{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Introduction to web scraping\n",
"\n",
"This workshop is a one-hour beginner's introduction to web scraping. \n",
"\n",
"This notebook deliberately has more content that we can reasonably cover in one hour. **The most important material is in bold**, and we'll focus on that material in person. To get the most out of this workshop, I'd suggest spending some time working through it in full after the workshop.\n",
"\n",
"We'll cover the following topics:\n",
"\n",
"[Motivation](#motivation)\n",
"\n",
"_Why would you want to scrape data from the web?_\n",
"\n",
"[How the Web works](#web)\n",
"\n",
"_A high-level appreciation of how the Web works will help us to scrape data effectively._\n",
"\n",
"[Making a request](#request)\n",
"\n",
"_How can we ask other computers on the Internet to send us data using Python?_\n",
"\n",
"[Parsing HTML](#parsing)\n",
"\n",
"_Web pages are just files in a special format. Extracting information out of these files involves parsing HTML._\n",
"\n",
"[Terms of Service](#terms)\n",
"\n",
"_Don't go scraping willy-nilly!_\n",
"\n",
"[Further resources](#resources)\n",
"\n",
"_So you want to learn more about web scraping._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Motivation\n",
"\n",
"It's 2019. The web is everywhere.\n",
"\n",
"* If you want to buy a house, real estate agents have [websites](https://www.wendytlouie.com/) where they list the houses they're currently selling. \n",
"* If you want to know whether to where a rain jacket or shorts, you check the weather on a [website](https://weather.com/weather/tenday/l/Berkeley+CA+USCA0087:1:US). \n",
"* If you want to know what's happening in the world, you read the news [online](https://www.sfchronicle.com/). \n",
"* If you've forgotten which city is the capital of Australia, you check [Wikipedia](https://en.wikipedia.org/wiki/Australia).\n",
"\n",
"**The point is this: there is an enormous amount of information (also known as data) on the web.**\n",
"\n",
"If we (in our capacities as, for example, data scientists, social scientists, digital humanists, businesses, public servants or members of the public) can get our hands on this information, **we can answer all sorts of interesting questions or solve important problems**.\n",
"\n",
"* Maybe you're studying gender bias in student evaluations of professors. One option would be to scrape ratings from [Rate My Professors](https://www.ratemyprofessors.com/) (provided you follow their [terms of service](https://www.ratemyprofessors.com/TermsOfUse_us.jsp#use))\n",
"* Perhaps you want to build an app that shows users articles relating to their specified interests. You could scrape stories from various news websites and then use NLP methods to decide which articles to show which users.\n",
"* [Geoff Boeing](https://geoffboeing.com/) and [Paul Waddell](https://ced.berkeley.edu/ced/faculty-staff/paul-waddell) recently published [a great study](https://arxiv.org/pdf/1605.05397.pdf) of the US housing market by scraping millions of Craiglist rental listings. Among other insights, their study shows which metropolitan areas in the US are more or less affordable to renters."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## How the Web works\n",
"\n",
"Here's our high-level description of the web.\n",
"\n",
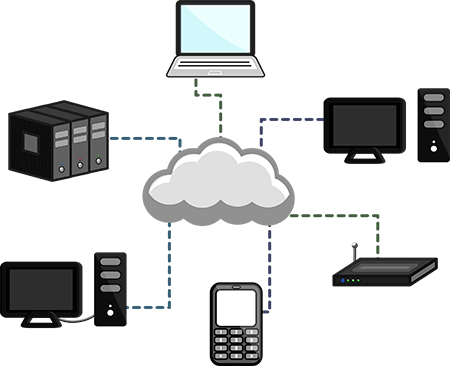
"**The internet is a bunch of computers connected together.** Some computers are laptops, some are desktops, some are smart phones, some are servers owned by companies. Each computer has its own address on the internet. Using these addresses, **one computer can ask another computer for some information (data). We say that the first computer sends a _request_ to the second computer, asking for some particular information. The second computer sends back a _response_**. The response could include the information requested, or it could be an error message. Perhaps the second computer doesn't have that information any more, or the first computer isn't allowed to access that information.\n",
"\n",
"\n",
"\n",
"We said that there is an enormous amount of information available on the web. When people put information on the web, they generally have two different audiences in mind, two different types of consumers of their information: humans and computers. If they want their information to be used primarily by humans, they'll make a website. This will let them lay out the information in a visually appealing way, choose colours, add pictures, and make the information interactive. If they want their information to be used by computers, they'll make a web API. A web API provides other computers structured access to their data. We won't cover APIs in this workshop, but you should know that i) APIs are very common and ii) if there is an API for a website/data source, you should use that over web scraping. Many data sources that you might be interested in (e.g. social media sites) have APIs.\n",
"\n",
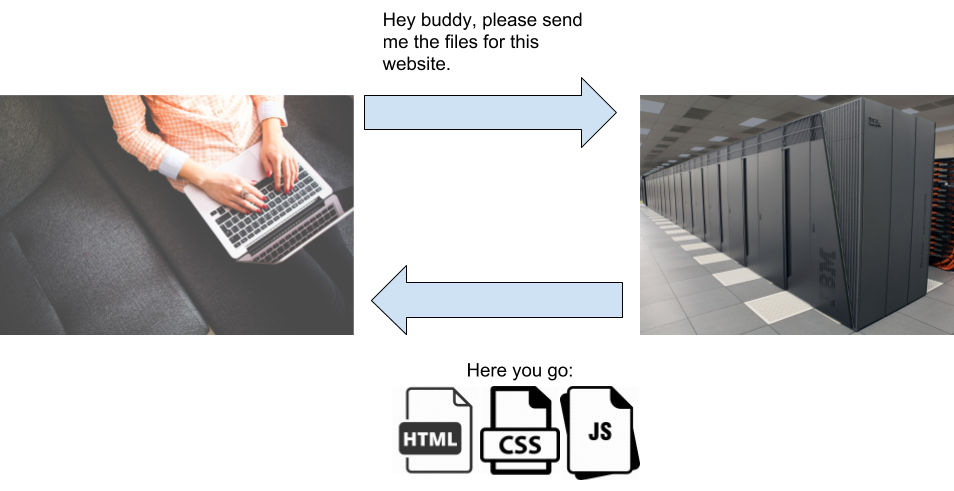
