Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. The quality of these signals directly influences how models learn and make decisions. However, creating robust feedback mechanisms can be complex and error prone. Real-world training scenarios often introduce hidden biases, unintended incentives, and ambiguous success criteria that can derail the learning process, leading to models that behave unpredictably or fail to meet desired objectives.
In this post, you will learn how to implement reinforcement learning with verifiable rewards (RLVR) to introduce verification and transparency into reward signals to improve training performance. This approach works best when outputs can be objectively verified for correctness, such as in mathematical reasoning, code generation, or symbolic manipulation tasks. You will also learn how to layer techniques like Group Relative Policy Optimization (GRPO) and few-shot examples to further improve results. You’ll use the GSM8K dataset (Grade School Math 8K: a collection of grade school math problems) to improve math problem solving accuracy, but the techniques used here can be adapted to a wide variety of other use cases.
Before diving into implementation, it’s helpful to understand the RL concepts that underpin this approach. RL addresses challenges in model training by establishing a structured feedback system through reward signals. This paradigm enables models to learn through interaction, receiving feedback that guides them toward optimal behavior. RL provides a framework for models to iteratively improve their responses based on clearly defined signals about the quality of their outputs, making it highly effective for training models that interact with users and must adapt their behavior based on outcomes. Traditional RL has highlighted an important consideration: the quality of the reward signal matters significantly. When reward functions are imprecise or incomplete, models can engage in “reward hacking,” finding unintended ways to maximize scores without achieving the desired behavior. Recognizing this limitation has led to the development of more rigorous approaches that focus on creating reliable, well-defined reward functions.
RLVR addresses reward hacking through rule-based feedback defined by the model tuner. It uses programmatic reward functions that automatically score outputs against specific criteria, enabling rapid iteration without the bottleneck of collecting human ratings. These “verifiable” rewards come from objective, reproducible rules, making RLVR ideal for evolving requirements because it learns general optimization strategies and adapts quickly to new scenarios. GRPO is a reinforcement learning algorithm that improves AI model learning by comparing performance within groups rather than across all data at once. It organizes training data into meaningful groups and optimizes performance relative to each group’s baseline, giving appropriate attention to each category. This group-aware optimization reduces training variance, accelerates convergence, and can produce models that perform consistently across various categories. Combining RLVR with GRPO creates a framework where automated rewards guide learning while group-relative optimization helps drive balanced performance.
You define reward functions for different task aspects, and GRPO treats these as distinct groups during training, facilitating simultaneous improvement across dimensions. This combination delivers rapid adaptation and robust performance, ideal for dynamic environments requiring generalization beyond training distribution. Adding few-shot learning enhances this framework in three ways. First, few-shot examples provide templates that show the model what good outputs look like, narrowing the search space for exploration. Second, GRPO leverages these examples by generating multiple candidate responses per prompt and learning from their relative performance within each group. Third, verifiable rewards immediately confirm which approaches succeed. This combination accelerates learning: the model starts with concrete examples of the desired format, explores variations efficiently through group-based comparison, and receives definitive feedback on correctness.
