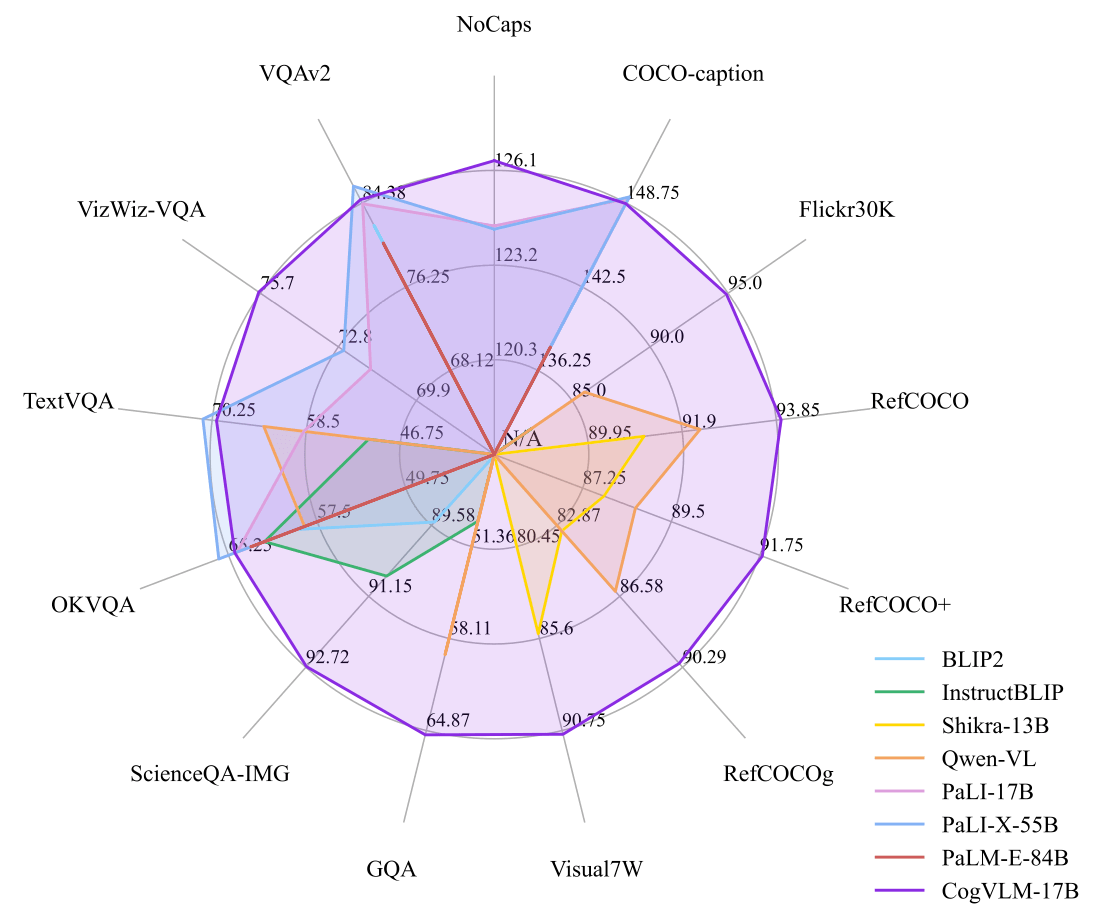
CogVLM📖 Paper: CogVLM: Visual Expert for Pretrained Language Models CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B拥有100亿的视觉参数和70亿的语言参数,支持490*490分辨率的图像理解和多轮对话。 CogVLM-17B 17B在10个经典的跨模态基准测试中取得了最先进的性能包括NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA 和 TDIUC 基准测试。 |
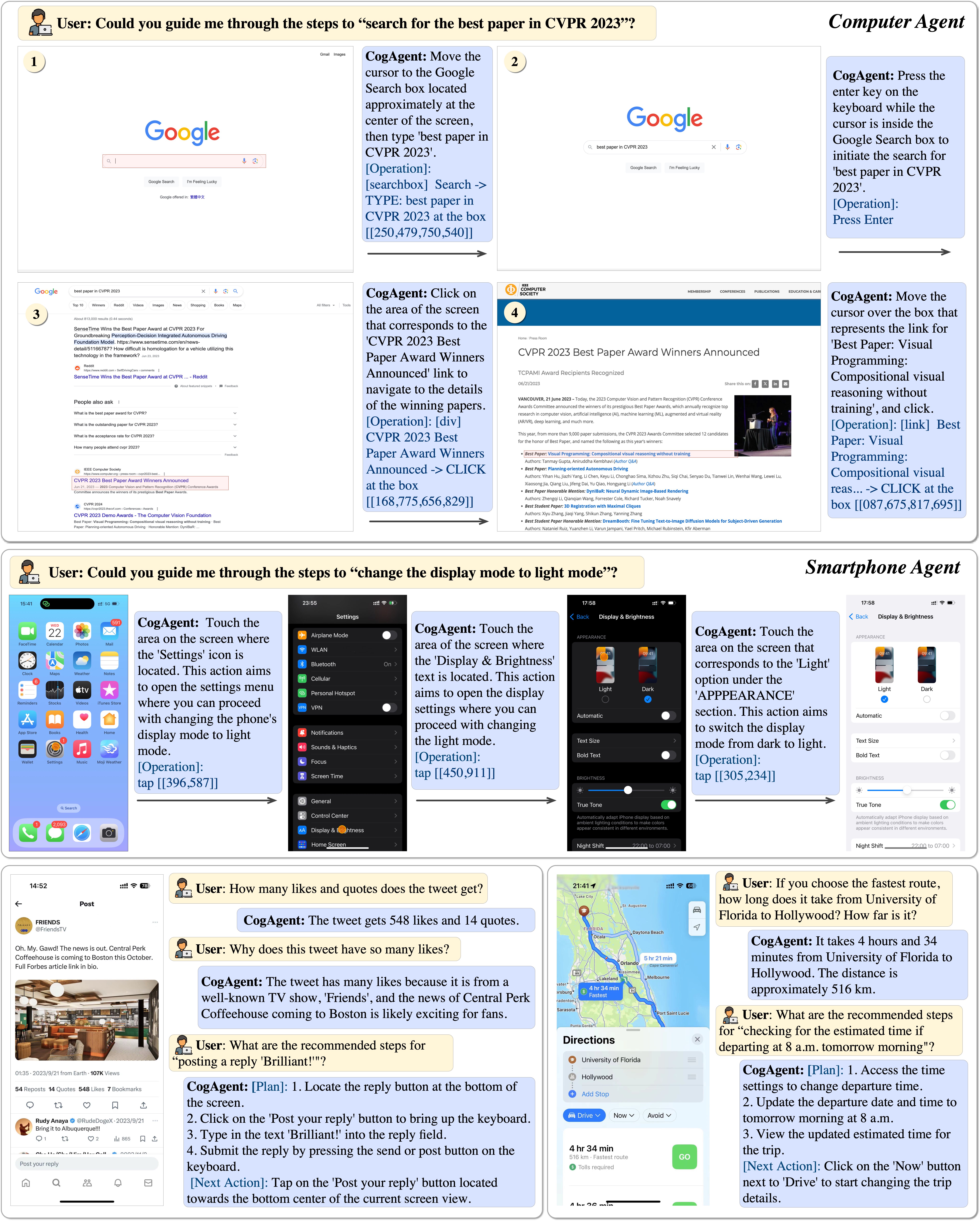
CogAgent📖 Paper: CogAgent: A Visual Language Model for GUI Agents CogAgent 是一个基于CogVLM改进的开源视觉语言模型。CogAgent-18B拥有110亿的视觉参数和70亿的语言参数, 支持1120*1120分辨率的图像理解。在CogVLM的能力之上,它进一步拥有了GUI图像Agent的能力。 CogAgent-18B 在9个经典的跨模态基准测试中实现了最先进的通用性能,包括 VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, 和 POPE 测试基准。它在包括AITW和Mind2Web在内的GUI操作数据集上显著超越了现有的模型。 |
|
🌐 CogVLM2 在线体验: this link |
|
| Method | LLM | MM-VET | POPE(adversarial) | TouchStone |
| BLIP-2 | Vicuna-13B | 22.4 | - | - |
