# H200 achieves nearly 12,000 tokens/sec on Llama2-13B with TensorRT-LLM
TensorRT-LLM evaluation of the [new H200 GPU](https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform) achieves **11,819 tokens/s on Llama2-13B** on a single GPU. H200 is up to **1.9x faster** than H100. This performance is enabled by H200's larger, faster [HBM3e memory](#latest-hbm-memory).
**H200 FP8 Max throughput**
|Model | Batch Size(1) | TP(2) | Input Length | Output Length | Throughput (out tok/s) |
|:----------|:-------------------------|:-----------------|:-------------|:--------------|-----------------------:|
| llama_13b | 1024 | 1 | 128 | 128 | 11,819 |
| llama_13b | 128 | 1 | 128 | 2048 | 4,750 |
| llama_13b | 64 | 1 | 2048 | 128 | 1,349 |
| llama_70b | 512 | 1 | 128 | 128 | 3,014 |
| llama_70b | 512 | 4 | 128 | 2048 | 6,616 |
| llama_70b | 64 | 2 | 2048 | 128 | 682 |
| llama_70b | 32 | 1 | 2048 | 128 | 303 |
Preliminary measured performance, subject to change. TensorRT-LLM v0.5.0, TensorRT v9.1.0.4 | H200, H100 FP8.
*(1) Largest batch supported on given TP configuration by power of 2.* *(2) TP = Tensor Parallelism*
Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html).
### H200 vs H100
H200's HBM3e larger capacity & faster memory enables up to **1.9x** performance on LLMs compared to H100. Max throughput improves due to its dependence on memory capacity and bandwidth, benefitting from the new HBM3e. First token latency is compute bound for most ISLs, meaning H200 retains similar time to first token as H100.
For practical examples of H200's performance:
**Max Throughput TP1:**
an offline summarization scenario (ISL/OSL=2048/128) with Llama-70B on a single H200 is 1.9x more performant than H100.
**Max Throughput TP8:**
an online chat agent scenario (ISL/OSL=80/200) with GPT3-175B on a full HGX (TP8) H200 is 1.6x more performant than H100.
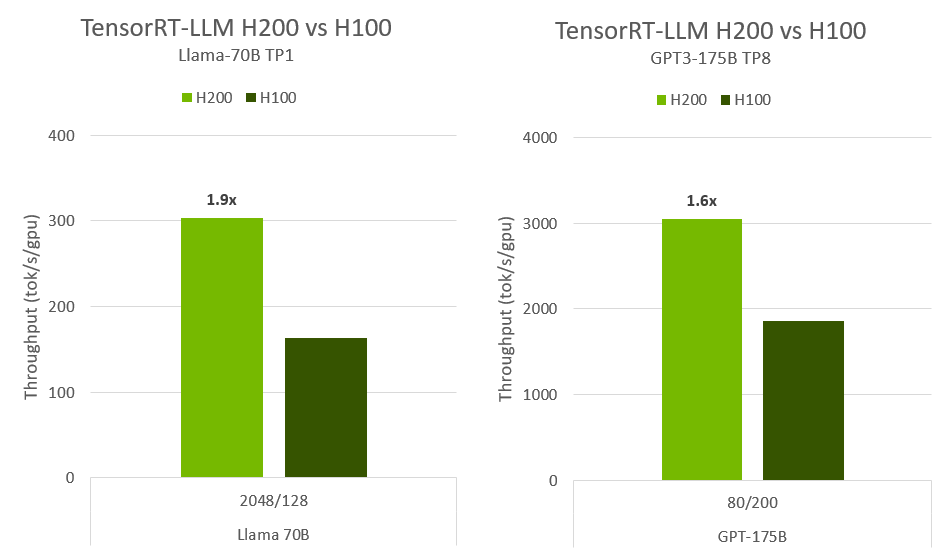 Preliminary measured performance, subject to change.
TensorRT-LLM v0.5.0, TensorRT v9.1.0.4. | Llama-70B: H100 FP8 BS 8, H200 FP8 BS 32 | GPT3-175B: H100 FP8 BS 64, H200 FP8 BS 128
**Max Throughput across TP/BS:**
Max throughput(3) on H200 vs H100 varies by model, sequence lengths, BS, and TP. Below results shown for maximum throughput per GPU across all these variables.
Preliminary measured performance, subject to change.
TensorRT-LLM v0.5.0, TensorRT v9.1.0.4. | Llama-70B: H100 FP8 BS 8, H200 FP8 BS 32 | GPT3-175B: H100 FP8 BS 64, H200 FP8 BS 128
**Max Throughput across TP/BS:**
Max throughput(3) on H200 vs H100 varies by model, sequence lengths, BS, and TP. Below results shown for maximum throughput per GPU across all these variables.
