{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "How to create NumPy arrays from scratch?.ipynb",
"provenance": [],
"collapsed_sections": [],
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1eIcaZBmBCw9",
"colab_type": "text"
},
"source": [
"# How to create NumPy arrays from scratch?"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8umW9wPtBFDM",
"colab_type": "text"
},
"source": [
"## This tutorial is all about understanding the NumPy python package and creating NumPy arrays from scratch.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E3w2bM5DBK9g",
"colab_type": "text"
},
"source": [
"Regardless of the data, the first step in analyzing them is transforming them into an array of numbers. The fundamental process of doing data science is efficiently is storing and manipulating numerical arrays. Because of this Python has specialized tools for handling numerical arrays:\n",
"\n",
"\n",
"\n",
"\n",
"1. NumPy Package\n",
"2. Pandas Package\n",
"\n",
"This tutorial only focuses on the NumPy package. However, Pandas package documentation will be provided in the latter days. Let's get started.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DTIm6swbBVy9",
"colab_type": "text"
},
"source": [
"# What is NumPy?\n",
"\n",
"NumPy stands for ***Numerical Python***. NumPy provides an efficient way to store and operate on dense data buffers. With the help of the NumPy library, we can create and operate with arrays to store the data. In some ways, NumPy’s arrays are like Python’s list built-in function.\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xgoajv0pBbSI",
"colab_type": "text"
},
"source": [
"# How to execute NumPy and check its version?\n",
"\n",
"Let’s get started. You can execute the below programs in your favorite python editors like **[PyCharm](https://www.jetbrains.com/pycharm/)**, **[Sublime Text](https://docs.anaconda.com/anaconda/user-guide/tasks/integration/sublime/)**, or Notebooks like **[Jupyter](https://jupyter.org/)** and **[Google Colab](https://colab.research.google.com/notebooks/welcome.ipynb)**. It's basically your preference to choose an IDE of your choice. I am using Google Colab to write my code because it gives me tons of options to provides good documentation. Also, visit the **[NumPy website](https://numpy.org/)** to get more guidelines about the installation process."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5X8X446xB1Ab",
"colab_type": "text"
},
"source": [
"Once you have installed the NumPy on your IDE you need to import it. It’s often a good practice to check the version of the library. So to install the NumPy library you need to use the below code."
]
},
{
"cell_type": "code",
"metadata": {
"id": "2gzE_X5EB1m4",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "04aa8896-481d-4416-e718-7ecd00568121"
},
"source": [
"import numpy\n",
"print(numpy.__version__)"
],
"execution_count": 1,
"outputs": [
{
"output_type": "stream",
"text": [
"1.17.4\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dxE6okLhB7Ni",
"colab_type": "text"
},
"source": [
"Just make sure that you the latest NumPy version to use all the features and options. Rather than using ***“numpy”*** we can use an alias as ***“np”***. This is called ***“Aliasing”***. Now the point of using an alias is we can use ***“np”*** rather ***“numpy”*** which is long to type every time when we use its methods. So creating an alias and checking the version can be done as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "dTkeJvNpCFki",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "3f809977-a13d-4bae-b690-658bd0f8f24b"
},
"source": [
"import numpy as np\n",
"print(np.__version__)"
],
"execution_count": 2,
"outputs": [
{
"output_type": "stream",
"text": [
"1.17.4\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "koAuX4c_CIPh",
"colab_type": "text"
},
"source": [
"From now on we can use “np” rather than “numpy” every time.\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9U57ZwsWCKLE",
"colab_type": "text"
},
"source": [
"## Why Numpy arrays came into the picture when there were python’s fixed type arrays?\n",
"\n",
"Python provides several different options for storing efficient, fixed-type data. Python has a built-in array module called “array” which is used to create arrays of uniform type. This was its main disadvantage."
]
},
{
"cell_type": "code",
"metadata": {
"id": "nilhob0YCOA_",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "63365b95-f1ec-442a-e1a1-64cb0ca3611d"
},
"source": [
"import array\n",
"# Creating an array\n",
"print(array.array('i', [1, 2, 3, 4, 5]))"
],
"execution_count": 3,
"outputs": [
{
"output_type": "stream",
"text": [
"array('i', [1, 2, 3, 4, 5])\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "lSzHhTj8CQGq",
"colab_type": "text"
},
"source": [
"The ***“i”*** here indicates the integer data. We cannot try to store other types of data in the array module. It often leads to an error."
