English | 简体中文
![]()
![]()

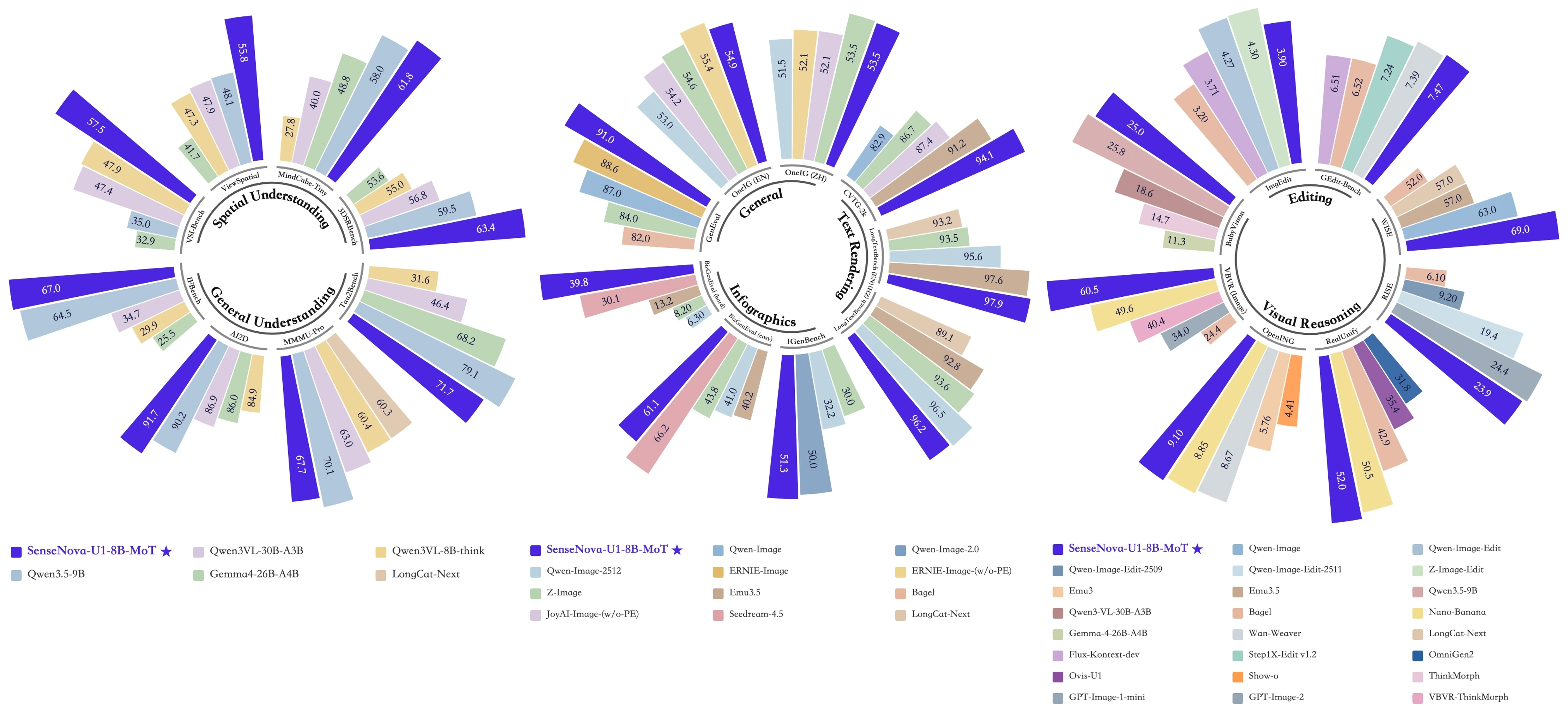
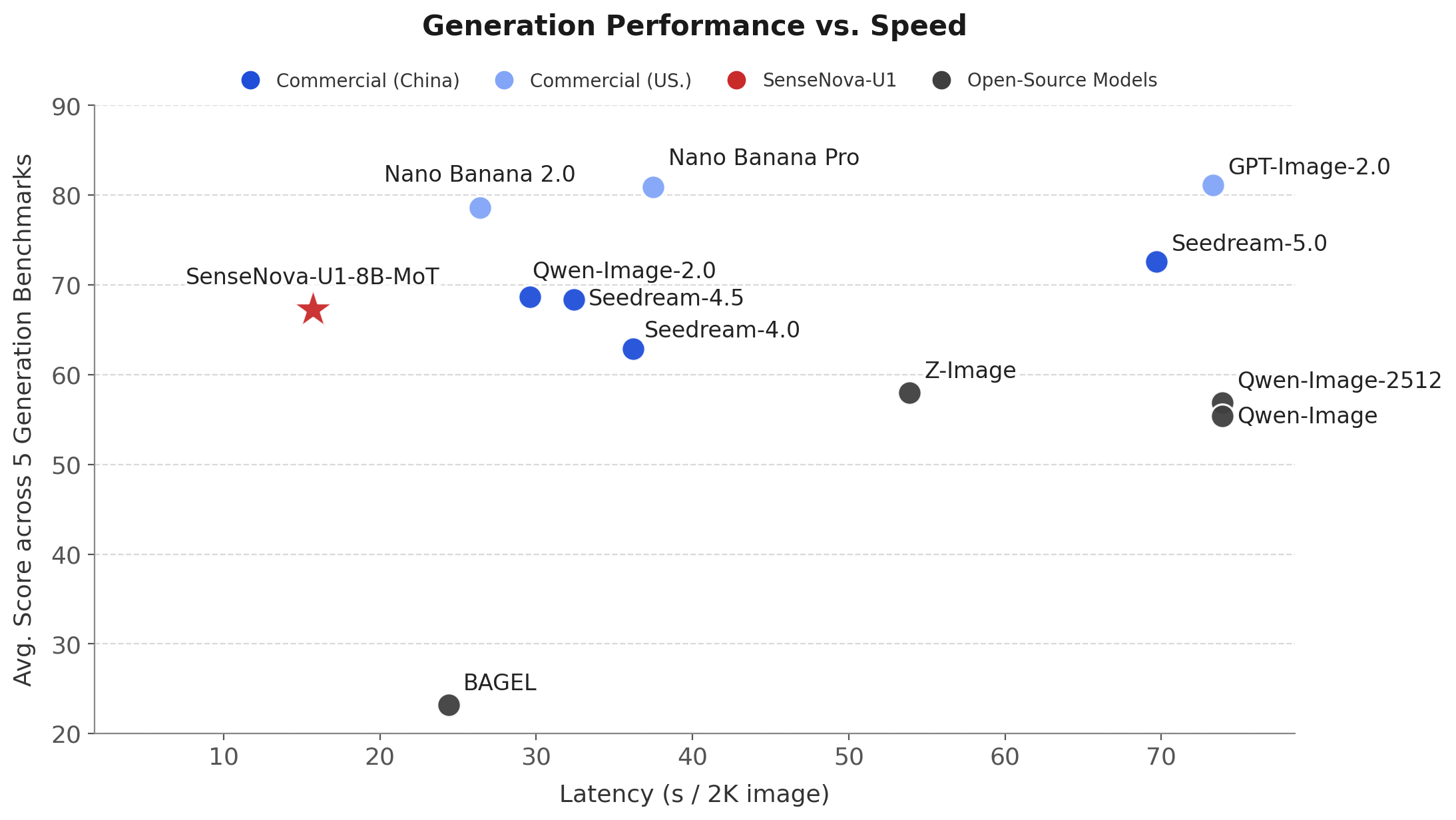
左图:在 OneIG(EN、ZH)、LongText(EN、ZH)、CVTG、BizGenEval(Easy、Hard)与 IGenBench 上的生成延迟与平均性能对比。
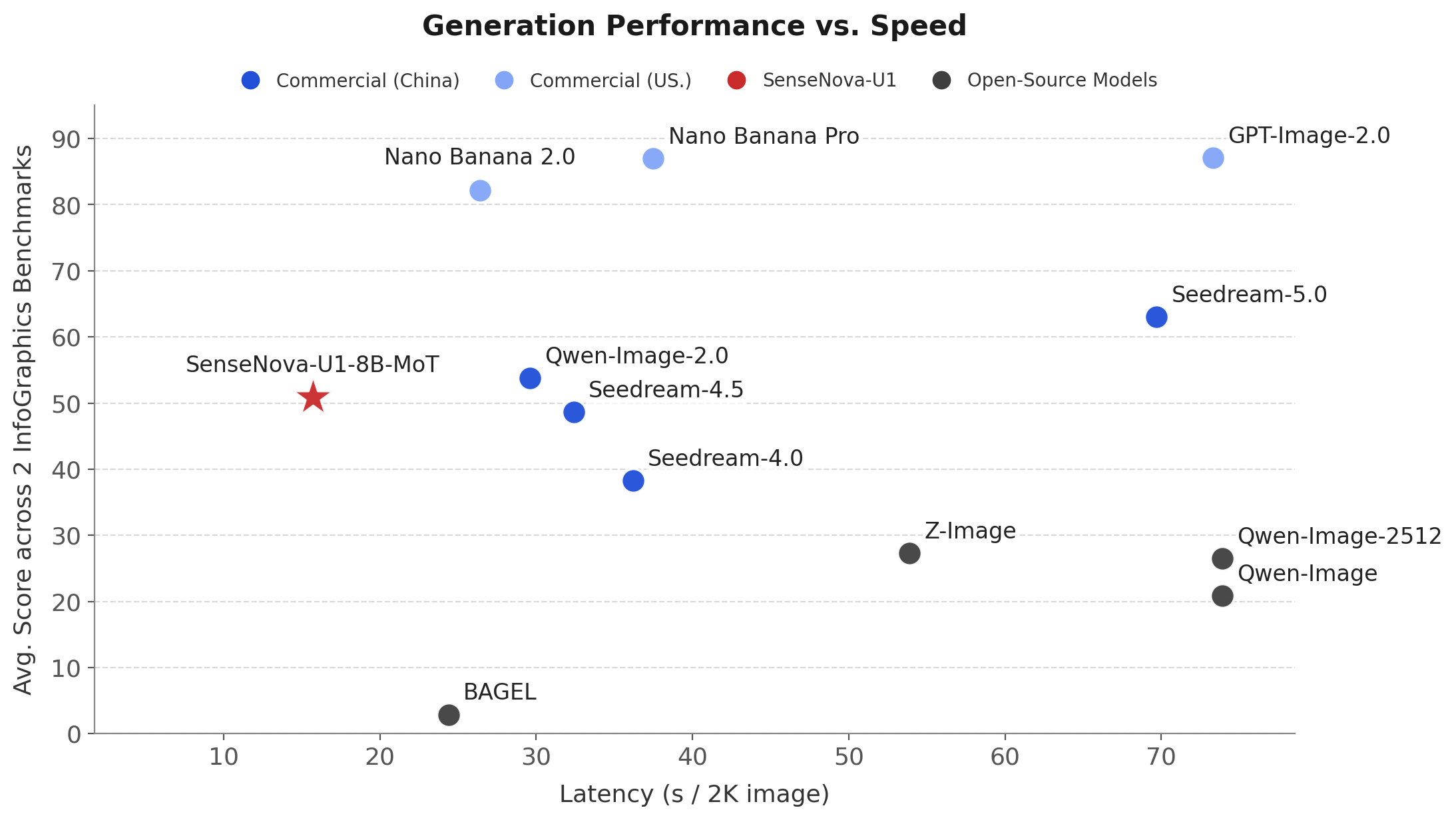
右图:在信息图基准(BizGenEval(Easy、Hard)、IGenBench)上的生成延迟与平均性能对比。
 ](./docs/assets/showcases/t2i_general/16_9_dense_face_hd_07.webp) | [
](./docs/assets/showcases/t2i_general/16_9_dense_face_hd_07.webp) | [ ](./docs/assets/showcases/t2i_general/16_9_dense_text_rendering_18.webp) | [
](./docs/assets/showcases/t2i_general/16_9_dense_text_rendering_18.webp) | [ ](./docs/assets/showcases/t2i_general/16_9_dense_text_rendering_12.webp) |
| [
](./docs/assets/showcases/t2i_general/16_9_dense_text_rendering_12.webp) |
| [ ](./docs/assets/showcases/t2i_general/1_1_face_hd_13.webp) | [
](./docs/assets/showcases/t2i_general/1_1_face_hd_13.webp) | [ ](./docs/assets/showcases/t2i_general/1_1_face_hd_17.webp) | [
](./docs/assets/showcases/t2i_general/1_1_face_hd_17.webp) | [ ](./docs/assets/showcases/t2i_general/1_1_dense_artistic_10.webp) |
| [
](./docs/assets/showcases/t2i_general/1_1_dense_artistic_10.webp) |
| [ ](./docs/assets/showcases/t2i_general/1_1_landscape_06.webp) | [
](./docs/assets/showcases/t2i_general/1_1_landscape_06.webp) | [ ](./docs/assets/showcases/t2i_general/1_1_dense_landscape_12.webp) | [
](./docs/assets/showcases/t2i_general/1_1_dense_landscape_12.webp) | [ ](./docs/assets/showcases/t2i_general/1_1_landscape_07.webp) |
| [
](./docs/assets/showcases/t2i_general/1_1_landscape_07.webp) |
| [ ](./docs/assets/showcases/t2i_general/9_16_dense_face_hd_10.webp) | [
](./docs/assets/showcases/t2i_general/9_16_dense_face_hd_10.webp) | [ ](./docs/assets/showcases/t2i_general/9_16_human_pose_11.webp) | [
](./docs/assets/showcases/t2i_general/9_16_human_pose_11.webp) | [ ](./docs/assets/showcases/t2i_general/9_16_artistic_07.webp) |
| [
](./docs/assets/showcases/t2i_general/9_16_artistic_07.webp) |
| [ ](./docs/assets/showcases/t2i_general/9_16_sensenova_u1_31.webp) | [
](./docs/assets/showcases/t2i_general/9_16_sensenova_u1_31.webp) | [ ](./docs/assets/showcases/t2i_general/9_16_dense_landscape_05.webp) | [
](./docs/assets/showcases/t2i_general/9_16_dense_landscape_05.webp) | [ ](./docs/assets/showcases/t2i_general/9_16_dense_artistic_11.webp) |
