward. If the memory is controlled by memory pool and the cost of allocating/releasing memory is small, setting the flag to be true can save some memory.
* Inputs:
1. Decoder input feature: The features vector obtained by looking up the embedding table, or the previous result of the decoder. The shape is \[ request batch size, hidden dimension \].
2. Encoder output feature: The output from the encoder. The shape is \[ request batch size, maximum sequence length of encoder output, encoder hidden dimension \].
3. Encoder sequence length: The sequence lengths of encoder inputs. The shape is \[ request batch size \].
4. Finished buffer: Record one sentence is finished or not. The shape is \[ request batch size \].
5. Step: The current step, used in attention layer. The shape is \[ 1 \]. This is a pointer on CPU.
6. Sequence lengths: The sequence lengths of decoded sentences. The shape is \[ request batch size \].
* Outputs:
1. Decoder output feature: The shape is \[ request batch size, hidden dimension \].
2. Key caches: The buffer to store the keys of self-attention of previous steps. The shape is \[ number of decoder layer, request batch size, head number, size per head // x, maximum sequence length, x \], where x is 4 under FP32, and 8 under FP16.
3. Value caches: The buffer to store the values of self-attention of previous steps. The shape is \[ number of decoder layer, request batch size, head number, maximum sequence length, size per head \].
4. Key memory caches: The buffer to store the keys of cross attention of previous steps. The shape is \[ number of decoder layer, request batch size, maximum sequence length of encoder output, hidden dimension \].
5. Value memory caches: The buffer to store the values of cross attention of previous steps. The shape is \[ number of decoder layer, request batch size, maximum sequence length of encoder output, hidden dimension \].
### Decoding
The source codes are put in `src/fastertransformer/models/decoding/Decoding.cc`. The arguments, inputs, and outputs of decoding are:
* Arguments:
1. Maximum batch size
2. Maximum sequence length
3. Maximum sequence length of encoder output
4. beam width for beam search. If setting b to be 1, then we don’t use beam search but use sampling.
5. Head number
6. Size per head
7. Intermediate size. The inter size of feed forward network. It is often set to 4 * head_num * size_per_head.
8. Number of decoder layers
9. Vocab size
10. Start id of the vocabulary
11. End id of the vocabulary
12. Diversity rate of beam search. A hyper hyper-parameter for [simple diverse decoding](https://arxiv.org/pdf/1611.08562.pdf).
13. top_k value for top k sampling.
14. top_p value for top p sampling
15. Temperature for logit. Setting to be 1.0 if you don’t want to apply the temperature.
16. Length penalty for logit. Setting to be 1.0 if you don’t want to apply the length penalty.
17. Repetition penalty for logit. Setting to be 1.0 if you don’t want to apply the repetition penalty.
18. CUDA stream.
19. Pointer of cuBLAS wrapper, which is declared in `src/fastertransformer/utils/cublasMMWrapper.h`.
20. Pointer of memory allocator, which is declared in `src/fastertransformer/utils/allocator.h`
21. “is_free_buffer_after_forward” flag. If setting to be true, FasterTransformer will allocate buffer before forward, and free buffer after forward. If the memory is controlled by memory pool and the cost of
allocating/releasing memory is small, setting the flag to be true can save some memory.
22. Pointer of CUDA device properties, which is used to get the properties of hardware like size of shared memory.
* Inputs:
1. The output of the encoder. The shape is \[ request batch size * beam width, memory sequence length, encoder hidden dimension \].
2. The sequence length of the source sentence. The shape is \[ request batch size * beam width \].
* Outputs:
1. Output ids. The shape is \[maximum sequence length, batch size, beam width \].
2. Parent ids. It is used to find the best path in beam search. It is deprecated now.
3. Sequence lengths. The shape is \[batch size * beam width\]. It records the final sequence lengths of all sentences.
Although there are many arguments, most of them are fixed. For example, argument 5 ~ 11 are model hyper-parameters and fixed after we determine the model hyper-parameters. Argument 18, 19, 20 and 22 are some settings about CUDA, and progress are fixed.
### Optimization
1. Kernel optimization: First, since the sequence length of query in `SelfAttention` and `CrossAttention` is always 1, we use customed fused multi-head attention kernel to optimize. Second, we fuse many small operations into one kernel. For example, `AddBiasResidualLayerNorm` combines the adding bias, adding residual of previous block and the computation of layer normalization into 1 kernel. Third, we optimize top k operation and sampling to accelerate the beam search and sampling. Finally, to prevent from recomputing the previous keys and values, we allocate a buffer to store them at each step. Although it takes some additional memory usage, we can save the cost of recomputing, allocating buffer at each step, and the cost of concatenation.
2. Memory optimization: Different to traditional models like BERT, GPT-3 has 175 billion parameters, taking 350 GBs even if we store the model by half precision. Therefore, we must reduce the memory usage for other parts. In FasterTransformer, we will reuse the memory buffer of different decoder layers. Since the number of layers in GPT-3 is 96, we only need 1/96 memory.
## Setup
The following section lists the requirements to use FasterTransformer.
### Requirements
- CMake >= 3.8 for Tensorflow, CMake >= 3.13 for PyTorch
- CUDA 11.0 or newer version
- Python 3 is recommended because some features are not supported in python 2
- Tensorflow: Verify on 1.15, 1.13 and 1.14 should work.
- PyTorch: Verify on 1.8.0, >= 1.5.0 should work.
These components are readily available within the NGC TensorFlow Docker image below.
