A program correlator compares two versions of a program and generates matches between
them. These matches are either functions (this function in the old version became this
function in the new version), or data (this piece of defined data in the old is now here in
the new version).
Each correlator has its own strengths and weaknesses, as well as characteristics for
generating scores. For instance, some correlators may run better after already having run
certain others (and processing their results). Some correlators return hard-coded scores due
to the nature of their correlation. It is important to read the specifics of each
correlator's description to understand how to best use it.
Below is a list of built-in (i.e, not discovered) program correlators.
Exact Data Match will iterate through your entire source program's list of defined data,
and look for a 1:1 correspondence for this data in the destination program. For instance,
if you have a defined string "This is a string" that appears only once in the source
program, and the Exact Data Matcher finds a single area in the destination program with
"This is a string", it will report it as a match.
Exact Data Match reports 1.0 for similarity score (because by definition, the data are
exactly the same) and 1.0 for confidence score (because it was found only once in each
program).
Duplicate Data Match will iterate through your source program's defined data, look for
matches in the destination program, and only create matches if the correspondence is NOT
1:1, i.e. 1:N, M:1, or M:N. Switch tables are often found by this correlator.
Duplicate Data Match reports 1.0 for similarity score (because by definition, the data
is exactly the same), but the confidence scores will all be less than 1.0. Duplicate Data
Match uses 10/(total source and destination matches) for raw confidence, but due to the
log10 scaling of the confidence reporting column these values will always be
less than 0.7*.
Note that the data does not need to be defined in the destination program for these
correlators to find matches.
Similar Data Match will iterate through your source and destination programs' defined data,
and look for similar data based on locality sensitive hashing of 4-grams.
Similar Data Match reports a similarity score based on the cosine difference between the
vector representations of the two data objects. A similarity of 1.0 means the data matches exactly.
The confidence scores are based on the similarity score and the vector lengths of the data objects.
 Note that functions MUST be defined in the
destination program for these correlators to find matches.
Note that functions MUST be defined in the
destination program for these correlators to find matches.
Exact Function Bytes Match is very similar to the Exact Data Match correlator, except it
looks for functions. If there is an exact byte-for-byte, 1:1 correspondence between a
function in the source program and a function in the destination program, it will create a
match.
Exact Function Bytes Match reports 1.0 for similarity score (because by definition, the
functions are exactly the same) and 1.0 for confidence score (because it was found only
once in each program).
Exact Function Instructions Match is almost exactly like Exact Function Bytes Match,
except that it removes the operands from the instructions by masking them out. This has an
advantage on certain CPU architectures (RISC)/compilers that can compile the same source
using different registers but otherwise identical opcodes. If a 1:1 correspondence is found
between a masked source function and a masked destination function, a match is created.
Exact Function Instructions Match reports 1.0 for similarity score, even though the
functions aren't necessarily identical byte-for-byte. It reports 1.0 for confidence score
(because it was found only once in each program).
Duplicate Function Match will iterate through your source program's functions, look for
matches in the destination program, and only create matches if the correspondence is NOT
1:1, i.e. 1:N, M:1, or M:N. It uses the operand masking to eliminate operands from the
opcodes when searching for matches. Boilerplate or template functions are often found by
this correlator.
Duplicate Function Match reports 1.0 for similarity score, even though the functions
aren't necessarily identical byte-for-byte. The confidence scores will all be less than
1.0. Duplicate Function Match uses 10/(total source and destination matches) for raw
confidence, but due to the log10 scaling of the confidence reporting column
these values will always be less than 0.7*.
Exact Function Mnemonic Match is almost exactly like Exact Function Instructions Match,
except that it uses the mnemonic names representing an instruction instead of the bytes representing
the instruction. This will find cases where the same instruction names are used but the underlying instruction bytes have changed.
Differences between the two correlators will be rare.
If a 1:1 correspondence is found between a masked source function and a masked destination function, a match is created.
