", "...": "..."}
```
The HTTP response is a JSON object and may contain multiple fields. The `.text` field stores the WAV base64 string for the generated audio. In most cases, you only need to extract that field and base64-decode it; for example, after saving the response as `response.json`, you can run `jq -r '.text' response.json | base64 -d -i > output.wav`.
## Evaluation
This section summarizes the **family‑level evaluation highlights** for MOSS‑TTS, MOSS-TTSD and MOSS‑VoiceGenerator. For full details, see each model’s model card.
### MOSS‑TTS
MOSS‑TTS achieved state‑of‑the‑art results on the open‑source zero‑shot TTS benchmark `Seed‑TTS‑eval`, surpassing all open‑source models and rivaling leading closed‑source systems.
| Model | Params | Open‑source | EN WER (%) ↓ | EN SIM (%) ↑ | ZH CER (%) ↓ | ZH SIM (%) ↑ |
|---|---:|:---:|---:|---:|---:|---:|
| DiTAR | 0.6B | ❌ | 1.69 | 73.5 | 1.02 | 75.3 |
| FishAudio‑S1 | 4B | ❌ | 1.72 | 62.57 | 1.22 | 72.1 |
| CosyVoice3 | 1.5B | ❌ | 2.22 | 72 | 1.12 | 78.1 |
| Seed‑TTS | | ❌ | 2.25 | 76.2 | 1.12 | 79.6 |
| MiniMax‑Speech | | ❌ | 1.65 | 69.2 | 0.83 | 78.3 |
| | | | | | | |
| CosyVoice | 0.3B | ✅ | 4.29 | 60.9 | 3.63 | 72.3 |
| CosyVoice2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 |
| CosyVoice3 | 0.5B | ✅ | 2.02 | 71.8 | 1.16 | 78 |
| F5‑TTS | 0.3B | ✅ | 2 | 67 | 1.53 | 76 |
| SparkTTS | 0.5B | ✅ | 3.14 | 57.3 | 1.54 | 66 |
| FireRedTTS | 0.5B | ✅ | 3.82 | 46 | 1.51 | 63.5 |
