[](https://github.com/SUFE-AIFLM-Lab/FinEval/blob/main/LICENSE)
[🌐Website](https://fineval.readthedocs.io/zh_CN/latest/) |
[🤗Hugging Face](https://huggingface.co/datasets/SUFE-AIFLM-Lab/FinEval) |
[📃Paper](https://arxiv.org/abs/2308.09975)
[English](/README.md) | [简体中文](/README_zh-CN.md)
Welcome to **FinEval**
Currently, while Large Language Models (LLMs) demonstrate excellent performance in general domains, their security and complex task processing capabilities in the highly specialized and risk-sensitive financial industry remain uncertain. This paper introduces FinEval, a pioneering Chinese benchmark dataset constructed to comprehensively evaluate the professional capabilities and security of LLMs in the financial domain, providing a solid foundation for addressing this challenge.
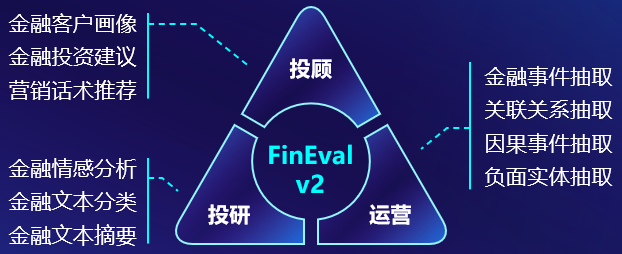
The FinEval financial domain evaluation benchmark, based on quantitative fundamental methods and developed through long-term objective research, summarization, and rigorous manual screening, utilizes over 26,000 diverse question types that are highly consistent with real-world application scenarios. These include multiple-choice questions, subjective and objective short-answer questions, reasoning and planning tasks, and retrieval-based question answering, covering financial academic knowledge, financial industry knowledge, financial security knowledge, financial intelligent agents, financial multi-modality, and financial rigor. It aims to comprehensively examine the overall application capabilities of large models in the financial domain. To ensure a comprehensive evaluation of model performance, FinEval combines subjective and objective scoring standards in its textual capability tests, including Accuracy, Rouge-L, and detailed expert evaluation criteria. It employs zero-shot, five-shot, zero-shot Chain-of-Thought (CoT), and five-shot CoT methods for evaluation.
By evaluating state-of-the-art LLMs on FinEval, the textual performance results show that Claude 3.5-Sonnet, under a zero-shot setting, achieved the highest average score of 72.9 across all financial domain tasks, indicating significant growth potential for LLMs in financial domain knowledge. In the multi-modal performance results, Qwen-VL-max performed the best among all evaluated models, achieving an average score of 76.3 and securing the top scores among evaluated models in ten sub-scenarios. This strongly suggests that Qwen-VL-max possesses stable and robust capabilities across multi-modal business scenarios of varying depths within finance. Our work provides a more comprehensive benchmark for financial knowledge assessment, utilizing common images from financial business scenarios, simulated examination data, and some open-ended questions, covering a broad scope of LLM evaluation.
# Content
## FinEval
- [Financial Academic Knowledge](#Financial-Academic-Knowledge)
- [Financial Industry Knowledge](#Financial-Industry-Knowledge)
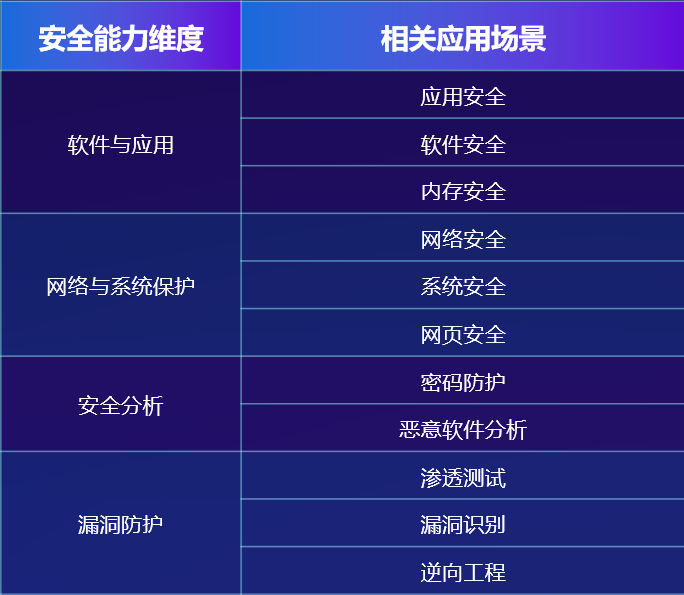
- [Financial Security Knowledge](#Financial-Security-Knowledge)
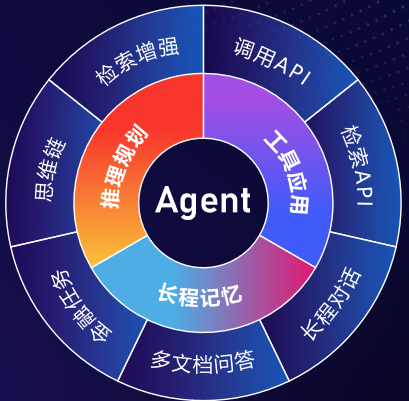
- [Financial Agent](#Financial-Agent)
- [Financial Multimodal Capabilities](#Financial-Multimodal-Capabilities)
- [Financial Rigor Testing](#Financial-Rigor-Testing)
- [Text Performance Leaderboard](#Text-Performance-Leaderboard)
- [Multimodal Performance Leaderboard](#Multimodal-Performance-Leaderboard)
## Usage
- [Installation](#Installation)
- [Evaluation](#Evaluation)
- [Dataset Preparation](#Dataset-Preparation)
- [Supporting New Datasets and Models](#Supporting-NewDatasets-and-Models)
- [How to Submit](#How-to-Submit)
- [Citation](#Citation)
## FinEval
### Financial Academic Knowledge
Financial Academic Knowledge is a collection of high-quality multiple-choice questions that encompass various fields such as Finance, Economy, Accounting, and Certificate. It consists of 4,661 questions covering 34 different academic subjects. FinEval aims to provide a comprehensive benchmark for assessing knowledge in financial academia. It utilizes simulated exam data and covers a wide range of evaluation scopes for large language models.