# MOSS-TTS-Nano

[English](README.md) | [简体中文](README_zh.md)
MOSS-TTS-Nano is an open-source **multilingual tiny speech generation model** from [MOSI.AI](https://mosi.cn/#hero) and the [OpenMOSS team](https://www.open-moss.com/). With only **0.1B parameters**, it is designed for **realtime speech generation**, can run directly on **CPU without a GPU**, and keeps the deployment stack simple enough for local demos, web serving, and lightweight product integration.
## MOSS-TTS 2.0 Feedback Collection
MOSS-TTS 2.0 is coming soon. To better optimize model capabilities and product experience, we are collecting feedback and suggestions from TTS users. Please take 2-3 minutes to fill out the [requirements collection form](https://acnc6zeentra.feishu.cn/share/base/form/shrcnyAe1LwqKWjCSuW4wiZ2Hef). Feature requests of any kind are welcome.
[demo_video.mp4](https://github.com/user-attachments/assets/25aca215-0bd7-4d0c-be95-8d1f6737aec8)
## News
* 2026.4.29: MOSS-TTS 2.0 is coming soon! We are collecting TTS feedback, suggestions, and feature requests via the [requirements collection form](https://acnc6zeentra.feishu.cn/share/base/form/shrcnyAe1LwqKWjCSuW4wiZ2Hef).
* 2026.4.27: We added updated evaluation results for [**MOSS-Audio-Tokenizer-Nano**](#moss-audio-tokenizer-nano), including reconstruction quality comparisons on speech, audio, and music benchmarks.
* 2026.4.17: We are excited to release a more efficient and fully standalone [**ONNX CPU Version**](#onnx-cpu-version), backed by the Hugging Face repositories [**MOSS-TTS-Nano-100M-ONNX**](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano-100M-ONNX) and [**MOSS-Audio-Tokenizer-Nano-ONNX**](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano-ONNX). It preserves the full voice cloning workflow while removing the PyTorch dependency during inference. In our tests, it delivers nearly **2x** the processing efficiency of the original version, and runs smoothly on a **single CPU core** on a **MacBook Air M4**. Built on top of this ONNX CPU version, we have also updated [**MOSS-TTS-Nano-Reader**](https://github.com/OpenMOSS/MOSS-TTS-Nano-Reader), which can now run the model directly inside the browser as an extension, without requiring a separate local inference service.
* 2026.4.16: We release the **MOSS-TTS-Nano finetuning code**. See [./finetuning/README.md](./finetuning/README.md) for training and usage details.
* 2026.4.14: We release [**MOSS-TTS-Nano-Reader**](https://github.com/OpenMOSS/MOSS-TTS-Nano-Reader), a local browser reading application built on top of **MOSS-TTS-Nano**.
* 2026.4.10: We release **MOSS-TTS-Nano**. A demo Space is available at [OpenMOSS-Team/MOSS-TTS-Nano](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTS-Nano). You can also view the demo and more details at [openmoss.github.io/MOSS-TTS-Nano-Demo/](https://openmoss.github.io/MOSS-TTS-Nano-Demo/).
## Demo
- Online Demo: [https://openmoss.github.io/MOSS-TTS-Nano-Demo/](https://openmoss.github.io/MOSS-TTS-Nano-Demo/)
- Hugging Face Space: [OpenMOSS-Team/MOSS-TTS-Nano](https://huggingface.co/spaces/OpenMOSS-Team/MOSS-TTS-Nano)
## Contents
- [News](#news)
- [Demo](#demo)
- [Introduction](#introduction)
- [Main Features](#main-features)
- [Supported Languages](#supported-languages)
- [Quickstart](#quickstart)
- [Environment Setup](#environment-setup)
- [Voice Clone with `infer.py`](#voice-clone-with-inferpy)
- [Local Web Demo with `app.py`](#local-web-demo-with-apppy)
- [ONNX CPU Inference](#onnx-cpu-version)
- [Export TTS-only ONNX Weights](#export-tts-only-onnx-weights)
- [CLI Command: `moss-tts-nano generate`](#cli-command-moss-tts-nano-generate)
- [CLI Command: `moss-tts-nano serve`](#cli-command-moss-tts-nano-serve)
- [Finetuning](#finetuning)
- [MOSS-Audio-Tokenizer-Nano](#moss-audio-tokenizer-nano)
- [MOSS-TTS Family](#moss-tts)
- [License](#license)
- [Citation](#citation)
- [Star History](#star-history)
## Introduction

MOSS-TTS-Nano focuses on the part of TTS deployment that matters most in practice: **small footprint**, **low latency**, **good enough quality for realtime products**, and **simple local setup**. It uses a pure autoregressive **Audio Tokenizer + LLM** pipeline and keeps the inference workflow friendly for both terminal users and web-demo users.
