
Operations associated with this data type allow:
(Source)
Typical uses:
(Ordered Dictionary ADT next time.)
Direct addressing and Hashing are two ways of implementing a dictionary. Are there others?

What happens to the usual assumptions?
Correctness: always, most of the time?
Termination: always, or almost always?
What does "performance" mean if the running
time/answer/even termination change from one run to the next?
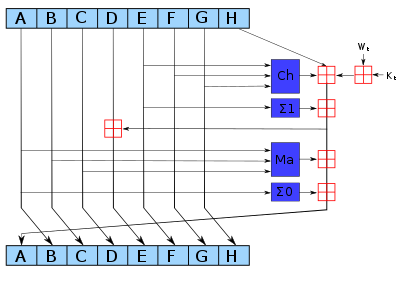
This employs chaining. Furthermore, we assume that the
distribution of elements is uniform across hash table slots.

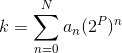
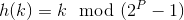
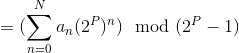
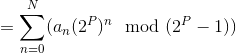 (By 1)
(By 1)
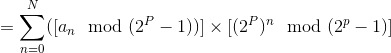 (By 2)
(By 2)
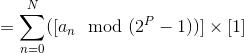 (By 3)
(By 3)