| FireRedTTS‑2 | 1.5B | ✅ | 1.95 | 66.5 | 1.14 | 73.6 |
| Qwen2.5‑Omni | 7B | ✅ | 2.72 | 63.2 | 1.7 | 75.2 |
| FishAudio‑S1‑mini | 0.5B | ✅ | 1.94 | 55 | 1.18 | 68.5 |
| IndexTTS2 | 1.5B | ✅ | 2.23 | 70.6 | 1.03 | 76.5 |
| VibeVoice | 1.5B | ✅ | 3.04 | 68.9 | 1.16 | 74.4 |
| HiggsAudio‑v2 | 3B | ✅ | 2.44 | 67.7 | 1.5 | 74 |
| GLM-TTS | 1.5B | ✅ | 2.23 | 67.2 | 1.03 | 76.1 |
| GLM-TTS-RL | 1.5B | ✅ | 1.91 | 68.1 | **0.89** | 76.4 |
| VoxCPM | 0.5B | ✅ | 1.85 | 72.9 | 0.93 | 77.2 |
| Qwen3‑TTS | 0.6B | ✅ | 1.68 | 70.39 | 1.23 | 76.4 |
| Qwen3‑TTS | 1.7B | ✅ | **1.5** | 71.45 | 1.33 | 76.72 |
| | | | | | | |
| **MossTTSDelay** | **8B** | ✅ | 1.84 | 70.86 | 1.37 | 76.98 |
| **MossTTSLocal** | **1.7B** | ✅ | 1.93 | **73.28** | 1.44 | **79.62** |
### MOSS‑TTSD
#### Objective Evaluation
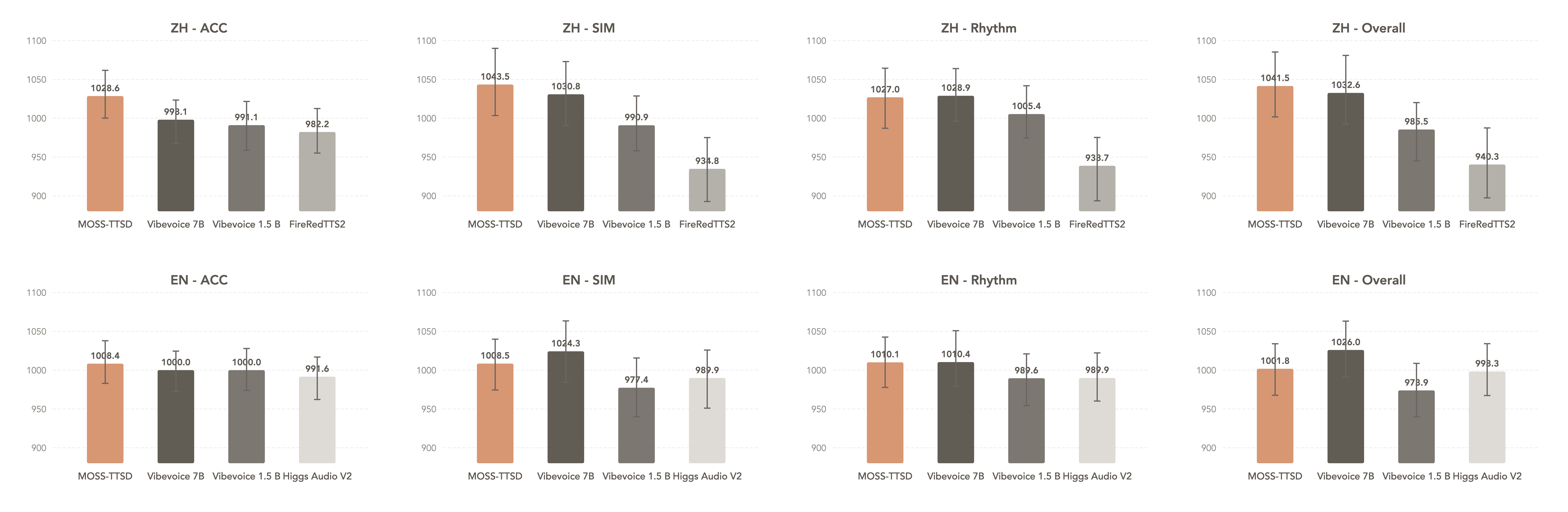
We evaluate MOSS‑TTSD-v1.0 using three objective metrics: Speaker Attribution Accuracy (ACC), Speaker Similarity (SIM), and Word Error Rate (WER). Benchmarked against multiple open-source and closed-source models, the results show that MOSS‑TTSD-v1.0 consistently achieves either the best or second-best performance.
| Model | ZH - SIM | ZH - ACC | ZH - WER | EN - SIM | EN - ACC | EN - WER |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **Comparison with Open-Source Models** | | | | | | |
| **MOSS-TTSD-v1.0** | **0.7949** | **0.9587** | **0.0485** | **0.7326** | **0.9626** | 0.0988 |