### Main Features
- **Tiny model size**: only **0.1B parameters**
- **Native audio format**: **48 kHz**, **2-channel** output
- **Multilingual**: supports **Chinese, English, and more**
- **Pure autoregressive architecture**: built on **Audio Tokenizer + LLM**
- **Streaming inference**: low realtime latency and fast first audio
- **CPU friendly**: streaming generation can run on a **4-core CPU**
- **Long-text capable**: supports long input with automatic chunked voice cloning
- **Open-source deployment**: direct `python infer.py`, `python app.py`, and packaged CLI support
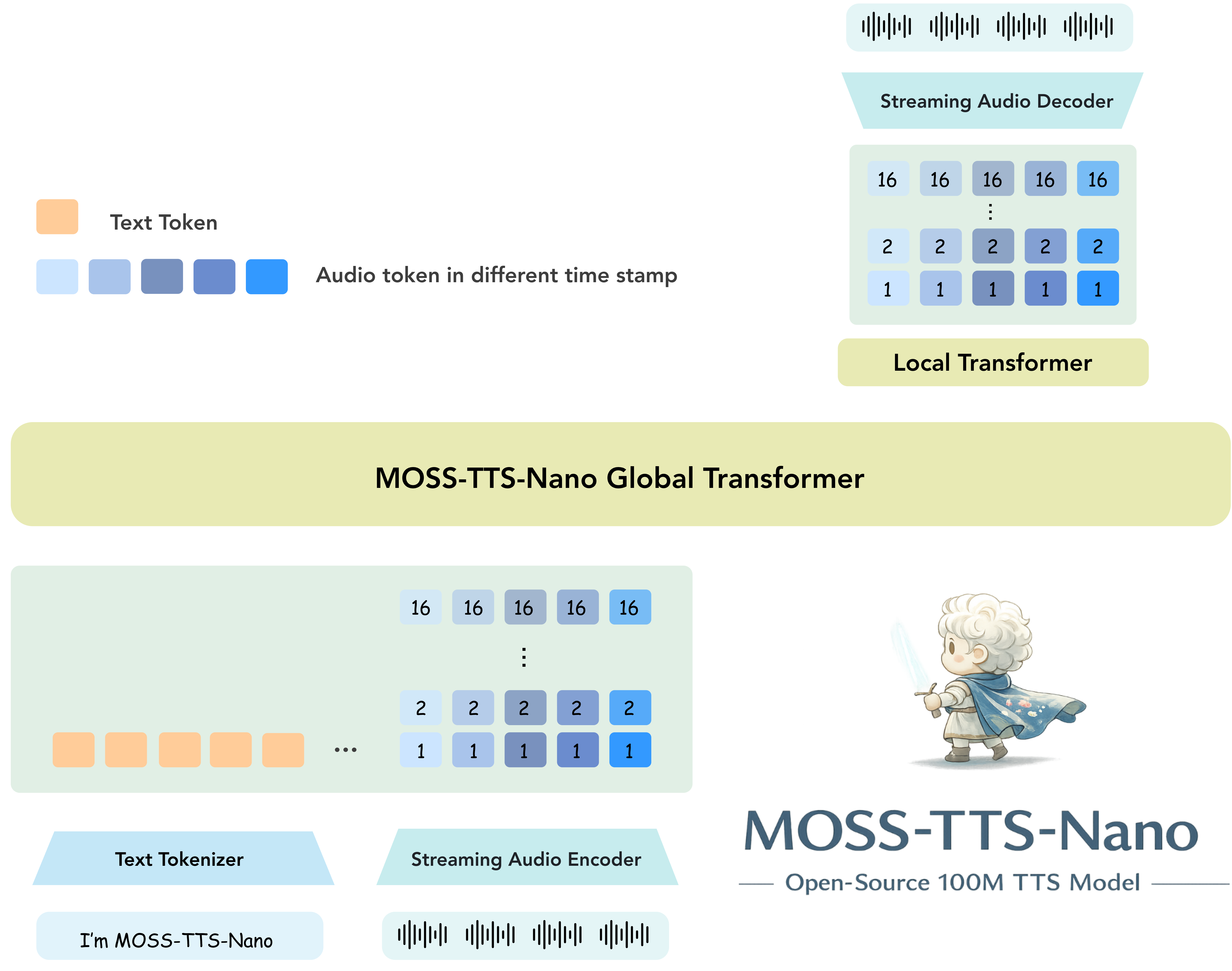
Architecture of MOSS-TTS-Nano
## Supported Languages
MOSS-TTS-Nano currently supports **20 languages**:
| Language | Code | Flag | Language | Code | Flag | Language | Code | Flag |
|---|---|---|---|---|---|---|---|---|
| Chinese | zh | 🇨🇳 | English | en | 🇺🇸 | German | de | 🇩🇪 |
| Spanish | es | 🇪🇸 | French | fr | 🇫🇷 | Japanese | ja | 🇯🇵 |
| Italian | it | 🇮🇹 | Hungarian | hu | 🇭🇺 | Korean | ko | 🇰🇷 |
| Russian | ru | 🇷🇺 | Persian (Farsi) | fa | 🇮🇷 | Arabic | ar | 🇸🇦 |
| Polish | pl | 🇵🇱 | Portuguese | pt | 🇵🇹 | Czech | cs | 🇨🇿 |
| Danish | da | 🇩🇰 | Swedish | sv | 🇸🇪 | Greek | el | 🇬🇷 |
| Turkish | tr | 🇹🇷 | | | | | | |
## Quickstart
### Environment Setup
We recommend a clean Python environment first, then installing the project in editable mode so the `moss-tts-nano` command becomes available locally.
The examples below intentionally keep arguments minimal and rely on the repository defaults.
By default, the code loads `OpenMOSS-Team/MOSS-TTS-Nano` and `OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano`.
#### Using Conda
```bash
conda create -n moss-tts-nano python=3.12 -y
conda activate moss-tts-nano
git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
cd MOSS-TTS-Nano
pip install -r requirements.txt
pip install -e .
```
If `WeTextProcessing` or `pynini` fails to install from `requirements.txt`, install `pynini` first in the same environment, then install `WeTextProcessing`, remove `WeTextProcessing` from `requirements.txt`, and finally rerun `pip install -r requirements.txt`.