]
},
{
"cell_type": "code",
"metadata": {
"id": "-U_dSfnOCWk0",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"outputId": "9df81810-4515-4434-b90d-cdee82968105"
},
"source": [
"import array\n",
"# Creating an array\n",
"print(array.array('i', [1, 2.0, 3, 4, 5]))"
],
"execution_count": 4,
"outputs": [
{
"output_type": "error",
"ename": "TypeError",
"evalue": "ignored",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0marray\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0;31m# Creating an array\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 3\u001b[0;31m \u001b[0mprint\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0marray\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0marray\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'i'\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m2.0\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m3\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m4\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m5\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m: integer argument expected, got float"
]
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8dETngFMCZHx",
"colab_type": "text"
},
"source": [
"However, Python’s array module provides efficient storage of array-based data. But NumPy arrays can perform efficient operations on that type of data. There are two ways that we can create NumPy arrays:\n",
"\n",
"\n",
"\n",
"1. Creating a NumPy array from Python Lists\n",
"2. Creating a NumPy array from scratch\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sME6AIUfCfPS",
"colab_type": "text"
},
"source": [
"# Creating a NumPy array from Python Lists\n",
"\n",
"We can use [**np.array**](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html) method to create arrays from python lists.\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "WrTlWGo7CpTD",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "6f4c78af-d082-432a-f320-f4f037355bee"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"print(type(a))"
],
"execution_count": 5,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "DSvQFYClCqr9",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "c94ed53d-6796-4f98-f113-e118eb2ba4cb"
},
"source": [
"# Creating a numpy array from the list\n",
"print(np.array(a))"
],
"execution_count": 6,
"outputs": [
{
"output_type": "stream",
"text": [
"[1 2 3 4 5]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "eL57ZGr2CsMs",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "0df56f26-4e49-4048-8c9d-72f41eb6fa55"
},
"source": [
"print(type(np.array(a)))"
],
"execution_count": 8,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NZkeIpZDCykV",
"colab_type": "text"
},
"source": [
"The NumPy library is limited to arrays with the same type, if there is a type mismatch then it would upcast if possible. Consider the below example:\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "L3idoUotC0Da",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "109eda44-7408-40b1-8207-afecf60d65ca"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2.0, 3, 4, 5]\n",
"print(type(a))"
],
"execution_count": 9,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "QA6_HdRiC4hz",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "502f90cc-71a6-466e-a5c3-fa0e39abd0b4"
},
"source": [
"# Creating a numpy array from the list\n",
"print(np.array(a))"
],
"execution_count": 10,
"outputs": [
{
"output_type": "stream",
"text": [
"[1. 2. 3. 4. 5.]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "maBixb3hC67m",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "7db51b83-00d1-489c-8de0-f2997f34c115"
},
"source": [
"print(type(np.array(a)))"
],
"execution_count": 11,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NmmBVcmHC9Ut",
"colab_type": "text"
},
"source": [
"So the original list was integers with one floating value but the numpy array upcasted it to all ***floating-point*** numbers. The integers are upcasted to floating-point numbers. Below is a small diagram that gives you enough knowledge to understand the upcast and downcast.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "w_8mpSnTDBTk",
"colab_type": "text"
},
"source": [
"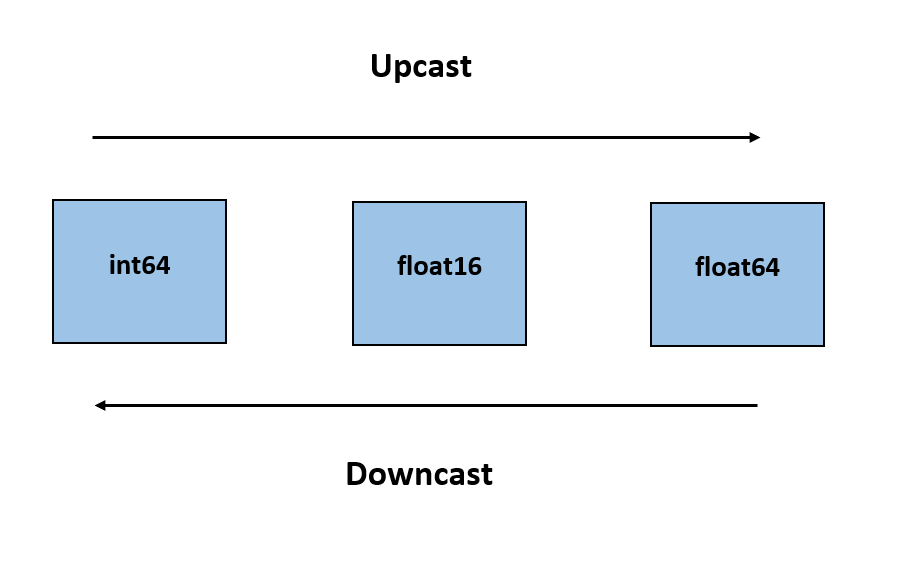\n",
"\n",
"Also explicitly setting the data type is also possible. This can be done using the keyword ***“dtype”***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "ManDdfTODQFG",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "dfcc0ecd-d68c-49f2-e117-883c999346eb"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"# Creating a numpy array from the list\n",
"np.array(a, dtype='float64')\n",
"print(np.array(a, dtype='float64'))"
],
"execution_count": 12,
"outputs": [
{
"output_type": "stream",
"text": [
"[1. 2. 3. 4. 5.]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1k4cfg4rDSu8",
"colab_type": "text"
},
"source": [
"As seen from the above example, the integer type list data is converted into the float type data by using the ***“dtype”*** keyword.\n",
"Numpy arrays can also be ***multidimensional*** (Array within an array). Here’s one way of doing it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "PQIMjA-VDXqU",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 104
},
"outputId": "6f2a624e-1e60-4093-b54f-1728ccdb51d9"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"# Creating a numpy array from the list\n",
"np.array([range(i, i + 4) for i in a])"
],
"execution_count": 13,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"array([[1, 2, 3, 4],\n",
" [2, 3, 4, 5],\n",
" [3, 4, 5, 6],\n",
" [4, 5, 6, 7],\n",
" [5, 6, 7, 8]])"
]
},
"metadata": {
"tags": []
},
"execution_count": 13
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vMRgNhcoDZla",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"> **Hint**: *Just increment the “i” value in terms of 1 (i+1, 2, 3, 4, …) by doing so you can increase the dimension of the array too. The above array is treated as 2D — Array.*\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iAHYsgnJDgJ5",
"colab_type": "text"
},
"source": [
"# Creating a NumPy array from scratch\n",
"\n",