Ensure you have the following components:
- [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker) and NGC container are recommended
- [NVIDIA Pascal](https://www.nvidia.com/en-us/data-center/pascal-gpu-architecture/) or [Volta](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/) or [Turing](https://www.nvidia.com/en-us/geforce/turing/) or [Ampere](https://www.nvidia.com/en-us/data-center/nvidia-ampere-gpu-architecture/) based GPU
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
- [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
- [Running TensorFlow](https://docs.nvidia.com/deeplearning/frameworks/tensorflow-release-notes/running.html#running)
- [Running PyTorch](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html)
For those unable to use the NGC container, to set up the required environment or create your own container, see the versioned [NVIDIA Container Support Matrix](https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html).
### Build the FasterTransformer
#### Prepare
You can choose the tensorflow version and python version you want. Here, we list some possible images:
To achieve best performance, we recommend to use the latest image. For example, running image `nvcr.io/nvidia/tensorflow:22.09-tf1-py3` by
```bash
nvidia-docker run -ti --shm-size 5g --rm nvcr.io/nvidia/tensorflow:22.09-tf1-py3 bash
git clone https://github.com/NVIDIA/FasterTransformer.git
mkdir -p FasterTransformer/build
cd FasterTransformer/build
git submodule init && git submodule update
```
#### Build the project
* Note: the `xx` of `-DSM=xx` in following scripts means the compute capability of your GPU. For example, 60 (P40) or 61 (P4) or 70 (V100) or 75(T4) or 80 (A100). Default setting is including 70, 75, 80 and 86.
1. build with C++
```bash
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release ..
make -j12
```
2. build with TensorFlow
Uses need to set the path of TensorFlow. For example, if we use `nvcr.io/nvidia/tensorflow:22.09-tf1-py3`, then
```bash
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_TF=ON -DTF_PATH=/usr/local/lib/python3.8/dist-packages/tensorflow_core/ ..
make -j12
```
3. build with PyTorch
```bash
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON ..
make -j12
```
This will build the TorchScript custom class. Please make sure that the `PyTorch >= 1.5.0`.
## How to use
### Decoder and decoding process
1. Run FasterTransformer decoding on C++
1.1 Generate the `gemm_config.in` file.
`./bin/decoding_gemm` can generate the best GEMM configuration. The arguments of `decoding_gemm` are:
```bash
./bin/decoding_gemm
```
Assume the settings of decoding are as follows.
- `batch_size`=32
- `beam_width`=4
- `head_number`=8
- `size_per_head`=64
- `vocabulary_size`=30000
- `sequence_length`=32
- `encoder's hidden dimension`=512
- `data_type`=0 (FP32) or 1 (FP16) or 2 (BF16)
Then the following scripts can generate the best GEMM configuration under such settings and record the configuration into the `gemm_config.in` file.
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 0
```
1.2 Run decoding under FP32 on C++
Assume the settings are the same as above, and the decoder contains 6 transformer layers.
In the decoding, we provide two kinds of methods to choose the tokens from the candidates. The first kind of method is the beam search algorithm. The second kind of method is sampling algorithm.
For beam search, we provide a simple diverse decoding of [link](https://arxiv.org/pdf/1611.08562.pdf). When the diversity rate is set to 0, it is equivalent to the naive beam search.
For sampling, we provide the top k sampling and top p sampling. Here, k is an integer number and p is a float point number. Note that we cannot use both at the same time. So, only one of both can be non-zero value.
`./bin/decoding_example` runs the decoding with beam search or sampling in the `C++`. The arguments of `decoding_example` is:
```bash
./bin/decoding_example
```
Data Type = 0 (FP32) or 1 (FP16) or 2 (BF16)
Then the following scripts can run the decoding with beam search under the above settings.
```bash
./bin/decoding_example 32 4 8 64 2048 30000 6 32 32 512 0 0.0 0
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 max_seq_len 32 num_layers 6 vocab_size 30000, top_k 0, top_p 0.000, FT-CPP-decoding-time 96.92 ms
```
If `beam_width` is 1, `decoding_example` will use sampling.
The following scripts can run the decoding with top k sampling or top p sampling with under the above settings.
```bash
./bin/decoding_gemm 32 1 8 64 2048 30000 32 512 0
./bin/decoding_example 32 1 8 64 2048 30000 6 32 32 512 4 0.0 0 # top_k = 4
./bin/decoding_example 32 1 8 64 2048 30000 6 32 32 512 0 0.5 0 # top_p = 0.5
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 1 head_num 8 size_per_head 64 max_seq_len 32 num_layers 6 vocab_size 30000, top_k 4, top_p 0.000, FT-CPP-decoding-time 55.05 ms
[INFO] batch_size 32 beam_width 1 head_num 8 size_per_head 64 max_seq_len 32 num_layers 6 vocab_size 30000, top_k 0, top_p 0.500, FT-CPP-decoding-time 75.91 ms
```
1.3 Run decoding under FP16/BF16 on C++
So far, we use the FP32 to run the FasterTransformer. If we use the volta or newer NVIDIA GPU, we can use tensor core to accelerate when we use the FP16. BF16 is only supported after Ampere NVIDIA GPU (SM 80).
To use the FP16, we only need to set the `` flag to 1 like following:
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 1
./bin/decoding_example 32 4 8 64 2048 30000 6 32 32 512 0 0.0 1
```
To use the BF16, we only need to set the `` flag to 2.
Note that the configuration of FP32 and FP16 are different, so we need to generate the configuration again.
