[[English Document](https://github.com/OpenGVLab/internGPT/blob/main/README.md)]
**[NOTE] 该项目仍在建设中,我们将继续更新,并欢迎社区的贡献/拉取请求。**

 |
|
 |
|
 # 🤖💬 InternGPT [[论文](https://arxiv.org/pdf/2305.05662.pdf)]
**InternGPT**(简称 **iGPT**) / **InternChat**(简称 **iChat**) 是一种基于指向语言驱动的视觉交互系统,允许您使用指向设备通过点击、拖动和绘制与 ChatGPT 进行互动。internGPT 的名称代表了 **inter**action(交互)、**n**onverbal(非语言)和 Chat**GPT**。与依赖纯语言的现有交互系统不同,通过整合指向指令,iGPT 显著提高了用户与聊天机器人之间的沟通效率,以及聊天机器人在视觉为中心任务中的准确性,特别是在复杂的视觉场景中。此外,在 iGPT 中,采用辅助控制机制来提高 LLM 的控制能力,并对一个大型视觉-语言模型 **Husky** 进行微调,以实现高质量的多模态对话(在ChatGPT-3.5-turbo评测中达到 **93.89% GPT-4 质量**)。
## 🥳 🚀 更新
- (2023.05.24) 🎉🎉🎉 现在已经支持[DragGAN](https://github.com/Zeqiang-Lai/DragGAN)! 使用方法请参考[视频演示](#draggan_demo)。赶紧来体验这个新功能吧: [Demo](https://igpt.opengvlab.com/).
- (2023.05.18) 已支持[ImageBind](https://github.com/facebookresearch/ImageBind) 🎉🎉🎉。使用方法请参考[视频演示](#imagebind_demo)。赶紧来体验: [Demo](https://igpt.opengvlab.com/)
- (2023.05.15) [model_zoo](https://huggingface.co/spaces/OpenGVLab/InternGPT/tree/main/model_zoo) 已经公开,里面包含了HuskyVQA! 赶紧在你自己的机器上部署试试吧!
- (2023.05.15) 我们的代码在 [Hugging Face](https://huggingface.co/spaces/OpenGVLab/InternGPT)也同步更新! 你可以复制一份仓库,然后使用自己的GPU运行demo。
## 🤖💬 在线Demo
**InternGPT** 上线了 (请访问: [https://igpt.opengvlab.com](https://igpt.opengvlab.com/)). 赶紧来体验吧!
[注意] 可能会出现排队等待较长时间。您可以clone我们的仓库并使用您自己的GPU运行。
### 🧭 Usage Tips
更新:
(2023.05.24) 我们现在支持 [DragGAN](https://arxiv.org/abs/2305.10973)。你可以按照以下步骤试用:
- 点击 `New Image` 按钮;
- 点击图片,其中蓝色表示起点,红色表示终点;
- 注意蓝色点的个数要和红色点的个数相同。然后你可以点击 `Drag It` 按钮;
- 处理完成后,你会收到一张编辑后的图片和一个展示编辑过程的视频。
# 🤖💬 InternGPT [[论文](https://arxiv.org/pdf/2305.05662.pdf)]
**InternGPT**(简称 **iGPT**) / **InternChat**(简称 **iChat**) 是一种基于指向语言驱动的视觉交互系统,允许您使用指向设备通过点击、拖动和绘制与 ChatGPT 进行互动。internGPT 的名称代表了 **inter**action(交互)、**n**onverbal(非语言)和 Chat**GPT**。与依赖纯语言的现有交互系统不同,通过整合指向指令,iGPT 显著提高了用户与聊天机器人之间的沟通效率,以及聊天机器人在视觉为中心任务中的准确性,特别是在复杂的视觉场景中。此外,在 iGPT 中,采用辅助控制机制来提高 LLM 的控制能力,并对一个大型视觉-语言模型 **Husky** 进行微调,以实现高质量的多模态对话(在ChatGPT-3.5-turbo评测中达到 **93.89% GPT-4 质量**)。
## 🥳 🚀 更新
- (2023.05.24) 🎉🎉🎉 现在已经支持[DragGAN](https://github.com/Zeqiang-Lai/DragGAN)! 使用方法请参考[视频演示](#draggan_demo)。赶紧来体验这个新功能吧: [Demo](https://igpt.opengvlab.com/).
