📄 Report • 🤗 HF Repo • 🤖 ModelScope • 🟣 WiseModel • 📔 Document • 🧰 OpenXLab • 🐦 Twitter
📍Experience the larger-scale ChatGLM model at chatglm.cn
📔 About `ChatGLM3-6B`For more detailed usage information, please refer to: + [ChatGLM3 technical documentation](https://lslfd0slxc.feishu.cn/wiki/WvQbwIJ9tiPAxGk8ywDck6yfnof?from=from_copylink) + [Bilibili video](https://www.bilibili.com/video/BV1uC4y1J7yA) + [YouTube video](https://www.youtube.com/watch?v=Pw9PB6R7ORA) ## GLM-4 Open Source Model and API We have released the latest **GLM-4** model, which has made new breakthroughs in multiple indicators. You can directly experience our latest model in the following two channels. + [GLM-4 open source model](https://github.com/THUDM/GLM-4) We have open sourced the GLM-4-9B series models, which have significantly improved the performance of various indicators. Welcome to try. + [Zhipu Qingyan](https://chatglm.cn/main/detail?fr=ecology_x) Experience the latest version of GLM-4, including **GLMs, All tools** and other functions. + [API platform](https://open.bigmodel.cn/?utm_campaign=open&_channel_track_key=OWTVNma9) The new generation of API platform has been launched. You can directly experience new models such as `GLM-4-0520`, `GLM-4-air`, `GLM-4-airx`, `GLM-4-flash`, `GLM-4`, `GLM-3-Turbo`, `CharacterGLM-3`, `CogView-3` on the API platform. Among them, the two models `GLM-4` and `GLM-3-Turbo` support new functions such as `System Prompt`, `Function Call`, `Retrieval`, and `Web_Search`. You are welcome to experience them. + [GLM4 API open source tutorial](https://github.com/MetaGLM/glm-cookbook/) GLM-4 API tutorial and basic applications, welcome to try. API-related questions can be asked in this open source tutorial, or use [GLM-4 API AI Assistant](https://open.bigmodel.cn/shareapp/v1/?share_code=sQwt5qyqYVaNh1O_87p8O) to get help with common problems. ----- ## ChatGLM3 Introduction **ChatGLM3** is a generation of pre-trained dialogue models jointly released by Zhipu AI and Tsinghua KEG. ChatGLM3-6B is the open-source model in the ChatGLM3 series, maintaining many excellent features of the first two generations such as smooth dialogue and low deployment threshold, while introducing the following features: 1. **Stronger Base Model:** The base model of ChatGLM3-6B, ChatGLM3-6B-Base, adopts a more diverse training dataset, more sufficient training steps, and a more reasonable training strategy. Evaluations on datasets from various perspectives such as semantics, mathematics, reasoning, code, and knowledge show that **ChatGLM3-6B-Base has the strongest performance among base models below 10B**. 