](./docs/assets/showcases/t2i_general/9_16_dense_artistic_11.webp) |
| 原始文本 | 推理过程 | 生成图像 |
|---|---|---|
| A male peacock trying to attract a female | 1. Instruction Understanding: The core subject is a single male peacock. The action involves the male peacock trying to attract a female. 2. Reasoning Process: Male peacocks perform this ritual by fanning their tail feathers into a massive, colorful circular display. 3. Establish the frame: The frame captures the male peacock in a full-body shot to show the entire display. The angle is eye-level to emphasize the height of the tail feathers. 4. Set the lighting and color: Natural lighting illuminates the colorful circular display with soft shadows. The palette features vibrant blues and greens on the tail feathers. 5. Lock the style: The style is a realistic photograph with sharp focus on the male peacock. The finish is natural without artistic filters. 6. Explicit Prompt: A vibrant male peacock with his tail feathers fully fanned out in a wide, iridescent display of blues and greens, standing in a garden. |
 |
| A small piece of dry wood and a dense iron block are in a transparent water tank | 1. Instruction Understanding: The core subjects are a small piece of dry wood and a dense iron block positioned within a transparent water tank. The wood is floating on the surface while the iron block is submerged at the bottom. 2. Reasoning Process: The wood is less dense than water so it will float, while the iron is denser and will sink to the bottom. 3. Establish the frame: The composition is a vertical medium shot centering the rectangular tank within the frame. The camera angle is eye-level to clearly display the water line and the submerged base. Focus is sharp across the entire depth of the tank to ensure both materials are distinct. 4. Build the environment: The scene is contained entirely within the clear glass walls of the water tank. The water fills the majority of the volume, providing a medium for the floating wood and sunken iron block. The background remains out of focus to keep attention on the tank's interior. 5. Set the lighting and color: Soft natural light illuminates the scene from the left, creating gentle reflections on the water surface. The color palette features the brown grain of the wood contrasting against the dark grey metallic finish of the iron. Shadows are soft and diffused through the liquid. 6. Explicit Prompt: A realistic photo of a transparent water tank showing a piece of wood floating on the surface and an iron block resting at the bottom. |