- (2023.05.18) 已支持[ImageBind](https://github.com/facebookresearch/ImageBind) 🎉🎉🎉。使用方法请参考[视频演示](#imagebind_demo)。赶紧来体验: [Demo](https://igpt.opengvlab.com/)
- (2023.05.15) [model_zoo](https://huggingface.co/spaces/OpenGVLab/InternGPT/tree/main/model_zoo) 已经公开,里面包含了HuskyVQA! 赶紧在你自己的机器上部署试试吧!
- (2023.05.15) 我们的代码在 [Hugging Face](https://huggingface.co/spaces/OpenGVLab/InternGPT)也同步更新! 你可以复制一份仓库,然后使用自己的GPU运行demo。
## 🤖💬 在线Demo
**InternGPT** 上线了 (请访问: [https://igpt.opengvlab.com](https://igpt.opengvlab.com/)). 赶紧来体验吧!
[注意] 可能会出现排队等待较长时间。您可以clone我们的仓库并使用您自己的GPU运行。
### 🧭 Usage Tips
更新:
(2023.05.24) 我们现在支持 [DragGAN](https://arxiv.org/abs/2305.10973)。你可以按照以下步骤试用:
- 点击 `New Image` 按钮;
- 点击图片,其中蓝色表示起点,红色表示终点;
- 注意蓝色点的个数要和红色点的个数相同。然后你可以点击 `Drag It` 按钮;
- 处理完成后,你会收到一张编辑后的图片和一个展示编辑过程的视频。
(2023.05.18) 我们现在已支持 [ImageBind](https://github.com/facebookresearch/ImageBind)。如果你想根据音频生成一张新的图片,你可以提前上传一个音频文件:
- 从**单个音频生成新的图片**,你可以发送如下消息:`"generate a real image from this audio"`;
- 从**音频和文本生成新的图片**,你可以发送如下消息:`"generate a real image from this audio and {your prompt}"`;
- 从**音频和图片生成新的图片**,你需要再上传一个图片,然后发送如下消息:`"generate a new image from above image and audio"`;
**主要功能使用:**
在图片上传成功后, 您可以发送如下消息与iGPT进行多模态相关的对话:`"what is it in the image?"` or `"what is the background color of image?"`.
您同样也可以交互式地操作、编辑或者生成图片,具体如下:
- 点击图片上的任意位置,然后按下 **`Pick`** 按钮,**预览分割区域**。您也可以按下 **`OCR`** 按钮,识别具体位置处存在的所有单词;
- 要在图像中 **删除掩码区域**,您可以发送如下消息:`“remove the masked region”`;
- 要在图像中 **替换掩码区域的物体为其他物体**,您可以发送如下消息:`“replace the masked region with {your prompt}”`;
- 想 **生成新图像**,您可以发送如下消息:`“generate a new image based on its segmentation describing {your prompt}”`;
- 想通过 **涂鸦创建新图像**,您应该按下 **`Whiteboard`** 按钮并在白板上绘制。绘制完成后,您需要按下 **`保存`** 按钮并发送如下消息:`“generate a new image based on this scribble describing {your prompt}”`。
[**InternGPT** 已上线,尝试一下!](https://igpt.opengvlab.com)