"Numpy arrays are actually used for creating larger arrays. It is more efficient to create large arrays from scratch using the numpy package library. Below are some of the examples of creating numpy arrays from scratch.\n",
"\n",
"## Creating an array filled with zeros of length 5\n",
"\n",
"\n",
"\n",
"\n",
"We can do this using the numpy built-in method called zeros as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "I2aW181pDrS5",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "734428d9-cb4e-44cd-f9c7-58ecb6f03615"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of zeros of length 5\n",
"print(np.zeros(5, dtype='int'))"
],
"execution_count": 14,
"outputs": [
{
"output_type": "stream",
"text": [
"[0 0 0 0 0]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Z4p6TLcyDtRh",
"colab_type": "text"
},
"source": [
"There are some standard numpy data types available. I cannot just discuss all of them in one stretch. Most of them are never used. So I will be providing the data types of numpy array in the form of a chart below just use that accordingly. If you don't know how to use the datatypes refer to **Explicitly changing the array datatypes** above its → ***dtypes = “name of the datatype”***\n",
"\n",
"\n",
"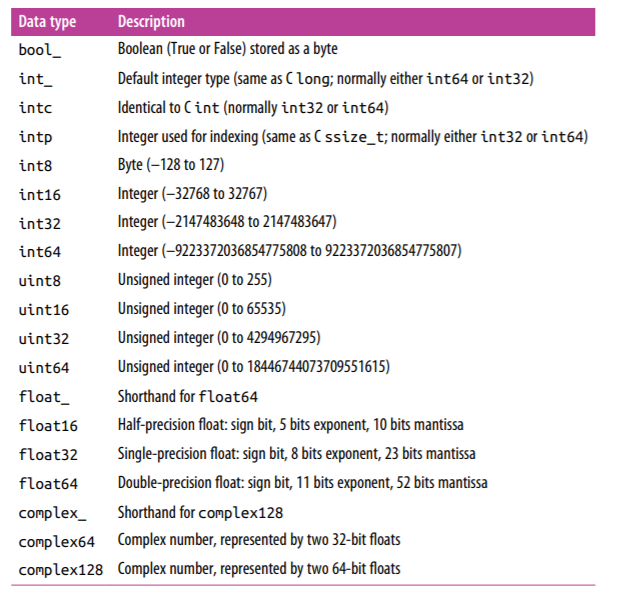\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cViijEL5D4Wb",
"colab_type": "text"
},
"source": [
"## Creating a 3 x 4 array filled with 1's\n",
"\n",
"Thanks to NumPy because we don’t have to put the array inside a looping statement (I hate to do that ;)). All you have to do is just mention the rows and the columns that you want your array to have inside the numpy.one method."
]
},
{
"cell_type": "code",
"metadata": {
"id": "QX68ptI2D9WP",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "28c701bc-fe22-42bb-d340-09a9ff123851"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of 1’s which should have 3 rows and 4 columns\n",
"print(np.ones((3, 4)))"
],
"execution_count": 15,
"outputs": [
{
"output_type": "stream",
"text": [
"[[1. 1. 1. 1.]\n",
" [1. 1. 1. 1.]\n",
" [1. 1. 1. 1.]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Zwgd4XtZD_q6",
"colab_type": "text"
},
"source": [
"So the number 3 → rows and 4 → obviously columns.\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JKo--ncJEA1B",
"colab_type": "text"
},
"source": [
"## Filling the numpy arrays with a particular number\n",
"\n",
"Till now we have seen filling the array with 0’s and 1’s but we should also know that numpy allows us to fill the arrays with any specific number of our choice. We can do this with the help of ***numpy.full*** method. For example, let us fill the array with the number **500**."
]
},
{
"cell_type": "code",
"metadata": {
"id": "dqMXs6DXEHp6",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "1417a49c-081a-479c-862d-fd5bd7f5d173"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of 500’s which should have 3 rows and 4 columns\n",
"print(np.full((3, 4), 500))"
],
"execution_count": 16,
"outputs": [
{
"output_type": "stream",
"text": [
"[[500 500 500 500]\n",
" [500 500 500 500]\n",
" [500 500 500 500]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JteQ6KRwEJOg",
"colab_type": "text"
},
"source": [
"With the help of the full method, we can add any number of our choice to our array.\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YjFfpiCbELXh",
"colab_type": "text"
},
"source": [
"## Creating a numpy array of random numbers\n",
"\n",
"***Uniform distribution →*** It is a probability distribution in which all the outcomes are equally likely. For example, tossing a coin has the probability of uniform distribution because the outcomes are a most likely head or a tail. It’s never going to be both at the same time.\n",
"The NumPy package library provides us a uniform distribution method to generate random numbers called ***numpy.random.uniform***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "PP_fiTUJETa7",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "1402fb40-8024-4075-a1e9-2247c2516830"
},
"source": [
"import numpy as np\n",
"# Create a 3x3 array of uniformly distributed \n",
"# random values between 0 and 1\n",
"print(np.random.random((3, 3)))"
],
"execution_count": 17,
"outputs": [
{
"output_type": "stream",
"text": [
"[[0.40583433 0.0190693 0.38431019]\n",
" [0.75331671 0.73285968 0.17811633]\n",
" [0.14079855 0.3221451 0.33576759]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fxJ3pdtHEVd2",
"colab_type": "text"
},
"source": [
"Also, the numpy package library has a seed generator along with the random number generator, with the help of the seed method we can control the sequence of the random numbers being generated. Most of them don’t know the specialty of the seed method and its purpose. To know more about the seed method refer below."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FvxENEqAEW8I",
"colab_type": "text"
},
"source": [
"## Why do we need “seed” inside the random number generator?\n",
"If we use the seed every time then we get the same sequence of random numbers.\n",
"\n",
"\n",
"\n",
"\n",
"> So, the same seed yields the same sequence of random numbers.\n",
"\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "s-tQmE-NEcub",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "2bdd6fcc-f8bf-429c-8f39-d203419e72c2"
},
"source": [
"import numpy as np\n",
"# Create a random number arrays of size 5\n",
"np.random.seed(0)\n",
"print(np.random.random(5))"
],
"execution_count": 18,
"outputs": [
{
"output_type": "stream",
"text": [
"[0.5488135 0.71518937 0.60276338 0.54488318 0.4236548 ]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4FuBx_StEepm",
"colab_type": "text"
},
"source": [
"No matter how many times you execute the above code you get the same random numbers every time. To know the difference just comment on the code (#) and then see the difference. Let us explore the seed method to a bit more extent.\n",
"For example, if you use seed(1) and then generate some random numbers they will be the same with the ones you generate later on but with the same seed (1) as shown below."
