{
"cells": [
{
"cell_type": "markdown",
"id": "74423d44",
"metadata": {},
"source": [
"# Call Center - Model Transfer Learning and Fine-Tuning"
]
},
{
"cell_type": "markdown",
"id": "245ac8b4",
"metadata": {},
"source": [
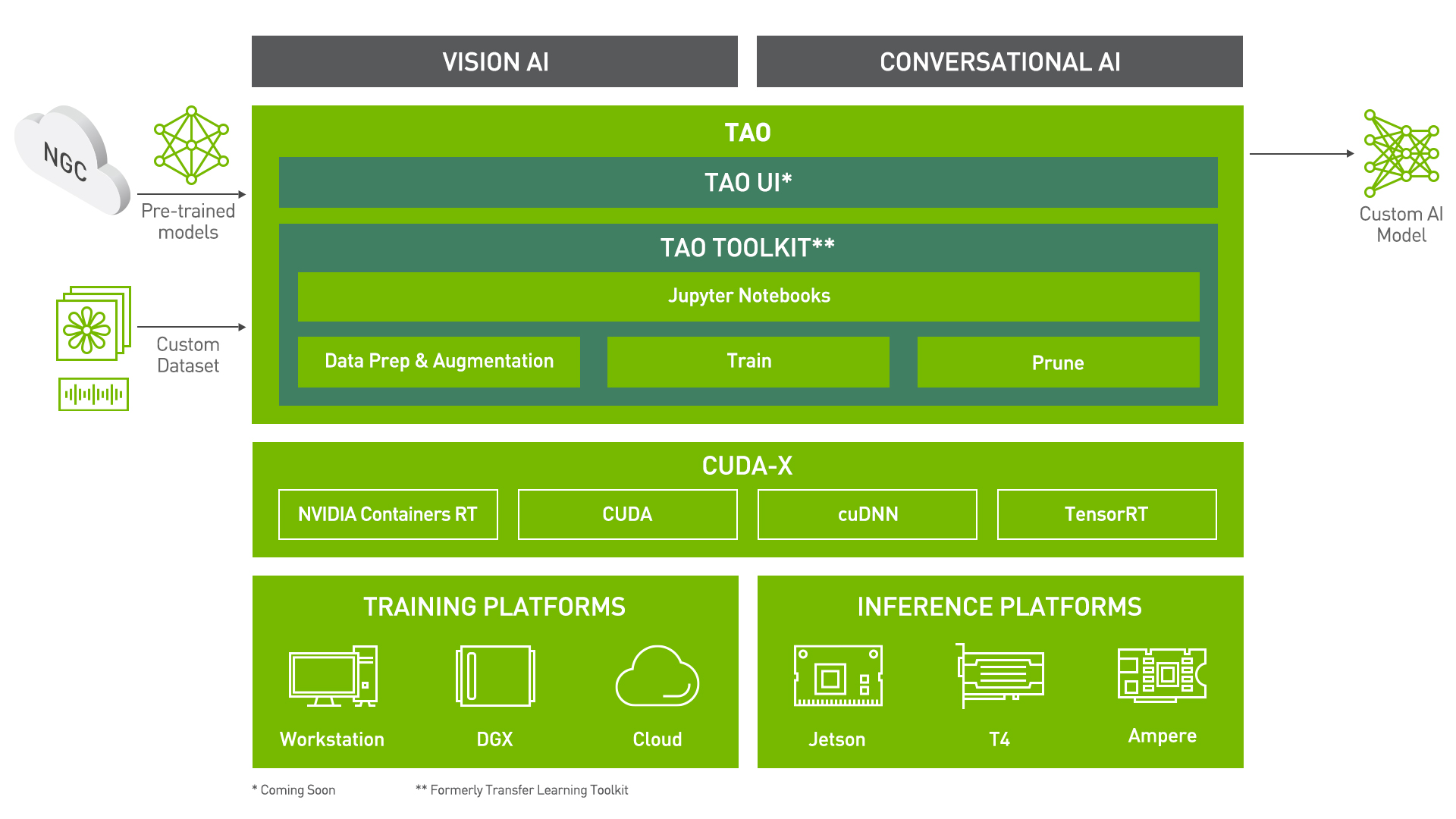
"TAO Toolkit is a python based AI toolkit for taking purpose-built pre-trained AI models and customizing them with your own data. Transfer learning extracts learned features from an existing neural network to a new one. Transfer learning is often used when creating a large training dataset is not feasible in order to enhance the base performance of state-of-the-art models.\n",
"\n",
"For this call center solution, the speech-to-text and sentiment analysis models are fine-tuned on call center data to augment the model performance on business specific terminology.\n",
"\n",
"For more information on the TAO Toolkit, please visit [here](https://developer.nvidia.com/tao)."
]
},
{
"cell_type": "markdown",
"id": "e7512dcc",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"id": "021d5b8c",
"metadata": {},
"source": [
"### Installing necessary dependencies "
]
},
{
"cell_type": "markdown",
"id": "46501bbb",
"metadata": {},
"source": [
"For ease of use, please install TAO Toolkit inside a python virtual environment. We recommend performing this step first and then launching the notebook from the virtual environment. Please refer to the README for these instructions."
]
},
{
"cell_type": "markdown",
"id": "41979a65",
"metadata": {},
"source": [
"## Importing Libraries"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "72eabef5",
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import re\n",
"import glob\n",
"import wave\n",
"import random\n",
"import contextlib\n",
"from tqdm.notebook import tqdm\n",
"\n",
"from utils_TLT import (\n",
" prepare_train_test_manifests,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "c8501e65",
"metadata": {},
"source": [
"Use these constants to affect different aspects of this pipeline:\n",
"- `DATA_DIR`: base folder where data is stored\n",
"- `DATASET_NAME`: name of the dataset\n",
"- `RIVA_MODEL_DIR`: directory where the exported models will be saved (.riva and .rmir)\n",
"- `STT_MODEL_NAME`: name of the speech-to-text model \n",
"- `SEA_MODEL_NAME`: name of the sentiment analysis model \n",
"\n",
"For the variable names, the `STT` tag corresponds to the speech-to-text model, the `SEA` prefix to the sentiment analysis.\n",
"\n",
"#### NOTE: MAKE SURE THESE CONSTANTS ALIGN WITH `Call Center - Sentiment Analysis Pipeline.ipynb`"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "c40c9ad5",
"metadata": {},
"outputs": [],
"source": [
"DATA_DIR = \"data\"\n",
"DATASET_NAME = \"ReleasedDataset_mp3\"\n",
"RIVA_MODEL_DIR = \"/sfl_data/riva/models\"\n",
"\n",
"STT_MODEL_NAME = \"speech-to-text-model.riva\"\n",
"SEA_MODEL_NAME = \"sentiment-analysis-model.riva\""
]
},
{
"cell_type": "markdown",
"id": "280714ed",
"metadata": {},
"source": [
"## Setting up directories "
]
},
{
"cell_type": "markdown",
"id": "d6f90845",
"metadata": {},
"source": [
"After installing TAO Toolkit, the next step is to setup the mounts. The TAO Toolkit launcher uses docker containers under the hood, and **for our data and results directory to be visible to the docker, they need to be mapped**. The launcher can be configured using the config file `~/.tao_mounts.json`. Apart from the mounts, you can also configure additional options like the Environment Variables and amount of Shared Memory available to the TAO Toolkit launcher.
\n",
"\n",
"The code below creates a `~/.tao_mounts.json` file. This maps directories in which we save the data, specs, results and cache. You should configure it for your specific case so these directories are correctly visible to the docker container. The `source` directories are found on the host machine and use the `HOST` tag in the variable names (e.g. `STT_HOST_CONFIG_DIR`). The `destination` directories are found on the docker container created by the TAO Toolkit and use the `TAO` tag in the variable names (e.g. `STT_TAO_CONFIG_DIR`)."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "61101669",
"metadata": {},
"outputs": [],
"source": [
"HOST_DATA_DIR = \"/sfl_data/devs/diego/NetApp_JarvisDemo/data\"\n",
"\n",
"# Speech to Text #\n",
"STT_HOST_CONFIG_DIR = \"/sfl_data/tao/config/speech_to_text\"\n",
"STT_HOST_RESULTS_DIR = \"/sfl_data/tao/results/speech_to_text\"\n",
"STT_HOST_CACHE_DIR = \"/sfl_data/tao/.cache/speech_to_text\"\n",
"\n",
"# Sentiment Analysis #\n",
"SEA_HOST_CONFIG_DIR = \"/sfl_data/tao/config/sentiment_analysis\"\n",
"SEA_HOST_RESULTS_DIR = \"/sfl_data/tao/results/sentiment_analysis\"\n",
"SEA_HOST_CACHE_DIR = \"/sfl_data/tao/.cache/sentiment_analysis\""
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "ec1808f2",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"!mkdir -p $STT_HOST_CONFIG_DIR\n",
"!mkdir -p $STT_HOST_RESULTS_DIR\n",
"!mkdir -p $STT_HOST_CACHE_DIR\n",
"\n",
"!mkdir -p $SEA_HOST_CONFIG_DIR\n",
"!mkdir -p $SEA_HOST_RESULTS_DIR\n",
"!mkdir -p $SEA_HOST_CACHE_DIR"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "22317c8e",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"Mounts\":[\n",
" {\n",
" \"source\": \"/sfl_data/devs/diego/NetApp_JarvisDemo/data\" ,\n",
" \"destination\": \"/data\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/config\" ,\n",
" \"destination\": \"/config\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/results\" ,\n",
" \"destination\": \"/results\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/.cache\",\n",
" \"destination\": \"/root/.cache\"\n",
" }\n",
" ],\n",
" \"DockerOptions\": {\n",
" \"shm_size\": \"128G\",\n",
" \"ulimits\": {\n",
" \"memlock\": -1,\n",
" \"stack\": 67108864\n",
" }\n",
" }\n",
"}\n"
]
}
],
"source": [
"%%bash\n",
"tee ~/.tao_mounts.json <<'EOF'\n",
"{\n",
" \"Mounts\":[\n",
" {\n",
" \"source\": \"/sfl_data/devs/diego/NetApp_JarvisDemo/data\" ,\n",
" \"destination\": \"/data\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/config\" ,\n",
" \"destination\": \"/config\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/results\" ,\n",
" \"destination\": \"/results\"\n",
" },\n",
" {\n",
" \"source\": \"/sfl_data/tao/.cache\",\n",
" \"destination\": \"/root/.cache\"\n",
" }\n",
" ],\n",
" \"DockerOptions\": {\n",
" \"shm_size\": \"128G\",\n",
" \"ulimits\": {\n",
" \"memlock\": -1,\n",
" \"stack\": 67108864\n",
" }\n",
" }\n",
"}\n",
"EOF"
]
},
{
"cell_type": "markdown",
"id": "248d5ffd",
"metadata": {},
"source": [
"Check if the GPUs are available using the `nvidia-smi` command."
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "875ff314",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Mon Sep 20 17:01:21 2021 \n",
"+-----------------------------------------------------------------------------+\n",
"| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |\n",
"|-------------------------------+----------------------+----------------------+\n",
"| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n",
"| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\n",
"| | | MIG M. |\n",
"|===============================+======================+======================|\n",
"| 0 Tesla V100-SXM2... On | 00000000:06:00.0 Off | 0 |\n",
"| N/A 37C P0 82W / 300W | 7670MiB / 32510MiB | 48% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 1 Tesla V100-SXM2... On | 00000000:07:00.0 Off | 0 |\n",
"| N/A 35C P0 44W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 2 Tesla V100-SXM2... On | 00000000:0A:00.0 Off | 0 |\n",
"| N/A 35C P0 43W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 3 Tesla V100-SXM2... On | 00000000:0B:00.0 Off | 0 |\n",
"| N/A 32C P0 44W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 4 Tesla V100-SXM2... On | 00000000:85:00.0 Off | 0 |\n",
"| N/A 33C P0 44W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 5 Tesla V100-SXM2... On | 00000000:86:00.0 Off | 0 |\n",
"| N/A 36C P0 45W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 6 Tesla V100-SXM2... On | 00000000:89:00.0 Off | 0 |\n",
"| N/A 36C P0 45W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
"| 7 Tesla V100-SXM2... On | 00000000:8A:00.0 Off | 0 |\n",
"| N/A 35C P0 42W / 300W | 0MiB / 32510MiB | 0% Default |\n",
"| | | N/A |\n",
"+-------------------------------+----------------------+----------------------+\n",
" \n",
"+-----------------------------------------------------------------------------+\n",
"| Processes: |\n",
"| GPU GI CI PID Type Process name GPU Memory |\n",
"| ID ID Usage |\n",
"|=============================================================================|\n",
"| 0 N/A N/A 1994212 C tritonserver 7667MiB |\n",
"+-----------------------------------------------------------------------------+\n"
]
}
],
"source": [
"!nvidia-smi"
]
},
{
"cell_type": "markdown",
"id": "725e6eb8",
"metadata": {},
"source": [
"You can check the docker image versions and the tasks that TAO Toolkit can perform with `tao --help` or `tao info`."
]
},
{
"cell_type": "markdown",
"id": "7e93fd26",
"metadata": {},
"source": [
"# [NetApp DataOps Toolkit](https://github.com/NetApp/netapp-dataops-toolkit)\n",
"\n",
"The massive volume of calls that a call center must process on a daily basis means that a database can be quickly overwhelmed by audio files. Efficiently managing the processing and transfer of these audio files is an integral part of the model training and fine-tuning.\n",
"\n",
"The data processing steps can be facilitated through the use of the **NetApp DataOps Toolkit**. This toolkit is a Python library that makes it simple for developers, data scientists, DevOps engineers, and data engineers to perform various data management tasks, such as provisioning a new data volume, near-instantaneously cloning a data volume, and near-instantaneously snapshotting a data volume for traceability/baselining. \n",
"\n",
"Installation and usage of the **NetApp DataOps Toolkit** for Traditional Environments requires that Python 3.6 or above be installed on the local host. Additionally, the toolkit requires that pip for Python3 be installed.\n",
"\n",
"For more information on the **NetApp DataOps Toolkit**, click [here](https://github.com/NetApp/netapp-dataops-toolkit)."
]
},
{
"cell_type": "markdown",
"id": "82dacc79",
"metadata": {},
"source": [
"To install the **NetApp DataOps Toolkit** for Traditional Environments, run the following command.\n",
"\n",
"```\n",
"python3 -m pip install netapp-dataops-traditional\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "40d4b869",
"metadata": {},
"source": [
"A config file must be created before the **NetApp DataOps Toolkit** for Traditional Environments can be used to perform data management operations. To create a config file, run the following command. This command will create a config file named 'config.json' in '~/.netapp_dataops/'.\n",
"\n",
"```\n",
"netapp_dataops_cli.py config\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "26967d0f",
"metadata": {},
"source": [
"# Speech-to-Text\n",
"\n",
"The speech-to-text (or Automatic Speech Recognition) is a part of NVIDIA's TAO Conversational AI Toolkit. This Toolkit can train models for common conversational AI tasks such as text classification, question answering, speech recognition, and more.\n",
"\n",
"For an overview of the Conversational AI Toolkit, click [here](https://ngc.nvidia.com/catalog/collections/nvidia:tao:tao_conversationalai)."
]
},
{
"cell_type": "markdown",
"id": "55ececfc",
"metadata": {},
"source": [
"### Set TAO Toolkit Paths\n",
"\n",
"`NOTE`: The following paths are set from the perspective of the TAO Toolkit Docker."
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "e0dfa808",
"metadata": {},
"outputs": [],
"source": [
"# the data directory structure is based off main_RIVA.ipynb\n",
"# the config and results are manually created\n",
"STT_TAO_DATA_DIR = \"/data\"\n",
"STT_TAO_CONFIG_DIR = \"/config/speech_to_text\"\n",
"STT_TAO_RESULTS_DIR = \"/results/speech_to_text\"\n",
"\n",
"# The encryption key from config.sh. Use the same key for all commands\n",
"KEY = 'tlt_encode'"
]
},
{
"cell_type": "markdown",
"id": "a9740a38",
"metadata": {},
"source": [
"### Downloading Specs\n",
"\n",
"TAO's Conversational AI Toolkit works off of spec files which make it easy to edit hyperparameters on the fly. We can proceed to downloading the spec files. The user may choose to modify/rewrite these specs, or even individually override them through the launcher. You can download the default spec files by using the download_specs command.\n",
"\n",
"The -o argument indicating the folder where the default configuration files will be downloaded, and -r that instructs the script where to save the logs. Make sure the -o points to an empty folder, otherwise the config files will not be downloaded. If you have already downloaded the config files, then this command will not overwrite them.\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "086ab781",
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2021-09-20 17:01:22,711 [INFO] root: Registry: ['nvcr.io']\n",
"2021-09-20 17:01:22,804 [WARNING] tlt.components.docker_handler.docker_handler: \n",
"Docker will run the commands as root. If you would like to retain your\n",
"local host permissions, please add the \"user\":\"UID:GID\" in the\n",
"DockerOptions portion of the \"/root/.tao_mounts.json\" file. You can obtain your\n",
"users UID and GID by using the \"id -u\" and \"id -g\" commands on the\n",
"terminal.\n",
"[NeMo W 2021-09-20 21:01:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[nltk_data] Downloading package averaged_perceptron_tagger to\n",
"[nltk_data] /root/nltk_data...\n",
"[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.\n",
"[nltk_data] Downloading package cmudict to /root/nltk_data...\n",
"[nltk_data] Unzipping corpora/cmudict.zip.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:27 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo I 2021-09-20 21:01:29 tlt_logging:20] Experiment configuration:\n",
" exp_manager:\n",
" task_name: download_specs\n",
" explicit_log_dir: /results/speech_to_text\n",
" source_data_dir: /opt/conda/lib/python3.8/site-packages/asr/speech_to_text/experiment_specs\n",
" target_data_dir: /config/speech_to_text\n",
" workflow: asr\n",
" \n",
"[NeMo W 2021-09-20 21:01:29 exp_manager:26] Exp_manager is logging to `/results/speech_to_text``, but it already exists.\n",
"Traceback (most recent call last):\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 198, in run_and_report\n",
" return func()\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 347, in \n",
" lambda: hydra.run(\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/_internal/hydra.py\", line 107, in run\n",
" return run_job(\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/core/utils.py\", line 127, in run_job\n",
" ret.return_value = task_function(task_cfg)\n",
" File \"/tlt-nemo/tlt_utils/download_specs.py\", line 59, in main\n",
"FileExistsError: The target directory `/config/speech_to_text` is not empty!\n",
"In order to avoid overriding the existing spec files please point to a different folder.\n",
"\n",
"During handling of the above exception, another exception occurred:\n",
"\n",
"Traceback (most recent call last):\n",
" File \"/tlt-nemo/tlt_utils/download_specs.py\", line 78, in \n",
" File \"/opt/conda/lib/python3.8/site-packages/nemo/core/config/hydra_runner.py\", line 98, in wrapper\n",
" _run_hydra(\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 346, in _run_hydra\n",
" run_and_report(\n",
" File \"/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 237, in run_and_report\n",
" assert mdl is not None\n",
"AssertionError\n",
"2021-09-20 17:01:30,776 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.\n"
]
}
],
"source": [
"!tao speech_to_text download_specs \\\n",
" -r $STT_TAO_RESULTS_DIR \\\n",
" -o $STT_TAO_CONFIG_DIR"
]
},
{
"cell_type": "markdown",
"id": "fa100b28",
"metadata": {},
"source": [
"### Overwrite Specs\n",
"\n",
"The default speech-to-text specs are built for translation into the Russian language. `finetune.yaml` must be overwritten for the pipeline to work in English.\n",
"\n",
"`NOTE`: **THE PATH TO `finetune.yaml` MUST ALIGN WITH `STT_HOST_CONFIG_DIR`**. If you change the `STT_HOST_CONFIG_DIR`, make sure you change the path between `tee` and `<<`."