| MOSS-TTSD-v0.7 | 0.7423 | 0.9391 | 0.0517 | 0.6743 | 0.9266 | 0.1612 |
| Vibevoice 7B | 0.7590 | 0.9222 | 0.0570 | 0.7140 | 0.9554 | **0.0946** |
| Vibevoice 1.5 B | 0.7415 | 0.8798 | 0.0818 | 0.6961 | 0.9353 | 0.1133 |
| FireRedTTS2 | 0.7383 | 0.9022 | 0.0768 | - | - | - |
| Higgs Audio V2 | - | - | - | 0.6860 | 0.9025 | 0.2131 |
| **Comparison with Proprietary Models** | | | | | | |
| **MOSS-TTSD-v1.0 (elevenlabs_voice)** | **0.8165** | **0.9736** | 0.0391 | **0.7304** | **0.9565** | 0.1005 |
| Eleven V3 | 0.6970 | 0.9653 | **0.0363** | 0.6730 | 0.9498 | **0.0824** |
| | | | | | | |
| **MOSS-TTSD-v1.0 (gemini_voice)** | - | - | - | **0.7893** | **0.9655** | 0.0984 |
| gemini-2.5-pro-preview-tts | - | - | - | 0.6786 | 0.9537 | **0.0859** |
| gemini-2.5-flash-preview-tts | - | - | - | 0.7194 | 0.9511 | 0.0871 |
| | | | | | | |
| **MOSS-TTSD-v1.0 (doubao_voice)** | **0.8226** | **0.9630** | 0.0571 | - | - | - |
| Doubao_Podcast | 0.8034 | 0.9606 | **0.0472** | - | - | - |
#### Subjective Evaluation
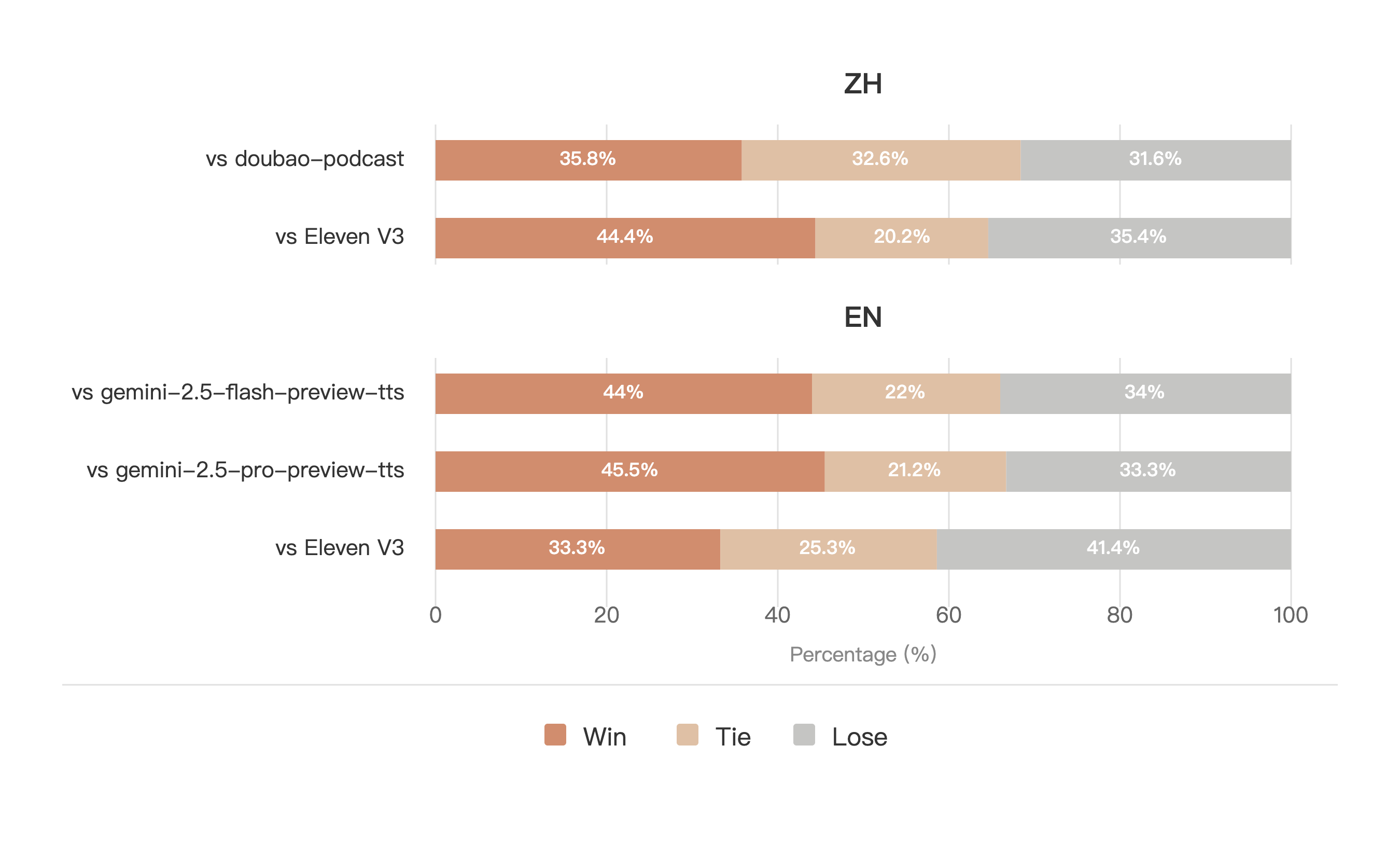
For open-source models, annotators are asked to score each sample pair in terms of speaker attribution accuracy, voice similarity, prosody, and overall quality. Following the methodology of the LMSYS Chatbot Arena, we compute Elo ratings and confidence intervals for each dimension.
For closed-source models, annotators are only asked to choose the overall preferred one in each pair, and we compute the win rate accordingly.