Exact Function Instructions Match reports 1.0 for similarity score, even though the
functions aren't necessarily identical byte-for-byte. It reports 1.0 for confidence score
(because it was found only once in each program).
The Legacy Import correlator is a legacy results file importer (and not really a
correlator). It reads text files with a very specific format, and only creates functions
matches based upon the contained data.
The format of the file is a series of matches, each match on its own line. The match is
comprised of 9 fields, each separated by whitespace. The 9 fields are as follows:
score (similarity, in the range [0.0, 1.0])
source length (in bytes)
destination length (in bytes)
source program name
source function name
source address
destination program name
destination function name
destination address
NOTE: this format is provided for users who
have existing results that absolutely positively can't see any way to get them into Version
Tracking another way. It is legacy, deprecated, and will likely be replaced in the future
with a new import format (most likely a legacy format -> new data import format conversion
tool will be released simultaneously). We strongly recommend you don't use this importer,
and instead start your Version Tracking analysis from scratch using our provided
correlators.
The "Implied Match" correlator is a placeholder for matches that were created based on
references from other accepted matches. There is no "Implied Match" algorithm that can be
run, but since all matches must have a correlator, the Implied Match correlator was created.
Its only purpose is to display Implied Matches in the matches table. See the Implied Matches
Table for more information.
The manual match correlator is a placeholder for matches that were created manually by the
user. There is no "Manual Match" algorithm that can be run, but since all matches must have a
correlator, the Manual Match correlator was created. Its only purpose is to display Manual
Matches in the matches table.
Exact Symbol Name Match is very similar to the Exact Data Match correlator and the Exact
Function Match correlators, except it looks for symbol names. If there is an exact 1:1
correspondence between a symbol name (after removing the _address suffix that is sometimes added to symbols)
in the source program and a symbol in the destination
program, it will create a match. Note that this correlator only works on symbols where
there is a defined function or defined data in the source program. For the function case,
there also must be a defined function in the destination program. For the data case, there does
not have to be defined data in the destination program. Also note that this correlator
ignores the default symbols that Ghidra automatically creates such as, but not limited to, those that
start with FUN_, DAT_, except strings that start with s_, u_, etc... Note: There is an option to
that allows users to find external symbol matches as well.
Exact Symbol Name Match reports 1.0 for similarity score (because by definition, the
symbols are exactly the same) and 1.0 for confidence score (because it was found only once
in each program).
Duplicate Exact Symbol Name Match will iterate through your source program's symbols,
look for matches in the destination program, and only create matches if the correspondence
is NOT 1:1, i.e. 1:N, M:1, or M:N. When there is more than one symbol with the same name in
Ghidra, Ghidra appends the address onto the end of it. This correlator strips off the
ending address before correlating symbol names and ignores the default symbols
that Ghidra automatically creates such as, but not limited to, those that
start with FUN_, DAT_, except strings that start with s_, u_, etc... Note: There is an option to
that allows users to find external symbol matches as well.
Duplicate Exact Symbol Name Match reports 1.0 for similarity score, since the symbols
(minus the tacked on address) are identical. The confidence scores will all be less than
1.0. Duplicate Exact Symbol Name Match uses 10/(total source and destination matches) for
raw confidence, but due to the log10 scaling of the confidence reporting column
these values will always be less than 0.7*.
* log10(10/N) < 0.7 for N > 1; e.g. log10(5) ~= 0.69897
Similar Symbol Name Match will iterate through your source and destination programs'
symbols, and look for similar names based on locality sensitive hashing of trigrams.
Similar Symbol Name Match reports a similarity score based on the cosine difference
between the vector representations of the two symbol names. A similarity of 1.0
means the symbols match exactly. The confidence scores are based on the similarity score and
the vector lengths of the names.
Each of the following program correlators determines correlation based on feature vectors constructed from
matched and unmatched references of their respective types. The algorithm used is
- Identify functions that reference each ACCEPTED (
 ) match of the correct type.