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 max_seq_len 32 num_layers 6 vocab_size 30000, top_k 0, top_p 0.000, FT-CPP-decoding-time 47.93 ms
```
2. Run FasterTransformer decoder/decoding on TensorFlow
2.1 Run FasterTransformer decoder under FP32 on TensorFlow
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 0
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--decoder_type 2
```
The outputs should be like to the following:
```bash
[[INFO][PYTHON] step:][29][True][max abs diff: ][4.17232513e-06][ op val: ][1.23598516][ tf val: ][1.23598933]
[[INFO][PYTHON] step:][30][True][max abs diff: ][4.05311584e-06][ op val: ][-2.40530682][ tf val: ][-2.40531087]
[[INFO][PYTHON] step:][31][False][max abs diff: ][3.7997961e-06][ op val: ][-0.120998174][ tf val: ][-0.121001974]
```
The results show that the differences between the decoder of TensorFlow and decoder are smaller than threshold. Sometimes, the differences are larger than the threshold and the checking will return "False", but it does not affect the results.
The argument `decoder_type` decides to use the decoder of TensorFlow or decoder of FasterTransformer. `decoder_type 2` uses both decoders and compares their results.
The following script demonstrates the execution time of the FasterTransformer decoder.
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 0
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--decoder_type 1 \
--test_time 1
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoder-time 138.90 ms.
```
The following script demonstrates the execution time of the TensorFlow decoder.
```bash
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--decoder_type 0 \
--test_time 1
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-beamsearch-time 564.37 ms.
```
2.2 Run FasterTransformer decoder under FP16 on TensorFlow
To use the FP16 in TensorFlow, we only need to set the `--data_type fp16` like following:
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 1
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp16 \
--decoder_type 2
```
The outputs should be like to the following:
```bash
[[INFO][PYTHON] step:][29][True][max abs diff: ][0.01171875][ op val: ][2.03125][ tf val: ][2.04296875]
[[INFO][PYTHON] step:][30][True][max abs diff: ][0.01171875][ op val: ][2.3671875][ tf val: ][2.35546875]
[[INFO][PYTHON] step:][31][True][max abs diff: ][0.01171875][ op val: ][2.33398438][ tf val: ][2.32226562]
```
The following script demonstrates the execution time of the FasterTransformer decoder.
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 1
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp16 \
--decoder_type 1 \
--test_time 1
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoder-time 132.48 ms.
```
The following script demonstrates the execution time of the TensorFlow decoder.
```bash
python ../examples/tensorflow/decoder/decoder_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--decoder_type 0 \
--test_time 1
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-beamsearch-time 503.52 ms.
```
Note that when the batch size is small, using FP16 may cause the inference speed to become slower. This is because that decoding is not computing bound and using FP16 in TensorFlow leads to some additional operation and casting.
2.3 Run FasterTransformer decoding under FP32 on TensorFlow
In the decoding, we provide two kinds of methods to choose the tokens from the candidates. The first kind of method is the beam search algorithm. The second kind of method is sampling algorithm.
For beam search, we provide a simple diverse decoding of [link](https://arxiv.org/pdf/1611.08562.pdf). When the `--beam_search_diversity_rate` is set to 0, it is equivalent to the naive beam search.
For sampling, we provide the top k sampling and top p sampling, which are set by the arguments `--sampling_topk` and `--sampling_topp`. Here, k is an integer number and p is a float point number. Note that we cannot use both at the same time. So, only one of both can be non-zero value.
The following script uses diverse decoding with diversity rate 0 and top k sampling with k = 4:
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 0
python ../examples/tensorflow/decoding/decoding_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--beam_search_diversity_rate 0.0 \
--sampling_topk 4 \
--sampling_topp 0.00 \
--test_time 0123
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-beamsearch-time 555.87 ms.
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-beamsearch-time 75.80 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-sampling-time 432.40 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-sampling-time 46.68 ms.
```
Note that the results of FasterTransformer may be different, especially when the batch size is larger.
Here, we use same configuration to run the decoding with beam search and sampling at the same time. This is not correct because the beam width of decoding with sampling is always 1, so the configurations of them are same only when the beam width is 1. However, this only little reduce the speed of decoding with sampling, so we ignore this problem here.
Here, the meaning of argument `--test_time` is different. 0 means testing the TensorFlow with beam search; 1 means testing the FasterTransformer with beam search; 2 means testing the TensorFlow with sampling; 3 means testing the FasterTransformer with sampling.
The following script uses diverse decoding with diversity rate -1.3 and top p sampling with p = 0.01:
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 0
python ../examples/tensorflow/decoding/decoding_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp32 \
--beam_search_diversity_rate -1.3 \
--sampling_topk 0 \
--sampling_topp 0.01 \
--test_time 0123
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-beamsearch-time 525.55 ms.
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-beamsearch-time 76.79 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-sampling-time 420.98 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-sampling-time 46.37 ms.
```
For the sampling algorithm, the results of TensorFlow and FasterTransformer are often different.
2.4 Run FasterTransformer decoding under FP16 on TensorFlow
```bash
./bin/decoding_gemm 32 4 8 64 2048 30000 32 512 1
python ../examples/tensorflow/decoding/decoding_example.py \
--batch_size 32 \
--beam_width 4 \
--head_number 8 \
--size_per_head 64 \
--vocab_size 30000 \
--max_seq_len 32 \
--num_layer 6 \
--memory_hidden_dim 512 \
--data_type fp16 \
--beam_search_diversity_rate 0.0 \
--sampling_topk 4 \
--sampling_topp 0.00 \
--test_time 0123
```
The outputs should be like to the following:
```bash
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-beamsearch-time 494.23 ms.
[INFO] batch_size 32 beam_width 4 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-beamsearch-time 50.43 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 TF-decoding-sampling-time 382.34 ms.
[INFO] batch_size 32 topk 4 topp 0.0 head_num 8 size_per_head 64 seq_len 32 decoder_layers 6 vocab_size 30000 FT-OP-decoding-sampling-time 33.19 ms.