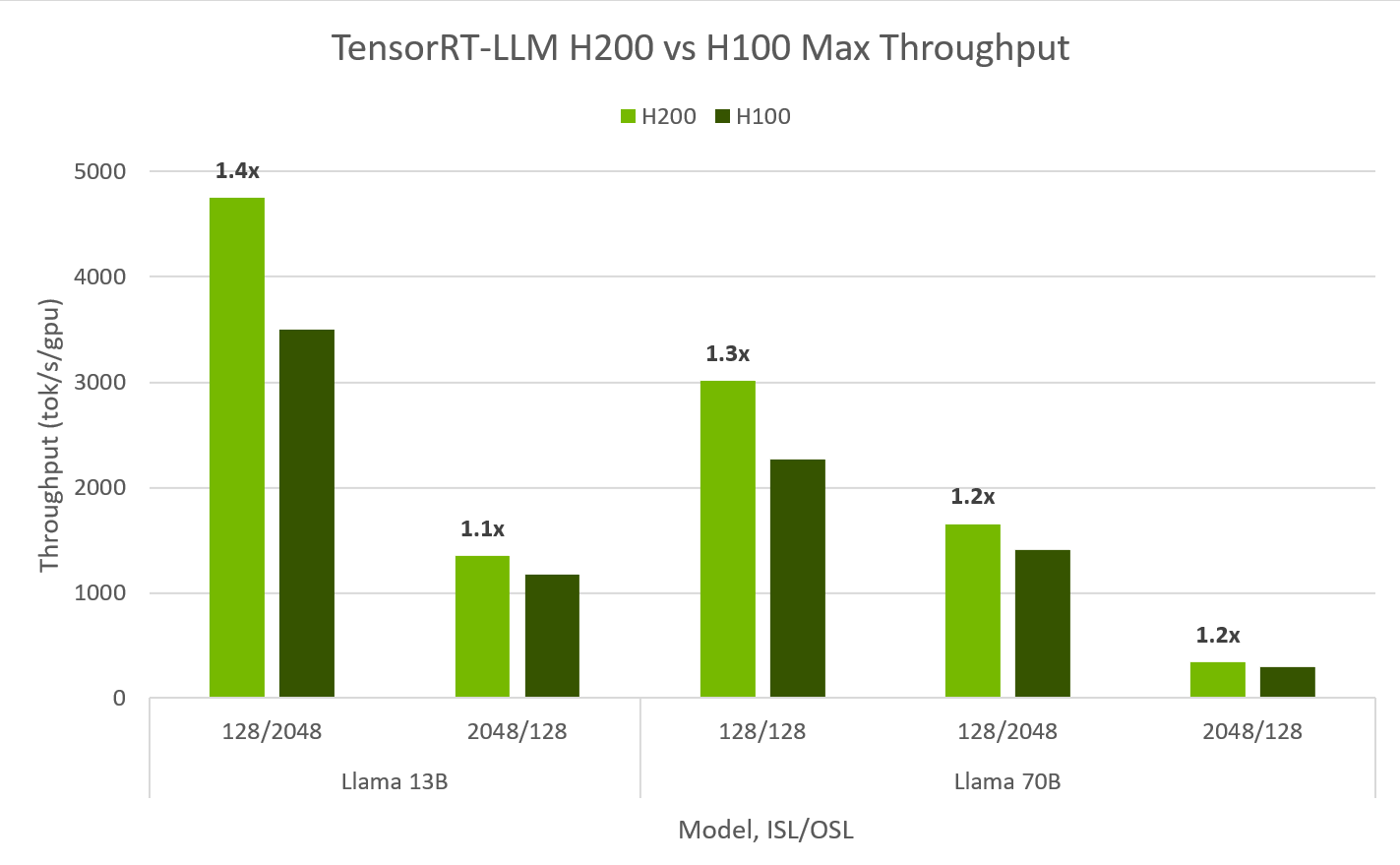 Preliminary measured performance, subject to change.
TensorRT-LLM v0.5.0, TensorRT v9.1.0.4 | H200, H100 FP8.
*(3) Max Throughput per GPU is defined as the highest tok/s per GPU, swept across TP configurations & BS powers of 2.*
### Latest HBM Memory
H200 is the newest addition to NVIDIA’s data center GPU portfolio. To maximize that compute performance, H200 is the first GPU with HBM3e memory with 4.8TB/s of memory bandwidth, a 1.4X increase over H100. H200 also expands GPU memory capacity nearly 2X to 141 gigabytes (GB). The combination of faster and larger HBM memory accelerates performance of LLM model inference performance with faster throughput and tokens per second. These results are measured and preliminary, more updates expected as optimizations for H200 continue with TensorRT-LLM.
Preliminary measured performance, subject to change.
TensorRT-LLM v0.5.0, TensorRT v9.1.0.4 | H200, H100 FP8.
*(3) Max Throughput per GPU is defined as the highest tok/s per GPU, swept across TP configurations & BS powers of 2.*
### Latest HBM Memory
H200 is the newest addition to NVIDIA’s data center GPU portfolio. To maximize that compute performance, H200 is the first GPU with HBM3e memory with 4.8TB/s of memory bandwidth, a 1.4X increase over H100. H200 also expands GPU memory capacity nearly 2X to 141 gigabytes (GB). The combination of faster and larger HBM memory accelerates performance of LLM model inference performance with faster throughput and tokens per second. These results are measured and preliminary, more updates expected as optimizations for H200 continue with TensorRT-LLM.