2. **More Complete Function Support:** ChatGLM3-6B adopts a newly designed [Prompt format](PROMPT_en.md), supporting multi-turn dialogues as usual. It also natively supports [tool invocation](tools_using_demo/README_en.md) (Function Call), code execution (Code Interpreter), and Agent tasks in complex scenarios. 3. **More Comprehensive Open-source Series:** In addition to the dialogue model [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b), the basic model [ChatGLM3-6B-Base](https://huggingface.co/THUDM/chatglm3-6b-base), the long-text dialogue model [ChatGLM3-6B-32K](https://huggingface.co/THUDM/chatglm3-6b-32k) and further strengthens the ability to understand long texts [ChatGLM3-6B-128K](https://huggingface.co/THUDM/chatglm3-6b-128k) have also been open-sourced. All these weights are **fully open** for academic research, and **free commercial use is also allowed** after registration via a [questionnaire](https://open.bigmodel.cn/mla/form). ----- The ChatGLM3 open-source model aims to promote the development of large-model technology together with the open-source community. Developers and everyone are earnestly requested to comply with the [open-source protocol](MODEL_LICENSE), and not to use the open-source models, codes, and derivatives for any purposes that might harm the nation and society, and for any services that have not been evaluated and filed for safety. Currently, no applications, including web, Android, Apple iOS, and Windows App, have been developed based on the **ChatGLM3 open-source model** by our project team. Although every effort has been made to ensure the compliance and accuracy of the data at various stages of model training, due to the smaller scale of the ChatGLM3-6B model and the influence of probabilistic randomness factors, the accuracy of output content cannot be guaranteed. The model output is also easily misled by user input. **This project does not assume risks and liabilities caused by data security, public opinion risks, or any misleading, abuse, dissemination, and improper use of open-source models and codes.