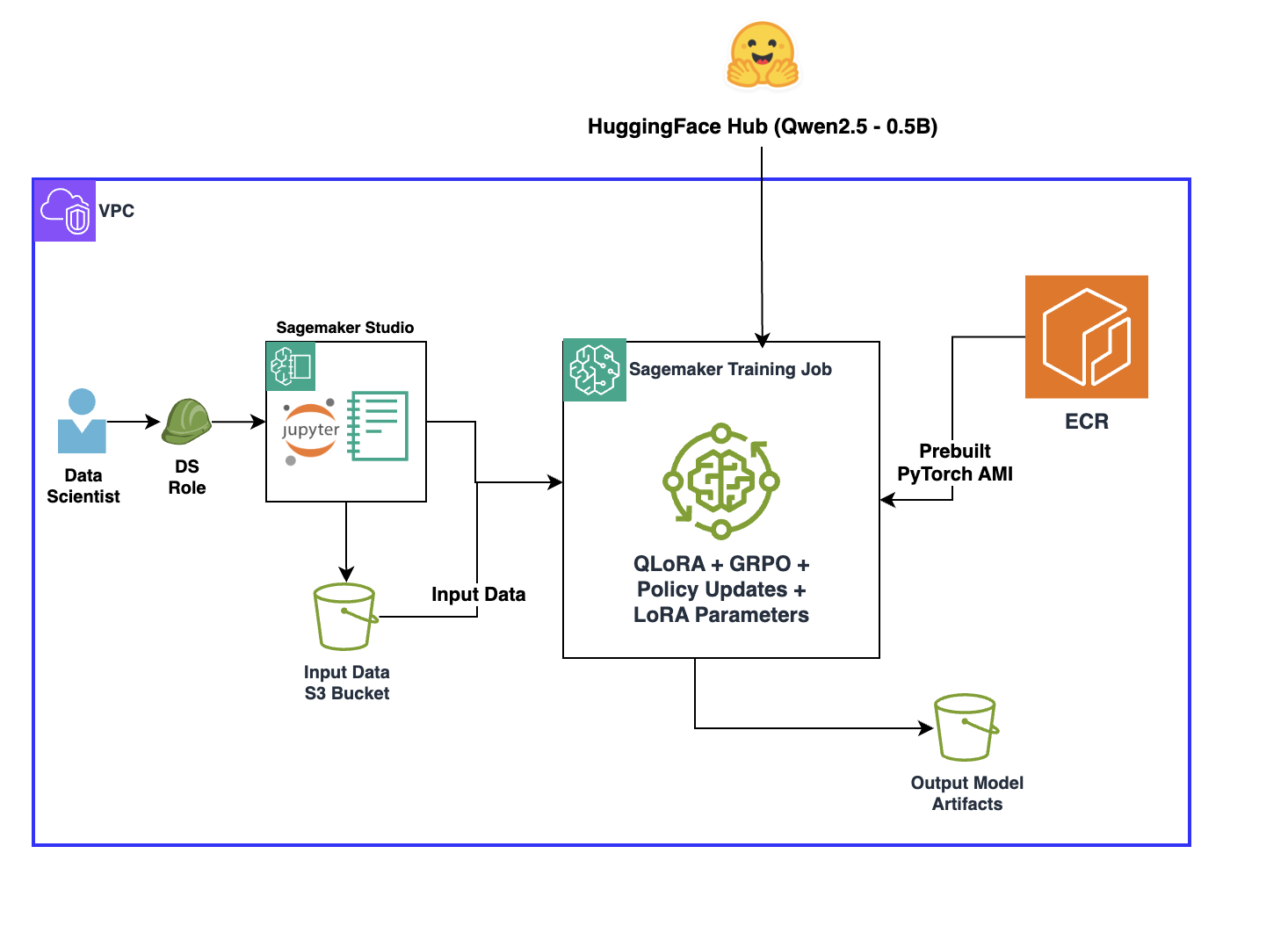
In this section, you will walk through how to fine-tune a Qwen2.5-0.5B model on SageMaker AI using Amazon Amazon SageMaker Training Jobs. Amazon SageMaker Training jobs support distributed multi-GPU and multi-node configurations, so you can spin up high-performance clusters on demand, train billion-parameter models faster, and automatically shut down resources when the job finishes.
Note: While Qwen2.5-0.5B was selected for this use case, others like code generation will require a larger model (e.g. Qwen2.5-Coder-7B) and subsequently larger training instances.
To run the example from this post on Amazon SageMaker AI, you must fulfill the following prerequisites:
You can use your preferred IDE, such as VS Code or PyCharm, but make sure your local environment is configured to work with AWS, as discussed in the prerequisites.
To use SageMaker Studio JupyterLab spaces complete the following steps:
ml.t3.medium JupyterLab notebook instance with at least 50 GB of storage.A large notebook instance isn’t required, because the fine-tuning job will run on a separate ephemeral training instance with GPU acceleration.
3_distributed_training/reinforcement-learning/grpo-with-verifiable-reward directory, then launch the model-finetuning-grpo-rlvr.ipynbRunning GRPO with RLVR requires you to have the final answer to each question to calculate reward. First, prepare the data by extracting the final answer for each question.