With Conda, we recommend:
```bash
conda install -c conda-forge pynini=2.1.6.post1 -y
pip install git+https://github.com/WhizZest/WeTextProcessing.git
pip install -r requirements.txt
```
If you are not using Conda, make sure you download a `pynini` wheel that matches your Python version and platform before installing `WeTextProcessing`. For a community-tested example, see [Issue #6](https://github.com/OpenMOSS/MOSS-TTS-Nano/issues/6).
### Voice Clone with `infer.py`
This repository keeps the direct Python entrypoint for local inference. The example below uses **voice clone mode**, which is the main recommended workflow for MOSS-TTS-Nano.
```bash
python infer.py \
--prompt-audio-path assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
```
This writes audio to `generated_audio/infer_output.wav` by default.
### Local Web Demo with `app.py`
You can launch the local FastAPI demo for browser-based testing:
```bash
python app.py
```
Then open `http://127.0.0.1:18083` in your browser.
### ONNX CPU Inference
We now strongly recommend trying the **ONNX CPU version** first for lightweight local deployment and CPU inference.
This version is designed to be more deployment-friendly while keeping the same core MOSS-TTS-Nano experience:
- **No PyTorch dependency during inference**: it runs directly on ONNX Runtime CPU.
- **Fully standalone CPU deployment**: suitable for local demos, services, and lightweight integration.
- **Feature-complete voice cloning workflow**: supports direct reference audio input, built-in voices, and `Realtime Streaming Decode`.
- **Faster in practice**: in our tests, processing efficiency is nearly **2x** that of the original version.
- **Strong single-core usability**: on a **MacBook Air M4**, we observed smooth inference with only **1 CPU core**.
The ONNX entrypoints are `infer_onnx.py`, `app_onnx.py`, and the packaged CLI with `--backend onnx`.
By default, all ONNX commands use `--execution-provider cpu`, so existing commands keep the same CPU behavior. If you have an NVIDIA GPU and a compatible `onnxruntime-gpu` installation, you can opt in to CUDA with `--execution-provider cuda`.