** ## Model List | Model | Seq Length | Download |:----------------:|:----------:|:-----------------------------------------------------------------------------------------------------------------------------------: | ChatGLM3-6B | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b) | ChatGLM3-6B-Base | 8k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-base) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-base) | ChatGLM3-6B-32K | 32k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-32k) \| [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-32k) | ChatGLM3-6B-128K | 128k | [HuggingFace](https://huggingface.co/THUDM/chatglm3-6b-128k) | [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-128k) ## Projects The following excellent open source repositories have in-depth support for the ChatGLM3-6B model, and everyone is welcome to expand their learning. Inference acceleration: * [chatglm.cpp](https://github.com/li-plus/chatglm.cpp): Real-time inference on your laptop accelerated by quantization, similar to llama.cpp. * [ChatGLM3-TPU](https://github.com/sophgo/ChatGLM3-TPU): Using the TPU accelerated inference solution, it runs about 7.5 token/s in real time on the end-side chip BM1684X (16T@FP16, 16G DDR). * [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM/tree/main): A high-performance GPU-accelerated inference solution developed by NVIDIA, you can refer to these [steps](./tensorrt_llm_demo/README.md) to deploy ChatGLM3. * [OpenVINO](https://github.com/openvinotoolkit): A high-performance CPU and GPU accelerated inference solution developed by Intel, you can refer to this [step](./Intel_device_demo/openvino_demo/README.md) to deploy the ChatGLM3-6B model Efficient fine-tuning: * [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory): An excellent, easy-to-use and efficient fine-tuning framework. Application framework: * [LangChain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat): Based on large language models such as ChatGLM and application frameworks such as Langchain, open source and offline deployable retrieval enhancement generation (RAG) large Model knowledge base project. * [BISHENG](https://github.com/dataelement/bisheng): open-source platform for developing LLM applications. It empowers and accelerates the development of LLM applications and helps users to enter the next generation of application development mode with the best experience. * [RAGFlow](https://github.com/infiniflow/ragflow): An open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data. ## Evaluation Results ### Typical Tasks We selected 8 typical Chinese-English datasets