{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
},
"tags": []
},
"source": [
"# Using Python to solve Regexp CrossWord Puzzles\n",
"\n",
"Have a look at the amazing website.\n",
"\n",
"I played during about two hours, and could manually solve almost all problems, quite easily for most of them.\n",
"But then I got stucked on [this one](https://regexcrossword.com/challenges/volapuk/puzzles/5).\n",
"\n",
"Soooooo. I want to use [Python3](https://docs.python.org/3/) [regular expressions](https://docs.python.org/3/library/re.html) and try to solve any such cross-word puzzles.\n",
"\n",
"**Warning:** This notebook will *not* explain the concept and syntax of regular expressions, go read on about it on Wikipedia or in a good book. The Python documentation gives a nice introduction [here](https://docs.python.org/3/howto/regex.html#regex-howto).\n",
"\n",
"- Author: [Lilian Besson](https://besson.link) ([@Naereen](https://GitHub.com/Naereen)) ;\n",
"- License: [MIT License](https://lbesson.mit-license.org/) ;\n",
"- Date: 28-02-2021."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Representation of a problem\n",
"\n",
"Here is a screenshot from the game webpage.\n",
"\n",
"\n",
"\n",
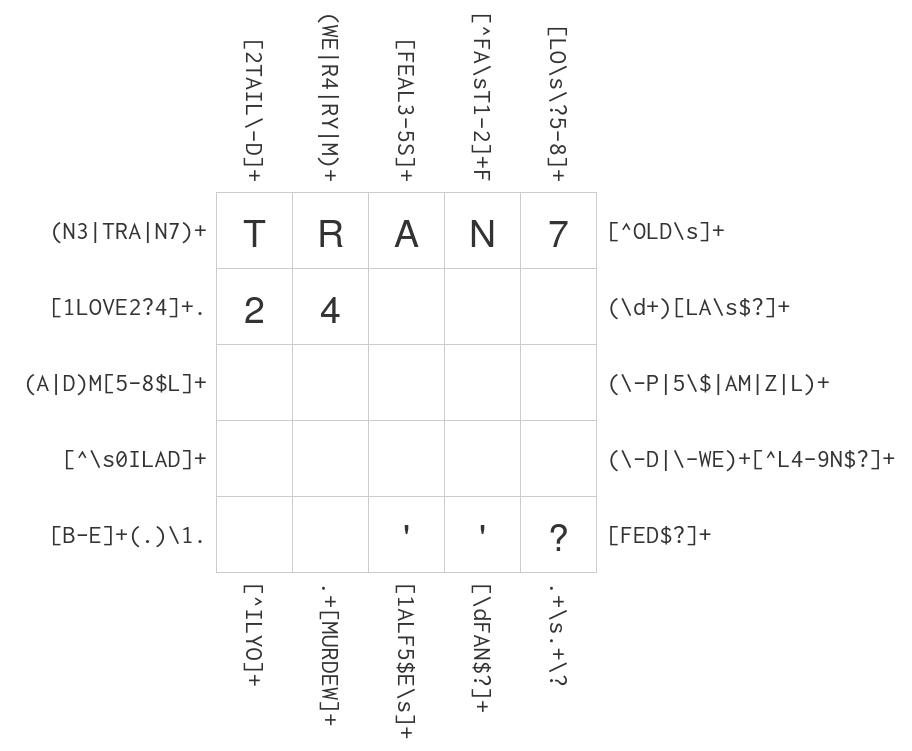
"As you can see, an instance of this game is determined by its rectangular size, let's denote it $(m, n)$, so here there are $m=5$ lines and $n=5$ columns.\n",
"\n",
"I'll also use this [easy problem](https://regexcrossword.com/challenges/beginner/puzzles/1):\n",
"\n",
"\n",
"\n",
"Let's define both, in a small dictionnary containing two to four lists of regexps."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Easy problem of size $(2,2)$ with four constraints"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.050325Z",
"start_time": "2021-03-04T13:49:22.046422Z"
}
},
"outputs": [],
"source": [
"problem1 = {\n",
" \"left_lines\": [\n",
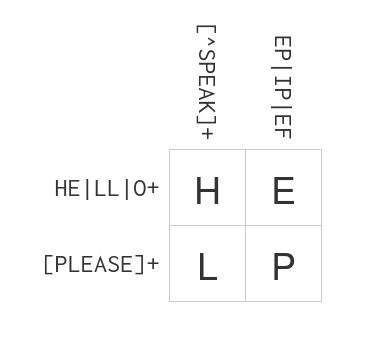
" r\"HE|LL|O+\", # HE|LL|O+ line 1\n",
" r\"[PLEASE]+\", # [PLEASE]+ line 2\n",
" ],\n",
" \"right_lines\": None,\n",
" \"top_columns\": [\n",
" r\"[^SPEAK]+\", # [^SPEAK]+ column 1\n",
" r\"EP|IP|EF\", # EP|IP|EF column 2\n",
" ],\n",
" \"bottom_columns\": None,\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The keys `\"right_lines\"` and `\"bottom_columns\"` can be empty, as for easier problems there are no constraints on the right and bottom."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Each line and column (but not each square) contains a regular expression, on a common alphabet of letters and symbols.\n",
"Let's write $\\Sigma$ this alphabet, which in the most general case is $\\Sigma=\\{$ `A`, `B`, ..., `Z`, `0`, ..., `9`, `:`, `?`, `.`, `$`, `-`$\\}$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For the first beginner problem, the alphabet can be shorten:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.067164Z",
"start_time": "2021-03-04T13:49:22.059077Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"alphabet1 = \n",
"['A', 'E', 'F', 'H', 'I', 'K', 'L', 'O', 'P', 'S']\n"
]
}
],
"source": [
"alphabet1 = {\n",
" 'H', 'E', 'L', 'O',\n",
" 'P', 'L', 'E', 'A', 'S', 'E',\n",
" 'S', 'P', 'E', 'A', 'K',\n",
" 'E', 'P', 'I', 'P', 'I', 'F',\n",
"}\n",
"\n",
"print(f\"alphabet1 = \\n{sorted(alphabet1)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Difficult problem of size $(5,5)$ with 20 constraints"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Defining the [second problem](https://regexcrossword.com/challenges/volapuk/puzzles/5) is just a question of more copy-pasting:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.075280Z",
"start_time": "2021-03-04T13:49:22.070449Z"
}
},
"outputs": [],
"source": [
"problem2 = {\n",
" \"left_lines\": [\n",
" r\"(N3|TRA|N7)+\", # left line 1\n",
" r\"[1LOVE2?4]+.\", # left line 2\n",
" r\"(A|D)M[5-8$L]+\", # left line 3\n",
" r\"[^\\s0ILAD]+\", # left line 4\n",
" r\"[B-E]+(.)\\1.\", # left line 5\n",
" ],\n",
" \"right_lines\": [\n",
" r\"[^OLD\\s]+\", # right line 1\n",
" r\"(\\d+)[LA\\s$?]+\", # right line 2\n",
" r\"(\\-P|5\\$|AM|Z|L)+\", # right line 3\n",
" r\"(\\-D|\\-WE)+[^L4-9N$?]+\", # right line 4\n",
" r\"[FED$?]+\", # right line 5\n",
" ],\n",
" \"top_columns\": [\n",
" r\"[2TAIL\\-D]+\", # top column 1\n",
" r\"(WE|R4|RY|M)+\", # top column 2\n",
" r\"[FEAL3-5S]+\", # top column 3\n",
" r\"[^FA\\sT1-2]+F\", # top column 4\n",
" r\"[LO\\s\\?5-8]+\", # top column 5\n",
" ],\n",
" \"bottom_columns\": [\n",
" r\"[^ILYO]+\", # top column 1\n",
" r\".+[MURDEW]+\", # top column 2\n",
" r\"[1ALF5$E\\s]+\", # top column 3\n",
" r\"[\\dFAN$?]+\", # top column 4\n",
" r\".+\\s.+\\?\", # top column 5\n",
" ],\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And its alphabet:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.082081Z",
"start_time": "2021-03-04T13:49:22.079554Z"
}
},
"outputs": [],
"source": [
"import string"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.088253Z",
"start_time": "2021-03-04T13:49:22.084467Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"alphabet2 = \n",
"['$', '-', '.', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']\n"
]
}
],
"source": [
"alphabet2 = set(string.digits) \\\n",
" | set(string.ascii_uppercase) \\\n",
" | { ':', '?', '.', '$', '-' }\n",
"\n",
"print(f\"alphabet2 = \\n{sorted(alphabet2)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### An intermediate problem of size $(3,3)$ with 12 constraints"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Defining the [third problem](https://regexcrossword.com/challenges/doublecross/puzzles/3) is just a question of more copy-pasting:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.099437Z",
"start_time": "2021-03-04T13:49:22.094071Z"
}
},
"outputs": [],
"source": [
"problem3 = {\n",
" \"left_lines\": [\n",
" r\"[ONE]*[SKA]\", # left line 1\n",
" r\".*(RE|ER)\", # left line 2\n",
" r\"A+[TUB]*\", # left line 3\n",
" ],\n",
" \"right_lines\": [\n",
" r\".*(O|S)*\", # right line 1\n",
" r\"[^GOA]*\", # right line 2\n",
" r\"[STUPA]+\", # right line 3\n",
" ],\n",
" \"top_columns\": [\n",
" r\".*[GAF]*\", # top column 1\n",
" r\"(P|ET|O|TEA)*\", # top column 2\n",
" r\"[RUSH]+\", # top column 3\n",
" ],\n",
" \"bottom_columns\": [\n",
" r\"(NF|FA|A|FN)+\", # top column 1\n",
" r\".*(A|E|I).*\", # top column 2\n",
" r\"[SUPER]*\", # top column 3\n",
" ],\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And its alphabet:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.107311Z",
"start_time": "2021-03-04T13:49:22.101694Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"alphabet3 = \n",
"['A', 'B', 'E', 'F', 'G', 'H', 'I', 'K', 'N', 'O', 'P', 'R', 'S', 'T', 'U']\n"
]
}
],
"source": [
"alphabet3 = {\n",
" 'O', 'N', 'E', 'S', 'K', 'A',\n",
" 'R', 'E', 'E', 'R',\n",
" 'A', 'T', 'U', 'B',\n",
" \n",
" 'O', 'S',\n",
" 'G', 'O', 'A',\n",
" 'S', 'T', 'U', 'P', 'A',\n",
" \n",
" 'G', 'A', 'F',\n",
" 'P', 'E', 'T', 'O', 'T', 'E', 'A',\n",
" 'R', 'U', 'S', 'H',\n",
"\n",
" 'N', 'F', 'F', 'A', 'A', 'F', 'N',\n",
" 'A', 'E', 'I',\n",
" 'S', 'U', 'P', 'E', 'R',\n",
"}\n",
"\n",
"print(f\"alphabet3 = \\n{sorted(alphabet3)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### A few useful functions\n",
"\n",
"Let's first extract the dimension of a problem:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.119216Z",
"start_time": "2021-03-04T13:49:22.115131Z"
}
},
"outputs": [],
"source": [
"def dimension_problem(problem):\n",
" m = len(problem['left_lines'])\n",
" if problem['right_lines'] is not None:\n",
" assert m == len(problem['right_lines'])\n",
" n = len(problem['top_columns'])\n",
" if problem['bottom_columns'] is not None:\n",
" assert n == len(problem['bottom_columns'])\n",
" return (m, n)"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.126827Z",
"start_time": "2021-03-04T13:49:22.121308Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"{'left_lines': ['HE|LL|O+', '[PLEASE]+'],\n",
" 'right_lines': None,\n",
" 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'],\n",