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "dc93b8bd",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'/sfl_data/tao/config/speech_to_text'"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"STT_HOST_CONFIG_DIR"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "4739d8df",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"trainer:\n",
" max_epochs: 1 # This is low for demo purposes\n",
"\n",
"# Whether or not to change the decoder vocabulary.\n",
"# Note that this MUST be set if the labels change, e.g. to a different language's character set\n",
"# or if additional punctuation characters are added.\n",
"change_vocabulary: true\n",
"\n",
"# Fine-tuning settings: training dataset\n",
"finetuning_ds:\n",
" manifest_filepath: ???\n",
" sample_rate: 16000\n",
" labels: [\" \", \"a\", \"b\", \"c\", \"d\", \"e\", \"f\", \"g\", \"h\", \"i\", \"j\", \"k\", \"l\", \"m\",\n",
" \"n\", \"o\", \"p\", \"q\", \"r\", \"s\", \"t\", \"u\", \"v\", \"w\", \"x\", \"y\", \"z\", \"'\"]\n",
" batch_size: 16\n",
" trim_silence: false\n",
" max_duration: 16.7\n",
" shuffle: true\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
"\n",
"# Fine-tuning settings: validation dataset\n",
"validation_ds:\n",
" manifest_filepath: ???\n",
" sample_rate: 16000\n",
" labels: [\" \", \"a\", \"b\", \"c\", \"d\", \"e\", \"f\", \"g\", \"h\", \"i\", \"j\", \"k\", \"l\", \"m\",\n",
" \"n\", \"o\", \"p\", \"q\", \"r\", \"s\", \"t\", \"u\", \"v\", \"w\", \"x\", \"y\", \"z\", \"'\"]\n",
" batch_size: 32\n",
" shuffle: false\n",
"\n",
"# Fine-tuning settings: optimizer\n",
"optim:\n",
" name: novograd\n",
" lr: 0.001\n"
]
}
],
"source": [
"%%bash\n",
"tee /sfl_data/tao/config/speech_to_text/finetune.yaml <<'EOF'\n",
"\n",
"trainer:\n",
" max_epochs: 1 # This is low for demo purposes\n",
"\n",
"# Whether or not to change the decoder vocabulary.\n",
"# Note that this MUST be set if the labels change, e.g. to a different language's character set\n",
"# or if additional punctuation characters are added.\n",
"change_vocabulary: true\n",
"\n",
"# Fine-tuning settings: training dataset\n",
"finetuning_ds:\n",
" manifest_filepath: ???\n",
" sample_rate: 16000\n",
" labels: [\" \", \"a\", \"b\", \"c\", \"d\", \"e\", \"f\", \"g\", \"h\", \"i\", \"j\", \"k\", \"l\", \"m\",\n",
" \"n\", \"o\", \"p\", \"q\", \"r\", \"s\", \"t\", \"u\", \"v\", \"w\", \"x\", \"y\", \"z\", \"'\"]\n",
" batch_size: 16\n",
" trim_silence: false\n",
" max_duration: 16.7\n",
" shuffle: true\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
"\n",
"# Fine-tuning settings: validation dataset\n",
"validation_ds:\n",
" manifest_filepath: ???\n",
" sample_rate: 16000\n",
" labels: [\" \", \"a\", \"b\", \"c\", \"d\", \"e\", \"f\", \"g\", \"h\", \"i\", \"j\", \"k\", \"l\", \"m\",\n",
" \"n\", \"o\", \"p\", \"q\", \"r\", \"s\", \"t\", \"u\", \"v\", \"w\", \"x\", \"y\", \"z\", \"'\"]\n",
" batch_size: 32\n",
" shuffle: false\n",
"\n",
"# Fine-tuning settings: optimizer\n",
"optim:\n",
" name: novograd\n",
" lr: 0.001\n",
"EOF"
]
},
{
"cell_type": "markdown",
"id": "4044712c",
"metadata": {},
"source": [
"## Training\n",
"\n",
"Download the Jasper pretrained model [here](https://ngc.nvidia.com/catalog/models/nvidia:tlt-jarvis:speechtotext_english_jasper/files). The wget command below has been modified to automatically save the model in its target location (`STT_HOST_CONFIG_DIR`). Note that the pretrained model only needs to be downloaded once."
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "caa791f6",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"if not os.path.exists(os.path.join(STT_HOST_CONFIG_DIR, \"speechtotext_english_jasper.tlt\")):\n",
" !wget -O $STT_HOST_CONFIG_DIR/speechtotext_english_jasper.tlt https://api.ngc.nvidia.com/v2/models/nvidia/tlt-jarvis/speechtotext_english_jasper/versions/trainable_v1.2/files/speechtotext_english_jasper.tlt"
]
},
{
"cell_type": "markdown",
"id": "a3c61a29",
"metadata": {},
"source": [
"## Fine-Tuning"
]
},
{
"cell_type": "markdown",
"id": "96fb21a0",
"metadata": {},
"source": [
"Before fine-tuning, we need to create a manifest for the train and test sets. There are a handful of parameters used to create this manifest:\n",
"- `N_SAMPLE`: number of calls to sample\n",
"- `MAX_DURATION`: maximum duration for the WAV files (for Jasper, 16.7 is the maximum)\n",
"- `SET_SIZES`: dictionary of set sizes (must include \"train\", \"valid\" and \"test\")\n",
"- `COMPANY_BLACKLIST`: blacklist of files to remove"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "16e9a9e1",
"metadata": {},
"outputs": [],
"source": [
"COMPANY_BLACKLIST = [\n",
" \"Hormel Foods Corp._20170223\",\n",
" \"Kraft Heinz Co_20170503\",\n",
" \"Amazon.com Inc._20170202\",\n",
" \"Vulcan Materials_20170802\",\n",
" \"Masco Corp._20171024\",\n",
" \"Fortive Corp_20170207\",\n",
" \"Salesforce.com_20170228\",\n",
" \"Home Depot_20170516\",\n",
" \"Hasbro Inc._20170206\",\n",
" \"Exxon Mobil Corp._20171027\",\n",
" \"Biogen Inc._20170126\",\n",
" \"Goodyear Tire & Rubber_20170428\",\n",
" \"Alaska Air Group Inc_20171025\",\n",
" \"FleetCor Technologies Inc_20170803\",\n",
" \"Roper Technologies_20170209\",\n",
" \"Foot Locker Inc_20170224\",\n",
" \"Starbucks Corp._20170126\",\n",
" \"Dover Corp._20170720\",\n",
" \"Xerox_20170801\",\n",
" \"AT&T Inc._2017042\",\n",
" \"AT&T Inc._20170425\",\n",
" \"Salesforce.com_20170822\",\n",
" \"Varian Medical Systems_20171025\",\n",
"]\n",
"\n",
"N_SAMPLE = 200\n",
"MAX_DURATION = 16.7\n",
"SET_SIZES = {\n",
" \"train\": 0.75,\n",
" \"valid\": 0.20,\n",
" \"test\": 0.05,\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "0ae696bf",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "79672da05e1f448fb4d23165ee902cde",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/200 [00:00 is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[nltk_data] Downloading package averaged_perceptron_tagger to\n",
"[nltk_data] /root/nltk_data...\n",
"[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.\n",
"[nltk_data] Downloading package cmudict to /root/nltk_data...\n",
"[nltk_data] Unzipping corpora/cmudict.zip.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:55 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:56 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:57 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:01:59 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo I 2021-09-20 21:02:00 tlt_logging:20] Experiment configuration:\n",
" restore_from: /config/speech_to_text/speechtotext_english_jasper.tlt\n",
" save_to: ???\n",
" exp_manager:\n",
" explicit_log_dir: /results/speech_to_text/finetune\n",
" exp_dir: null\n",
" name: finetuned-model\n",
" version: null\n",
" use_datetime_version: true\n",
" resume_if_exists: true\n",
" resume_past_end: false\n",
" resume_ignore_no_checkpoint: true\n",
" create_tensorboard_logger: false\n",
" summary_writer_kwargs: null\n",
" create_wandb_logger: false\n",
" wandb_logger_kwargs: null\n",
" create_checkpoint_callback: true\n",
" checkpoint_callback_params:\n",
" filepath: null\n",
" monitor: val_loss\n",
" verbose: true\n",
" save_last: true\n",
" save_top_k: 3\n",
" save_weights_only: false\n",
" mode: auto\n",
" period: 1\n",
" prefix: null\n",
" postfix: .tlt\n",
" save_best_model: false\n",
" files_to_copy: null\n",
" trainer:\n",
" logger: false\n",
" checkpoint_callback: false\n",
" callbacks: null\n",
" default_root_dir: null\n",
" gradient_clip_val: 0.0\n",
" process_position: 0\n",
" num_nodes: 1\n",
" num_processes: 1\n",
" gpus: 1\n",
" auto_select_gpus: false\n",
" tpu_cores: null\n",
" log_gpu_memory: null\n",
" progress_bar_refresh_rate: 1\n",
" overfit_batches: 0.0\n",
" track_grad_norm: -1\n",
" check_val_every_n_epoch: 1\n",
" fast_dev_run: false\n",
" accumulate_grad_batches: 1\n",
" max_epochs: 20\n",
" min_epochs: 1\n",
" max_steps: null\n",
" min_steps: null\n",
" limit_train_batches: 1.0\n",
" limit_val_batches: 1.0\n",
" limit_test_batches: 1.0\n",
" val_check_interval: 1.0\n",
" flush_logs_every_n_steps: 100\n",
" log_every_n_steps: 50\n",
" accelerator: ddp\n",
" sync_batchnorm: false\n",
" precision: 32\n",
" weights_summary: full\n",
" weights_save_path: null\n",
" num_sanity_val_steps: 2\n",
" truncated_bptt_steps: null\n",
" resume_from_checkpoint: null\n",
" profiler: null\n",
" benchmark: false\n",
" deterministic: false\n",
" reload_dataloaders_every_epoch: false\n",
" auto_lr_find: false\n",
" replace_sampler_ddp: true\n",
" terminate_on_nan: false\n",
" auto_scale_batch_size: false\n",
" prepare_data_per_node: true\n",
" amp_backend: native\n",
" amp_level: O0\n",
" change_vocabulary: true\n",
" finetuning_ds:\n",
" manifest_filepath: /config/speech_to_text/train_manifest.json\n",
" batch_size: 16\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: true\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" validation_ds:\n",
" manifest_filepath: /config/speech_to_text/valid_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: false\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" optim:\n",
" name: novograd\n",
" lr: 0.001\n",
" encryption_key: '*******'\n",
" tlt_checkpoint_interval: 0\n",
" \n",
"GPU available: True, used: True\n",
"GPU available: True, used: True\n",
"TPU available: None, using: 0 TPU cores\n",
"TPU available: None, using: 0 TPU cores\n",
"LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]\n",
"LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]\n",
"[NeMo W 2021-09-20 21:02:00 exp_manager:380] Exp_manager is logging to /results/speech_to_text/finetune, but it already exists.\n",
"[NeMo I 2021-09-20 21:02:00 exp_manager:328] Resuming from /results/speech_to_text/finetune/checkpoints/finetuned-model-last.ckpt\n",
"[NeMo I 2021-09-20 21:02:00 exp_manager:194] Experiments will be logged at /results/speech_to_text/finetune\n",
"[NeMo W 2021-09-20 21:02:01 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/distributed.py:49: UserWarning: Checkpoint directory /results/speech_to_text/finetune/checkpoints exists and is not empty.\n",
" warnings.warn(*args, **kwargs)\n",
" \n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"[NeMo W 2021-09-20 21:02:10 modelPT:145] Please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.\n",
" Train config : \n",
" manifest_filepath: /data/fisher_min5sec/small_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: null\n",
" trim_silence: true\n",
" shuffle: true\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo W 2021-09-20 21:02:10 modelPT:152] Please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s). \n",
" Validation config : \n",
" manifest_filepath: /data/fisher_min5sec/small_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: null\n",
" trim_silence: true\n",
" shuffle: false\n",
" max_duration: null\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo I 2021-09-20 21:02:10 features:236] PADDING: 16\n",
"[NeMo I 2021-09-20 21:02:10 features:252] STFT using torch\n",
"[NeMo I 2021-09-20 21:02:45 finetune:119] Model restored from '/config/speech_to_text/speechtotext_english_jasper.tlt'\n",
"[NeMo W 2021-09-20 21:02:45 ctc_models:216] Old [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', \"'\"] and new [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', \"'\"] match. Not changing anything.\n",
"[NeMo I 2021-09-20 21:02:46 collections:173] Dataset loaded with 18073 files totalling 45.33 hours\n",
"[NeMo I 2021-09-20 21:02:46 collections:174] 0 files were filtered totalling 0.00 hours\n",
"[NeMo I 2021-09-20 21:02:47 collections:173] Dataset loaded with 4341 files totalling 11.13 hours\n",
"[NeMo I 2021-09-20 21:02:47 collections:174] 0 files were filtered totalling 0.00 hours\n",
"[NeMo I 2021-09-20 21:02:47 modelPT:753] Optimizer config = Novograd (\n",
" Parameter Group 0\n",
" amsgrad: False\n",
" betas: (0.95, 0.98)\n",
" eps: 1e-08\n",
" grad_averaging: False\n",
" lr: 0.001\n",
" weight_decay: 0\n",
" )\n",
"[NeMo I 2021-09-20 21:02:47 lr_scheduler:492] Scheduler not initialized as no `sched` config supplied to setup_optimizer()\n",
"initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/1\n",
"initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/1\n",
"Added key: store_based_barrier_key:1 to store for rank: 0\n",
"[NeMo I 2021-09-20 21:02:47 modelPT:753] Optimizer config = Novograd (\n",
" Parameter Group 0\n",
" amsgrad: False\n",
" betas: (0.95, 0.98)\n",
" eps: 1e-08\n",
" grad_averaging: False\n",
" lr: 0.001\n",
" weight_decay: 0\n",
" )\n",
"[NeMo I 2021-09-20 21:02:47 lr_scheduler:492] Scheduler not initialized as no `sched` config supplied to setup_optimizer()\n",
"\n",
" | Name | Type | Params\n",
"-----------------------------------------------------------------------------------------\n",
"0 | preprocessor | AudioToMelSpectrogramPreprocessor | 0 \n",
"1 | preprocessor.featurizer | FilterbankFeatures | 0 \n",
"2 | encoder | ConvASREncoder | 332 M \n",
"3 | encoder.encoder | Sequential | 332 M \n",
"4 | encoder.encoder.0 | JasperBlock | 180 K \n",
"5 | encoder.encoder.0.mconv | ModuleList | 180 K \n",
"6 | encoder.encoder.0.mconv.0 | MaskedConv1d | 180 K \n",
"7 | encoder.encoder.0.mconv.0.conv | Conv1d | 180 K \n",
"8 | encoder.encoder.0.mconv.1 | BatchNorm1d | 512 \n",
"9 | encoder.encoder.0.mout | Sequential | 0 \n",
"10 | encoder.encoder.0.mout.0 | ReLU | 0 \n",
"11 | encoder.encoder.0.mout.1 | Dropout | 0 \n",
"12 | encoder.encoder.1 | JasperBlock | 3.7 M \n",
"13 | encoder.encoder.1.mconv | ModuleList | 3.6 M \n",
"14 | encoder.encoder.1.mconv.0 | MaskedConv1d | 720 K \n",
"15 | encoder.encoder.1.mconv.0.conv | Conv1d | 720 K \n",
"16 | encoder.encoder.1.mconv.1 | BatchNorm1d | 512 \n",
"17 | encoder.encoder.1.mconv.3 | Dropout | 0 \n",
"18 | encoder.encoder.1.mconv.4 | MaskedConv1d | 720 K \n",
"19 | encoder.encoder.1.mconv.4.conv | Conv1d | 720 K \n",
"20 | encoder.encoder.1.mconv.5 | BatchNorm1d | 512 \n",
"21 | encoder.encoder.1.mconv.7 | Dropout | 0 \n",
