# OlympiadBench

📄 Paper |
🤗 Hugging Face |
⏬ Data
This repo contains the evaluation code for the paper "[OlympiadBench: A Challenging Benchmark for Promoting AGI with
Olympiad-Level Bilingual Multimodal Scientific Problems](https://arxiv.org/pdf/2402.14008.pdf)"
## News!
- **[2024-07-17]** We update the dataset and upload it to [Hugging Face](https://huggingface.co/datasets/Hothan/OlympiadBench). The whole data can be accessed via this [**download link**](https://drive.google.com/file/d/1DnTCrvIv5vbfDmi2yYaCWnzUhvD34oB0/view?usp=sharing).
- **[2024-05-16]** OlympiadBench has been accepted to the main conference at [ACL 2024](https://2024.aclweb.org/).
- **[2024-03-24]** We publish the [experimental code](./inference/) and make updates to the dataset【Previous dataset can be downloaded via this [link](https://drive.google.com/file/d/1Ga_gnrgRWsM59mxLZBa_0GQ2sRfNiTtL/view?usp=sharing)】.
- **[2024-02-16]** The 🔥🔥OlympiadBench🔥🔥 benchmark is released! You can download the dataset from [here](https://drive.google.com/file/d/1-CWyWA01BQ2RObs-HXKNHarByDwFXloR/view?usp=drive_link).
## Leaderboard
### Experiment with full benchmark
| Model | Math | Physics | Avg. |
|------------------------|--------|-------|--------|
| GPT-4o | 32.48 | 13.10 | 25.89 |
| GPT-4V | 21.70 | 10.74 | 17.97 |
| Qwen-VL-Max | 12.65 | 5.09 | 10.09 |
| Claude3-Opus | 9.06 | 4.93 | 7.65 |
| Gemini-Pro-Vision | 5.14 | 2.45 | 4.22 |
| Yi-VL-34B | 4.23 | 1.46 | 3.42 |
| LLaVA-NeXT-34B | 4.30 | 2.08 | 3.65 |
### Experiment with text-only problems
| Model | Math | Physics | Avg. |
|------------------------|--------|-------|--------|
| GPT-4o | 41.54 | 27.64 | 39.72 |
| GPT-4 | 32.00 | 16.24 | 29.93 |
| GPT-4V | 31.01 | 16.24 | 29.07 |
| Qwen-VL-Max | 19.70 | 8.83 | 18.27 |
| Claude3-Opus | 13.43 | 10.83 | 13.09 |
| Gemini-Pro-Vision | 7.63 | 5.41 | 7.34 |
| Llama-3-70B-Instruct | 20.92 | 15.95 | 20.27 |
| DeepSeekMath-7B-RL | 18.09 | 9.97 | 17.02 |
| Yi-VL-34B | 6.24 | 2.28 | 5.72 |
| LLaVA-NeXT-34B | 6.29 | 3.13 | 5.87 |
## Overview
We introduce OlympiadBench, an Olympiad-level bilingual multimodal scientific benchmark. Notably, the best-performing model, GPT-4V, attains an average score of 17.97\% on OlympiadBench, with a mere 10.74\% in physics, highlighting the benchmark rigor and the intricacy of physical reasoning.