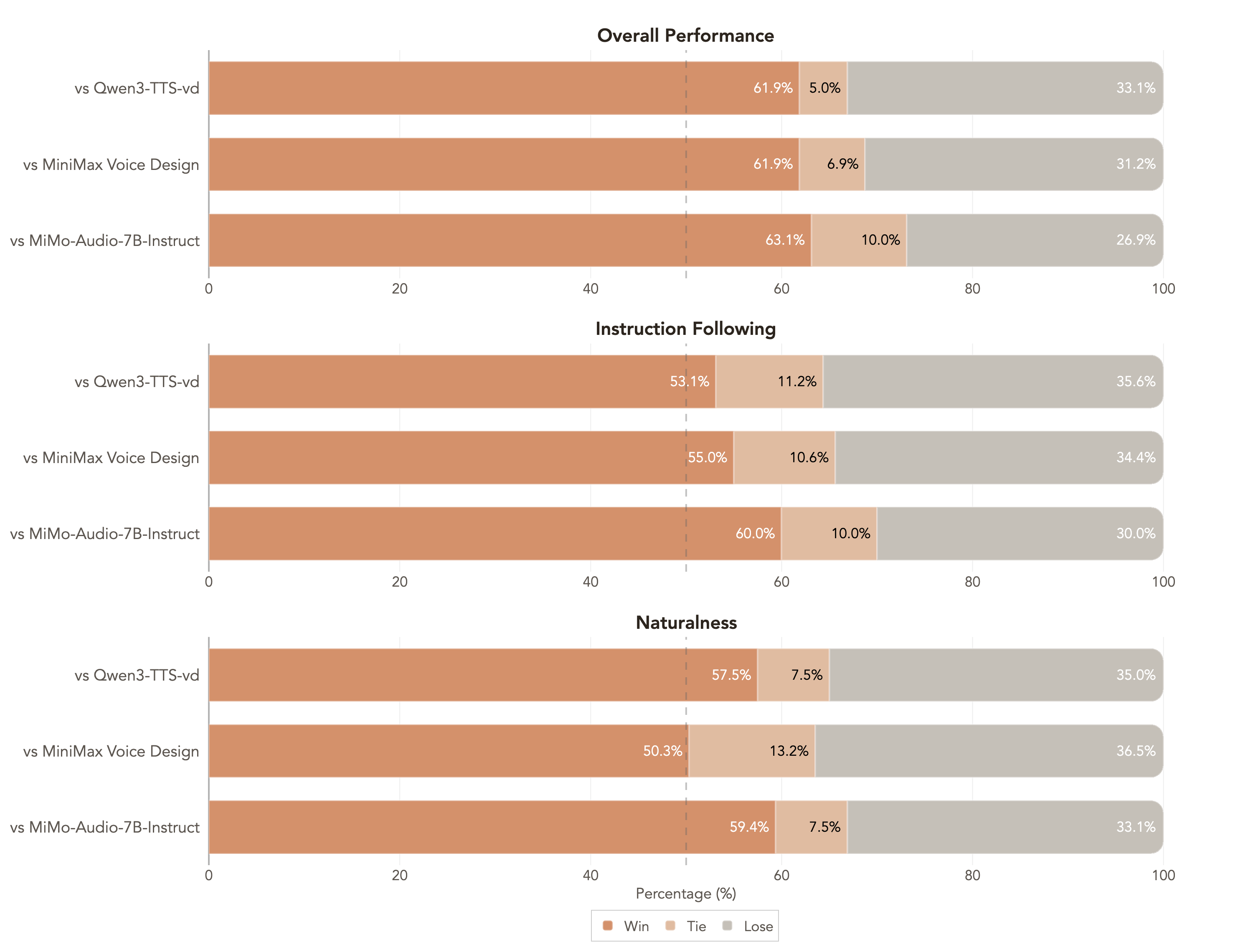
### MOSS‑VoiceGenerator
MOSS‑VoiceGenerator demonstrates strong subjective preference across **overall preference**, **instruction following**, and **naturalness**.
### MOSS‑TTS-Realtime
We evaluated the TTFB (Time To First Byte) and RTF (Real-Time Factor) of MOSS-TTS-Realtime.
Note: SDPA + torch.compile were enabled during testing. The following results are tested on a single L20 GPU.
| Model | TTFB (ms) | RTF |
|-------------|-----------|-----|
| **MOSS-TTS-Realtime** | 180(After warm up)| 0.51 |
We deployed Qwen3.5-9B using vLLM to measure $T_{\text{LLM-first-sentence}}$. The time required to generate 12 tokens (the TTS prefill length) was 197 ms.