"**Websites are just a bunch of files on one of those computers. They are just plain text files, so you can view them if you want. When you type in the address of a website in your browser, your computer sends a request to the computer located at that address. The request says \"hey buddy, please send me the file(s) for this website\". If everything goes well, the other computer will send back the file(s) in the response**. Everytime you navigate to a new website or page in your browser, this process repeats.\n",
"\n",
"\n",
"\n",
"**There are three main languages that that website files are written with: HyperText Markup Language (HTML), Cascading Style Sheets (CSS) and JavaScript (JS)**. They normally have `.html`, `.css` and `.js` file extensions. Each language (and thus each type of file) serves a different purpose. **HTML files are the ones we care about the most, because they are the ones that contain the text you see on a web page**. CSS files contain the instructions on how to make the content in a HTML visually appealing (all the colours, font sizes, border widths, etc.). JavaScript files have the instructions on how to make the information on a website interactive (things like changing colour when you click something, entering data in a form). In this workshop, we're going to focus on HTML.\n",
"\n",
"\n",
"**It's not too much of a simplification to say:**\n",
"\n",
"\\begin{equation}\n",
"\\textrm{Web scraping} = \\textrm{Making a request for a HTML file} + \\textrm{Parsing the HTML response}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making a request\n",
"\n",
"**The first step in web scraping is to get the HTML of the website we want to scrape. The [requests](http://docs.python-requests.org/en/master/) library is the easiest way to do this in Python.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Canberra'\n",
"\n",
"response = requests.get(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great, it looks like everything worked! Let's see our beautiful HTML:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Huh, that's weird. Doesn't look like HTML to me.\n",
"\n",
"What the `requests.get` function returned (and the thing in our `response` variable) was a Response object. It itself isn't the HTML that we wanted, but rather a collection of metadata about the request/response interaction between your computer and the Wikipedia server.\n",
"\n",
"For example, it knows whether the response was successful or not (`response.ok`), how long the whole interaction took (`response.elapsed`), what time the request took place (`response.headers['Date']`) and a whole bunch of other metadata."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.ok"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.headers['Date']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Of course, what we really care about is the HTML content. We can get that from the `Response` object with `response.text`. What we get back is a string of HTML, exactly the contents of the HTML file at the URL that we requested.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"html = response.text\n",
"print(html[:1000])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Get the HTML for [the Wikipedia page about HTML](https://en.wikipedia.org/wiki/HTML). \n",
"Print out the first 1000 characters and compare it to the HTML you see when you view the source HTML in your broswer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"url = 'https://en.wikipedia.org/wiki/HTML'\n",
"response = requests.get(url)\n",
"html = response.text"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Write a function called `get_html` that takes a URL as an argument and returns the HTML contents as a string. Test your function on the page for [Sir Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" return response.text\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"What happens if the request doesn't go so smoothly? Add a defensive measure to your function to check that the response recieved was successful."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" assert response.ok, \"Whoops, this request didn't go as planned!\"\n",
" return response.text\n",
" \n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Parsing HTML\n",
"\n",
"**The second step in web scraping is parsing HTML. This is where things can get a little tricky.** \n",
"\n",
"**Imagine you're in the field of education, in fact your specialty is studying higher education institutions. You're wondering how different disciplines change over time. Is it true that disciplines are incorporating more computational techniques as the years go on? Is that true for all disciplines or only some? Can we spot emerging themes across a whole university?**\n",
"\n",
"**To answer these questions, we're going to need data. We're going to collect a dataset of all courses registered at UC Berkeley, not just those being taught this semester but all courses currently approved to be taught. These are listed on [this page](http://guide.berkeley.edu/courses/), called the Academic Guide. Well, actually they're not directly listed on that page. That page lists the departments/programs/units that teach currently approved courses. If we click on each department (for the sake of brevity, I'm just going to call them all \"departments\"), we can see the list of all courses they're approved to teach. For example, [here's](http://guide.berkeley.edu/courses/aerospc/) the page for Aerospace Studies. We'll call these pages departmental pages.**\n",
