{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Основы программирования в Python\n",
"\n",
"*Алла Тамбовцева, НИУ ВШЭ*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Немного про язык html\n",
"\n",
"**HTML (HyperText Markup Language)** – язык разметки (для тех, кто работал с *RMarkdown*: *Markdown* ‒ тоже язык разметки, только попроще). Поэтому, любая html-страница в интернете – это обычный текст, в котором отмечено, какие части представляют собой заголовок, абзац, таблицу, картинку и так далее. Вообще, правилом хорошего тона считается включать в html-код только содержательные вещи с разметкой, а все оформление и интерактив выносить в отдельные файлы.\n",
"\n",
"Обычно, за страницей в интернете кроется примерно следующее. На сервере лежит несколько папок. В одной папке лежат сами html-страницы с размеченным текстом. В другой – хранятся файлы *css* (*Cascading Style Sheets*), в которых заданы параметры оформления разных страниц (цвет заголовков, фона, меню, ширина рамочек вокруг текста и картинок и прочее). В третьей папке находятся файлы с кодом на *JavaScript*, которые отвечают за всевозможный интерактив: будь то всплывающий перевод слова при наведении курсора, увеличение картинки при просмотре, подсветка формы для заполнения, если формат даты неверный, и так далее. JavaScript ‒ тоже отдельный язык программирования (несмотря на название, с Java не связан), на котором пишется код, соответствующий интерактиву.\n",
"\n",
"Все эти файлы связаны между собой: к каждому html-файлу присоединены с помощью ссылок css-файл с оформлением и код javascript. Иногда, к сожалению, html-страницы создаются не по стандартам, и в файле с текстом встречаются огромные куски, отвечающие за оформление, что значительно затрудняет работу (на примеры таких сайтов мы потом посмотрим).\n",
"\n",
"Сегодня мы начнем разбирать веб-скрейпинг и парсинг html-файлов. Обычно два этих процесса связаны, просто парсинг – более узкое понятие. Веб-скрейпинг (*web scraping*) – это вообще выгрузка данных с веб-страниц, а парсинг (*parsing*) – это выбор текста из файла с разметкой, например, из html или xml. Но прежде, чем разбирать работу с html-файлами, давайте познакомимся поближе с их структурой. Для этого зайдем на сайт [w3schools.com](https://www.w3schools.com/Html/) и откроем [раздел](https://www.w3schools.com/Html/tryit.asp?filename=tryhtml_default) *Try it yourself*. \n",
"\n",
"Это удобный учебный инструмент для создания html-файлов (и да, вообще на сайте много документации и тьюториалов по html, css и веб-дизайну вообще). Давайте создадим свою страничку. \n",
"\n",
"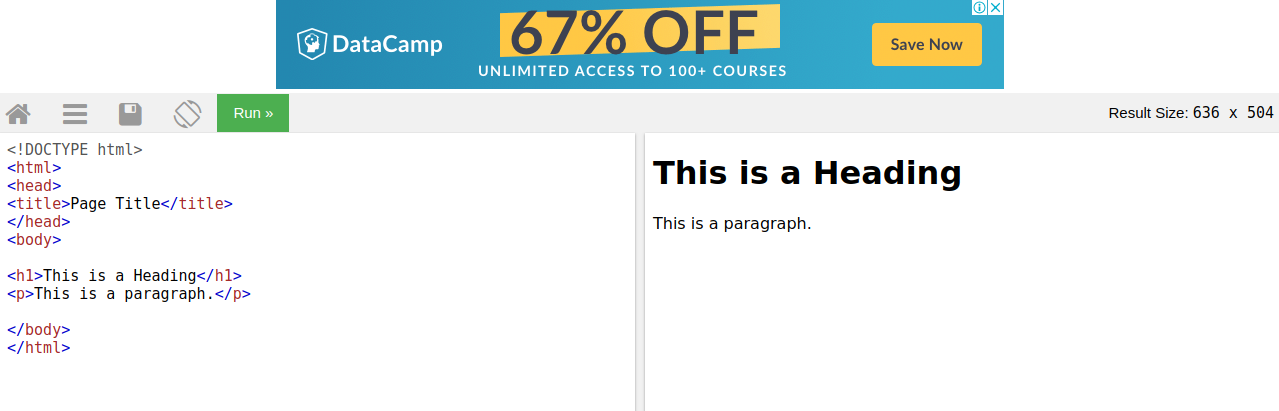\n",
"\n",
"Для разметки используются тэги – служебные слова в треугольных скобках `<>`. Тэги бывают разными: открывающие и закрывающие. Закрывающие тэги начинаются с прямого слэша (`/`). \n",
"\n",
"Вся страница заключается в тэг ``. В начале обычно указывается какая-то мета-информация: язык страницы, кодировка, метки, название и прочее. Здесь, правда, такого нет. \"Тело\" документа, собственно страница, которая отображается при просмотре, заключается в тэг ``. \n",
"\n",
"Для заголовков используются тэги с `h` (`h` – от *header*). Тэги `` ‒ для заголовков первого уровня, тэг `` – для заголовков уровня, и так далее. В тэги `` заключаются абзацы (`p` – от *paragraph*). Давайте для начала внесем изменения в файл ‒ создадим страничку о себе. Можете скопировать код ниже в поле на странице *Try it Yourself* и нажать кнопку *Run*."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"\n",
"\n",
"Page Title\n",
"\n",
"\n",
"\n",
"Моя первая html-страница
\n",
"О себе
\n",
"Я учусь создавать html-страницы.