$T_{\text{LLM-first-sentence}} + T_{\text{MOSS-TTS-Realtime-TTFB}} = 197ms + 180ms = 377ms$
## MOSS-TTS-Nano
### Introduction
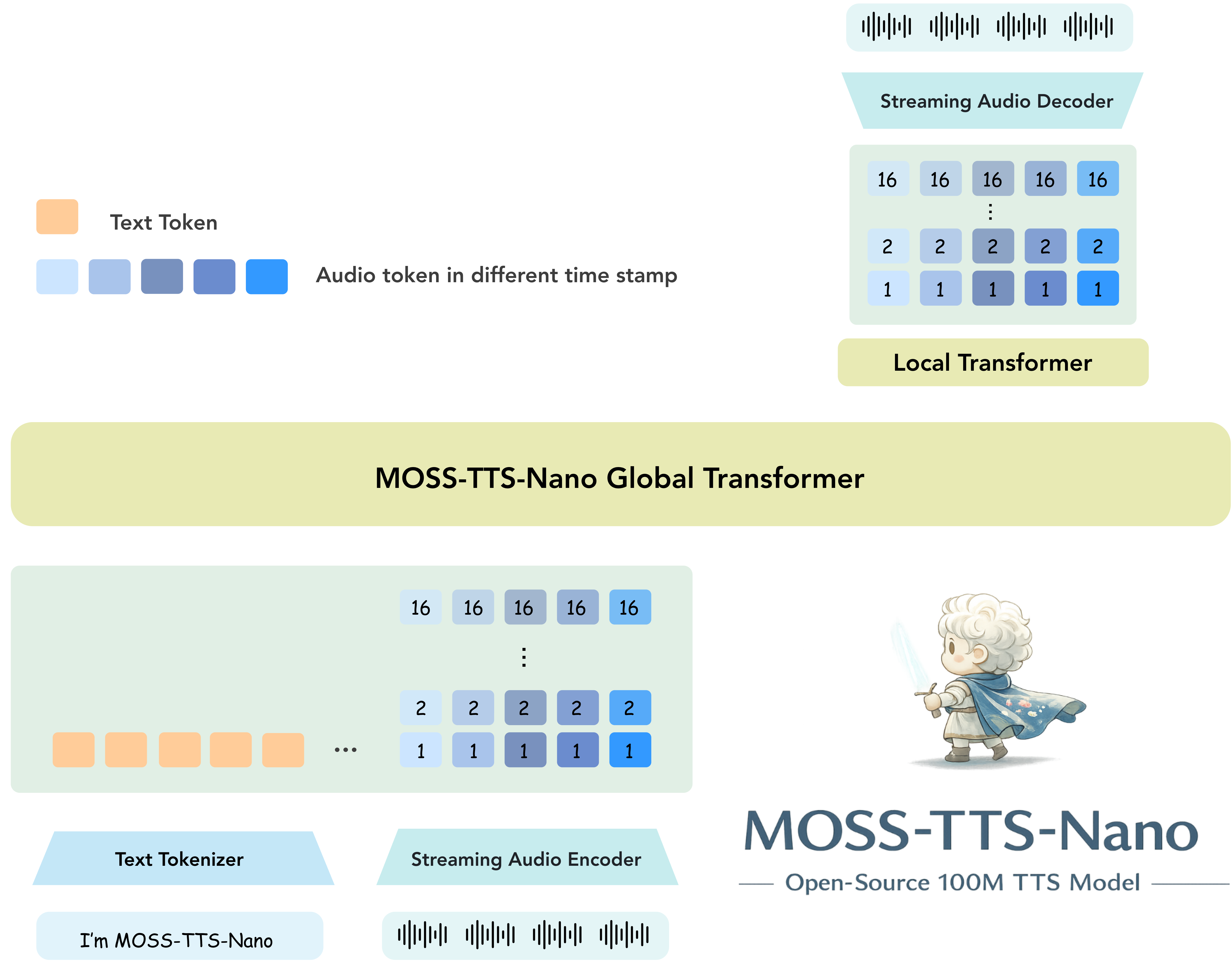
**MOSS-TTS-Nano** is our lightweight TTS model designed for CPU-first realtime deployment. It focuses on the part of speech generation that matters most in practical products: a small footprint, low-latency streaming generation, and voice-cloning quality that is strong enough for local demos, web services, and lightweight production integration. Built on a pure autoregressive **Audio Tokenizer + LLM** pipeline, it keeps the deployment stack simple while making realtime speech generation accessible even without a GPU.
Its main features include:
- **0.1B parameters**: a compact model size that keeps memory usage and deployment cost low, making local deployment and lightweight serving much easier.
- **Realtime generation on just 4 CPU cores**: streaming speech generation can run efficiently on CPU-only environments, which is practical for local applications and cost-sensitive deployment scenarios.