" 'bottom_columns': None}"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"problem1"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.133929Z",
"start_time": "2021-03-04T13:49:22.129103Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"(2, 2)"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dimension_problem(problem1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's write a representation of a grid, a solution (or partial solution) of a problem:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.143110Z",
"start_time": "2021-03-04T13:49:22.140135Z"
}
},
"outputs": [],
"source": [
"___ = \"_\" # represents an empty answer, as _ is not in the alphabet\n",
"grid1_partial = [\n",
" [ 'H', ___ ],\n",
" [ ___, 'P' ],\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.147654Z",
"start_time": "2021-03-04T13:49:22.145124Z"
}
},
"outputs": [],
"source": [
"grid1_solution = [\n",
" [ 'H', 'E' ],\n",
" [ 'L', 'P' ],\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As well as a few complete grids which are NOT solutions"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.155886Z",
"start_time": "2021-03-04T13:49:22.153295Z"
}
},
"outputs": [],
"source": [
"grid1_wrong1 = [\n",
" [ 'H', 'E' ],\n",
" [ 'L', 'F' ],\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.162698Z",
"start_time": "2021-03-04T13:49:22.160030Z"
}
},
"outputs": [],
"source": [
"grid1_wrong2 = [\n",
" [ 'H', 'E' ],\n",
" [ 'E', 'P' ],\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.168090Z",
"start_time": "2021-03-04T13:49:22.165555Z"
}
},
"outputs": [],
"source": [
"grid1_wrong3 = [\n",
" [ 'H', 'E' ],\n",
" [ 'O', 'F' ],\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.172665Z",
"start_time": "2021-03-04T13:49:22.170184Z"
}
},
"outputs": [],
"source": [
"grid1_wrong4 = [\n",
" [ 'O', 'E' ],\n",
" [ 'O', 'F' ],\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We also write these short functions to extract the $i$-th line or $j$-th column:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.180194Z",
"start_time": "2021-03-04T13:49:22.176726Z"
}
},
"outputs": [],
"source": [
"def nth_line(grid, line):\n",
" return \"\".join(grid[line])\n",
"\n",
"def nth_column(grid, column):\n",
" return \"\".join(grid[line][column] for line in range(len(grid)))"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.186497Z",
"start_time": "2021-03-04T13:49:22.182421Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['HE', 'LP']"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[ nth_line(grid1_solution, line) for line in range(len(grid1_solution)) ]"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.192689Z",
"start_time": "2021-03-04T13:49:22.188612Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['HL', 'EP']"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[ nth_column(grid1_solution, column) for column in range(len(grid1_solution[0])) ]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A partial solution for the intermediate problem:"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.198204Z",
"start_time": "2021-03-04T13:49:22.194654Z"
}
},
"outputs": [],
"source": [
"___ = \"_\" # represents an empty answer, as _ is not in the alphabet\n",
"grid3_solution = [\n",
" [ 'N', 'O', 'S' ],\n",
" [ 'F', 'E', 'R' ],\n",
" [ 'A', 'T', 'U' ],\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And a partial solution for the harder problem:"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.206430Z",
"start_time": "2021-03-04T13:49:22.201541Z"
}
},
"outputs": [],
"source": [
"___ = \"_\" # represents an empty answer, as _ is not in the alphabet\n",
"grid2_partial = [\n",
" [ 'T', 'R', 'A', 'N', '7' ],\n",
" [ '2', '4', ___, ___, ' ' ],\n",
" [ 'A', ___, ___, ___, ___ ],\n",
" [ '-', ___, ___, ___, ___ ],\n",
" [ 'D', ___, ___, ___, '?' ],\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's extract the dimension of a grid, just to check it:"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.214029Z",
"start_time": "2021-03-04T13:49:22.209058Z"
}
},
"outputs": [],
"source": [
"def dimension_grid(grid):\n",
" m = len(grid)\n",
" n = len(grid[0])\n",
" assert all(n == len(grid[i]) for i in range(1, m))\n",
" return (m, n)"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.219697Z",
"start_time": "2021-03-04T13:49:22.216562Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Grid grid1_partial has dimension: (2, 2)\n",
"Grid grid1_solution has dimension: (2, 2)\n"
]
}
],
"source": [
"print(f\"Grid grid1_partial has dimension: {dimension_grid(grid1_partial)}\")\n",
"print(f\"Grid grid1_solution has dimension: {dimension_grid(grid1_solution)}\")"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.226557Z",
"start_time": "2021-03-04T13:49:22.223372Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Grid grid2_partial has dimension: (5, 5)\n"
]
}
],
"source": [
"print(f\"Grid grid2_partial has dimension: {dimension_grid(grid2_partial)}\")"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.232026Z",
"start_time": "2021-03-04T13:49:22.228895Z"
}
},
"outputs": [],
"source": [
"def check_dimensions(problem, grid):\n",
" return dimension_problem(problem) == dimension_grid(grid)"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.237546Z",
"start_time": "2021-03-04T13:49:22.234487Z"
}
},
"outputs": [],
"source": [
"assert check_dimensions(problem1, grid1_partial)\n",
"assert check_dimensions(problem1, grid1_solution)"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.242333Z",
"start_time": "2021-03-04T13:49:22.239544Z"
}
},
"outputs": [],
"source": [
"assert not check_dimensions(problem2, grid1_partial)"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.248867Z",
"start_time": "2021-03-04T13:49:22.246403Z"
}
},
"outputs": [],
"source": [
"assert check_dimensions(problem2, grid2_partial)"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.253177Z",
"start_time": "2021-03-04T13:49:22.250869Z"
}
},
"outputs": [],
"source": [
"assert not check_dimensions(problem1, grid2_partial)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Two more checks\n",
"\n",
"We also have to check if a word is in an alphabet:"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.263302Z",
"start_time": "2021-03-04T13:49:22.259549Z"
}
},
"outputs": [],
"source": [
"def check_alphabet(alphabet, word, debug=True):\n",
" result = True\n",
" for i, letter in enumerate(word):\n",
" new_result = letter in alphabet\n",
" if debug and result and not new_result:\n",
" print(f\"The word {repr(word)} is not in alphabet {repr(alphabet)}, as its #{i}th letter {letter} is not present.\")\n",
" result = result and new_result\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.267399Z",
"start_time": "2021-03-04T13:49:22.265121Z"
}
},
"outputs": [],
"source": [
"assert check_alphabet(alphabet1, 'H' 'E') # concatenate the strings"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.276356Z",
"start_time": "2021-03-04T13:49:22.273525Z"
}
},
"outputs": [],
"source": [
"assert check_alphabet(alphabet1, 'H' 'E')\n",
"assert check_alphabet(alphabet1, 'L' 'P')\n",
"assert check_alphabet(alphabet1, 'H' 'L')\n",
"assert check_alphabet(alphabet1, 'E' 'P')"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.280611Z",
"start_time": "2021-03-04T13:49:22.278249Z"
}
},
"outputs": [],
"source": [
"assert check_alphabet(alphabet2, \"TRAN7\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And also check that a word matches a regexp:"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.286830Z",
"start_time": "2021-03-04T13:49:22.284569Z"
}
},
"outputs": [],
"source": [
"import re"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As the [documentation](https://docs.python.org/3/library/re.html#re.compile) explains it:\n",
"\n",
"> but using `prog = re.compile(regepx)` and saving the resulting regular expression object `prog` for reuse is more efficient when the expression will be used several times in a single program.\n",
"\n",
"I don't want to have to think about compiling a regexp before using it, so... I'm gonna memoize them!"