"\n",
"### Challenge\n",
"\n",
"View the source HTML of [the page listing all departments](http://guide.berkeley.edu/courses/), and see if you can find the part of the HTML where the departments are listed. There's a lot of other stuff in the file that we don't care too much about. You could try `Crtl-F`ing for the name of a department you can see on the webpage.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"**Solution**\n",
"\n",
"You should see something like this:\n",
"\n",
"\n",
"```\n",
"
\n",
"```\n",
"\n",
"**This is HTML. HTML uses \"tags\", code that surrounds the raw text which indicates the structure of the content. The tags are enclosed in `<` and `>` symbols. The `
` says \"this is a new thing in a list and `
` says \"that's the end of that new thing in the list\". Similarly, the `` and the `` say, \"everything between us is a hyperlink\". In this HTML file, each department is listed in a list with `
 \n",
"\n",
"We said that there is an enormous amount of information available on the web. When people put information on the web, they generally have two different audiences in mind, two different types of consumers of their information: humans and computers. If they want their information to be used primarily by humans, they'll make a website. This will let them lay out the information in a visually appealing way, choose colours, add pictures, and make the information interactive. If they want their information to be used by computers, they'll make a web API. A web API provides other computers structured access to their data. We won't cover APIs in this workshop, but you should know that i) APIs are very common and ii) if there is an API for a website/data source, you should use that over web scraping. Many data sources that you might be interested in (e.g. social media sites) have APIs.\n",
"\n",
"**Websites are just a bunch of files on one of those computers. They are just plain text files, so you can view them if you want. When you type in the address of a website in your browser, your computer sends a request to the computer located at that address. The request says \"hey buddy, please send me the file(s) for this website\". If everything goes well, the other computer will send back the file(s) in the response**. Everytime you navigate to a new website or page in your browser, this process repeats.\n",
"\n",
"
\n",
"\n",
"We said that there is an enormous amount of information available on the web. When people put information on the web, they generally have two different audiences in mind, two different types of consumers of their information: humans and computers. If they want their information to be used primarily by humans, they'll make a website. This will let them lay out the information in a visually appealing way, choose colours, add pictures, and make the information interactive. If they want their information to be used by computers, they'll make a web API. A web API provides other computers structured access to their data. We won't cover APIs in this workshop, but you should know that i) APIs are very common and ii) if there is an API for a website/data source, you should use that over web scraping. Many data sources that you might be interested in (e.g. social media sites) have APIs.\n",
"\n",
"**Websites are just a bunch of files on one of those computers. They are just plain text files, so you can view them if you want. When you type in the address of a website in your browser, your computer sends a request to the computer located at that address. The request says \"hey buddy, please send me the file(s) for this website\". If everything goes well, the other computer will send back the file(s) in the response**. Everytime you navigate to a new website or page in your browser, this process repeats.\n",
"\n",
" \n",
"\n",
"**There are three main languages that that website files are written with: HyperText Markup Language (HTML), Cascading Style Sheets (CSS) and JavaScript (JS)**. They normally have `.html`, `.css` and `.js` file extensions. Each language (and thus each type of file) serves a different purpose. **HTML files are the ones we care about the most, because they are the ones that contain the text you see on a web page**. CSS files contain the instructions on how to make the content in a HTML visually appealing (all the colours, font sizes, border widths, etc.). JavaScript files have the instructions on how to make the information on a website interactive (things like changing colour when you click something, entering data in a form). In this workshop, we're going to focus on HTML.\n",
"\n",
"\n",
"**It's not too much of a simplification to say:**\n",
"\n",
"\\begin{equation}\n",
"\\textrm{Web scraping} = \\textrm{Making a request for a HTML file} + \\textrm{Parsing the HTML response}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making a request\n",