To prepare a CUDA ONNX Runtime environment, replace the CPU ONNX Runtime wheel with the GPU wheel:
```bash
pip uninstall -y onnxruntime
pip install "onnxruntime-gpu>=1.20.0"
```
If `--model-dir` is omitted, the script automatically checks `./models`. When the model files are missing, it downloads them on first run from:
- [OpenMOSS-Team/MOSS-TTS-Nano-100M-ONNX](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano-100M-ONNX)
- [OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano-ONNX](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano-ONNX)
Downloaded files are stored under:
- `models/MOSS-TTS-Nano-100M-ONNX`
- `models/MOSS-Audio-Tokenizer-Nano-ONNX`
Example:
```bash
python infer_onnx.py \
--prompt-audio-path assets/audio/zh_1.wav \
--text "Welcome to the ONNX Runtime CPU demo."
```
Optional CUDA execution:
```bash
python infer_onnx.py \
--execution-provider cuda \
--prompt-audio-path assets/audio/zh_1.wav \
--text "Welcome to the ONNX Runtime CUDA demo."
```
CUDA execution requires `onnxruntime-gpu`.
If you already have the ONNX assets in another directory, pass it explicitly:
```bash
python infer_onnx.py \
--model-dir /path/to/models \
--prompt-audio-path assets/audio/zh_1.wav \
--text "Welcome to the ONNX Runtime CPU demo."
```
### ONNX Local Web Demo with `app_onnx.py`
You can also launch the ONNX-backed local web demo:
```bash
python app_onnx.py
```
To run the ONNX web demo with CUDA, start it with:
```bash
python app_onnx.py \
--execution-provider cuda
```
Then open `http://127.0.0.1:18083` in your browser.
The first startup may spend extra time downloading assets if `models/` does not contain the ONNX weights yet.
### Export TTS-only ONNX Weights
If you retrain `MOSS-TTS-Nano`, you need to re-export the TTS-side ONNX weights. The exporter under [`onnx/`](./onnx) takes a local Hugging Face-format `MOSS-TTS-Nano` checkpoint and outputs a TTS-only ONNX model directory.
Example:
```bash
python onnx/export_hf_to_tts_onnx.py \
--checkpoint-path /path/to/MOSS-TTS-Nano \
--output-dir /path/to/MOSS-TTS-Nano-100M-ONNX
```
The output directory contains:
- `moss_tts_prefill.onnx`
- `moss_tts_decode_step.onnx`
- `moss_tts_local_decoder.onnx`
- `moss_tts_local_cached_step.onnx`
- `moss_tts_local_fixed_sampled_frame.onnx`
- `moss_tts_global_shared.data`
- `moss_tts_local_shared.data`
- `tts_browser_onnx_meta.json`
- `tokenizer.model`
This is intended for the ONNX deployment path only. Existing prompt audio codes produced by `MOSS-Audio-Tokenizer-Nano` do not need to be regenerated when the audio tokenizer stays fixed.
### CLI Command: `moss-tts-nano generate`
After `pip install -e .`, you can call the packaged CLI directly:
```bash
moss-tts-nano generate \
--prompt-speech assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
```
For the ONNX CPU backend, add `--backend onnx`:
```bash
moss-tts-nano generate \
--backend onnx \
--prompt-speech assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
```
To opt in to CUDA:
```bash
moss-tts-nano generate \
--backend onnx \
--execution-provider cuda \
--prompt-speech assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
```
Useful notes:
- `moss-tts-nano generate` writes to `generated_audio/moss_tts_nano_output.wav` by default.
- `--prompt-speech` is the friendly alias for the reference audio path used by voice cloning.
- `--text-file` is supported for long-form synthesis.
- ONNX CUDA execution requires `onnxruntime-gpu`; without `--execution-provider cuda`, ONNX inference remains CPU-only.
### CLI Command: `moss-tts-nano serve`
You can also launch the web demo through the packaged CLI:
```bash
moss-tts-nano serve
```
For the ONNX web demo:
```bash
moss-tts-nano serve \
--backend onnx
```
For the ONNX web demo with CUDA:
```bash
moss-tts-nano serve \
--backend onnx \
--execution-provider cuda
```
This command forwards to the corresponding web app, keeps the model loaded in memory, and serves the local browser demo plus HTTP generation endpoints.
For server deployment with paged KV cache, streaming, and an OpenAI-compatible `/v1/audio/speech` endpoint, please read the [vLLM-Omni MOSS-TTS-Nano README](https://github.com/vllm-project/vllm-omni/blob/main/examples/online_serving/moss_tts_nano/README.md).
### Finetuning
Finetuning tutorials are already provided.
