
ConStory-Bench
Lost in Stories: Consistency Bugs in Long Story Generation by LLMs





---
## 🔍 Overview
LLMs can generate stories with tens of thousands of words, but they often contradict themselves along the way — characters forget their backstories, timelines break, and world rules silently change.
**ConStory-Bench** is a benchmark for evaluating **narrative consistency** in long-form story generation. It includes prompts, an automated evaluation pipeline (**ConStory-Checker**), and pre-computed results for a wide range of models.
ConStory-Checker detects consistency errors across **5 categories** (19 subtypes):
- **Characterization** — memory contradictions, knowledge conflicts, skill/power fluctuations, forgotten abilities
- **Factual Detail** — appearance mismatches, nomenclature confusions, quantitative errors
- **Narrative Style** — perspective shifts, tone inconsistencies, style breaks
- **Timeline & Plot** — time contradictions, duration errors, causality violations, abandoned plots
- **World-building & Setting** — rule violations, social norm conflicts, geographical contradictions
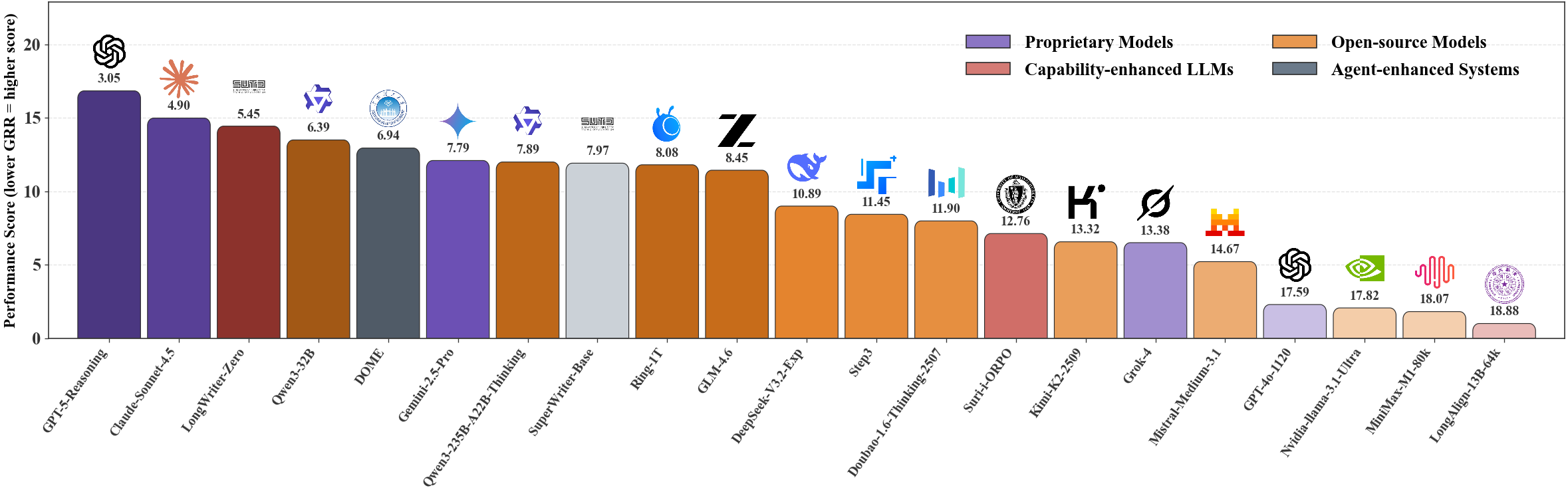
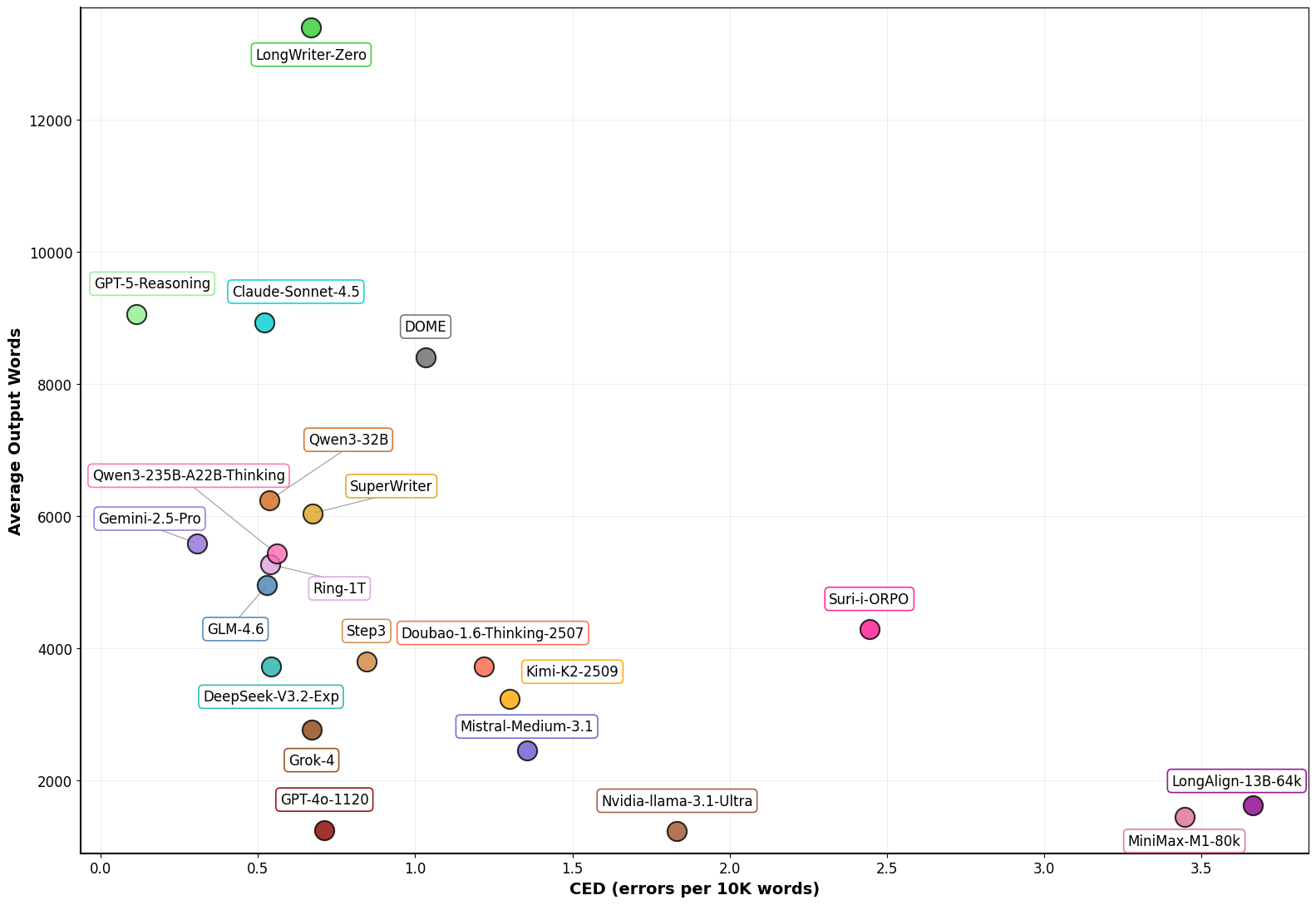
🏆 **With ConStory-Bench, we aim to track how well LLMs maintain narrative consistency as they scale. View our [Leaderboard](https://picrew.github.io/constory-bench.github.io/leadboard/) (updating).**
## 🔥 News
- [2026-04-07] Our paper *Lost in Stories: Consistency Bugs in Long Story Generation by LLMs* was accepted to **ACL 2026**.