"22 | encoder.encoder.1.mconv.8 | MaskedConv1d | 720 K \n",
"23 | encoder.encoder.1.mconv.8.conv | Conv1d | 720 K \n",
"24 | encoder.encoder.1.mconv.9 | BatchNorm1d | 512 \n",
"25 | encoder.encoder.1.mconv.11 | Dropout | 0 \n",
"26 | encoder.encoder.1.mconv.12 | MaskedConv1d | 720 K \n",
"27 | encoder.encoder.1.mconv.12.conv | Conv1d | 720 K \n",
"28 | encoder.encoder.1.mconv.13 | BatchNorm1d | 512 \n",
"29 | encoder.encoder.1.mconv.15 | Dropout | 0 \n",
"30 | encoder.encoder.1.mconv.16 | MaskedConv1d | 720 K \n",
"31 | encoder.encoder.1.mconv.16.conv | Conv1d | 720 K \n",
"32 | encoder.encoder.1.mconv.17 | BatchNorm1d | 512 \n",
"33 | encoder.encoder.1.res | ModuleList | 66.0 K\n",
"34 | encoder.encoder.1.res.0 | ModuleList | 66.0 K\n",
"35 | encoder.encoder.1.res.0.0 | MaskedConv1d | 65.5 K\n",
"36 | encoder.encoder.1.res.0.0.conv | Conv1d | 65.5 K\n",
"37 | encoder.encoder.1.res.0.1 | BatchNorm1d | 512 \n",
"38 | encoder.encoder.1.mout | Sequential | 0 \n",
"39 | encoder.encoder.1.mout.1 | Dropout | 0 \n",
"40 | encoder.encoder.2 | JasperBlock | 3.7 M \n",
"41 | encoder.encoder.2.mconv | ModuleList | 3.6 M \n",
"42 | encoder.encoder.2.mconv.0 | MaskedConv1d | 720 K \n",
"43 | encoder.encoder.2.mconv.0.conv | Conv1d | 720 K \n",
"44 | encoder.encoder.2.mconv.1 | BatchNorm1d | 512 \n",
"45 | encoder.encoder.2.mconv.3 | Dropout | 0 \n",
"46 | encoder.encoder.2.mconv.4 | MaskedConv1d | 720 K \n",
"47 | encoder.encoder.2.mconv.4.conv | Conv1d | 720 K \n",
"48 | encoder.encoder.2.mconv.5 | BatchNorm1d | 512 \n",
"49 | encoder.encoder.2.mconv.7 | Dropout | 0 \n",
"50 | encoder.encoder.2.mconv.8 | MaskedConv1d | 720 K \n",
"51 | encoder.encoder.2.mconv.8.conv | Conv1d | 720 K \n",
"52 | encoder.encoder.2.mconv.9 | BatchNorm1d | 512 \n",
"53 | encoder.encoder.2.mconv.11 | Dropout | 0 \n",
"54 | encoder.encoder.2.mconv.12 | MaskedConv1d | 720 K \n",
"55 | encoder.encoder.2.mconv.12.conv | Conv1d | 720 K \n",
"56 | encoder.encoder.2.mconv.13 | BatchNorm1d | 512 \n",
"57 | encoder.encoder.2.mconv.15 | Dropout | 0 \n",
"58 | encoder.encoder.2.mconv.16 | MaskedConv1d | 720 K \n",
"59 | encoder.encoder.2.mconv.16.conv | Conv1d | 720 K \n",
"60 | encoder.encoder.2.mconv.17 | BatchNorm1d | 512 \n",
"61 | encoder.encoder.2.res | ModuleList | 132 K \n",
"62 | encoder.encoder.2.res.0 | ModuleList | 66.0 K\n",
"63 | encoder.encoder.2.res.0.0 | MaskedConv1d | 65.5 K\n",
"64 | encoder.encoder.2.res.0.0.conv | Conv1d | 65.5 K\n",
"65 | encoder.encoder.2.res.0.1 | BatchNorm1d | 512 \n",
"66 | encoder.encoder.2.res.1 | ModuleList | 66.0 K\n",
"67 | encoder.encoder.2.res.1.0 | MaskedConv1d | 65.5 K\n",
"68 | encoder.encoder.2.res.1.0.conv | Conv1d | 65.5 K\n",
"69 | encoder.encoder.2.res.1.1 | BatchNorm1d | 512 \n",
"70 | encoder.encoder.2.mout | Sequential | 0 \n",
"71 | encoder.encoder.2.mout.1 | Dropout | 0 \n",
"72 | encoder.encoder.3 | JasperBlock | 9.2 M \n",
"73 | encoder.encoder.3.mconv | ModuleList | 8.9 M \n",
"74 | encoder.encoder.3.mconv.0 | MaskedConv1d | 1.3 M \n",
"75 | encoder.encoder.3.mconv.0.conv | Conv1d | 1.3 M \n",
"76 | encoder.encoder.3.mconv.1 | BatchNorm1d | 768 \n",
"77 | encoder.encoder.3.mconv.3 | Dropout | 0 \n",
"78 | encoder.encoder.3.mconv.4 | MaskedConv1d | 1.9 M \n",
"79 | encoder.encoder.3.mconv.4.conv | Conv1d | 1.9 M \n",
"80 | encoder.encoder.3.mconv.5 | BatchNorm1d | 768 \n",
"81 | encoder.encoder.3.mconv.7 | Dropout | 0 \n",
"82 | encoder.encoder.3.mconv.8 | MaskedConv1d | 1.9 M \n",
"83 | encoder.encoder.3.mconv.8.conv | Conv1d | 1.9 M \n",
"84 | encoder.encoder.3.mconv.9 | BatchNorm1d | 768 \n",
"85 | encoder.encoder.3.mconv.11 | Dropout | 0 \n",
"86 | encoder.encoder.3.mconv.12 | MaskedConv1d | 1.9 M \n",
"87 | encoder.encoder.3.mconv.12.conv | Conv1d | 1.9 M \n",
"88 | encoder.encoder.3.mconv.13 | BatchNorm1d | 768 \n",
"89 | encoder.encoder.3.mconv.15 | Dropout | 0 \n",
"90 | encoder.encoder.3.mconv.16 | MaskedConv1d | 1.9 M \n",
"91 | encoder.encoder.3.mconv.16.conv | Conv1d | 1.9 M \n",
"92 | encoder.encoder.3.mconv.17 | BatchNorm1d | 768 \n",
"93 | encoder.encoder.3.res | ModuleList | 297 K \n",
"94 | encoder.encoder.3.res.0 | ModuleList | 99.1 K\n",
"95 | encoder.encoder.3.res.0.0 | MaskedConv1d | 98.3 K\n",
"96 | encoder.encoder.3.res.0.0.conv | Conv1d | 98.3 K\n",
"97 | encoder.encoder.3.res.0.1 | BatchNorm1d | 768 \n",
"98 | encoder.encoder.3.res.1 | ModuleList | 99.1 K\n",
"99 | encoder.encoder.3.res.1.0 | MaskedConv1d | 98.3 K\n",
"100 | encoder.encoder.3.res.1.0.conv | Conv1d | 98.3 K\n",
"101 | encoder.encoder.3.res.1.1 | BatchNorm1d | 768 \n",
"102 | encoder.encoder.3.res.2 | ModuleList | 99.1 K\n",
"103 | encoder.encoder.3.res.2.0 | MaskedConv1d | 98.3 K\n",
"104 | encoder.encoder.3.res.2.0.conv | Conv1d | 98.3 K\n",
"105 | encoder.encoder.3.res.2.1 | BatchNorm1d | 768 \n",
"106 | encoder.encoder.3.mout | Sequential | 0 \n",
"107 | encoder.encoder.3.mout.1 | Dropout | 0 \n",
"108 | encoder.encoder.4 | JasperBlock | 10.0 M\n",
"109 | encoder.encoder.4.mconv | ModuleList | 9.6 M \n",
"110 | encoder.encoder.4.mconv.0 | MaskedConv1d | 1.9 M \n",
"111 | encoder.encoder.4.mconv.0.conv | Conv1d | 1.9 M \n",
"112 | encoder.encoder.4.mconv.1 | BatchNorm1d | 768 \n",
"113 | encoder.encoder.4.mconv.3 | Dropout | 0 \n",
"114 | encoder.encoder.4.mconv.4 | MaskedConv1d | 1.9 M \n",
"115 | encoder.encoder.4.mconv.4.conv | Conv1d | 1.9 M \n",
"116 | encoder.encoder.4.mconv.5 | BatchNorm1d | 768 \n",
"117 | encoder.encoder.4.mconv.7 | Dropout | 0 \n",
"118 | encoder.encoder.4.mconv.8 | MaskedConv1d | 1.9 M \n",
"119 | encoder.encoder.4.mconv.8.conv | Conv1d | 1.9 M \n",
"120 | encoder.encoder.4.mconv.9 | BatchNorm1d | 768 \n",
"121 | encoder.encoder.4.mconv.11 | Dropout | 0 \n",
"122 | encoder.encoder.4.mconv.12 | MaskedConv1d | 1.9 M \n",
"123 | encoder.encoder.4.mconv.12.conv | Conv1d | 1.9 M \n",
"124 | encoder.encoder.4.mconv.13 | BatchNorm1d | 768 \n",
"125 | encoder.encoder.4.mconv.15 | Dropout | 0 \n",
"126 | encoder.encoder.4.mconv.16 | MaskedConv1d | 1.9 M \n",
"127 | encoder.encoder.4.mconv.16.conv | Conv1d | 1.9 M \n",
"128 | encoder.encoder.4.mconv.17 | BatchNorm1d | 768 \n",
"129 | encoder.encoder.4.res | ModuleList | 445 K \n",
"130 | encoder.encoder.4.res.0 | ModuleList | 99.1 K\n",
"131 | encoder.encoder.4.res.0.0 | MaskedConv1d | 98.3 K\n",
"132 | encoder.encoder.4.res.0.0.conv | Conv1d | 98.3 K\n",
"133 | encoder.encoder.4.res.0.1 | BatchNorm1d | 768 \n",
"134 | encoder.encoder.4.res.1 | ModuleList | 99.1 K\n",
"135 | encoder.encoder.4.res.1.0 | MaskedConv1d | 98.3 K\n",
"136 | encoder.encoder.4.res.1.0.conv | Conv1d | 98.3 K\n",
"137 | encoder.encoder.4.res.1.1 | BatchNorm1d | 768 \n",
"138 | encoder.encoder.4.res.2 | ModuleList | 99.1 K\n",
"139 | encoder.encoder.4.res.2.0 | MaskedConv1d | 98.3 K\n",
"140 | encoder.encoder.4.res.2.0.conv | Conv1d | 98.3 K\n",
"141 | encoder.encoder.4.res.2.1 | BatchNorm1d | 768 \n",
"142 | encoder.encoder.4.res.3 | ModuleList | 148 K \n",
"143 | encoder.encoder.4.res.3.0 | MaskedConv1d | 147 K \n",
"144 | encoder.encoder.4.res.3.0.conv | Conv1d | 147 K \n",
"145 | encoder.encoder.4.res.3.1 | BatchNorm1d | 768 \n",
"146 | encoder.encoder.4.mout | Sequential | 0 \n",
"147 | encoder.encoder.4.mout.1 | Dropout | 0 \n",
"148 | encoder.encoder.5 | JasperBlock | 22.0 M\n",
"149 | encoder.encoder.5.mconv | ModuleList | 21.2 M\n",
"150 | encoder.encoder.5.mconv.0 | MaskedConv1d | 3.3 M \n",
"151 | encoder.encoder.5.mconv.0.conv | Conv1d | 3.3 M \n",
"152 | encoder.encoder.5.mconv.1 | BatchNorm1d | 1.0 K \n",
"153 | encoder.encoder.5.mconv.3 | Dropout | 0 \n",
"154 | encoder.encoder.5.mconv.4 | MaskedConv1d | 4.5 M \n",
"155 | encoder.encoder.5.mconv.4.conv | Conv1d | 4.5 M \n",
"156 | encoder.encoder.5.mconv.5 | BatchNorm1d | 1.0 K \n",
"157 | encoder.encoder.5.mconv.7 | Dropout | 0 \n",
"158 | encoder.encoder.5.mconv.8 | MaskedConv1d | 4.5 M \n",
"159 | encoder.encoder.5.mconv.8.conv | Conv1d | 4.5 M \n",
"160 | encoder.encoder.5.mconv.9 | BatchNorm1d | 1.0 K \n",
"161 | encoder.encoder.5.mconv.11 | Dropout | 0 \n",
"162 | encoder.encoder.5.mconv.12 | MaskedConv1d | 4.5 M \n",
"163 | encoder.encoder.5.mconv.12.conv | Conv1d | 4.5 M \n",
"164 | encoder.encoder.5.mconv.13 | BatchNorm1d | 1.0 K \n",
"165 | encoder.encoder.5.mconv.15 | Dropout | 0 \n",
"166 | encoder.encoder.5.mconv.16 | MaskedConv1d | 4.5 M \n",
"167 | encoder.encoder.5.mconv.16.conv | Conv1d | 4.5 M \n",
"168 | encoder.encoder.5.mconv.17 | BatchNorm1d | 1.0 K \n",
"169 | encoder.encoder.5.res | ModuleList | 791 K \n",
"170 | encoder.encoder.5.res.0 | ModuleList | 132 K \n",
"171 | encoder.encoder.5.res.0.0 | MaskedConv1d | 131 K \n",
"172 | encoder.encoder.5.res.0.0.conv | Conv1d | 131 K \n",
"173 | encoder.encoder.5.res.0.1 | BatchNorm1d | 1.0 K \n",
"174 | encoder.encoder.5.res.1 | ModuleList | 132 K \n",
"175 | encoder.encoder.5.res.1.0 | MaskedConv1d | 131 K \n",
"176 | encoder.encoder.5.res.1.0.conv | Conv1d | 131 K \n",
"177 | encoder.encoder.5.res.1.1 | BatchNorm1d | 1.0 K \n",
"178 | encoder.encoder.5.res.2 | ModuleList | 132 K \n",
"179 | encoder.encoder.5.res.2.0 | MaskedConv1d | 131 K \n",
"180 | encoder.encoder.5.res.2.0.conv | Conv1d | 131 K \n",
"181 | encoder.encoder.5.res.2.1 | BatchNorm1d | 1.0 K \n",
"182 | encoder.encoder.5.res.3 | ModuleList | 197 K \n",
"183 | encoder.encoder.5.res.3.0 | MaskedConv1d | 196 K \n",
"184 | encoder.encoder.5.res.3.0.conv | Conv1d | 196 K \n",
"185 | encoder.encoder.5.res.3.1 | BatchNorm1d | 1.0 K \n",
"186 | encoder.encoder.5.res.4 | ModuleList | 197 K \n",
"187 | encoder.encoder.5.res.4.0 | MaskedConv1d | 196 K \n",
"188 | encoder.encoder.5.res.4.0.conv | Conv1d | 196 K \n",
"189 | encoder.encoder.5.res.4.1 | BatchNorm1d | 1.0 K \n",
"190 | encoder.encoder.5.mout | Sequential | 0 \n",
"191 | encoder.encoder.5.mout.1 | Dropout | 0 \n",
"192 | encoder.encoder.6 | JasperBlock | 23.3 M\n",
"193 | encoder.encoder.6.mconv | ModuleList | 22.3 M\n",
"194 | encoder.encoder.6.mconv.0 | MaskedConv1d | 4.5 M \n",
"195 | encoder.encoder.6.mconv.0.conv | Conv1d | 4.5 M \n",
"196 | encoder.encoder.6.mconv.1 | BatchNorm1d | 1.0 K \n",
"197 | encoder.encoder.6.mconv.3 | Dropout | 0 \n",
"198 | encoder.encoder.6.mconv.4 | MaskedConv1d | 4.5 M \n",
"199 | encoder.encoder.6.mconv.4.conv | Conv1d | 4.5 M \n",
"200 | encoder.encoder.6.mconv.5 | BatchNorm1d | 1.0 K \n",
"201 | encoder.encoder.6.mconv.7 | Dropout | 0 \n",
"202 | encoder.encoder.6.mconv.8 | MaskedConv1d | 4.5 M \n",
"203 | encoder.encoder.6.mconv.8.conv | Conv1d | 4.5 M \n",
"204 | encoder.encoder.6.mconv.9 | BatchNorm1d | 1.0 K \n",
"205 | encoder.encoder.6.mconv.11 | Dropout | 0 \n",
"206 | encoder.encoder.6.mconv.12 | MaskedConv1d | 4.5 M \n",
"207 | encoder.encoder.6.mconv.12.conv | Conv1d | 4.5 M \n",
"208 | encoder.encoder.6.mconv.13 | BatchNorm1d | 1.0 K \n",
"209 | encoder.encoder.6.mconv.15 | Dropout | 0 \n",
"210 | encoder.encoder.6.mconv.16 | MaskedConv1d | 4.5 M \n",
"211 | encoder.encoder.6.mconv.16.conv | Conv1d | 4.5 M \n",
"212 | encoder.encoder.6.mconv.17 | BatchNorm1d | 1.0 K \n",
"213 | encoder.encoder.6.res | ModuleList | 1.1 M \n",
"214 | encoder.encoder.6.res.0 | ModuleList | 132 K \n",
"215 | encoder.encoder.6.res.0.0 | MaskedConv1d | 131 K \n",
"216 | encoder.encoder.6.res.0.0.conv | Conv1d | 131 K \n",
"217 | encoder.encoder.6.res.0.1 | BatchNorm1d | 1.0 K \n",
"218 | encoder.encoder.6.res.1 | ModuleList | 132 K \n",
"219 | encoder.encoder.6.res.1.0 | MaskedConv1d | 131 K \n",
"220 | encoder.encoder.6.res.1.0.conv | Conv1d | 131 K \n",
"221 | encoder.encoder.6.res.1.1 | BatchNorm1d | 1.0 K \n",
"222 | encoder.encoder.6.res.2 | ModuleList | 132 K \n",
"223 | encoder.encoder.6.res.2.0 | MaskedConv1d | 131 K \n",
"224 | encoder.encoder.6.res.2.0.conv | Conv1d | 131 K \n",
"225 | encoder.encoder.6.res.2.1 | BatchNorm1d | 1.0 K \n",
"226 | encoder.encoder.6.res.3 | ModuleList | 197 K \n",
"227 | encoder.encoder.6.res.3.0 | MaskedConv1d | 196 K \n",
"228 | encoder.encoder.6.res.3.0.conv | Conv1d | 196 K \n",
"229 | encoder.encoder.6.res.3.1 | BatchNorm1d | 1.0 K \n",
"230 | encoder.encoder.6.res.4 | ModuleList | 197 K \n",
"231 | encoder.encoder.6.res.4.0 | MaskedConv1d | 196 K \n",
"232 | encoder.encoder.6.res.4.0.conv | Conv1d | 196 K \n",
"233 | encoder.encoder.6.res.4.1 | BatchNorm1d | 1.0 K \n",
"234 | encoder.encoder.6.res.5 | ModuleList | 263 K \n",
"235 | encoder.encoder.6.res.5.0 | MaskedConv1d | 262 K \n",
"236 | encoder.encoder.6.res.5.0.conv | Conv1d | 262 K \n",
"237 | encoder.encoder.6.res.5.1 | BatchNorm1d | 1.0 K \n",
"238 | encoder.encoder.6.mout | Sequential | 0 \n",
"239 | encoder.encoder.6.mout.1 | Dropout | 0 \n",
"240 | encoder.encoder.7 | JasperBlock | 42.9 M\n",
"241 | encoder.encoder.7.mconv | ModuleList | 41.3 M\n",
"242 | encoder.encoder.7.mconv.0 | MaskedConv1d | 6.9 M \n",
"243 | encoder.encoder.7.mconv.0.conv | Conv1d | 6.9 M \n",
"244 | encoder.encoder.7.mconv.1 | BatchNorm1d | 1.3 K \n",
"245 | encoder.encoder.7.mconv.3 | Dropout | 0 \n",
"246 | encoder.encoder.7.mconv.4 | MaskedConv1d | 8.6 M \n",
"247 | encoder.encoder.7.mconv.4.conv | Conv1d | 8.6 M \n",
"248 | encoder.encoder.7.mconv.5 | BatchNorm1d | 1.3 K \n",
"249 | encoder.encoder.7.mconv.7 | Dropout | 0 \n",
"250 | encoder.encoder.7.mconv.8 | MaskedConv1d | 8.6 M \n",
"251 | encoder.encoder.7.mconv.8.conv | Conv1d | 8.6 M \n",
"252 | encoder.encoder.7.mconv.9 | BatchNorm1d | 1.3 K \n",
"253 | encoder.encoder.7.mconv.11 | Dropout | 0 \n",
"254 | encoder.encoder.7.mconv.12 | MaskedConv1d | 8.6 M \n",
"255 | encoder.encoder.7.mconv.12.conv | Conv1d | 8.6 M \n",
"256 | encoder.encoder.7.mconv.13 | BatchNorm1d | 1.3 K \n",
"257 | encoder.encoder.7.mconv.15 | Dropout | 0 \n",
"258 | encoder.encoder.7.mconv.16 | MaskedConv1d | 8.6 M \n",
"259 | encoder.encoder.7.mconv.16.conv | Conv1d | 8.6 M \n",
"260 | encoder.encoder.7.mconv.17 | BatchNorm1d | 1.3 K \n",
"261 | encoder.encoder.7.res | ModuleList | 1.6 M \n",
"262 | encoder.encoder.7.res.0 | ModuleList | 165 K \n",