]
},
{
"cell_type": "code",
"metadata": {
"id": "aUKV6m8UEgDQ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 52
},
"outputId": "50a047f5-950d-4241-f1f8-a75a94dcb2b3"
},
"source": [
"import numpy as np\n",
"# Create a random number arrays of size 5\n",
"np.random.seed(1)\n",
"print(np.random.random(5))"
],
"execution_count": 19,
"outputs": [
{
"output_type": "stream",
"text": [
"[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-01\n",
" 1.46755891e-01]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "9cB9gf7TEhfJ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "6f770e9e-fc55-48a0-d55e-d165b41c9bcb"
},
"source": [
"print(np.random.random(5))"
],
"execution_count": 20,
"outputs": [
{
"output_type": "stream",
"text": [
"[0.09233859 0.18626021 0.34556073 0.39676747 0.53881673]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "sBr8xovdEkwV",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 52
},
"outputId": "a8d829c3-e9f5-470a-f86e-41bdbfd0022c"
},
"source": [
"np.random.seed(1)\n",
"print(np.random.random(5))"
],
"execution_count": 21,
"outputs": [
{
"output_type": "stream",
"text": [
"[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-01\n",
" 1.46755891e-01]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hIRHC1tlEmxL",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"> ***Same seed same random numbers ensure “Reproducibility”*** — [Quora.com](https://www.quora.com/What-is-seed-in-random-number-generation)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qhbrb5w2Exqj",
"colab_type": "text"
},
"source": [
"Also, the range of the seed is from 0 and 2**32–1. Don’t just use negative numbers as the seed value, if you do so you will get an error as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "JWkvdQV4E9Ok",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 287
},
"outputId": "5fbdafa0-e3a3-4322-bae9-e803172d8d00"
},
"source": [
"import numpy as np\n",
"np.random.seed(-1)"
],
"execution_count": 22,
"outputs": [
{
"output_type": "error",
"ename": "ValueError",
"evalue": "ignored",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mnumpy\u001b[0m \u001b[0;32mas\u001b[0m \u001b[0mnp\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 2\u001b[0;31m \u001b[0mnp\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mrandom\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mseed\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;32mmtrand.pyx\u001b[0m in \u001b[0;36mnumpy.random.mtrand.RandomState.seed\u001b[0;34m()\u001b[0m\n",
"\u001b[0;32mmt19937.pyx\u001b[0m in \u001b[0;36mnumpy.random.mt19937.MT19937._legacy_seeding\u001b[0;34m()\u001b[0m\n",
"\u001b[0;32mmt19937.pyx\u001b[0m in \u001b[0;36mnumpy.random.mt19937.MT19937._legacy_seeding\u001b[0;34m()\u001b[0m\n",
"\u001b[0;31mValueError\u001b[0m: Seed must be between 0 and 2**32 - 1"
]
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tLdjquIeFBEM",
"colab_type": "text"
},
"source": [
"***Normal Distribution →*** Is Also known as the Gaussian Distribution, a continuous probability distribution for a real-valued random variable. It is also known as a ***symmetric distribution*** where most of the values cluster at the center of the peak. The standard deviation determines the spread.\n",
"\n",
"\n",
"The NumPy package library provides us a uniform distribution method to generate random numbers called ***numpy.random.normal***. The syntax is almost the same as the uniform distribution but you need to add two more vital data here known as the ***mean*** and the ***standard deviation***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "xYDNbvr3FLq6",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "3b5483b7-f25e-45e0-e3a0-1c2e4971487e"
},
"source": [
"import numpy as np\n",
"# Create a 3x3 array of normally distributed random values\n",
"# with mean 0 and standard deviation 1\n",
"print(np.random.normal(0, 1, (3, 3)))"
],
"execution_count": 23,
"outputs": [
{
"output_type": "stream",
"text": [
"[[-1.10593508 -1.65451545 -2.3634686 ]\n",
" [ 1.13534535 -1.01701414 0.63736181]\n",
" [-0.85990661 1.77260763 -1.11036305]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Y1y9eg95FNKt",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_fL6oUdAFOuG",
"colab_type": "text"
},
"source": [
"## Creating an identity matrix using numpy array\n",
"\n",
"An identity matrix is a matrix where the principal diagonal elements are 1 and the other elements except the principal diagonal elements are 0. The numpy package library provides a method to generate an identity matrix called the eye. An identity matrix is a square matrix meaning it has equal rows and columns."