## 📄 Paper
- arXiv Abstract: https://arxiv.org/abs/2603.05890
- arXiv PDF: https://arxiv.org/pdf/2603.05890
## 📦 Dataset
All data is hosted on HuggingFace: [jayden8888/ConStory-Bench](https://huggingface.co/datasets/jayden8888/ConStory-Bench)
| File | Description |
| --- | --- |
| `prompts.parquet` | Benchmark prompts (4 task types) |
| `stories.parquet` | Generated stories from multiple models |
| `evaluations/*.csv` | ConStory-Checker results per model |
### Load Data
```python
from datasets import load_dataset
# Load prompts
prompts = load_dataset("jayden8888/ConStory-Bench", data_files="prompts.parquet", split="train")
print(len(prompts)) # 2000
# Load all stories
stories = load_dataset("jayden8888/ConStory-Bench", data_files="stories.parquet", split="train")
```
Or with pandas:
```python
import pandas as pd
prompts = pd.read_parquet("hf://datasets/jayden8888/ConStory-Bench/prompts.parquet")
stories = pd.read_parquet("hf://datasets/jayden8888/ConStory-Bench/stories.parquet")
```
## ⚡ Quick Start
### Install
```bash
git clone https://github.com/Picrew/ConStory-Bench.git
cd ConStory-Bench
pip install -r requirements.txt
```
### Step 1 — Generate Stories
Use any OpenAI-compatible API:
```bash
export OPENAI_API_KEY="your-key"
python -m constory.generate \
--input data/prompts.parquet \
--output data/stories/my_model.parquet \
--model gpt-4o \
--concurrent 5
```
Also works with local servers (vLLM, Ollama, etc.):
```bash
python -m constory.generate \
--input data/prompts.parquet \
--output data/stories/llama3.parquet \
--model meta-llama/Llama-3-70B-Instruct \
--api-base http://localhost:8000/v1 \
--api-key token-abc123
```
### Step 2 — Evaluate with ConStory-Checker
```bash
python -m constory.judge \
--input data/stories/my_model.parquet \
--story-column generated_story \
--model-name my_model \
--concurrent 3
```
### Step 3 — Compute Metrics
```bash
# All models
python -m constory.metrics \
--eval-dir evaluations/ \
--config configs/models.yaml \
--mode both
# Single model
python -m constory.metrics \
--eval-dir evaluations/ \
--mode ced \
--eval-file my_model.csv \
--story-column generated_story \
--model-name my_model
```
### Step 4 — Error Correlation Analysis
Compute **conditional probability matrices** P(B|A) between the 5 error categories.
For example: "Given a story has *Timeline* errors, what is the probability it also has *Factual* errors?"
```bash
# All models
python -m constory.correlation \
--eval-dir evaluations/ \
--config configs/models.yaml
# 8 representative models from the paper
python -m constory.correlation \
--eval-dir evaluations/ \
--config configs/models.yaml \
--models "GPT-5-Reasoning,Claude-Sonnet-4.5,Gemini-2.5-Pro,Qwen3-235B-A22B-Thinking,GLM-4.6,DeepSeek-V3.2-Exp,Kimi-K2-2509,GPT-4o-1120"
```
### Step 5 — Error Positional Distribution
Analyze **where** in the story errors appear — the position (0–100%) where the original fact is established vs. where the contradiction occurs, and the gap between them.
```bash
# 8 representative models from the paper
python -m constory.positional \
--eval-dir evaluations/ \
--config configs/models.yaml \
--models "GPT-5-Reasoning,Claude-Sonnet-4.5,Gemini-2.5-Pro,Qwen3-235B-A22B-Thinking,GLM-4.6,DeepSeek-V3.2-Exp,Kimi-K2-2509,GPT-4o-1120"
```
## Leaderboard
Full results on our **[🏆 Leaderboard](https://picrew.github.io/constory-bench.github.io/leadboard/)** (updating).