See [./finetuning/README.md](./finetuning/README.md) for details.
## MOSS-Audio-Tokenizer-Nano
### Introduction
**MOSS-Audio-Tokenizer** is the unified discrete audio interface for the entire MOSS-TTS family. It is built on the **Cat** (**C**ausal **A**udio **T**okenizer with **T**ransformer) architecture, a CNN-free audio tokenizer composed entirely of causal Transformer blocks. It serves as the shared audio backbone for MOSS-TTS, MOSS-TTS-Nano, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-SoundEffect, and MOSS-TTS-Realtime, providing a consistent audio representation across the full product family.
To further improve perceptual quality while reducing inference cost, we trained **MOSS-Audio-Tokenizer-Nano**, a lightweight tokenizer with approximately **20 million parameters** designed for high-fidelity audio compression. It supports **48 kHz** input and output as well as **stereo audio**, which helps reduce compression loss and improve listening quality. It can compress **48 kHz stereo audio** into a **12.5 Hz** token stream and uses **RVQ with 16 codebooks**, enabling high-fidelity reconstruction across variable bitrates from **0.125 kbps to 2 kbps**.
To learn more about setup, advanced usage, and evaluation metrics, please visit the [MOSS-Audio-Tokenizer Repository](https://github.com/OpenMOSS/MOSS-Audio-Tokenizer).
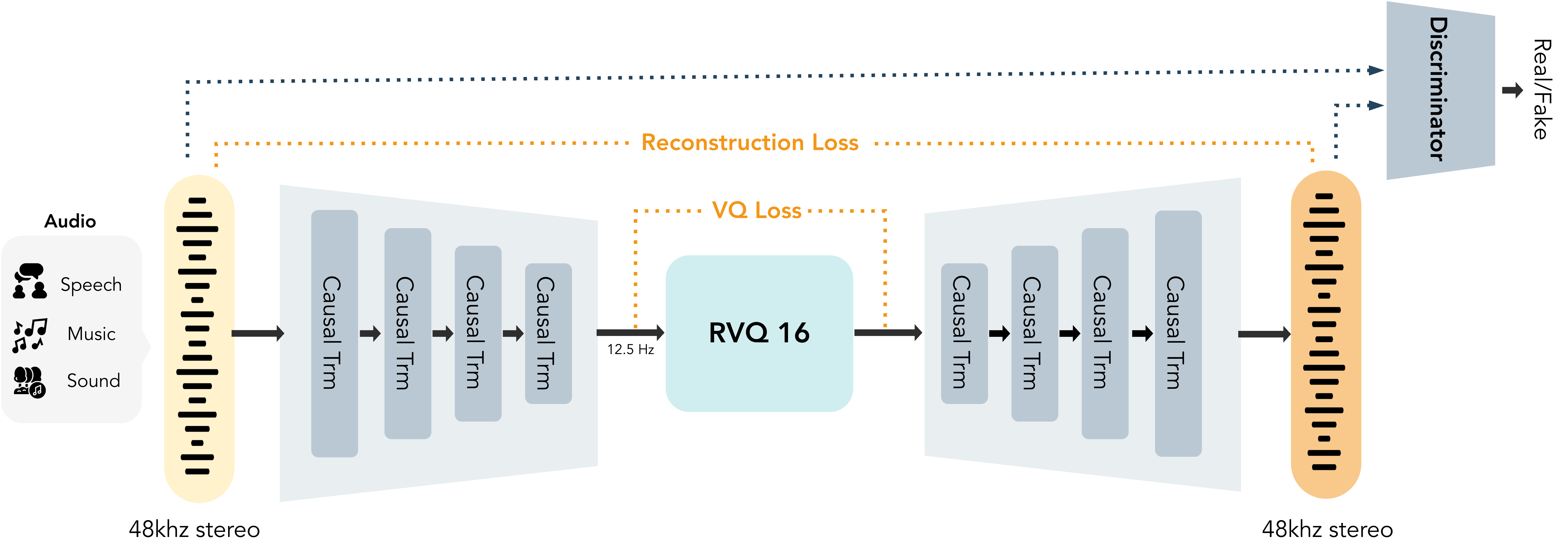 Architecture of MOSS-Audio-Tokenizer-Nano
Architecture of MOSS-Audio-Tokenizer-Nano
### Model Weights
| Model | Hugging Face | ModelScope |
|:-----:|:------------:|:----------:|
| **MOSS-Audio-Tokenizer-Nano** | [](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano) | [](https://modelscope.cn/models/openmoss/MOSS-Audio-Tokenizer-Nano) |
### Evaluation Metrics
The table below compares the reconstruction quality of MOSS-Audio-Tokenizer-Nano with open-source audio tokenizers with **no more than 120M parameters** on speech, audio, and music data. As shown in the table and figure, MOSS-Audio-Tokenizer-Nano achieves the best overall reconstruction quality while remaining one of the smallest models in the comparison.