```
Note that the results of FasterTransformer may be different, especially when the batch size is larger.
3. Run FasterTransformer decoder/decoding on PyTorch
Please install OpenNMT-py first before running the demos by
```bash
pip install opennmt-py==1.1.1
```
3.1 Generate the `gemm_config.in` file:
```bash
./bin/decoding_gemm
./bin/decoding_gemm 8 4 8 64 2048 31538 32 512 1
```
Data Type = 0 (FP32) or 1 (FP16) or 2 (BF16)
If you want to use the library in other directory, please generate this file according to your setting and copy it to your working directory.
3.2 Run the PyTorch decoder sample:
```bash
python ../examples/pytorch/decoder/decoder_example.py <--data_type fp32/fp16/bf16> <--time>
python ../examples/pytorch/decoder/decoder_example.py 8 6 32 8 64 --data_type fp16 --time
```
The outputs should be like to the following:
```bash
step: 30 Mean relative diff: 0.01395416259765625 Max relative diff: 1.38671875 Min relative diff: 0.0
step: 31 Mean relative diff: 0.0148468017578125 Max relative diff: 2.880859375 Min relative diff: 0.0
[INFO] ONMTDecoder time costs: 218.37 ms
[INFO] FTDecoder time costs: 25.15 ms
```
Note that the relative diff is very large. It is caused by the random initial weights and inputs, and it does not affect the result of translation.
3.3 Run the PyTorch decoding sample:
```bash
python pytorch/decoding_sample.py <--data_type fp32/fp16/bf16> <--time>
python ../examples/pytorch/decoding/decoding_example.py 8 6 32 8 64 4 31538 --data_type fp16 --time
```
The outputs should be like to the following:
```bash
[INFO] TorchDecoding time costs: 289.08 ms
[INFO] TorchDecoding (with FTDecoder) time costs: 104.15 ms
[INFO] FTDecoding time costs: 30.57 ms
```
Random initialized parameters may lead to different results. You can download the pretrained model following the instruction in the next part, and add `--use_pretrained`, then you can get the same results.
### Translation process
1. Translation with FasterTransformer on TensorFlow
This subsection demonstrates how to use FasterTransformer decoding to translate a sentence. We use the pretrained model and testing data in [OpenNMT-tf](https://opennmt.net/Models-tf/), which translates from English to German.
Because the FasterTransformer Encoder is based on BERT, we cannot restore the model of encoder of OpenNMT to FasterTransformer Encoder. Therefore, we use OpenNMT-tf to build the encoder and preprocess the source sentence.
Another problem is that the implementation of FasterTransformer Decoder and decoder of OpenNMT-tf is a little different. For example, the decoder of OpenNMT-tf uses one convolution to compute query, key, and value in masked-multi-head-attention; but FasterTransformer Decoder splits them into three gemms. One method is using the tool `utils/dump_model.py` to convert the pretrained model to fit the model structure of FasterTransformer Decoder. Another method is Splitting the weights during inference.
`download_model_data.sh` will install the OpenNMT-tf v1, downloading the pretrained model into the `translation` folder, and convert the model.
```bash
bash ../examples/tensorflow/decoding/utils/translation/download_model_data.sh
```
Then run the translation sample by the following script:
```bash
./bin/decoding_gemm 128 4 8 64 2048 32001 100 512 0
python ../examples/tensorflow/decoding/translate_example.py \
--batch_size 128 \
--beam_width 4 \
--max_seq_len 32 \
--data_type fp32 \
--beam_search_diversity_rate 0.0 \
--sampling_topk 1 \
--sampling_topp 0.00 \
--test_time 012345
```
The outputs of should be similar to the following:
```bash
[INFO] tf-decoding-beamsearch translates 24 batches taking 31.39 ms to translate 67092 tokens, BLEU score: 26.29, 2137 tokens/sec.
[INFO] op-decoder-beamsearch translates 24 batches taking 10.37 ms to translate 67092 tokens, BLEU score: 26.29, 6473 tokens/sec.
[INFO] op-decoding-beamsearch translates 24 batches taking 7.88 ms to translate 67124 tokens, BLEU score: 26.31, 8513 tokens/sec.
[INFO] tf-decoding-sampling translates 24 batches taking 16.23 ms to translate 67813 tokens, BLEU score: 25.79, 4178 tokens/sec.
[INFO] op-decoder-sampling translates 24 batches taking 6.29 ms to translate 67813 tokens, BLEU score: 25.79, 10781 tokens/sec.
[INFO] op-decoding-sampling translates 24 batches taking 4.10 ms to translate 67813 tokens, BLEU score: 25.79, 16524 tokens/sec.
```
The scripts of running under FP16 is following:
```bash
python ../examples/tensorflow/ckpt_type_convert.py --init_checkpoint=../translation/ckpt/model.ckpt-500000 --fp16_checkpoint=../translation/ckpt_fp16/model.ckpt-500000
./bin/decoding_gemm 128 4 8 64 32001 100 512 1
python ../examples/tensorflow/decoding/translate_example.py \
--batch_size 128 \
--beam_width 4 \
--max_seq_len 32 \
--data_type fp16 \
--beam_search_diversity_rate 0.0 \
--sampling_topk 1 \
--sampling_topp 0.00 \
--test_time 012345
```
The outputs of should be similar to the following:
```bash
[INFO] tf-decoding-beamsearch translates 24 batches taking 22.75 ms to translate 67094 tokens, BLEU score: 26.31, 2949 tokens/sec.