]
},
{
"cell_type": "code",
"metadata": {
"id": "qlsKW04vFRzc",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 87
},
"outputId": "c2fcb418-37f7-42d8-f22b-19d347aabe73"
},
"source": [
"import numpy as np\n",
"# Create a identity matrix of 4 rows and 4 columns\n",
"print(np.eye(4))"
],
"execution_count": 24,
"outputs": [
{
"output_type": "stream",
"text": [
"[[1. 0. 0. 0.]\n",
" [0. 1. 0. 0.]\n",
" [0. 0. 1. 0.]\n",
" [0. 0. 0. 1.]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7-vAtP-uFTec",
"colab_type": "text"
},
"source": [
"The number 4 represents the rows and columns since it is a square matrix we only need to specify the value once (4 in this case).\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1LtTKX6EFWLc",
"colab_type": "text"
},
"source": [
"This is the end of this tutorial “[How to create NumPy arrays from scratch?](https://towardsdatascience.com/how-to-create-numpy-arrays-from-scratch-3e0341f9ffea)”, this is just the introductory tutorial for NumPy Package library. However, much more complex concepts of the NumPy package library will be discussed in the upcoming tutorials. Thank you guys for spending your time reading my tutorial. I hope you enjoyed it. If you have any doubts related to NumPy, then the comment section is all yours. Until then Goodbye, See you have a good day."
]
}
]
}
"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1eIcaZBmBCw9",
"colab_type": "text"
},
"source": [
"# How to create NumPy arrays from scratch?"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8umW9wPtBFDM",
"colab_type": "text"
},
"source": [
"## This tutorial is all about understanding the NumPy python package and creating NumPy arrays from scratch.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E3w2bM5DBK9g",
"colab_type": "text"
},
"source": [
"Regardless of the data, the first step in analyzing them is transforming them into an array of numbers. The fundamental process of doing data science is efficiently is storing and manipulating numerical arrays. Because of this Python has specialized tools for handling numerical arrays:\n",
"\n",
"\n",
"\n",
"\n",
"1. NumPy Package\n",
"2. Pandas Package\n",
"\n",
"This tutorial only focuses on the NumPy package. However, Pandas package documentation will be provided in the latter days. Let's get started.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DTIm6swbBVy9",
"colab_type": "text"
},
"source": [
"# What is NumPy?\n",
"\n",
"NumPy stands for ***Numerical Python***. NumPy provides an efficient way to store and operate on dense data buffers. With the help of the NumPy library, we can create and operate with arrays to store the data. In some ways, NumPy’s arrays are like Python’s list built-in function.\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xgoajv0pBbSI",
"colab_type": "text"
},
"source": [
"# How to execute NumPy and check its version?\n",
"\n",
"Let’s get started. You can execute the below programs in your favorite python editors like **[PyCharm](https://www.jetbrains.com/pycharm/)**, **[Sublime Text](https://docs.anaconda.com/anaconda/user-guide/tasks/integration/sublime/)**, or Notebooks like **[Jupyter](https://jupyter.org/)** and **[Google Colab](https://colab.research.google.com/notebooks/welcome.ipynb)**. It's basically your preference to choose an IDE of your choice. I am using Google Colab to write my code because it gives me tons of options to provides good documentation. Also, visit the **[NumPy website](https://numpy.org/)** to get more guidelines about the installation process."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5X8X446xB1Ab",
"colab_type": "text"
},
"source": [
"Once you have installed the NumPy on your IDE you need to import it. It’s often a good practice to check the version of the library. So to install the NumPy library you need to use the below code."
]
},
{
"cell_type": "code",
"metadata": {
"id": "2gzE_X5EB1m4",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "04aa8896-481d-4416-e718-7ecd00568121"
},
"source": [
"import numpy\n",
"print(numpy.__version__)"
],
"execution_count": 1,
"outputs": [
{
"output_type": "stream",
"text": [
"1.17.4\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dxE6okLhB7Ni",
"colab_type": "text"
},
"source": [
"Just make sure that you the latest NumPy version to use all the features and options. Rather than using ***“numpy”*** we can use an alias as ***“np”***. This is called ***“Aliasing”***. Now the point of using an alias is we can use ***“np”*** rather ***“numpy”*** which is long to type every time when we use its methods. So creating an alias and checking the version can be done as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "dTkeJvNpCFki",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "3f809977-a13d-4bae-b690-658bd0f8f24b"
},
"source": [
"import numpy as np\n",
"print(np.__version__)"
],
"execution_count": 2,
"outputs": [
{
"output_type": "stream",
"text": [
"1.17.4\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "koAuX4c_CIPh",
"colab_type": "text"
},
"source": [
"From now on we can use “np” rather than “numpy” every time.\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9U57ZwsWCKLE",
"colab_type": "text"
},
"source": [
"## Why Numpy arrays came into the picture when there were python’s fixed type arrays?\n",
"\n",
"Python provides several different options for storing efficient, fixed-type data. Python has a built-in array module called “array” which is used to create arrays of uniform type. This was its main disadvantage."
]
},
{
"cell_type": "code",
"metadata": {
"id": "nilhob0YCOA_",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "63365b95-f1ec-442a-e1a1-64cb0ca3611d"
},
"source": [
"import array\n",
"# Creating an array\n",
"print(array.array('i', [1, 2, 3, 4, 5]))"
],
"execution_count": 3,
"outputs": [
{
"output_type": "stream",
"text": [
"array('i', [1, 2, 3, 4, 5])\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "lSzHhTj8CQGq",
"colab_type": "text"
},
"source": [
"The ***“i”*** here indicates the integer data. We cannot try to store other types of data in the array module. It often leads to an error."
