Special thanks to:

### [Warp is built for coding with multiple AI agents](https://go.warp.dev/MediaCrawler)
# 🔥 MediaCrawler - Social Media Platform Crawler 🕷️

[](https://github.com/NanmiCoder/MediaCrawler/stargazers)
[](https://github.com/NanmiCoder/MediaCrawler/network/members)
[](https://github.com/NanmiCoder/MediaCrawler/issues)
[](https://github.com/NanmiCoder/MediaCrawler/pulls)
[](https://github.com/NanmiCoder/MediaCrawler/blob/main/LICENSE)
[](README.md)
[](README_en.md)
[](README_es.md)
> **Disclaimer:**
>
> Please use this repository for learning purposes only ⚠️⚠️⚠️⚠️, [Web scraping illegal cases](https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China)
>
>All content in this repository is for learning and reference purposes only, and commercial use is prohibited. No person or organization may use the content of this repository for illegal purposes or infringe upon the legitimate rights and interests of others. The web scraping technology involved in this repository is only for learning and research, and may not be used for large-scale crawling of other platforms or other illegal activities. This repository assumes no legal responsibility for any legal liability arising from the use of the content of this repository. By using the content of this repository, you agree to all terms and conditions of this disclaimer.
>
> Click to view a more detailed disclaimer. [Click to jump](#disclaimer)
## 📖 Project Introduction
A powerful **multi-platform social media data collection tool** that supports crawling public information from mainstream platforms including Xiaohongshu, Douyin, Kuaishou, Bilibili, Weibo, Tieba, Zhihu, and more.
### 🔧 Technical Principles
- **Core Technology**: Based on [Playwright](https://playwright.dev/) browser automation framework for login and maintaining login state
- **No JS Reverse Engineering Required**: Uses browser context environment with preserved login state to obtain signature parameters through JS expressions
- **Advantages**: No need to reverse complex encryption algorithms, significantly lowering the technical barrier
## ✨ Features
| Platform | Keyword Search | Specific Post ID Crawling | Secondary Comments | Specific Creator Homepage | Login State Cache | IP Proxy Pool | Generate Comment Word Cloud |
| ------ | ---------- | -------------- | -------- | -------------- | ---------- | -------- | -------------- |
| Xiaohongshu | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Douyin | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Kuaishou | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bilibili | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Weibo | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Tieba | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Zhihu | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
MediaCrawlerPro Major Release! Open source is not easy, welcome to subscribe and support!
> Focus on learning mature project architectural design, not just crawling technology. The code design philosophy of the Pro version is equally worth in-depth study!
[MediaCrawlerPro](https://github.com/MediaCrawlerPro) core advantages over the open-source version:
#### 🎯 Core Feature Upgrades
- ✅ **Content Deconstruction Agent** (New feature)
- ✅ **Resume crawling functionality** (Key feature)
- ✅ **Multi-account + IP proxy pool support** (Key feature)
- ✅ **Remove Playwright dependency**, easier to use
- ✅ **Complete Linux environment support**
#### 🏗️ Architectural Design Optimization
- ✅ **Code refactoring optimization**, more readable and maintainable (decoupled JS signature logic)
- ✅ **Enterprise-level code quality**, suitable for building large-scale crawler projects
- ✅ **Perfect architectural design**, high scalability, greater source code learning value
#### 🎁 Additional Features
- ✅ **Social media video downloader desktop app** (suitable for learning full-stack development)
- ✅ **Multi-platform homepage feed recommendations** (HomeFeed)
- [ ] **AI Agent based on comment analysis is under development 🚀🚀**
Click to view: [MediaCrawlerPro Project Homepage](https://github.com/MediaCrawlerPro) for more information
## 🚀 Quick Start
> 💡 **Open source is not easy, if this project helps you, please give a ⭐ Star to support!**
## 📋 Prerequisites
### 🚀 uv Installation (Recommended)
Before proceeding with the next steps, please ensure that uv is installed on your computer:
- **Installation Guide**: [uv Official Installation Guide](https://docs.astral.sh/uv/getting-started/installation)
- **Verify Installation**: Enter the command `uv --version` in the terminal. If the version number is displayed normally, the installation was successful
- **Recommendation Reason**: uv is currently the most powerful Python package management tool, with fast speed and accurate dependency resolution
### 🟢 Node.js Installation
The project depends on Node.js, please download and install from the official website:
- **Download Link**: https://nodejs.org/en/download/
- **Version Requirement**: >= 16.0.0
### 📦 Python Package Installation
```shell
# Enter project directory
cd MediaCrawler
# Use uv sync command to ensure consistency of python version and related dependency packages
uv sync
```
### 🌐 Browser Driver Installation
```shell
# Install browser driver
uv run playwright install
```
> **💡 Tip**: MediaCrawler now supports using playwright to connect to your local Chrome browser, solving some issues caused by Webdriver.