[INFO] op-decoder-beamsearch translates 24 batches taking 7.73 ms to translate 67089 tokens, BLEU score: 26.30, 8682 tokens/sec.
[INFO] op-decoding-beamsearch translates 24 batches taking 5.27 ms to translate 67130 tokens, BLEU score: 26.33, 12746 tokens/sec.
[INFO] tf-decoding-sampling translates 24 batches taking 13.65 ms to translate 67828 tokens, BLEU score: 25.83, 4968 tokens/sec.
[INFO] op-decoder-sampling translates 24 batches taking 4.92 ms to translate 67831 tokens, BLEU score: 25.80, 13773 tokens/sec.
[INFO] op-decoding-sampling translates 24 batches taking 2.54 ms to translate 67844 tokens, BLEU score: 25.82, 26718 tokens/sec.
```
2. Translation with FasterTransformer on PyTorch
We have a translation demo for En-De translation.
You need to download the pretrained_model first by:
```bash
bash ../examples/pytorch/decoding/utils/download_model.sh
```
Then you can run the demo by:
```bash
python ../examples/pytorch/decoding/translate_example.py --batch_size --beam_size --model_type --data_type --output_file
```
you can also use `--input_file` to set the input file to be translated.
the `` can be:
- `decoding_ext`: using our FasterTransformer decoding module
- `torch_decoding`: PyTorch version decoding with the method FasterTransformer decoding uses
- `torch_decoding_with_decoder_ext`: PyTorch version decoding with the method FasterTransformer decoding uses but replace the decoder with the FasterTransformer decoder
the `` can be `fp32` or `fp16` or `bf16`
If you do not specify the output file, it only print to the standard output.
If you want to evaluate the BLEU score, please recover the BPE first by:
```bash
python ../examples/pytorch/decoding/utils/recover_bpe.py
python ../examples/pytorch/decoding/utils/recover_bpe.py
```
the `` for our demo is `pytorch/translation/data/test.de`, the `` is the output from `translate_example.py`.
Then you can evaluate the BLEU score, for example, through `sacrebleu`:
```bash
pip install sacrebleu
cat | sacrebleu
```
The following scripts run translation under FP32 and get the bleu score:
```bash
./bin/decoding_gemm 128 4 8 64 2048 31538 100 512 0
python ../examples/pytorch/decoding/translate_example.py --batch_size 128 --beam_size 4 --model_type decoding_ext --data_type fp32 --output_file output.txt
python ../examples/pytorch/decoding/utils/recover_bpe.py ../examples/pytorch/decoding/utils/translation/test.de debpe_ref.txt
python ../examples/pytorch/decoding/utils/recover_bpe.py output.txt debpe_output.txt
pip install sacrebleu
cat debpe_output.txt | sacrebleu debpe_ref.txt
```
## Performance
Hardware settings:
* CPU: Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz
* T4 (with mclk 5000MHz, pclk 1590MHz) with Intel(R) Xeon(R) CPU E5-2603 v4 @ 1.70GHz
* V100 (with mclk 877MHz, pclk 1380MHz) with Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz (dgx-1 server)
To run the following benchmark, we need to install the unix computing tool "bc" by
```bash
apt-get install bc
```
To understand the speedup on real application, we use real end-to-end model and task in this benchmark on both TensorFlow and PyTorch. It is hard to compare the performance of v3.1 and v4.0 this the benchmark directly. But by our testing, compared to v3.1, v4.0 brings at most 50% speedup, especially for large batch size.
### End-to-end translation performance on TensorFlow
We demonstrate the throughput of TensorFlow (`TF`), `FT Decoder` and `FT Decoding` for end-to-end translation. Here, TensorFlow means that the program fully runs on TensorFlow. FT Decoder means that we replace the decoder transformer layer by FasterTransformer. FT Decoding means that we replace the whole procedure of decoder by FasterTransformer. Besides, we also replace the encoder transformer layer by FasterTransformer Encoder in FT Decoding.
We do not demonstrate the performance of TensorFlow with XLA since we did not find that using XLA has obvious speedup. We also skip the BLEU score because the score of TensorFlow, FT Decoder and FT Decoding are close.
Although the bleu scores of all methods are close, the results may be little different, and the number of generated tokens may be also different. So, we use throughput but not latency to show the performance in this benchmark.
The benchmark of beamsearch were obtained by running the `sample/tensorflow/scripts/profile_decoding_beamsearch_performance.sh`; while The benchmark of sampling were obtained by running the `sample/tensorflow/scripts/profile_decoding_sampling_performance.sh`..
In this benchmark, we updated the following parameters:
* head_num = 8 for both encoder and decoder
* size_per_head = 64 for both encoder and decoder
* num_layers = 6 for both encoder and decoder
* vocabulary_size = 32001
* max_seq_len = 128
#### Beamsearch performance on A100 and TensorFlow
* Performance on FP32
User can use `export NVIDIA_TF32_OVERRIDE=0` to enforce the program run under FP32.