]
},
{
"cell_type": "code",
"metadata": {
"id": "-U_dSfnOCWk0",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"outputId": "9df81810-4515-4434-b90d-cdee82968105"
},
"source": [
"import array\n",
"# Creating an array\n",
"print(array.array('i', [1, 2.0, 3, 4, 5]))"
],
"execution_count": 4,
"outputs": [
{
"output_type": "error",
"ename": "TypeError",
"evalue": "ignored",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0marray\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0;31m# Creating an array\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 3\u001b[0;31m \u001b[0mprint\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0marray\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0marray\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'i'\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m2.0\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m3\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m4\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m5\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m: integer argument expected, got float"
]
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8dETngFMCZHx",
"colab_type": "text"
},
"source": [
"However, Python’s array module provides efficient storage of array-based data. But NumPy arrays can perform efficient operations on that type of data. There are two ways that we can create NumPy arrays:\n",
"\n",
"\n",
"\n",
"1. Creating a NumPy array from Python Lists\n",
"2. Creating a NumPy array from scratch\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sME6AIUfCfPS",
"colab_type": "text"
},
"source": [
"# Creating a NumPy array from Python Lists\n",
"\n",
"We can use [**np.array**](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html) method to create arrays from python lists.\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "WrTlWGo7CpTD",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "6f4c78af-d082-432a-f320-f4f037355bee"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"print(type(a))"
],
"execution_count": 5,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "DSvQFYClCqr9",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "c94ed53d-6796-4f98-f113-e118eb2ba4cb"
},
"source": [
"# Creating a numpy array from the list\n",
"print(np.array(a))"
],
"execution_count": 6,
"outputs": [
{
"output_type": "stream",
"text": [
"[1 2 3 4 5]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "eL57ZGr2CsMs",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "0df56f26-4e49-4048-8c9d-72f41eb6fa55"
},
"source": [
"print(type(np.array(a)))"
],
"execution_count": 8,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NZkeIpZDCykV",
"colab_type": "text"
},
"source": [
"The NumPy library is limited to arrays with the same type, if there is a type mismatch then it would upcast if possible. Consider the below example:\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "L3idoUotC0Da",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "109eda44-7408-40b1-8207-afecf60d65ca"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2.0, 3, 4, 5]\n",
"print(type(a))"
],
"execution_count": 9,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "QA6_HdRiC4hz",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "502f90cc-71a6-466e-a5c3-fa0e39abd0b4"
},
"source": [
"# Creating a numpy array from the list\n",
"print(np.array(a))"
],
"execution_count": 10,
"outputs": [
{
"output_type": "stream",
"text": [
"[1. 2. 3. 4. 5.]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "maBixb3hC67m",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "7db51b83-00d1-489c-8de0-f2997f34c115"
},
"source": [
"print(type(np.array(a)))"
],
"execution_count": 11,
"outputs": [
{
"output_type": "stream",
"text": [
"\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NmmBVcmHC9Ut",
"colab_type": "text"
},
"source": [
"So the original list was integers with one floating value but the numpy array upcasted it to all ***floating-point*** numbers. The integers are upcasted to floating-point numbers. Below is a small diagram that gives you enough knowledge to understand the upcast and downcast.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "w_8mpSnTDBTk",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"Also explicitly setting the data type is also possible. This can be done using the keyword ***“dtype”***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "ManDdfTODQFG",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "dfcc0ecd-d68c-49f2-e117-883c999346eb"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"# Creating a numpy array from the list\n",
"np.array(a, dtype='float64')\n",
"print(np.array(a, dtype='float64'))"
],
"execution_count": 12,
"outputs": [
{
"output_type": "stream",
"text": [
"[1. 2. 3. 4. 5.]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1k4cfg4rDSu8",
"colab_type": "text"
},
"source": [
"As seen from the above example, the integer type list data is converted into the float type data by using the ***“dtype”*** keyword.\n",
"Numpy arrays can also be ***multidimensional*** (Array within an array). Here’s one way of doing it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "PQIMjA-VDXqU",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 104
},
"outputId": "6f2a624e-1e60-4093-b54f-1728ccdb51d9"
},
"source": [
"import numpy as np\n",
"# Creating a list named \"a\"\n",
"a = [1, 2, 3, 4, 5]\n",
"# Creating a numpy array from the list\n",
"np.array([range(i, i + 4) for i in a])"
],
"execution_count": 13,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"array([[1, 2, 3, 4],\n",
" [2, 3, 4, 5],\n",
" [3, 4, 5, 6],\n",
" [4, 5, 6, 7],\n",
" [5, 6, 7, 8]])"
]
},
"metadata": {
"tags": []
},
"execution_count": 13
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vMRgNhcoDZla",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"> **Hint**: *Just increment the “i” value in terms of 1 (i+1, 2, 3, 4, …) by doing so you can increase the dimension of the array too. The above array is treated as 2D — Array.*\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iAHYsgnJDgJ5",
"colab_type": "text"
},
"source": [
"# Creating a NumPy array from scratch\n",
"\n",
"Numpy arrays are actually used for creating larger arrays. It is more efficient to create large arrays from scratch using the numpy package library. Below are some of the examples of creating numpy arrays from scratch.\n",
"\n",
"## Creating an array filled with zeros of length 5\n",
"\n",
"\n",
"\n",
"\n",
"We can do this using the numpy built-in method called zeros as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "I2aW181pDrS5",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "734428d9-cb4e-44cd-f9c7-58ecb6f03615"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of zeros of length 5\n",
"print(np.zeros(5, dtype='int'))"
],
"execution_count": 14,
"outputs": [
{
"output_type": "stream",
"text": [
"[0 0 0 0 0]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Z4p6TLcyDtRh",
"colab_type": "text"
},
"source": [
"There are some standard numpy data types available. I cannot just discuss all of them in one stretch. Most of them are never used. So I will be providing the data types of numpy array in the form of a chart below just use that accordingly. If you don't know how to use the datatypes refer to **Explicitly changing the array datatypes** above its → ***dtypes = “name of the datatype”***\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cViijEL5D4Wb",
"colab_type": "text"
},
"source": [
"## Creating a 3 x 4 array filled with 1's\n",
"\n",
"Thanks to NumPy because we don’t have to put the array inside a looping statement (I hate to do that ;)). All you have to do is just mention the rows and the columns that you want your array to have inside the numpy.one method."