]
},
{
"cell_type": "code",
"execution_count": 42,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:50:22.132210Z",
"start_time": "2021-03-04T13:50:22.128605Z"
}
},
"outputs": [],
"source": [
"memory_of_compiled_regexps = dict()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we are ready to write our \"smart\" match function:"
]
},
{
"cell_type": "code",
"execution_count": 43,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:50:24.121435Z",
"start_time": "2021-03-04T13:50:24.112089Z"
}
},
"outputs": [],
"source": [
"def match(regexp, word, debug=True):\n",
" global memory_of_compiled_regexps\n",
" if regexp not in memory_of_compiled_regexps:\n",
" prog = re.compile(regexp)\n",
" memory_of_compiled_regexps[regexp] = prog\n",
" print(f\"For the first time seeing this regexp {repr(regexp)}, compiling it and storing in memory_of_compiled_regexps, now of size {len(memory_of_compiled_regexps)}.\")\n",
" else:\n",
" prog = memory_of_compiled_regexps[regexp]\n",
" \n",
" result = re.fullmatch(regexp, word)\n",
" result = prog.fullmatch(word)\n",
"\n",
" entire_match = result is not None\n",
" # entire_match = result.group(0) == word\n",
" if debug:\n",
" if entire_match:\n",
" print(f\"The word {repr(word)} is matched by {repr(regexp)}\")\n",
" else:\n",
" print(f\"The word {repr(word)} is NOT matched by {repr(regexp)}\")\n",
" return entire_match"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's compare the time of the first match and next ones:"
]
},
{
"cell_type": "code",
"execution_count": 44,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:50:36.806089Z",
"start_time": "2021-03-04T13:50:36.800602Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For the first time seeing this regexp '(N3|TRA|N7)+', compiling it and storing in memory_of_compiled_regexps, now of size 1.\n",
"The word 'TRAN7' is matched by '(N3|TRA|N7)+'\n",
"CPU times: user 238 µs, sys: 0 ns, total: 238 µs\n",
"Wall time: 173 µs\n"
]
},
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 44,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"%%time\n",
"match(r\"(N3|TRA|N7)+\", \"TRAN7\")"
]
},
{
"cell_type": "code",
"execution_count": 45,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:50:41.125495Z",
"start_time": "2021-03-04T13:50:41.116688Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The word 'TRAN8' is NOT matched by '(N3|TRA|N7)+'\n",
"CPU times: user 176 µs, sys: 71 µs, total: 247 µs\n",
"Wall time: 169 µs\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 45,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"%%time\n",
"match(r\"(N3|TRA|N7)+\", \"TRAN8\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Well of course it's not different for tiny test like this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.473244Z",
"start_time": "2021-03-04T13:49:22.310Z"
}
},
"outputs": [],
"source": [
"match(r\"(N3|TRA|N7)+\", \"\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:49:22.474431Z",
"start_time": "2021-03-04T13:49:22.315Z"
}
},
"outputs": [],
"source": [
"match(r\"(N3|TRA|N7)+\", \"TRA\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That should be enough to start the first \"easy\" task."
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:51:43.127920Z",
"start_time": "2021-03-04T13:51:28.920580Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1.14 µs ± 15.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)\n",
"603 ns ± 7.87 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)\n"
]
}
],
"source": [
"%timeit match(r\"(N3|TRA|N7)+\", \"TRA\", debug=False)\n",
"\n",
"%timeit re.fullmatch(r\"(N3|TRA|N7)+\", \"TRA\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can see that our \"memoization trick\" indeed helped to speed-up the time required to check a regexp, by about a factor 2, even for very small tests like this."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## First easy task: check that a line/column word validate its contraints\n",
"\n",
"Given a problem $P$ of dimension $(m, n)$, its alphabet $\\Sigma$, a position $i \\in [| 0, m-1 |]$ of a line or $j \\times [|0, n-1 |]$ of a column, and a word $w \\in \\Sigma^k$ (with $k=m$ for line or $k=n$ for column), I want to write a function that checks the validity of each (left/right) line, or (top/bottom) constraints.\n",
"\n",
"To ease debugging, and in the goal of using this Python program to improve my skills in solving such puzzles, I don't want this function to just reply `True` or `False`, but to also print for each constraints if it is satisfied or not.\n",
"\n",
"**Bonus:** for each regexp contraint, highlight the parts which corresponded to each letter of the word?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For lines"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are ready to check the one or two constraints of a line.\n",
"The same function will be written for columns, just below."
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:01.040332Z",
"start_time": "2021-03-04T13:52:01.030692Z"
}
},
"outputs": [],
"source": [
"def check_line(problem, alphabet, word, position, debug=True, early=False):\n",
" if not check_alphabet(alphabet, word, debug=debug):\n",
" return False\n",
" m, n = dimension_problem(problem)\n",
" if len(word) != n:\n",
" if debug:\n",
" print(f\"Word {repr(word)} does not have correct size n = {n} for lines\")\n",
" return False\n",
" assert 0 <= position < m\n",
" constraints = []\n",
" if \"left_lines\" in problem and problem[\"left_lines\"] is not None:\n",
" constraints += [ problem[\"left_lines\"][position] ]\n",
" if \"right_lines\" in problem and problem[\"right_lines\"] is not None:\n",
" constraints += [ problem[\"right_lines\"][position] ]\n",
" # okay we have one or two constraint for this line,\n",
" assert len(constraints) in {1, 2}\n",
" # let's check them!\n",
" result = True\n",
" for cnb, constraint in enumerate(constraints):\n",
" if debug:\n",
" print(f\"For line constraint #{cnb} {repr(constraint)}:\")\n",
" new_result = match(constraint, word, debug=debug)\n",
" if early and not new_result: return False\n",
" result = result and new_result\n",
" return result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's try it!"
]
},
{
"cell_type": "code",
"execution_count": 49,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:01.582177Z",
"start_time": "2021-03-04T13:52:01.575753Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"({'left_lines': ['HE|LL|O+', '[PLEASE]+'],\n",
" 'right_lines': None,\n",
" 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'],\n",
" 'bottom_columns': None},\n",
" {'A', 'E', 'F', 'H', 'I', 'K', 'L', 'O', 'P', 'S'},\n",
" [['H', 'E'], ['L', 'P']])"
]
},
"execution_count": 49,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"problem1, alphabet1, grid1_solution"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:01.795061Z",
"start_time": "2021-03-04T13:52:01.787542Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For line number 0, checking word 'HE':\n",
"For line constraint #0 'HE|LL|O+':\n",
"For the first time seeing this regexp 'HE|LL|O+', compiling it and storing in memory_of_compiled_regexps, now of size 2.\n",
"The word 'HE' is matched by 'HE|LL|O+'\n",
"- For line number 1, checking word 'LP':\n",
"For line constraint #0 '[PLEASE]+':\n",
"For the first time seeing this regexp '[PLEASE]+', compiling it and storing in memory_of_compiled_regexps, now of size 3.\n",
"The word 'LP' is matched by '[PLEASE]+'\n"
]
}
],
"source": [
"n, m = dimension_problem(problem1)\n",
"\n",
"for line in range(n):\n",
" word = nth_line(grid1_solution, line)\n",
" print(f\"- For line number {line}, checking word {repr(word)}:\")\n",
" result = check_line(problem1, alphabet1, word, line)"
]
},
{
"cell_type": "code",
"execution_count": 51,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:02.006862Z",
"start_time": "2021-03-04T13:52:01.994228Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"# For word 'OK':\n",
"For line constraint #0 'HE|LL|O+':\n",
"The word 'OK' is NOT matched by 'HE|LL|O+'\n",
" => False\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'OK' is NOT matched by '[PLEASE]+'\n",
" => False\n",
"# For word 'HEY':\n",
"The word 'HEY' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #2th letter Y is not present.\n",
" => False\n",
"The word 'HEY' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #2th letter Y is not present.\n",
" => False\n",
"# For word 'NOT':\n",
"The word 'NOT' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"The word 'NOT' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"# For word 'HELL':\n",
"Word 'HELL' does not have correct size n = 2 for lines\n",
" => False\n",
"Word 'HELL' does not have correct size n = 2 for lines\n",
" => False\n",
"# For word 'N':\n",
"The word 'N' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"The word 'N' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"# For word '':\n",
"Word '' does not have correct size n = 2 for lines\n",
" => False\n",
"Word '' does not have correct size n = 2 for lines\n",
" => False\n",
"# For word 'HU':\n",
"The word 'HU' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter U is not present.\n",
" => False\n",
"The word 'HU' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter U is not present.\n",
" => False\n",
"# For word 'OO':\n",
"For line constraint #0 'HE|LL|O+':\n",
"The word 'OO' is matched by 'HE|LL|O+'\n",
" => True\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'OO' is NOT matched by '[PLEASE]+'\n",
" => False\n",
"# For word 'EA':\n",
"For line constraint #0 'HE|LL|O+':\n",
"The word 'EA' is NOT matched by 'HE|LL|O+'\n",
" => False\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'EA' is matched by '[PLEASE]+'\n",
" => True\n"
]
}
],
"source": [
"n, m = dimension_problem(problem1)\n",
"fake_words = [\"OK\", \"HEY\", \"NOT\", \"HELL\", \"N\", \"\", \"HU\", \"OO\", \"EA\"]\n",
"\n",
"for word in fake_words:\n",
" print(f\"# For word {repr(word)}:\")\n",
" for line in range(n):\n",
" result = check_line(problem1, alphabet1, word, line)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That was long, but it works fine!"
]
},
{
"cell_type": "code",
"execution_count": 52,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:02.397647Z",
"start_time": "2021-03-04T13:52:02.387909Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For line number 0, checking word 'TRAN7':\n",
"For line constraint #0 '(N3|TRA|N7)+':\n",
"The word 'TRAN7' is matched by '(N3|TRA|N7)+'\n",
"For line constraint #1 '[^OLD\\\\s]+':\n",
"For the first time seeing this regexp '[^OLD\\\\s]+', compiling it and storing in memory_of_compiled_regexps, now of size 4.\n",
"The word 'TRAN7' is matched by '[^OLD\\\\s]+'\n",
" => True\n"
]
}
],
"source": [
"n, m = dimension_problem(problem2)\n",
"\n",
"for line in [0]:\n",
" word = nth_line(grid2_partial, line)\n",
" print(f\"- For line number {line}, checking word {repr(word)}:\")\n",
" result = check_line(problem2, alphabet2, word, line)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "code",
"execution_count": 53,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:02.575329Z",
"start_time": "2021-03-04T13:52:02.563686Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For line number 0, checking word 'TRAN8':\n",
"For line constraint #0 '(N3|TRA|N7)+':\n",
"The word 'TRAN8' is NOT matched by '(N3|TRA|N7)+'\n",
"For line constraint #1 '[^OLD\\\\s]+':\n",
"The word 'TRAN8' is matched by '[^OLD\\\\s]+'\n",
" => False\n",
"- For line number 0, checking word 'N2TRA':\n",
"For line constraint #0 '(N3|TRA|N7)+':\n",
"The word 'N2TRA' is NOT matched by '(N3|TRA|N7)+'\n",
"For line constraint #1 '[^OLD\\\\s]+':\n",
"The word 'N2TRA' is matched by '[^OLD\\\\s]+'\n",
" => False\n",
"- For line number 0, checking word 'N3N3N7':\n",
"Word 'N3N3N7' does not have correct size n = 5 for lines\n",
" => False\n",
"- For line number 0, checking word 'N3N3':\n",
"Word 'N3N3' does not have correct size n = 5 for lines\n",
" => False\n",
"- For line number 0, checking word 'TRA9':\n",
"Word 'TRA9' does not have correct size n = 5 for lines\n",
" => False\n",
"- For line number 0, checking word 'O L D':\n",
"The word 'O L D' is not in alphabet {'Z', 'E', 'I', 'V', 'R', 'A', 'F', 'D', 'Q', '3', 'Y', 'L', '4', 'W', '$', '5', 'M', 'B', 'N', '2', '8', '1', 'T', 'X', 'H', '-', 'S', '?', 'G', '9', 'U', 'P', '7', 'O', '.', 'C', 'J', 'K', '0', '6', ':'}, as its #1th letter is not present.\n",
" => False\n",
"- For line number 0, checking word 'TRA ':\n",
"The word 'TRA ' is not in alphabet {'Z', 'E', 'I', 'V', 'R', 'A', 'F', 'D', 'Q', '3', 'Y', 'L', '4', 'W', '$', '5', 'M', 'B', 'N', '2', '8', '1', 'T', 'X', 'H', '-', 'S', '?', 'G', '9', 'U', 'P', '7', 'O', '.', 'C', 'J', 'K', '0', '6', ':'}, as its #3th letter is not present.\n",
" => False\n"
]
}
],
"source": [
"n, m = dimension_problem(problem2)\n",
"fake_words = [\n",
" \"TRAN8\", \"N2TRA\", # violate first constraint\n",
" \"N3N3N7\", \"N3N3\", \"TRA9\", # smaller or bigger dimension\n",
" \"O L D\", \"TRA \", # violate second contraint\n",
"]\n",
"\n",
"for word in fake_words:\n",
" for line in [0]:\n",
" print(f\"- For line number {line}, checking word {repr(word)}:\")\n",
" result = check_line(problem2, alphabet2, word, line)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For columns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are ready to check the one or two constraints of a line.\n",
"The same function will be written for columns, just below."