- Speech metrics are evaluated on LibriSpeech test-clean (English) and AISHELL-2 (Chinese), reported as EN/ZH.
- Audio metrics are evaluated on the AudioSet evaluation subset, while music metrics are evaluated on MUSDB, reported as audio/music.
- STFT-Dist. denotes the STFT distance.
- Higher is better for speech metrics, while lower is better for audio/music metrics (Mel-Loss, STFT-Dist.).
- Ch. denotes the number of input/output channels supported by the audio tokenizer: `ch=1` means mono audio, and `ch=2` means stereo audio.
- Nvq denotes the number of quantizers.
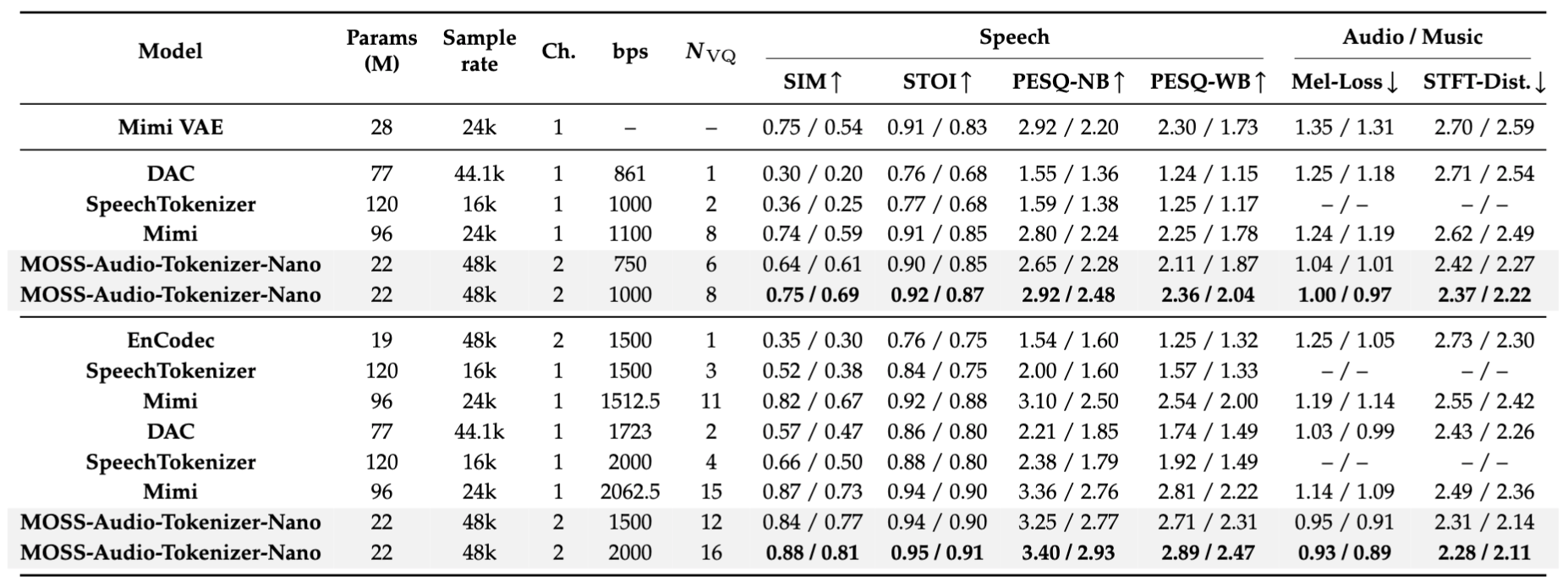
Reconstruction quality comparison of open-source audio tokenizers on speech and audio/music data.
### LibriSpeech Speech Metrics (MOSS-Audio-Tokenizer-Nano vs. Open-source Tokenizers)
The plots below compare MOSS-Audio-Tokenizer-Nano with other open-source audio tokenizers and codecs with **no more than 120M parameters** on the LibriSpeech dataset. The models are evaluated with SIM, STOI, PESQ-NB, and PESQ-WB, where higher values indicate better reconstruction quality.