]
},
{
"cell_type": "code",
"metadata": {
"id": "QX68ptI2D9WP",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "28c701bc-fe22-42bb-d340-09a9ff123851"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of 1’s which should have 3 rows and 4 columns\n",
"print(np.ones((3, 4)))"
],
"execution_count": 15,
"outputs": [
{
"output_type": "stream",
"text": [
"[[1. 1. 1. 1.]\n",
" [1. 1. 1. 1.]\n",
" [1. 1. 1. 1.]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Zwgd4XtZD_q6",
"colab_type": "text"
},
"source": [
"So the number 3 → rows and 4 → obviously columns.\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JKo--ncJEA1B",
"colab_type": "text"
},
"source": [
"## Filling the numpy arrays with a particular number\n",
"\n",
"Till now we have seen filling the array with 0’s and 1’s but we should also know that numpy allows us to fill the arrays with any specific number of our choice. We can do this with the help of ***numpy.full*** method. For example, let us fill the array with the number **500**."
]
},
{
"cell_type": "code",
"metadata": {
"id": "dqMXs6DXEHp6",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "1417a49c-081a-479c-862d-fd5bd7f5d173"
},
"source": [
"import numpy as np\n",
"# Creating a numpy array of 500’s which should have 3 rows and 4 columns\n",
"print(np.full((3, 4), 500))"
],
"execution_count": 16,
"outputs": [
{
"output_type": "stream",
"text": [
"[[500 500 500 500]\n",
" [500 500 500 500]\n",
" [500 500 500 500]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JteQ6KRwEJOg",
"colab_type": "text"
},
"source": [
"With the help of the full method, we can add any number of our choice to our array.\n",
"\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YjFfpiCbELXh",
"colab_type": "text"
},
"source": [
"## Creating a numpy array of random numbers\n",
"\n",
"***Uniform distribution →*** It is a probability distribution in which all the outcomes are equally likely. For example, tossing a coin has the probability of uniform distribution because the outcomes are a most likely head or a tail. It’s never going to be both at the same time.\n",
"The NumPy package library provides us a uniform distribution method to generate random numbers called ***numpy.random.uniform***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "PP_fiTUJETa7",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "1402fb40-8024-4075-a1e9-2247c2516830"
},
"source": [
"import numpy as np\n",
"# Create a 3x3 array of uniformly distributed \n",
"# random values between 0 and 1\n",
"print(np.random.random((3, 3)))"
],
"execution_count": 17,
"outputs": [
{
"output_type": "stream",
"text": [
"[[0.40583433 0.0190693 0.38431019]\n",
" [0.75331671 0.73285968 0.17811633]\n",
" [0.14079855 0.3221451 0.33576759]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fxJ3pdtHEVd2",
"colab_type": "text"
},
"source": [
"Also, the numpy package library has a seed generator along with the random number generator, with the help of the seed method we can control the sequence of the random numbers being generated. Most of them don’t know the specialty of the seed method and its purpose. To know more about the seed method refer below."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FvxENEqAEW8I",
"colab_type": "text"
},
"source": [
"## Why do we need “seed” inside the random number generator?\n",
"If we use the seed every time then we get the same sequence of random numbers.\n",
"\n",
"\n",
"\n",
"\n",
"> So, the same seed yields the same sequence of random numbers.\n",
"\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "s-tQmE-NEcub",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "2bdd6fcc-f8bf-429c-8f39-d203419e72c2"
},
"source": [
"import numpy as np\n",
"# Create a random number arrays of size 5\n",
"np.random.seed(0)\n",
"print(np.random.random(5))"
],
"execution_count": 18,
"outputs": [
{
"output_type": "stream",
"text": [
"[0.5488135 0.71518937 0.60276338 0.54488318 0.4236548 ]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4FuBx_StEepm",
"colab_type": "text"
},
"source": [
"No matter how many times you execute the above code you get the same random numbers every time. To know the difference just comment on the code (#) and then see the difference. Let us explore the seed method to a bit more extent.\n",
"For example, if you use seed(1) and then generate some random numbers they will be the same with the ones you generate later on but with the same seed (1) as shown below."