**Video Demo with DragGAN: **
https://github.com/OpenGVLab/InternGPT/assets/13723743/529abde4-5dce-48de-bb38-0a0c199bb980
**iGPT + ImageBind视频演示:**
https://github.com/OpenGVLab/InternGPT/assets/13723743/bacf3e58-6c24-4c0f-8cf7-e0c4b8b3d2af
**iGPT 视频演示:**
https://github.com/OpenGVLab/InternGPT/assets/13723743/8fd9112f-57d9-4871-a369-4e1929aa2593
## 🗓️ 项目规划
- [ ] 支持中文
- [ ] 支持 MOSS
- [ ] 基于 InternImage 和 InternVideo 的更强大的基础模型
- [ ] 更准确的交互体验
- [ ] OpenMMLab Toolkit
- [ ] 网页 & 代码生成
- [ ] 支持搜索引擎
- [ ] 低成本部署
- [x] 支持 [DragGAN](https://arxiv.org/abs/2305.10973)
- [x] 支持 [ImageBind](https://github.com/facebookresearch/ImageBind)
- [x] Agent响应验证
- [x] 提示词优化
- [x] 用户手册和视频demo
- [x] 支持语音助手
- [x] 支持点击交互
- [x] 交互式图像编辑
- [x] 交互式图像生成
- [x] 交互式视觉问答
- [x] Segment Anything模型
- [x] 图像修复
- [x] 图像描述
- [x] 图像抠图
- [x] 光学字符识别(OCR)
- [x] 动作识别
- [x] 视频描述
- [x] 视频密集描述
- [x] 视频高光时刻截取
## 🏠 系统概览
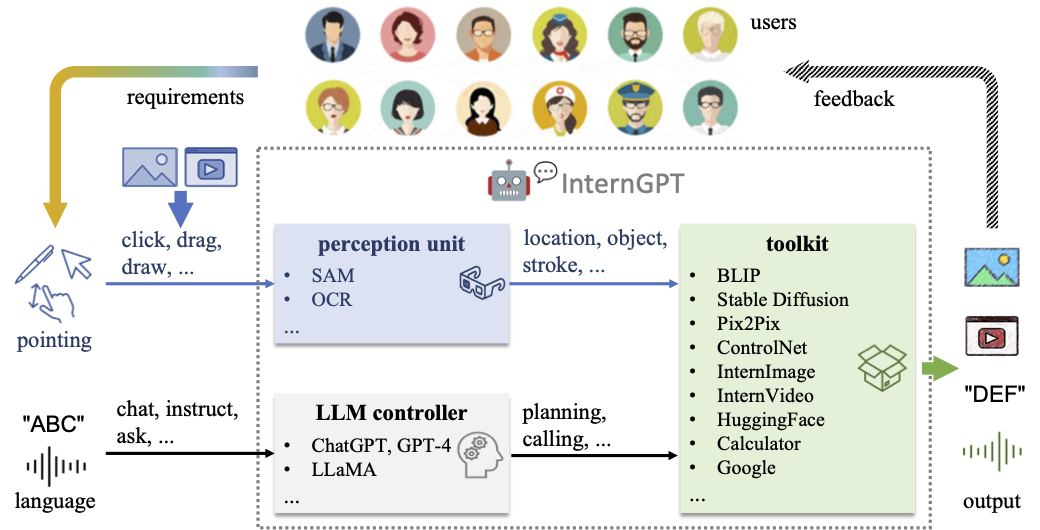
## 🎁 主要功能
A) 移除遮盖的对象

B) 交互式图像编辑

C) 图像生成

D) 交互式视觉问答

E) 交互式图像生成

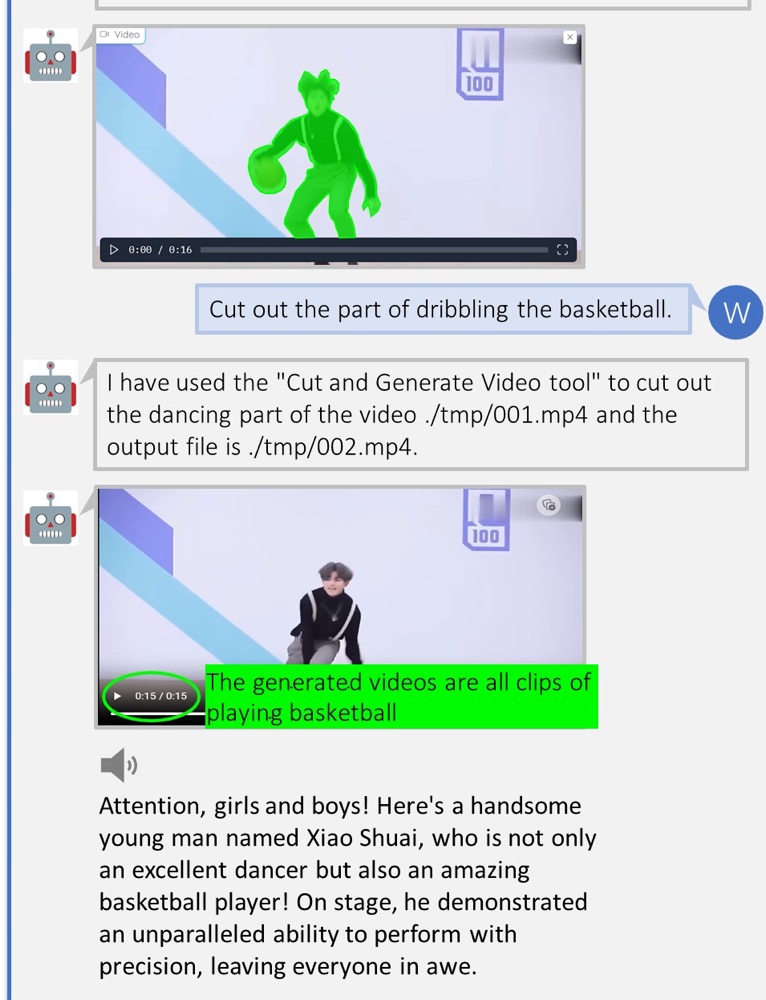
F) 视频高光解说
## 🛠️ 安装
### 基本要求
- Linux
- Python 3.8+
- PyTorch 1.12+
- CUDA 11.6+
- GCC & G++ 5.4+
- GPU Memory > 17G 用于加载基本工具 (HuskyVQA, SegmentAnything, ImageOCRRecognition)
### 安装Python的依赖项
```shell
pip install -r requirements.txt
```
### 🗃 模型库
我们模型库 `model_zoo` 正式在[huggingface](https://huggingface.co/spaces/OpenGVLab/InternGPT/tree/main/model_zoo)公开!在运行我们的demo前,你需要先将`model_zoo`下载到本地,然后放进项目的根目录下面。
小彩蛋:HuskyVQA模型也在`model_zoo`里开源了!经我们测试,HuskyVQA的视觉问答能力达到了业界顶尖水平。更多细节请参考我们的[report](https://arxiv.org/pdf/2305.05662.pdf)。
### 使用docker部署
请提前将`model_zoo`和`certificate`文件添加到项目的根目录下面, 然后将`docker/InternGPT_CN/docker-compose.yml`中的`/path/to/InternGPT`变量修改为项目根目录。
你可以修改`docker/InternGPT_CN/docker-compose.yml`文件中`command`部分的`load`变量来运行更多的功能。
```shell
cd docker/InternGPT_CN
