 \n",
"\n",
"##
\n",
"\n",
"## Деревья решений в игрушечной задаче и на данных Adult репозитория UCI\n", "\n", "**В задании Вам предлагается разобраться с тем, как работает дерево решений, на игрушечном примере, затем обучить и настроить деревья и (при желании) случайный лес в задаче классификации на данных Adult репозитория UCI. Ответьте на все вопросы в этой тетрадке и заполните ответы в [гугл-форме](https://docs.google.com/forms/d/1bC3jNPH7XZUty_DaIvt0fPrsiS8YFkcpeBKHPSG0hw0/edit).**" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Подключаем необходимые библиотеки" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "%matplotlib inline\n", "from matplotlib import pyplot as plt\n", "\n", "plt.rcParams['figure.figsize'] = (10, 8)\n", "import collections\n", "\n", "import numpy as np\n", "import pandas as pd\n", "import seaborn as sns\n", "from sklearn import preprocessing\n", "from sklearn.ensemble import RandomForestClassifier\n", "from sklearn.metrics import accuracy_score\n", "from sklearn.model_selection import GridSearchCV\n", "from sklearn.preprocessing import LabelEncoder\n", "from sklearn.tree import DecisionTreeClassifier, export_graphviz" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Часть 1. Игрушечный набор данных \"девушка в баре\"" ] }, { "cell_type": "markdown", "metadata": { "collapsed": true }, "source": [ "**Цель – \"на пальцах\", с помощью игрушечной задачи классификации разобраться в том, как работают деревья решений. Само по себе дерево решений – довольно слабый алгоритм, но основанные на нем алгоритмы случайного леса и градиентного бустинга - пожалуй, лучшее, что есть на сегодняшний день (в задачах, где можно обойтись без нейронных сетей). Поэтому разобраться в том, как работает дерево решений, полезно.**" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "**Рассмотрим игрушечную задачу бинарной классификации: поедет ли с Вами девушка из бара? Это будет зависеть от Вашей внешности и красноречия, крепости предлагаемых напитков и, как это ни меркантильно, от количества потраченных в баре денег.**\n", "
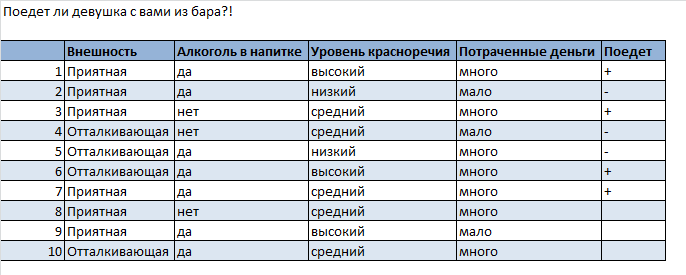 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Создание набора данных"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Создание датафрейма с dummy variables\n",
"def create_df(dic, feature_list):\n",
" out = pd.DataFrame(dic)\n",
" out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1)\n",
" out.drop(feature_list, axis = 1, inplace = True)\n",
" return out\n",
"\n",
"# Некоторые значения признаков есть в тесте, но нет в трейне и наоборот\n",
"def intersect_features(train, test):\n",
" common_feat = list( set(train.keys()) & set(test.keys()))\n",
" return train[common_feat], test[common_feat]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"features = ['Внешность', 'Алкоголь_в_напитке',\n",
" 'Уровень_красноречия', 'Потраченные_деньги']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучающая выборка**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_train = {}\n",
"df_train['Внешность'] = ['приятная', 'приятная', 'приятная', 'отталкивающая',\n",
" 'отталкивающая', 'отталкивающая', 'приятная'] \n",
"df_train['Алкоголь_в_напитке'] = ['да', 'да', 'нет', 'нет', 'да', 'да', 'да']\n",
"df_train['Уровень_красноречия'] = ['высокий', 'низкий', 'средний', 'средний', 'низкий',\n",
" 'высокий', 'средний']\n",
"df_train['Потраченные_деньги'] = ['много', 'мало', 'много', 'мало', 'много',\n",
" 'много', 'много']\n",
"df_train['Поедет'] = LabelEncoder().fit_transform(['+', '-', '+', '-', '-', '+', '+'])\n",
"\n",
"df_train = create_df(df_train, features)\n",
"df_train"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Тестовая выборка**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_test = {}\n",
"df_test['Внешность'] = ['приятная', 'приятная', 'отталкивающая'] \n",
"df_test['Алкоголь_в_напитке'] = ['нет', 'да', 'да']\n",
"df_test['Уровень_красноречия'] = ['средний', 'высокий', 'средний']\n",
"df_test['Потраченные_деньги'] = ['много', 'мало', 'много']\n",
"df_test = create_df(df_test, features)\n",
"df_test"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Некоторые значения признаков есть в тесте, но нет в трейне и наоборот\n",
"y = df_train['Поедет']\n",
"df_train, df_test = intersect_features(train=df_train, test=df_test)\n",