) match of the correct type.
- Construct a sourceMap and a destinationMap of the form {referencingFunction:featureVector}
where the featureVector identifies an ACCEPTED match with the log weight for
the probability that it appears in any one function in the system.
NOTE: The same feature and log weight are added to sourceMap and destinationMap for each match.
- For each referencingFunction add a unique feature* to its featureVector with probability 0.5 for each
of its UNMATCHED references of the correct type.
- Score each pair of SOURCE and DESTINATION functions by the angle between their feature vectors,
taking the highest scoring pairs as the result.
- Refine the results by removing matches that have no clear winner.
* This is to account for the probabilistic cost of a reference being switched, dropped or picked
up between SOURCE and DESTINATION versions. Theoretically this should be dependent on the probability of the referenced element occurring,
but for simplicity we consider the model for a generalized switch and drop/pickup by assigning
a probability of 0.5 to each of the unmatched references made in any of our considered functions.
The Data Reference Correlator uses ACCEPTED matched data to find other function matches based on common data they reference.
That is, a reference is considered if it is a reference to matched data location.
Example
- (
 ) Start a Version Tracking session
) Start a Version Tracking session
- (
 ) Run the "Exact Data Match" correlator
) Run the "Exact Data Match" correlator
- () Accept all the matches
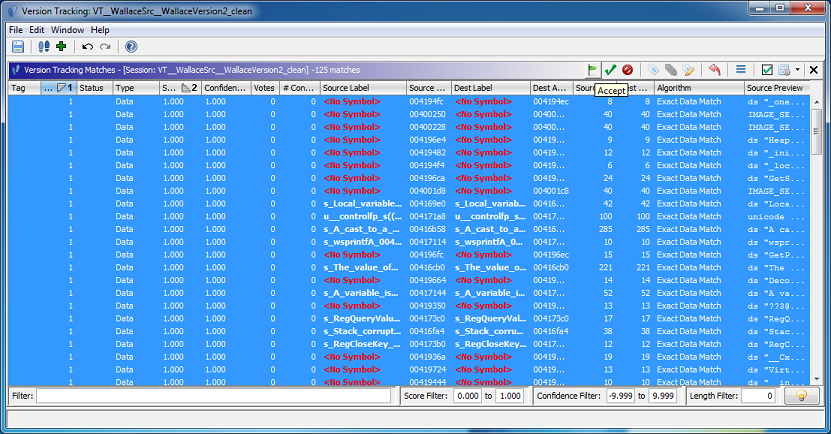
- () Run the "Data Reference Correlator"
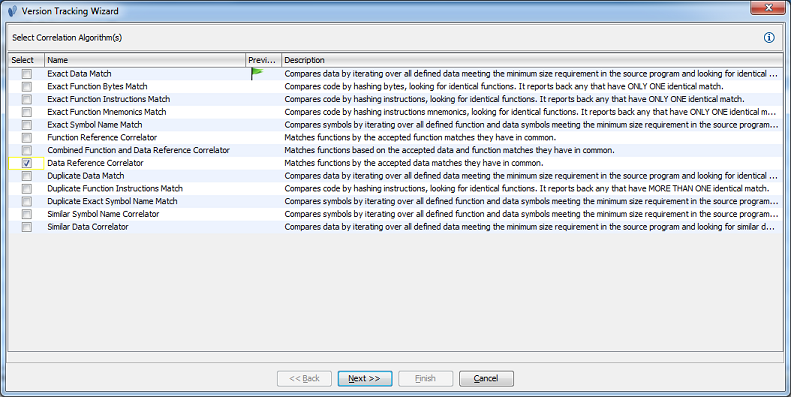
- Try using the default options (click 'Next' and 'Finish'):
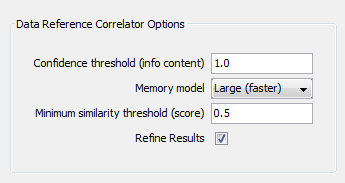
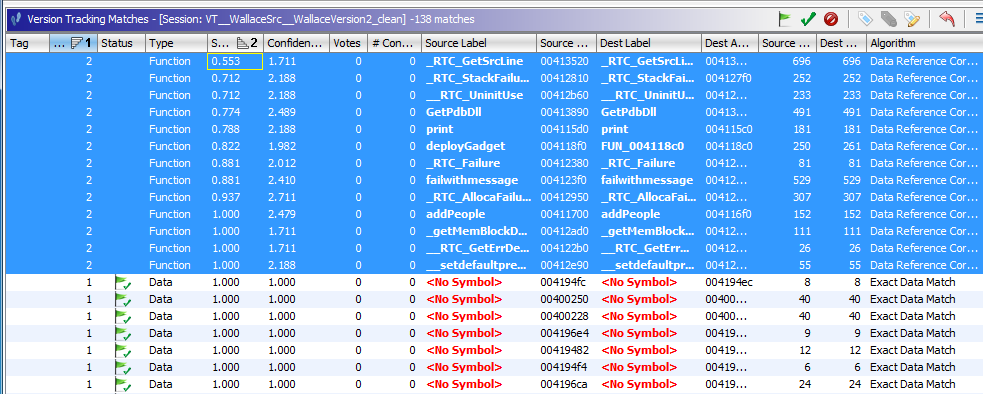
- Now try sorting on Score for the Data Reference Correlator and note that the lowest score is above the
minimum threshold set in the options. If a function is missing that you expect to see in the results, try
lowering the thresholds and/or unchecking the "Refine Results" checkbox.
The Function Reference Correlator uses ACCEPTED matched functions to find other