and conducted performance tests on the ChatGLM3-6B (base) version. | Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval | |------------------|:-----:|:----:|:----:|:----:|:------:|:-----:|:----:|:-------:| | ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - | | Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 | | ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 | > "Best Baseline" refers to the pre-trained models that perform best on the corresponding datasets with model parameters > below 10B, excluding models that are trained specifically for a single task and do not maintain general capabilities. > In the tests of ChatGLM3-6B-Base, BBH used a 3-shot test, GSM8K and MATH that require inference used a 0-shot CoT > test, MBPP used a 0-shot generation followed by running test cases to calculate Pass@1, and other multiple-choice type > datasets all used a 0-shot test. We have conducted manual evaluation tests on ChatGLM3-6B-32K in multiple long-text application scenarios. Compared with the second-generation model, its effect has improved by more than 50% on average. In applications such as paper reading, document summarization, and financial report analysis, this improvement is particularly significant. In addition, we also tested the model on the LongBench evaluation set, and the specific results are shown in the table below. | Model | Average | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic | |-----------------|:-------:|:-------:|:-------------:|:------------:|:----:|:--------:|:---------:| | ChatGLM2-6B-32K | 41.5 | 24.8 | 37.6 | 34.7 | 52.8 | 51.3 | 47.7 | | ChatGLM3-6B-32K | 50.2 | 26.6 | 45.8 | 46.1 | 56.2 | 61.2 | 65 | ## How to Use ### Environment Installation First, you need to download this repository: ```shell git clone https://github.com/THUDM/ChatGLM3 cd ChatGLM3 ``` Then use pip to install the dependencies: ``` pip install -r requirements.txt ``` + In order to ensure that the version of `torch` is correct, please strictly follow the instructions of [official documentation](https://pytorch.org/get-started/locally/) for installation. ### Integrated Demo We provide an integrated demo that incorporates the following three functionalities. Please refer to [Integrated Demo](composite_demo/README_en.md) for how to run it. - Chat: Dialogue mode, where you can interact with the model. - Tool: Tool mode, where in addition to dialogue, the model can also perform other operations using tools. 