# 构建镜像并运行一个容器
docker compose up
# 或者启动一个交互式BASH会话
docker compose run -i --entrypoint /bin/bash igpt_cn
```
## 👨🏫 运行指南
运行以下 shell 可启动一个 gradio 服务:
```shell
python -u app.py --load "HuskyVQA_cuda:0,SegmentAnything_cuda:0,ImageOCRRecognition_cuda:0" --port 3456 -e
```
如果您想启用语音助手,请使用 openssl 生成证书:
```shell
mkdir certificate
openssl req -x509 -newkey rsa:4096 -keyout certificate/key.pem -out certificate/cert.pem -sha256 -days 365 -nodes
```
然后运行:
```shell
python -u app.py --load "HuskyVQA_cuda:0,SegmentAnything_cuda:0,ImageOCRRecognition_cuda:0" --port 3456 --https -e
```
如果您想减少响应时间并且有足够的显存容量,请移除命令中的`-e`选项。
## 🎫 许可
该项目根据[Apache 2.0 license](LICENSE)发布。
## 🖊️ 引用
如果您在研究中发现这个项目有用,请考虑引用我们的论文:
```BibTeX
@article{2023interngpt,
title={InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language},
author={Liu, Zhaoyang and He, Yinan and Wang, Wenhai and Wang, Weiyun and Wang, Yi and Chen, Shoufa and Zhang, Qinglong and Yang, Yang and Li, Qingyun and Yu, Jiashuo and others},
journal={arXiv preprint arXiv:2305.05662},
year={2023}
}
```
## 🤝 致谢
感谢以下开源项目:
[Hugging Face](https://github.com/huggingface)
[LangChain](https://github.com/hwchase17/langchain)
[TaskMatrix](https://github.com/microsoft/TaskMatrix)
[SAM](https://github.com/facebookresearch/segment-anything)
[Stable Diffusion](https://github.com/CompVis/stable-diffusion)
[ControlNet](https://github.com/lllyasviel/ControlNet)
[InstructPix2Pix](https://github.com/timothybrooks/instruct-pix2pix)
[BLIP](https://github.com/salesforce/BLIP)
[Latent Diffusion Models](https://github.com/CompVis/latent-diffusion)
[EasyOCR](https://github.com/JaidedAI/EasyOCR)
[ImageBind](https://github.com/facebookresearch/ImageBind)
[DragGAN](https://github.com/XingangPan/DragGAN)
如果您在试用、运行、部署中有任何问题,欢迎加入我们的微信群讨论!如果您对项目有任何的想法和建议,欢迎加入我们的微信群讨论!
加入微信群组二维码:
