### Agents remember,Humans innovate.
[](https://www.npmjs.com/package/@tencentdb-agent-memory/memory-tencentdb)
[](./LICENSE)
[](https://nodejs.org/)
[](https://github.com/openclaw/openclaw)
[](https://hermes-agent.nousresearch.com/docs/)
[](https://discord.gg/kDtHb5RW2)
[Highlights](#-highlights) · [Overview](#overview) · [Core Technology](#core-technology-reject-flat-storage-embrace-layering-and-symbolization) · [Features](#-features) · [Quick Start](#quick-start)
[**English**](./README.md) · [简体中文](./README_CN.md)
---
## ✨ Highlights
> **TencentDB Agent Memory = symbolic short-term memory + layered long-term memory.**
>
> - **Symbolic short-term memory** offloads heavy tool logs and condenses them into compact Mermaid symbols, cutting token usage and improving task success.
> - **Layered long-term memory** distills fragmented conversations into structured personas and scenes, instead of flat vector piles.
When integrated with OpenClaw, it cuts token usage by up to **61.38%**, improves pass rate by **51.52%** (relative), and raises PersonaMem accuracy from **48%** to **76%**.
| Memory Capability | Benchmark | OpenClaw Success | With Plugin | Relative Δ | OpenClaw Tokens | With Plugin Tokens | Relative Δ |
| :--- | :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **Short-term** | WideSearch | 33% | **50%** | **+51.52%** | 221.31M | **85.64M** | **−61.38%** |
| **Short-term** | SWE-bench | 58.4% | **64.2%** | **+9.93%** | 3474.1M | **2375.4M** | **−33.09%** |
| **Short-term** | AA-LCR | 44.0% | **47.5%** | **+7.95%** | 112.0M | **77.3M** | **−30.98%** |
| **Long-term** | PersonaMem | 48% | **76%** | **+59%** | — | — | — |
> These results are measured over continuous long-horizon sessions, not isolated turns. For example, SWE-bench runs 50 consecutive tasks per session to simulate the context-accumulation pressure of real-world long-horizon agents.
---
## Overview
**Memory is not about hoarding everything in the AI — it is about sparing humans from having to repeat themselves.**
In practice, we constantly re-explain the same SOPs, project background, tool conventions, and output formats to the Agent. Such information should not require repetition, nor should it be indiscriminately dumped into the context.
TencentDB Agent Memory helps the Agent learn your workflows, retain task context, and reuse past experience. We reject both brute-force history accumulation and irreversible lossy summarization. Instead, we design memory as a layered system: **symbolic memory** for in-task information overload, and **memory layering** for cross-session experience.
> **Let the Agent remember what should be remembered, so people can focus on judgment, creation, and work that truly matters.**
---
## Core Technology: Reject Flat Storage, Embrace Layering and Symbolization
Our architecture rests on two pillars: **memory layering** and **symbolic memory**. Together they ensure Agents do not merely "remember more", but "reason better".
### 1. Memory Layering: Progressive Disclosure with Heterogeneous Storage
Traditional memory systems shred data into fragments and dump them into a flat vector store. Recall degenerates into a blind search across disconnected fragments, with no macro-level guidance.
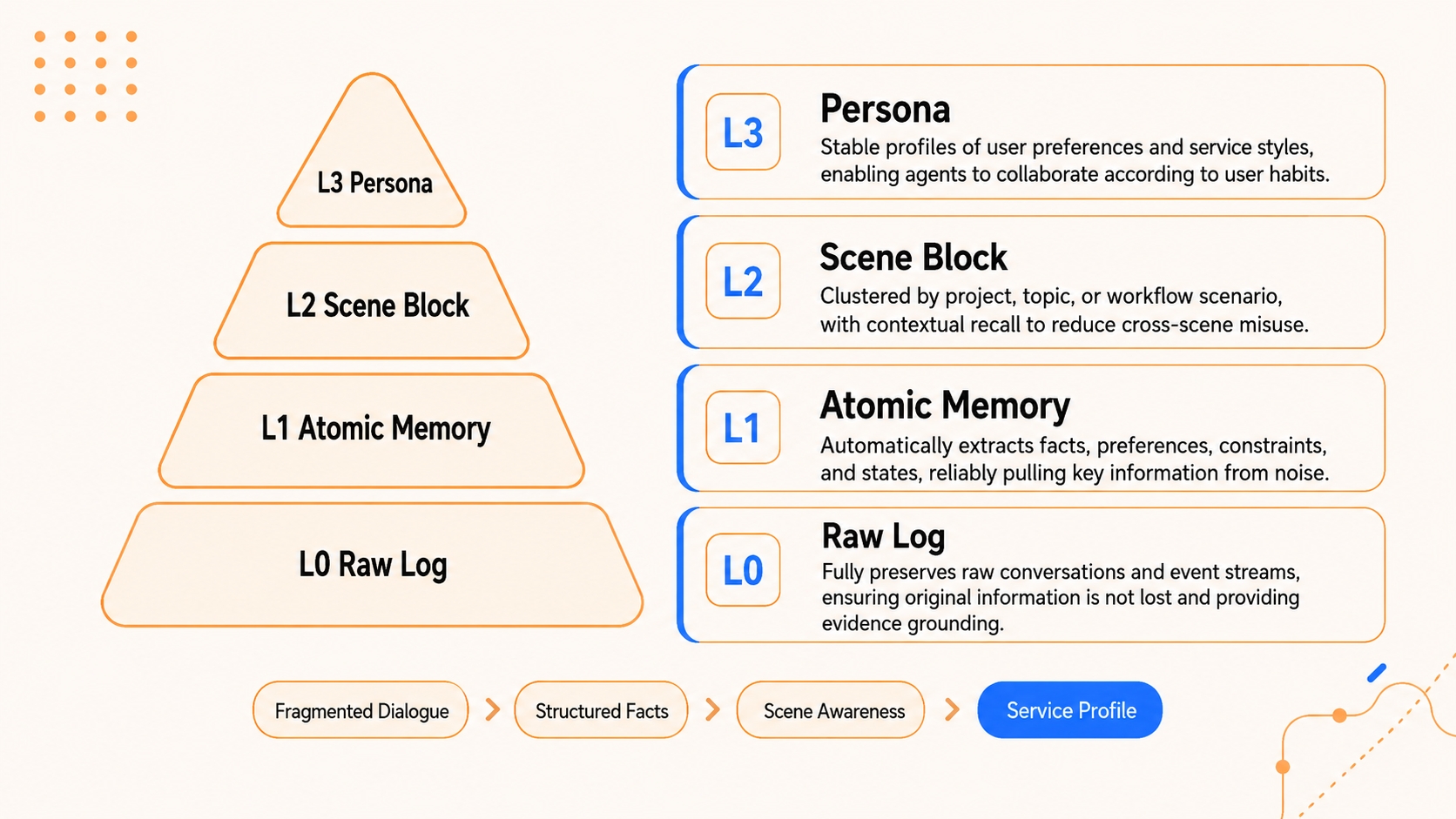
Whether it is long-term knowledge, short-term tasks, or future skill capabilities, memory should never be flat — both its formation and its recall must be hierarchical. TencentDB Agent Memory adopts **layering** as its unified architectural paradigm:
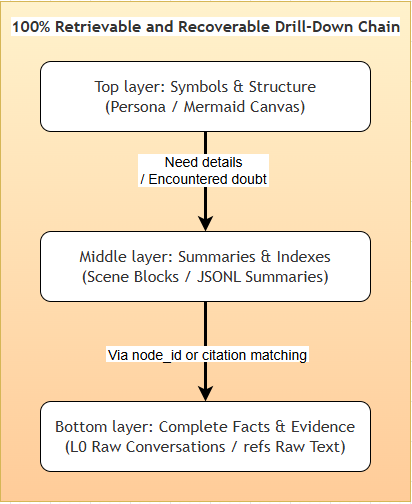
* **Short-term context layering.** The bottom layer archives raw tool outputs (`refs/*.md`); the middle layer extracts step-level summaries (`jsonl`); the top layer condenses state into a lightweight Mermaid canvas. The Agent only needs to attend to the top-layer structure in context, and drills down to the lower layers via `node_id` when an error occurs.
* **Long-term personalization layering.** In place of flat logs, we build a semantic pyramid: **L0 Conversation** (raw dialogue) → **L1 Atom** (atomic facts) → **L2 Scenario** (scene blocks) → **L3 Persona** (user profile). The Persona layer carries day-to-day preferences; the system drills down to Atoms only when details matter.
* **Skill generation layering.** Layering also applies to actions. The middle layer derives common solution patterns (**Scenario**) from bottom-layer execution traces (**Conversation**), and the top layer distills reusable Skills or standard SOPs (**Persona**).