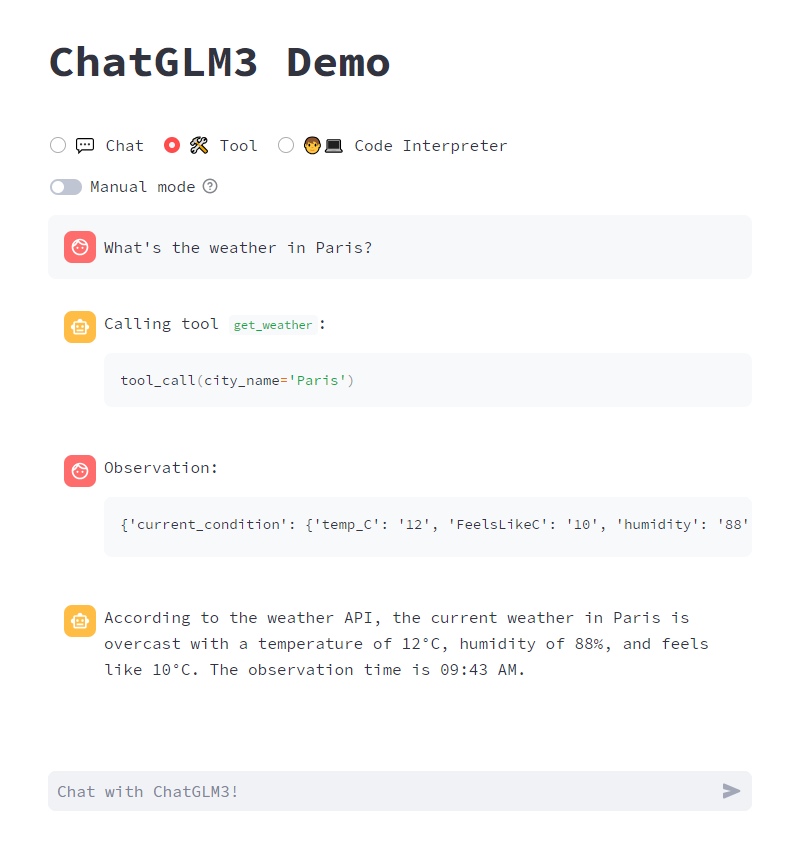 - Code Interpreter: Code interpreter mode, where the model can execute code in a Jupyter environment and obtain results to complete complex tasks.  ### Usage The ChatGLM model can be called to start a conversation using the following code: ``` >> from transformers import AutoTokenizer, AutoModel >> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True) >> model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda') >> model = model.eval() >> response, history = model.chat(tokenizer, "你好", history=[]) >> print(response) Hello 👋! I am the AI assistant ChatGLM3-6B, nice to meet you, feel free to ask me any questions. >> response, history = model.chat(tokenizer, "What should I do if I can't sleep at night?", history=history) >> print(response) Having trouble sleeping at night may make you feel anxious or uncomfortable, but here are some ways to help you fall asleep: 1. Develop a regular sleep schedule: Keeping a regular sleep schedule can help you develop healthy sleep habits and make it easier for you to fall asleep. Try to go to bed at the same time every day and get up at the same time. 2. Create a comfortable sleeping environment: Make sure the sleeping environment is comfortable, quiet, dark and at a suitable temperature. You can use comfortable bedding and keep the room ventilated. 3. Relax your body and mind: Doing some relaxing activities before bed, such as taking a hot bath, listening to some soft music, reading some interesting books, etc., can help relieve tension and anxiety and make it easier for you to fall asleep. 4. Avoid drinking caffeinated beverages: Caffeine is a stimulant that can affect your sleep quality. Try to avoid drinking caffeinated beverages such as coffee, tea and cola before bed. 5. Avoid doing things that are not related to sleep in bed: Doing things that are not related to sleep in bed, such as watching movies, playing games or working, etc., may interfere with your sleep. 6. Try breathing techniques: Deep breathing is a relaxation technique that can help you relieve tension and anxiety, making it easier for you to fall asleep. Try breathing in slowly, holding it for a few seconds, and then exhaling slowly. If these methods don't help you fall asleep, you may consider consulting a doctor or sleep specialist for further advice. ``` #### Load Model Locally The above code will automatically download the model implementation