]
},
{
"cell_type": "code",
"execution_count": 54,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:03.173298Z",
"start_time": "2021-03-04T13:52:03.165492Z"
}
},
"outputs": [],
"source": [
"def check_column(problem, alphabet, word, position, debug=True, early=False):\n",
" if not check_alphabet(alphabet, word, debug=debug):\n",
" return False\n",
" m, n = dimension_problem(problem)\n",
" if len(word) != m:\n",
" if debug:\n",
" print(f\"Word {repr(word)} does not have correct size n = {n} for columns\")\n",
" return False\n",
" assert 0 <= position < n\n",
" constraints = []\n",
" if \"top_columns\" in problem and problem[\"top_columns\"] is not None:\n",
" constraints += [ problem[\"top_columns\"][position] ]\n",
" if \"bottom_columns\" in problem and problem[\"bottom_columns\"] is not None:\n",
" constraints += [ problem[\"bottom_columns\"][position] ]\n",
" # okay we have one or two constraint for this column,\n",
" assert len(constraints) in {1, 2}\n",
" # let's check them!\n",
" result = True\n",
" for cnb, constraint in enumerate(constraints):\n",
" if debug:\n",
" print(f\"For column constraint #{cnb} {repr(constraint)}:\")\n",
" new_result = match(constraint, word, debug=debug)\n",
" if early and not new_result: return False\n",
" result = result and new_result\n",
" return result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's try it!"
]
},
{
"cell_type": "code",
"execution_count": 55,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:03.619768Z",
"start_time": "2021-03-04T13:52:03.615803Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"({'left_lines': ['HE|LL|O+', '[PLEASE]+'],\n",
" 'right_lines': None,\n",
" 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'],\n",
" 'bottom_columns': None},\n",
" {'A', 'E', 'F', 'H', 'I', 'K', 'L', 'O', 'P', 'S'},\n",
" [['H', 'E'], ['L', 'P']])"
]
},
"execution_count": 55,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"problem1, alphabet1, grid1_solution"
]
},
{
"cell_type": "code",
"execution_count": 56,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:04.368338Z",
"start_time": "2021-03-04T13:52:04.353500Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For column number 0, checking word 'HL':\n",
"For column constraint #0 '[^SPEAK]+':\n",
"For the first time seeing this regexp '[^SPEAK]+', compiling it and storing in memory_of_compiled_regexps, now of size 5.\n",
"The word 'HL' is matched by '[^SPEAK]+'\n",
"- For column number 1, checking word 'EP':\n",
"For column constraint #0 'EP|IP|EF':\n",
"For the first time seeing this regexp 'EP|IP|EF', compiling it and storing in memory_of_compiled_regexps, now of size 6.\n",
"The word 'EP' is matched by 'EP|IP|EF'\n"
]
}
],
"source": [
"n, m = dimension_problem(problem1)\n",
"\n",
"for column in range(m):\n",
" word = nth_column(grid1_solution, column)\n",
" print(f\"- For column number {column}, checking word {repr(word)}:\")\n",
" result = check_column(problem1, alphabet1, word, column)"
]
},
{
"cell_type": "code",
"execution_count": 57,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:04.562128Z",
"start_time": "2021-03-04T13:52:04.552948Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"# For word 'OK':\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'OK' is NOT matched by '[^SPEAK]+'\n",
" => False\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'OK' is NOT matched by 'EP|IP|EF'\n",
" => False\n",
"# For word 'HEY':\n",
"The word 'HEY' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #2th letter Y is not present.\n",
" => False\n",
"The word 'HEY' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #2th letter Y is not present.\n",
" => False\n",
"# For word 'NOT':\n",
"The word 'NOT' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"The word 'NOT' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"# For word 'HELL':\n",
"Word 'HELL' does not have correct size n = 2 for columns\n",
" => False\n",
"Word 'HELL' does not have correct size n = 2 for columns\n",
" => False\n",
"# For word 'N':\n",
"The word 'N' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"The word 'N' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter N is not present.\n",
" => False\n",
"# For word '':\n",
"Word '' does not have correct size n = 2 for columns\n",
" => False\n",
"Word '' does not have correct size n = 2 for columns\n",
" => False\n",
"# For word 'HU':\n",
"The word 'HU' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter U is not present.\n",
" => False\n",
"The word 'HU' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter U is not present.\n",
" => False\n",
"# For word 'OO':\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'OO' is matched by '[^SPEAK]+'\n",
" => True\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'OO' is NOT matched by 'EP|IP|EF'\n",
" => False\n",
"# For word 'EA':\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'EA' is NOT matched by '[^SPEAK]+'\n",
" => False\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EA' is NOT matched by 'EP|IP|EF'\n",
" => False\n"
]
}
],
"source": [
"n, m = dimension_problem(problem1)\n",
"fake_words = [\"OK\", \"HEY\", \"NOT\", \"HELL\", \"N\", \"\", \"HU\", \"OO\", \"EA\"]\n",
"\n",
"for word in fake_words:\n",
" print(f\"# For word {repr(word)}:\")\n",
" for column in range(m):\n",
" result = check_column(problem1, alphabet1, word, column)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That was long, but it works fine!"
]
},
{
"cell_type": "code",
"execution_count": 58,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:04.994447Z",
"start_time": "2021-03-04T13:52:04.986422Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For column number 0, checking word 'T2A-D':\n",
"For column constraint #0 '[2TAIL\\\\-D]+':\n",
"For the first time seeing this regexp '[2TAIL\\\\-D]+', compiling it and storing in memory_of_compiled_regexps, now of size 7.\n",
"The word 'T2A-D' is matched by '[2TAIL\\\\-D]+'\n",
"For column constraint #1 '[^ILYO]+':\n",
"For the first time seeing this regexp '[^ILYO]+', compiling it and storing in memory_of_compiled_regexps, now of size 8.\n",
"The word 'T2A-D' is matched by '[^ILYO]+'\n",
" => True\n"
]
}
],
"source": [
"n, m = dimension_problem(problem2)\n",
"\n",
"for column in [0]:\n",
" word = nth_column(grid2_partial, column)\n",
" print(f\"- For column number {column}, checking word {repr(word)}:\")\n",
" result = check_column(problem2, alphabet2, word, column)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "code",
"execution_count": 59,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:05.230532Z",
"start_time": "2021-03-04T13:52:05.219692Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- For line number 0, checking word 'TRAN8':\n",
"For column constraint #0 '[2TAIL\\\\-D]+':\n",
"The word 'TRAN8' is NOT matched by '[2TAIL\\\\-D]+'\n",
"For column constraint #1 '[^ILYO]+':\n",
"The word 'TRAN8' is matched by '[^ILYO]+'\n",
" => False\n",
"- For line number 0, checking word 'N2TRA':\n",
"For column constraint #0 '[2TAIL\\\\-D]+':\n",
"The word 'N2TRA' is NOT matched by '[2TAIL\\\\-D]+'\n",
"For column constraint #1 '[^ILYO]+':\n",
"The word 'N2TRA' is matched by '[^ILYO]+'\n",
" => False\n",
"- For line number 0, checking word 'N3N3N7':\n",
"Word 'N3N3N7' does not have correct size n = 5 for columns\n",
" => False\n",
"- For line number 0, checking word 'N3N3':\n",
"Word 'N3N3' does not have correct size n = 5 for columns\n",
" => False\n",
"- For line number 0, checking word 'TRA9':\n",
"Word 'TRA9' does not have correct size n = 5 for columns\n",
" => False\n",
"- For line number 0, checking word 'O L D':\n",
"The word 'O L D' is not in alphabet {'Z', 'E', 'I', 'V', 'R', 'A', 'F', 'D', 'Q', '3', 'Y', 'L', '4', 'W', '$', '5', 'M', 'B', 'N', '2', '8', '1', 'T', 'X', 'H', '-', 'S', '?', 'G', '9', 'U', 'P', '7', 'O', '.', 'C', 'J', 'K', '0', '6', ':'}, as its #1th letter is not present.\n",
" => False\n",
"- For line number 0, checking word 'TRA ':\n",
"The word 'TRA ' is not in alphabet {'Z', 'E', 'I', 'V', 'R', 'A', 'F', 'D', 'Q', '3', 'Y', 'L', '4', 'W', '$', '5', 'M', 'B', 'N', '2', '8', '1', 'T', 'X', 'H', '-', 'S', '?', 'G', '9', 'U', 'P', '7', 'O', '.', 'C', 'J', 'K', '0', '6', ':'}, as its #3th letter is not present.\n",
" => False\n"
]
}
],
"source": [
"n, m = dimension_problem(problem2)\n",
"fake_words = [\n",
" \"TRAN8\", \"N2TRA\", # violate first constraint\n",
" \"N3N3N7\", \"N3N3\", \"TRA9\", # smaller or bigger dimension\n",
" \"O L D\", \"TRA \", # violate second contraint\n",
"]\n",
"\n",
"for word in fake_words:\n",
" for line in [0]:\n",
" print(f\"- For line number {line}, checking word {repr(word)}:\")\n",
" result = check_column(problem2, alphabet2, word, line)\n",
" print(f\" => {result}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Second easy task: check that a proposed grid is a valid solution\n",
"\n",
"I think it's easy, as we just have to use $m$ times the `check_line` and $n$ times the `check_column` functions."
