# Life-Harness
### Adapting the interface, not the model, for deterministic LLM agents
[](https://arxiv.org/abs/2605.22166)
[](#benchmarks)
[](#results)
[](#results)
[](#why-life-harness)

**Life-Harness** is the code release for **"Adapting the Interface, Not the Model:
Runtime Harness Adaptation for Deterministic LLM Agents."** It targets a practical
question: when a frozen LLM agent repeatedly fails in a deterministic environment,
can we improve the runtime harness around the agent instead of retraining the
model or modifying the environment?
The answer is yes. Life-Harness turns recurring failures into reusable runtime
interventions across action realization, environment contracts, trajectory
regulation, and procedural skills. The model remains frozen; the benchmark
environment remains intact; only the harness interface adapts.
| Benchmarks | Model backbones | Settings improved | Avg. relative gain | Training-free |
| ---: | ---: | ---: | ---: | ---: |
| 7 | 18 | 116 / 126 | 88.5% | Yes |
## Why Life-Harness
| What changes? | What stays fixed? | Why it matters |
| --- | --- | --- |
| Runtime harness behavior | LLM weights | No finetuning or model-specific training pipeline |
| Prompted environment interface | Benchmark environment | Keeps deterministic evaluation comparable |
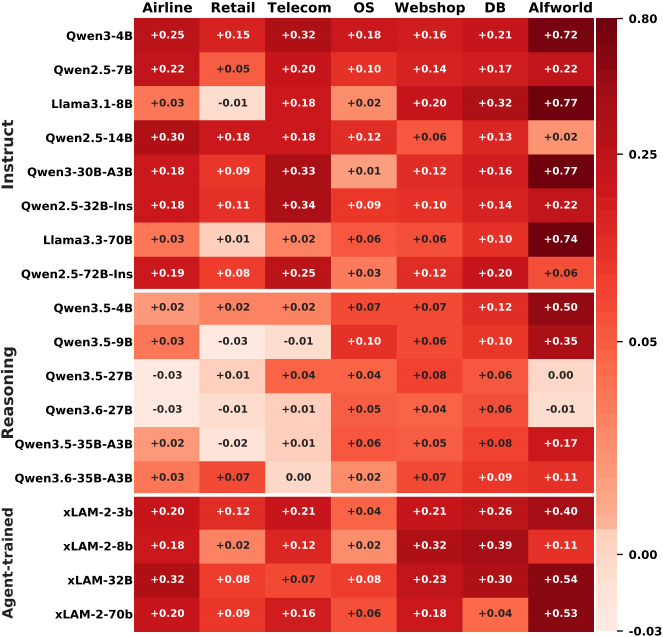
## Results
Across **7 deterministic agent benchmarks** and **18 model backbones**,
Life-Harness improves **116 / 126** model-environment settings, with an
**88.5% average relative improvement** reported in the paper.
## Method
Life-Harness evolves a small set of runtime layers from observed failures, then
reuses those layers during evaluation.
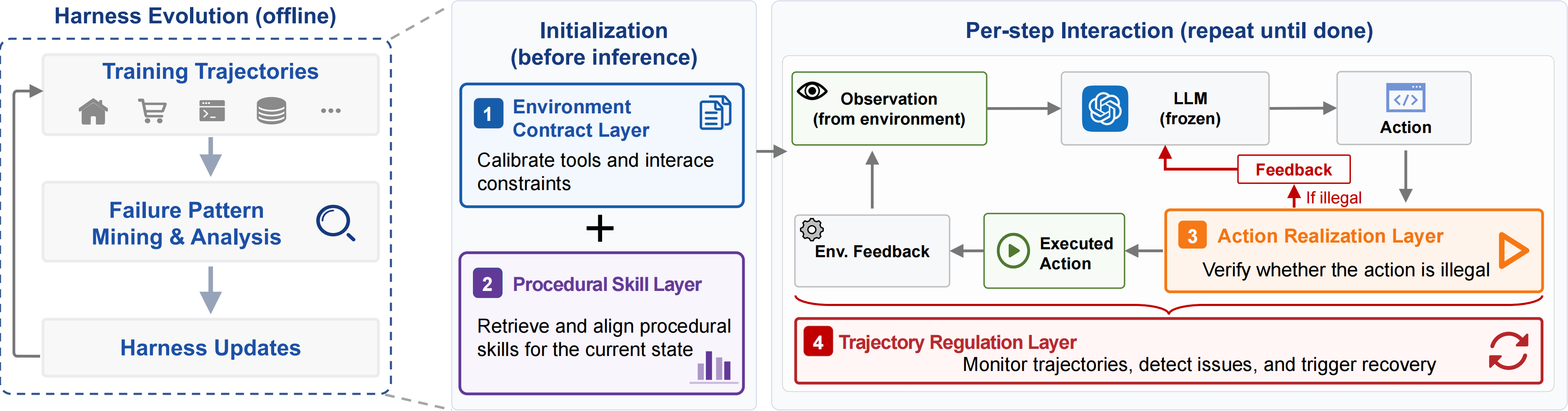
| Harness flag | Paper layer | Runtime role |
| --- | --- | --- |
| `h2` | Action Realization Layer | Helps convert model decisions into executable environment actions. |
| `h3` | Environment Contract Layer | Makes task and environment constraints explicit at runtime. |
| `h4` | Trajectory Regulation Layer | Regulates multi-step interaction traces to avoid repeated failure patterns. |
| `h5` | Procedural Skill Layer | Reuses procedural knowledge distilled from recurring successful recoveries. |
When the harness is disabled, these layers are not applied.
## Benchmarks
This repository keeps the two benchmark families in separate folders because
their environments and dependencies are intentionally different.
| Suite | Environments | Start here |
| --- | --- | --- |
| AgentBench-style harness | ALFWorld, DBBench, OS, WebShop | [AgentBench/README.md](AgentBench/README.md) |
| tau-bench-style harness | Airline, Retail, Telecom | [TauBench/README.md](TauBench/README.md) |
```text
Life-harness/
AgentBench/ # Docker-based AgentBench-style tasks
TauBench/ # uv-based tau-bench-style tasks
assets/ # README figures
```
## Quick Start
Clone the repository, then enter the benchmark suite you want to run:
```bash
cd Life-harness
# tau-bench-style tasks: Airline, Retail, Telecom
cd TauBench
# AgentBench-style tasks: ALFWorld, DBBench, OS, WebShop
cd ../AgentBench
```
Each subfolder README contains its own environment setup, evaluation commands,
and harness switches. API keys and provider URLs should be configured locally
through environment variables or `.env` files; do not commit them.
## Citation
If you use this repository, please cite the paper:
```bibtex
@article{xu2026adapting,
title = {Adapting the Interface, Not the Model: Runtime Harness Adaptation for Deterministic LLM Agents},
author = {Xu, Tianshi and others},
journal = {arXiv},
year = {2026},
url = {https://arxiv.org/abs/2605.22166},
urldate = {2026-05-22}
}
```