# T5 MODEL
## Table of contents
- [1. Training Setup](#1-training-setup)
- [2. Configurations](#2-configurations)
- [3. Training Results](#3-training-results)
## 1. Training setup
To run the model on a Slurm based cluster
```
PYTORCH_IMAGE=nvcr.io/nvidia/pytorch:23.09-py3
ACCOUNT_NAME=""
PARTITION=""
JOB_NAME=""
NUM_NODES=1
CHECKPOINT_PATH="" #
TENSORBOARD_LOGS_PATH=""#
VOCAB_FILE="" #/bert-large-cased-vocab.txt
DATA_PATH="" #_text_document
srun -N $NUM_NODES --container-image $PYTORCH_IMAGE --container-mounts "/path/to/data:/path/to/data,/path/to/megatron-lm:/workspace/megatron-lm" --account $ACCOUNT -N 1 -J $JOB_NAME -p $PARTITION --no-container-mount-home -c "
cd /workspace/megatron-lm
./examples/t5/train_t5_220m_distributed.sh $CHECKPOINT_PATH $TENSORBOARD_LOGS_PATH $VOCAB_FILE $DATA_PATH"
```
## 2. Configurations
The architecture arguments below shows configuration for T5 220M model.
### 220M
```
--num-layers 12 \
--hidden-size 768 \
--num-attention-heads 12 \
--kv-channels 64 \
--ffn-hidden-size 3072 \
--encoder-seq-length 512 \
--decoder-seq-length 128 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
```
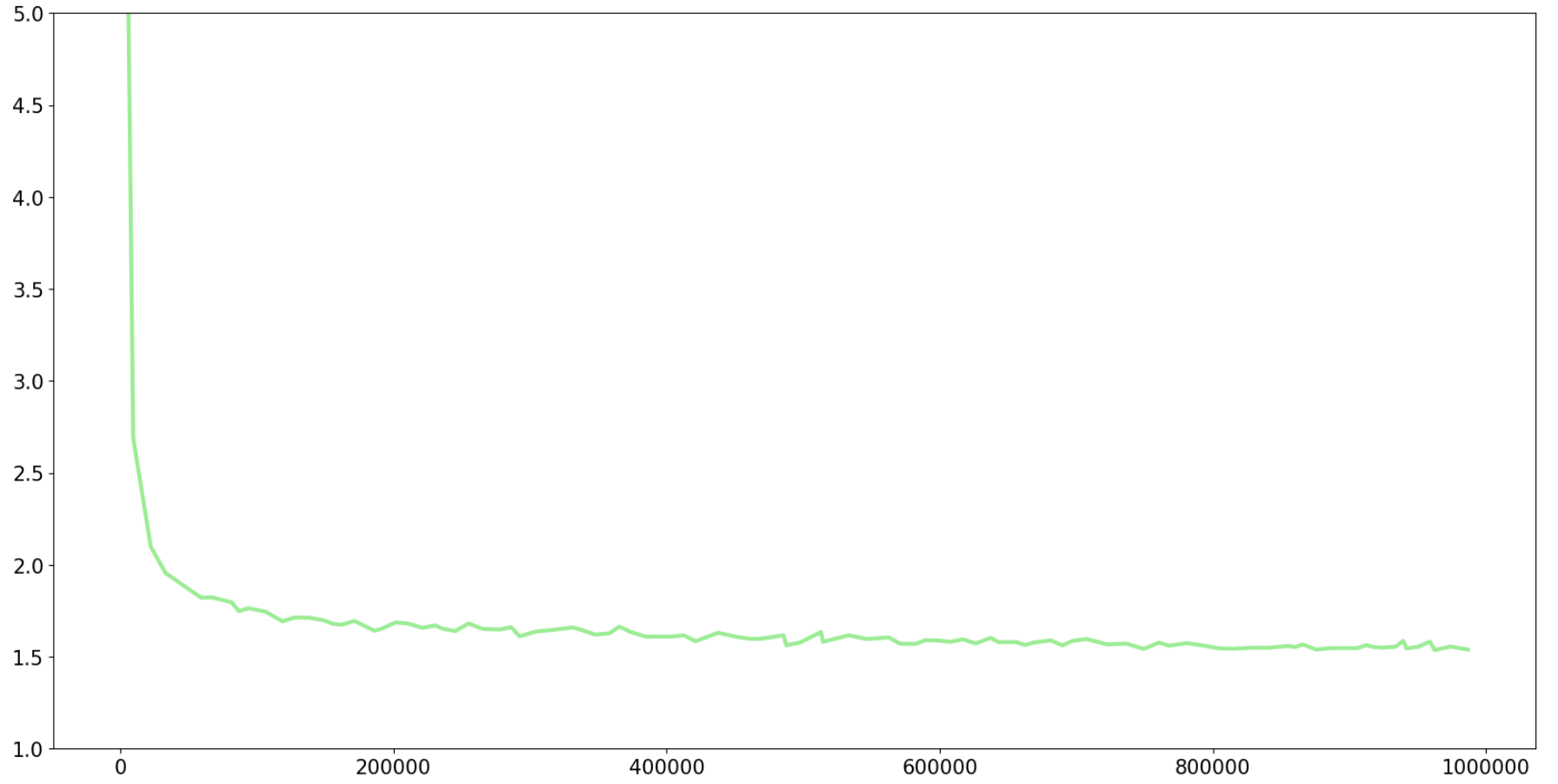
## 3. Training Results
Below is the training curve for the 220M model on Pile dataset. The training takes 4 days on 32 GPUs, with batch size of 2048.
Finetuning on SQUAD dataset, the validation result is: 63.44\%