| Otter | MPT-7B | 24.7 | - | - |
| MiniGPT4 | Vicuna-13B | 24.4 | 70.4 | 531.7 |
| InstructBLIP | Vicuna-13B | 25.6 | 77.3 | 552.4 |
| LLaMA-Adapter v2 | LLaMA-7B | 31.4 | - | 590.1 |
| LLaVA | LLaMA2-7B | 28.1 | 66.3 | 602.7 |
| mPLUG-Owl | LLaMA-7B | - | 66.8 | 605.4 |
| LLaVA-1.5 | Vicuna-13B | 36.3 | 84.5 | - |
| Emu | LLaMA-13B | 36.3 | - | - |
| Qwen-VL-Chat | - | - | - | 645.2 |
| DreamLLM | Vicuna-7B | 35.9 | 76.5 | - |
| CogVLM | Vicuna-7B | 52.8 | 87.6 | 742.0 |
| RefCOCO | RefCOCO+ | RefCOCOg | Visual7W | ||||||
| val | testA | testB | val | testA | testB | val | test | test | |
| cogvim-grounding-generalist | 92.51 | 93.95 | 88.73 | 87.52 | 91.81 | 81.43 | 89.46 | 90.09 | 90.96 |
| cogvim-grounding-generalist-v1.1 | **92.76** | **94.75** | **88.99** | **88.68** | **92.91** | **83.39** | **89.75** | **90.79** | **91.05** |