For the same model, we control the bitrate by adjusting the number of RVQ codebooks used during inference.
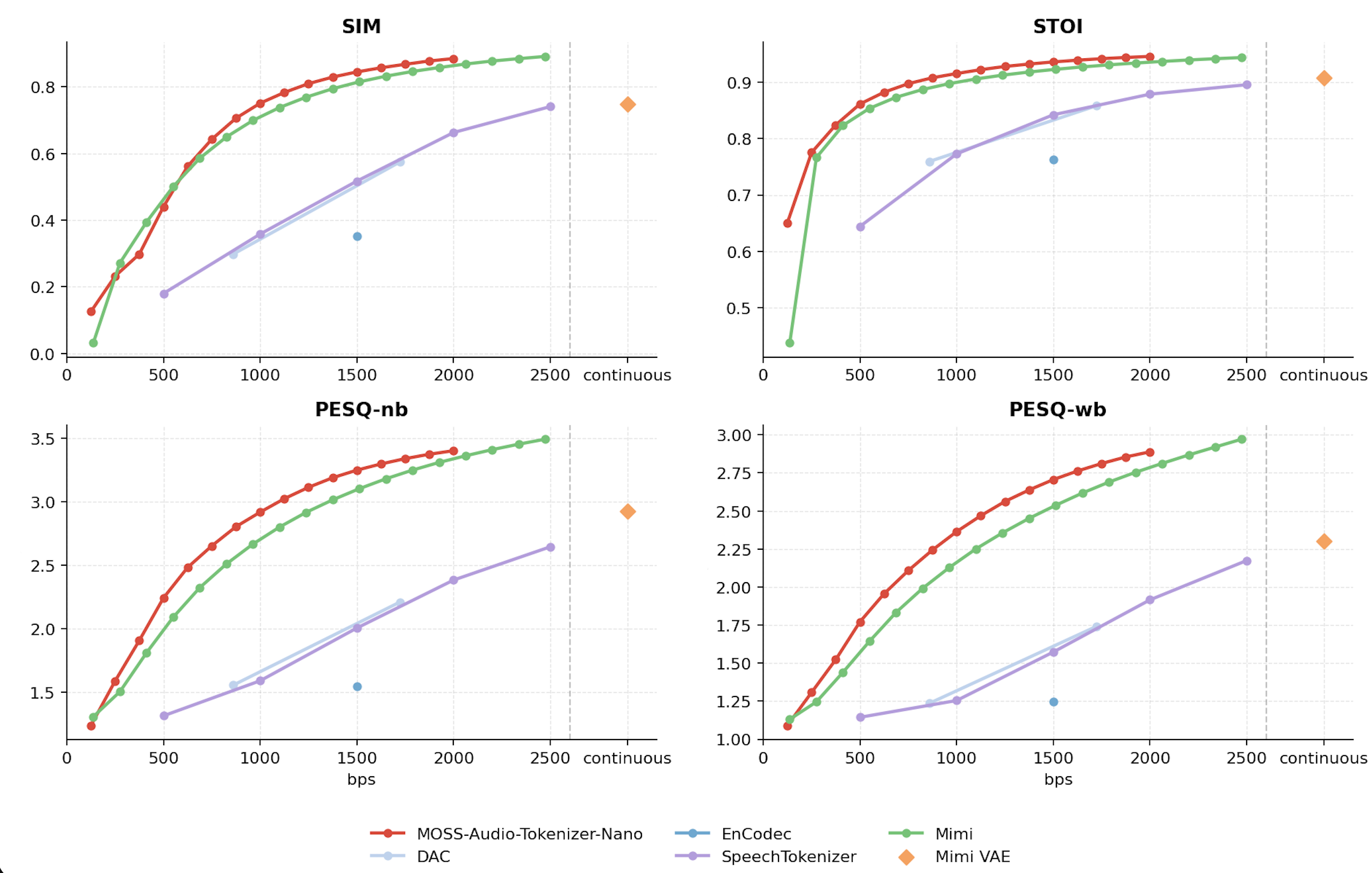
LibriSpeech reconstruction quality comparison across different bitrates.
## MOSS-TTS Family
### Introduction

MOSS‑TTS Family is an open‑source **speech and sound generation model family** from [MOSI.AI](https://mosi.cn/#hero) and the [OpenMOSS team](https://www.open-moss.com/). It is designed for **high‑fidelity**, **high‑expressiveness**, and **complex real‑world scenarios**, covering stable long‑form speech, multi‑speaker dialogue, voice/character design, environmental sound effects, and real‑time streaming TTS.