## Data process
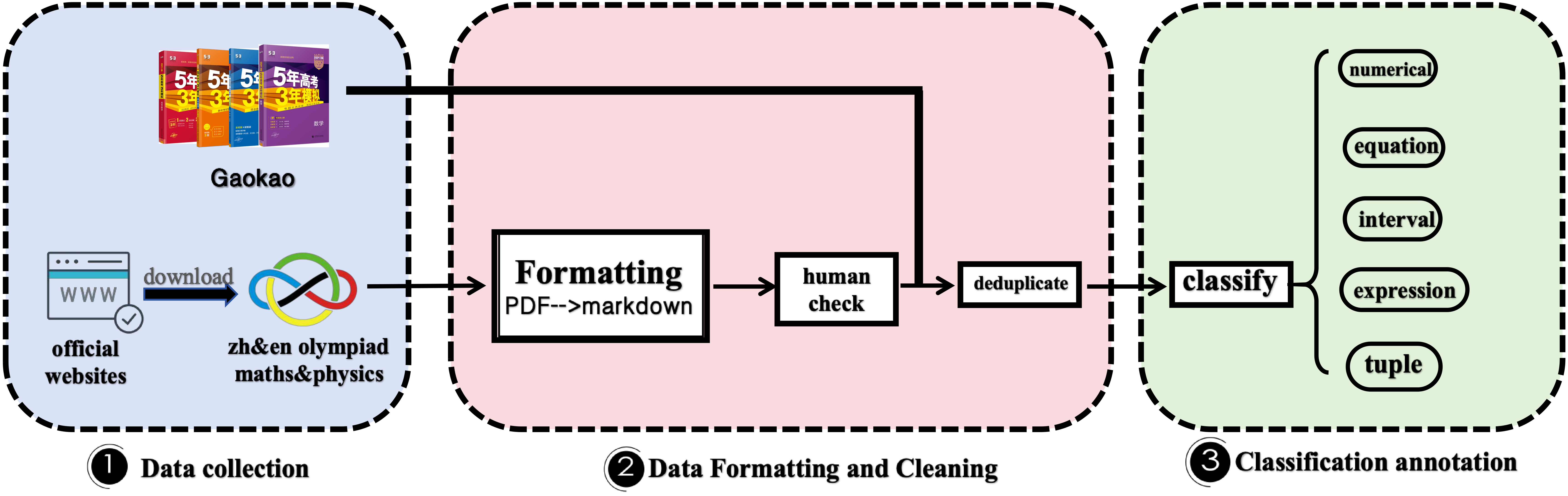
This collection comprises 8,476 math and physics problems sourced from:
- International Olympiads;
- Chinese Olympiads;
- the Chinese College Entrance Exam (GaoKao)
We use Mathpix OCR to parse official PDFs, then meticulously inspect, clean, revise and dedupe the data. Finally, we annotate the data with crucial information such as answer types and subfields, yielding a dataset that is clean, accurate, and detailed. OlympiadBench includes open-ended questions and proof problems. For the open-ended questions, we standardize the answer format and develop an automated scoring pipeline [here](eval/auto_scoring_judge.py). For the proof problems, we conduct sample assessments.
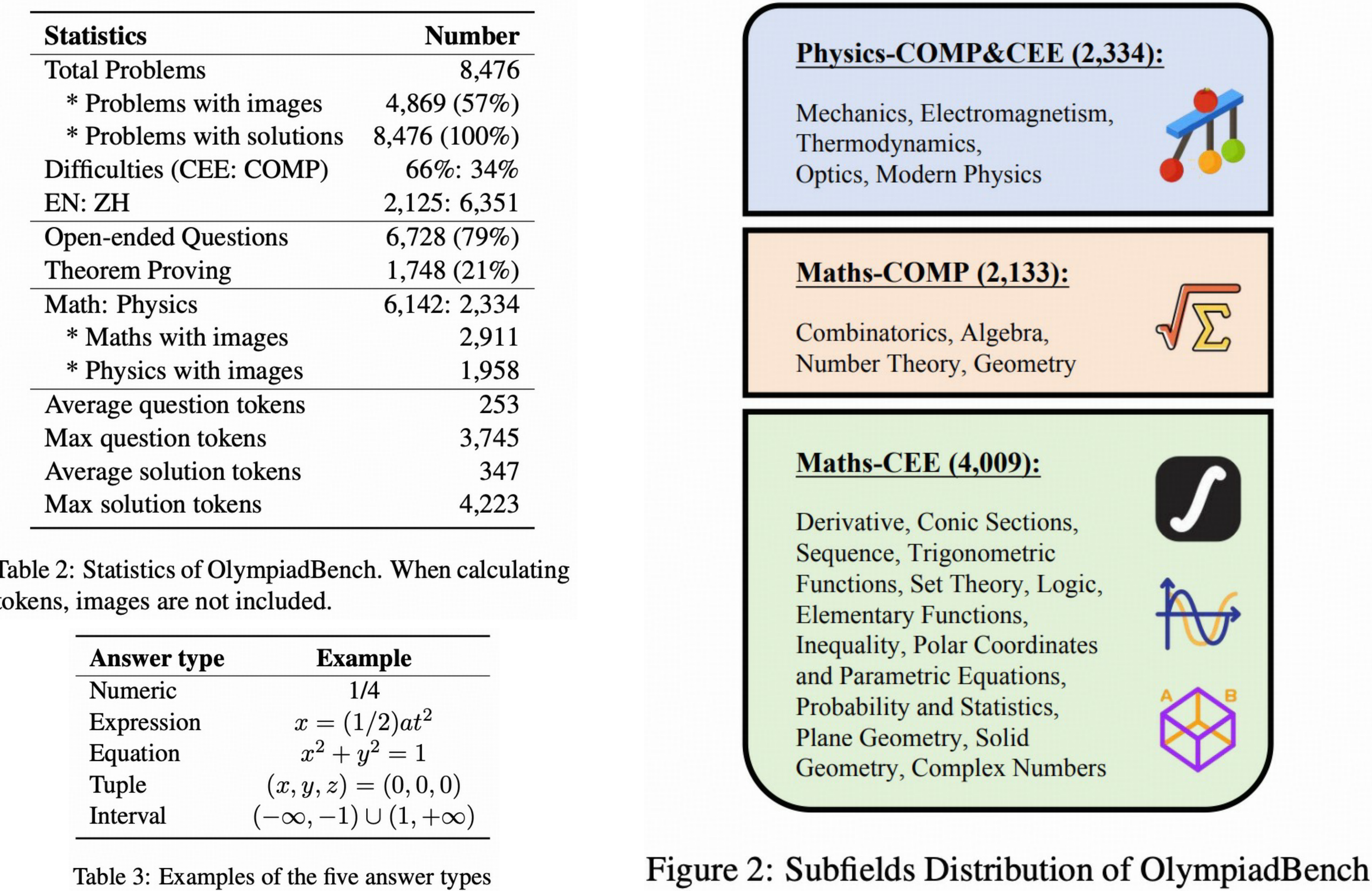

The downloaded dataset contains two folders, ``data`` and ``images``.
The ``data`` contains the categorized data. For example, OE_MM_physics_en_COMP.json, TP_TO_maths_zh_CEE.json.
* OE: Open-ended questions
* TP: Theorem proof problems
* MM: Multimodal