>
> Currently, `xhs` and `dy` are available using CDP mode to connect to local browsers. If needed, check the configuration items in `config/base_config.py`.
## 🚀 Run Crawler Program
```shell
# The project does not enable comment crawling mode by default. If you need comments, please modify the ENABLE_GET_COMMENTS variable in config/base_config.py
# Other supported options can also be viewed in config/base_config.py with Chinese comments
# Read keywords from configuration file to search related posts and crawl post information and comments
uv run main.py --platform xhs --lt qrcode --type search
# Read specified post ID list from configuration file to get information and comment information of specified posts
uv run main.py --platform xhs --lt qrcode --type detail
# Open corresponding APP to scan QR code for login
# For other platform crawler usage examples, execute the following command to view
uv run main.py --help
```
## WebUI Support
🖥️ WebUI Visual Operation Interface
MediaCrawler provides a web-based visual operation interface, allowing you to easily use crawler features without command line.
#### Start WebUI Service
```shell
# Start API server (default port 8080)
uv run uvicorn api.main:app --port 8080 --reload
# Or start using module method
uv run python -m api.main
```
After successful startup, visit `http://localhost:8080` to open the WebUI interface.
#### WebUI Features
- Visualize crawler parameter configuration (platform, login method, crawling type, etc.)
- Real-time view of crawler running status and logs
- Data preview and export
#### Interface Preview
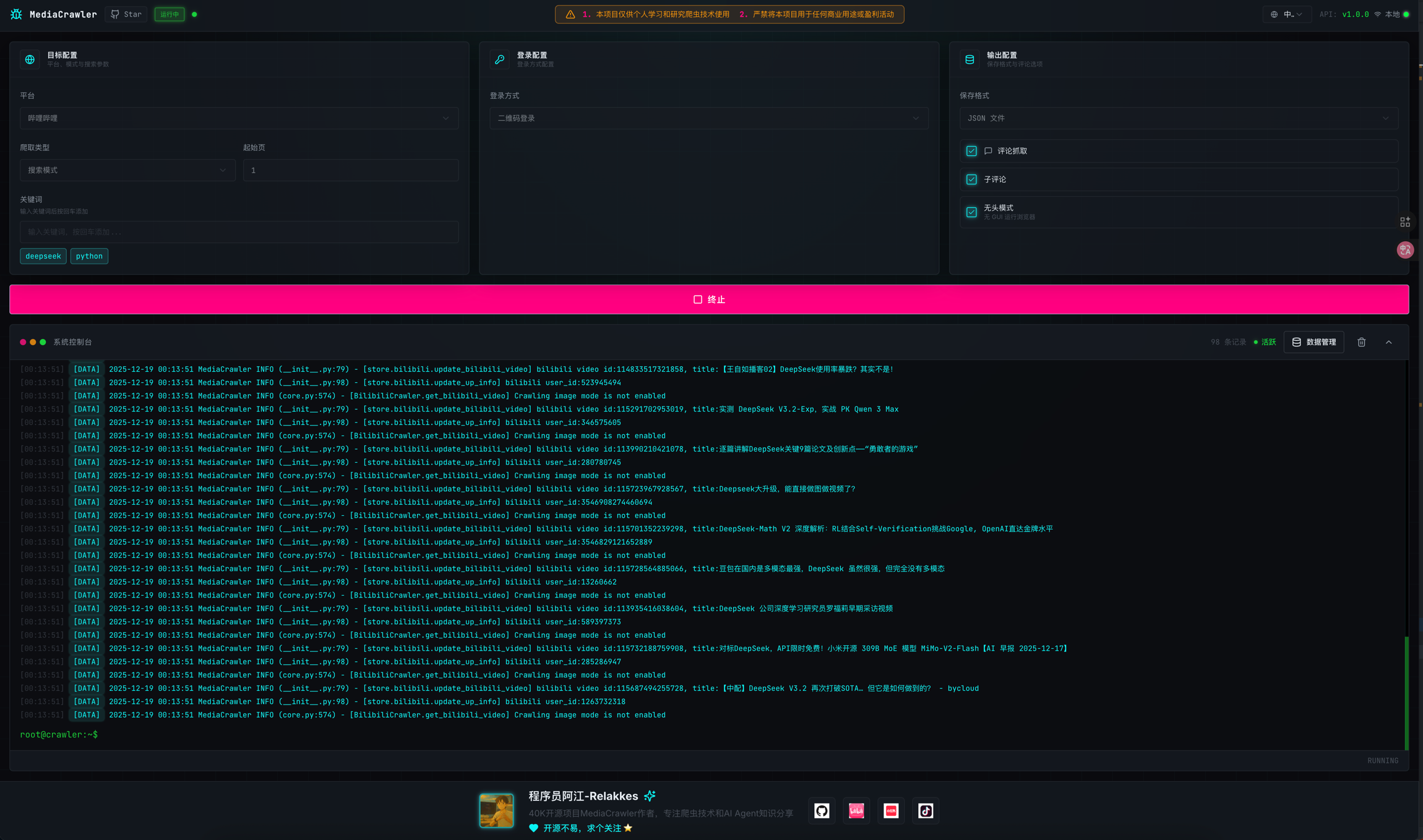
🔗 Using Python native venv environment management (Not recommended)