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 213 | 414 | 698 | 1.94 | 3.27 |
| 1 | 4 | FP32 | 174 | 430 | 855 | 2.47 | 4.91 |
| 1 | 32 | FP32 | 106 | 182 | 677 | 1.71 | 6.38 |
| 8 | 1 | FP32 | 929 | 2214 | 4578 | 2.38 | 4.92 |
| 8 | 4 | FP32 | 726 | 1808 | 3874 | 2.49 | 5.33 |
| 8 | 32 | FP32 | 325 | 422 | 1322 | 1.29 | 4.06 |
| 128 | 1 | FP32 | 6468 | 14274 | 24008 | 2.20 | 3.71 |
| 128 | 4 | FP32 | 2739 | 3959 | 9492 | 1.44 | 3.46 |
| 128 | 32 | FP32 | 491 | 579 | 1354 | 1.17 | 2.75 |
* Performance on FP16
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 240 | 646 | 1392 | 2.69 | 5.80 |
| 1 | 4 | FP16 | 176 | 501 | 1272 | 2.84 | 7.22 |
| 1 | 32 | FP16 | 106 | 194 | 930 | 1.83 | 8.77 |
| 8 | 1 | FP16 | 1007 | 2857 | 6399 | 2.83 | 6.35 |
| 8 | 4 | FP16 | 746 | 2019 | 5370 | 2.70 | 7.19 |
| 8 | 32 | FP16 | 399 | 512 | 2797 | 1.28 | 7.01 |
| 128 | 1 | FP16 | 8274 | 19309 | 45551 | 2.33 | 5.50 |
| 128 | 4 | FP16 | 3984 | 5515 | 27248 | 1.38 | 6.83 |
| 128 | 32 | FP16 | 711 | 812 | 3767 | 1.14 | 5.29 |
#### Sampling performance on A100 and TensorFlow
* Performance on FP32
User can use `export NVIDIA_TF32_OVERRIDE=0` to enforce the program run under FP32.
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP32 | 208 | 415 | 703 | 1.99 | 3.37 |
| 1 | 32 | FP32 | 198 | 382 | 683 | 1.92 | 3.44 |
| 1 | 0.75 | FP32 | 197 | 366 | 612 | 1.85 | 3.10 |
| 8 | 4 | FP32 | 931 | 2158 | 4449 | 2.31 | 4.77 |
| 8 | 32 | FP32 | 872 | 1988 | 4389 | 2.27 | 5.03 |
| 8 | 0.75 | FP32 | 884 | 1861 | 3435 | 2.10 | 3.88 |
| 128 | 4 | FP32 | 6274 | 13606 | 23967 | 2.16 | 3.82 |
| 128 | 32 | FP32 | 6168 | 13037 | 22688 | 2.11 | 3.67 |
| 128 | 0.75 | FP32 | 5635 | 11402 | 19125 | 2.02 | 3.39 |
* Performance on FP16
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP16 | 238 | 636 | 1367 | 2.67 | 5.74 |
| 1 | 32 | FP16 | 243 | 571 | 1293 | 2.34 | 5.32 |
| 1 | 0.75 | FP16 | 227 | 531 | 1152 | 2.33 | 5.07 |
| 8 | 4 | FP16 | 990 | 2714 | 6165 | 2.74 | 6.22 |
| 8 | 32 | FP16 | 986 | 2488 | 5802 | 2.52 | 5.88 |
| 8 | 0.75 | FP16 | 930 | 2329 | 4902 | 2.50 | 5.27 |
| 128 | 4 | FP16 | 8445 | 18415 | 44960 | 2.18 | 5.32 |
| 128 | 32 | FP16 | 7861 | 17264 | 40943 | 2.19 | 5.20 |
| 128 | 0.75 | FP16 | 7173 | 15048 | 35418 | 2.09 | 4.93 |
#### Beamsearch performance on V100 and TensorFlow
* Performance on FP32
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 95 | 351 | 800 | 3.69 | 8.42 |
| 1 | 4 | FP32 | 110 | 341 | 763 | 3.10 | 6.93 |
| 1 | 32 | FP32 | 78 | 171 | 489 | 2.19 | 6.26 |
| 8 | 1 | FP32 | 484 | 1645 | 3694 | 3.39 | 7.63 |
| 8 | 4 | FP32 | 511 | 1435 | 3068 | 2.80 | 6.00 |
| 8 | 32 | FP32 | 231 | 427 | 916 | 1.84 | 3.96 |
| 128 | 1 | FP32 | 3157 | 8373 | 19803 | 2.65 | 6.27 |
| 128 | 4 | FP32 | 1773 | 3648 | 7848 | 2.05 | 4.42 |
* Performance on FP16
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 153 | 360 | 1043 | 2.35 | 6.81 |
| 1 | 4 | FP16 | 143 | 333 | 915 | 2.32 | 6.39 |
| 1 | 32 | FP16 | 102 | 179 | 630 | 1.75 | 6.17 |
| 8 | 1 | FP16 | 662 | 1652 | 4863 | 2.49 | 7.34 |
| 8 | 4 | FP16 | 619 | 1457 | 3995 | 2.35 | 6.45 |
| 8 | 32 | FP16 | 359 | 504 | 1413 | 1.40 | 3.93 |
| 128 | 1 | FP16 | 5693 | 10454 | 30890 | 1.83 | 5.42 |
| 128 | 4 | FP16 | 3316 | 5231 | 16856 | 1.57 | 5.08 |
#### Sampling performance on V100 and TensorFlow
* Performance on FP32
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP32 | 119 | 379 | 759 | 3.18 | 6.37 |
| 1 | 32 | FP32 | 103 | 368 | 739 | 3.57 | 7.17 |
| 1 | 0.75 | FP32 | 111 | 324 | 619 | 2.91 | 5.57 |
| 8 | 4 | FP32 | 491 | 1765 | 3475 | 3.59 | 7.07 |
| 8 | 32 | FP32 | 483 | 1637 | 3395 | 3.38 | 7.02 |
| 8 | 0.75 | FP32 | 460 | 1460 | 2645 | 3.17 | 5.75 |
| 128 | 4 | FP32 | 3387 | 9203 | 18165 | 2.71 | 5.36 |
| 128 | 32 | FP32 | 3380 | 8605 | 17541 | 2.54 | 5.18 |
| 128 | 0.75 | FP32 | 3194 | 6898 | 13925 | 2.15 | 4.35 |
* Performance on FP16
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP16 | 169 | 412 | 992 | 2.43 | 5.86 |