and parameters by `transformers`. The complete model implementation is available on [Hugging Face Hub](https://huggingface.co/THUDM/chatglm3-6b). If your network environment is poor, downloading model parameters might take a long time or even fail. In this case, you can first download the model to your local machine, and then load it from there. To download the model from Hugging Face Hub, you need to [install Git LFS](https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage) first, then run ```Shell git clone https://huggingface.co/THUDM/chatglm3-6b ``` If the download from HuggingFace is slow, you can also download it from [ModelScope](https://modelscope.cn/models/ZhipuAI/chatglm3-6b). # Model Fine-tuning We provide a basic fine-tuning framework for ChatGLM3-6B. You can use it to fine-tune the model on your own dataset. For more details, please refer to [Fine-tuning Demo](finetune_demo/README_en.md). ### Web-based Dialogue Demo 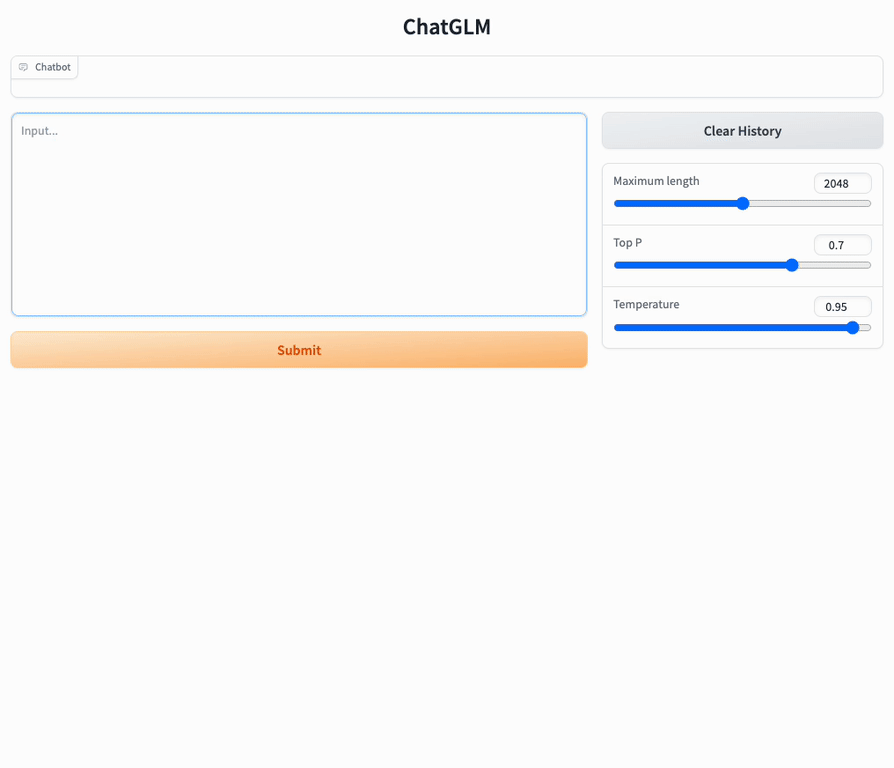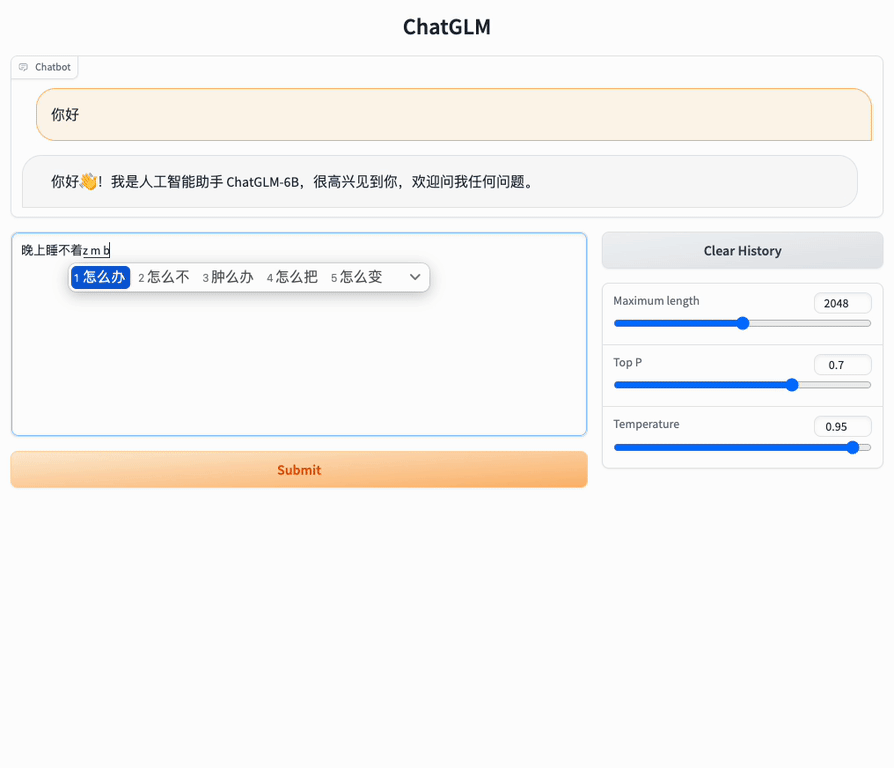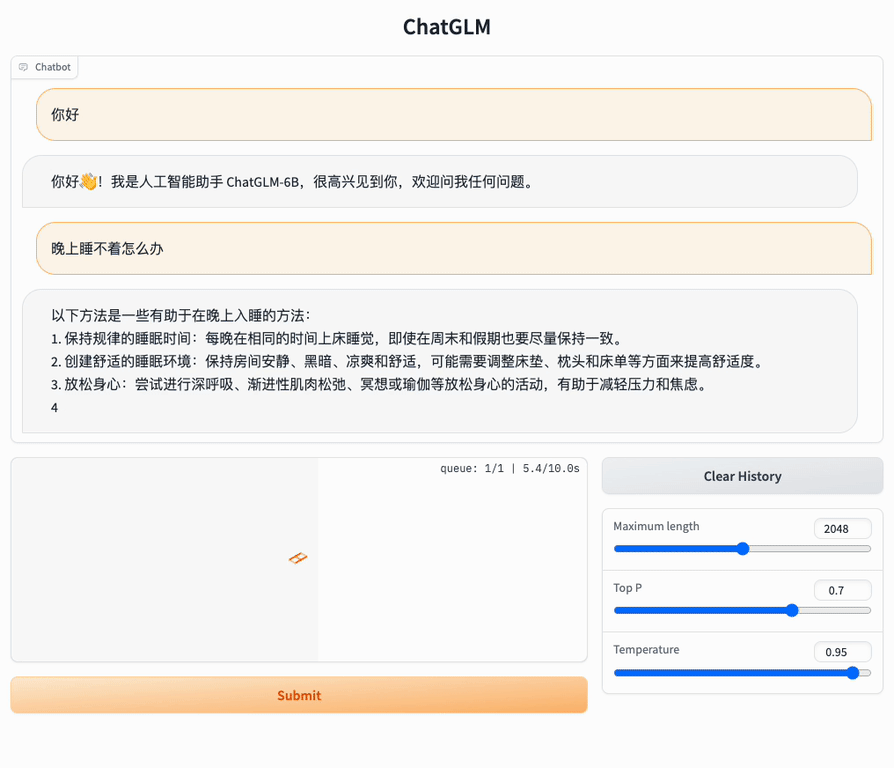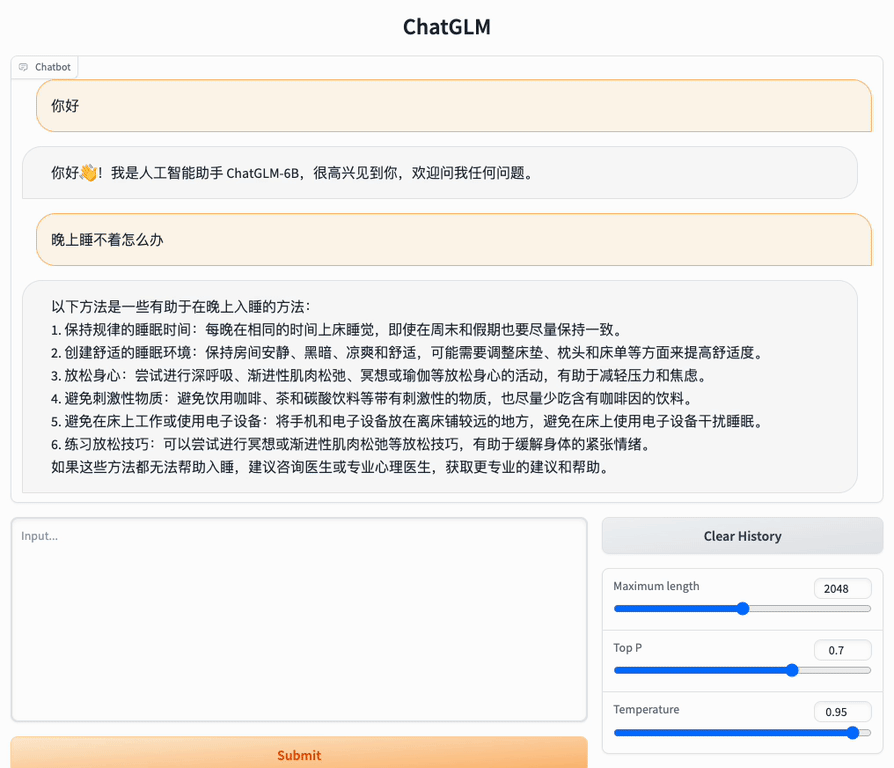 You can launch a web-based demo using Gradio with the following command: ```shell python web_demo_gradio.py ``` 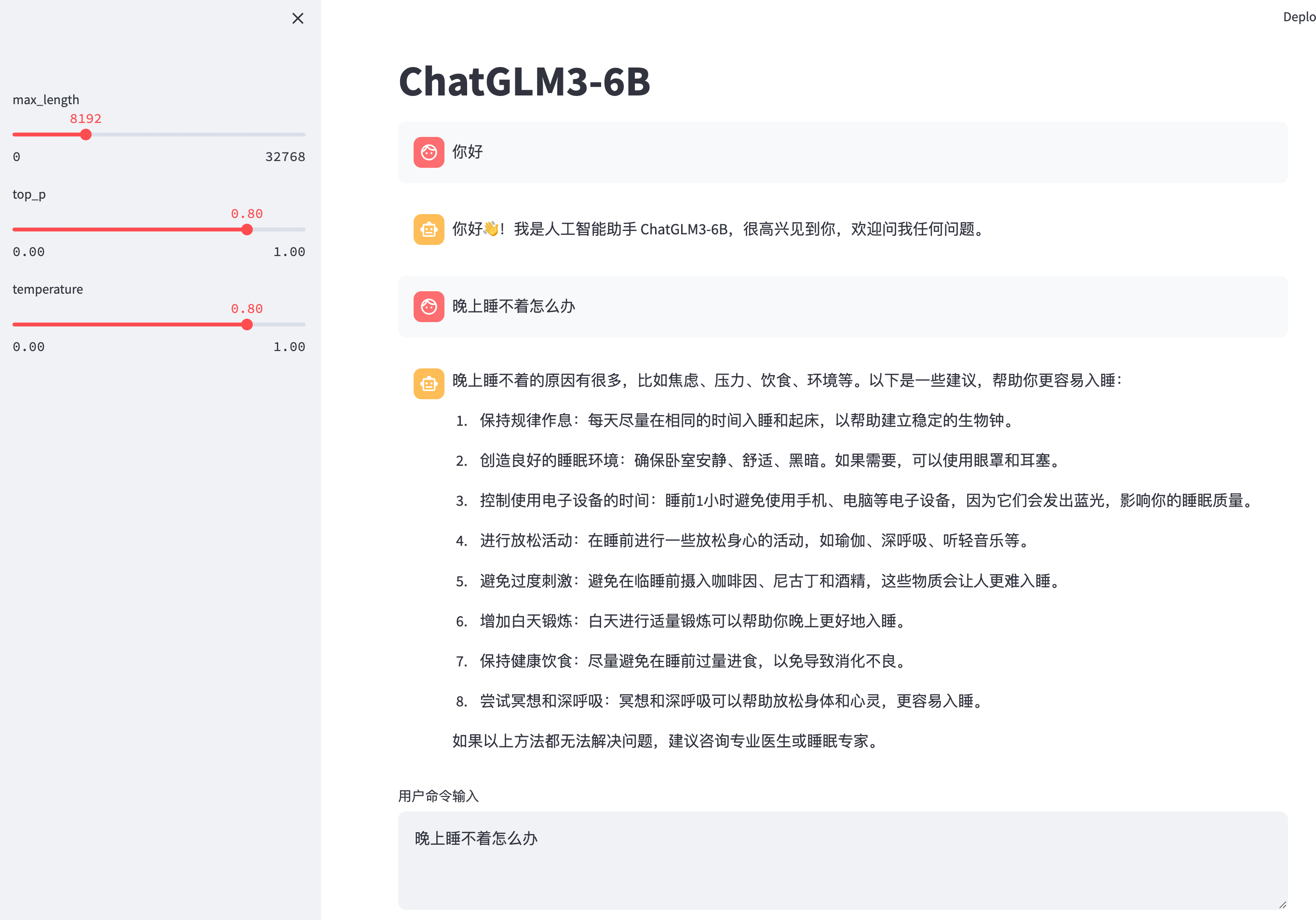 You can launch a web-based demo using Streamlit with the following command: ```shell streamlit run web_demo_streamlit.py ``` The web-based demo will run a Web Server and output an address. You can use it by opening the output address in a browser. Based on tests, the web-based demo using Streamlit runs more smoothly. ### Command Line Dialogue Demo 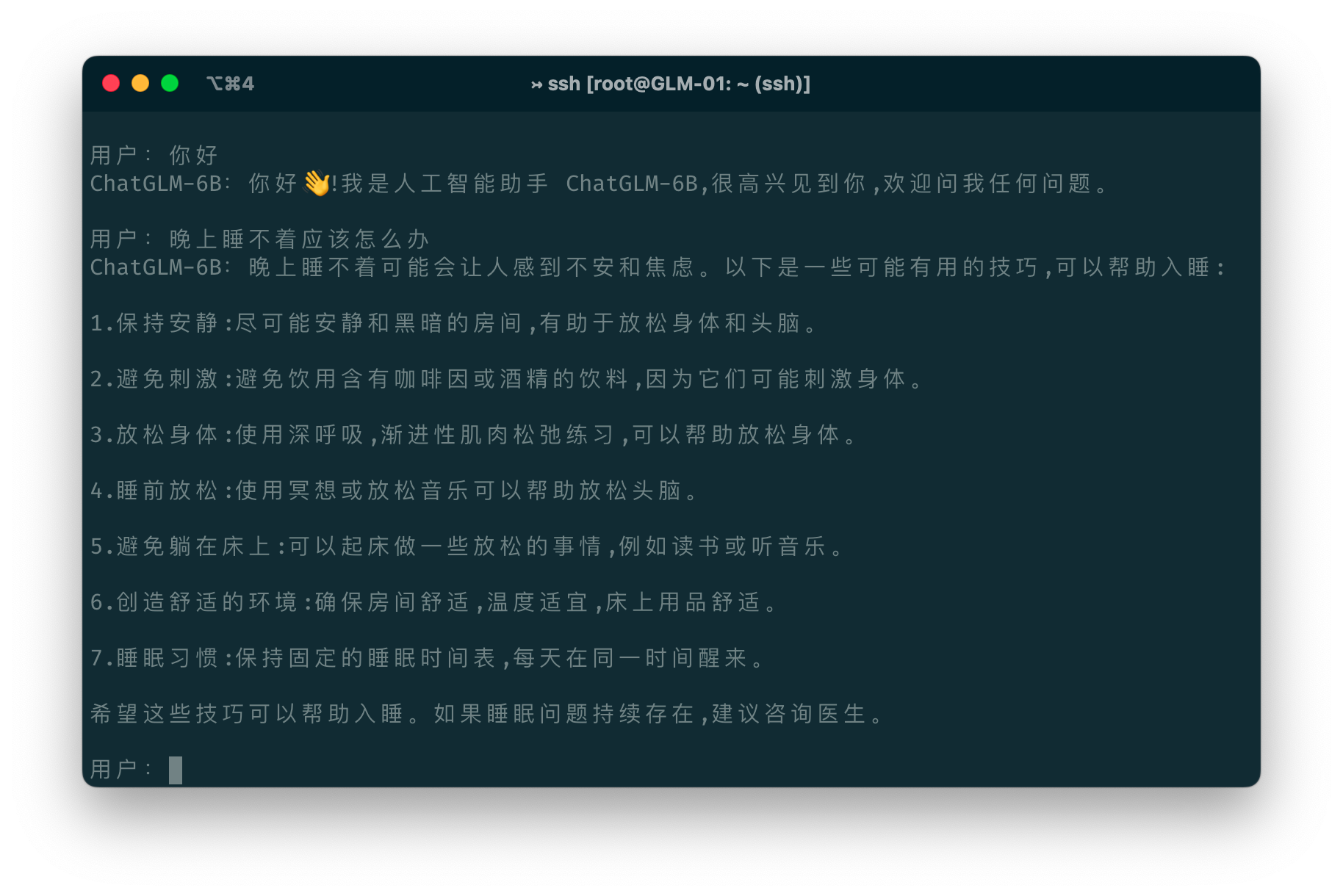 Run [cli_demo.py](basic_demo/cli_demo.py) in the repository: ```shell python cli_demo.py ``` The program will interact in the command line, enter instructions in the command line and hit enter to generate a response. Enter `clear` to clear the dialogue history, enter `stop` to terminate the program. ### OpenAI API /Zhipu API Demo We have launched open source model API deployment code in OpenAI / ZhipuAI format, which can be used as the backend of any ChatGPT-based application. Currently, you can deploy by running [api_server.py](openai_api_demo/api_server.py) in the warehouse ```shell cd openai_api_demo python api_server.py ``` At the same time, we also wrote a sample code to test the performance of API calls. + OpenAI test script: [openai_api_request.py](openai_api_demo/openai_api_request.py) + ZhipuAI test script: [zhipu_api_request.py](openai_api_demo/zhipu_api_request.py) + Test with Curl + chat Curl test ```shell curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ -d "{\"model\": \"chatglm3-6b\", \"messages\": [{\"role\": \"system\", \"content\": \"You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.