#### Create and activate Python virtual environment
> If crawling Douyin and Zhihu, you need to install nodejs environment in advance, version greater than or equal to: `16`
```shell
# Enter project root directory
cd MediaCrawler
# Create virtual environment
# My python version is: 3.9.6, the libraries in requirements.txt are based on this version
# If using other python versions, the libraries in requirements.txt may not be compatible, please resolve on your own
python -m venv venv
# macOS & Linux activate virtual environment
source venv/bin/activate
# Windows activate virtual environment
venv\Scripts\activate
```
#### Install dependency libraries
```shell
pip install -r requirements.txt
```
#### Install playwright browser driver
```shell
playwright install
```
#### Run crawler program (native environment)
```shell
# The project does not enable comment crawling mode by default. If you need comments, please modify the ENABLE_GET_COMMENTS variable in config/base_config.py
# Other supported options can also be viewed in config/base_config.py with Chinese comments
# Read keywords from configuration file to search related posts and crawl post information and comments
python main.py --platform xhs --lt qrcode --type search
# Read specified post ID list from configuration file to get information and comment information of specified posts
python main.py --platform xhs --lt qrcode --type detail
# Open corresponding APP to scan QR code for login
# For other platform crawler usage examples, execute the following command to view
python main.py --help
```
## 💾 Data Storage
MediaCrawler supports multiple data storage methods, including CSV, JSON, Excel, SQLite, and MySQL databases.