| 1 | 32 | FP16 | 167 | 376 | 970 | 2.25 | 5.80 |
| 1 | 0.75 | FP16 | 160 | 350 | 845 | 2.18 | 5.28 |
| 8 | 4 | FP16 | 739 | 1802 | 4620 | 2.43 | 6.25 |
| 8 | 32 | FP16 | 785 | 1754 | 4425 | 2.23 | 5.63 |
| 8 | 0.75 | FP16 | 715 | 1586 | 3634 | 2.21 | 5.08 |
| 128 | 4 | FP16 | 6217 | 11392 | 29409 | 1.83 | 4.73 |
| 128 | 32 | FP16 | 5937 | 10366 | 27995 | 1.74 | 4.71 |
| 128 | 0.75 | FP16 | 5129 | 8423 | 22094 | 1.64 | 4.30 |
#### Beamsearch performance on T4 and TensorFlow
* Performance on FP32
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 40 | 151 | 599 | 3.77 | 14.97 |
| 1 | 4 | FP32 | 34 | 137 | 563 | 4.02 | 16.55 |
| 1 | 32 | FP32 | 37 | 91 | 330 | 2.45 | 8.91 |
| 8 | 1 | FP32 | 193 | 807 | 2868 | 4.18 | 14.86 |
| 8 | 4 | FP32 | 198 | 644 | 2205 | 3.25 | 11.13 |
| 8 | 32 | FP32 | 94 | 209 | 366 | 2.22 | 3.89 |
| 128 | 1 | FP32 | 1234 | 3420 | 10313 | 2.77 | 8.35 |
| 128 | 4 | FP32 | 677 | 1260 | 3114 | 1.86 | 4.59 |
* Performance on FP16
| Batch Size | Beam Width | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 57 | 175 | 786 | 3.07 | 13.78 |
| 1 | 4 | FP16 | 55 | 169 | 766 | 3.07 | 13.92 |
| 1 | 32 | FP16 | 45 | 94 | 465 | 2.08 | 10.33 |
| 8 | 1 | FP16 | 226 | 683 | 4077 | 3.02 | 18.03 |
| 8 | 4 | FP16 | 217 | 631 | 3440 | 2.90 | 15.85 |
| 8 | 32 | FP16 | 151 | 259 | 619 | 1.71 | 4.09 |
| 128 | 1 | FP16 | 2060 | 4474 | 21675 | 2.17 | 10.52 |
| 128 | 4 | FP16 | 1250 | 1948 | 8796 | 1.55 | 7.03 |
#### Sampling performance on T4 and TensorFlow
* Performance on FP32
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP32 | 49 | 201 | 584 | 4.10 | 11.91 |
| 1 | 32 | FP32 | 50 | 175 | 568 | 3.50 | 11.36 |
| 1 | 0.75 | FP32 | 48 | 156 | 494 | 3.25 | 10.29 |
| 8 | 4 | FP32 | 226 | 791 | 2753 | 3.50 | 12.18 |
| 8 | 32 | FP32 | 230 | 859 | 2643 | 3.73 | 11.49 |
| 8 | 0.75 | FP32 | 230 | 706 | 2225 | 3.06 | 9.67 |
| 128 | 4 | FP32 | 1443 | 3729 | 8822 | 2.58 | 6.11 |
| 128 | 32 | FP32 | 1372 | 3396 | 8694 | 2.47 | 6.33 |
| 128 | 0.75 | FP32 | 1259 | 2640 | 7127 | 2.09 | 5.66 |
* Performance on FP16
| Batch Size | Topk/Topp | Precision | TF
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :-------: | :-------: | :-----------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 4 | FP16 | 70 | 211 | 765 | 3.01 | 10.92 |
| 1 | 32 | FP16 | 68 | 201 | 756 | 2.95 | 11.11 |
| 1 | 0.75 | FP16 | 65 | 163 | 658 | 2.50 | 10.12 |
| 8 | 4 | FP16 | 296 | 904 | 3821 | 3.05 | 12.90 |
| 8 | 32 | FP16 | 291 | 851 | 3929 | 2.92 | 13.50 |
| 8 | 0.75 | FP16 | 280 | 723 | 3168 | 2.58 | 11.31 |
| 128 | 4 | FP16 | 2649 | 4810 | 21185 | 1.81 | 7.99 |
| 128 | 32 | FP16 | 2337 | 4632 | 18966 | 1.98 | 8.11 |
| 128 | 0.75 | FP16 | 1937 | 3269 | 15599 | 1.68 | 8.05 |
### End-to-end translation performance on PyTorch
We demonstrate the throughput of PyTorch, FT Decoder and FT Decoding for end-to-end translation. Here, PyTorch means that the program fully runs on PyTorch. FT Decoder means that we replace the decoder transformer layer by FasterTransformer. FT Decoding means that we replace the whole procedure of decoder by FasterTransformer.
We also skip the BLEU score because the score of PyTorch, FT Decoder and FT Decoding are close.
Although the bleu scores of all methods are close, the results may be little different, and the number of generated tokens may be also different. So, we use throughput but not latency to show the performance in this benchmark.
This benchmark was obtained by running the `../sample/pytorch/scripts/profile_decoder_decoding.sh`.
In this benchmark, we updated the following parameters:
* head_num = 8 for both encoder and decoder
* size_per_head = 64 for both encoder and decoder
* num_layers = 6 for both encoder and decoder
* vocabulary_size = 31538
* max_seq_len = 128
#### Beamsearch performance on A100 and PyTorch
* Performance on FP32
User can use `export NVIDIA_TF32_OVERRIDE=0` to enforce the program run under FP32.