function matches based on common functions they reference. That is, a reference is
considered if it is a reference to a matched function.
Example
- By first running the "Exact Function Instructions Match" correlator, and then
running the "Function Reference Correlator" with the default options as above, we see
potential matches with Scores >= 0.5.
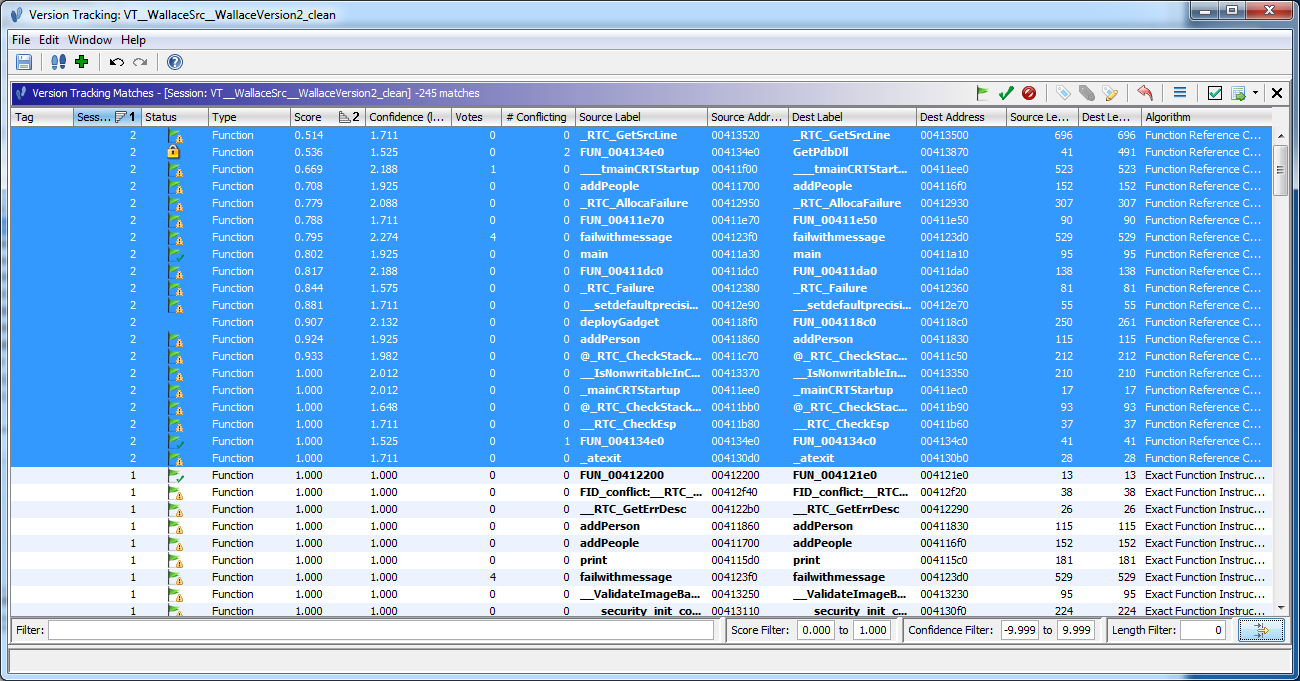
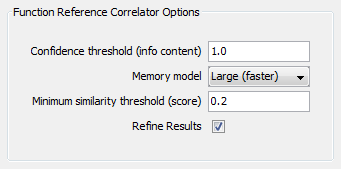
- By lowering the "Minimum similarity threshold (score)", we see one additional possible match.
The lower score indicates to us that this function, "__onexit", makes reference to functions that have not been matched yet.
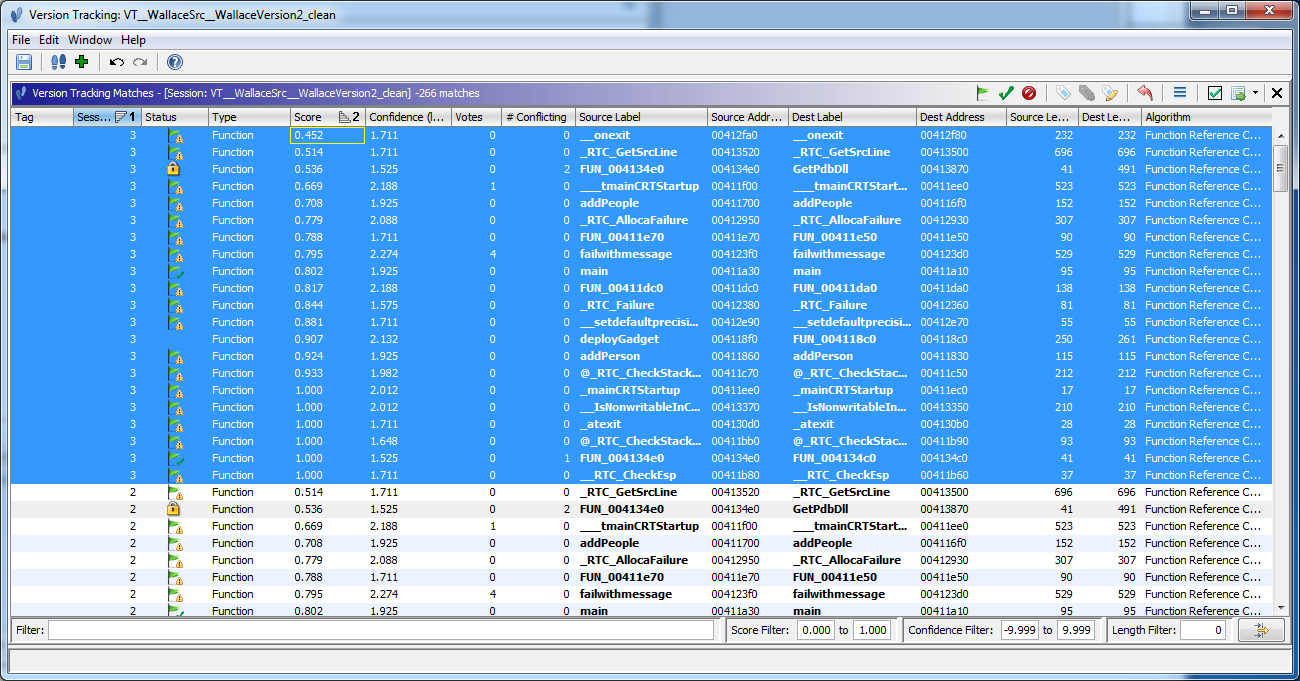
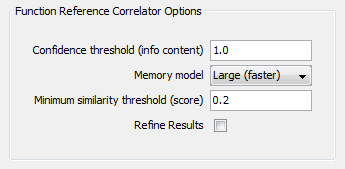
- By using the same thresholds as above, but also unchecking the "Refine Results" box, we
get many more results returned from the Reference Correlator. In this case, most of the additional results
are BLOCKED by our previously ACCEPTED matches, which, for example, results in only the correct pair for
"print" being made available for matching.