]
},
{
"cell_type": "code",
"execution_count": 60,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:05.718771Z",
"start_time": "2021-03-04T13:52:05.711229Z"
}
},
"outputs": [],
"source": [
"def check_grid(problem, alphabet, grid, debug=True, early=False):\n",
" m, n = dimension_problem(problem)\n",
" \n",
" ok_lines = [False] * m\n",
" for line in range(m):\n",
" word = nth_line(grid, line)\n",
" ok_lines[line] = check_line(problem, alphabet, word, line, debug=debug, early=early)\n",
" \n",
" ok_columns = [False] * n\n",
" for column in range(n):\n",
" word = nth_column(grid, column)\n",
" ok_columns[column] = check_column(problem, alphabet, word, column, debug=debug, early=early)\n",
" \n",
" return all(ok_lines) and all(ok_columns)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's try it!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For the easy problem"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For a partial grid, of course it's going to be invalid just because `'_'` is *not* in the alphabet $\\Sigma$."
]
},
{
"cell_type": "code",
"execution_count": 61,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:06.793808Z",
"start_time": "2021-03-04T13:52:06.784452Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The word 'H_' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter _ is not present.\n",
"The word '_P' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter _ is not present.\n",
"The word 'H_' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #1th letter _ is not present.\n",
"The word '_P' is not in alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}, as its #0th letter _ is not present.\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 61,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_partial)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For a complete grid, let's check that our solution is valid:"
]
},
{
"cell_type": "code",
"execution_count": 62,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:07.188493Z",
"start_time": "2021-03-04T13:52:07.178654Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 'HE|LL|O+':\n",
"The word 'HE' is matched by 'HE|LL|O+'\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'LP' is matched by '[PLEASE]+'\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'HL' is matched by '[^SPEAK]+'\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EP' is matched by 'EP|IP|EF'\n"
]
},
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 62,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_solution)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And let's also check that the few wrong solutions are indeed not valid:"
]
},
{
"cell_type": "code",
"execution_count": 63,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:07.611879Z",
"start_time": "2021-03-04T13:52:07.604558Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 'HE|LL|O+':\n",
"The word 'HE' is matched by 'HE|LL|O+'\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'LF' is NOT matched by '[PLEASE]+'\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'HL' is matched by '[^SPEAK]+'\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EF' is matched by 'EP|IP|EF'\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 63,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_wrong1)"
]
},
{
"cell_type": "code",
"execution_count": 64,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:07.842336Z",
"start_time": "2021-03-04T13:52:07.834547Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 'HE|LL|O+':\n",
"The word 'HE' is matched by 'HE|LL|O+'\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'EP' is matched by '[PLEASE]+'\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'HE' is NOT matched by '[^SPEAK]+'\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EP' is matched by 'EP|IP|EF'\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 64,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_wrong2)"
]
},
{
"cell_type": "code",
"execution_count": 65,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:08.034368Z",
"start_time": "2021-03-04T13:52:08.028366Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 'HE|LL|O+':\n",
"The word 'HE' is matched by 'HE|LL|O+'\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'OF' is NOT matched by '[PLEASE]+'\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'HO' is matched by '[^SPEAK]+'\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EF' is matched by 'EP|IP|EF'\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 65,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_wrong3)"
]
},
{
"cell_type": "code",
"execution_count": 66,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:08.258600Z",
"start_time": "2021-03-04T13:52:08.253041Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 'HE|LL|O+':\n",
"The word 'OE' is NOT matched by 'HE|LL|O+'\n",
"For line constraint #0 '[PLEASE]+':\n",
"The word 'OF' is NOT matched by '[PLEASE]+'\n",
"For column constraint #0 '[^SPEAK]+':\n",
"The word 'OO' is matched by '[^SPEAK]+'\n",
"For column constraint #0 'EP|IP|EF':\n",
"The word 'EF' is matched by 'EP|IP|EF'\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 66,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem1, alphabet1, grid1_wrong4)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can see that for each wrong grid, at least one of the contraint is violated!\n",
"\n",
"That's pretty good!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For the intermediate problem\n",
"\n",
"My solution for the intermediate problem `problem3` is indeed valid:\n",
"\n",
"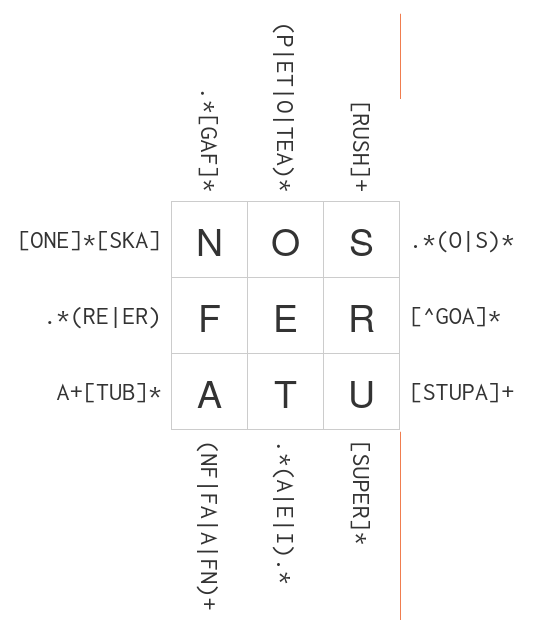"
]
},
{
"cell_type": "code",
"execution_count": 67,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:09.451127Z",
"start_time": "2021-03-04T13:52:09.435280Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For line constraint #0 '[ONE]*[SKA]':\n",
"For the first time seeing this regexp '[ONE]*[SKA]', compiling it and storing in memory_of_compiled_regexps, now of size 9.\n",
"The word 'NOS' is matched by '[ONE]*[SKA]'\n",
"For line constraint #1 '.*(O|S)*':\n",
"For the first time seeing this regexp '.*(O|S)*', compiling it and storing in memory_of_compiled_regexps, now of size 10.\n",
"The word 'NOS' is matched by '.*(O|S)*'\n",
"For line constraint #0 '.*(RE|ER)':\n",
"For the first time seeing this regexp '.*(RE|ER)', compiling it and storing in memory_of_compiled_regexps, now of size 11.\n",
"The word 'FER' is matched by '.*(RE|ER)'\n",
"For line constraint #1 '[^GOA]*':\n",
"For the first time seeing this regexp '[^GOA]*', compiling it and storing in memory_of_compiled_regexps, now of size 12.\n",
"The word 'FER' is matched by '[^GOA]*'\n",
"For line constraint #0 'A+[TUB]*':\n",
"For the first time seeing this regexp 'A+[TUB]*', compiling it and storing in memory_of_compiled_regexps, now of size 13.\n",
"The word 'ATU' is matched by 'A+[TUB]*'\n",
"For line constraint #1 '[STUPA]+':\n",
"For the first time seeing this regexp '[STUPA]+', compiling it and storing in memory_of_compiled_regexps, now of size 14.\n",
"The word 'ATU' is matched by '[STUPA]+'\n",
"For column constraint #0 '.*[GAF]*':\n",
"For the first time seeing this regexp '.*[GAF]*', compiling it and storing in memory_of_compiled_regexps, now of size 15.\n",
"The word 'NFA' is matched by '.*[GAF]*'\n",
"For column constraint #1 '(NF|FA|A|FN)+':\n",
"For the first time seeing this regexp '(NF|FA|A|FN)+', compiling it and storing in memory_of_compiled_regexps, now of size 16.\n",
"The word 'NFA' is matched by '(NF|FA|A|FN)+'\n",
"For column constraint #0 '(P|ET|O|TEA)*':\n",
"For the first time seeing this regexp '(P|ET|O|TEA)*', compiling it and storing in memory_of_compiled_regexps, now of size 17.\n",
"The word 'OET' is matched by '(P|ET|O|TEA)*'\n",
"For column constraint #1 '.*(A|E|I).*':\n",
"For the first time seeing this regexp '.*(A|E|I).*', compiling it and storing in memory_of_compiled_regexps, now of size 18.\n",
"The word 'OET' is matched by '.*(A|E|I).*'\n",
"For column constraint #0 '[RUSH]+':\n",
"For the first time seeing this regexp '[RUSH]+', compiling it and storing in memory_of_compiled_regexps, now of size 19.\n",
"The word 'SRU' is matched by '[RUSH]+'\n",
"For column constraint #1 '[SUPER]*':\n",
"For the first time seeing this regexp '[SUPER]*', compiling it and storing in memory_of_compiled_regexps, now of size 20.\n",
"The word 'SRU' is matched by '[SUPER]*'\n"
]
},
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 67,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"check_grid(problem3, alphabet3, grid3_solution)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For the hard problem\n",
"\n",
"Well I don't have a solution yet, so I cannot check it!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Third easy task: generate all words of a given size in the alphabet\n",
"\n",
"Using [`itertools.product`](https://docs.python.org/3/library/itertools.html#itertools.product) and the alphabet defined above, it's going to be easy.\n",
"\n",
"Note that I'll first try with a smaller alphabet, to check the result (for problem 1)."
]
},
{
"cell_type": "code",
"execution_count": 68,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:09.956672Z",
"start_time": "2021-03-04T13:52:09.952276Z"
}
},
"outputs": [],
"source": [
"import itertools"
]
},
{
"cell_type": "code",
"execution_count": 69,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:10.131193Z",
"start_time": "2021-03-04T13:52:10.127556Z"
}
},
"outputs": [],
"source": [
"def all_words_of_alphabet(alphabet, size):\n",
" yield from itertools.product(alphabet, repeat=size)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Just a quick check:"
]
},
{
"cell_type": "code",
"execution_count": 70,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:10.541027Z",
"start_time": "2021-03-04T13:52:10.534723Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[('0', '0', '0'),\n",
" ('0', '0', '1'),\n",
" ('0', '1', '0'),\n",
" ('0', '1', '1'),\n",
" ('1', '0', '0'),\n",
" ('1', '0', '1'),\n",
" ('1', '1', '0'),\n",
" ('1', '1', '1')]"
]
},
"execution_count": 70,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"list(all_words_of_alphabet(['0', '1'], 3))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The time and memory complexity of this function should be $\\mathcal{O}(|\\Sigma|^k)$ for words of size $k\\in\\mathbb{N}^*$."