\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"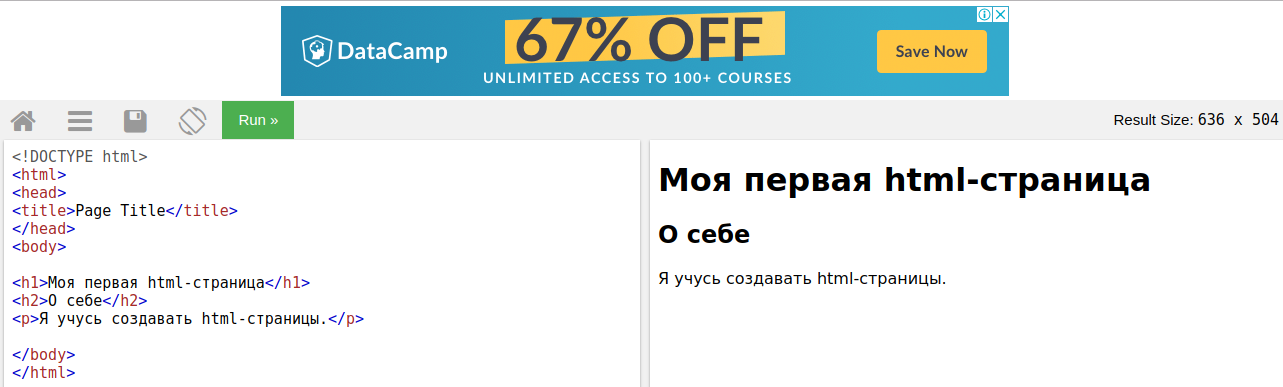"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Теперь добавим небольшую таблицу. Знания об устройстве таблиц нам понадобятся, потому что чаще всего при парсинге приходится «выцапывать» данные из таблиц на html-страницах.\n",
"\n",
"Вся таблица заключается в тэги ``. Далее таблица заполняется по строкам. Строка таблицы заключается в тэги `|
` (от *table row*). Ячейки таблицы тоже имеют свои тэги. Если ячейка обычная, то есть не является названием столбца или строки, она окружена тэгом ` | ` (от *table *), если является ‒ то ` | ` (от *table header*).\n",
"\n",
"Создадим свою таблицу:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"\n",
"| Фамилия | \n",
"Имя | \n",
"Возраст | \n",
"
\n",
"\n",
"| Тамбовцева | \n",
"Алла | \n",
"24 | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Можем добавить явные границы ячеек – добавить атрибут *border* и отрегулировать ширину. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"\n",
"| Фамилия | \n",
"Имя | \n",
"Возраст | \n",
"
\n",
"\n",
"| Тамбовцева | \n",
"Алла | \n",
"24 | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Еще добавим заголовок и на этом закончим."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"\n",
"\n",
"Page Title\n",
"\n",
"\n",
"\n",
"Моя первая html-страница
\n",
"О себе
\n",
"Я учусь создавать html-страницы.
\n",
"\n",
"\n",
"Информация\n",
"\n",
"| Фамилия | \n",
"Имя | \n",
"Возраст | \n",
"
\n",
"\n",
"| Тамбовцева | \n",
"Алла | \n",
"24 | \n",
"
\n",
"
\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.5"
}
},
"nbformat": 4,
"nbformat_minor": 2
}