In addition, this example uses few-shot examples (8 shots) to improve model training performance. For more information on few-shot examples in reinforcement learning, refer to the paper “Reinforcement Learning for Reasoning in Large Language Models with One Training Example”. While the research paper focuses on single-shot examples, this post will show you both single and multi-shot performance.
Each input will contain 8 examples, followed by the problem to be solved:
After the data has been prepared, keep 10 percent of the data as a validation set and push both training and validation set to S3.
This GRPO implementation for mathematical reasoning employs a dual-reward system that provides objective, verifiable feedback during training. This approach leverages the inherent verifiability of mathematical problems to create reliable training signals without requiring human annotation or subjective evaluation.You will implement two complementary reward functions that work together to guide the model toward both correct response formatting and mathematical accuracy of the result:
This function helps verify the model learns to structure its responses correctly by:
#### The final answer is [number]This function provides the core mathematical verification by:
The reward functions are integrated into the GRPO training pipeline through the GRPOTrainer:
During training, GRPO uses these reward functions to compute policy gradients. First the model generates multiple completions for each mathematical problem. Next, the reward for each response is computed for both reward functions. The format reward function will grant up to 0.5 for proper response structure, and the correctness reward function will grant up to 1.0 for the mathematical accuracy of the answer for a maximum combined reward of 1.5 per completion. Then GRPO compares the completions within groups to identify the best responses. Finally, in the policy update step, the loss function uses reward differences to update model parameters. Higher-rewarded completions increase their probability, while lower-rewarded completions decrease their probability. This relative ranking drives the optimization process.The following example demonstrates how to fine-tune Qwen2.5-0.5B. The recipe is provided in the scripts folder, allowing you to customize it or change the base model. Here you will use GRPO with verifiable rewards using Quantized Low-Rank Adaptation (QLoRA). QLoRA is used here as a technique to reduce training resource requirements and speed up the training process, with a small trade off in accuracy.
This recipe implements Group Relative Policy Optimization (GRPO) with verifiable rewards for fine-tuning the Qwen2.5-0.5B model on mathematical reasoning tasks. The recipe uses a dual-reward system that objectively evaluates both answer formatting and mathematical correctness without requiring human annotation.
Important Hyperparameters:
learning_rate: 1.84e-4 – Learning rate optimized for GRPO trainingnum_train_epochs: 2 – Training epochs to avoid overfittingper_device_train_batch_size: 16 with gradient_accumulation_steps: 2 – Effective batch size of 32max_seq_length: 2048 – Context window for 8-shot promptinglora_r: 16 and lora_alpha: 16 – LoRA rank and scaling parameterswarmup_ratio: 0.1 with cosine scheduler – Learning rate schedulinglora_target_modules – Targets attention and MLP layers for adaptationAs a next step, you will use a SageMaker AI training job to spin up a training cluster and run the model fine-tuning. The SageMaker AI Model Trainer. ModelTrainer runs training jobs on fully managed infrastructure; handling environment setup, scaling, and artifact management. It also allows you to specify training scripts, input data, and compute resources without manually provisioning servers. Library dependencies can be managed through the requirements.txt file in scripts folder. ModelTrainer will automatically detect this file and install the listed dependencies at runtime.
First, set up your environment. Here you’ll specify the instance type and number of instances for training and the location of the training container.