"\n",
"**The first step in web scraping is to get the HTML of the website we want to scrape. The [requests](http://docs.python-requests.org/en/master/) library is the easiest way to do this in Python.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Canberra'\n",
"\n",
"response = requests.get(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great, it looks like everything worked! Let's see our beautiful HTML:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Huh, that's weird. Doesn't look like HTML to me.\n",
"\n",
"What the `requests.get` function returned (and the thing in our `response` variable) was a Response object. It itself isn't the HTML that we wanted, but rather a collection of metadata about the request/response interaction between your computer and the Wikipedia server.\n",
"\n",
"For example, it knows whether the response was successful or not (`response.ok`), how long the whole interaction took (`response.elapsed`), what time the request took place (`response.headers['Date']`) and a whole bunch of other metadata."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.ok"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.headers['Date']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Of course, what we really care about is the HTML content. We can get that from the `Response` object with `response.text`. What we get back is a string of HTML, exactly the contents of the HTML file at the URL that we requested.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"html = response.text\n",
"print(html[:1000])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Get the HTML for [the Wikipedia page about HTML](https://en.wikipedia.org/wiki/HTML). \n",
"Print out the first 1000 characters and compare it to the HTML you see when you view the source HTML in your broswer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"url = 'https://en.wikipedia.org/wiki/HTML'\n",
"response = requests.get(url)\n",
"html = response.text"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Write a function called `get_html` that takes a URL as an argument and returns the HTML contents as a string. Test your function on the page for [Sir Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" return response.text\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"What happens if the request doesn't go so smoothly? Add a defensive measure to your function to check that the response recieved was successful."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" assert response.ok, \"Whoops, this request didn't go as planned!\"\n",
" return response.text\n",
" \n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Parsing HTML\n",
"\n",
"**The second step in web scraping is parsing HTML. This is where things can get a little tricky.** \n",
"\n",
"**Imagine you're in the field of education, in fact your specialty is studying higher education institutions. You're wondering how different disciplines change over time. Is it true that disciplines are incorporating more computational techniques as the years go on? Is that true for all disciplines or only some? Can we spot emerging themes across a whole university?**\n",
"\n",
"**To answer these questions, we're going to need data. We're going to collect a dataset of all courses registered at UC Berkeley, not just those being taught this semester but all courses currently approved to be taught. These are listed on [this page](http://guide.berkeley.edu/courses/), called the Academic Guide. Well, actually they're not directly listed on that page. That page lists the departments/programs/units that teach currently approved courses. If we click on each department (for the sake of brevity, I'm just going to call them all \"departments\"), we can see the list of all courses they're approved to teach. For example, [here's](http://guide.berkeley.edu/courses/aerospc/) the page for Aerospace Studies. We'll call these pages departmental pages.**\n",
"\n",
"### Challenge\n",
"\n",
"View the source HTML of [the page listing all departments](http://guide.berkeley.edu/courses/), and see if you can find the part of the HTML where the departments are listed. There's a lot of other stuff in the file that we don't care too much about. You could try `Crtl-F`ing for the name of a department you can see on the webpage.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"**Solution**\n",
"\n",
"You should see something like this:\n",
"\n",
"\n",
"```\n",
"
\n",
"\n",
"**There are three main languages that that website files are written with: HyperText Markup Language (HTML), Cascading Style Sheets (CSS) and JavaScript (JS)**. They normally have `.html`, `.css` and `.js` file extensions. Each language (and thus each type of file) serves a different purpose. **HTML files are the ones we care about the most, because they are the ones that contain the text you see on a web page**. CSS files contain the instructions on how to make the content in a HTML visually appealing (all the colours, font sizes, border widths, etc.). JavaScript files have the instructions on how to make the information on a website interactive (things like changing colour when you click something, entering data in a form). In this workshop, we're going to focus on HTML.\n",