- **Multilingual voice cloning**: supports multilingual voice cloning workflows, making it suitable for cross-language synthesis with a single reference speaker.
- **48 kHz stereo input/output**: natively supports high-quality stereo audio, improving both reference-audio fidelity and final listening quality.
To learn more about setup, advanced usage, and evaluation metrics, please visit the [MOSS-TTS-Nano repository](https://github.com/OpenMOSS/MOSS-TTS-Nano).
Architecture of MOSS-TTS-Nano
### Model Weights
| Model | Hugging Face | ModelScope |
|:-----:|:------------:|:----------:|
| **MOSS-TTS-Nano** | [](https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano) | [](https://modelscope.cn/models/openmoss/MOSS-TTS-Nano) |
## MOSS-Audio-Tokenizer
### Introduction
**MOSS-Audio-Tokenizer** serves as the unified discrete audio interface for the entire MOSS-TTS Family. It is based on the **Cat** (**C**ausal **A**udio **T**okenizer with **T**ransformer) architecture—a 1.6-billion-parameter, "CNN-free" homogeneous audio tokenizer built entirely from Causal Transformer blocks.
- **Unified Discrete Bridge**: It acts as the shared backbone for MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-SoundEffect, and MOSS-TTS-Realtime, providing a consistent audio representation across the family.
- **Extreme Compression & High Fidelity**: It compresses 24kHz raw audio into a remarkably low frame rate of 12.5Hz. Utilizing a 32-layer Residual Vector Quantizer (RVQ), it supports high-fidelity reconstruction across variable bitrates from 0.125kbps to 4kbps.