\"}, {\"role\": \"user\", \"content\": \"你好,给我讲一个故事,大概100字\"}], \"stream\": false, \"max_tokens\": 100, \"temperature\": 0.8, \"top_p\": 0.8}" ```` + Standard openai interface agent-chat Curl test ```shell curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ -d "{\"model\": \"chatglm3-6b\", \"messages\": [{\"role\": \"user\", \"content\": \"37乘以8加7除2等于多少?\"}], "tools": [{"name": "track", "description": "追踪指定股票的实时价格", "parameters": {"type": "object", "properties": {"symbol": {"description": "需要追踪的股票代码"}}, "required": []}}, {"name": "Calculator", "description": "数学计算器,计算数学问题", "parameters": {"type": "object", "properties": {"symbol": {"description": "要计算的数学公式"}}, "required": []}} ], \"stream\": true, \"max_tokens\": 100, \"temperature\": 0.8, \"top_p\": 0.8}" ```` + Openai style custom interface agent-chat Curl test (You need to implement the contents of the custom tool description script openai_api_demo/tools/schema.py, and specify AGENT_CONTROLLER in api_server.py as 'true'): ```shell curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ -d "{\"model\": \"chatglm3-6b\", \"messages\": [{\"role\": \"user\", \"content\": \"37乘以8加7除2等于多少?\"}], \"stream\": true, \"max_tokens\": 100, \"temperature\": 0.8, \"top_p\": 0.8}" ```` This interface is used for autonomous scheduling of OpenAI-style custom toolboxes. It has the ability to self-process and respond to scheduling exceptions, without the need to implement additional scheduling algorithms, and users do not need an api_key. + Testing with Python ```shell cd openai_api_demo python openai_api_request.py ``` If the test is successful, the model should return a story. ### Tool Invocation For methods of tool invocation, please refer to [Tool Invocation](tools_using_demo/README_en.md). ## Low-Cost Deployment ### Model Quantization By default, the model is loaded with FP16 precision, running the above code requires about 13GB of VRAM. If your GPU's VRAM is limited, you can try loading the model quantitatively, as follows: ```python model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).quantize(4).cuda() ``` Model