]
},
{
"cell_type": "code",
"metadata": {
"id": "aUKV6m8UEgDQ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 52
},
"outputId": "50a047f5-950d-4241-f1f8-a75a94dcb2b3"
},
"source": [
"import numpy as np\n",
"# Create a random number arrays of size 5\n",
"np.random.seed(1)\n",
"print(np.random.random(5))"
],
"execution_count": 19,
"outputs": [
{
"output_type": "stream",
"text": [
"[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-01\n",
" 1.46755891e-01]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "9cB9gf7TEhfJ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 35
},
"outputId": "6f770e9e-fc55-48a0-d55e-d165b41c9bcb"
},
"source": [
"print(np.random.random(5))"
],
"execution_count": 20,
"outputs": [
{
"output_type": "stream",
"text": [
"[0.09233859 0.18626021 0.34556073 0.39676747 0.53881673]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "sBr8xovdEkwV",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 52
},
"outputId": "a8d829c3-e9f5-470a-f86e-41bdbfd0022c"
},
"source": [
"np.random.seed(1)\n",
"print(np.random.random(5))"
],
"execution_count": 21,
"outputs": [
{
"output_type": "stream",
"text": [
"[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-01\n",
" 1.46755891e-01]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hIRHC1tlEmxL",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"> ***Same seed same random numbers ensure “Reproducibility”*** — [Quora.com](https://www.quora.com/What-is-seed-in-random-number-generation)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qhbrb5w2Exqj",
"colab_type": "text"
},
"source": [
"Also, the range of the seed is from 0 and 2**32–1. Don’t just use negative numbers as the seed value, if you do so you will get an error as shown below:"
]
},
{
"cell_type": "code",
"metadata": {
"id": "JWkvdQV4E9Ok",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 287
},
"outputId": "5fbdafa0-e3a3-4322-bae9-e803172d8d00"
},
"source": [
"import numpy as np\n",
"np.random.seed(-1)"
],
"execution_count": 22,
"outputs": [
{
"output_type": "error",
"ename": "ValueError",
"evalue": "ignored",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mnumpy\u001b[0m \u001b[0;32mas\u001b[0m \u001b[0mnp\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 2\u001b[0;31m \u001b[0mnp\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mrandom\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mseed\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;32mmtrand.pyx\u001b[0m in \u001b[0;36mnumpy.random.mtrand.RandomState.seed\u001b[0;34m()\u001b[0m\n",
"\u001b[0;32mmt19937.pyx\u001b[0m in \u001b[0;36mnumpy.random.mt19937.MT19937._legacy_seeding\u001b[0;34m()\u001b[0m\n",
"\u001b[0;32mmt19937.pyx\u001b[0m in \u001b[0;36mnumpy.random.mt19937.MT19937._legacy_seeding\u001b[0;34m()\u001b[0m\n",
"\u001b[0;31mValueError\u001b[0m: Seed must be between 0 and 2**32 - 1"
]
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tLdjquIeFBEM",
"colab_type": "text"
},
"source": [
"***Normal Distribution →*** Is Also known as the Gaussian Distribution, a continuous probability distribution for a real-valued random variable. It is also known as a ***symmetric distribution*** where most of the values cluster at the center of the peak. The standard deviation determines the spread.\n",
"\n",
"\n",
"The NumPy package library provides us a uniform distribution method to generate random numbers called ***numpy.random.normal***. The syntax is almost the same as the uniform distribution but you need to add two more vital data here known as the ***mean*** and the ***standard deviation***."
]
},
{
"cell_type": "code",
"metadata": {
"id": "xYDNbvr3FLq6",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 69
},
"outputId": "3b5483b7-f25e-45e0-e3a0-1c2e4971487e"
},
"source": [
"import numpy as np\n",
"# Create a 3x3 array of normally distributed random values\n",
"# with mean 0 and standard deviation 1\n",
"print(np.random.normal(0, 1, (3, 3)))"
],
"execution_count": 23,
"outputs": [
{
"output_type": "stream",
"text": [
"[[-1.10593508 -1.65451545 -2.3634686 ]\n",
" [ 1.13534535 -1.01701414 0.63736181]\n",
" [-0.85990661 1.77260763 -1.11036305]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Y1y9eg95FNKt",
"colab_type": "text"
},
"source": [
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_fL6oUdAFOuG",
"colab_type": "text"
},
"source": [
"## Creating an identity matrix using numpy array\n",
"\n",
"An identity matrix is a matrix where the principal diagonal elements are 1 and the other elements except the principal diagonal elements are 0. The numpy package library provides a method to generate an identity matrix called the eye. An identity matrix is a square matrix meaning it has equal rows and columns."
]
},
{
"cell_type": "code",
"metadata": {
"id": "qlsKW04vFRzc",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 87
},
"outputId": "c2fcb418-37f7-42d8-f22b-19d347aabe73"
},
"source": [
"import numpy as np\n",
"# Create a identity matrix of 4 rows and 4 columns\n",
"print(np.eye(4))"
],
"execution_count": 24,
"outputs": [
{
"output_type": "stream",
"text": [
"[[1. 0. 0. 0.]\n",
" [0. 1. 0. 0.]\n",
" [0. 0. 1. 0.]\n",
" [0. 0. 0. 1.]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7-vAtP-uFTec",
"colab_type": "text"
},
"source": [
"The number 4 represents the rows and columns since it is a square matrix we only need to specify the value once (4 in this case).\n",
"\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1LtTKX6EFWLc",
"colab_type": "text"
},
"source": [
"This is the end of this tutorial “[How to create NumPy arrays from scratch?](https://towardsdatascience.com/how-to-create-numpy-arrays-from-scratch-3e0341f9ffea)”, this is just the introductory tutorial for NumPy Package library. However, much more complex concepts of the NumPy package library will be discussed in the upcoming tutorials. Thank you guys for spending your time reading my tutorial. I hope you enjoyed it. If you have any doubts related to NumPy, then the comment section is all yours. Until then Goodbye, See you have a good day."
]
}
]
}