"263 | encoder.encoder.7.res.0.0 | MaskedConv1d | 163 K \n",
"264 | encoder.encoder.7.res.0.0.conv | Conv1d | 163 K \n",
"265 | encoder.encoder.7.res.0.1 | BatchNorm1d | 1.3 K \n",
"266 | encoder.encoder.7.res.1 | ModuleList | 165 K \n",
"267 | encoder.encoder.7.res.1.0 | MaskedConv1d | 163 K \n",
"268 | encoder.encoder.7.res.1.0.conv | Conv1d | 163 K \n",
"269 | encoder.encoder.7.res.1.1 | BatchNorm1d | 1.3 K \n",
"270 | encoder.encoder.7.res.2 | ModuleList | 165 K \n",
"271 | encoder.encoder.7.res.2.0 | MaskedConv1d | 163 K \n",
"272 | encoder.encoder.7.res.2.0.conv | Conv1d | 163 K \n",
"273 | encoder.encoder.7.res.2.1 | BatchNorm1d | 1.3 K \n",
"274 | encoder.encoder.7.res.3 | ModuleList | 247 K \n",
"275 | encoder.encoder.7.res.3.0 | MaskedConv1d | 245 K \n",
"276 | encoder.encoder.7.res.3.0.conv | Conv1d | 245 K \n",
"277 | encoder.encoder.7.res.3.1 | BatchNorm1d | 1.3 K \n",
"278 | encoder.encoder.7.res.4 | ModuleList | 247 K \n",
"279 | encoder.encoder.7.res.4.0 | MaskedConv1d | 245 K \n",
"280 | encoder.encoder.7.res.4.0.conv | Conv1d | 245 K \n",
"281 | encoder.encoder.7.res.4.1 | BatchNorm1d | 1.3 K \n",
"282 | encoder.encoder.7.res.5 | ModuleList | 328 K \n",
"283 | encoder.encoder.7.res.5.0 | MaskedConv1d | 327 K \n",
"284 | encoder.encoder.7.res.5.0.conv | Conv1d | 327 K \n",
"285 | encoder.encoder.7.res.5.1 | BatchNorm1d | 1.3 K \n",
"286 | encoder.encoder.7.res.6 | ModuleList | 328 K \n",
"287 | encoder.encoder.7.res.6.0 | MaskedConv1d | 327 K \n",
"288 | encoder.encoder.7.res.6.0.conv | Conv1d | 327 K \n",
"289 | encoder.encoder.7.res.6.1 | BatchNorm1d | 1.3 K \n",
"290 | encoder.encoder.7.mout | Sequential | 0 \n",
"291 | encoder.encoder.7.mout.1 | Dropout | 0 \n",
"292 | encoder.encoder.8 | JasperBlock | 45.1 M\n",
"293 | encoder.encoder.8.mconv | ModuleList | 43.0 M\n",
"294 | encoder.encoder.8.mconv.0 | MaskedConv1d | 8.6 M \n",
"295 | encoder.encoder.8.mconv.0.conv | Conv1d | 8.6 M \n",
"296 | encoder.encoder.8.mconv.1 | BatchNorm1d | 1.3 K \n",
"297 | encoder.encoder.8.mconv.3 | Dropout | 0 \n",
"298 | encoder.encoder.8.mconv.4 | MaskedConv1d | 8.6 M \n",
"299 | encoder.encoder.8.mconv.4.conv | Conv1d | 8.6 M \n",
"300 | encoder.encoder.8.mconv.5 | BatchNorm1d | 1.3 K \n",
"301 | encoder.encoder.8.mconv.7 | Dropout | 0 \n",
"302 | encoder.encoder.8.mconv.8 | MaskedConv1d | 8.6 M \n",
"303 | encoder.encoder.8.mconv.8.conv | Conv1d | 8.6 M \n",
"304 | encoder.encoder.8.mconv.9 | BatchNorm1d | 1.3 K \n",
"305 | encoder.encoder.8.mconv.11 | Dropout | 0 \n",
"306 | encoder.encoder.8.mconv.12 | MaskedConv1d | 8.6 M \n",
"307 | encoder.encoder.8.mconv.12.conv | Conv1d | 8.6 M \n",
"308 | encoder.encoder.8.mconv.13 | BatchNorm1d | 1.3 K \n",
"309 | encoder.encoder.8.mconv.15 | Dropout | 0 \n",
"310 | encoder.encoder.8.mconv.16 | MaskedConv1d | 8.6 M \n",
"311 | encoder.encoder.8.mconv.16.conv | Conv1d | 8.6 M \n",
"312 | encoder.encoder.8.mconv.17 | BatchNorm1d | 1.3 K \n",
"313 | encoder.encoder.8.res | ModuleList | 2.1 M \n",
"314 | encoder.encoder.8.res.0 | ModuleList | 165 K \n",
"315 | encoder.encoder.8.res.0.0 | MaskedConv1d | 163 K \n",
"316 | encoder.encoder.8.res.0.0.conv | Conv1d | 163 K \n",
"317 | encoder.encoder.8.res.0.1 | BatchNorm1d | 1.3 K \n",
"318 | encoder.encoder.8.res.1 | ModuleList | 165 K \n",
"319 | encoder.encoder.8.res.1.0 | MaskedConv1d | 163 K \n",
"320 | encoder.encoder.8.res.1.0.conv | Conv1d | 163 K \n",
"321 | encoder.encoder.8.res.1.1 | BatchNorm1d | 1.3 K \n",
"322 | encoder.encoder.8.res.2 | ModuleList | 165 K \n",
"323 | encoder.encoder.8.res.2.0 | MaskedConv1d | 163 K \n",
"324 | encoder.encoder.8.res.2.0.conv | Conv1d | 163 K \n",
"325 | encoder.encoder.8.res.2.1 | BatchNorm1d | 1.3 K \n",
"326 | encoder.encoder.8.res.3 | ModuleList | 247 K \n",
"327 | encoder.encoder.8.res.3.0 | MaskedConv1d | 245 K \n",
"328 | encoder.encoder.8.res.3.0.conv | Conv1d | 245 K \n",
"329 | encoder.encoder.8.res.3.1 | BatchNorm1d | 1.3 K \n",
"330 | encoder.encoder.8.res.4 | ModuleList | 247 K \n",
"331 | encoder.encoder.8.res.4.0 | MaskedConv1d | 245 K \n",
"332 | encoder.encoder.8.res.4.0.conv | Conv1d | 245 K \n",
"333 | encoder.encoder.8.res.4.1 | BatchNorm1d | 1.3 K \n",
"334 | encoder.encoder.8.res.5 | ModuleList | 328 K \n",
"335 | encoder.encoder.8.res.5.0 | MaskedConv1d | 327 K \n",
"336 | encoder.encoder.8.res.5.0.conv | Conv1d | 327 K \n",
"337 | encoder.encoder.8.res.5.1 | BatchNorm1d | 1.3 K \n",
"338 | encoder.encoder.8.res.6 | ModuleList | 328 K \n",
"339 | encoder.encoder.8.res.6.0 | MaskedConv1d | 327 K \n",
"340 | encoder.encoder.8.res.6.0.conv | Conv1d | 327 K \n",
"341 | encoder.encoder.8.res.6.1 | BatchNorm1d | 1.3 K \n",
"342 | encoder.encoder.8.res.7 | ModuleList | 410 K \n",
"343 | encoder.encoder.8.res.7.0 | MaskedConv1d | 409 K \n",
"344 | encoder.encoder.8.res.7.0.conv | Conv1d | 409 K \n",
"345 | encoder.encoder.8.res.7.1 | BatchNorm1d | 1.3 K \n",
"346 | encoder.encoder.8.mout | Sequential | 0 \n",
"347 | encoder.encoder.8.mout.1 | Dropout | 0 \n",
"348 | encoder.encoder.9 | JasperBlock | 74.2 M\n",
"349 | encoder.encoder.9.mconv | ModuleList | 71.3 M\n",
"350 | encoder.encoder.9.mconv.0 | MaskedConv1d | 12.3 M\n",
"351 | encoder.encoder.9.mconv.0.conv | Conv1d | 12.3 M\n",
"352 | encoder.encoder.9.mconv.1 | BatchNorm1d | 1.5 K \n",
"353 | encoder.encoder.9.mconv.3 | Dropout | 0 \n",
"354 | encoder.encoder.9.mconv.4 | MaskedConv1d | 14.7 M\n",
"355 | encoder.encoder.9.mconv.4.conv | Conv1d | 14.7 M\n",
"356 | encoder.encoder.9.mconv.5 | BatchNorm1d | 1.5 K \n",
"357 | encoder.encoder.9.mconv.7 | Dropout | 0 \n",
"358 | encoder.encoder.9.mconv.8 | MaskedConv1d | 14.7 M\n",
"359 | encoder.encoder.9.mconv.8.conv | Conv1d | 14.7 M\n",
"360 | encoder.encoder.9.mconv.9 | BatchNorm1d | 1.5 K \n",
"361 | encoder.encoder.9.mconv.11 | Dropout | 0 \n",
"362 | encoder.encoder.9.mconv.12 | MaskedConv1d | 14.7 M\n",
"363 | encoder.encoder.9.mconv.12.conv | Conv1d | 14.7 M\n",
"364 | encoder.encoder.9.mconv.13 | BatchNorm1d | 1.5 K \n",
"365 | encoder.encoder.9.mconv.15 | Dropout | 0 \n",
"366 | encoder.encoder.9.mconv.16 | MaskedConv1d | 14.7 M\n",
"367 | encoder.encoder.9.mconv.16.conv | Conv1d | 14.7 M\n",
"368 | encoder.encoder.9.mconv.17 | BatchNorm1d | 1.5 K \n",
"369 | encoder.encoder.9.res | ModuleList | 3.0 M \n",
"370 | encoder.encoder.9.res.0 | ModuleList | 198 K \n",
"371 | encoder.encoder.9.res.0.0 | MaskedConv1d | 196 K \n",
"372 | encoder.encoder.9.res.0.0.conv | Conv1d | 196 K \n",
"373 | encoder.encoder.9.res.0.1 | BatchNorm1d | 1.5 K \n",
"374 | encoder.encoder.9.res.1 | ModuleList | 198 K \n",
"375 | encoder.encoder.9.res.1.0 | MaskedConv1d | 196 K \n",
"376 | encoder.encoder.9.res.1.0.conv | Conv1d | 196 K \n",
"377 | encoder.encoder.9.res.1.1 | BatchNorm1d | 1.5 K \n",
"378 | encoder.encoder.9.res.2 | ModuleList | 198 K \n",
"379 | encoder.encoder.9.res.2.0 | MaskedConv1d | 196 K \n",
"380 | encoder.encoder.9.res.2.0.conv | Conv1d | 196 K \n",
"381 | encoder.encoder.9.res.2.1 | BatchNorm1d | 1.5 K \n",
"382 | encoder.encoder.9.res.3 | ModuleList | 296 K \n",
"383 | encoder.encoder.9.res.3.0 | MaskedConv1d | 294 K \n",
"384 | encoder.encoder.9.res.3.0.conv | Conv1d | 294 K \n",
"385 | encoder.encoder.9.res.3.1 | BatchNorm1d | 1.5 K \n",
"386 | encoder.encoder.9.res.4 | ModuleList | 296 K \n",
"387 | encoder.encoder.9.res.4.0 | MaskedConv1d | 294 K \n",
"388 | encoder.encoder.9.res.4.0.conv | Conv1d | 294 K \n",
"389 | encoder.encoder.9.res.4.1 | BatchNorm1d | 1.5 K \n",
"390 | encoder.encoder.9.res.5 | ModuleList | 394 K \n",
"391 | encoder.encoder.9.res.5.0 | MaskedConv1d | 393 K \n",
"392 | encoder.encoder.9.res.5.0.conv | Conv1d | 393 K \n",
"393 | encoder.encoder.9.res.5.1 | BatchNorm1d | 1.5 K \n",
"394 | encoder.encoder.9.res.6 | ModuleList | 394 K \n",
"395 | encoder.encoder.9.res.6.0 | MaskedConv1d | 393 K \n",
"396 | encoder.encoder.9.res.6.0.conv | Conv1d | 393 K \n",
"397 | encoder.encoder.9.res.6.1 | BatchNorm1d | 1.5 K \n",
"398 | encoder.encoder.9.res.7 | ModuleList | 493 K \n",
"399 | encoder.encoder.9.res.7.0 | MaskedConv1d | 491 K \n",
"400 | encoder.encoder.9.res.7.0.conv | Conv1d | 491 K \n",
"401 | encoder.encoder.9.res.7.1 | BatchNorm1d | 1.5 K \n",
"402 | encoder.encoder.9.res.8 | ModuleList | 493 K \n",
"403 | encoder.encoder.9.res.8.0 | MaskedConv1d | 491 K \n",
"404 | encoder.encoder.9.res.8.0.conv | Conv1d | 491 K \n",
"405 | encoder.encoder.9.res.8.1 | BatchNorm1d | 1.5 K \n",
"406 | encoder.encoder.9.mout | Sequential | 0 \n",
"407 | encoder.encoder.9.mout.1 | Dropout | 0 \n",
"408 | encoder.encoder.10 | JasperBlock | 77.3 M\n",
"409 | encoder.encoder.10.mconv | ModuleList | 73.7 M\n",
"410 | encoder.encoder.10.mconv.0 | MaskedConv1d | 14.7 M\n",
"411 | encoder.encoder.10.mconv.0.conv | Conv1d | 14.7 M\n",
"412 | encoder.encoder.10.mconv.1 | BatchNorm1d | 1.5 K \n",
"413 | encoder.encoder.10.mconv.3 | Dropout | 0 \n",
"414 | encoder.encoder.10.mconv.4 | MaskedConv1d | 14.7 M\n",
"415 | encoder.encoder.10.mconv.4.conv | Conv1d | 14.7 M\n",
"416 | encoder.encoder.10.mconv.5 | BatchNorm1d | 1.5 K \n",
"417 | encoder.encoder.10.mconv.7 | Dropout | 0 \n",
"418 | encoder.encoder.10.mconv.8 | MaskedConv1d | 14.7 M\n",
"419 | encoder.encoder.10.mconv.8.conv | Conv1d | 14.7 M\n",
"420 | encoder.encoder.10.mconv.9 | BatchNorm1d | 1.5 K \n",
"421 | encoder.encoder.10.mconv.11 | Dropout | 0 \n",
"422 | encoder.encoder.10.mconv.12 | MaskedConv1d | 14.7 M\n",
"423 | encoder.encoder.10.mconv.12.conv | Conv1d | 14.7 M\n",
"424 | encoder.encoder.10.mconv.13 | BatchNorm1d | 1.5 K \n",
"425 | encoder.encoder.10.mconv.15 | Dropout | 0 \n",
"426 | encoder.encoder.10.mconv.16 | MaskedConv1d | 14.7 M\n",
"427 | encoder.encoder.10.mconv.16.conv | Conv1d | 14.7 M\n",
"428 | encoder.encoder.10.mconv.17 | BatchNorm1d | 1.5 K \n",
"429 | encoder.encoder.10.res | ModuleList | 3.6 M \n",
"430 | encoder.encoder.10.res.0 | ModuleList | 198 K \n",
"431 | encoder.encoder.10.res.0.0 | MaskedConv1d | 196 K \n",
"432 | encoder.encoder.10.res.0.0.conv | Conv1d | 196 K \n",
"433 | encoder.encoder.10.res.0.1 | BatchNorm1d | 1.5 K \n",
"434 | encoder.encoder.10.res.1 | ModuleList | 198 K \n",
"435 | encoder.encoder.10.res.1.0 | MaskedConv1d | 196 K \n",
"436 | encoder.encoder.10.res.1.0.conv | Conv1d | 196 K \n",
"437 | encoder.encoder.10.res.1.1 | BatchNorm1d | 1.5 K \n",
"438 | encoder.encoder.10.res.2 | ModuleList | 198 K \n",
"439 | encoder.encoder.10.res.2.0 | MaskedConv1d | 196 K \n",
"440 | encoder.encoder.10.res.2.0.conv | Conv1d | 196 K \n",
"441 | encoder.encoder.10.res.2.1 | BatchNorm1d | 1.5 K \n",
"442 | encoder.encoder.10.res.3 | ModuleList | 296 K \n",
"443 | encoder.encoder.10.res.3.0 | MaskedConv1d | 294 K \n",
"444 | encoder.encoder.10.res.3.0.conv | Conv1d | 294 K \n",
"445 | encoder.encoder.10.res.3.1 | BatchNorm1d | 1.5 K \n",
"446 | encoder.encoder.10.res.4 | ModuleList | 296 K \n",
"447 | encoder.encoder.10.res.4.0 | MaskedConv1d | 294 K \n",
"448 | encoder.encoder.10.res.4.0.conv | Conv1d | 294 K \n",
"449 | encoder.encoder.10.res.4.1 | BatchNorm1d | 1.5 K \n",
"450 | encoder.encoder.10.res.5 | ModuleList | 394 K \n",
"451 | encoder.encoder.10.res.5.0 | MaskedConv1d | 393 K \n",
"452 | encoder.encoder.10.res.5.0.conv | Conv1d | 393 K \n",
"453 | encoder.encoder.10.res.5.1 | BatchNorm1d | 1.5 K \n",
"454 | encoder.encoder.10.res.6 | ModuleList | 394 K \n",
"455 | encoder.encoder.10.res.6.0 | MaskedConv1d | 393 K \n",
"456 | encoder.encoder.10.res.6.0.conv | Conv1d | 393 K \n",
"457 | encoder.encoder.10.res.6.1 | BatchNorm1d | 1.5 K \n",
"458 | encoder.encoder.10.res.7 | ModuleList | 493 K \n",
"459 | encoder.encoder.10.res.7.0 | MaskedConv1d | 491 K \n",
"460 | encoder.encoder.10.res.7.0.conv | Conv1d | 491 K \n",
"461 | encoder.encoder.10.res.7.1 | BatchNorm1d | 1.5 K \n",
"462 | encoder.encoder.10.res.8 | ModuleList | 493 K \n",
"463 | encoder.encoder.10.res.8.0 | MaskedConv1d | 491 K \n",
"464 | encoder.encoder.10.res.8.0.conv | Conv1d | 491 K \n",
"465 | encoder.encoder.10.res.8.1 | BatchNorm1d | 1.5 K \n",
"466 | encoder.encoder.10.res.9 | ModuleList | 591 K \n",
"467 | encoder.encoder.10.res.9.0 | MaskedConv1d | 589 K \n",
"468 | encoder.encoder.10.res.9.0.conv | Conv1d | 589 K \n",
"469 | encoder.encoder.10.res.9.1 | BatchNorm1d | 1.5 K \n",
"470 | encoder.encoder.10.mout | Sequential | 0 \n",
"471 | encoder.encoder.10.mout.1 | Dropout | 0 \n",
"472 | encoder.encoder.11 | JasperBlock | 20.0 M\n",
"473 | encoder.encoder.11.mconv | ModuleList | 20.0 M\n",
"474 | encoder.encoder.11.mconv.0 | MaskedConv1d | 20.0 M\n",
"475 | encoder.encoder.11.mconv.0.conv | Conv1d | 20.0 M\n",
"476 | encoder.encoder.11.mconv.1 | BatchNorm1d | 1.8 K \n",
"477 | encoder.encoder.11.mout | Sequential | 0 \n",
"478 | encoder.encoder.11.mout.1 | Dropout | 0 \n",
"479 | encoder.encoder.12 | JasperBlock | 919 K \n",
"480 | encoder.encoder.12.mconv | ModuleList | 919 K \n",
"481 | encoder.encoder.12.mconv.0 | MaskedConv1d | 917 K \n",
"482 | encoder.encoder.12.mconv.0.conv | Conv1d | 917 K \n",
"483 | encoder.encoder.12.mconv.1 | BatchNorm1d | 2.0 K \n",
"484 | encoder.encoder.12.mout | Sequential | 0 \n",
"485 | encoder.encoder.12.mout.1 | Dropout | 0 \n",
"486 | decoder | ConvASRDecoder | 29.7 K\n",
"487 | decoder.decoder_layers | Sequential | 29.7 K\n",
"488 | decoder.decoder_layers.0 | Conv1d | 29.7 K\n",
"489 | loss | CTCLoss | 0 \n",
"490 | spec_augmentation | SpectrogramAugmentation | 0 \n",
"491 | spec_augmentation.spec_cutout | SpecCutout | 0 \n",
"492 | _wer | WER | 0 \n",
"-----------------------------------------------------------------------------------------\n",
"332 M Trainable params\n",
"0 Non-trainable params\n",
"332 M Total params\n",
"\n",
" | Name | Type | Params\n",
"-----------------------------------------------------------------------------------------\n",
"0 | preprocessor | AudioToMelSpectrogramPreprocessor | 0 \n",
"1 | preprocessor.featurizer | FilterbankFeatures | 0 \n",