📖 **For detailed usage instructions, please see: [Data Storage Guide](docs/data_storage_guide.md)**
---
[🚀 MediaCrawlerPro Major Release 🚀! More features, better architectural design!](https://github.com/MediaCrawlerPro)
### 💬 Discussion Groups
- **WeChat Discussion Group**: [Click to join](https://nanmicoder.github.io/MediaCrawler/%E5%BE%AE%E4%BF%A1%E4%BA%A4%E6%B5%81%E7%BE%A4.html)
- **Bilibili Account**: [Follow me](https://space.bilibili.com/434377496), sharing AI and crawler technology knowledge
### 💰 Sponsor Display

TikHub.io provides 900+ highly stable data interfaces, covering 14+ mainstream domestic and international platforms including TK, DY, XHS, Y2B, Ins, X, etc. Supports multi-dimensional public data APIs for users, content, products, comments, etc., with 40M+ cleaned structured datasets. Use invitation code cfzyejV9 to register and recharge, and get an additional $2 bonus.
---

Thordata: Reliable and cost-effective proxy service provider. Provides stable, efficient and compliant global proxy IP services for enterprises and developers. Register now to get 1GB free residential proxy trial and 2000 serp-api calls.
【Residential Proxies】 | 【serp-api】
### 🤝 Become a Sponsor
Become a sponsor and showcase your product here, getting massive exposure daily!
**Contact Information**:
- WeChat: `relakkes`
- Email: `relakkes@gmail.com`
---
### 📚 Other
- **FAQ**: [MediaCrawler Complete Documentation](https://nanmicoder.github.io/MediaCrawler/)
- **Crawler Beginner Tutorial**: [CrawlerTutorial Free Tutorial](https://github.com/NanmiCoder/CrawlerTutorial)
- **News Crawler Open Source Project**: [NewsCrawlerCollection](https://github.com/NanmiCoder/NewsCrawlerCollection)
## ⭐ Star Trend Chart
If this project helps you, please give a ⭐ Star to support and let more people see MediaCrawler!
[](https://star-history.com/#NanmiCoder/MediaCrawler&Date)
## 📚 References
- **Xiaohongshu Signature Repository**: [Cloxl's xhs signature repository](https://github.com/Cloxl/xhshow)
- **Xiaohongshu Client**: [ReaJason's xhs repository](https://github.com/ReaJason/xhs)
- **SMS Forwarding**: [SmsForwarder reference repository](https://github.com/pppscn/SmsForwarder)
- **Intranet Penetration Tool**: [ngrok official documentation](https://ngrok.com/docs/)
# Disclaimer
## 1. Project Purpose and Nature
This project (hereinafter referred to as "this project") was created as a technical research and learning tool, aimed at exploring and learning network data collection technologies. This project focuses on research of data crawling technologies for social media platforms, intended to provide learners and researchers with technical exchange purposes.
## 2. Legal Compliance Statement
The project developer (hereinafter referred to as "developer") solemnly reminds users to strictly comply with relevant laws and regulations of the People's Republic of China when downloading, installing and using this project, including but not limited to the "Cybersecurity Law of the People's Republic of China", "Counter-Espionage Law of the People's Republic of China" and all applicable national laws and policies. Users shall bear all legal responsibilities that may arise from using this project.
## 3. Usage Purpose Restrictions
This project is strictly prohibited from being used for any illegal purposes or non-learning, non-research commercial activities. This project may not be used for any form of illegal intrusion into other people's computer systems, nor may it be used for any activities that infringe upon others' intellectual property rights or other legitimate rights and interests. Users should ensure that their use of this project is purely for personal learning and technical research, and may not be used for any form of illegal activities.
## 4. Disclaimer
The developer has made every effort to ensure the legitimacy and security of this project, but assumes no responsibility for any form of direct or indirect losses that may arise from users' use of this project. Including but not limited to any data loss, equipment damage, legal litigation, etc. caused by using this project.
## 5. Intellectual Property Statement
The intellectual property rights of this project belong to the developer. This project is protected by copyright law and international copyright treaties as well as other intellectual property laws and treaties. Users may download and use this project under the premise of complying with this statement and relevant laws and regulations.
## 6. Final Interpretation Rights
The developer has the final interpretation rights regarding this project. The developer reserves the right to change or update this disclaimer at any time without further notice.
## 🙏 Acknowledgments
### JetBrains Open Source License Support
Thanks to JetBrains for providing free open source license support for this project!