"df_train"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_test"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Постройте от руки (или в графическом редакторе) дерево решений для этого набора данных. Дополнительно (для желающих) – можете сделать отрисовку дерева и написать код для построения всего дерева.**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 1. Какова энтропия начальной системы ($S_0$)? Под состояниями системы понимаем значения признака \"Поедет\" – 0 или 1 (то есть всего 2 состояния)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 2. Рассмотрим разбиение обучающей выборки по признаку \"Внешность\\_приятная\". Какова энтропия $S_1$ левой группы, тех, у кого внешность приятная, и правой группы – $S_2$? Каков прирост информации при данном разбиении (IG)? "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Постройте с помощью `sklearn` дерево решений, обучив его на обучающей выборке. Глубину можно не ограничивать.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Дополнительно: отобразите дерево с помощью graphviz. Можно использовать `pydot` или, например, [онлайн-сервис](https://www.coolutils.com/ru/online/DOT-to-PNG) dot2png.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Часть 2. Функции для расчета энтропии и прироста информации"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Примерчик для проверки: 9 синих шариков и 11 желтых. Пусть шарик находится в состоянии \"1\", если он синий и \"0\" – если он желтый."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"balls = [1 for i in range(9)] + [0 for i in range(11)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Дальше пусть шарики разбиваются на 2 группы\n",
"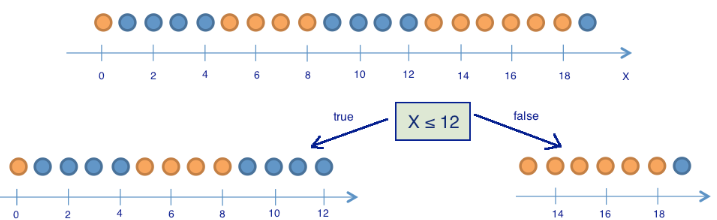"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# две группы\n",
"balls_left = [1 for i in range(8)] + [0 for i in range(5)] # 8 синих и 5 желтых\n",
"balls_right = [1 for i in range(1)] + [0 for i in range(6)] # 1 синий и 6 желтых"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Реализуйте функцию для расчета энтропии Шеннона.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def entropy(a_list):\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Проверка"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(entropy(balls)) # 9 синих и 11 желтых\n",
"print(entropy(balls_left)) # 8 синих и 5 желтых\n",
"print(entropy(balls_right)) # 1 синий и 6 желтых\n",
"print(entropy([1,2,3,4,5,6])) # энтропия игральной кости с несмещенным центром тяжести"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 3. Чему равна энтропия состояния, заданного списком `balls_left`?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 4. Чему равна энтропия игральной кости с несмещенным центром тяжести?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# расчет прироста информации\n",
"\n",
"def information_gain(root, left, right):\n",
" ''' root - изначальный набор данных, left и right два разбиения изначального набора'''\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 5. Каков прирост информации при разделении выборки на `balls_left` и `balls_right`?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def best_feature_to_split(X, y):\n",
" ''' Выводит прирост информации при разбиении по каждому признаку'''\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Опционально:**\n",
"\n",
" - реализуйте алгоритм построения дерева за счет рекурсивного вызова функции `best_feature_to_split`\n",
" - нарисуйте полученное дерево"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Часть 3. Набор данных \"Adult\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Описание набора:**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**[Набор](https://archive.ics.uci.edu/dataset/2/adult) данных UCI Adult** (качать не надо, все есть в репозитории): классификация людей с помощью демографических данных для прогнозирования, зарабатывает ли человек более \\$ 50 000 в год.\n",
"\n",
"Описание признаков: \n",
"\n",
"**Age** – возраст, количественный признак \n",
"**Workclass** – тип работодателя, количественный признак \n",
"**fnlwgt** – итоговый вес обьекта, количественный признак \n",
"**Education** – уровень образования, качественный признак \n",
"**Education_Num** – количество лет обучения, количественный признак \n",
"**Martial_Status** – семейное положение, категориальный признак \n",
"**Occupation** – профессия, категориальный признак \n",
"**Relationship** – тип семейных отношений, категориальный признак \n",
"**Race** – раса, категориальный признак \n",
"**Sex** – пол, качественный признак \n",
"**Capital_Gain** – прирост капитала, количественный признак \n",
"**Capital_Loss** – потери капитала, количественный признак \n",
"**Hours_per_week** – количество часов работы в неделю, количественный признак \n",
"**Country** – страна, категориальный признак \n",
" \n",