]
},
{
"cell_type": "code",
"execution_count": 71,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:37.610503Z",
"start_time": "2021-03-04T13:52:10.944257Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Generating 4 words of size = 2 takes about\n",
"754 ns ± 13.4 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)\n",
"Generating 8 words of size = 3 takes about\n",
"923 ns ± 9.82 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)\n",
"Generating 16 words of size = 4 takes about\n",
"1.38 µs ± 30.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)\n",
"Generating 32 words of size = 5 takes about\n",
"2.28 µs ± 44 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)\n"
]
}
],
"source": [
"alphabet0 = ['0', '1']\n",
"len_alphabet = len(alphabet0)\n",
"for k in [2, 3, 4, 5]:\n",
" print(f\"Generating {len_alphabet**k} words of size = {k} takes about\")\n",
" %timeit list(all_words_of_alphabet(alphabet0, k))"
]
},
{
"cell_type": "code",
"execution_count": 72,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:52:47.212999Z",
"start_time": "2021-03-04T13:52:37.635433Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"117 ms ± 1.39 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
]
}
],
"source": [
"%timeit list(all_words_of_alphabet(['0', '1', '2', '3'], 10))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can quickly check that even for the larger alphabet of size ~40, it's quite quick for small words of length $\\leq 5$:"
]
},
{
"cell_type": "code",
"execution_count": 73,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:53:07.011668Z",
"start_time": "2021-03-04T13:52:47.240771Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Generating 100 words of size = 2 takes about\n",
"6.27 µs ± 1.35 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each)\n",
"Generating 1000 words of size = 3 takes about\n",
"45.9 µs ± 729 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n",
"Generating 10000 words of size = 4 takes about\n",
"519 µs ± 6.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n",
"Generating 100000 words of size = 5 takes about\n",
"8.36 ms ± 330 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
]
}
],
"source": [
"len_alphabet = len(alphabet1)\n",
"for k in [2, 3, 4, 5]:\n",
" print(f\"Generating {len_alphabet**k} words of size = {k} takes about\")\n",
" %timeit list(all_words_of_alphabet(alphabet1, k))"
]
},
{
"cell_type": "code",
"execution_count": 74,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:54:49.671837Z",
"start_time": "2021-03-04T13:53:07.035916Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Generating 1681 words of size = 2 takes about\n",
"79.2 µs ± 990 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n",
"Generating 68921 words of size = 3 takes about\n",
"4.57 ms ± 51.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n",
"Generating 2825761 words of size = 4 takes about\n",
"230 ms ± 4.53 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n",
"Generating 115856201 words of size = 5 takes about\n",
"11.1 s ± 215 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
]
}
],
"source": [
"len_alphabet = len(alphabet2)\n",
"for k in [2, 3, 4, 5]:\n",
" print(f\"Generating {len_alphabet**k} words of size = {k} takes about\")\n",
" %timeit list(all_words_of_alphabet(alphabet2, k))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Who, it takes 12 seconds to just *generate* all the possible words for the largest problem (which is just of size $(5,5)$)...\n",
"\n",
"I'm afraid that my naive approach to solve the puzzle will be VERY slow..."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Fourth easy task: generate all grids of a given size"
]
},
{
"cell_type": "code",
"execution_count": 75,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:54:56.115315Z",
"start_time": "2021-03-04T13:54:56.108986Z"
}
},
"outputs": [],
"source": [
"def all_grids_of_alphabet(alphabet, lines, columns):\n",
" all_words = list(itertools.product(alphabet, repeat=columns))\n",
" all_words = [ \"\".join(words) for words in all_words ]\n",
" all_grids = itertools.product(all_words, repeat=lines)\n",
" for pre_tr_grid in all_grids:\n",
" tr_grid = [\n",
" [\n",
" pre_tr_grid[line][column]\n",
" for line in range(lines)\n",
" ]\n",
" for column in range(columns)\n",
" ]\n",
" yield tr_grid"
]
},
{
"cell_type": "code",
"execution_count": 76,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:00.017935Z",
"start_time": "2021-03-04T13:54:58.878130Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[['0']]\n",
"[['1']]\n",
"[['0', '0'], ['0', '0']]\n",
"[['1', '1'], ['1', '1']]\n",
"[['0'], ['0']]\n",
"[['1'], ['1']]\n",
"[['0', '0']]\n",
"[['1', '1']]\n",
"[['0', '0', '0'], ['0', '0', '0'], ['0', '0', '0']]\n",
"[['1', '1', '1'], ['1', '1', '1'], ['1', '1', '1']]\n",
"[['0', '0', '0'], ['0', '0', '0']]\n",
"[['1', '1', '1'], ['1', '1', '1']]\n",
"[['0', '0'], ['0', '0'], ['0', '0']]\n",
"[['1', '1'], ['1', '1'], ['1', '1']]\n",
"[['0']]\n",
"[['1']]\n",
"[['0', '0'], ['0', '0']]\n",
"[['1', '1'], ['1', '1']]\n",
"[['0'], ['0']]\n",
"[['1'], ['1']]\n",
"[['0', '0']]\n",
"[['1', '1']]\n",
"[['0', '0', '0'], ['0', '0', '0'], ['0', '0', '0']]\n",
"[['1', '1', '1'], ['1', '1', '1'], ['1', '1', '1']]\n",
"[['0', '0', '0'], ['0', '0', '0']]\n",
"[['1', '1', '1'], ['1', '1', '1']]\n",
"[['0', '0'], ['0', '0'], ['0', '0']]\n",
"[['1', '1'], ['1', '1'], ['1', '1']]\n"
]
}
],
"source": [
"for alphabet in ( ['0', '1'], ['T', 'A', 'C', 'G'] ):\n",
" for (n, m) in [ (1, 1), (2, 2), (1, 2), (2, 1), (3, 3), (3, 2), (2, 3) ]:\n",
" assert len(list(all_grids_of_alphabet(alphabet, n, m))) == len(alphabet)**(n*m)\n",
" print(list(all_grids_of_alphabet(alphabet0, n, m))[0])\n",
" print(list(all_grids_of_alphabet(alphabet0, n, m))[-1])"
]
},
{
"cell_type": "code",
"execution_count": 77,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:00.061358Z",
"start_time": "2021-03-04T13:55:00.051009Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For the alphabet ['0', '1'] of size = 2 :\n",
"CPU times: user 28 µs, sys: 6 µs, total: 34 µs\n",
"Wall time: 37.9 µs\n",
"For (n, m) = (1, 1) the number of grids is 2\n",
"CPU times: user 21 µs, sys: 4 µs, total: 25 µs\n",
"Wall time: 29.8 µs\n",
"For (n, m) = (2, 1) the number of grids is 4\n",
"CPU times: user 20 µs, sys: 4 µs, total: 24 µs\n",
"Wall time: 26.5 µs\n",
"For (n, m) = (1, 2) the number of grids is 4\n",
"CPU times: user 38 µs, sys: 8 µs, total: 46 µs\n",
"Wall time: 48.9 µs\n",
"For (n, m) = (2, 2) the number of grids is 16\n"
]
}
],
"source": [
"print(f\"For the alphabet {alphabet0} of size = {len(alphabet0)} :\")\n",
"for (n, m) in [ (1, 1), (2, 1), (1, 2), (2, 2) ]:\n",
" %time all_these_grids = list(all_grids_of_alphabet(alphabet0, n, m))\n",
" print(f\"For (n, m) = {(n, m)} the number of grids is {len(all_these_grids)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### How long does it take and how many grids for the easy problem?"
]
},
{
"cell_type": "code",
"execution_count": 78,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:03.975396Z",
"start_time": "2021-03-04T13:55:03.932232Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For the alphabet {'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'} of size = 10 :\n",
"CPU times: user 73 µs, sys: 0 ns, total: 73 µs\n",
"Wall time: 80.1 µs\n",
"For (n, m) = (1, 1) the number of grids is 10\n",
"CPU times: user 303 µs, sys: 31 µs, total: 334 µs\n",
"Wall time: 341 µs\n",
"For (n, m) = (2, 1) the number of grids is 100\n",
"CPU times: user 584 µs, sys: 124 µs, total: 708 µs\n",
"Wall time: 719 µs\n",
"For (n, m) = (1, 2) the number of grids is 100\n",
"CPU times: user 27.6 ms, sys: 152 µs, total: 27.7 ms\n",
"Wall time: 27.3 ms\n",
"For (n, m) = (2, 2) the number of grids is 10000\n"
]
}
],
"source": [
"print(f\"For the alphabet {alphabet1} of size = {len(alphabet1)} :\")\n",
"for (n, m) in [ (1, 1), (2, 1), (1, 2), (2, 2) ]:\n",
" %time all_these_grids = list(all_grids_of_alphabet(alphabet1, n, m))\n",
" print(f\"For (n, m) = {(n, m)} the number of grids is {len(all_these_grids)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's still pretty small and fast!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### How long does it take and how many grids for the hard problem?"