- **Massive-Scale General Audio Training**: Trained from scratch on 3 million hours of diverse data (speech, sound effects, and music), the model achieves state-of-the-art reconstruction among open source audio tokenizers.
- **Native Streaming Design**: The pure Causal Transformer architecture is specifically designed for scalability and low-latency streaming inference, enabling real-time production workflows.
To learn more about setup, advanced usage, and evaluation metrics, please visit the [MOSS-Audio-Tokenizer Repository](https://github.com/OpenMOSS/MOSS-Audio-Tokenizer)
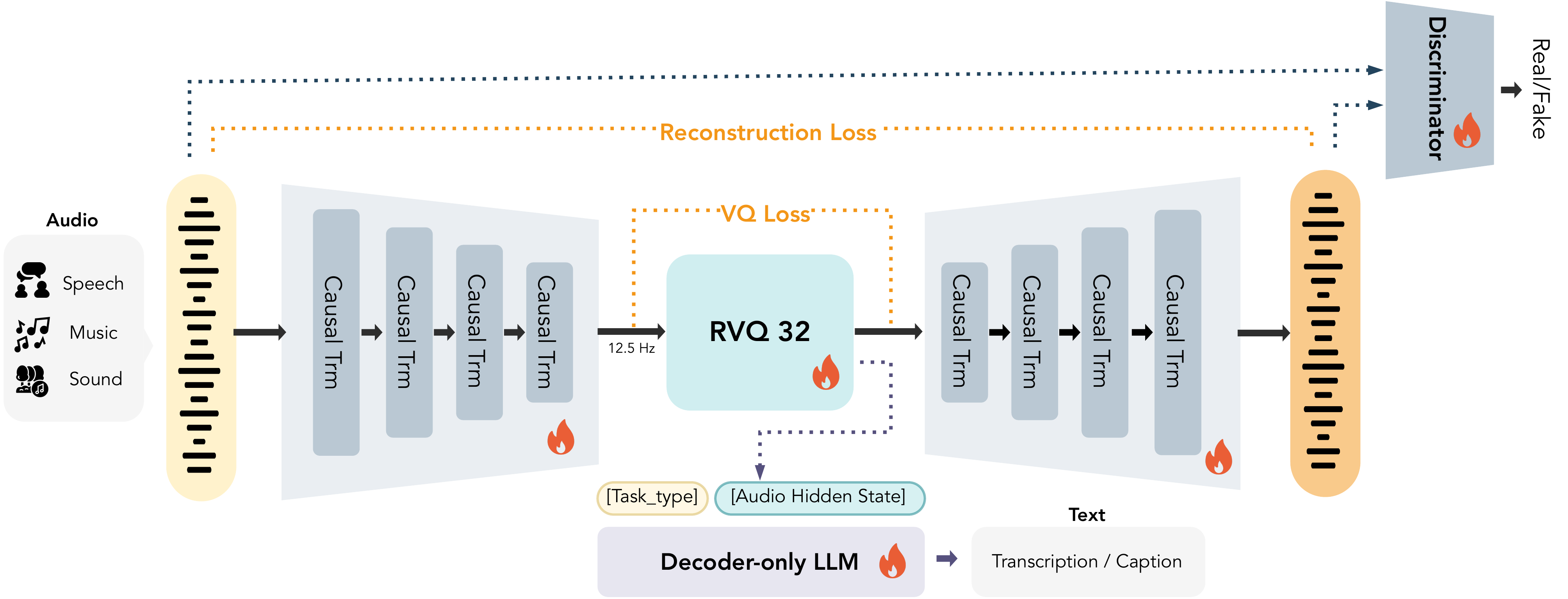 Architecture of MOSS Audio Tokenizer
Architecture of MOSS Audio Tokenizer
### Model Weights
| Model | Hugging Face | ModelScope |
|:-----:|:------------:|:----------:|
| **MOSS-Audio-Tokenizer** | [](https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer) | [](https://modelscope.cn/models/openmoss/MOSS-Audio-Tokenizer) |
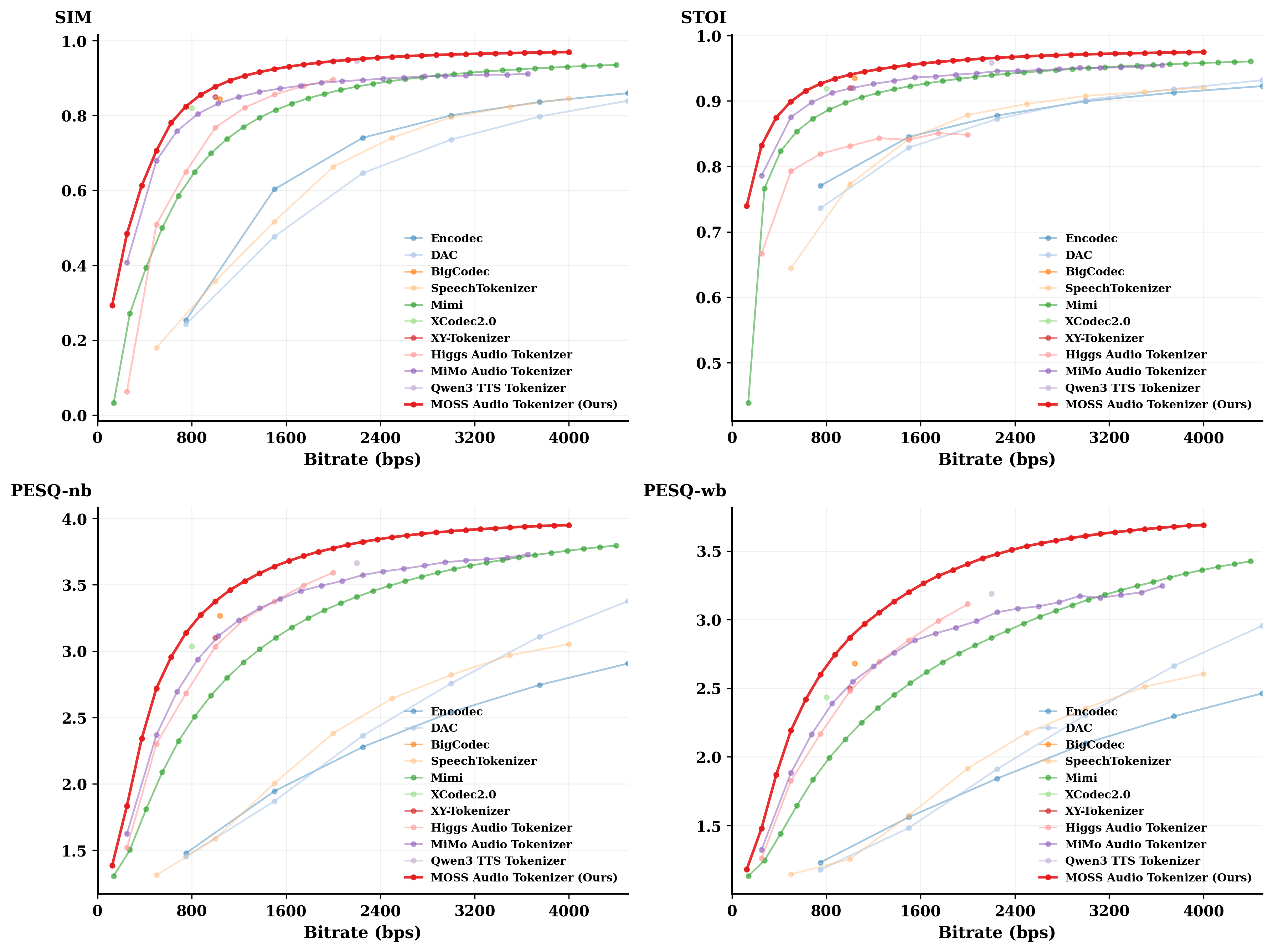
### Objective Reconstruction Evaluation
We compare **MOSS Audio Tokenizer** with open-source audio tokenizers on the LibriSpeech test-clean subset using SIM, STOI, PESQ-NB, and PESQ-WB. Bitrate is controlled by varying the number of RVQ codebooks during decoding, and MOSS Audio Tokenizer leads reconstruction quality among open-source audio tokenizers at comparable 0–4 kbps bitrates.