"2 | encoder | ConvASREncoder | 332 M \n",
"3 | encoder.encoder | Sequential | 332 M \n",
"4 | encoder.encoder.0 | JasperBlock | 180 K \n",
"5 | encoder.encoder.0.mconv | ModuleList | 180 K \n",
"6 | encoder.encoder.0.mconv.0 | MaskedConv1d | 180 K \n",
"7 | encoder.encoder.0.mconv.0.conv | Conv1d | 180 K \n",
"8 | encoder.encoder.0.mconv.1 | BatchNorm1d | 512 \n",
"9 | encoder.encoder.0.mout | Sequential | 0 \n",
"10 | encoder.encoder.0.mout.0 | ReLU | 0 \n",
"11 | encoder.encoder.0.mout.1 | Dropout | 0 \n",
"12 | encoder.encoder.1 | JasperBlock | 3.7 M \n",
"13 | encoder.encoder.1.mconv | ModuleList | 3.6 M \n",
"14 | encoder.encoder.1.mconv.0 | MaskedConv1d | 720 K \n",
"15 | encoder.encoder.1.mconv.0.conv | Conv1d | 720 K \n",
"16 | encoder.encoder.1.mconv.1 | BatchNorm1d | 512 \n",
"17 | encoder.encoder.1.mconv.3 | Dropout | 0 \n",
"18 | encoder.encoder.1.mconv.4 | MaskedConv1d | 720 K \n",
"19 | encoder.encoder.1.mconv.4.conv | Conv1d | 720 K \n",
"20 | encoder.encoder.1.mconv.5 | BatchNorm1d | 512 \n",
"21 | encoder.encoder.1.mconv.7 | Dropout | 0 \n",
"22 | encoder.encoder.1.mconv.8 | MaskedConv1d | 720 K \n",
"23 | encoder.encoder.1.mconv.8.conv | Conv1d | 720 K \n",
"24 | encoder.encoder.1.mconv.9 | BatchNorm1d | 512 \n",
"25 | encoder.encoder.1.mconv.11 | Dropout | 0 \n",
"26 | encoder.encoder.1.mconv.12 | MaskedConv1d | 720 K \n",
"27 | encoder.encoder.1.mconv.12.conv | Conv1d | 720 K \n",
"28 | encoder.encoder.1.mconv.13 | BatchNorm1d | 512 \n",
"29 | encoder.encoder.1.mconv.15 | Dropout | 0 \n",
"30 | encoder.encoder.1.mconv.16 | MaskedConv1d | 720 K \n",
"31 | encoder.encoder.1.mconv.16.conv | Conv1d | 720 K \n",
"32 | encoder.encoder.1.mconv.17 | BatchNorm1d | 512 \n",
"33 | encoder.encoder.1.res | ModuleList | 66.0 K\n",
"34 | encoder.encoder.1.res.0 | ModuleList | 66.0 K\n",
"35 | encoder.encoder.1.res.0.0 | MaskedConv1d | 65.5 K\n",
"36 | encoder.encoder.1.res.0.0.conv | Conv1d | 65.5 K\n",
"37 | encoder.encoder.1.res.0.1 | BatchNorm1d | 512 \n",
"38 | encoder.encoder.1.mout | Sequential | 0 \n",
"39 | encoder.encoder.1.mout.1 | Dropout | 0 \n",
"40 | encoder.encoder.2 | JasperBlock | 3.7 M \n",
"41 | encoder.encoder.2.mconv | ModuleList | 3.6 M \n",
"42 | encoder.encoder.2.mconv.0 | MaskedConv1d | 720 K \n",
"43 | encoder.encoder.2.mconv.0.conv | Conv1d | 720 K \n",
"44 | encoder.encoder.2.mconv.1 | BatchNorm1d | 512 \n",
"45 | encoder.encoder.2.mconv.3 | Dropout | 0 \n",
"46 | encoder.encoder.2.mconv.4 | MaskedConv1d | 720 K \n",
"47 | encoder.encoder.2.mconv.4.conv | Conv1d | 720 K \n",
"48 | encoder.encoder.2.mconv.5 | BatchNorm1d | 512 \n",
"49 | encoder.encoder.2.mconv.7 | Dropout | 0 \n",
"50 | encoder.encoder.2.mconv.8 | MaskedConv1d | 720 K \n",
"51 | encoder.encoder.2.mconv.8.conv | Conv1d | 720 K \n",
"52 | encoder.encoder.2.mconv.9 | BatchNorm1d | 512 \n",
"53 | encoder.encoder.2.mconv.11 | Dropout | 0 \n",
"54 | encoder.encoder.2.mconv.12 | MaskedConv1d | 720 K \n",
"55 | encoder.encoder.2.mconv.12.conv | Conv1d | 720 K \n",
"56 | encoder.encoder.2.mconv.13 | BatchNorm1d | 512 \n",
"57 | encoder.encoder.2.mconv.15 | Dropout | 0 \n",
"58 | encoder.encoder.2.mconv.16 | MaskedConv1d | 720 K \n",
"59 | encoder.encoder.2.mconv.16.conv | Conv1d | 720 K \n",
"60 | encoder.encoder.2.mconv.17 | BatchNorm1d | 512 \n",
"61 | encoder.encoder.2.res | ModuleList | 132 K \n",
"62 | encoder.encoder.2.res.0 | ModuleList | 66.0 K\n",
"63 | encoder.encoder.2.res.0.0 | MaskedConv1d | 65.5 K\n",
"64 | encoder.encoder.2.res.0.0.conv | Conv1d | 65.5 K\n",
"65 | encoder.encoder.2.res.0.1 | BatchNorm1d | 512 \n",
"66 | encoder.encoder.2.res.1 | ModuleList | 66.0 K\n",
"67 | encoder.encoder.2.res.1.0 | MaskedConv1d | 65.5 K\n",
"68 | encoder.encoder.2.res.1.0.conv | Conv1d | 65.5 K\n",
"69 | encoder.encoder.2.res.1.1 | BatchNorm1d | 512 \n",
"70 | encoder.encoder.2.mout | Sequential | 0 \n",
"71 | encoder.encoder.2.mout.1 | Dropout | 0 \n",
"72 | encoder.encoder.3 | JasperBlock | 9.2 M \n",
"73 | encoder.encoder.3.mconv | ModuleList | 8.9 M \n",
"74 | encoder.encoder.3.mconv.0 | MaskedConv1d | 1.3 M \n",
"75 | encoder.encoder.3.mconv.0.conv | Conv1d | 1.3 M \n",
"76 | encoder.encoder.3.mconv.1 | BatchNorm1d | 768 \n",
"77 | encoder.encoder.3.mconv.3 | Dropout | 0 \n",
"78 | encoder.encoder.3.mconv.4 | MaskedConv1d | 1.9 M \n",
"79 | encoder.encoder.3.mconv.4.conv | Conv1d | 1.9 M \n",
"80 | encoder.encoder.3.mconv.5 | BatchNorm1d | 768 \n",
"81 | encoder.encoder.3.mconv.7 | Dropout | 0 \n",
"82 | encoder.encoder.3.mconv.8 | MaskedConv1d | 1.9 M \n",
"83 | encoder.encoder.3.mconv.8.conv | Conv1d | 1.9 M \n",
"84 | encoder.encoder.3.mconv.9 | BatchNorm1d | 768 \n",
"85 | encoder.encoder.3.mconv.11 | Dropout | 0 \n",
"86 | encoder.encoder.3.mconv.12 | MaskedConv1d | 1.9 M \n",
"87 | encoder.encoder.3.mconv.12.conv | Conv1d | 1.9 M \n",
"88 | encoder.encoder.3.mconv.13 | BatchNorm1d | 768 \n",
"89 | encoder.encoder.3.mconv.15 | Dropout | 0 \n",
"90 | encoder.encoder.3.mconv.16 | MaskedConv1d | 1.9 M \n",
"91 | encoder.encoder.3.mconv.16.conv | Conv1d | 1.9 M \n",
"92 | encoder.encoder.3.mconv.17 | BatchNorm1d | 768 \n",
"93 | encoder.encoder.3.res | ModuleList | 297 K \n",
"94 | encoder.encoder.3.res.0 | ModuleList | 99.1 K\n",
"95 | encoder.encoder.3.res.0.0 | MaskedConv1d | 98.3 K\n",
"96 | encoder.encoder.3.res.0.0.conv | Conv1d | 98.3 K\n",
"97 | encoder.encoder.3.res.0.1 | BatchNorm1d | 768 \n",
"98 | encoder.encoder.3.res.1 | ModuleList | 99.1 K\n",
"99 | encoder.encoder.3.res.1.0 | MaskedConv1d | 98.3 K\n",
"100 | encoder.encoder.3.res.1.0.conv | Conv1d | 98.3 K\n",
"101 | encoder.encoder.3.res.1.1 | BatchNorm1d | 768 \n",
"102 | encoder.encoder.3.res.2 | ModuleList | 99.1 K\n",
"103 | encoder.encoder.3.res.2.0 | MaskedConv1d | 98.3 K\n",
"104 | encoder.encoder.3.res.2.0.conv | Conv1d | 98.3 K\n",
"105 | encoder.encoder.3.res.2.1 | BatchNorm1d | 768 \n",
"106 | encoder.encoder.3.mout | Sequential | 0 \n",
"107 | encoder.encoder.3.mout.1 | Dropout | 0 \n",
"108 | encoder.encoder.4 | JasperBlock | 10.0 M\n",
"109 | encoder.encoder.4.mconv | ModuleList | 9.6 M \n",
"110 | encoder.encoder.4.mconv.0 | MaskedConv1d | 1.9 M \n",
"111 | encoder.encoder.4.mconv.0.conv | Conv1d | 1.9 M \n",
"112 | encoder.encoder.4.mconv.1 | BatchNorm1d | 768 \n",
"113 | encoder.encoder.4.mconv.3 | Dropout | 0 \n",
"114 | encoder.encoder.4.mconv.4 | MaskedConv1d | 1.9 M \n",
"115 | encoder.encoder.4.mconv.4.conv | Conv1d | 1.9 M \n",
"116 | encoder.encoder.4.mconv.5 | BatchNorm1d | 768 \n",
"117 | encoder.encoder.4.mconv.7 | Dropout | 0 \n",
"118 | encoder.encoder.4.mconv.8 | MaskedConv1d | 1.9 M \n",
"119 | encoder.encoder.4.mconv.8.conv | Conv1d | 1.9 M \n",
"120 | encoder.encoder.4.mconv.9 | BatchNorm1d | 768 \n",
"121 | encoder.encoder.4.mconv.11 | Dropout | 0 \n",
"122 | encoder.encoder.4.mconv.12 | MaskedConv1d | 1.9 M \n",
"123 | encoder.encoder.4.mconv.12.conv | Conv1d | 1.9 M \n",
"124 | encoder.encoder.4.mconv.13 | BatchNorm1d | 768 \n",
"125 | encoder.encoder.4.mconv.15 | Dropout | 0 \n",
"126 | encoder.encoder.4.mconv.16 | MaskedConv1d | 1.9 M \n",
"127 | encoder.encoder.4.mconv.16.conv | Conv1d | 1.9 M \n",
"128 | encoder.encoder.4.mconv.17 | BatchNorm1d | 768 \n",
"129 | encoder.encoder.4.res | ModuleList | 445 K \n",
"130 | encoder.encoder.4.res.0 | ModuleList | 99.1 K\n",
"131 | encoder.encoder.4.res.0.0 | MaskedConv1d | 98.3 K\n",
"132 | encoder.encoder.4.res.0.0.conv | Conv1d | 98.3 K\n",
"133 | encoder.encoder.4.res.0.1 | BatchNorm1d | 768 \n",
"134 | encoder.encoder.4.res.1 | ModuleList | 99.1 K\n",
"135 | encoder.encoder.4.res.1.0 | MaskedConv1d | 98.3 K\n",
"136 | encoder.encoder.4.res.1.0.conv | Conv1d | 98.3 K\n",
"137 | encoder.encoder.4.res.1.1 | BatchNorm1d | 768 \n",
"138 | encoder.encoder.4.res.2 | ModuleList | 99.1 K\n",
"139 | encoder.encoder.4.res.2.0 | MaskedConv1d | 98.3 K\n",
"140 | encoder.encoder.4.res.2.0.conv | Conv1d | 98.3 K\n",
"141 | encoder.encoder.4.res.2.1 | BatchNorm1d | 768 \n",
"142 | encoder.encoder.4.res.3 | ModuleList | 148 K \n",
"143 | encoder.encoder.4.res.3.0 | MaskedConv1d | 147 K \n",
"144 | encoder.encoder.4.res.3.0.conv | Conv1d | 147 K \n",
"145 | encoder.encoder.4.res.3.1 | BatchNorm1d | 768 \n",
"146 | encoder.encoder.4.mout | Sequential | 0 \n",
"147 | encoder.encoder.4.mout.1 | Dropout | 0 \n",
"148 | encoder.encoder.5 | JasperBlock | 22.0 M\n",
"149 | encoder.encoder.5.mconv | ModuleList | 21.2 M\n",
"150 | encoder.encoder.5.mconv.0 | MaskedConv1d | 3.3 M \n",
"151 | encoder.encoder.5.mconv.0.conv | Conv1d | 3.3 M \n",
"152 | encoder.encoder.5.mconv.1 | BatchNorm1d | 1.0 K \n",
"153 | encoder.encoder.5.mconv.3 | Dropout | 0 \n",
"154 | encoder.encoder.5.mconv.4 | MaskedConv1d | 4.5 M \n",
"155 | encoder.encoder.5.mconv.4.conv | Conv1d | 4.5 M \n",
"156 | encoder.encoder.5.mconv.5 | BatchNorm1d | 1.0 K \n",
"157 | encoder.encoder.5.mconv.7 | Dropout | 0 \n",
"158 | encoder.encoder.5.mconv.8 | MaskedConv1d | 4.5 M \n",
"159 | encoder.encoder.5.mconv.8.conv | Conv1d | 4.5 M \n",
"160 | encoder.encoder.5.mconv.9 | BatchNorm1d | 1.0 K \n",
"161 | encoder.encoder.5.mconv.11 | Dropout | 0 \n",
"162 | encoder.encoder.5.mconv.12 | MaskedConv1d | 4.5 M \n",
"163 | encoder.encoder.5.mconv.12.conv | Conv1d | 4.5 M \n",
"164 | encoder.encoder.5.mconv.13 | BatchNorm1d | 1.0 K \n",
"165 | encoder.encoder.5.mconv.15 | Dropout | 0 \n",
"166 | encoder.encoder.5.mconv.16 | MaskedConv1d | 4.5 M \n",
"167 | encoder.encoder.5.mconv.16.conv | Conv1d | 4.5 M \n",
"168 | encoder.encoder.5.mconv.17 | BatchNorm1d | 1.0 K \n",
"169 | encoder.encoder.5.res | ModuleList | 791 K \n",
"170 | encoder.encoder.5.res.0 | ModuleList | 132 K \n",
"171 | encoder.encoder.5.res.0.0 | MaskedConv1d | 131 K \n",
"172 | encoder.encoder.5.res.0.0.conv | Conv1d | 131 K \n",
"173 | encoder.encoder.5.res.0.1 | BatchNorm1d | 1.0 K \n",
"174 | encoder.encoder.5.res.1 | ModuleList | 132 K \n",
"175 | encoder.encoder.5.res.1.0 | MaskedConv1d | 131 K \n",
"176 | encoder.encoder.5.res.1.0.conv | Conv1d | 131 K \n",
"177 | encoder.encoder.5.res.1.1 | BatchNorm1d | 1.0 K \n",
"178 | encoder.encoder.5.res.2 | ModuleList | 132 K \n",
"179 | encoder.encoder.5.res.2.0 | MaskedConv1d | 131 K \n",
"180 | encoder.encoder.5.res.2.0.conv | Conv1d | 131 K \n",
"181 | encoder.encoder.5.res.2.1 | BatchNorm1d | 1.0 K \n",
"182 | encoder.encoder.5.res.3 | ModuleList | 197 K \n",
"183 | encoder.encoder.5.res.3.0 | MaskedConv1d | 196 K \n",
"184 | encoder.encoder.5.res.3.0.conv | Conv1d | 196 K \n",
"185 | encoder.encoder.5.res.3.1 | BatchNorm1d | 1.0 K \n",
"186 | encoder.encoder.5.res.4 | ModuleList | 197 K \n",
"187 | encoder.encoder.5.res.4.0 | MaskedConv1d | 196 K \n",
"188 | encoder.encoder.5.res.4.0.conv | Conv1d | 196 K \n",
"189 | encoder.encoder.5.res.4.1 | BatchNorm1d | 1.0 K \n",
"190 | encoder.encoder.5.mout | Sequential | 0 \n",
"191 | encoder.encoder.5.mout.1 | Dropout | 0 \n",
"192 | encoder.encoder.6 | JasperBlock | 23.3 M\n",
"193 | encoder.encoder.6.mconv | ModuleList | 22.3 M\n",
"194 | encoder.encoder.6.mconv.0 | MaskedConv1d | 4.5 M \n",
"195 | encoder.encoder.6.mconv.0.conv | Conv1d | 4.5 M \n",
"196 | encoder.encoder.6.mconv.1 | BatchNorm1d | 1.0 K \n",
"197 | encoder.encoder.6.mconv.3 | Dropout | 0 \n",
"198 | encoder.encoder.6.mconv.4 | MaskedConv1d | 4.5 M \n",
"199 | encoder.encoder.6.mconv.4.conv | Conv1d | 4.5 M \n",
"200 | encoder.encoder.6.mconv.5 | BatchNorm1d | 1.0 K \n",
"201 | encoder.encoder.6.mconv.7 | Dropout | 0 \n",
"202 | encoder.encoder.6.mconv.8 | MaskedConv1d | 4.5 M \n",
"203 | encoder.encoder.6.mconv.8.conv | Conv1d | 4.5 M \n",
"204 | encoder.encoder.6.mconv.9 | BatchNorm1d | 1.0 K \n",
"205 | encoder.encoder.6.mconv.11 | Dropout | 0 \n",
"206 | encoder.encoder.6.mconv.12 | MaskedConv1d | 4.5 M \n",
"207 | encoder.encoder.6.mconv.12.conv | Conv1d | 4.5 M \n",
"208 | encoder.encoder.6.mconv.13 | BatchNorm1d | 1.0 K \n",
"209 | encoder.encoder.6.mconv.15 | Dropout | 0 \n",
"210 | encoder.encoder.6.mconv.16 | MaskedConv1d | 4.5 M \n",
"211 | encoder.encoder.6.mconv.16.conv | Conv1d | 4.5 M \n",
"212 | encoder.encoder.6.mconv.17 | BatchNorm1d | 1.0 K \n",
"213 | encoder.encoder.6.res | ModuleList | 1.1 M \n",
"214 | encoder.encoder.6.res.0 | ModuleList | 132 K \n",
"215 | encoder.encoder.6.res.0.0 | MaskedConv1d | 131 K \n",
"216 | encoder.encoder.6.res.0.0.conv | Conv1d | 131 K \n",
"217 | encoder.encoder.6.res.0.1 | BatchNorm1d | 1.0 K \n",
"218 | encoder.encoder.6.res.1 | ModuleList | 132 K \n",
"219 | encoder.encoder.6.res.1.0 | MaskedConv1d | 131 K \n",
"220 | encoder.encoder.6.res.1.0.conv | Conv1d | 131 K \n",
"221 | encoder.encoder.6.res.1.1 | BatchNorm1d | 1.0 K \n",
"222 | encoder.encoder.6.res.2 | ModuleList | 132 K \n",
"223 | encoder.encoder.6.res.2.0 | MaskedConv1d | 131 K \n",
"224 | encoder.encoder.6.res.2.0.conv | Conv1d | 131 K \n",
"225 | encoder.encoder.6.res.2.1 | BatchNorm1d | 1.0 K \n",
"226 | encoder.encoder.6.res.3 | ModuleList | 197 K \n",
"227 | encoder.encoder.6.res.3.0 | MaskedConv1d | 196 K \n",
"228 | encoder.encoder.6.res.3.0.conv | Conv1d | 196 K \n",
"229 | encoder.encoder.6.res.3.1 | BatchNorm1d | 1.0 K \n",
"230 | encoder.encoder.6.res.4 | ModuleList | 197 K \n",
"231 | encoder.encoder.6.res.4.0 | MaskedConv1d | 196 K \n",
"232 | encoder.encoder.6.res.4.0.conv | Conv1d | 196 K \n",
"233 | encoder.encoder.6.res.4.1 | BatchNorm1d | 1.0 K \n",
"234 | encoder.encoder.6.res.5 | ModuleList | 263 K \n",
"235 | encoder.encoder.6.res.5.0 | MaskedConv1d | 262 K \n",
"236 | encoder.encoder.6.res.5.0.conv | Conv1d | 262 K \n",
"237 | encoder.encoder.6.res.5.1 | BatchNorm1d | 1.0 K \n",
"238 | encoder.encoder.6.mout | Sequential | 0 \n",
"239 | encoder.encoder.6.mout.1 | Dropout | 0 \n",
"240 | encoder.encoder.7 | JasperBlock | 42.9 M\n",
"241 | encoder.encoder.7.mconv | ModuleList | 41.3 M\n",
"242 | encoder.encoder.7.mconv.0 | MaskedConv1d | 6.9 M \n",
"243 | encoder.encoder.7.mconv.0.conv | Conv1d | 6.9 M \n",