]
},
{
"cell_type": "code",
"execution_count": 79,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:12.659639Z",
"start_time": "2021-03-04T13:55:06.058330Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For the alphabet {'Z', 'E', 'I', 'V', 'R', 'A', 'F', 'D', 'Q', '3', 'Y', 'L', '4', 'W', '$', '5', 'M', 'B', 'N', '2', '8', '1', 'T', 'X', 'H', '-', 'S', '?', 'G', '9', 'U', 'P', '7', 'O', '.', 'C', 'J', 'K', '0', '6', ':'} of size = 41 :\n",
"CPU times: user 1.05 ms, sys: 224 µs, total: 1.28 ms\n",
"Wall time: 1.28 ms\n",
"For (n, m) = (1, 1) the number of grids is 41\n",
"CPU times: user 2.67 ms, sys: 0 ns, total: 2.67 ms\n",
"Wall time: 2.68 ms\n",
"For (n, m) = (2, 1) the number of grids is 1681\n",
"CPU times: user 4.54 ms, sys: 30 µs, total: 4.57 ms\n",
"Wall time: 4.58 ms\n",
"For (n, m) = (1, 2) the number of grids is 1681\n",
"CPU times: user 6.39 s, sys: 191 ms, total: 6.59 s\n",
"Wall time: 6.58 s\n",
"For (n, m) = (2, 2) the number of grids is 2825761\n"
]
}
],
"source": [
"print(f\"For the alphabet {alphabet2} of size = {len(alphabet2)} :\")\n",
"for (n, m) in [ (1, 1), (2, 1), (1, 2), (2, 2) ]:\n",
" %time all_these_grids = list(all_grids_of_alphabet(alphabet2, n, m))\n",
" print(f\"For (n, m) = {(n, m)} the number of grids is {len(all_these_grids)}\")"
]
},
{
"cell_type": "code",
"execution_count": 80,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:18.833093Z",
"start_time": "2021-03-04T13:55:18.830020Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"4750104241"
]
},
"execution_count": 80,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"41**(2*3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Just for $(n, m) = (2, 2)$ it takes about 7 seconds...\n",
"So to scale for $(n, m) = (5, 5)$ would just take... WAY TOO MUCH TIME!"
]
},
{
"cell_type": "code",
"execution_count": 81,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:25.214371Z",
"start_time": "2021-03-04T13:55:25.211137Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"20873554875923477449109855954682643681001"
]
},
"execution_count": 81,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"n, m = 5, 5\n",
"41**(5*5)"
]
},
{
"cell_type": "code",
"execution_count": 82,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:31.600510Z",
"start_time": "2021-03-04T13:55:31.598390Z"
}
},
"outputs": [],
"source": [
"import math"
]
},
{
"cell_type": "code",
"execution_count": 83,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:37.968480Z",
"start_time": "2021-03-04T13:55:37.965381Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"40.31959641799339"
]
},
"execution_count": 83,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"math.log10(41**(5*5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For a grid of size $(5,5)$, the number of different possible grids is about $10^{40}$, that is CRAZY large, we have no hope of solving this problem with a brute force approach.\n",
"\n",
"How much time would that require, just to generate the grids?"
]
},
{
"cell_type": "code",
"execution_count": 84,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:44.758283Z",
"start_time": "2021-03-04T13:55:44.754139Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"4.9e+22"
]
},
"execution_count": 84,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"s = 7\n",
"estimate_of_running_time = 7*s * len(alphabet1)**(5*5) / len(alphabet1)**(2*2)\n",
"estimate_of_running_time # in seconds"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This rough estimate gives about $5 * 10^{22}$ seconds, about $10^{15}$ years, so about a million of billion years !"
]
},
{
"cell_type": "code",
"execution_count": 85,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T13:55:51.836129Z",
"start_time": "2021-03-04T13:55:51.831465Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"15.191389473093146"
]
},
"execution_count": 85,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"math.log10( estimate_of_running_time / (60*60*24*365) )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## First difficult task: for each possible grid, check if its valid "
]
},
{
"cell_type": "code",
"execution_count": 91,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T14:29:25.325177Z",
"start_time": "2021-03-04T14:29:25.273736Z"
}
},
"outputs": [],
"source": [
"def naive_solve(problem, alphabet, debug=False, early=True):\n",
" n, m = dimension_problem(problem)\n",
" good_grids = []\n",
" for possible_grid in all_grids_of_alphabet(alphabet, n, m):\n",
" is_good_grid = check_grid(problem, alphabet, possible_grid, debug=debug, early=early)\n",
" if is_good_grid:\n",
" if early:\n",
" return [ possible_grid ]\n",
" good_grids.append(possible_grid)\n",
" return good_grids"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's try it!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Solving the easy problem"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's check that we can quickly find *one* solution:"
]
},
{
"cell_type": "code",
"execution_count": 92,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:08.828968Z",
"start_time": "2021-03-04T15:25:08.700736Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For problem 1\n",
"{'left_lines': ['HE|LL|O+', '[PLEASE]+'], 'right_lines': None, 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'], 'bottom_columns': None}\n",
"On alphabet\n",
"{'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}\n",
"==> We found one solution:\n",
"[[['H', 'E'], ['L', 'P']]]\n",
"CPU times: user 111 ms, sys: 3.25 ms, total: 114 ms\n",
"Wall time: 115 ms\n"
]
}
],
"source": [
"%%time\n",
"good_grids1 = naive_solve(problem1, alphabet1, debug=False, early=True)\n",
"\n",
"print(f\"For problem 1\\n{problem1}\\nOn alphabet\\n{alphabet1}\\n==> We found one solution:\\n{good_grids1}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then can we find more solutions?"
]
},
{
"cell_type": "code",
"execution_count": 93,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:15.345738Z",
"start_time": "2021-03-04T15:25:15.175555Z"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"For problem 1\n",
"{'left_lines': ['HE|LL|O+', '[PLEASE]+'], 'right_lines': None, 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'], 'bottom_columns': None}\n",
"On alphabet\n",
"{'S', 'P', 'E', 'O', 'L', 'H', 'I', 'K', 'A', 'F'}\n",
"==> We found these solutions:\n",
"[[['H', 'E'], ['L', 'P']]]\n",
"CPU times: user 168 ms, sys: 441 µs, total: 169 ms\n",
"Wall time: 167 ms\n"
]
}
],
"source": [
"%%time\n",
"good_grids1 = naive_solve(problem1, alphabet1, debug=False, early=False)\n",
"\n",
"print(f\"For problem 1\\n{problem1}\\nOn alphabet\\n{alphabet1}\\n==> We found these solutions:\\n{good_grids1}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"No there is indeed a unique solution here for the first \"easy\" problem!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Solving the intermediate problem"
]
},
{
"cell_type": "code",
"execution_count": 261,
"metadata": {
"ExecuteTime": {
"end_time": "2021-02-28T21:18:52.984044Z",
"start_time": "2021-02-28T21:12:33.121174Z"
}
},
"outputs": [
{
"ename": "KeyboardInterrupt",
"evalue": "",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36mnaive_solve\u001b[0;34m(problem, alphabet, debug, early)\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0mn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mm\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mdimension_problem\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mproblem\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3\u001b[0m \u001b[0mgood_grids\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 4\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mpossible_grid\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mall_grids_of_alphabet\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mm\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 5\u001b[0m \u001b[0mis_good_grid\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mcheck_grid\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mproblem\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpossible_grid\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mdebug\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mdebug\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mearly\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mearly\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mis_good_grid\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36mall_grids_of_alphabet\u001b[0;34m(alphabet, lines, columns)\u001b[0m\n\u001b[1;32m 9\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mline\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 10\u001b[0m ]\n\u001b[0;32m---> 11\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mcolumn\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcolumns\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 12\u001b[0m ]\n\u001b[1;32m 13\u001b[0m \u001b[0;32myield\u001b[0m \u001b[0mtr_grid\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m(.0)\u001b[0m\n\u001b[1;32m 9\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mline\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 10\u001b[0m ]\n\u001b[0;32m---> 11\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mcolumn\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcolumns\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 12\u001b[0m ]\n\u001b[1;32m 13\u001b[0m \u001b[0;32myield\u001b[0m \u001b[0mtr_grid\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;31mKeyboardInterrupt\u001b[0m: "
]
}
],
"source": [
"%%time\n",
"good_grids3 = naive_solve(problem3, alphabet3, debug=False, early=True)\n",
"\n",
"print(f\"For problem 3\\n{problem3}\\nOn alphabet\\n{alphabet3}\\n==> We found one solution:\\n{good_grids3}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That was so long...\n",
"\n",
"I could try to use Pypy3 IPython kernel, to speed things up?\n",
"\n",
"> Yes it's possible to use a Pypy kernel from your regular Python notebook!\n",
"> See "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Solving the hard problem\n",
"\n",
"Most probably, it will run forever if I use the naive approach of:\n",
"\n",
"- generate all grids of $m$ words of size $n$ in given alphabet $\\Sigma$ ;\n",
"- for all grid:\n",
" + test it using naive algorithm\n",
" + if it's valid: adds it to the list of good grids\n",
"\n",
"There are $|\\Sigma|^{n \\times m}$ possible grids, so this approach is doubly exponential in $n$ for square grids.\n",
"\n",
"I must think of a better approach...\n",
"Being just exponential in $\\max(m, n)$ would imply that it's practical for the harder problem of size $(5,5)$."
