

Spry XML data set advanced examples
Spry XML data sets use the browser’s XMLHTTPRequest object to asynchronously load the specified URL. When the XML data arrives, it is actually in two formats: a text format, and a document object model (DOM) tree format.
For example, say that you’ve specified “/photos.php?galleryid=2000” as your data source. (This is a path to a web service that retrieves XML data).
<script type="text/javascript">
var dsPhotos = new Spry.Data.XMLDataSet("/photos.php?galleryid=2000", "/gallery/photos/photo");
</script>
The following code represents the data as it arrives in text format:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following example represents the data as it arrives in DOM-tree format.
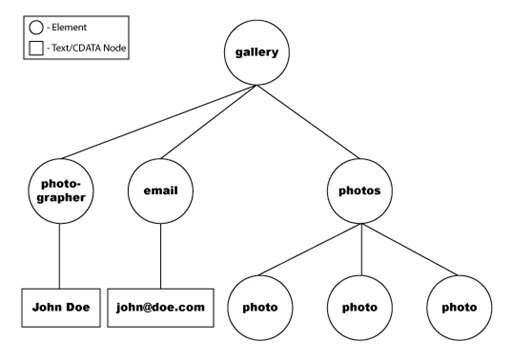
The data set then uses the XPath specified in the constructor to navigate the XML DOM tree to find the particular nodes that represent the data you are interested in.
The following code shows data selected with the /gallery/photos/photo XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16"/> <photo path="tree.jpg" width="16" height="16"/> <photo path="surf.jpg" width="16" height="16"/> </photos> </gallery>
The following example is the DOM-tree representation of the selected nodes.
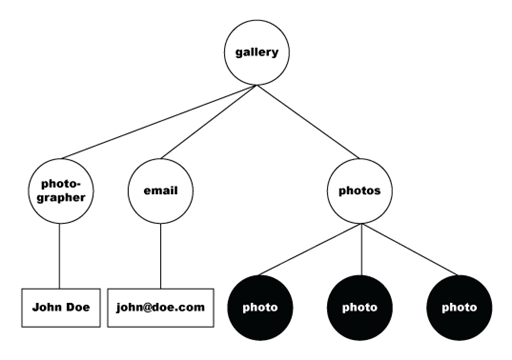
The data set then flattens the set of nodes into a tabular format, which the following table represents.
|
@path |
@width |
@height |
|---|---|---|
|
sun.jpg |
16 |
16 |
|
tree.jpg |
16 |
16 |
|
surf.jpg |
16 |
16 |
In this instance, Spry derives the column names of the flattened table from the selected nodes and their attributes. The way Spry determines column names, however, can vary, depending on the XPath you specify.
Spry uses the following guidelines when flattening data and creating columns:
-
If the selected node has attributes, Spry creates a column for each attribute and places the value of the attribute in that column. The names for these columns are the names of the attributes preceded by an @ sign. For example, if a node has an id attribute, the column name is @id.
-
If the selected node has no element children, and has text or CDATA underneath it, then Spry creates a column and places that text or CDATA in that column. The name of this column is the tag name of the node for normal XML elements.
-
If the selected node has element children, Spry creates a column for the value of each element and its attributes, but only for each element child that has no element children of its own. The names of the columns are the tag names of the children elements, or in the case of an attribute on a child element, the format "childTagName/@attrName".
-
If the selected node is an attribute, Spry creates a column for the attribute, and the column name is the name of the attribute preceded by an @ sign.
-
Spry ignores element children that have their own element children.
The examples that follow provide more details on the flattening process and how Spry generates column names for data sets.
For more information on controlling the flattening process beyond what Spry does by default, see the Nested XML Data samples page on Adobe Labs.
Example of selecting and flattening an element with attributes and a text value
The following code shows data selected with the /gallery/photographer XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected node.
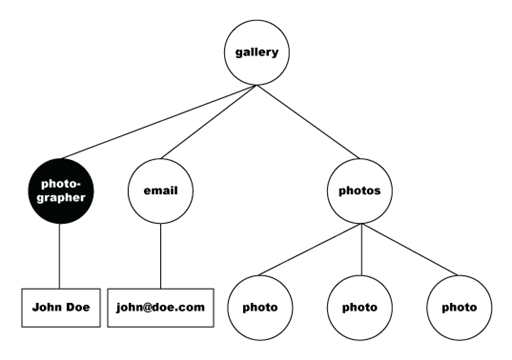
The data set then flattens the selected data into the following table.
|
photographer |
@id |
|---|---|
|
John Doe |
4532 |
In this particular case, only one node is selected, so you get only one row in the data set. The value of the photographer node is the text "John Doe", so a column named photographer is created to store that value. The id attribute is an attribute of the photographer node, so its value is placed in the @id column. All attribute names are preceded by an @ sign.
Example of selecting and flattening an element with attributes and element children
The following code shows data selected with the /gallery XPath:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected node:
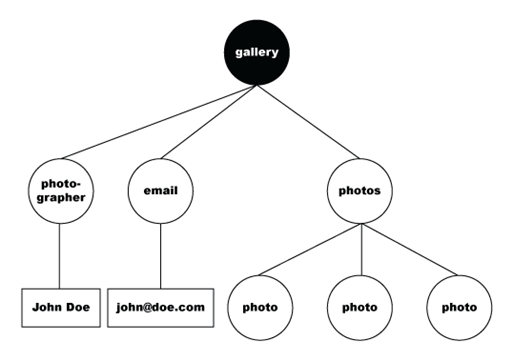
The data set then flattens the selected data into the following table.
|
@id |
photographer |
photographer/@id |
|
|---|---|---|---|
|
12345 |
John Doe |
4532 |
john@doe.com |
Notice that the column names for attributes of children elements are prefixed with the tag name of the child element. In this particular case, photographer is a child element of the selected gallery node, so its id attribute is prefixed with photographer/@. Also notice that nothing was added to the table for the photos element, even though it is a child of the gallery node. That is because Spry does not flatten any child elements that contain other elements.
Example of selecting and flattening an attribute of a single element
With XPath you can also select attributes of nodes. The following code shows data selected with the gallery/photos/photo/@path XPath, in bold:
<gallery id="12345"> <photographer id="4532">John Doe</photographer> <email>john@doe.com</email> <photos id="2000"> <photo path="sun.jpg" width="16" height="16" /> <photo path="tree.jpg" width="16" height="16" /> <photo path="surf.jpg" width="16" height="16" /> </photos> </gallery>
The following is the DOM-tree representation of the selected nodes.
The data set then flattens the selected data into the following table.
|
@path |
|---|
|
sun.jpg |
|
tree.jpg |
|
surf.jpg |