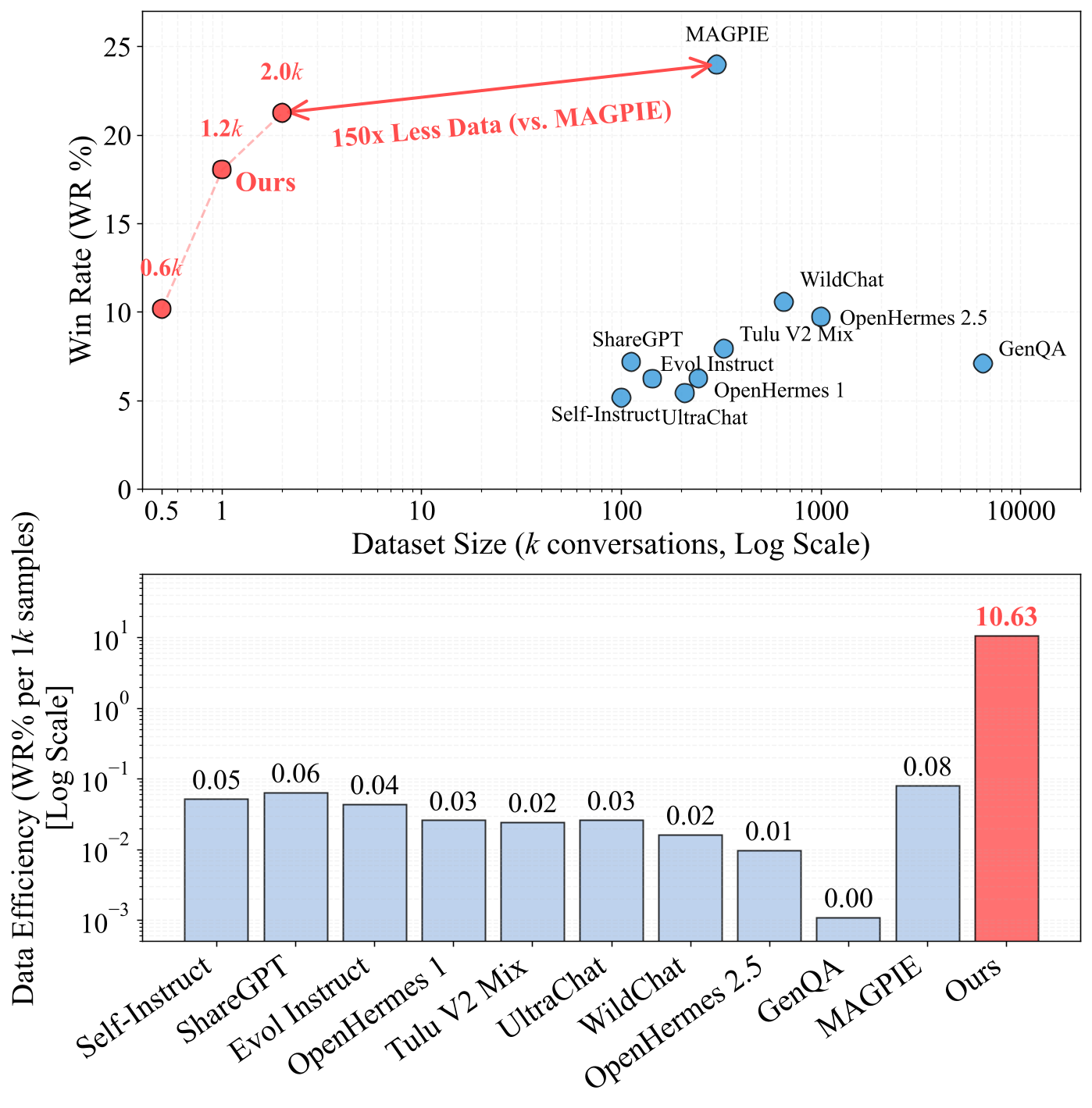
Figure 1: The Efficiency Frontier of Instruction Following Datasets. Our proposed method achieves a Win Rate on AlpacaEval 2.0 comparable to MAGPIE while using only 2K synthetic samples (vs. 300K for MAGPIE).
--- ## Getting Started ### Installation ```bash git clone https://github.com/Zhongzhi660/FAC-Synthesis.git cd FAC-Synthesis pip install -r requirements.txt ``` --- ### Repository Structure ```text FAC-Synthesis/ ├── LICENSE ├── README.md ├── requirements.txt │ ├── sae_pretrain/ # SAE pretraining │ ├── datasets/ # pretraining corpora (constructed from public sources) │ └── outputs/ # SAE pre-trained weights │ ├── sae_feature_analysis/ # SAE feature analysis pipeline │ ├── interpret_features/ # feature interpretation (span collection + annotation) │ ├── identify_task_relevant_features/ # task-relevant feature identification │ └── identify_missing_features/ # missing-feature discovery (coverage gap) │ ├── fac_synthesis/ # FAC synthesis pipeline │ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction │ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis │ └── training_scripts/ # Downstream training / evaluation scripts ├── toxicity_detection/ ├── reward_modeling/ ├── instruction_following/ └── behavior_steering/ ``` ### Pre-training Sparse Autoencoders Most of the scripts for SAE pretraining are located in `sae_pretrain/`. We provide pre-trained SAE checkpoints on Hugging Face: - **Llama-3.1-8B-Instruct SAE**: [Zhongzhi1228/sae_llama_l16_h65536](https://huggingface.co/Zhongzhi1228/sae_llama_l16_h65536) - **Qwen2-7B-Instruct SAE**: [Zhongzhi1228/sae_qwen_l14_h65536](https://huggingface.co/Zhongzhi1228/sae_qwen_l14_h65536) - **Mistral-7B-Instruct SAE**: [Zhongzhi1228/sae_mistral_l16_h65536](https://huggingface.co/Zhongzhi1228/sae_mistral_l16_h65536) To pre-train SAEs, run the following commands: ```bash # Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16) python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16 # Step-2: Train SAEs on the target layer (e.g., layer 16) python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16 ``` ### Analyzing the features of SAE Feature analysis scripts are located in `sae_feature_analysis/`. To group activation spans and generate human-readable feature interpretations, run: ```bash # Step-1: Group extracted activation spans python groupby_textspans.py /xxx/threshold_0.0 # Step-2: Annotate feature explanations based on grouped spans python annotate_explanations.py /xxx/threshold_0.0.tsv # Step-3: Identify task-relevant features from the explanations python annotate_toxicity.py /xxx/threshold_0.0_explained.tsv # Step-4: Identify missing features via FAC analysis python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available) ``` ### Coverage-guided data synthesis Coverage-guided synthesis scripts are located in fac_synthesis/. To generate synthetic queries, run ```bash # Step-1 (1): Contrastive Pair Construction python generate_data_llama_r1.py \ --features xxx.tsv \ --out xxx \ --temperature 0.8 # Step-1 (2): Feature-Covered Sample Synthesis python analyze_step1_synthetic_data.py python merge_step1_failed_cases.py # Step-2: Feature-Covered Sample Synthesis python generate_data_llama_r2.py \ --features xxx.tsv \ --out xxx \ --temperature 0.8 ``` --- ## Acknowledgements In the evaluation stage, our downstream training and testing scripts are adapted from the following open-source repositories: - [RLHF-Reward-Modeling](https://github.com/RLHFlow/RLHF-Reward-Modeling) - [CAA](https://github.com/nrimsky/CAA) - [LLaMAFactory](https://github.com/hiyouga/LLaMAFactory) ## Citation If you find this work helpful for your research, please cite our paper 🤩: ```bibtex @article{li2026less, title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs}, author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao}, journal={arXiv preprint arXiv:2602.10388}, year={2026} } ```