"\n",
"\n",
"**It's not too much of a simplification to say:**\n",
"\n",
"\\begin{equation}\n",
"\\textrm{Web scraping} = \\textrm{Making a request for a HTML file} + \\textrm{Parsing the HTML response}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Making a request\n",
"\n",
"**The first step in web scraping is to get the HTML of the website we want to scrape. The [requests](http://docs.python-requests.org/en/master/) library is the easiest way to do this in Python.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Canberra'\n",
"\n",
"response = requests.get(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great, it looks like everything worked! Let's see our beautiful HTML:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Huh, that's weird. Doesn't look like HTML to me.\n",
"\n",
"What the `requests.get` function returned (and the thing in our `response` variable) was a Response object. It itself isn't the HTML that we wanted, but rather a collection of metadata about the request/response interaction between your computer and the Wikipedia server.\n",
"\n",
"For example, it knows whether the response was successful or not (`response.ok`), how long the whole interaction took (`response.elapsed`), what time the request took place (`response.headers['Date']`) and a whole bunch of other metadata."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.ok"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response.headers['Date']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Of course, what we really care about is the HTML content. We can get that from the `Response` object with `response.text`. What we get back is a string of HTML, exactly the contents of the HTML file at the URL that we requested.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"html = response.text\n",
"print(html[:1000])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Get the HTML for [the Wikipedia page about HTML](https://en.wikipedia.org/wiki/HTML). \n",
"Print out the first 1000 characters and compare it to the HTML you see when you view the source HTML in your broswer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"url = 'https://en.wikipedia.org/wiki/HTML'\n",
"response = requests.get(url)\n",
"html = response.text"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"Write a function called `get_html` that takes a URL as an argument and returns the HTML contents as a string. Test your function on the page for [Sir Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" return response.text\n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Challenge\n",
"\n",
"What happens if the request doesn't go so smoothly? Add a defensive measure to your function to check that the response recieved was successful."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# your solution here"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# solution\n",
"def get_html(url):\n",
" response = requests.get(url)\n",
" assert response.ok, \"Whoops, this request didn't go as planned!\"\n",
" return response.text\n",
" \n",
"\n",
"url = 'https://en.wikipedia.org/wiki/Tim_Berners-Lee'\n",
"html = get_html(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Parsing HTML\n",
"\n",
"**The second step in web scraping is parsing HTML. This is where things can get a little tricky.** \n",
"\n",
"**Imagine you're in the field of education, in fact your specialty is studying higher education institutions. You're wondering how different disciplines change over time. Is it true that disciplines are incorporating more computational techniques as the years go on? Is that true for all disciplines or only some? Can we spot emerging themes across a whole university?**\n",
"\n",
"**To answer these questions, we're going to need data. We're going to collect a dataset of all courses registered at UC Berkeley, not just those being taught this semester but all courses currently approved to be taught. These are listed on [this page](http://guide.berkeley.edu/courses/), called the Academic Guide. Well, actually they're not directly listed on that page. That page lists the departments/programs/units that teach currently approved courses. If we click on each department (for the sake of brevity, I'm just going to call them all \"departments\"), we can see the list of all courses they're approved to teach. For example, [here's](http://guide.berkeley.edu/courses/aerospc/) the page for Aerospace Studies. We'll call these pages departmental pages.**\n",
"\n",
"### Challenge\n",
"\n",
"View the source HTML of [the page listing all departments](http://guide.berkeley.edu/courses/), and see if you can find the part of the HTML where the departments are listed. There's a lot of other stuff in the file that we don't care too much about. You could try `Crtl-F`ing for the name of a department you can see on the webpage.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"**Solution**\n",
"\n",
"You should see something like this:\n",
"\n",
"\n",
"```\n",
"