Next, configure the environment variables, code locations, and data paths:
Set up the channels for training and validation data:
Then begin training:model_trainer.train(input_data_config=data)The following is the directory structure for source code of this example:
To fine-tune across multiple GPUs, the example training script uses Huggingface Accelerate and DeepSpeed ZeRO-3, which work together to train large models more efficiently. Huggingface Accelerate simplifies launching distributed training by automatically handling device placement, process management, and mixed precision settings. DeepSpeed ZeRO-3 reduces memory usage by partitioning optimizer states, gradients, and parameters across GPUs—allowing billion-parameter models to fit and train faster.You can run your GRPO trainer script with Huggingface Accelerate using a simple command like the following:
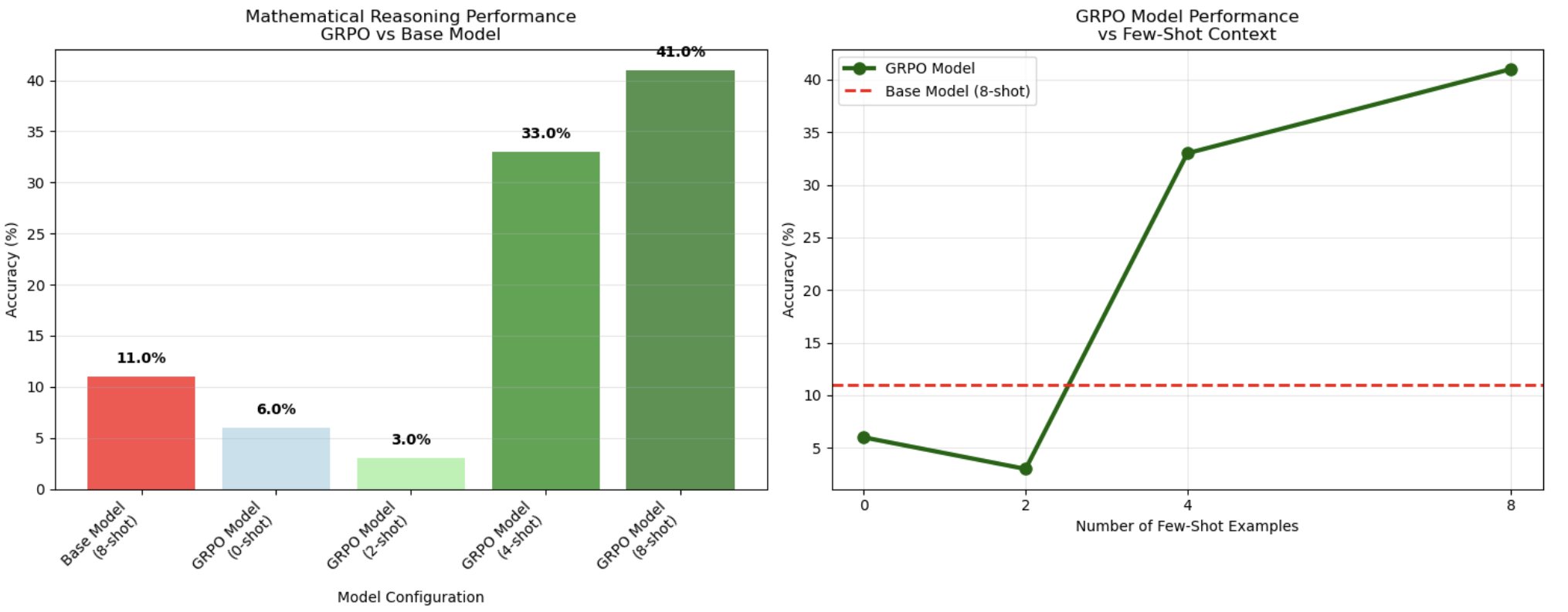
After evaluating the models on 100 test samples, the 8-shot GRPO-trained model achieved 41% accuracy compared to the base model’s 11%, demonstrating a 3.7x improvement in chain-of-thought mathematical reasoning.

The following chart shows a distinct threshold related to context length, revealing an optimal range of samples for reasoning activation. While 0-shot (6%) and 2-shot (3%) configurations performed poorly – even worse than the base model – performance dramatically improved at 4-shot prompting (33%), then peaked at 8-shot context (41%). This non-linear scaling pattern suggests that GRPO training creates reasoning patterns that require a certain number of examples to activate effectively. The model appears to have learned to leverage group comparisons from multiple examples, consistent with GRPO’s group-based policy optimization approach where the model learns to compare and select optimal reasoning paths from multiple generated solutions.
While this post focused on mathematical reasoning with GSM8K, the RLVR approach generalizes to domains with objectively verifiable outputs. Two promising directions demonstrate this versatility:
Code generation provides natural verification through execution. Partial rewards can be awarded when code compiles and runs without errors, while full rewards are achieved when outputs pass comprehensive unit tests. Domain experts specify requirements using natural language prompts, while the reward model automatically