"244 | encoder.encoder.7.mconv.1 | BatchNorm1d | 1.3 K \n",
"245 | encoder.encoder.7.mconv.3 | Dropout | 0 \n",
"246 | encoder.encoder.7.mconv.4 | MaskedConv1d | 8.6 M \n",
"247 | encoder.encoder.7.mconv.4.conv | Conv1d | 8.6 M \n",
"248 | encoder.encoder.7.mconv.5 | BatchNorm1d | 1.3 K \n",
"249 | encoder.encoder.7.mconv.7 | Dropout | 0 \n",
"250 | encoder.encoder.7.mconv.8 | MaskedConv1d | 8.6 M \n",
"251 | encoder.encoder.7.mconv.8.conv | Conv1d | 8.6 M \n",
"252 | encoder.encoder.7.mconv.9 | BatchNorm1d | 1.3 K \n",
"253 | encoder.encoder.7.mconv.11 | Dropout | 0 \n",
"254 | encoder.encoder.7.mconv.12 | MaskedConv1d | 8.6 M \n",
"255 | encoder.encoder.7.mconv.12.conv | Conv1d | 8.6 M \n",
"256 | encoder.encoder.7.mconv.13 | BatchNorm1d | 1.3 K \n",
"257 | encoder.encoder.7.mconv.15 | Dropout | 0 \n",
"258 | encoder.encoder.7.mconv.16 | MaskedConv1d | 8.6 M \n",
"259 | encoder.encoder.7.mconv.16.conv | Conv1d | 8.6 M \n",
"260 | encoder.encoder.7.mconv.17 | BatchNorm1d | 1.3 K \n",
"261 | encoder.encoder.7.res | ModuleList | 1.6 M \n",
"262 | encoder.encoder.7.res.0 | ModuleList | 165 K \n",
"263 | encoder.encoder.7.res.0.0 | MaskedConv1d | 163 K \n",
"264 | encoder.encoder.7.res.0.0.conv | Conv1d | 163 K \n",
"265 | encoder.encoder.7.res.0.1 | BatchNorm1d | 1.3 K \n",
"266 | encoder.encoder.7.res.1 | ModuleList | 165 K \n",
"267 | encoder.encoder.7.res.1.0 | MaskedConv1d | 163 K \n",
"268 | encoder.encoder.7.res.1.0.conv | Conv1d | 163 K \n",
"269 | encoder.encoder.7.res.1.1 | BatchNorm1d | 1.3 K \n",
"270 | encoder.encoder.7.res.2 | ModuleList | 165 K \n",
"271 | encoder.encoder.7.res.2.0 | MaskedConv1d | 163 K \n",
"272 | encoder.encoder.7.res.2.0.conv | Conv1d | 163 K \n",
"273 | encoder.encoder.7.res.2.1 | BatchNorm1d | 1.3 K \n",
"274 | encoder.encoder.7.res.3 | ModuleList | 247 K \n",
"275 | encoder.encoder.7.res.3.0 | MaskedConv1d | 245 K \n",
"276 | encoder.encoder.7.res.3.0.conv | Conv1d | 245 K \n",
"277 | encoder.encoder.7.res.3.1 | BatchNorm1d | 1.3 K \n",
"278 | encoder.encoder.7.res.4 | ModuleList | 247 K \n",
"279 | encoder.encoder.7.res.4.0 | MaskedConv1d | 245 K \n",
"280 | encoder.encoder.7.res.4.0.conv | Conv1d | 245 K \n",
"281 | encoder.encoder.7.res.4.1 | BatchNorm1d | 1.3 K \n",
"282 | encoder.encoder.7.res.5 | ModuleList | 328 K \n",
"283 | encoder.encoder.7.res.5.0 | MaskedConv1d | 327 K \n",
"284 | encoder.encoder.7.res.5.0.conv | Conv1d | 327 K \n",
"285 | encoder.encoder.7.res.5.1 | BatchNorm1d | 1.3 K \n",
"286 | encoder.encoder.7.res.6 | ModuleList | 328 K \n",
"287 | encoder.encoder.7.res.6.0 | MaskedConv1d | 327 K \n",
"288 | encoder.encoder.7.res.6.0.conv | Conv1d | 327 K \n",
"289 | encoder.encoder.7.res.6.1 | BatchNorm1d | 1.3 K \n",
"290 | encoder.encoder.7.mout | Sequential | 0 \n",
"291 | encoder.encoder.7.mout.1 | Dropout | 0 \n",
"292 | encoder.encoder.8 | JasperBlock | 45.1 M\n",
"293 | encoder.encoder.8.mconv | ModuleList | 43.0 M\n",
"294 | encoder.encoder.8.mconv.0 | MaskedConv1d | 8.6 M \n",
"295 | encoder.encoder.8.mconv.0.conv | Conv1d | 8.6 M \n",
"296 | encoder.encoder.8.mconv.1 | BatchNorm1d | 1.3 K \n",
"297 | encoder.encoder.8.mconv.3 | Dropout | 0 \n",
"298 | encoder.encoder.8.mconv.4 | MaskedConv1d | 8.6 M \n",
"299 | encoder.encoder.8.mconv.4.conv | Conv1d | 8.6 M \n",
"300 | encoder.encoder.8.mconv.5 | BatchNorm1d | 1.3 K \n",
"301 | encoder.encoder.8.mconv.7 | Dropout | 0 \n",
"302 | encoder.encoder.8.mconv.8 | MaskedConv1d | 8.6 M \n",
"303 | encoder.encoder.8.mconv.8.conv | Conv1d | 8.6 M \n",
"304 | encoder.encoder.8.mconv.9 | BatchNorm1d | 1.3 K \n",
"305 | encoder.encoder.8.mconv.11 | Dropout | 0 \n",
"306 | encoder.encoder.8.mconv.12 | MaskedConv1d | 8.6 M \n",
"307 | encoder.encoder.8.mconv.12.conv | Conv1d | 8.6 M \n",
"308 | encoder.encoder.8.mconv.13 | BatchNorm1d | 1.3 K \n",
"309 | encoder.encoder.8.mconv.15 | Dropout | 0 \n",
"310 | encoder.encoder.8.mconv.16 | MaskedConv1d | 8.6 M \n",
"311 | encoder.encoder.8.mconv.16.conv | Conv1d | 8.6 M \n",
"312 | encoder.encoder.8.mconv.17 | BatchNorm1d | 1.3 K \n",
"313 | encoder.encoder.8.res | ModuleList | 2.1 M \n",
"314 | encoder.encoder.8.res.0 | ModuleList | 165 K \n",
"315 | encoder.encoder.8.res.0.0 | MaskedConv1d | 163 K \n",
"316 | encoder.encoder.8.res.0.0.conv | Conv1d | 163 K \n",
"317 | encoder.encoder.8.res.0.1 | BatchNorm1d | 1.3 K \n",
"318 | encoder.encoder.8.res.1 | ModuleList | 165 K \n",
"319 | encoder.encoder.8.res.1.0 | MaskedConv1d | 163 K \n",
"320 | encoder.encoder.8.res.1.0.conv | Conv1d | 163 K \n",
"321 | encoder.encoder.8.res.1.1 | BatchNorm1d | 1.3 K \n",
"322 | encoder.encoder.8.res.2 | ModuleList | 165 K \n",
"323 | encoder.encoder.8.res.2.0 | MaskedConv1d | 163 K \n",
"324 | encoder.encoder.8.res.2.0.conv | Conv1d | 163 K \n",
"325 | encoder.encoder.8.res.2.1 | BatchNorm1d | 1.3 K \n",
"326 | encoder.encoder.8.res.3 | ModuleList | 247 K \n",
"327 | encoder.encoder.8.res.3.0 | MaskedConv1d | 245 K \n",
"328 | encoder.encoder.8.res.3.0.conv | Conv1d | 245 K \n",
"329 | encoder.encoder.8.res.3.1 | BatchNorm1d | 1.3 K \n",
"330 | encoder.encoder.8.res.4 | ModuleList | 247 K \n",
"331 | encoder.encoder.8.res.4.0 | MaskedConv1d | 245 K \n",
"332 | encoder.encoder.8.res.4.0.conv | Conv1d | 245 K \n",
"333 | encoder.encoder.8.res.4.1 | BatchNorm1d | 1.3 K \n",
"334 | encoder.encoder.8.res.5 | ModuleList | 328 K \n",
"335 | encoder.encoder.8.res.5.0 | MaskedConv1d | 327 K \n",
"336 | encoder.encoder.8.res.5.0.conv | Conv1d | 327 K \n",
"337 | encoder.encoder.8.res.5.1 | BatchNorm1d | 1.3 K \n",
"338 | encoder.encoder.8.res.6 | ModuleList | 328 K \n",
"339 | encoder.encoder.8.res.6.0 | MaskedConv1d | 327 K \n",
"340 | encoder.encoder.8.res.6.0.conv | Conv1d | 327 K \n",
"341 | encoder.encoder.8.res.6.1 | BatchNorm1d | 1.3 K \n",
"342 | encoder.encoder.8.res.7 | ModuleList | 410 K \n",
"343 | encoder.encoder.8.res.7.0 | MaskedConv1d | 409 K \n",
"344 | encoder.encoder.8.res.7.0.conv | Conv1d | 409 K \n",
"345 | encoder.encoder.8.res.7.1 | BatchNorm1d | 1.3 K \n",
"346 | encoder.encoder.8.mout | Sequential | 0 \n",
"347 | encoder.encoder.8.mout.1 | Dropout | 0 \n",
"348 | encoder.encoder.9 | JasperBlock | 74.2 M\n",
"349 | encoder.encoder.9.mconv | ModuleList | 71.3 M\n",
"350 | encoder.encoder.9.mconv.0 | MaskedConv1d | 12.3 M\n",
"351 | encoder.encoder.9.mconv.0.conv | Conv1d | 12.3 M\n",
"352 | encoder.encoder.9.mconv.1 | BatchNorm1d | 1.5 K \n",
"353 | encoder.encoder.9.mconv.3 | Dropout | 0 \n",
"354 | encoder.encoder.9.mconv.4 | MaskedConv1d | 14.7 M\n",
"355 | encoder.encoder.9.mconv.4.conv | Conv1d | 14.7 M\n",
"356 | encoder.encoder.9.mconv.5 | BatchNorm1d | 1.5 K \n",
"357 | encoder.encoder.9.mconv.7 | Dropout | 0 \n",
"358 | encoder.encoder.9.mconv.8 | MaskedConv1d | 14.7 M\n",
"359 | encoder.encoder.9.mconv.8.conv | Conv1d | 14.7 M\n",
"360 | encoder.encoder.9.mconv.9 | BatchNorm1d | 1.5 K \n",
"361 | encoder.encoder.9.mconv.11 | Dropout | 0 \n",
"362 | encoder.encoder.9.mconv.12 | MaskedConv1d | 14.7 M\n",
"363 | encoder.encoder.9.mconv.12.conv | Conv1d | 14.7 M\n",
"364 | encoder.encoder.9.mconv.13 | BatchNorm1d | 1.5 K \n",
"365 | encoder.encoder.9.mconv.15 | Dropout | 0 \n",
"366 | encoder.encoder.9.mconv.16 | MaskedConv1d | 14.7 M\n",
"367 | encoder.encoder.9.mconv.16.conv | Conv1d | 14.7 M\n",
"368 | encoder.encoder.9.mconv.17 | BatchNorm1d | 1.5 K \n",
"369 | encoder.encoder.9.res | ModuleList | 3.0 M \n",
"370 | encoder.encoder.9.res.0 | ModuleList | 198 K \n",
"371 | encoder.encoder.9.res.0.0 | MaskedConv1d | 196 K \n",
"372 | encoder.encoder.9.res.0.0.conv | Conv1d | 196 K \n",
"373 | encoder.encoder.9.res.0.1 | BatchNorm1d | 1.5 K \n",
"374 | encoder.encoder.9.res.1 | ModuleList | 198 K \n",
"375 | encoder.encoder.9.res.1.0 | MaskedConv1d | 196 K \n",
"376 | encoder.encoder.9.res.1.0.conv | Conv1d | 196 K \n",
"377 | encoder.encoder.9.res.1.1 | BatchNorm1d | 1.5 K \n",
"378 | encoder.encoder.9.res.2 | ModuleList | 198 K \n",
"379 | encoder.encoder.9.res.2.0 | MaskedConv1d | 196 K \n",
"380 | encoder.encoder.9.res.2.0.conv | Conv1d | 196 K \n",
"381 | encoder.encoder.9.res.2.1 | BatchNorm1d | 1.5 K \n",
"382 | encoder.encoder.9.res.3 | ModuleList | 296 K \n",
"383 | encoder.encoder.9.res.3.0 | MaskedConv1d | 294 K \n",
"384 | encoder.encoder.9.res.3.0.conv | Conv1d | 294 K \n",
"385 | encoder.encoder.9.res.3.1 | BatchNorm1d | 1.5 K \n",
"386 | encoder.encoder.9.res.4 | ModuleList | 296 K \n",
"387 | encoder.encoder.9.res.4.0 | MaskedConv1d | 294 K \n",
"388 | encoder.encoder.9.res.4.0.conv | Conv1d | 294 K \n",
"389 | encoder.encoder.9.res.4.1 | BatchNorm1d | 1.5 K \n",
"390 | encoder.encoder.9.res.5 | ModuleList | 394 K \n",
"391 | encoder.encoder.9.res.5.0 | MaskedConv1d | 393 K \n",
"392 | encoder.encoder.9.res.5.0.conv | Conv1d | 393 K \n",
"393 | encoder.encoder.9.res.5.1 | BatchNorm1d | 1.5 K \n",
"394 | encoder.encoder.9.res.6 | ModuleList | 394 K \n",
"395 | encoder.encoder.9.res.6.0 | MaskedConv1d | 393 K \n",
"396 | encoder.encoder.9.res.6.0.conv | Conv1d | 393 K \n",
"397 | encoder.encoder.9.res.6.1 | BatchNorm1d | 1.5 K \n",
"398 | encoder.encoder.9.res.7 | ModuleList | 493 K \n",
"399 | encoder.encoder.9.res.7.0 | MaskedConv1d | 491 K \n",
"400 | encoder.encoder.9.res.7.0.conv | Conv1d | 491 K \n",
"401 | encoder.encoder.9.res.7.1 | BatchNorm1d | 1.5 K \n",
"402 | encoder.encoder.9.res.8 | ModuleList | 493 K \n",
"403 | encoder.encoder.9.res.8.0 | MaskedConv1d | 491 K \n",
"404 | encoder.encoder.9.res.8.0.conv | Conv1d | 491 K \n",
"405 | encoder.encoder.9.res.8.1 | BatchNorm1d | 1.5 K \n",
"406 | encoder.encoder.9.mout | Sequential | 0 \n",
"407 | encoder.encoder.9.mout.1 | Dropout | 0 \n",
"408 | encoder.encoder.10 | JasperBlock | 77.3 M\n",
"409 | encoder.encoder.10.mconv | ModuleList | 73.7 M\n",
"410 | encoder.encoder.10.mconv.0 | MaskedConv1d | 14.7 M\n",
"411 | encoder.encoder.10.mconv.0.conv | Conv1d | 14.7 M\n",
"412 | encoder.encoder.10.mconv.1 | BatchNorm1d | 1.5 K \n",
"413 | encoder.encoder.10.mconv.3 | Dropout | 0 \n",
"414 | encoder.encoder.10.mconv.4 | MaskedConv1d | 14.7 M\n",
"415 | encoder.encoder.10.mconv.4.conv | Conv1d | 14.7 M\n",
"416 | encoder.encoder.10.mconv.5 | BatchNorm1d | 1.5 K \n",
"417 | encoder.encoder.10.mconv.7 | Dropout | 0 \n",
"418 | encoder.encoder.10.mconv.8 | MaskedConv1d | 14.7 M\n",
"419 | encoder.encoder.10.mconv.8.conv | Conv1d | 14.7 M\n",
"420 | encoder.encoder.10.mconv.9 | BatchNorm1d | 1.5 K \n",
"421 | encoder.encoder.10.mconv.11 | Dropout | 0 \n",
"422 | encoder.encoder.10.mconv.12 | MaskedConv1d | 14.7 M\n",
"423 | encoder.encoder.10.mconv.12.conv | Conv1d | 14.7 M\n",
"424 | encoder.encoder.10.mconv.13 | BatchNorm1d | 1.5 K \n",
"425 | encoder.encoder.10.mconv.15 | Dropout | 0 \n",
"426 | encoder.encoder.10.mconv.16 | MaskedConv1d | 14.7 M\n",
"427 | encoder.encoder.10.mconv.16.conv | Conv1d | 14.7 M\n",
"428 | encoder.encoder.10.mconv.17 | BatchNorm1d | 1.5 K \n",
"429 | encoder.encoder.10.res | ModuleList | 3.6 M \n",
"430 | encoder.encoder.10.res.0 | ModuleList | 198 K \n",
"431 | encoder.encoder.10.res.0.0 | MaskedConv1d | 196 K \n",
"432 | encoder.encoder.10.res.0.0.conv | Conv1d | 196 K \n",
"433 | encoder.encoder.10.res.0.1 | BatchNorm1d | 1.5 K \n",
"434 | encoder.encoder.10.res.1 | ModuleList | 198 K \n",
"435 | encoder.encoder.10.res.1.0 | MaskedConv1d | 196 K \n",
"436 | encoder.encoder.10.res.1.0.conv | Conv1d | 196 K \n",
"437 | encoder.encoder.10.res.1.1 | BatchNorm1d | 1.5 K \n",
"438 | encoder.encoder.10.res.2 | ModuleList | 198 K \n",
"439 | encoder.encoder.10.res.2.0 | MaskedConv1d | 196 K \n",
"440 | encoder.encoder.10.res.2.0.conv | Conv1d | 196 K \n",
"441 | encoder.encoder.10.res.2.1 | BatchNorm1d | 1.5 K \n",
"442 | encoder.encoder.10.res.3 | ModuleList | 296 K \n",
"443 | encoder.encoder.10.res.3.0 | MaskedConv1d | 294 K \n",
"444 | encoder.encoder.10.res.3.0.conv | Conv1d | 294 K \n",
"445 | encoder.encoder.10.res.3.1 | BatchNorm1d | 1.5 K \n",
"446 | encoder.encoder.10.res.4 | ModuleList | 296 K \n",
"447 | encoder.encoder.10.res.4.0 | MaskedConv1d | 294 K \n",
"448 | encoder.encoder.10.res.4.0.conv | Conv1d | 294 K \n",
"449 | encoder.encoder.10.res.4.1 | BatchNorm1d | 1.5 K \n",
"450 | encoder.encoder.10.res.5 | ModuleList | 394 K \n",
"451 | encoder.encoder.10.res.5.0 | MaskedConv1d | 393 K \n",
"452 | encoder.encoder.10.res.5.0.conv | Conv1d | 393 K \n",
"453 | encoder.encoder.10.res.5.1 | BatchNorm1d | 1.5 K \n",
"454 | encoder.encoder.10.res.6 | ModuleList | 394 K \n",
"455 | encoder.encoder.10.res.6.0 | MaskedConv1d | 393 K \n",
"456 | encoder.encoder.10.res.6.0.conv | Conv1d | 393 K \n",
"457 | encoder.encoder.10.res.6.1 | BatchNorm1d | 1.5 K \n",
"458 | encoder.encoder.10.res.7 | ModuleList | 493 K \n",
"459 | encoder.encoder.10.res.7.0 | MaskedConv1d | 491 K \n",
"460 | encoder.encoder.10.res.7.0.conv | Conv1d | 491 K \n",
"461 | encoder.encoder.10.res.7.1 | BatchNorm1d | 1.5 K \n",
"462 | encoder.encoder.10.res.8 | ModuleList | 493 K \n",
"463 | encoder.encoder.10.res.8.0 | MaskedConv1d | 491 K \n",
"464 | encoder.encoder.10.res.8.0.conv | Conv1d | 491 K \n",
"465 | encoder.encoder.10.res.8.1 | BatchNorm1d | 1.5 K \n",
"466 | encoder.encoder.10.res.9 | ModuleList | 591 K \n",
"467 | encoder.encoder.10.res.9.0 | MaskedConv1d | 589 K \n",
"468 | encoder.encoder.10.res.9.0.conv | Conv1d | 589 K \n",
"469 | encoder.encoder.10.res.9.1 | BatchNorm1d | 1.5 K \n",
"470 | encoder.encoder.10.mout | Sequential | 0 \n",
"471 | encoder.encoder.10.mout.1 | Dropout | 0 \n",
"472 | encoder.encoder.11 | JasperBlock | 20.0 M\n",
"473 | encoder.encoder.11.mconv | ModuleList | 20.0 M\n",
"474 | encoder.encoder.11.mconv.0 | MaskedConv1d | 20.0 M\n",
"475 | encoder.encoder.11.mconv.0.conv | Conv1d | 20.0 M\n",
"476 | encoder.encoder.11.mconv.1 | BatchNorm1d | 1.8 K \n",
"477 | encoder.encoder.11.mout | Sequential | 0 \n",
"478 | encoder.encoder.11.mout.1 | Dropout | 0 \n",
"479 | encoder.encoder.12 | JasperBlock | 919 K \n",