]
},
{
"cell_type": "code",
"execution_count": 192,
"metadata": {
"ExecuteTime": {
"end_time": "2021-02-28T20:13:50.218005Z",
"start_time": "2021-02-28T20:13:36.668666Z"
}
},
"outputs": [
{
"ename": "KeyboardInterrupt",
"evalue": "",
"output_type": "error",
"traceback": [
"\u001b[0;31m-------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36mnaive_solve\u001b[0;34m(problem, alphabet, debug, early)\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0mn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mm\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mdimension_problem\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mproblem\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3\u001b[0m \u001b[0mgood_grids\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 4\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mpossible_grid\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mall_grids_of_alphabet\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mm\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 5\u001b[0m \u001b[0mis_good_grid\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mcheck_grid\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mproblem\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpossible_grid\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mdebug\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mdebug\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mearly\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mearly\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mis_good_grid\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36mall_grids_of_alphabet\u001b[0;34m(alphabet, lines, columns)\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0mall_grids_of_alphabet\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlines\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mcolumns\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 2\u001b[0;31m \u001b[0mall_words\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mlist\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mitertools\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mproduct\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0malphabet\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrepeat\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mcolumns\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 3\u001b[0m \u001b[0mall_words\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m \u001b[0;34m\"\"\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mjoin\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mwords\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mwords\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mall_words\u001b[0m \u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 4\u001b[0m \u001b[0mall_grids\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mitertools\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mproduct\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mall_words\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrepeat\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mpre_tr_grid\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mall_grids\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;31mKeyboardInterrupt\u001b[0m: "
]
}
],
"source": [
"%%time\n",
"good_grids2 = naive_solve(problem2, alphabet2, debug=False, early=True)\n",
"\n",
"print(f\"For problem 2\\n{problem2}\\nOn alphabet\\n{alphabet2}\\n==> We found one solution:\\n{good_grids2}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"My first idea was to try to tackle each constraint independently, and generate the set of words that satisfy this contraint. (by naively checking `check(constraint, word)` for each word in $\\Sigma^n$ or $\\Sigma^m$).\n",
"\n",
"- if there are two line constraints (left/right), get the intersection of the two sets of words;\n",
"- then, *for each* line we have a set of possible words:\n",
" + we can build each column, and then check that the top/bottom constraint is valid or not\n",
" + if valid, continue to next column until the last\n",
" + if all columns are valid, then these lines/columns form a possible grid!\n",
" + (if we want only one solution, stop now, otherwise continue)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Second difficult task: a more efficient approach to solve any problem"
]
},
{
"cell_type": "code",
"execution_count": 94,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:28.384578Z",
"start_time": "2021-03-04T15:25:28.381711Z"
}
},
"outputs": [],
"source": [
"n, m = dimension_problem(problem1)"
]
},
{
"cell_type": "code",
"execution_count": 95,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:35.360406Z",
"start_time": "2021-03-04T15:25:35.321505Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"{'left_lines': ['HE|LL|O+', '[PLEASE]+'],\n",
" 'right_lines': None,\n",
" 'top_columns': ['[^SPEAK]+', 'EP|IP|EF'],\n",
" 'bottom_columns': None}"
]
},
"execution_count": 95,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"problem1"
]
},
{
"cell_type": "code",
"execution_count": 96,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:42.970992Z",
"start_time": "2021-03-04T15:25:42.966542Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"{'A', 'E', 'F', 'H', 'I', 'K', 'L', 'O', 'P', 'S'}"
]
},
"execution_count": 96,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"alphabet1"
]
},
{
"cell_type": "code",
"execution_count": 97,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:49.461422Z",
"start_time": "2021-03-04T15:25:49.457590Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"100"
]
},
"execution_count": 97,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(list(all_words_of_alphabet(alphabet1, n)))"
]
},
{
"cell_type": "code",
"execution_count": 98,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:25:55.996061Z",
"start_time": "2021-03-04T15:25:55.983844Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['SS', 'SP', 'SE', 'SO', 'SL', 'SH', 'SI', 'SK', 'SA', 'SF']"
]
},
"execution_count": 98,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[\"\".join(word) for word in list(all_words_of_alphabet(alphabet1, n))][:10]"
]
},
{
"cell_type": "code",
"execution_count": 99,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:27:41.528610Z",
"start_time": "2021-03-04T15:27:41.520134Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[['OO', 'LL', 'HE'],\n",
" ['SS',\n",
" 'SP',\n",
" 'SE',\n",
" 'SL',\n",
" 'SA',\n",
" 'PS',\n",
" 'PP',\n",
" 'PE',\n",
" 'PL',\n",
" 'PA',\n",
" 'ES',\n",
" 'EP',\n",
" 'EE',\n",
" 'EL',\n",
" 'EA',\n",
" 'LS',\n",
" 'LP',\n",
" 'LE',\n",
" 'LL',\n",
" 'LA',\n",
" 'AS',\n",
" 'AP',\n",
" 'AE',\n",
" 'AL',\n",
" 'AA']]"
]
},
"execution_count": 99,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[\n",
" [ \"\".join(word)\n",
" for word in all_words_of_alphabet(alphabet1, n)\n",
" if check_line(problem1, alphabet1, \"\".join(word), line, debug=False, early=True)\n",
" ]\n",
" for line in range(m)\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 100,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:27:47.887335Z",
"start_time": "2021-03-04T15:27:47.881290Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[['OO',\n",
" 'OL',\n",
" 'OH',\n",
" 'OI',\n",
" 'OF',\n",
" 'LO',\n",
" 'LL',\n",
" 'LH',\n",
" 'LI',\n",
" 'LF',\n",
" 'HO',\n",
" 'HL',\n",
" 'HH',\n",
" 'HI',\n",
" 'HF',\n",
" 'IO',\n",
" 'IL',\n",
" 'IH',\n",
" 'II',\n",
" 'IF',\n",
" 'FO',\n",
" 'FL',\n",
" 'FH',\n",
" 'FI',\n",
" 'FF'],\n",
" ['EP', 'EF', 'IP']]"
]
},
"execution_count": 100,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[\n",
" [ \"\".join(word)\n",
" for word in all_words_of_alphabet(alphabet1, m)\n",
" if check_column(problem1, alphabet1, \"\".join(word), column, debug=False, early=True)\n",
" ]\n",
" for column in range(n)\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So let's write this algorithm.\n",
"\n",
"I'm using a [`tqdm.tqdm()`](https://tqdm.github.io/docs/notebook/) wrapper on the foor loops, to keep an eye on the progress."
]
},
{
"cell_type": "code",
"execution_count": 101,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:27:54.174226Z",
"start_time": "2021-03-04T15:27:54.170465Z"
}
},
"outputs": [],
"source": [
"from tqdm.notebook import trange, tqdm"
]
},
{
"cell_type": "code",
"execution_count": 102,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:28:02.884111Z",
"start_time": "2021-03-04T15:28:02.856130Z"
}
},
"outputs": [],
"source": [
"def smart_solve(problem, alphabet, debug=False, early=True):\n",
" n, m = dimension_problem(problem)\n",
" good_grids = []\n",
" \n",
" possible_words_for_lines = [\n",
" [ \"\".join(word)\n",
" for word in all_words_of_alphabet(alphabet, n)\n",
" if check_line(problem, alphabet, \"\".join(word), line, debug=False, early=True)\n",
" # TODO don't compute this \"\".join(word) twice?\n",
" ]\n",
" for line in range(m)\n",
" ]\n",
" number_of_combinations = 1\n",
" for line in range(m):\n",
" number_of_combinations *= len(possible_words_for_lines[line])\n",
" print(f\"- There are {len(possible_words_for_lines[line])} different words for line #{line}\")\n",
" print(f\"=> There are {number_of_combinations} combinations of words for lines #{0}..#{m-1}\")\n",
"\n",
" for possible_words in tqdm(\n",
" list(itertools.product(*possible_words_for_lines)),\n",
" desc=\"lines\"\n",
" ):\n",
" if debug: print(f\" Trying possible_words from line constraints = {possible_words}\")\n",
" column = 0\n",
" no_wrong_column = True\n",
" while no_wrong_column and column < n:\n",
" word_column = \"\".join(possible_words[line][column] for line in range(m))\n",
" if debug: print(f\" For column #{column}, word = {word_column}, checking constraint...\")\n",
" if not check_column(problem, alphabet, word_column, column, debug=False, early=True):\n",
" # this word is NOT valid for this column, so let's go to the next word\n",
" if debug: print(f\" This word {word_column} is NOT valid for this column {column}, so let's go to the next word\")\n",
" no_wrong_column = False\n",
" # break: this was failing... broke the outer for-loop and not the inner one\n",
" column += 1\n",
" if no_wrong_column:\n",
" print(f\" These words seemed to satisfy the column constraints!\\n{possible_words}\")\n",
" \n",
" # so all columns are valid! this choice of words is good!\n",
" possible_grid = [\n",
" list(word) for word in possible_words\n",
" ]\n",
" print(f\"Giving this grid:\\n{possible_grid}\")\n",
" # let's check it, just in case (this takes a short time, compared to the rest)\n",
" is_good_grid = check_grid(problem, alphabet, possible_grid, debug=debug, early=early)\n",
" if is_good_grid:\n",
" if early:\n",
" return [ possible_grid ]\n",
" good_grids.append(possible_grid)\n",
" \n",
" # after the outer for loop on possible_words\n",
" return good_grids"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And let's try it:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### For the easy problem"
]
},
{
"cell_type": "code",
"execution_count": 103,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:28:09.265437Z",
"start_time": "2021-03-04T15:28:09.261978Z"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[['H', 'E'], ['L', 'P']]"
]
},
"execution_count": 103,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"grid1_solution"
]
},
{
"cell_type": "code",
"execution_count": 104,
"metadata": {
"ExecuteTime": {
"end_time": "2021-03-04T15:28:15.460286Z",
"start_time": "2021-03-04T15:28:15.363959Z"
},
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"- There are 3 different words for line #0\n",
"- There are 25 different words for line #1\n",
"=> There are 75 combinations of words for lines #0..#1\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "f33ed78568574093a6772ff601cc4d75",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"lines: 0%| | 0/75 [00:00 There are 4536 combinations of words for lines #0..#2\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "8eea7be8e24845a5b5db38dea3fac8f5",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"lines: 0%| | 0/4536 [00:00 If you're extra curious about this puzzle problem, and my experiments, you can continue from here and finish these ideas:\n",
"\n",
"- It could be great if it were be possible to give a partially filled grid, and start from there.\n",
"\n",
"- It could also be great to just be able to fill *one* cell in the grid, in case you're blocked and want some hint."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
},
"tags": []
},
"source": [
"## My feeling about these problems and my solutions\n",
"\n",
"I could have tried to be more efficient, but I didn't have much time to spend on this."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
},
"tags": []
},
"source": [
"## Conclusion\n",
"\n",
"That was nice! Writing this notebook took about 4.5 hours entirely, from first idea to final edit, on Sunday 28th of February, 2021. (note that I was also cooking my [pancakes](https://perso.crans.org/besson/cuisine/pancakes.html) during the first half, so I wasn't intensely coding)\n",
"\n",
"Have a look at [my other notebooks](https://GitHub.com/Naereen/notebooks/)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": false,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {
"height": "calc(100% - 180px)",
"left": "10px",
"top": "150px",
"width": "288px"
},
"toc_section_display": true,
"toc_window_display": true
},
"toc-autonumbering": true,
"toc-showcode": true,
"toc-showmarkdowntxt": false,
"toc-showtags": false,
"varInspector": {
"cols": {
"lenName": 16,
"lenType": 16,
"lenVar": 40
},
"kernels_config": {
"python": {
"delete_cmd_postfix": "",
"delete_cmd_prefix": "del ",
"library": "var_list.py",
"varRefreshCmd": "print(var_dic_list())"
},
"r": {
"delete_cmd_postfix": ") ",
"delete_cmd_prefix": "rm(",
"library": "var_list.r",
"varRefreshCmd": "cat(var_dic_list()) "
}
},
"types_to_exclude": [
"module",
"function",
"builtin_function_or_method",
"instance",
"_Feature"
],
"window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 4
}