 |
| A typical dish from the country where Naples is located | 1. Instruction Understanding: The core subject is a Neapolitan pizza presented as a typical dish. The context specifies Naples, Italy, as the country of origin for this food item. 2. Reasoning Process: Naples is in Italy, and a classic dish is a Neapolitan pizza. 3. Establish the frame: The Neapolitan pizza is captured in a close-up shot that fills the central frame. The angle is slightly elevated to show the round form of the dish clearly. 4. Set the lighting and color: Soft lighting illuminates the surface of the Neapolitan pizza to reveal texture. Warm tones dominate the color palette, emphasizing the baked nature of the dish. 5. Lock the style: The image utilizes a realistic photographic style with sharp focus on the main subject. The finish appears natural and appetizing, suitable for food documentation. 6. Explicit Prompt: A delicious Neapolitan pizza with a soft, charred crust, tomato sauce, and fresh mozzarella, served on a rustic wooden table, realistic food photography. |
 |
| A solution of calcium carbonate reacting with acetic acid | 1. Instruction Understanding: The core subject is a solution of calcium carbonate and acetic acid. The prompt specifies the reacting state of the chemical mixture. 2. Reasoning Process: The reaction produces carbon dioxide gas, which would be visible as a steady stream of bubbles rising through the liquid. 3. Establish the frame: The camera frames the solution closely to capture the details of the reaction. The composition centers on the liquid where the gas is visible. 4. Set the lighting and color: The liquid appears clear, allowing the white bubbles to stand out distinctly. The lighting is bright and even to illuminate the stream of gas. 5. Lock the style: The image maintains a realistic photographic style suitable for scientific observation. The focus is sharp on the reacting solution and bubbles. 6. Explicit Prompt: A test tube filled with a clear liquid and a rapid, effervescent stream of carbon dioxide bubbles rising to the surface, laboratory experiment. |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |












| 编辑指令 | 原始图像 | 推理过程 | 编辑结果 |
|---|---|---|---|
| Draw what it will look like one hour later. |  |
1. Source Image Analysis: The source image shows a glass cup of hot tea with steeping tea leaves, and the water appears relatively clear. 2. Instruction Understanding: The instruction asks for the appearance one hour later. 3. Reasoning Process: Over time, tannins and pigments leach out, making the tea noticeably darker and more uniformly colored, and the leaves may look more swollen and darker from soaking. 4. Expected Visual Changes: The expected visible result is a deeper amber-to-brown tea color and more fully saturated liquid. 5. Elements to Preserve: The glass cup, scattered leaves around it, background, and camera angle should remain unchanged. 6. Explicit Edit Prompt: Edit the tea liquid to a much darker, more saturated amber-brown color as if fully steeped, and make the tea leaves look slightly darker and more swollen, while keeping the glass cup, surrounding leaves, background, and framing unchanged. |
 |
| Draw what it will look like immediately after someone stands up from sitting on it for a long time. |  |
1. Source Image Analysis: The source image shows a fluffy lime-green beanbag chair that looks evenly plump and undisturbed on a white background. 2. Instruction Understanding: The edit instruction asks for its appearance immediately after someone stood up from sitting there for a long time. 3. Reasoning Process: Prolonged weight compresses the fabric and internal fill, leaving a depressed seat area, wrinkles radiating outward, and a slowly recovering shape. 4. Expected Visual Changes: The visible result should be a noticeable dip and creasing where a person was seated. 5. Elements to Preserve: The background, beanbag color, lighting, and camera angle should remain unchanged while only the beanbag's shape shows the compression. 6. Explicit Edit Prompt: Edit the beanbag chair to show a clear seated depression in the center with surrounding wrinkles and slightly compressed fabric, while keeping the white background, lighting, and camera angle unchanged. |
 |
| Change the water to high-concentration saltwater |  |