"480 | encoder.encoder.12.mconv | ModuleList | 919 K \n",
"481 | encoder.encoder.12.mconv.0 | MaskedConv1d | 917 K \n",
"482 | encoder.encoder.12.mconv.0.conv | Conv1d | 917 K \n",
"483 | encoder.encoder.12.mconv.1 | BatchNorm1d | 2.0 K \n",
"484 | encoder.encoder.12.mout | Sequential | 0 \n",
"485 | encoder.encoder.12.mout.1 | Dropout | 0 \n",
"486 | decoder | ConvASRDecoder | 29.7 K\n",
"487 | decoder.decoder_layers | Sequential | 29.7 K\n",
"488 | decoder.decoder_layers.0 | Conv1d | 29.7 K\n",
"489 | loss | CTCLoss | 0 \n",
"490 | spec_augmentation | SpectrogramAugmentation | 0 \n",
"491 | spec_augmentation.spec_cutout | SpecCutout | 0 \n",
"492 | _wer | WER | 0 \n",
"-----------------------------------------------------------------------------------------\n",
"332 M Trainable params\n",
"0 Non-trainable params\n",
"332 M Total params\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Restored states from the checkpoint file at /results/speech_to_text/finetune/checkpoints/finetuned-model-last.ckpt\n",
"Restored states from the checkpoint file at /results/speech_to_text/finetune/checkpoints/finetuned-model-last.ckpt\n",
"Validation sanity check: 0it [00:00, ?it/s][NeMo W 2021-09-20 21:03:29 patch_utils:49] torch.stft() signature has been updated for PyTorch 1.7+\n",
" Please update PyTorch to remain compatible with later versions of NeMo.\n",
"Validation sanity check: 100%|████████████████████| 2/2 [00:10<00:00, 7.28s/it][NeMo W 2021-09-20 21:03:41 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/distributed.py:49: UserWarning: The validation_epoch_end should not return anything as of 9.1. To log, use self.log(...) or self.write(...) directly in the LightningModule\n",
" warnings.warn(*args, **kwargs)\n",
" \n",
"Training: 0it [00:00, ?it/s] \n",
"[NeMo I 2021-09-20 21:05:05 finetune:138] Experiment logs saved to '/results/speech_to_text/finetune'\n",
"[NeMo I 2021-09-20 21:05:05 finetune:139] Fine-tuned model saved to '/results/speech_to_text/finetune/checkpoints/finetuned-model.tlt'\n",
"2021-09-20 17:05:07,658 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.\n"
]
}
],
"source": [
"!tao speech_to_text finetune \\\n",
" -e $STT_TAO_CONFIG_DIR/finetune.yaml \\\n",
" -g 1 \\\n",
" -k $KEY \\\n",
" -m $STT_TAO_CONFIG_DIR/speechtotext_english_jasper.tlt \\\n",
" -r $STT_TAO_RESULTS_DIR/finetune \\\n",
" finetuning_ds.manifest_filepath=$STT_TAO_CONFIG_DIR/train_manifest.json \\\n",
" validation_ds.manifest_filepath=$STT_TAO_CONFIG_DIR/valid_manifest.json \\\n",
" trainer.max_epochs=20 \\\n",
" finetuning_ds.max_duration=$MAX_DURATION \\\n",
" validation_ds.max_duration=$MAX_DURATION \\\n",
" finetuning_ds.trim_silence=false \\\n",
" validation_ds.trim_silence=false \\\n",
" finetuning_ds.batch_size=16 \\\n",
" finetuning_ds.batch_size=16 \\\n",
" finetuning_ds.num_workers=16 \\\n",
" validation_ds.num_workers=16 \\\n",
" trainer.gpus=1 \\\n",
" optim.lr=0.001"
]
},
{
"cell_type": "markdown",
"id": "8e395d55",
"metadata": {},
"source": [
"## Evaluate\n",
"\n",
"Once the model has been fine-tuned, its performance needs to be assessed. The base JASPER model is compared with the fine-tuned version.\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "fa8dc1c2",
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2021-09-20 17:05:18,564 [INFO] root: Registry: ['nvcr.io']\n",
"2021-09-20 17:05:18,653 [WARNING] tlt.components.docker_handler.docker_handler: \n",
"Docker will run the commands as root. If you would like to retain your\n",
"local host permissions, please add the \"user\":\"UID:GID\" in the\n",
"DockerOptions portion of the \"/root/.tao_mounts.json\" file. You can obtain your\n",
"users UID and GID by using the \"id -u\" and \"id -g\" commands on the\n",
"terminal.\n",
"[NeMo W 2021-09-20 21:05:22 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[nltk_data] Downloading package averaged_perceptron_tagger to\n",
"[nltk_data] /root/nltk_data...\n",
"[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.\n",
"[nltk_data] Downloading package cmudict to /root/nltk_data...\n",
"[nltk_data] Unzipping corpora/cmudict.zip.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:23 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:25 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:05:26 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo I 2021-09-20 21:05:27 tlt_logging:20] Experiment configuration:\n",
" restore_from: /results/speech_to_text/finetune/checkpoints/finetuned-model.tlt\n",
" exp_manager:\n",
" explicit_log_dir: /results/speech_to_text/evaluate\n",
" exp_dir: null\n",
" name: null\n",
" version: null\n",
" use_datetime_version: true\n",
" resume_if_exists: false\n",
" resume_past_end: false\n",
" resume_ignore_no_checkpoint: false\n",
" create_tensorboard_logger: false\n",
" summary_writer_kwargs: null\n",
" create_wandb_logger: false\n",
" wandb_logger_kwargs: null\n",
" create_checkpoint_callback: false\n",
" checkpoint_callback_params:\n",
" filepath: null\n",
" monitor: val_loss\n",
" verbose: true\n",
" save_last: true\n",
" save_top_k: 3\n",
" save_weights_only: false\n",
" mode: auto\n",
" period: 1\n",
" prefix: null\n",
" postfix: .nemo\n",
" save_best_model: false\n",
" files_to_copy: null\n",
" trainer:\n",
" logger: false\n",
" checkpoint_callback: false\n",
" callbacks: null\n",
" default_root_dir: null\n",
" gradient_clip_val: 0.0\n",
" process_position: 0\n",
" num_nodes: 1\n",
" num_processes: 1\n",
" gpus: 1\n",
" auto_select_gpus: false\n",
" tpu_cores: null\n",
" log_gpu_memory: null\n",
" progress_bar_refresh_rate: 1\n",
" overfit_batches: 0.0\n",
" track_grad_norm: -1\n",
" check_val_every_n_epoch: 1\n",
" fast_dev_run: false\n",
" accumulate_grad_batches: 1\n",
" max_epochs: 1000\n",
" min_epochs: 1\n",
" max_steps: null\n",
" min_steps: null\n",
" limit_train_batches: 1.0\n",
" limit_val_batches: 1.0\n",
" limit_test_batches: 1.0\n",
" val_check_interval: 1.0\n",
" flush_logs_every_n_steps: 100\n",
" log_every_n_steps: 50\n",
" accelerator: ddp\n",
" sync_batchnorm: false\n",
" precision: 32\n",
" weights_summary: full\n",
" weights_save_path: null\n",
" num_sanity_val_steps: 2\n",
" truncated_bptt_steps: null\n",
" resume_from_checkpoint: null\n",
" profiler: null\n",
" benchmark: false\n",
" deterministic: false\n",
" reload_dataloaders_every_epoch: false\n",
" auto_lr_find: false\n",
" replace_sampler_ddp: true\n",
" terminate_on_nan: false\n",
" auto_scale_batch_size: false\n",
" prepare_data_per_node: true\n",
" amp_backend: native\n",
" amp_level: O2\n",
" test_ds:\n",
" manifest_filepath: /config/speech_to_text/test_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: null\n",
" trim_silence: true\n",
" shuffle: false\n",
" max_duration: null\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" encryption_key: '*******'\n",
" \n",
"GPU available: True, used: True\n",
"GPU available: True, used: True\n",
"TPU available: None, using: 0 TPU cores\n",
"TPU available: None, using: 0 TPU cores\n",
"LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]\n",
"LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]\n",
"[NeMo W 2021-09-20 21:05:27 exp_manager:380] Exp_manager is logging to /results/speech_to_text/evaluate, but it already exists.\n",
"[NeMo I 2021-09-20 21:05:27 exp_manager:194] Experiments will be logged at /results/speech_to_text/evaluate\n",
"[NeMo W 2021-09-20 21:05:40 modelPT:145] Please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.\n",
" Train config : \n",
" manifest_filepath: /config/speech_to_text/train_manifest.json\n",
" batch_size: 16\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: true\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo W 2021-09-20 21:05:40 modelPT:152] Please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s). \n",
" Validation config : \n",
" manifest_filepath: /config/speech_to_text/valid_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: false\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo I 2021-09-20 21:05:40 features:236] PADDING: 16\n",
"[NeMo I 2021-09-20 21:05:40 features:252] STFT using torch\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"[NeMo I 2021-09-20 21:06:15 collections:173] Dataset loaded with 991 files totalling 2.53 hours\n",
"[NeMo I 2021-09-20 21:06:15 collections:174] 0 files were filtered totalling 0.00 hours\n",
"initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/1\n",
"initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/1\n",
"Added key: store_based_barrier_key:1 to store for rank: 0\n",
"[NeMo W 2021-09-20 21:06:16 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/distributed.py:49: UserWarning: The dataloader, test dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 78 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.\n",
" warnings.warn(*args, **kwargs)\n",
" \n",
"Testing: 0it [00:00, ?it/s][NeMo W 2021-09-20 21:06:30 patch_utils:49] torch.stft() signature has been updated for PyTorch 1.7+\n",
" Please update PyTorch to remain compatible with later versions of NeMo.\n",
"Testing: 100%|██████████████████████████████████| 31/31 [05:55<00:00, 12.17s/it][NeMo W 2021-09-20 21:12:12 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/distributed.py:49: UserWarning: The testing_epoch_end should not return anything as of 9.1. To log, use self.log(...) or self.write(...) directly in the LightningModule\n",
" warnings.warn(*args, **kwargs)\n",
" \n",
"Testing: 100%|██████████████████████████████████| 31/31 [05:55<00:00, 11.48s/it]\n",
"--------------------------------------------------------------------------------\n",
"DATALOADER:0 TEST RESULTS\n",
"{'test_loss': tensor(143.2543, device='cuda:0'),\n",
" 'test_wer': tensor(0.4080, device='cuda:0')}\n",
"--------------------------------------------------------------------------------\n",
"[NeMo I 2021-09-20 21:12:12 evaluate:99] Experiment logs saved to '/results/speech_to_text/evaluate'\n",
"2021-09-20 17:12:14,089 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.\n"
]
}
],
"source": [
"!tao speech_to_text evaluate \\\n",
" -e $STT_TAO_CONFIG_DIR/evaluate.yaml \\\n",
" -g 1 \\\n",
" -k $KEY \\\n",
" -m $STT_TAO_RESULTS_DIR/finetune/checkpoints/finetuned-model.tlt \\\n",
" -r $STT_TAO_RESULTS_DIR/evaluate \\\n",
" test_ds.manifest_filepath=$STT_TAO_CONFIG_DIR/test_manifest.json"
]
},
{
"cell_type": "markdown",
"id": "a18c8b4f",
"metadata": {},
"source": [
"## Export Model to RIVA"
]
},
{
"cell_type": "markdown",
"id": "3afa8421",
"metadata": {},
"source": [
"With TAO Toolkit, you can also export your model in a format that can deployed using Nvidia RIVA.\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "5e12a669",
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2021-09-20 17:12:25,262 [INFO] root: Registry: ['nvcr.io']\n",
"2021-09-20 17:12:25,356 [WARNING] tlt.components.docker_handler.docker_handler: \n",
"Docker will run the commands as root. If you would like to retain your\n",
"local host permissions, please add the \"user\":\"UID:GID\" in the\n",
"DockerOptions portion of the \"/root/.tao_mounts.json\" file. You can obtain your\n",
"users UID and GID by using the \"id -u\" and \"id -g\" commands on the\n",
"terminal.\n",
"[NeMo W 2021-09-20 21:12:29 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[nltk_data] Downloading package averaged_perceptron_tagger to\n",
"[nltk_data] /root/nltk_data...\n",
"[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.\n",
"[nltk_data] Downloading package cmudict to /root/nltk_data...\n",
"[nltk_data] Unzipping corpora/cmudict.zip.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:30 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:32 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo W 2021-09-20 21:12:33 experimental:27] Module is experimental, not ready for production and is not fully supported. Use at your own risk.\n",
"[NeMo I 2021-09-20 21:12:34 tlt_logging:20] Experiment configuration:\n",
" restore_from: /results/speech_to_text/finetune/checkpoints/finetuned-model.tlt\n",
" export_to: speech-to-text-model.riva\n",
" export_format: JARVIS\n",
" exp_manager:\n",
" task_name: export\n",
" explicit_log_dir: /results/speech_to_text/riva\n",
" encryption_key: '******'\n",
" \n",
"[NeMo W 2021-09-20 21:12:34 exp_manager:26] Exp_manager is logging to `/results/speech_to_text/riva``, but it already exists.\n",
"[NeMo W 2021-09-20 21:12:45 modelPT:145] Please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.\n",
" Train config : \n",
" manifest_filepath: /config/speech_to_text/train_manifest.json\n",
" batch_size: 16\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: true\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo W 2021-09-20 21:12:45 modelPT:152] Please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s). \n",
" Validation config : \n",
" manifest_filepath: /config/speech_to_text/valid_manifest.json\n",
" batch_size: 32\n",
" sample_rate: 16000\n",
" labels:\n",
" - ' '\n",
" - a\n",
" - b\n",
" - c\n",
" - d\n",
" - e\n",
" - f\n",
" - g\n",
" - h\n",
" - i\n",
" - j\n",
" - k\n",
" - l\n",
" - m\n",
" - 'n'\n",
" - o\n",
" - p\n",
" - q\n",
" - r\n",
" - s\n",
" - t\n",
" - u\n",
" - v\n",
" - w\n",
" - x\n",
" - 'y'\n",
" - z\n",
" - ''''\n",
" num_workers: 16\n",
" trim_silence: false\n",
" shuffle: false\n",
" max_duration: 16.7\n",
" is_tarred: false\n",
" tarred_audio_filepaths: null\n",
" \n",
"[NeMo I 2021-09-20 21:12:45 features:236] PADDING: 16\n",
"[NeMo I 2021-09-20 21:12:45 features:252] STFT using torch\n",
"[NeMo I 2021-09-20 21:13:18 export:53] Model restored from '/results/speech_to_text/finetune/checkpoints/finetuned-model.tlt'\n",
"[NeMo W 2021-09-20 21:13:26 conv_asr:61] Turned off 108 masked convolutions\n",
"[NeMo I 2021-09-20 21:13:59 exportable:205] onnx-graphsurgeon module is not instlled.That may result in suboptimal optimization of exported ONNX graph (including unneeded DOUBLE initializers).Please follow the instructions available at:https://github.com/NVIDIA/TensorRT/tree/master/tools/onnx-graphsurgeonto install onnx-graphsurgeon from source to improve exported graph.\n",