"Целевая переменная: **Target** – уровень заработка, категориальный (бинарный) признак "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Считываем обучающую и тестовую выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train = pd.read_csv('../../data/adult_train.csv', sep=';') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.tail()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test = pd.read_csv('../../data/adult_test.csv', sep=';') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.tail()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# необходимо убрать строки с неправильными метками в тестовой выборке\n",
"data_test = data_test[(data_test['Target'] == ' >50K.') \n",
" | (data_test['Target']==' <=50K.')]\n",
"\n",
"# перекодируем target в числовое поле\n",
"data_train.at[data_train['Target'] == ' <=50K', 'Target'] = 0\n",
"data_train.at[data_train['Target'] == ' >50K', 'Target'] = 1\n",
"\n",
"data_test.at[data_test['Target'] == ' <=50K.', 'Target'] = 0\n",
"data_test.at[data_test['Target'] == ' >50K.', 'Target'] = 1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Первичный анализ данных.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.describe(include='all').T"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train['Target'].value_counts()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(25, 15))\n",
"cols = 5\n",
"rows = np.ceil(float(data_train.shape[1]) / cols)\n",
"for i, column in enumerate(data_train.columns):\n",
" ax = fig.add_subplot(rows, cols, i + 1)\n",
" ax.set_title(column)\n",
" if data_train.dtypes[column] == np.object:\n",
" data_train[column].value_counts().plot(kind=\"bar\", axes=ax)\n",
" else:\n",
" data_train[column].hist(axes=ax)\n",
" plt.xticks(rotation=\"vertical\")\n",
"plt.subplots_adjust(hspace=0.7, wspace=0.2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Проверяем типы данных**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.dtypes"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Выяснилось, что в тесте возраст отнесен к типу object, необходимо это исправить."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['Age'] = data_test['Age'].astype(int)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Также приведем показатели типа float в int для соответствия train и test выборок."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['fnlwgt'] = data_test['fnlwgt'].astype(int)\n",
"data_test['Education_Num'] = data_test['Education_Num'].astype(int)\n",
"data_test['Capital_Gain'] = data_test['Capital_Gain'].astype(int)\n",
"data_test['Capital_Loss'] = data_test['Capital_Loss'].astype(int)\n",
"data_test['Hours_per_week'] = data_test['Hours_per_week'].astype(int)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Заполним пропуски в количественных полях медианными значениями, а в категориальных – наиболее часто встречающимся значением**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# выделим в выборках категориальные и числовые поля\n",
"\n",
"categorical_columns_train = [c for c in data_train.columns \n",
" if data_train[c].dtype.name == 'object']\n",
"numerical_columns_train = [c for c in data_train.columns \n",
" if data_train[c].dtype.name != 'object']\n",
"\n",
"categorical_columns_test = [c for c in data_test.columns \n",
" if data_test[c].dtype.name == 'object']\n",
"numerical_columns_test = [c for c in data_test.columns \n",
" if data_test[c].dtype.name != 'object']\n",
"\n",
"print('categorical_columns_test:', categorical_columns_test)\n",
"print('categorical_columns_train:', categorical_columns_train)\n",
"print('numerical_columns_test:', numerical_columns_test)\n",
"print('numerical_columns_train:', numerical_columns_train)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# заполним пропуски\n",
"\n",
"for c in categorical_columns_train:\n",
" data_train[c] = data_train[c].fillna(data_train[c].mode())\n",
"for c in categorical_columns_test:\n",
" data_test[c] = data_test[c].fillna(data_train[c].mode())\n",
" \n",
"for c in numerical_columns_train:\n",
" data_train[c] = data_train[c].fillna(data_train[c].median())\n",
"for c in numerical_columns_test:\n",
" data_test[c] = data_test[c].fillna(data_train[c].median()) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Кодируем категориальные признаки 'Workclass', 'Education', 'Martial_Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Country'. Это можно сделать с помощью метода `pandas get_dummies`.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train = pd.concat([data_train, pd.get_dummies(data_train['Workclass'], \n",
" prefix=\"Workclass\"),\n",
" pd.get_dummies(data_train['Education'], prefix=\"Education\"),\n",
" pd.get_dummies(data_train['Martial_Status'], prefix=\"Martial_Status\"),\n",
" pd.get_dummies(data_train['Occupation'], prefix=\"Occupation\"),\n",
" pd.get_dummies(data_train['Relationship'], prefix=\"Relationship\"),\n",
" pd.get_dummies(data_train['Race'], prefix=\"Race\"),\n",
" pd.get_dummies(data_train['Sex'], prefix=\"Sex\"),\n",
" pd.get_dummies(data_train['Country'], prefix=\"Country\")],\n",
" axis=1)\n",
"\n",
"data_test = pd.concat([data_test, pd.get_dummies(data_test['Workclass'], prefix=\"Workclass\"),\n",
" pd.get_dummies(data_test['Education'], prefix=\"Education\"),\n",
" pd.get_dummies(data_test['Martial_Status'], prefix=\"Martial_Status\"),\n",
" pd.get_dummies(data_test['Occupation'], prefix=\"Occupation\"),\n",
" pd.get_dummies(data_test['Relationship'], prefix=\"Relationship\"),\n",
" pd.get_dummies(data_test['Race'], prefix=\"Race\"),\n",
" pd.get_dummies(data_test['Sex'], prefix=\"Sex\"),\n",
" pd.get_dummies(data_test['Country'], prefix=\"Country\")],\n",
" axis=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.drop(['Workclass', 'Education', 'Martial_Status',\n",
" 'Occupation', 'Relationship', 'Race', 'Sex', 'Country'],\n",
" axis=1, inplace=True)\n",
"data_test.drop(['Workclass', 'Education', 'Martial_Status', 'Occupation', \n",
" 'Relationship', 'Race', 'Sex', 'Country'],\n",
" axis=1, inplace=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.describe(include='all').T"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"set(data_train.columns) - set(data_test.columns)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.shape, data_test.shape"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**В тестовой выборке не оказалось Голландии. Заведем необходимый признак из нулей.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['Country_ Holand-Netherlands'] = np.zeros([data_test.shape[0], 1])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"set(data_train.columns) - set(data_test.columns)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"X_train=data_train.drop(['Target'], axis=1)\n",
"y_train = data_train['Target']\n",
"\n",
"X_test=data_test.drop(['Target'], axis=1)\n",
"y_test = data_test['Target']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.1. Дерево решений без настройки параметров "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений (`DecisionTreeClassifier`) максимальной глубины 3 и получите качество на тесте. Используйте параметр `random_state` = 17 для воспроизводимости результатов.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree = # Ваш код здесь\n",
"tree.fit # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree_predictions = tree.predict # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 6. Какова доля правильных ответов дерева решений на тестовой выборке при максимальной глубине дерева = 3 и random_state = 17?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.2. Дерево решений с настройкой параметров "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений (`DecisionTreeClassifier`, опять `random_state` = 17 ). Максимальную глубину настройте на кросс-валидации с помощью `GridSearchCV`. Проведите 5-кратную кросс-валидацию**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree_params = {'max_depth': range(2,11)}\n",
"\n",
"locally_best_tree = GridSearchCV # Ваш код здесь \n",
"\n",
"locally_best_tree.fit # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"Best params:\", locally_best_tree.best_params_)\n",
"print(\"Best cross validaton score\", locally_best_tree.best_score_)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений максимальной глубины 9 (это лучшее значение `max_depth` в моем случае) и оцените долю правильных ответов на тесте. Используйте параметр random_state = 17 для воспроизводимости результатов.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tuned_tree = # Ваш код здесь\n",
"tuned_tree.fit # Ваш код здесь\n",
"tuned_tree_predictions = tuned_tree.predict # Ваш код здесь\n",
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 7. Какова доля правильных ответов дерева решений на тестовой выборке при максимальной глубине дерева = 9 и random_state = 17?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.3. Случайный лес без настройки параметров (опционально)¶"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Немного забежим вперед и попробуем в нашей задаче случайный лес. Пока можно его себе представлять, как куча деревьев решений, обученных на немного разных подвыборках исходной обучающей выборки, причем эта куча деревьев обычно работает существенно лучше, чем отдельные деревья. **\n",
"\n",
"**Обучите на имеющейся выборке случайный лес (`RandomForestClassifier`), число деревьев сделайте равным ста, а `random_state` = 17.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rf = # Ваш код здесь\n",
"rf.fit # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"forest_predictions = rf.predict # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.4. Случайный лес с настройкой параметров (опционально)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке случайный лес (`RandomForestClassifier`). Максимальную глубину и максимальное число признаков для каждого дерева настройте с помощью GridSearchCV.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"forest_params = {'max_depth': range(10, 21),\n",
" 'max_features': range(5, 105, 10)}\n",
"\n",
"locally_best_forest = GridSearchCV # Ваш код здесь\n",
"\n",
"locally_best_forest.fit # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"Best params:\", locally_best_forest.best_params_)\n",
"print(\"Best cross validaton score\", locally_best_forest.best_score_)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tuned_forest_predictions = locally_best_forest.predict # Ваш код здесь\n",
"accuracy_score # Ваш код здесь"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 1
}
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Создание набора данных"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Создание датафрейма с dummy variables\n",
"def create_df(dic, feature_list):\n",
" out = pd.DataFrame(dic)\n",
" out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1)\n",
" out.drop(feature_list, axis = 1, inplace = True)\n",
" return out\n",
"\n",
"# Некоторые значения признаков есть в тесте, но нет в трейне и наоборот\n",
"def intersect_features(train, test):\n",
" common_feat = list( set(train.keys()) & set(test.keys()))\n",
" return train[common_feat], test[common_feat]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"features = ['Внешность', 'Алкоголь_в_напитке',\n",
" 'Уровень_красноречия', 'Потраченные_деньги']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучающая выборка**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_train = {}\n",
"df_train['Внешность'] = ['приятная', 'приятная', 'приятная', 'отталкивающая',\n",
" 'отталкивающая', 'отталкивающая', 'приятная'] \n",
"df_train['Алкоголь_в_напитке'] = ['да', 'да', 'нет', 'нет', 'да', 'да', 'да']\n",
"df_train['Уровень_красноречия'] = ['высокий', 'низкий', 'средний', 'средний', 'низкий',\n",
" 'высокий', 'средний']\n",
"df_train['Потраченные_деньги'] = ['много', 'мало', 'много', 'мало', 'много',\n",
" 'много', 'много']\n",
"df_train['Поедет'] = LabelEncoder().fit_transform(['+', '-', '+', '-', '-', '+', '+'])\n",
"\n",
"df_train = create_df(df_train, features)\n",
"df_train"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Тестовая выборка**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_test = {}\n",
"df_test['Внешность'] = ['приятная', 'приятная', 'отталкивающая'] \n",
"df_test['Алкоголь_в_напитке'] = ['нет', 'да', 'да']\n",
"df_test['Уровень_красноречия'] = ['средний', 'высокий', 'средний']\n",
"df_test['Потраченные_деньги'] = ['много', 'мало', 'много']\n",
"df_test = create_df(df_test, features)\n",
"df_test"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Некоторые значения признаков есть в тесте, но нет в трейне и наоборот\n",
"y = df_train['Поедет']\n",
"df_train, df_test = intersect_features(train=df_train, test=df_test)\n",
"df_train"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_test"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Постройте от руки (или в графическом редакторе) дерево решений для этого набора данных. Дополнительно (для желающих) – можете сделать отрисовку дерева и написать код для построения всего дерева.**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 1. Какова энтропия начальной системы ($S_0$)? Под состояниями системы понимаем значения признака \"Поедет\" – 0 или 1 (то есть всего 2 состояния)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 2. Рассмотрим разбиение обучающей выборки по признаку \"Внешность\\_приятная\". Какова энтропия $S_1$ левой группы, тех, у кого внешность приятная, и правой группы – $S_2$? Каков прирост информации при данном разбиении (IG)? "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Постройте с помощью `sklearn` дерево решений, обучив его на обучающей выборке. Глубину можно не ограничивать.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Дополнительно: отобразите дерево с помощью graphviz. Можно использовать `pydot` или, например, [онлайн-сервис](https://www.coolutils.com/ru/online/DOT-to-PNG) dot2png.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Часть 2. Функции для расчета энтропии и прироста информации"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Примерчик для проверки: 9 синих шариков и 11 желтых. Пусть шарик находится в состоянии \"1\", если он синий и \"0\" – если он желтый."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"balls = [1 for i in range(9)] + [0 for i in range(11)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Дальше пусть шарики разбиваются на 2 группы\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# две группы\n",
"balls_left = [1 for i in range(8)] + [0 for i in range(5)] # 8 синих и 5 желтых\n",
"balls_right = [1 for i in range(1)] + [0 for i in range(6)] # 1 синий и 6 желтых"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Реализуйте функцию для расчета энтропии Шеннона.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def entropy(a_list):\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Проверка"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(entropy(balls)) # 9 синих и 11 желтых\n",
"print(entropy(balls_left)) # 8 синих и 5 желтых\n",
"print(entropy(balls_right)) # 1 синий и 6 желтых\n",
"print(entropy([1,2,3,4,5,6])) # энтропия игральной кости с несмещенным центром тяжести"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 3. Чему равна энтропия состояния, заданного списком `balls_left`?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 4. Чему равна энтропия игральной кости с несмещенным центром тяжести?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# расчет прироста информации\n",
"\n",
"def information_gain(root, left, right):\n",
" ''' root - изначальный набор данных, left и right два разбиения изначального набора'''\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 5. Каков прирост информации при разделении выборки на `balls_left` и `balls_right`?"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def best_feature_to_split(X, y):\n",
" ''' Выводит прирост информации при разбиении по каждому признаку'''\n",
" \n",
" # Ваш код здесь\n",
" pass"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Опционально:**\n",
"\n",
" - реализуйте алгоритм построения дерева за счет рекурсивного вызова функции `best_feature_to_split`\n",
" - нарисуйте полученное дерево"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Часть 3. Набор данных \"Adult\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Описание набора:**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**[Набор](https://archive.ics.uci.edu/dataset/2/adult) данных UCI Adult** (качать не надо, все есть в репозитории): классификация людей с помощью демографических данных для прогнозирования, зарабатывает ли человек более \\$ 50 000 в год.\n",
"\n",
"Описание признаков: \n",
"\n",
"**Age** – возраст, количественный признак \n",
"**Workclass** – тип работодателя, количественный признак \n",
"**fnlwgt** – итоговый вес обьекта, количественный признак \n",
"**Education** – уровень образования, качественный признак \n",
"**Education_Num** – количество лет обучения, количественный признак \n",
"**Martial_Status** – семейное положение, категориальный признак \n",
"**Occupation** – профессия, категориальный признак \n",
"**Relationship** – тип семейных отношений, категориальный признак \n",
"**Race** – раса, категориальный признак \n",
"**Sex** – пол, качественный признак \n",
"**Capital_Gain** – прирост капитала, количественный признак \n",
"**Capital_Loss** – потери капитала, количественный признак \n",
"**Hours_per_week** – количество часов работы в неделю, количественный признак \n",
"**Country** – страна, категориальный признак \n",
" \n",
"Целевая переменная: **Target** – уровень заработка, категориальный (бинарный) признак "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Считываем обучающую и тестовую выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train = pd.read_csv('../../data/adult_train.csv', sep=';') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.tail()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test = pd.read_csv('../../data/adult_test.csv', sep=';') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.tail()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# необходимо убрать строки с неправильными метками в тестовой выборке\n",
"data_test = data_test[(data_test['Target'] == ' >50K.') \n",
" | (data_test['Target']==' <=50K.')]\n",
"\n",
"# перекодируем target в числовое поле\n",
"data_train.at[data_train['Target'] == ' <=50K', 'Target'] = 0\n",
"data_train.at[data_train['Target'] == ' >50K', 'Target'] = 1\n",
"\n",
"data_test.at[data_test['Target'] == ' <=50K.', 'Target'] = 0\n",
"data_test.at[data_test['Target'] == ' >50K.', 'Target'] = 1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Первичный анализ данных.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.describe(include='all').T"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train['Target'].value_counts()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(25, 15))\n",
"cols = 5\n",
"rows = np.ceil(float(data_train.shape[1]) / cols)\n",
"for i, column in enumerate(data_train.columns):\n",
" ax = fig.add_subplot(rows, cols, i + 1)\n",
" ax.set_title(column)\n",
" if data_train.dtypes[column] == np.object:\n",
" data_train[column].value_counts().plot(kind=\"bar\", axes=ax)\n",
" else:\n",
" data_train[column].hist(axes=ax)\n",
" plt.xticks(rotation=\"vertical\")\n",
"plt.subplots_adjust(hspace=0.7, wspace=0.2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Проверяем типы данных**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.dtypes"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Выяснилось, что в тесте возраст отнесен к типу object, необходимо это исправить."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['Age'] = data_test['Age'].astype(int)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Также приведем показатели типа float в int для соответствия train и test выборок."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['fnlwgt'] = data_test['fnlwgt'].astype(int)\n",
"data_test['Education_Num'] = data_test['Education_Num'].astype(int)\n",
"data_test['Capital_Gain'] = data_test['Capital_Gain'].astype(int)\n",
"data_test['Capital_Loss'] = data_test['Capital_Loss'].astype(int)\n",
"data_test['Hours_per_week'] = data_test['Hours_per_week'].astype(int)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Заполним пропуски в количественных полях медианными значениями, а в категориальных – наиболее часто встречающимся значением**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# выделим в выборках категориальные и числовые поля\n",
"\n",
"categorical_columns_train = [c for c in data_train.columns \n",
" if data_train[c].dtype.name == 'object']\n",
"numerical_columns_train = [c for c in data_train.columns \n",
" if data_train[c].dtype.name != 'object']\n",
"\n",
"categorical_columns_test = [c for c in data_test.columns \n",
" if data_test[c].dtype.name == 'object']\n",
"numerical_columns_test = [c for c in data_test.columns \n",
" if data_test[c].dtype.name != 'object']\n",
"\n",
"print('categorical_columns_test:', categorical_columns_test)\n",
"print('categorical_columns_train:', categorical_columns_train)\n",
"print('numerical_columns_test:', numerical_columns_test)\n",
"print('numerical_columns_train:', numerical_columns_train)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# заполним пропуски\n",
"\n",
"for c in categorical_columns_train:\n",
" data_train[c] = data_train[c].fillna(data_train[c].mode())\n",
"for c in categorical_columns_test:\n",
" data_test[c] = data_test[c].fillna(data_train[c].mode())\n",
" \n",
"for c in numerical_columns_train:\n",
" data_train[c] = data_train[c].fillna(data_train[c].median())\n",
"for c in numerical_columns_test:\n",
" data_test[c] = data_test[c].fillna(data_train[c].median()) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Кодируем категориальные признаки 'Workclass', 'Education', 'Martial_Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Country'. Это можно сделать с помощью метода `pandas get_dummies`.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train = pd.concat([data_train, pd.get_dummies(data_train['Workclass'], \n",
" prefix=\"Workclass\"),\n",
" pd.get_dummies(data_train['Education'], prefix=\"Education\"),\n",
" pd.get_dummies(data_train['Martial_Status'], prefix=\"Martial_Status\"),\n",
" pd.get_dummies(data_train['Occupation'], prefix=\"Occupation\"),\n",
" pd.get_dummies(data_train['Relationship'], prefix=\"Relationship\"),\n",
" pd.get_dummies(data_train['Race'], prefix=\"Race\"),\n",
" pd.get_dummies(data_train['Sex'], prefix=\"Sex\"),\n",
" pd.get_dummies(data_train['Country'], prefix=\"Country\")],\n",
" axis=1)\n",
"\n",
"data_test = pd.concat([data_test, pd.get_dummies(data_test['Workclass'], prefix=\"Workclass\"),\n",
" pd.get_dummies(data_test['Education'], prefix=\"Education\"),\n",
" pd.get_dummies(data_test['Martial_Status'], prefix=\"Martial_Status\"),\n",
" pd.get_dummies(data_test['Occupation'], prefix=\"Occupation\"),\n",
" pd.get_dummies(data_test['Relationship'], prefix=\"Relationship\"),\n",
" pd.get_dummies(data_test['Race'], prefix=\"Race\"),\n",
" pd.get_dummies(data_test['Sex'], prefix=\"Sex\"),\n",
" pd.get_dummies(data_test['Country'], prefix=\"Country\")],\n",
" axis=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.drop(['Workclass', 'Education', 'Martial_Status',\n",
" 'Occupation', 'Relationship', 'Race', 'Sex', 'Country'],\n",
" axis=1, inplace=True)\n",
"data_test.drop(['Workclass', 'Education', 'Martial_Status', 'Occupation', \n",
" 'Relationship', 'Race', 'Sex', 'Country'],\n",
" axis=1, inplace=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.describe(include='all').T"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"set(data_train.columns) - set(data_test.columns)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.shape, data_test.shape"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**В тестовой выборке не оказалось Голландии. Заведем необходимый признак из нулей.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test['Country_ Holand-Netherlands'] = np.zeros([data_test.shape[0], 1])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"set(data_train.columns) - set(data_test.columns)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_train.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_test.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"X_train=data_train.drop(['Target'], axis=1)\n",
"y_train = data_train['Target']\n",
"\n",
"X_test=data_test.drop(['Target'], axis=1)\n",
"y_test = data_test['Target']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.1. Дерево решений без настройки параметров "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений (`DecisionTreeClassifier`) максимальной глубины 3 и получите качество на тесте. Используйте параметр `random_state` = 17 для воспроизводимости результатов.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree = # Ваш код здесь\n",
"tree.fit # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree_predictions = tree.predict # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 6. Какова доля правильных ответов дерева решений на тестовой выборке при максимальной глубине дерева = 3 и random_state = 17?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.2. Дерево решений с настройкой параметров "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений (`DecisionTreeClassifier`, опять `random_state` = 17 ). Максимальную глубину настройте на кросс-валидации с помощью `GridSearchCV`. Проведите 5-кратную кросс-валидацию**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tree_params = {'max_depth': range(2,11)}\n",
"\n",
"locally_best_tree = GridSearchCV # Ваш код здесь \n",
"\n",
"locally_best_tree.fit # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"Best params:\", locally_best_tree.best_params_)\n",
"print(\"Best cross validaton score\", locally_best_tree.best_score_)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке дерево решений максимальной глубины 9 (это лучшее значение `max_depth` в моем случае) и оцените долю правильных ответов на тесте. Используйте параметр random_state = 17 для воспроизводимости результатов.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tuned_tree = # Ваш код здесь\n",
"tuned_tree.fit # Ваш код здесь\n",
"tuned_tree_predictions = tuned_tree.predict # Ваш код здесь\n",
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Вопрос 7. Какова доля правильных ответов дерева решений на тестовой выборке при максимальной глубине дерева = 9 и random_state = 17?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.3. Случайный лес без настройки параметров (опционально)¶"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Немного забежим вперед и попробуем в нашей задаче случайный лес. Пока можно его себе представлять, как куча деревьев решений, обученных на немного разных подвыборках исходной обучающей выборки, причем эта куча деревьев обычно работает существенно лучше, чем отдельные деревья. **\n",
"\n",
"**Обучите на имеющейся выборке случайный лес (`RandomForestClassifier`), число деревьев сделайте равным ста, а `random_state` = 17.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rf = # Ваш код здесь\n",
"rf.fit # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"forest_predictions = rf.predict # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"accuracy_score # Ваш код здесь"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.4. Случайный лес с настройкой параметров (опционально)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Обучите на имеющейся выборке случайный лес (`RandomForestClassifier`). Максимальную глубину и максимальное число признаков для каждого дерева настройте с помощью GridSearchCV.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"forest_params = {'max_depth': range(10, 21),\n",
" 'max_features': range(5, 105, 10)}\n",
"\n",
"locally_best_forest = GridSearchCV # Ваш код здесь\n",
"\n",
"locally_best_forest.fit # Ваш код здесь"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"Best params:\", locally_best_forest.best_params_)\n",
"print(\"Best cross validaton score\", locally_best_forest.best_score_)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Сделайте с помощью полученной модели прогноз для тестовой выборки.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tuned_forest_predictions = locally_best_forest.predict # Ваш код здесь\n",
"accuracy_score # Ваш код здесь"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 1
}