* TO: Text-only
* physics: Physics problems
* maths: Math problems
* en: English
* zh: Chinese
* COMP: Competition problems
* CEE: Chinese College Entrance Exam problems
``images`` contains the corresponding images in ``data``.
The data format for all datasets is as follows:
{
"id": 2231,
"subfield": "Geometry",
"context": null,
"question": "Turbo the snail sits on a point on a circle with circumference 1. Given an infinite sequence of positive real numbers $c_{1}, c_{2}, c_{3}, \\ldots$. Turbo successively crawls distances $c_{1}, c_{2}, c_{3}, \\ldots$ around the circle, each time choosing to crawl either clockwise or counterclockwise.\n\nFor example, if the sequence $c_{1}, c_{2}, c_{3}, \\ldots$ is $0.4,0.6,0.3, \\ldots$, then Turbo may start crawling as follows:\n\n\nDetermine the largest constant $C>0$ with the following property: for every sequence of positive real numbers $c_{1}, c_{2}, c_{3}, \\ldots$ with $c_{i} The key results are as follows:
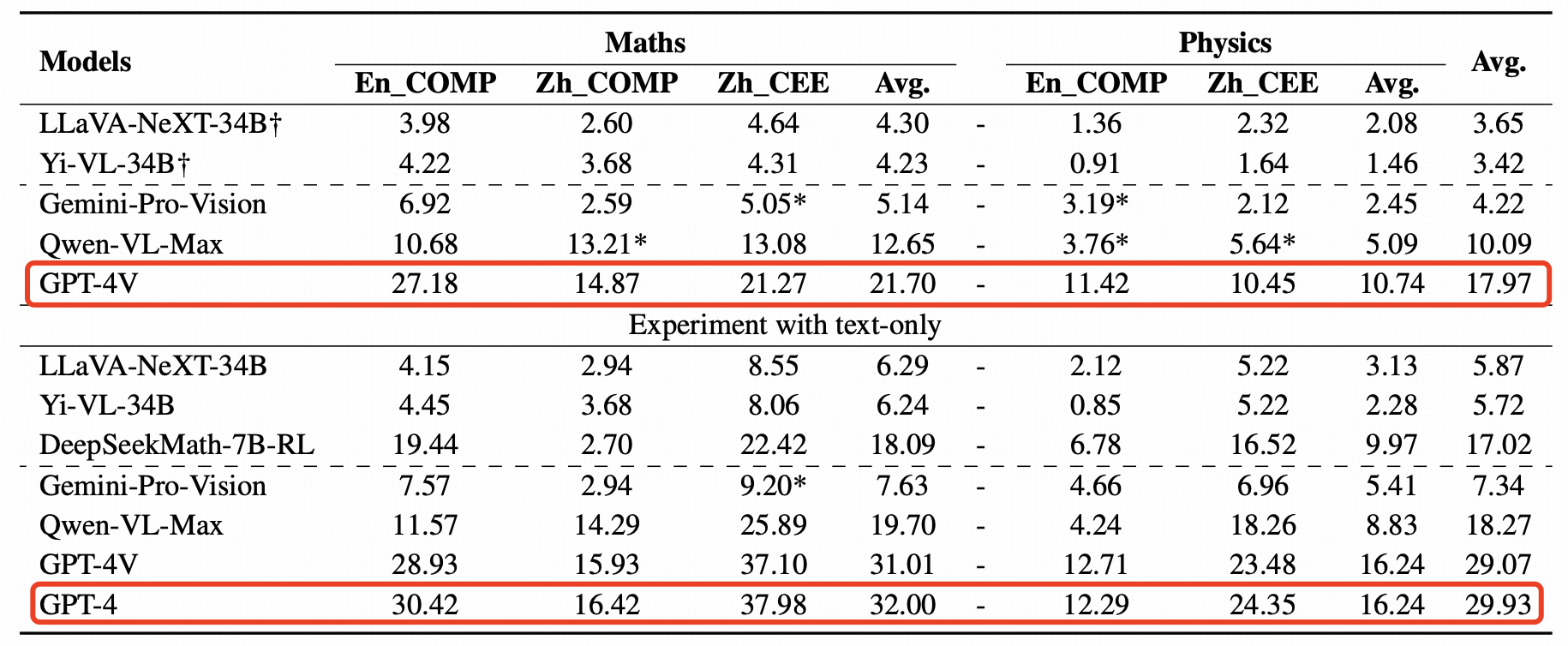
- GPT-4V only achieves 17.97%. GPT-4 gets 29.93% on text-only tasks.
- A huge gap between closed- and open-source models.
- The challenge lies more on question-with-images, Physics and none-English text.
The key results are as follows:
- GPT-4V only achieves 17.97%. GPT-4 gets 29.93% on text-only tasks.
- A huge gap between closed- and open-source models.
- The challenge lies more on question-with-images, Physics and none-English text.
## Contact
If interested in our work, please contact us at:
- Chaoqun He: hechaoqun1998@gmail.com
- Renjie Luo: renjie.luo@outlook.com
- Yuzhuo Bai: byz22@mails.tsinghua.edu.cn
## Citation
**BibTeX:**
```bibtex
@misc{he2024olympiadbench,
title={OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems},
author={Chaoqun He and Renjie Luo and Yuzhuo Bai and Shengding Hu and Zhen Leng Thai and Junhao Shen and Jinyi Hu and Xu Han and Yujie Huang and Yuxiang Zhang and Jie Liu and Lei Qi and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2402.14008},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```