"[NeMo W 2021-09-20 21:13:59 export_utils:198] Swapped 0 modules\n",
"[NeMo I 2021-09-20 21:13:59 exportable:205] onnx-graphsurgeon module is not instlled.That may result in suboptimal optimization of exported ONNX graph (including unneeded DOUBLE initializers).Please follow the instructions available at:https://github.com/NVIDIA/TensorRT/tree/master/tools/onnx-graphsurgeonto install onnx-graphsurgeon from source to improve exported graph.\n",
"[NeMo I 2021-09-20 21:15:22 export:68] Experiment logs saved to '/results/speech_to_text/riva'\n",
"[NeMo I 2021-09-20 21:15:22 export:69] Exported model to '/results/speech_to_text/riva/speech-to-text-model.riva'\n",
"2021-09-20 17:15:24,261 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.\n"
]
}
],
"source": [
"!tao speech_to_text export \\\n",
" -e $STT_TAO_CONFIG_DIR/export.yaml \\\n",
" -g 1 \\\n",
" -k $KEY \\\n",
" -m $STT_TAO_RESULTS_DIR/finetune/checkpoints/finetuned-model.tlt \\\n",
" -r $STT_TAO_RESULTS_DIR/riva \\\n",
" export_format=JARVIS \\\n",
" export_to=$STT_MODEL_NAME"
]
},
{
"cell_type": "markdown",
"id": "cdd56a21",
"metadata": {},
"source": [
"Copy the model to the RIVA model directory (`RIVA_MODEL_DIR`). **NOTE: Make sure this directory aligns with the config.sh file for RIVA.**"
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "2c2934d8",
"metadata": {},
"outputs": [],
"source": [
"!cp $STT_HOST_RESULTS_DIR/riva/$STT_MODEL_NAME $RIVA_MODEL_DIR/$STT_MODEL_NAME"
]
},
{
"cell_type": "markdown",
"id": "5327b9e5",
"metadata": {},
"source": [
"### Business Use Case\n",
"\n",
"There are business specific words and phrases that base ASR models (such as Jasper and Quartznet) are not likely to have seen in their training. Through the use of fine-tuning, industry specific vocabulary can be integrated into the model language."
]
},
{
"cell_type": "markdown",
"id": "e41b32c4",
"metadata": {},
"source": [
"# Sentiment Analysis"
]
},
{
"cell_type": "markdown",
"id": "8c8b1a21",
"metadata": {},
"source": [
"### Set TAO Toolkit Paths\n",
"\n",
"NOTE: The following paths are set from the perspective of the TAO Toolkit Docker."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "caf000d0",
"metadata": {},
"outputs": [],
"source": [
"SEA_TAO_DATA_DIR = \"/data\"\n",
"SEA_TAO_CONFIG_DIR = \"/config/sentiment_analysis\"\n",
"SEA_TAO_RESULTS_DIR = \"/results/sentiment_analysis\"\n",
"\n",
"# The encryption key from config.sh. Use the same key for all commands\n",
"KEY = 'tlt_encode'"
]
},
{
"cell_type": "markdown",
"id": "1e6c923a",
"metadata": {},
"source": [
"### Downloading Specs\n",
"We can proceed to downloading the spec files. The user may choose to modify/rewrite these specs, or even individually override them through the launcher. You can download the default spec files by using the `download_specs` command.
\n",
"\n",
"The -o argument indicating the folder where the default specification files will be downloaded, and -r that instructs the script where to save the logs. **Make sure the -o points to an empty folder!**\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "06794f5b",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"!tao text_classification download_specs \\\n",
" -r $SEA_TAO_RESULTS_DIR \\\n",
" -o $SEA_TAO_CONFIG_DIR"
]
},
{
"cell_type": "markdown",
"id": "75b5ee98",
"metadata": {},
"source": [
"\n",
"### Dataset Convert\n",
"\n",
"- source_data_dir: directory path for the downloaded dataset\n",
"- target_data_dir: directory path for the processed dataset"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c9052bfd",
"metadata": {},
"outputs": [],
"source": [
"# For BERT dataset conversion\n",
"!tao text_classification dataset_convert \\\n",
" -e $SEA_TAO_CONFIG_DIR/dataset_convert.yaml \\\n",
" -r $SEA_TAO_CONFIG_DIR/dataset_convert \\\n",
" dataset_name=sst2 source_data_dir=$SEA_TAO_DATA_DIR/SST-2 target_data_dir=$SEA_TAO_DATA_DIR/processed"
]
},
{
"cell_type": "markdown",
"id": "f4d9a2ff",
"metadata": {},
"source": [
"\n",
"### Training\n",
"\n",
"Training a model using TAO Toolkit is as simple as configuring your spec file and running the train command. The code cell below uses the default train.yaml available for users as reference. It is configured by default to use the `bert-base-uncased` pretrained model. Additionally, these configurations could easily be overridden using the tlt-launcher CLI as shown below. For instance, below we override the `training_ds.file`, `validation_ds.file`, `trainer.max_epochs`, `training_ds.num_workers` and `validation_ds.num_workers` configurations to suit our needs. We encourage you to take a look at the .yaml spec files we provide!
\n",
"\n",
"In order to get good results, you need to train for 20-50 epochs (depends on the size of the data). Training with 1 epoch in the tutorial is just for demonstration purposes.\n",
"\n",
"\n",
"For training a Text Classification model in TAO Toolkit, we use the `tao text_classification train` command with the following args:\n",
"- `-e`: Path to the spec file\n",
"- `-g`: Number of GPUs to use\n",
"- `-k`: User specified encryption key to use while saving/loading the model\n",
"- `-r`: Path to a folder where the outputs should be written. Make sure this is mapped in tlt_mounts.json\n",
"- Any overrides to the spec file eg. trainer.max_epochs\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e5ff7e4b",
"metadata": {},
"outputs": [],
"source": [
"# For BERT training on SST-2\n",
"!tao text_classification train \\\n",
" -e $SEA_TAO_CONFIG_DIR/train.yaml \\\n",
" -g 1 \\\n",
" -k $KEY \\\n",
" -r $SEA_TAO_RESULTS_DIR/train \\\n",
" training_ds.file_path=$SEA_TAO_DATA_DIR/processed/train.tsv \\\n",
" validation_ds.file_path=$SEA_TAO_DATA_DIR/processed/dev.tsv \\\n",
" model.class_labels.class_labels_file=$SEA_TAO_DATA_DIR/processed/label_ids.csv \\\n",
" trainer.max_epochs=10 \\\n",
" optim.lr=0.00002"
]
},
{
"cell_type": "markdown",
"id": "58e79da0",
"metadata": {},
"source": [
"\n",
"### Fine-Tuning\n",
"\n",
"The command for fine-tuning is very similar to that of training. Instead of `tao text_classification train`, we use `tao text_classification finetune` instead. We also specify the spec file corresponding to fine-tuning. All commands in TAO Toolkit follow a similar pattern.\n",
"\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3dfdeee0",
"metadata": {},
"outputs": [],
"source": [
"!tao text_classification finetune \\\n",
" -e $SEA_TAO_CONFIG_DIR/finetune.yaml \\\n",
" -g 1 \\\n",
" -m $SEA_TAO_RESULTS_DIR/train/checkpoints/trained-model.tlt \\\n",
" -k $KEY \\\n",
" -r $SEA_TAO_RESULTS_DIR/finetune \\\n",
" finetuning_ds.file_path=$SEA_TAO_DATA_DIR/processed/train.tsv \\\n",
" validation_ds.file_path=$SEA_TAO_DATA_DIR/processed/dev.tsv \\\n",
" trainer.max_epochs=10 \\\n",
" optim.lr=0.00002"
]
},
{
"cell_type": "markdown",
"id": "767cc0f2",
"metadata": {},
"source": [
"\n",
"### Evaluation\n",
"The evaluation spec .yaml is as simple as:\n",
"\n",
"```\n",
"test_ds:\n",
" file: ??? # e.g. $DATA_DIR/test.tsv\n",
" batch_size: 32\n",
" shuffle: false\n",
" num_samples: 500\n",
"```\n",
"\n",
"Below, we use `tao text_classification evaluate` and override the test data configuration by specifying `test_ds.file_path`. Other arguments follow the same pattern as before.\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ffa456dd",
"metadata": {},
"outputs": [],
"source": [
"!tao text_classification evaluate \\\n",
" -e $SEA_TAO_CONFIG_DIR/evaluate.yaml \\\n",
" -g 1 \\\n",
" -m $SEA_TAO_RESULTS_DIR/finetune/checkpoints/finetuned-model.tlt \\\n",
" -k $KEY \\\n",
" -r $SEA_TAO_RESULTS_DIR/evaluate \\\n",
" test_ds.file_path=$SEA_TAO_DATA_DIR/SST-2/dev.tsv \\\n",
" test_ds.batch_size=32"
]
},
{
"cell_type": "markdown",
"id": "b24b57c2",
"metadata": {},
"source": [
"\n",
"### Export to Riva\n",
"\n",
"With TAO Toolkit, you can also export your model in a format that can deployed using [NVIDIA Riva](https://developer.nvidia.com/riva), a highly performant application framework for multi-modal conversational AI services using GPUs! The same command for exporting to ONNX can be used here. The only small variation is the configuration for `export_format` in the spec file!"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3f7d43c9",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"!tao text_classification export \\\n",
" -e $SEA_TAO_CONFIG_DIR/export.yaml \\\n",
" -g 1 \\\n",
" -m $SEA_TAO_RESULTS_DIR/finetune/checkpoints/finetuned-model.tlt \\\n",
" -k $KEY \\\n",
" -r $SEA_TAO_RESULTS_DIR/riva \\\n",
" export_format=JARVIS \\\n",
" export_to=$SEA_MODEL_NAME"
]
},
{
"cell_type": "markdown",
"id": "9e918f8f",
"metadata": {},
"source": [
"Copy the model to the RIVA model directory (`RIVA_MODEL_DIR`). **`NOTE`: Make sure this directory aligns with the config.sh file for RIVA.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b7073904",
"metadata": {},
"outputs": [],
"source": [
"!cp $SEA_HOST_RESULTS_DIR/riva/$SEA_MODEL_NAME $RIVA_MODEL_DIR/$SEA_MODEL_NAME"
]
},
{
"cell_type": "markdown",
"id": "031f147e",
"metadata": {},
"source": [
"### Business Use Case\n",
"\n",
"There are customer specific words and phrases that base BERT models are not likely to have seen in their training. Through the use of fine-tuning, industry specific vocabulary can be integrated into the model language."
]
},
{
"cell_type": "markdown",
"id": "33d5112d",
"metadata": {},
"source": [
"# TAO Toolkit-RIVA Integration\n",
"\n",
"In the previous sections, the speech-to-text and sentiment analysis models were saved to the .riva format. The next step is to convert these models to the .rimr format so they can be deployed on a RIVA server.\n",
"\n",
"For more information on how to build and deploy models using the TAO Toolkit, visit [here](https://developer.nvidia.com/blog/building-and-deploying-conversational-ai-models-using-tao-toolkit/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "dc36d607",
"metadata": {},
"outputs": [],
"source": [
"# ServiceMaker Docker image (must be the same as the image_init_speech in config.sh)\n",
"RIVA_SM_CONTAINER = \"nvcr.io/nvidia/riva/riva-speech:1.4.0-beta-servicemaker\"\n",
"\n",
"# Model names (must be the same as in config.sh)\n",
"RIVA_STT_MODEL_NAME = STT_MODEL_NAME.replace(\".riva\",\".rmir\")\n",
"RIVA_SEA_MODEL_NAME = SEA_MODEL_NAME.replace(\".riva\",\".rmir\")\n",
"\n",
"print(f\"Saved models '{RIVA_STT_MODEL_NAME}' and '{RIVA_SEA_MODEL_NAME}'\")"
]
},
{
"cell_type": "markdown",
"id": "10009312",
"metadata": {},
"source": [
"Check all the trained models are in the correct directory."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7973869b",
"metadata": {},
"outputs": [],
"source": [
"trained_models = os.listdir(RIVA_MODEL_DIR)\n",
"trained_models = [f for f in trained_models if \".riva\" in f]\n",
"\n",
"assert STT_MODEL_NAME in trained_models, f\"Missing the speech-to-text model named '{STT_MODEL_NAME}'\"\n",
"assert SEA_MODEL_NAME in trained_models, f\"Missing the sentiment analysis model named '{SEA_MODEL_NAME}'\""
]
},
{
"cell_type": "markdown",
"id": "4a54a8f9",
"metadata": {},
"source": [
"### 1. Riva-build\n",
"\n",
"This step helps build a Riva-ready version of the model. It’s only output is an intermediate format (called a RMIR) of an end to end pipeline for the supported services within Riva. We are taking a ASR QuartzNet Model in consideration.\n",
"\n",
"riva-build is responsible for the combination of one or more exported models (.riva files) into a single file containing an intermediate format called Riva Model Intermediate Representation (.rmir). This file contains a deployment-agnostic specification of the whole end-to-end pipeline along with all the assets required for the final deployment and inference."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "887a4afe",
"metadata": {},
"outputs": [],
"source": [
"!docker pull $RIVA_SM_CONTAINER"
]
},
{
"cell_type": "markdown",
"id": "beeeb398",
"metadata": {},
"source": [
"#### Builds the speech-to-text model"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2021b382",
"metadata": {},
"outputs": [],
"source": [
"!docker run --rm --gpus 0 -v $RIVA_MODEL_DIR:/data $RIVA_SM_CONTAINER -- \\\n",
" riva-build speech_recognition -f /data/$RIVA_STT_MODEL_NAME:$KEY /data/$STT_MODEL_NAME:$KEY \\\n",
" --offline --decoder_type=greedy"
]
},
{
"cell_type": "markdown",
"id": "d68e6287",
"metadata": {},
"source": [
"#### Builds the sentiment analysis model"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6d999a12",
"metadata": {},
"outputs": [],
"source": [
"!docker run --rm --gpus 0 -v $RIVA_MODEL_DIR:/data $RIVA_SM_CONTAINER -- \\\n",
" riva-build text_classification -f /data/$RIVA_SEA_MODEL_NAME:$KEY /data/$SEA_MODEL_NAME:$KEY"
]
},
{
"cell_type": "markdown",
"id": "85898915",
"metadata": {},
"source": [
"### 2. Riva-deploy\n",
"\n",
"The deployment tool takes as input one or more Riva Model Intermediate Representation (RMIR) files and a target model repository directory. It creates an ensemble configuration specifying the pipeline for the execution and finally writes all those assets to the output model repository directory.\n",
"\n",
"Note that this step is analogous to running `riva_init.sh`."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0194bbf4",
"metadata": {},
"outputs": [],
"source": [
"!docker run --rm --gpus 0 -v $RIVA_MODEL_DIR:/data $RIVA_SM_CONTAINER -- \\\n",
" riva-deploy -f /data/$RIVA_STT_MODEL_NAME:$KEY /data/models"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b5d2a43c",
"metadata": {},
"outputs": [],
"source": [
"!docker run --rm --gpus 0 -v $RIVA_MODEL_DIR:/data $RIVA_SM_CONTAINER -- \\\n",
" riva-deploy -f /data/$RIVA_SEA_MODEL_NAME:$KEY /data/models"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.1"
}
},
"nbformat": 4,
"nbformat_minor": 5
}