## 📚 More Information
### 🌟 Community Projects
The MOSS-TTS community has been growing rapidly, and we’re delighted to showcase some outstanding projects and features built by community members:
- **[ComfyUI-MOSS-TTS](https://github.com/richservo/comfyui-moss-tts)** A MOSS-TTS extension for ComfyUI.
- **[MOSS-TTS-OpenAI](https://github.com/dasilva333/moss-tts-openai)** An OpenAI-compatible TTS API for MOSS-TTS.
- **[AnyPod](https://github.com/rulerman/AnyPod)** A podcast generation tool using MOSS-TTS/MOSS-TTSD as the backend.
- **Norwegian LoRA for MOSS-TTS** — A community-trained LoRA adapter (`mlp`, r=16) fine-tuned on the [NbAiLab/NST](https://huggingface.co/datasets/NbAiLab/NST) Norwegian speech dataset. Contributed by [Martin Bergo](https://x.com/martinbergo) at [Tosee](https://tosee.no/). LoRA weights: [ToSee-Norway/MOSS-TTS-Norwegian-LoRA](https://huggingface.co/ToSee-Norway/MOSS-TTS-Norwegian-LoRA). Training scripts are available in [`community/norwegian-lora/`](community/norwegian-lora/).
## LICENSE
Models in MOSS-TTS Family are licensed under the Apache License 2.0.
## Citation
```bibtex
@misc{gong2026mossttstechnicalreport,
title={MOSS-TTS Technical Report},
author={Yitian Gong and Botian Jiang and Yiwei Zhao and Yucheng Yuan and Kuangwei Chen and Yaozhou Jiang and Cheng Chang and Dong Hong and Mingshu Chen and Ruixiao Li and Yiyang Zhang and Yang Gao and Hanfu Chen and Ke Chen and Songlin Wang and Xiaogui Yang and Yuqian Zhang and Kexin Huang and ZhengYuan Lin and Kang Yu and Ziqi Chen and Jin Wang and Zhaoye Fei and Qinyuan Cheng and Shimin Li and Xipeng Qiu},
year={2026},
eprint={2603.18090},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.18090},
}
@misc{zhang2026mossttsdtextspokendialogue,
title={MOSS-TTSD: Text to Spoken Dialogue Generation},
author={Yuqian Zhang and Donghua Yu and Zhengyuan Lin and Botian Jiang and Mingshu Chen and Yaozhou Jiang and Yiwei Zhao and Yiyang Zhang and Yucheng Yuan and Hanfu Chen and Kexin Huang and Jun Zhan and Cheng Chang and Zhaoye Fei and Shimin Li and Xiaogui Yang and Qinyuan Cheng and Xipeng Qiu},
year={2026},
eprint={2603.19739},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.19739},
}
@misc{huang2026mossvoicegeneratorcreaterealisticvoices,
title={MOSS-VoiceGenerator: Create Realistic Voices with Natural Language Descriptions},
author={Kexin Huang and Liwei Fan and Botian Jiang and Yaozhou Jiang and Qian Tu and Jie Zhu and Yuqian Zhang and Yiwei Zhao and Chenchen Yang and Zhaoye Fei and Shimin Li and Xiaogui Yang and Qinyuan Cheng and Xipeng Qiu},
year={2026},
eprint={2603.28086},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.28086},
}
```
## Star History
[](https://www.star-history.com/#OpenMOSS/MOSS-TTS&type=date&legend=top-left)