1. Source Image Analysis: The source image shows an egg resting at the bottom of a glass of water. 2. Instruction Understanding: The instruction asks to change the medium to high-concentration saltwater. 3. Reasoning Process: Saltwater is denser than fresh water, which increases the buoyant force on the egg. 4. Expected Visual Changes: As density increases, the egg will overcome gravity and float higher or suspend in the middle of the liquid. 5. Elements to Preserve: The glass and the egg's appearance should remain consistent, focusing on the shift in the egg's vertical position. 6. Explicit Edit Prompt: Edit the position of the egg so it is floating in the middle of the liquid instead of resting on the bottom, while keeping the glass and the egg's appearance unchanged. |
 |
| What the fruit looks like when ripe in the picture |  |
1. Source Image Analysis: The source image shows green, unripe bananas. 2. Instruction Understanding: The instruction asks for the appearance of the fruit when ripe. 3. Reasoning Process: Ripening involves a breakdown of chlorophyll and the production of sugars, which turns the skin from green to yellow and often causes small brown sugar spots to appear. 4. Expected Visual Changes: The color and texture of the peel should transition to a ripe state. 5. Elements to Preserve: The shape of the bananas and the white background should remain constant. 6. Explicit Edit Prompt: Edit the green bananas to be bright yellow with small brown spots, while keeping the original shape and white background unchanged. |
 |
 ](./docs/assets/showcases/interleave/case_0005_matchgirl_warm_au.webp) |
| [
](./docs/assets/showcases/interleave/case_0005_matchgirl_warm_au.webp) |
| [ ](./docs/assets/showcases/interleave/case_0006_orange_cat_travel.webp) |
](./docs/assets/showcases/interleave/case_0006_orange_cat_travel.webp) |
 ](./docs/assets/showcases/interleave/reasoning.png) |
](./docs/assets/showcases/interleave/reasoning.png) |
 ](./docs/assets/showcases/vqa/general_case.webp) |
](./docs/assets/showcases/vqa/general_case.webp) |
 ](./docs/assets/showcases/vqa/agentic_case.webp) |
](./docs/assets/showcases/vqa/agentic_case.webp) |
 ](./docs/assets/showcases/wm/1.png) |
](./docs/assets/showcases/wm/1.png) |

| Discord | 微信交流群 |
 |
 |