| Model | Category | CED | Avg Words | Total |
| --- | --- | --- | --- | --- |
| GPT-5-Reasoning | Proprietary | 0.113 | 9,050 | 1,990 |
| Gemini-2.5-Pro | Proprietary | 0.302 | 5,091 | 1,996 |
| Gemini-2.5-Flash | Proprietary | 0.305 | 5,504 | 1,996 |
| Claude-Sonnet-4.5 | Proprietary | 0.520 | 8,929 | 1,998 |
| GLM-4.6 | Open-source | 0.528 | 4,949 | 2,000 |
| Qwen3-32B | Open-source | 0.537 | 6,237 | 2,000 |
| Ring-1T | Open-source | 0.539 | 5,264 | 1,999 |
| DeepSeek-V3.2-Exp | Open-source | 0.541 | 3,724 | 2,000 |
| Qwen3-235B-A22B-Thinking | Open-source | 0.559 | 5,424 | 2,000 |
| GLM-4.5 | Open-source | 0.595 | 5,421 | 2,000 |
| LongWriter-Zero-32B | Capability-enhanced | 0.669 | 13,393 | 1,857 |
| Grok-4 | Proprietary | 0.670 | 2,765 | 2,000 |
| SuperWriter | Agent-enhanced | 0.674 | 6,036 | 2,000 |
| Ling-1T | Open-source | 0.699 | 5,088 | 2,000 |
| GPT-4o-1120 | Proprietary | 0.711 | 1,241 | 1,774 |
| Step3 | Open-source | 0.845 | 3,793 | 1,916 |
| Qwen3-Next-80B-Thinking | Open-source | 0.959 | 4,820 | 1,973 |
| DOME | Agent-enhanced | 1.033 | 8,399 | 1,969 |
| Doubao-1.6-Thinking-2507 | Proprietary | 1.217 | 3,713 | 2,000 |
| Kimi-K2-2509 | Open-source | 1.300 | 3,227 | 1,792 |
| Kimi-K2-2507 | Open-source | 1.330 | 3,046 | 2,000 |
| Mistral-Medium-3.1 | Proprietary | 1.355 | 2,447 | 2,000 |
| Qwen3-235B-A22B | Open-source | 1.447 | 3,246 | 2,000 |
| Qwen3-Next-80B | Open-source | 1.603 | 4,013 | 2,000 |
| Qwen3-4B-Instruct-2507 | Open-source | 1.685 | 4,919 | 1,997 |
| Nvidia-Llama-3.1-Ultra | Open-source | 1.833 | 1,224 | 1,998 |
| Qwen3-30B-A3B-Instruct-2507 | Open-source | 2.130 | 2,968 | 2,000 |
| DeepSeek-V3 | Open-source | 2.422 | 670 | 2,000 |
| Suri-ORPO | Capability-enhanced | 2.445 | 4,279 | 2,000 |
| QwenLong-L1-32B | Open-source | 3.413 | 1,234 | 2,000 |
| DeepSeek-R1 | Open-source | 3.419 | 680 | 1,952 |
| MiniMax-M1-80k | Open-source | 3.447 | 1,442 | 1,716 |
| LongAlign-13B | Capability-enhanced | 3.664 | 1,624 | 2,000 |
## Repository Structure
```text
ConStory-Bench/
├── README.md
├── LICENSE # MIT
├── requirements.txt
├── assets/ # Logo, figures from paper
├── configs/
│ └── models.yaml # Model registry (name, file, column, category)
├── constory/ # Core Python package
│ ├── __init__.py
│ ├── generate.py # Story generation (OpenAI-compatible API)
│ ├── judge.py # ConStory-Checker (LLM-as-judge)
│ ├── metrics.py # CED & GRR computation
│ ├── correlation.py # Error correlation analysis (P(B|A))
│ └── positional.py # Error positional distribution analysis
├── prompts/ # Judge prompt templates (5 categories)
│ ├── characterization.md
│ ├── factual_detail.md
│ ├── narrative_style.md
│ ├── timeline_plot.md
│ └── world_building.md
└── scripts/
├── run_generation.sh
└── run_judge.sh
```
## 📝 Citation
```bibtex
@misc{li2026loststoriesconsistencybugs,
title={Lost in Stories: Consistency Bugs in Long Story Generation by LLMs},
author={Junjie Li and Xinrui Guo and Yuhao Wu and Roy Ka-Wei Lee and Hongzhi Li and Yutao Xie},
year={2026},
eprint={2603.05890},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.05890}
}
```
## License
[MIT License](LICENSE)