quantization will bring some performance loss. Through testing, ChatGLM3-6B can still perform natural and smooth generation under 4-bit quantization. ### CPU Deployment If you don't have GPU hardware, you can also run inference on the CPU, but the inference speed will be slower. The usage is as follows (requires about 32GB of memory): ```python model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float() ``` ### Mac Deployment For Macs equipped with Apple Silicon or AMD GPUs, the MPS backend can be used to run ChatGLM3-6B on the GPU. Refer to Apple's [official instructions](https://developer.apple.com/metal/pytorch) to install PyTorch-Nightly (the correct version number should be 2.x.x.dev2023xxxx, not 2.x.x). Currently, only [loading the model locally](README_en.md#load-model-locally) is supported on MacOS. Change the model loading in the code to load locally and use the MPS backend: ```python model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps') ``` Loading the half-precision ChatGLM3-6B model requires about 13GB of memory. Machines with smaller memory (such as a 16GB memory MacBook Pro) will use virtual memory on the hard disk when there is insufficient free memory, resulting in a significant slowdown in inference speed. ### Multi-GPU Deployment If you have multiple GPUs, but each GPU's VRAM size is not enough to accommodate the complete model, then the model can be split across multiple GPUs. First, install accelerate: `pip install accelerate`, and then load the model as usual. ### OpenVINO Demo ChatGLM3-6B already supports the use of OpenVINO The toolkit accelerates inference and has a greater inference speed improvement on Intel's GPUs and GPU devices. For specific usage, please refer to [OpenVINO Demo](Intel_device_demo/openvino_demo/README.md). ### TensorRT-LLM Demo ChatGLM3-6B now supports accelerated inference using the TensorRT-LLM toolkit, significantly improving model inference speed. For specific usage, please refer to the [TensorRT-LLM Demo](tensorrt_llm_demo/tensorrt_llm_cli_demo.py) and the official technical documentation. ## Citation If you find our work helpful, please consider citing the following papers. ``` @misc{glm2024chatglm, title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools}, author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang}, year={2024}, eprint={2406.12793}, archivePrefix={arXiv}, primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'} } ```