The family currently includes:
- **MOSS-TTS**: the flagship model for **high-fidelity zero-shot voice cloning**, **long-speech generation**, **fine-grained control over Pinyin, phonemes, and duration**, and **multilingual/code-switched synthesis**.
- **MOSS-TTS-Local-Transformer**: a smaller model in the family based on `MossTTSLocal`, designed to keep the MOSS-TTS style of speech generation in a lighter model size.
- **MOSS-TTSD-v1.0**: a spoken dialogue generation model for **expressive**, **multi-speaker**, and **ultra-long** dialogue audio.
- **MOSS-VoiceGenerator**: a voice design model that can generate diverse voices and speaking styles directly from **text prompts**, without reference speech.
- **MOSS-SoundEffect**: a controllable sound generation model for natural ambience, city scenes, animals, human actions, and short music-like audio fragments.
- **MOSS-TTS-Realtime**: a realtime speech model for low-latency voice agents, designed to keep replies natural, coherent, and voice-consistent across turns.
### Released Models
| Model | Architecture | Size | Hugging Face | ModelScope |
|---|---|---:|---|---|
| **MOSS-TTS** | `MossTTSDelay` | 8B | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTS) | [](https://modelscope.cn/models/openmoss/MOSS-TTS) |
| **MOSS-TTS-Local-Transformer** | `MossTTSLocal` | 1.7B | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Local-Transformer) | [](https://modelscope.cn/models/openmoss/MOSS-TTS-Local-Transformer) |
| **MOSS-TTSD-v1.0** | `MossTTSDelay` | 8B | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTSD-v1.0) | [](https://modelscope.cn/models/openmoss/MOSS-TTSD-v1.0) |
| **MOSS-VoiceGenerator** | `MossTTSDelay` | 1.7B | [](https://huggingface.co/OpenMOSS-Team/MOSS-VoiceGenerator) | [](https://modelscope.cn/models/openmoss/MOSS-VoiceGenerator) |
| **MOSS-SoundEffect** | `MossTTSDelay` | 8B | [](https://huggingface.co/OpenMOSS-Team/MOSS-SoundEffect) | [](https://modelscope.cn/models/openmoss/MOSS-SoundEffect) |
| **MOSS-TTS-Realtime** | `MossTTSRealtime` | 1.7B | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Realtime) | [](https://modelscope.cn/models/openmoss/MOSS-TTS-Realtime) |
## License
This repository will follow the license specified in the root `LICENSE` file. If you are reading this before that file is published, please treat the repository as **not yet licensed for redistribution**.
## Citation
If you use the MOSS-TTS work in your research or product, please cite:
```bibtex
@misc{openmoss2026mossttsnano,
title={MOSS-TTS-Nano},
author={OpenMOSS Team},
year={2026},
howpublished={GitHub repository},
url={https://github.com/OpenMOSS/MOSS-TTS-Nano}
}
```
```bibtex
@misc{gong2026mossttstechnicalreport,
title={MOSS-TTS Technical Report},
author={Yitian Gong and Botian Jiang and Yiwei Zhao and Yucheng Yuan and Kuangwei Chen and Yaozhou Jiang and Cheng Chang and Dong Hong and Mingshu Chen and Ruixiao Li and Yiyang Zhang and Yang Gao and Hanfu Chen and Ke Chen and Songlin Wang and Xiaogui Yang and Yuqian Zhang and Kexin Huang and ZhengYuan Lin and Kang Yu and Ziqi Chen and Jin Wang and Zhaoye Fei and Qinyuan Cheng and Shimin Li and Xipeng Qiu},
year={2026},
eprint={2603.18090},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.18090}
}
```
```bibtex
@misc{gong2026mossaudiotokenizerscalingaudiotokenizers,
title={MOSS-Audio-Tokenizer: Scaling Audio Tokenizers for Future Audio Foundation Models},
author={Yitian Gong and Kuangwei Chen and Zhaoye Fei and Xiaogui Yang and Ke Chen and Yang Wang and Kexin Huang and Mingshu Chen and Ruixiao Li and Qingyuan Cheng and Shimin Li and Xipeng Qiu},
year={2026},
eprint={2602.10934},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2602.10934},
}
```
## Star History
[](https://star-history.com/#OpenMOSS/MOSS-TTS-Nano&Date)