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 169 | 376 | 684 | 2.22 | 4.03 |
| 1 | 4 | FP32 | 152 | 423 | 855 | 2.76 | 5.59 |
| 1 | 32 | FP32 | 123 | 366 | 683 | 2.96 | 5.51 |
| 8 | 1 | FP32 | 666 | 1916 | 4301 | 2.87 | 6.45 |
| 8 | 4 | FP32 | 616 | 1822 | 3718 | 2.95 | 6.02 |
| 8 | 32 | FP32 | 431 | 771 | 1318 | 1.78 | 3.05 |
| 128 | 1 | FP32 | 5054 | 10847 | 18784 | 2.14 | 3.71 |
| 128 | 4 | FP32 | 2722 | 4217 | 8793 | 1.54 | 3.23 |
| 128 | 32 | FP32 | 412 | 564 | 1362 | 1.36 | 3.30 |
* Performance on FP16
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 160 | 561 | 1413 | 3.50 | 8.81 |
| 1 | 4 | FP16 | 135 | 504 | 1275 | 3.71 | 9.40 |
| 1 | 32 | FP16 | 119 | 426 | 947 | 3.55 | 7.90 |
| 8 | 1 | FP16 | 666 | 2437 | 6131 | 3.65 | 9.20 |
| 8 | 4 | FP16 | 589 | 2150 | 5217 | 3.64 | 8.84 |
| 8 | 32 | FP16 | 447 | 1111 | 2799 | 2.48 | 6.25 |
| 128 | 1 | FP16 | 5239 | 14783 | 33745 | 2.82 | 6.44 |
| 128 | 4 | FP16 | 3353 | 6459 | 23360 | 1.92 | 6.96 |
| 128 | 32 | FP16 | 529 | 901 | 3836 | 1.70 | 7.24 |
#### Beamsearch performance on V100 and PyTorch
* Perofrmance on FP32
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 92 | 277 | 699 | 3.00 | 7.56 |
| 1 | 4 | FP32 | 80 | 226 | 703 | 2.82 | 8.76 |
| 1 | 32 | FP32 | 69 | 217 | 471 | 3.12 | 6.76 |
| 8 | 1 | FP32 | 385 | 1232 | 3225 | 3.20 | 8.37 |
| 8 | 4 | FP32 | 352 | 1121 | 2756 | 3.18 | 7.81 |
| 8 | 32 | FP32 | 262 | 465 | 950 | 1.77 | 3.62 |
| 128 | 1 | FP32 | 2968 | 6213 | 12848 | 2.09 | 4.32 |
| 128 | 4 | FP32 | 1953 | 2447 | 6759 | 1.25 | 3.46 |
* Performance on FP16
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 78 | 267 | 967 | 3.40 | 12.39 |
| 1 | 4 | FP16 | 76 | 251 | 868 | 3.29 | 11.39 |
| 1 | 32 | FP16 | 70 | 217 | 635 | 3.10 | 9.07 |
| 8 | 1 | FP16 | 357 | 1242 | 4508 | 3.47 | 12.61 |
| 8 | 4 | FP16 | 336 | 886 | 3769 | 2.63 | 11.20 |
| 8 | 32 | FP16 | 265 | 575 | 1454 | 2.17 | 5.48 |
| 128 | 1 | FP16 | 3193 | 7396 | 19264 | 2.31 | 6.03 |
| 128 | 4 | FP16 | 2141 | 3141 | 12609 | 1.46 | 5.88 |
#### Beamsearch performance on T4 and PyTorch
* Perofrmance on FP32
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP32 | 62 | 179 | 566 | 2.85 | 8.99 |
| 1 | 4 | FP32 | 56 | 158 | 535 | 2.79 | 9.46 |
| 1 | 32 | FP32 | 47 | 144 | 312 | 3.06 | 6.62 |
| 8 | 1 | FP32 | 259 | 764 | 2418 | 2.94 | 9.30 |
| 8 | 4 | FP32 | 239 | 711 | 1914 | 2.97 | 7.99 |
| 8 | 32 | FP32 | 140 | 183 | 358 | 1.30 | 2.54 |
| 128 | 1 | FP32 | 1803 | 2885 | 6400 | 1.60 | 3.54 |
| 128 | 4 | FP32 | 690 | 836 | 2519 | 1.21 | 3.64 |
* Performance on FP16
| Batch Size | Beam Width | Precision | PyTorch
Throughput (token/sec) | FT Decoder
Throughput (token/sec) | FT Decoding
Throughput (token/sec) | FT Decoder
Speedup | FT Decoding
Speedup |
| :--------: | :--------: | :-------: | :----------------------------------: | :-------------------------------------: | :--------------------------------------: | :----------------------: | :-----------------------: |
| 1 | 1 | FP16 | 60 | 176 | 774 | 2.93 | 12.81 |
| 1 | 4 | FP16 | 55 | 170 | 699 | 3.08 | 12.68 |
| 1 | 32 | FP16 | 46 | 147 | 468 | 3.17 | 10.06 |
| 8 | 1 | FP16 | 254 | 832 | 3389 | 3.27 | 13.32 |
| 8 | 4 | FP16 | 237 | 759 | 2981 | 3.19 | 12.53 |
| 8 | 32 | FP16 | 164 | 256 | 636 | 1.56 | 3.87 |
| 128 | 1 | FP16 | 2035 | 4000 | 10836 | 1.96 | 5.32 |
| 128 | 4 | FP16 | 977 | 1192 | 6369 | 1.21 | 6.51 |