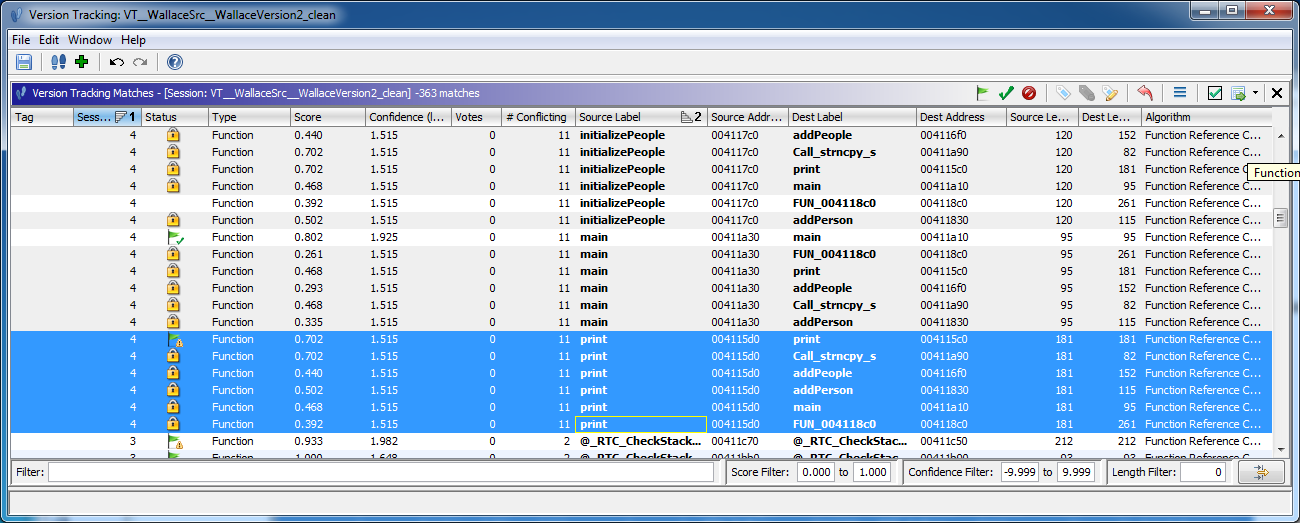
NOTE: By deafult the Version Tracking table does not display "Blocked" matches.
To see them, go to the Match Table Filters ( in the upper right corner)
and check the box next to "Blocked" under "Association Status".
in the upper right corner)
and check the box next to "Blocked" under "Association Status".
The Combined Function and Data Reference Correlator matches functions based on the accepted
data and function matches they have in common. This means that the set of references considered
for each tested function includes all its data and function references. That is, a reference is
considered if it is a reference to a matched function or matched data location.
NOTE: If no matches are returned, make sure there are existing ACCEPTED matches
(). This means you will need to run other correlators first, such as
Provided by: Version Tracking Plugin
Related Topics: