{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "Learning One-Hot Encoding in Python the Easy Way.ipynb",
"provenance": [],
"collapsed_sections": [],
"authorship_tag": "ABX9TyMCG9J8p2GznMycFusm+/c8",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FMvwrGiPrXXb",
"colab_type": "text"
},
"source": [
"# **Learning One-Hot Encoding in Python the Easy Way**\n",
"\n",
"## **In this tutorial, we will learn one of the important concepts in feature engineering know as one-hot encoding from scratch.**\n",
"\n",
"\n",
"\n",
"Let's understand the situation first and then define one-hot encoding. Sometimes solving a problem is one of the fastest ways to understand the concepts. Alright, let's create a situation first (I just made up the situation)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5FGt0Ocdrj21",
"colab_type": "text"
},
"source": [
"# **Situation**\n",
"\n",
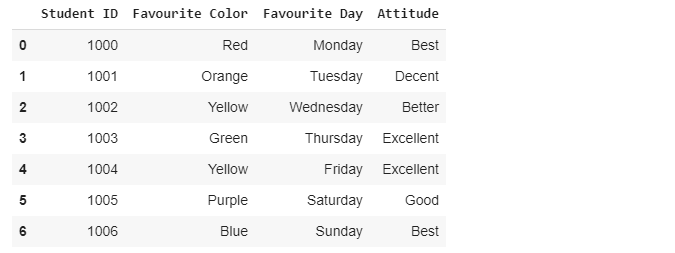
"Let's say you are solving a simple data science problem. Now, it doesn't matter what the actual problem is about but you are caught up in a situation where you have a tiny data set which has 7 instances and each of this instance has 4 features. In lame words, the data set has **7 rows** and **4 columns**. Out of which the three columns are of type `object` meaning those columns comprise **string values**. The other column is of type `int` meaning it has only integer values. Now enough talk let's practically see how the data set looks like. Rather than showing you the raw data (.CSV format). I formatted it into a data frame using the [pandas library](https://pandas.pydata.org/).\n",
"\n",
"\n",
"\n",
"To be on the safer side, let's see the data types of the columns.\n",
"\n",
"\n",
"\n",
"Now the actual situation starts since some learning algorithms work only with numeric data you have to somehow deal with this object data. There are two options to deal with this situation:\n",
"\n",
"* **Delete** all the three columns and then go to sleep\n",
"* **Read** this tutorial and implement one-hot encoding\n",
"\n",
"I know **option 1** works well, but sometimes you have to focus and work hard for a living. Now the solution to this situation is to convert this `object` type of data into several `binary` ones. What I mean by this is look at the data set very closely. The column **Favourite Color** has 6 unique values such as **Red, Orange, Yellow, Green, Purple, and Blue**. Now we can transform this feature into a vector of six numerical values as shown below:\n",
"\n",
"\n",
"\n",
"Similarly don't you think we can transform the Favourite Day column into a vector of six numerical values too? Because there are 7 unique days in this column such as **Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday**.\n",
"\n",
"\n",
"\n",
"\n",
"Now you might be thinking what about the **Attitude** column can we not do the same. But the catch point here is no. Don't do the same. Here we shall learn a new concept called **order**. Since there are **decent, good, better, best and excellent**. We shall order them as {**decent, good, better, best, excellent**} as {**1, 2, 3, 4, 5**} or {**0, 1, 2, 3, 4**}.\n",
"\n",
"\n",
"\n",
"> This is because when the ordering of some values matters we can replace those values by keeping only one variable.\n",
"\n",
"Remember this technique does not work in all the cases. For example, some of you might think that can't we use the same technique to fill the values for the other two columns too. By doing so you will certainly decrease the dimensions of the feature vector but it implies that there is an order among the values in that category and it will often confuse the learning algorithm. The learning algorithm will try to find a **state** or **regularity** when there is no one and the algorithm will most likely **overfit**. So think and use this technique wisely. Use this only when the order of the values is important. This technique can be used in the cases of **quality of an article, user reviews of a product, taste of food, etc**.\n",
"\n",
"So knowingly or unknowingly you have learned and mastered the concept of One-hot encoding, and where to use it. This is how you convert the **categorical or object type data into numeric type data**. Let us see how we can actually code this and come out of this situation.\n",
"\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "u0AYG6wltNOt",
"colab_type": "text"
},
"source": [
"## **Creating the dataset from scratch**\n",
"\n",
"As mentioned earlier, this is a made-up dataset. Created for this tutorial. Nothing personal."
]
},
{
"cell_type": "code",
"metadata": {
"id": "Pa2XmepqtUr0",
"colab_type": "code",
"colab": {}
},
"source": [
"import pandas as pd\n",
"\n",
"# Creating a list with some values \n",
"\n",
"studentID = [1000, 1001, 1002, 1003, 1004, 1005, 1006]\n",
"color = ['Red', 'Orange', \"Yellow\", 'Green', 'Yellow', 'Purple', 'Blue']\n",
"DaysOfTheWeek = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']\n",
"Attitude = ['Best', 'Decent', 'Better', 'Excellent', 'Excellent', 'Good', 'Best']"
],
"execution_count": 0,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "GitCX-h4tYMS",
"colab_type": "text"
},
"source": [
"Now that we have the list let's convert this into a data frame. To do this we need to **zip** all the list values and then store it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "hN9bMbpltZzJ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 266
},
"outputId": "cee45134-d1fb-4c69-87f7-a8e74a92cbf9"
},
"source": [
"# Converting the list into a data frame and simultaneously renaming the columns.\n",
"\n",
"df = pd.DataFrame(list(zip(studentID, color, DaysOfTheWeek, Attitude)), columns =['Student ID', 'Favourite Color', 'Favourite Day', 'Attitude'])\n",
"df"
],
"execution_count": 21,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/html": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FMvwrGiPrXXb",
"colab_type": "text"
},
"source": [
"# **Learning One-Hot Encoding in Python the Easy Way**\n",
"\n",
"## **In this tutorial, we will learn one of the important concepts in feature engineering know as one-hot encoding from scratch.**\n",
"\n",
"\n",
"\n",
"Let's understand the situation first and then define one-hot encoding. Sometimes solving a problem is one of the fastest ways to understand the concepts. Alright, let's create a situation first (I just made up the situation)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5FGt0Ocdrj21",
"colab_type": "text"
},
"source": [
"# **Situation**\n",
"\n",
"Let's say you are solving a simple data science problem. Now, it doesn't matter what the actual problem is about but you are caught up in a situation where you have a tiny data set which has 7 instances and each of this instance has 4 features. In lame words, the data set has **7 rows** and **4 columns**. Out of which the three columns are of type `object` meaning those columns comprise **string values**. The other column is of type `int` meaning it has only integer values. Now enough talk let's practically see how the data set looks like. Rather than showing you the raw data (.CSV format). I formatted it into a data frame using the [pandas library](https://pandas.pydata.org/).\n",
"\n",
"\n",
"\n",
"To be on the safer side, let's see the data types of the columns.\n",
"\n",
"\n",
"\n",
"Now the actual situation starts since some learning algorithms work only with numeric data you have to somehow deal with this object data. There are two options to deal with this situation:\n",
"\n",
"* **Delete** all the three columns and then go to sleep\n",
"* **Read** this tutorial and implement one-hot encoding\n",
"\n",
"I know **option 1** works well, but sometimes you have to focus and work hard for a living. Now the solution to this situation is to convert this `object` type of data into several `binary` ones. What I mean by this is look at the data set very closely. The column **Favourite Color** has 6 unique values such as **Red, Orange, Yellow, Green, Purple, and Blue**. Now we can transform this feature into a vector of six numerical values as shown below:\n",
"\n",
"\n",
"\n",
"Similarly don't you think we can transform the Favourite Day column into a vector of six numerical values too? Because there are 7 unique days in this column such as **Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday**.\n",
"\n",
"\n",
"\n",
"\n",
"Now you might be thinking what about the **Attitude** column can we not do the same. But the catch point here is no. Don't do the same. Here we shall learn a new concept called **order**. Since there are **decent, good, better, best and excellent**. We shall order them as {**decent, good, better, best, excellent**} as {**1, 2, 3, 4, 5**} or {**0, 1, 2, 3, 4**}.\n",
"\n",
"\n",
"\n",
"> This is because when the ordering of some values matters we can replace those values by keeping only one variable.\n",
"\n",
"Remember this technique does not work in all the cases. For example, some of you might think that can't we use the same technique to fill the values for the other two columns too. By doing so you will certainly decrease the dimensions of the feature vector but it implies that there is an order among the values in that category and it will often confuse the learning algorithm. The learning algorithm will try to find a **state** or **regularity** when there is no one and the algorithm will most likely **overfit**. So think and use this technique wisely. Use this only when the order of the values is important. This technique can be used in the cases of **quality of an article, user reviews of a product, taste of food, etc**.\n",
"\n",
"So knowingly or unknowingly you have learned and mastered the concept of One-hot encoding, and where to use it. This is how you convert the **categorical or object type data into numeric type data**. Let us see how we can actually code this and come out of this situation.\n",
"\n",
"\n",
"\n",
"\n",
"---\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "u0AYG6wltNOt",
"colab_type": "text"
},
"source": [
"## **Creating the dataset from scratch**\n",
"\n",
"As mentioned earlier, this is a made-up dataset. Created for this tutorial. Nothing personal."
]
},
{
"cell_type": "code",
"metadata": {
"id": "Pa2XmepqtUr0",
"colab_type": "code",
"colab": {}
},
"source": [
"import pandas as pd\n",
"\n",
"# Creating a list with some values \n",
"\n",
"studentID = [1000, 1001, 1002, 1003, 1004, 1005, 1006]\n",
"color = ['Red', 'Orange', \"Yellow\", 'Green', 'Yellow', 'Purple', 'Blue']\n",
"DaysOfTheWeek = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']\n",
"Attitude = ['Best', 'Decent', 'Better', 'Excellent', 'Excellent', 'Good', 'Best']"
],
"execution_count": 0,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "GitCX-h4tYMS",
"colab_type": "text"
},
"source": [
"Now that we have the list let's convert this into a data frame. To do this we need to **zip** all the list values and then store it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "hN9bMbpltZzJ",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 266
},
"outputId": "cee45134-d1fb-4c69-87f7-a8e74a92cbf9"
},
"source": [
"# Converting the list into a data frame and simultaneously renaming the columns.\n",
"\n",
"df = pd.DataFrame(list(zip(studentID, color, DaysOfTheWeek, Attitude)), columns =['Student ID', 'Favourite Color', 'Favourite Day', 'Attitude'])\n",
"df"
],
"execution_count": 21,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student ID | \n",
" Favourite Color | \n",
" Favourite Day | \n",
" Attitude | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1000 | \n",
" Red | \n",
" Monday | \n",
" Best | \n",
"
\n",
" \n",
" | 1 | \n",
" 1001 | \n",
" Orange | \n",
" Tuesday | \n",
" Decent | \n",
"
\n",
" \n",
" | 2 | \n",
" 1002 | \n",
" Yellow | \n",
" Wednesday | \n",
" Better | \n",
"
\n",
" \n",
" | 3 | \n",
" 1003 | \n",
" Green | \n",
" Thursday | \n",
" Excellent | \n",
"
\n",
" \n",
" | 4 | \n",
" 1004 | \n",
" Yellow | \n",
" Friday | \n",
" Excellent | \n",
"
\n",
" \n",
" | 5 | \n",
" 1005 | \n",
" Purple | \n",
" Saturday | \n",
" Good | \n",
"
\n",
" \n",
" | 6 | \n",
" 1006 | \n",
" Blue | \n",
" Sunday | \n",
" Best | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student ID | \n",
" Attitude | \n",
" Favourite Color_Blue | \n",
" Favourite Color_Green | \n",
" Favourite Color_Orange | \n",
" Favourite Color_Purple | \n",
" Favourite Color_Red | \n",
" Favourite Color_Yellow | \n",
" Favourite Day_Friday | \n",
" Favourite Day_Monday | \n",
" Favourite Day_Saturday | \n",
" Favourite Day_Sunday | \n",
" Favourite Day_Thursday | \n",
" Favourite Day_Tuesday | \n",
" Favourite Day_Wednesday | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1000 | \n",
" Best | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1001 | \n",
" Decent | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1002 | \n",
" Better | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1003 | \n",
" Excellent | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1004 | \n",
" Excellent | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1005 | \n",
" Good | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 6 | \n",
" 1006 | \n",
" Best | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student ID | \n",
" Attitude | \n",
" Favourite Color_Blue | \n",
" Favourite Color_Green | \n",
" Favourite Color_Orange | \n",
" Favourite Color_Purple | \n",
" Favourite Color_Red | \n",
" Favourite Color_Yellow | \n",
" Favourite Day_Friday | \n",
" Favourite Day_Monday | \n",
" Favourite Day_Saturday | \n",
" Favourite Day_Sunday | \n",
" Favourite Day_Thursday | \n",
" Favourite Day_Tuesday | \n",
" Favourite Day_Wednesday | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1000 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1001 | \n",
" 2 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1002 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1003 | \n",
" 3 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1004 | \n",
" 3 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1005 | \n",
" 4 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 6 | \n",
" 1006 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"